基于跨视图原型非对比学习的异构图嵌入模型
2024-11-04张敏杨雨晴贺艳婷史晨辉





摘 要:
基于非对比学习(NCL)的异构图嵌入模型不依赖负样本学习数据的内在特征和模式,可能导致模型无法有效地学习节点之间的区分度。提出了一种基于跨视图原型非对比学习的异构图嵌入模型(XP-NCL),通过寻找额外的正样本提供更多关于源节点的上下文信息,并重新考虑了正样本之间的相似性,从而为下游任务学习更高效的节点表征。该模型首先设计了一种基于异构图随机游走的树型结构,通过筛选出满足局部结构约束的随机游走路径,从而构建正样本的有向筛选树(DFT),该树包含丰富的邻居信息和语义信息;其次针对异构图的特性,定义了跨视图原型指数(ISDR)和峰值算子(peak operator),从多个维度考虑了同类样本在数量和数值上的对齐;在此基础上,模型利用停止梯度更新进行训练。最后,在ACM、DBLP和freebase数据集上,实验验证了节点的分类和聚类性能,结果表明,即使不使用负样本,XP-NCL表征与其他同构图和异构图基线相比,很多情况下都可以呈现出更优越的性能。
关键词:异构图嵌入;非对比学习;有向筛选树正样本采样;交对称差比;峰值算子
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2024)09-007-2611-09
doi:10.19734/j.issn.1001-3695.2024.01.0016
Heterogeneous graph embedding based on cross-view prototype non-contrastive learning
Zhang Min, Yang Yuqing, He Yanting, Shi Chenhui
(School of Computer Science & Technology, Taiyuan University of Science & Technology, Taiyuan 030024, China)
Abstract:
Heterogeneous graph embedding models based on non-contrastive learning (NCL) do not rely on negative sampling to learn the intrinsic features and patterns, which may cause the model fail to efficiently learn the differences between vertexes. This paper proposed a heterogeneous graph embedding model based on cross-view prototype non-contrastive learning (XP-NCL), which learnt better node representations for downstream tasks by finding additional positive samples with more contextual information, and reconsidered the similarity between positive samples. The model firstly designed a tree structure based on random walks in heterogeneous graph. This directed filtering tree (DFT) about positive samples contained rich neighboring and semantic information by filtering out random walk paths that satisfied local structural constraints. Secondly, to achieve the alignment of similar samples in terms of numerical and quantitative from multiple dimensions, XP-NCL defined the cross-view prototype index (ISDR) and peak operator based on the characteristics of heterogeneous graphs. Furthermore, the model trained using stop-gradient updating. Finally, experiments verify the classification and clustering performance of the node on ACM, DBLP and freebase datasets, and the results show that even without the negative samples, the XP-NCL representation can achieve superior performance in many cases compared to other homogeneous and heterogeneous graph baselines.
Key words:heterogeneous graph embedding; non-contrastive learning; directed filtering tree positive sampling; intersection to symmetric difference ratio; peak operator
0 引言
非对比学习通常使用一些技术来实现下游任务的良好表示,如梯度更新策略[1,2]和额外的预测操作[3~5]等。与对比学习(CL)相比,非对比学习不依赖负样本对,这使得它们在许多情况下更容易实现,训练过程也更加简单和直观。例如,当没有明确的负样本定义时,非对比学习可能更适用。另一方面,选择高质量的负样本是一个挑战,负样本应该与正样本在语义上不相关,但在实践中,确定哪些样本不相关常常是困难的,不恰当选择的负样本可能导致模型的性能下降。如果负样本的数量远远大于正样本,模型可能会过度关注于负样本,而忽略了正样本的精确识别,且非对比学习通常具有更强的泛化能力。由于非对比学习不依赖于对比学习样本,在许多应用场景中能够更好地适应不同分布的数据集。特别是在包含复杂的多类型节点和关系的异构图(如真实的生物网络、社交网络和引文网络)中,其中的正样本通常是具有相似语义或相关性的节点对,而负样本则是随机采样的,与正样本之间可能存在较大的语义鸿沟,这种语义鸿沟可能会影响模型的学习效果。因此,在本文中,利用非对比学习对异构图进行表示。有关异构图表示学习的相关技术及应用,可以参考文献[6~9]。
然而,目前基于NCL的异构图嵌入模型仍处于早期阶段,存在一些局限性。特别是,异构图中不同类型和数量的节点和边表示了各种各样的关系,这种复杂性使得对其进行统一的表示变得困难。在异构图非对比学习任务中,常常通过构建多个视图对其中的节点信息进行编码,然后利用不同视图下的编码向量完成对比学习任务,如元路径视图和网络模式视图。这些视图通过不同角度考虑异构图中的节点关系和属性,可以充分挖掘异构图中的异质性。与对比学习相比,非对比学习无须额外的负样本,可以简化训练过程,降低数据处理的复杂性,但由此产生的统一表征可能无法有效捕捉节点之间的局部拓扑结构。因此,常常需要额外的正样本提供更多关于源节点的上下文信息,以帮助模型更好地理解异构图中的结构和语义信息。另一方面,非对比学习可能更关注于学习样本的内在特性,而不是仅仅依赖于样本之间的相似性。因此,它具有更好的泛化能力,能够在未见过的数据上表现更好。但是由于负样本的缺失,模型可能无法有效地学习节点之间的区分度,从而影响模型的性能,由此产生的统一表示可能会导致下游任务崩溃。因此,在构建NCL任务时,常常需要重新考虑正样本之间的相似性。本文通过元路径视图及网络模式视图对异构图进行嵌入表示,并且以原型损失为指导,构建了新的跨视图原型指数和峰值算子,从数值上和数量上实现了不同视图下节点特征表示的对齐。作为非对比学习模型的代表作,BYOL旨在最大限度地减少在线网络预测的目标网络表示之间的相似性损失。以BYOL[1]为基本框架,本文的贡献包括以下几点:
a)提出了一种用于异构图嵌入的跨视图原型非对比学习模型,该模型在没有负样本的情况下,也可以为下游任务学到节点的良好表示,且XP-NCL是第一个从有向筛选树中选择正样本而不需要任何负样本的工作。
b)设计了一种基于异构图随机游走的树型结构,通过选择异构图中满足局部结构约束的随机游走路径,从而构建正样本有向筛选树,该树包含丰富的邻居信息和语义信息。
c)针对异构图的特性,定义了跨视图原型指数(交对称差比,ISDR)和峰值算子(peak operator),分别从多个角度实现了样本在数量和数值上的对齐,包括跨视图同类样本在数量上的对齐,每个视图中实例和原型的对齐,以及跨视图实例之间的对齐。
1 符号描述
在本章中,给出了异构图的一些形式化定义和异构图嵌入的定义。图1提供了图示说明,表1总结了常用符号。
4 实验
在本章中,将通过实验来证明XP-NCL在异构图嵌入方面的作用。实验旨在回答以下几个问题:
Q1:XP-NCL在节点分类方面表现如何?
