混合内存架构下数据放置研究综述
2024-11-04林炳辉张建勋乔欣雨


摘 要:
当前基于DRAM和NVM的混合内存系统在系统结构领域的研究前景广阔,特别是对混合内存系统进行数据放置的研究已经成为国内外研究的热点。对混合内存架构下数据放置策略进行了研究,在介绍当前常见混合内存架构的基础上,对现有数据放置策略的设计思路进行了全面分析,主要涉及硬件/软件机制、内存访问特征、静态/动态分析、机器智能、触发方式和粒度选择等方面,并针对混合内存性能、功耗和耐久性的数据放置优化进行总结。综合分析发现,现有的混合内存数据放置策略在内存架构、数据迁移、计算成本和全局优化等方面还存在局限性,未来在架构设计以及内存管理方面的改进还有很大的研究探索空间和发展前景。
关键词:混合内存;数据放置;非易失性存储器;研究综述
中图分类号:TP333 文献标志码:A 文章编号:1001-3695(2024)09-003-2585-07
doi:10.19734/j.issn.1001-3695.2023.12.0639
Review of data placement in hybrid memory architecture
Lin Binghui, Zhang Jianxun, Qiao Xinyu
(School of Information Technology Engineering, Tianjin University of Technology & Education, Tianjin 300222, China)
Abstract:
The current research on hybrid memory systems based on DRAM and NVM is promising in the field of system architecture, especially the research on data placement in hybrid memory systems has become a research hotspot in domestic and foreign studies. This paper studied the data placement strategy in hybrid memory architecture. On the basis of introducing the common hybrid memory architectures, it comprehensively analyzed the design ideas of existing data placement strategies, mainly involving hardware/software mechanisms, memory access characteristics, static/dynamic analysis, machine intelligence, trigger modes, and granularity selection, and summarized the data placement optimization in hybrid memory in terms of performance, power consumption, and endurance. The comprehensive