Q2:XP-NCL在节点聚类方面表现如何?
Q3:上述各部分损失的影响是什么?
Q4:不同动态加权方式对下游任务的影响如何?
4.1 数据描述
实验使用了三种常见的异构图,以评估XP-NCL与其他基线相比的性能。具体来说,使用ACM、DBLP和freebase数据集进行节点分类和聚类测试,表3提供了这些数据集的简单统计信息。
a)ACM:该数据集提取了发表在KDD、SIGMOD、SIGCOMM、MobiCOMM和VLDB上的论文,并将论文分为三类(数据库、无线通信和数据挖掘)。每篇论文都有与之相关的作者和术语,这些关系由元路径集{PAP, PSP}表示。
b)DBLP:这是一个计算机科学书目网站。采用的是文献[22]提取的DBLP子集。最终的任务是将作者分为数据库、数据挖掘、人工智能和信息检索四个研究领域。
c)freebase:该数据集的目标节点是电影,并将其分为三类。采用了文献[37]中的一个子集。在实验中,考虑了元路径{MAM、MDM、MWM}。
4.2 对比算法
将XP-NCL与不同类型的图嵌入模型(包括无监督同构图和异构图嵌入模型)进行了比较。
a)无监督同构图嵌入方法:DGI[5]最大化节点局部表示和全局表示之间的互信息来学习节点的表示。GraphCL[11]提出了一种图对比学习框架,用于学习图数据的无监督表示。
b)无监督异构图嵌入方法:HERec[38]基于元路径的随机游走策略来学习节点表示。MetaGraph2Vec[39]使用元图进行随机游走的生成,并学习多类型异构图节点的潜在表示。DMGI[23]引入了正则化框架,以最小化特定关系类型节点嵌入之间的不一致性。HeCo[22]首次使用网络模式和元路径来构建对比视图。
c)对比实验设置:对于同构图嵌入方法{DGI、GraphCL},测试了它们的所有元路径,并报告了最佳性能。在DGI和DMGI中,将epoch设为1 000,学习率设为0.000 5。其他参数保持默认值。在GraphCL和HeCo中,设置提前停止的patience为20。在MetaGraph2Vec中,设置每个节点的游走次数为10,每次随机游走的长度为100。对于所有基线,在模型运行结束后都会保留其嵌入结果,并使用相同的分类和聚类方法对其进行验证。
4.3 实验设计
至于本文提出的模型,实验是在Python 3.7环境下使用PyTorch 1.10.2实现的。所有实验均在配备80 GB显存的NVIDIA A800 GPU上进行。实验采用Adam优化器训练模型,并从{8E-4, 9E-4, 1E-3, 1E-2}中微调学习率。在线网络和目标网络中的投影头和预测头的参数设计:在线网络中,同时包含投影头和预测头,投影头为两层全连接网络,其输入维度、中间层维度、输出维度分别为64、384、64;预测头为两层全连接层,其输入维度、中间层维度、输出维度分别为64、128、64;在目标网络中,仅包含投影头,其输入维度、中间层维度、输出维度分别为64、384、64。起初,邻近样本的数量通过HeCo选择,并对其进行了微调。对于正样本屏蔽,从{0.1, 0.2, 0.3}中选择比例。为进行公平比较,将嵌入维度设为64,并随机运行10次实验。在测试分类任务模块时,学习率设定为0.01;在测试聚类任务时,应用K-means,最大迭代次数设为500。
4.4 分类结果
使用学习到的表示来训练线性分类器,在每个数据集中,随机选择每类20、40、60个标记节点作为训练集,1 000个节点作为验证集,1 000个节点作为测试集,并使用macro-F1、micro-F1和AUC作为评估指标。表4列出了所有结果,这些结果都是在α=cos(θ/2)-θ/2-1/2取得的。从表4中可以看出,XP-NCL在很多情况下都取得了最佳性能。通过对结果的分析,得出以下结论:
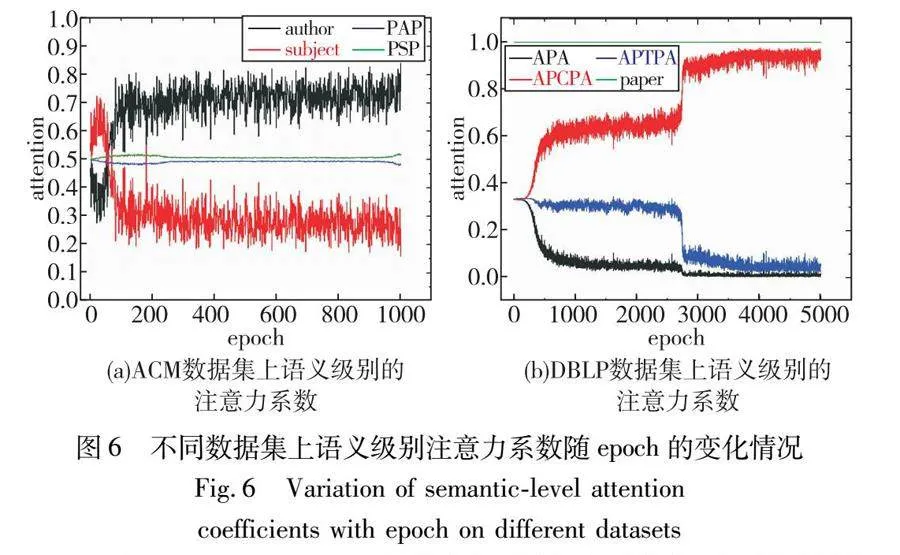
a)在所有基线中,异构图表示方法的整体结果要比同构图更好一些,这表明充分挖掘异构图中的丰富语义信息是十分必要的。如图6所示,对在线网络和目标网络在模型训练过程中的语义级注意力系数进行了可视化。在ACM数据集中,每个论文节点有一个主题和多个作者邻居,因此随着模型的训练,作者类节点的注意力系数越来越大。与节点级语义信息相比,基于元路径的语义信息的注意力系数变化较小。这说明在模型训练的初始阶段,元路径通常包含更丰富的语义信息。在DBLP数据集中,作者只与论文有边连接,因此关于论文的节点级注意力系数总是1。随着模型的训练,元路径APCPA的权重越来越大,这是因为大部分会议中本身就包含了术语的信息。
b)从AUC指标来看,在ACM数据集中,XP-NCL的结果比其他算法要差一些,但在BDLP数据集中却取得了最好的结果。这一现象可能与数据集中样本类别的数量分布有关系,在ACM数据集中,最多的一类节点数量是最少一类节点数量的二倍。
c)与HeCo相比,本文的方法在很多情况下取得了更好的结果。这表明,即使没有负样本,XP-NCL仍然有效,也就是说,负样本在对比学习框架中并不是必需的。
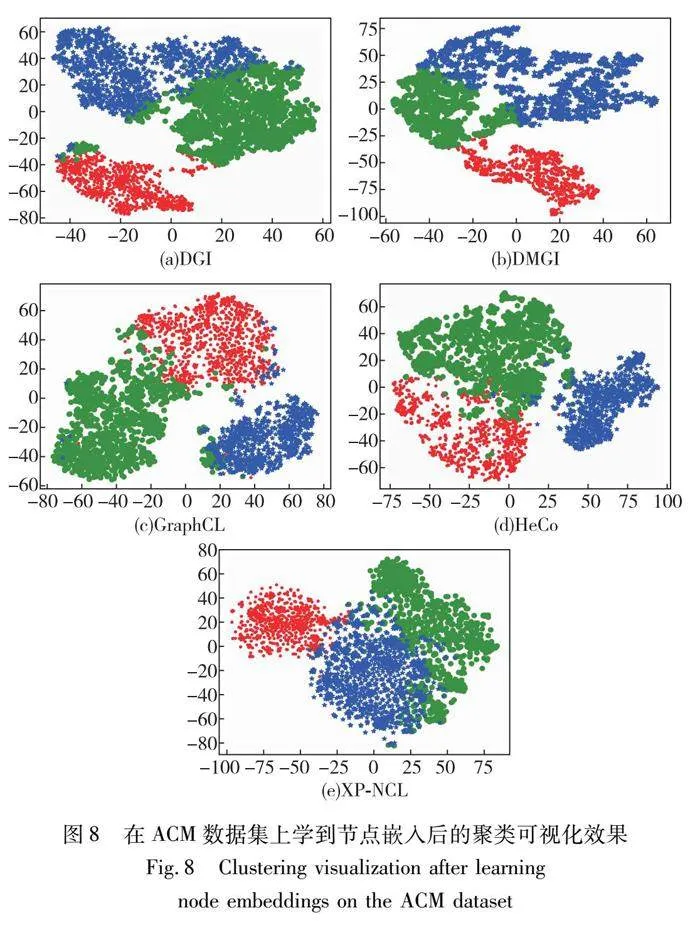
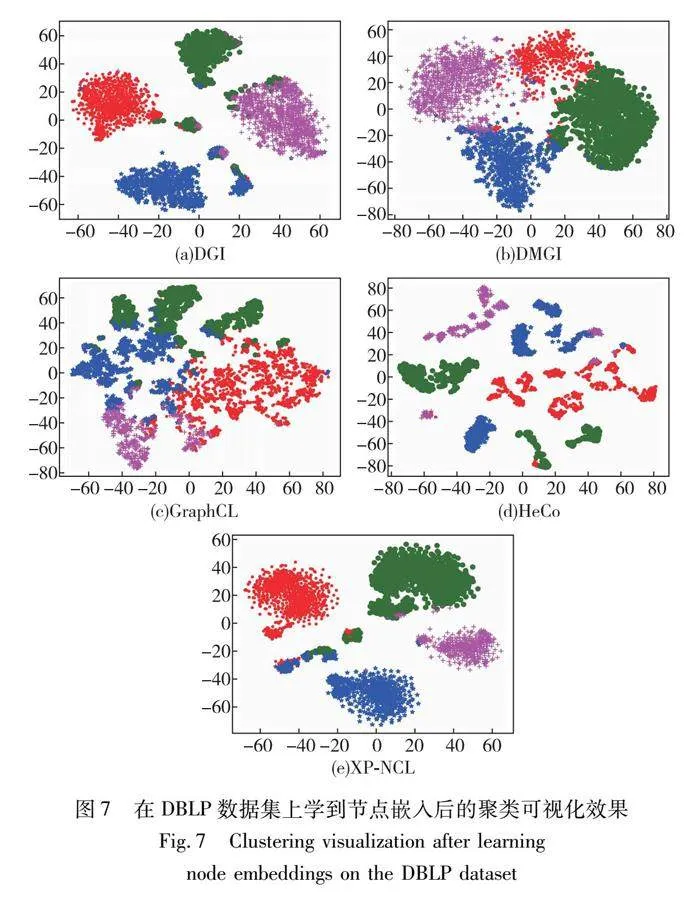