analysis reveals that existing data placement strategies in hybrid memory still have limitations in terms of memory architecture, data migration, computational cost, and global optimization. In the future, there is still a lot of research space and development prospects in improving architectural design and memory management.
Key words:hybrid memory; data placement; non-volatile memory; research review
0 引言
随着高性能计算、人工智能、大数据和云计算等领域的蓬勃发展,相关技术对高内存占用、高吞吐量和低能耗的需求日益增加[1],应用对内存系统的容量、能效和访问延迟提出了较高的要求。然而,由于传统的动态随机存取存储器(dynamic random access memory, DRAM)静态功耗高且存在可扩展性问题,从而导致DRAM内存系统成为当前计算机系统性能提升的主要瓶颈之一。大量研究表明[2~5],基于DRAM的主存系统消耗了现代计算机系统中约40%的能耗。
新兴的非易失性存储器(non-volatile memory,NVM)技术是未来极具潜力的内存技术。NVM主要包括相变存储器(phase change memory, PCM)、自旋转移矩磁随机存储器(spin transfer torque random access memory,STT-RAM)、铁电随机存储器(ferroelectric random access memory,FeRAM)、阻变随机存储器(resistive random access memory,RRAM)[6~9]。为综合对比不同内存技术的特点,表1[2,7,8]从读/写延迟、耐久性和功耗等几个方面对现有的内存技术进行了对比分析。尽管NVM具备非易失性、高密度和低静态功耗等优势,但相较于DRAM仍存在写功耗高、写延迟高和耐久性有限等问题[10~13],导致NVM并不能完全取代现有的DRAM。因此在内存设计上需充分考虑两者的内存特性。当前采用基于DRAM和NVM的混合内存结构替代单一DRAM组成的传统内存结构设计已经成为系统结构研究领域的共识,并已经成功应用于商用系统。新型的混合内存结构设计在不影响成本和性能的情况下获得了高容量的内存[12],同时也增加了对内存管理的复杂性,如何对混合内存进行有效调度和管理的研究也成为研究的热点领域,其中包括混合内存系统的数据放置研究。
混合内存数据放置的研究主要包括数据的分配和迁移两个方面。当前,DRAM-NVM混合内存系统的数据放置主要面临以下挑战:一是识别和管理需要进行数据放置的数据,选择合适的数据进行放置,才能提升混合内存系统的性能;二是设计数据放置的算法,需要对数据放置考虑以何种方式实现和何时触发等因素,同时还需要考虑数据迁移的频率。如果迁移频率过高,可能会导致不必要的迁移,而如果迁移频率过低,一些必要的迁移可能无法及时进行。