总的来说,通过实验验证了XP-NCL在三个真实异构图上的分类性能,可以看出,XP-NCL表征与同构图和异构图基线相比,呈现出更优越的性能。以DBLP数据集为例,该数据集包含四类节点(paper, author, conference, term)和三类边(write, publish, belong),这些节点之间的多种关系构成了异构图。通过应用本文研究的异构图嵌入方法,可以将这些复杂的异构图转换为低维的向量表示,从而挖掘节点之间的潜在关联。在本文中,将这些向量表示作为特征输入到机器学习模型中,用于节点的分类和聚类任务中。在表4中,展示了使用模型对author类节点的分类结果,结果表明,XP-NCL表征与同构图和异构图基线相比,很多情况下都可以呈现出更优越的性能。图7(e)展示了XP-NCL在DBLP数据集上的聚类结果,从聚类结果可以看出,本文方法聚类结果更加紧凑,且无法区分的样本大多分布在簇边缘部分。
4.5 聚类结果
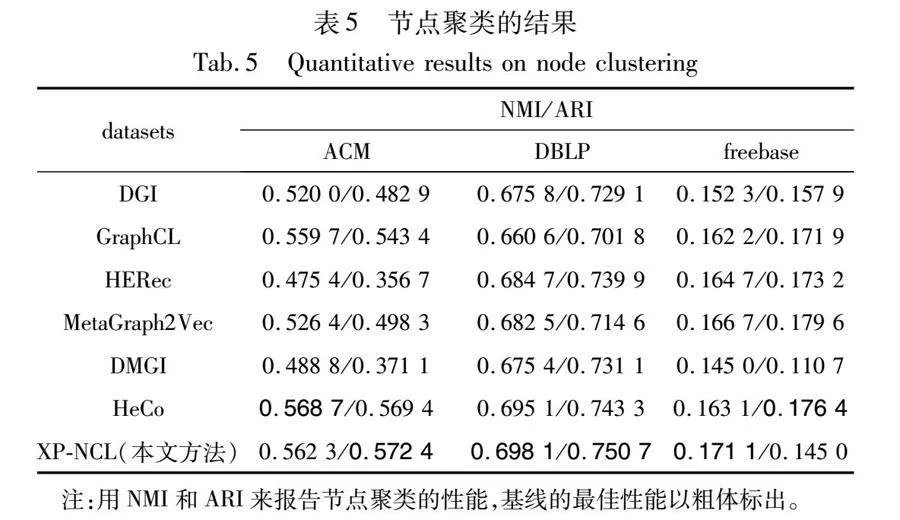
在这项任务中,进一步使用学习到的表示进行K-means聚类,以验证所学节点嵌入的质量。采用NMI和ARI作为评价指标,结果如表5所示。为了缓解初始聚类中心不同带来的不稳定性,重复了10次聚类实验,并汇报了平均结果。可以看出,XP-NCL在大多数情况下都表现良好。尤其是在DBLP数据集上,本文方法获得了最好的结果,证明了模型的优越性。这得益于原型损失的设计,其促使节点在同一簇中的表示更加紧凑,从而有助于提高聚类效果。
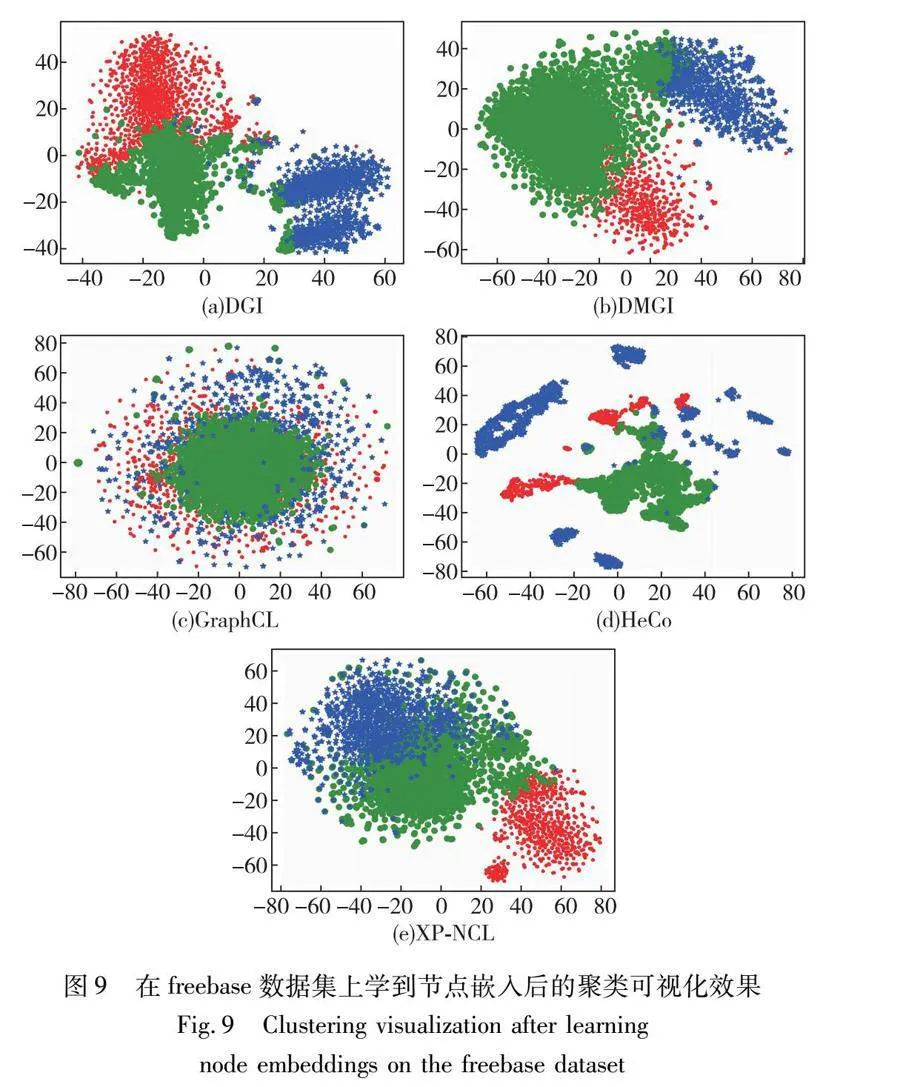
为了提供更直观的评估,对三个数据集聚类后的结果进行了可视化。使用t-SNE绘制了DGI、DMGI、GraphCL、HeCo和XP-NCL的学习嵌入,结果如图7~图9所示,不同颜色代表不同的类别。相比于其他方法,XP-NCL得到的簇更加紧凑,且误分的样本通常只存在于簇边界部分。这一点得益于该模型不需要负样本和局部结构约束的正样本选择策略,且只有少量的样本无法进行区分。
4.6 损失函数分析
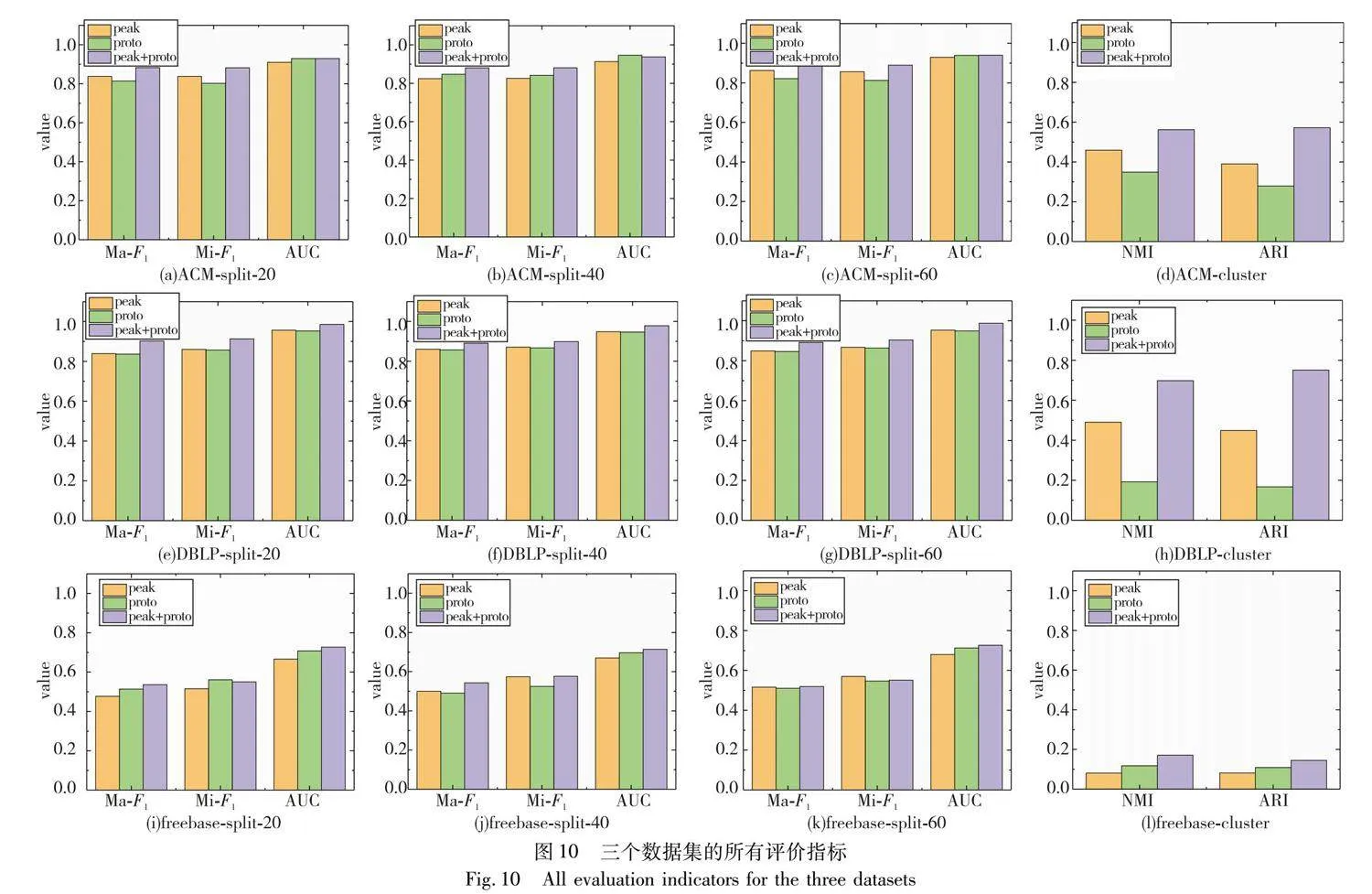
在本节中,将分别使用原型和峰值作为损失函数,然后讨论将这两个部分结合的必要性。实验在三个模型上进行:a)去掉了原型损失,因此模型被称为peak;b)去掉了峰值损失,模型被称为proto;c)文中提出的模型peak+proto。
图10分别显示了三个数据集的所有评价指标,从第一行到第三行分别为ACM、DBLP和freebase数据集在不同采样情况下的原型、峰值和原型+峰值损失对模型评价指数的影响。可以看到,无论是分类任务还是聚类任务,总体结果在大多数
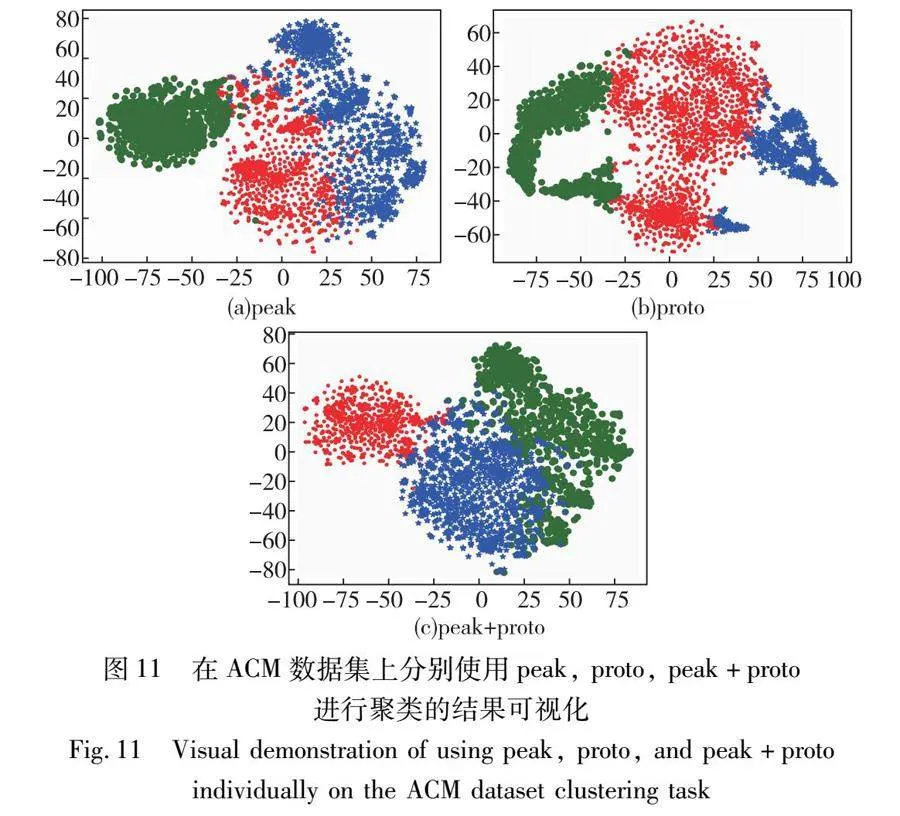
情况下都是peak+proto>peak>proto。以ACM数据集为例,在图11中更加直观地使用t-SNE展示了单独使用每种损失后的聚类结果。通过聚类结果发现:a)proto主要用于将同类样本聚类在一起,但聚类的最终形状很难保持一致,例如可能是球状或带状;b)peak则是将正样本之间的距离拉得更近,让簇更紧密。
4.7 动态加权方案分析
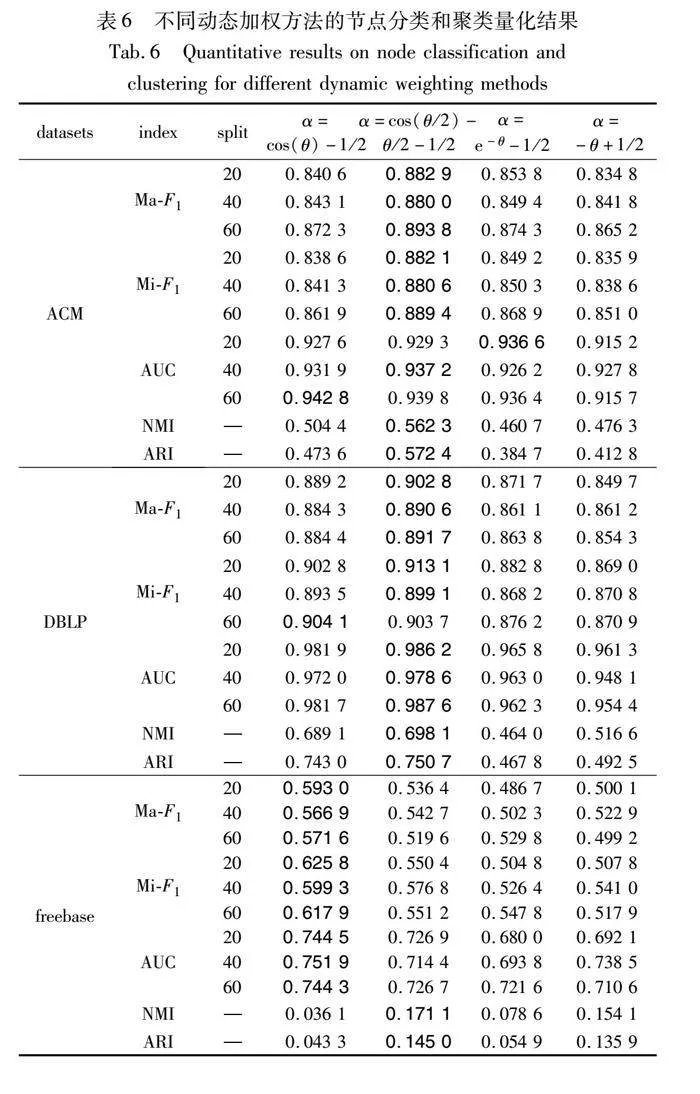
在3.3节中,设计了四种不同类型的动态加权方案,表6列出了所有实验结果,最高性能以粗体标出。结果表明,当选α=cos(θ/2)-θ/2-1/2时,在ACM和DBLP数据集中得到了最好的结果,而在α=cos(θ)-1/2,freebase数据集中得到了最好的结果。但是在freebase数据集中,聚类任务中学习到的嵌入效果很差,这可能与数据集本身有关。
5 结束语
本文提出了一个基于跨视图原型非对比学习的异构图嵌入模型。该模型不使用负样本,而是通过有向筛选树为每个节点选择一个最相似的正样本。在此基础上,定义了交对称差比与峰值算子来重构跨视图特征对齐,并设计了动态损失加权方案。当设计非对比学习模型时,从多个维度考虑不同视图之间的对齐是至关重要的,更多的对齐方案即将发布。在异构图非对比学习中,如何选择更好的正样本也是下一步要解决的问题。
参考文献:
[1]Grill J B,Strub F,Altché F,et al. Bootstrap your own latent-a new approach to self-supervised learning [C]//Advances in Neural Information Processing Systems. 2020: 21271-21284.
[2]Tang Shixiang,Su Peng,Chen Dapeng,et al. Gradient regularized contrastive learning for continual domain adaptation [C]// Proc of AAAI Conference on Artificial Intelligence. 2021: 2665-2673.
[3]He Kaiming,Fan Haoqi,Wu Yuxin,et al. Momentum contrast for unsupervised visual representation learning [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[4]Chen Xinlei,Fan Haoqi,Girshick R,et al. Improved baselines with momentum contrastive learning [EB/OL]. (2020). https://arxiv.org/abs/2003. 04297.