本文关注于混合内存系统中数据的分配和迁移来对数据放置策略进行研究,并从架构设计、方法特点和优化目标等方面对现有的混合内存数据放置策略进行了梳理,并探讨了混合内存放置策略未来的研究方向。
1 混合内存架构
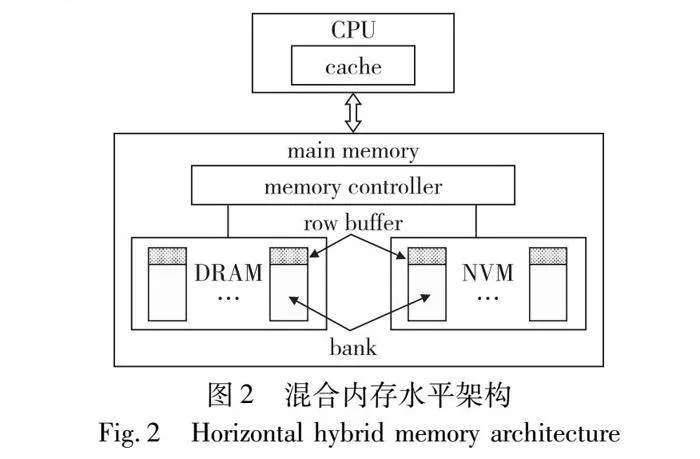
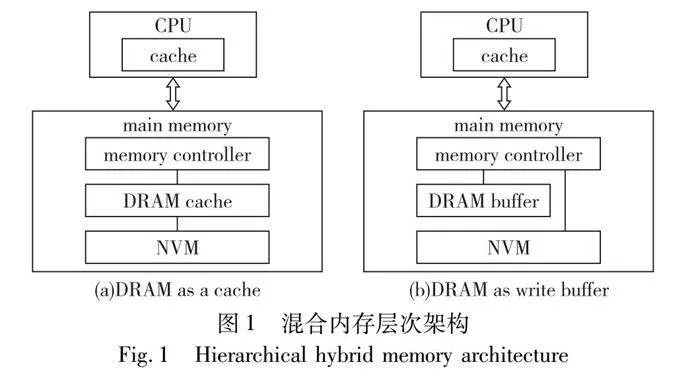
混合内存架构根据DRAM和NVM的相对位置和功能进行分类,主要分为层次架构和水平架构[2]。
1.1 层次架构
如图1所示,层次架构将DRAM作为NVM的高速缓存层或者缓冲区,而将NVM作为主存层[14]。由NVM和DRAM缓存构成的混合内存系统,在应用程序执行期间,DRAM负责缓存最近访问的数据以减少对NVM的访问次数,而NVM负责保存大部分所需的数据以缓解DRAM和NVM之间读/写延迟的不对称性。由NVM和DRAM写缓冲区构成的混合内存系统,DRAM用于接收来自最后一级缓存(last level cache,LLC)的写数据,以提供更高的性能。
1.1.1 层次架构的优势
层次架构下,内存访问只在DRAM缺失时,请求才被定向到NVM,因此对NVM的访问量减少。在层次架构中,数据通常按需获取,因此DRAM中没有带宽损失或容量损失,加之DRAM由硬件管理,对操作系统和应用程序是完全透明的[15]。
1.1.2 层次架构的局限性
在层次架构中,DRAM被组织为N路组相联缓存,需要额外的硬件来管理DRAM缓存,在实现上较为复杂。管理用于跟踪DRAM缓存数据的元数据可能会导致过高的存储开销,从而增加内存访问延迟[10,16,17]。面对局部性差的工作负载,缓存的性能会显著下降并伴随功耗的上升。虽然DRAM作为缓冲区也能够提升系统性能,但每次写请求至少需要在DRAM中执行一次写操作,可能还需要在将数据刷新到NVM时执行一次DRAM读操作和一次NVM写操作。这些额外的读/写操作都会增加内存系统的总能耗。此外,DRAM空间不会增加混合内存的总体容量。
1.2 水平架构
如图2所示,在水平架构中,DRAM和NVM形成了一个统一可寻址的内存层。
1.2.1 水平架构的优势
水平架构使DRAM和NVM共享一个公共地址空间,能够提供更高的容量[18]。由于可以同时访问两种内存,所以水平架构提供的内存带宽更高。此外,水平架构不需要额外的硬件来维护内存,DRAM和NVM对操作系统是可见的[15]。
1.2.2 水平架构的局限性
为了提高数据访问性能,水平架构的混合内存系统需要将频繁访问的NVM热页面迁移到DRAM。在进行页面迁移时,需要修改软件或操作系统干预来确保页面分配的进行,因此会增加系统开销。在跟踪内存活动时,页面级内存监控需要硬件支持,需要对硬件进行修改才能统计内存访问[2]。此外,系统的数据放置策略也在很大程度上决定了混合内存系统的性能[19]。
1.3 架构设计改进
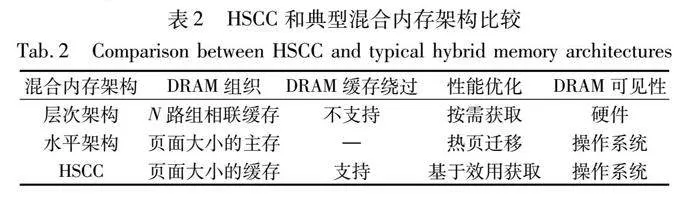
现有的研究通过融合两种内存架构的优点进行了设计改进。例如,Kotra等人[20]提出的Chameleon可以根据应用程序的内存需求动态配置。Chameleon使用空闲空间作为缓存,当应用程序需要更大的容量时,其会切换到统一地址空间。Liu等人[10]提出了一种用于混合内存架构的硬件/软件协同缓存机制HSCC,以解决基于硬件机制的限制。如表2[10]所示,HSCC将DRAM和NVM以水平架构的形式组织,但在逻辑上支持层次架构。HSCC通过软件层进行DRAM缓存管理来简化硬件设计。同样,Chi等人[17]提出Mocha混合内存架构,将DRAM和NVM在物理上组织成一个统一地址空间,但在逻辑上将DRAM视为NVM的缓存。改进后架构具有更低的数据迁移流量和更好的系统性能,此类方法可以避免大量的硬件修改,同时保证混合内存管理的灵活性。