[5]Velikovic' P,Fedus W,Hamilton W L,et al. Deep graph infomax [EB/OL]. (2018).https://arxiv.org/abs/1809. 10341.
[6]Wang Xiao,Bo Deyu,Shi Chuan,et al. A survey on heterogeneous graph embedding: methods,techniques,applications and sources [J]. IEEE Trans on Big Data,2022,9(2): 415-436.
[7]Liu Xiao,Zhang Fanjin,Hou Zhenyu,et al. Self-supervised learning: generative or contrastive [J]. IEEE Trans on Knowledge and Data Engineering,2021,35(1): 857-876.
[8]Balestriero R,Ibrahim M,Sobal V,et al. A cookbook of self-supervised learning [EB/OL].(2023).https://arxiv.org/abs/2304. 12210.
[9]吴相帅,孙福振,张文龙,等. 基于图注意力的异构图社交推荐网络 [J]. 计算机应用研究,2023,40(10): 3076-3081,3106. (Wu Xiangshuai,Sun Fuzhen,Zhang Wenlong,et al. GAT based heterogeneous graph neural network for social recommendation [J]. Application Research of Computers,2023,40(10): 3076-3081,3106.)
[10]Zhou Zhichao,Hu Yu,Zhang Yue,et al. Multiview deep graph infomax to achieve unsupervised graph embedding [J]. IEEE Trans on Cybernetics,2022,53(10):6329-6339.
[11]You Yuning,Chen Tianlong,Sui Yongduo,et al. Graph contrastive learning with augmentations [C]// Advances in Neural Information Processing Systems. 2020: 5812-5823.
[12]Yu Ruiyun,Yang Kang,Wang Zhihong,et al. Multimodal interaction aware embedding for location-based social networks [J]. AI Communications,2023,36(1): 41-55.
[13]You Yuning,Chen Tianlong,Shen Yang,et al. Graph contrastive learning automated [C]//Proc of International Conference on Machine Learning. 2021: 12121-12132.
[14]Zhang Rui,Zimek A,Schneider-Kamp P. Unsupervised representation learning on attributed multiplex network [C]// Proc of the 31st ACM International Conference on Information & Knowledge Management. New York:ACM Press,2022: 2610-2619.
[15]Shang Jingbo,Qu Meng,Liu Jialu,et al. Meta-path guided embedding for similarity search in large-scale heterogeneous information networks [EB/OL]. (2016). https://arxiv.org/abs/1610. 09769.
[16]Zhao Jianan,Wen Qianlong,Sun Shiyu,et al. Multi-view self-supervised heterogeneous graph embedding [C]//Proc of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer International Publishing,2021: 319-334.
[17]Li Qi,Chen Wenping,Fang Zhaoxi,et al. A multi-view contrastive learning for heterogeneous network embedding [J]. Scientific Reports,2023,13(1): 6732.
[18]Zhong Hongwei,Wang Mingyang,Zhang Xinyue. Unsupervised embedding learning for large-scale heterogeneous networks based on metapath graph sampling [J]. Entropy,2023,25(2): 297.
[19]Fu Xinyu,Zhang Jiani,Meng Ziqiao,et al. MAGNN: metapath aggregated graph neural network for heterogeneous graph embedding [C]// Proc of Web Conference. 2020: 2331-2341.
[20]Yu Jianxiang,Li Xiang. Heterogeneous graph contrastive learning with meta-path contexts and weighted negative samples [C]// Proc of SIAM International Conference on Data Mining. 2023: 37-45.
[21]Xu Keyulu,Hu Weihua,Leskovec J,et al. How powerful are graph neural networks? [EB/OL]. (2018). https://arxiv.org/abs/ 1810. 00826.
[22]Wang Xiao,Liu Nian,Han Hui,et al. Self-supervised heterogeneous graph neural network with co-contrastive learning [C]// Proc of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 1726-1736.
[23]Park C,Kim D,Han J,et al. Unsupervised attributed multiplex network embedding [C]// Proc of AAAI Conference on Artificial Intelligence. 2020: 5371-5378.
[24]Jin Di,Huo Cuiying,Dang Jianwu,et al. Heterogeneous graph neural networks using self-supervised reciprocally contrastive learning [EB/OL]. (2022).https://arxiv.org/abs/2205. 00256.
[25]Wang Zehong,Li Qi,Yu Donghua,et al. Heterogeneous graph con-trastive multi-view learning [C]// Proc of SIAM International Confe-rence on Data Mining. 2023: 136-144.
[26]Wan Ziming,Wang Deqing,Ming Xuehua,et al. RHCO: a relation-aware heterogeneous graph neural network with contrastive learning for large-scale graphs [EB/OL]. (2022).https://arxiv.org/abs/ 2211. 11752.
[27]Qian Yiyue,Zhang Yiming,Chawla N,et al. Malicious repositories detection with adversarial heterogeneous graph contrastive learning [C]// Proc of the 31st ACM International Conference on Information & Knowledge Management. New York:ACM Press,2022: 1645-1654.
[28]Zhu Yanqiao,Xu Yichen,Cui Hejie,et al. Structure-enhanced heterogeneous graph contrastive learning [C]// Proc of SIAM International Conference on Data Mining.2022: 82-90.
[29]Che Feihu,Tao Jianhua,Yang Guohua,et al. Multi-aspect self-supervised learning for heterogeneous information network [J]. Know-ledge-Based Systems,2021,233: 107474.
[30]Chen Xinlei,He Kaiming. Exploring simple siamese representation learning [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 15750-15758.
[31]Bielak P,Kajdanowicz T,Chawla N V. Graph barlow twins: a self-supervised representation learning framework for graphs [J]. Know-ledge-Based Systems,2022,256: 109631.
[32]Zhang Hengrui,Wu Qitian,Yan Junchi,et al. From canonical correlation analysis to self-supervised graph neural networks [C]//Advances in Neural Information Processing Systems. 2021: 76-89.
[33]Park M. Cross-view self-supervised learning on heterogeneous graph neural network via bootstrapping [EB/OL]. (2022). https://arxiv.org/abs/2201. 03340.
[34]Dong Yuxiao,Chawla N V,Swami A. metapath2vec: scalable representation learning for heterogeneous networks [C]// Proc of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM Press,2017: 135-144.
[35]Li Junnan,Zhou Pan,Xiong Caiming,et al. Prototypical contrastive learning of unsupervised representations [EB/OL]. (2020).https://arxiv.org/abs/2005. 04966.
[36]He Mingguo,Wei Zhewei,Huang Zengfeng,et al. BernNet: learning arbitrary graph spectral filters via bernstein approximation [C]//Advances in Neural Information Processing Systems. 2021: 14239-14251.
[37]Li Xiang,Ding Danhao,Kao Ben,et al. Leveraging meta-path contexts for classification in heterogeneous information networks [C]// Proc of IEEE 37th International Conference on Data Engineering. Pisca-taway,NJ:IEEE Press,2021: 912-923.
[38]Shi Chuan,Hu Binbin,Zhao W X,et al. Heterogeneous information network embedding for recommendation [J]. IEEE Trans on Knowledge and Data Engineering,2018,31(2): 357-370.
[39]Zhang Daokun,Yin Jie,Zhu Xingquan,et al. MetaGraph2Vec: complex semantic path augmented heterogeneous network embedding [C]//Proc of the 22nd Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin:Springer International Publishing,2018: 196-208.
收稿日期:2024-01-12;修回日期:2024-03-20 基金项目:国家自然科学基金资助项目(U1931209);山西省科技合作交流专项区域合作项目(202204041101037,202204041101033);太原科技大学研究生教育创新项目(BY2023015)
作者简介:张敏(1998—),男,山西长治人,硕士研究生,主要研究方向为数据挖掘与机器学习;杨雨晴(1992—),女,湖南常德人,讲师,博士,主要研究方向为数据挖掘与机器学习;贺艳婷(1988—),女(通信作者),山西晋城人,讲师,博士研究生,主要研究方向为机器学习(yantinghe@tyust.edu.cn);史晨辉(1998—),男,河南周口人,博士研究生,主要研究方向为数据挖掘与机器学习.