2 混合内存数据放置方法分类及特点
数据放置主要涉及在应用程序执行之前对数据的初始分配,以及应对实时工作负载的数据迁移。
2.1 基于硬件和软件的数据放置
2.1.1 基于硬件机制
在混合内存中,基于硬件的数据放置支持小粒度的内存管理,不需要修改软件,总体上的性能开销更少,对于具有良好局部性的应用程序也更有利[19]。但基于硬件的数据放置也存在问题,其需要额外的硬件来跟踪内存访问活动并执行数据放置,同时可能会消耗DRAM的部分容量[13]。此外,如果应用程序的空间局部性较差,可能会影响带宽利用率。
2.1.2 基于软件机制
基于软件的数据放置可以开发专门的API处理数据的分配和迁移以满足系统需求,不需要额外的硬件支持[13]。修改软件和自定义操作系统策略使内存资源的管理变得更加灵活。但基于软件的数据放置通常成本更高,操作系统干预、调用中断/处理程序和修改页表等操作都需要额外成本[13]。操作系统通常以页面粒度进行数据放置,以页面粒度进行迁移可能会产生更高的开销[13,21,22]。此外,操纵系统可能会对热页面的识别不够准确,导致错过必要的迁移或发生不必要的迁移。
2.1.3 存在的挑战
在基于硬件的方法中,最大的挑战是在不增加规模和成本开销的情况下处理数据放置,而基于软件的方法应该致力于在对现有软件进行最小修改的情况下进行数据放置[8]。
2.2 基于访问频率的数据放置
混合内存数据放置策略通常将频繁访问的数据存储在DRAM中,将很少访问的数据存储在NVM中。根据数据的访问次数,可将数据分成热数据和冷数据。通常,热数据被迁移到DRAM,而冷数据保留在NVM中。只根据数据的使用时间不足以准确识别热数据[21,23]。CMMP[21]、UIMigrate[23]、On-fly-Page[24]都通过额外的计数器跟踪数据的访问次数,以确定待迁移的数据。此外,在NVM中频繁写入数据不仅会降低性能还会增加功耗。因此APP-LRU[14]和写感知与行缓冲区缺失(WARM)计数器[25]根据写次数将写密集型数据从NVM迁移到DRAM。
2.3 基于局部性和内存级并行的数据放置
2.3.1 考虑局部性原理
根据局部性原理,如果某个数据被访问,那么在不久的将来,该数据很可能会再次被访问或者在内存中相邻的数据很可能会被访问。在行缓冲区中被访问多次的行表现出较高的行缓冲区局部性。Yoon等人[26]观察到在延迟、带宽和功耗方面,NVM的行缓冲区缺失成本相比DRAM的要高得多,由此提出利用行缓冲区局部性来进行混合内存间的页面迁移。行缓冲区命中率低的页面被迁移到DRAM,而行缓冲区命中率高的页面仍然保留在NVM中。计数器用于跟踪NVM中行的缺失计数,以增加这些行的迁移优先级,具有良好局部性的应用程序的性能和能效可以得到提升。
2.3.2 考虑内存级并行
内存级并行能在执行程序的同时利用多个内存访问操作来提高性能和效率。Li等人[12]首次考虑了内存级并行,提出了基于效用的混合内存页面管理策略UH-MEM。UH-MEM通过综合考虑访问频率、行缓冲区局部性和内存级并行,计算页面从慢速内存(NVM)迁移到快速内存(DRAM)的潜在系统性能收益,称之为效用值,将具有最大效用值的页面迁移到快速内存中。
2.4 基于静态分析的数据放置
基于静态分析的数据放置在程序编译阶段或程序加载阶段进行,将数据分配到内存中的特定位置,之后不随工作负载的变化而改变。表3总结了基于静态分析的数据放置策略。
Wei等人[27]研究发现,理解程序语义,系统可以更好地指导混合内存中数据的初始放置。根据程序语义进行初始放置能够显著减少由错误的迁移带来的内存拷贝开销。通过分析代码和跟踪堆对象,对具有相似访问特征的对象进行分配,同时考虑将代码段放置到NVM中,将堆栈数据和全局数据放置在DRAM中。Hassan等人[28]提出应用程序级对象的细粒度,将数据放置在混合内存中,其中的对象可以是单独的程序变量或内存分配块。通过分析应用程序中对象的内存访问模式,选择受益最大的对象放置在DRAM中。Liu等人[22]提出的对象级内存分配和迁移机制OAM,对于不可变对象,只需要根据性能/能量模型计算的平均效用将其分配在DRAM或NVM上,而不需要考虑运行时对象迁移。Olson等人[29]提出的MemBrain利用程序分析和源代码分析,并使用离线性能反馈来指导每个区域的分配,实现了不同类型内存有效而透明的数据放置。
由于内存访问模式相对固定,所以基于静态分析的数据放置在程序运行前可以进行有效的优化。这种策略适用于工作负载变化较小的场景,可以提供稳定的性能表现,但难以应对在运行时变化的场景。
2.5 基于动态分析的数据放置
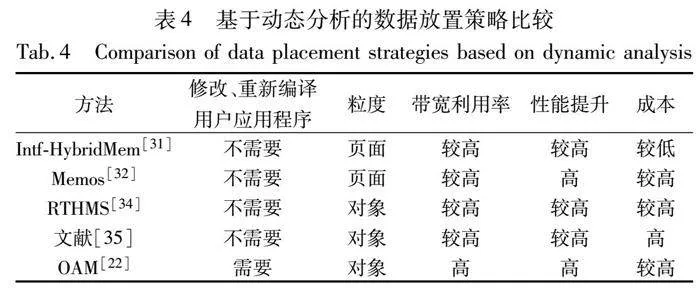
通过动态监测并分析数据访问模式,基于动态分析的数据放置策略可以实时调整数据的位置和存储方式,根据当前的工作负载和系统状态,决定是否进行数据迁移,并将数据存储在最优的存储位置以最小化访问的总成本[30]。表4总结了基于动态分析的数据放置策略[22,31~35]。
混合内存数据放置决策需要考虑多种参数和不确定性,例如内存大小、读/写延迟、耐久性和功耗等。为此,de Moura等人[31]提出了使用模糊逻辑系统来支持混合内存中的页面迁移。该策略通过访问更新器和Intf-HybridMem两个模块来实现动态数据放置。访问更新模块首先将页面访问存储在访问缓冲区中,并定期更新连接到Intf-HybridMem的数据缓冲区。该策略评估访问更新器接收到的数据,根据数据访问模式和内存特性对数据进行分类,返回数据缓冲区中每个页面的迁移建议值,并将读取频率高的页面存储在NVM中,其他页面存储在DRAM中。
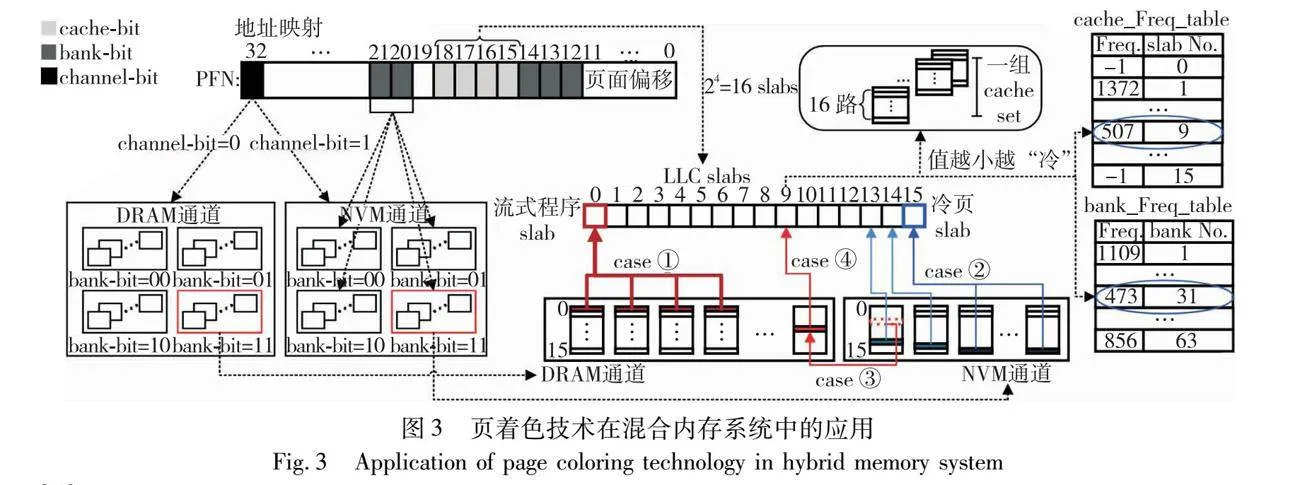
Liu等人[32]尝试将页着色技术应用到DRAM-NVM混合内存管理。通过结合采样和页表遍历,以较低的监控采样频率精确地获取内存页面的热度,利用混合内存所处的地址空间对页面着色。同时,通过与cache、bank和内存通道(channel)等相关联来控制数据分布并消除多道程序之间在内存体系上的相互干扰,进而有效提高了包含 NVM 在内的整个内存体系的资源利用率。如图3[32,33]所示,页着色技术通过为第32位着色控制内存通道,确定使用DRAM还是NVM来容纳特定页面,同时使用页帧号(page frame number,PFN)的第15~18位来构成cache set的颜色,以实现对cache的划分和分配,并通过bank索引位来实现对内存bank的划分和分配。根据页面的读/写特征将页面映射到DRAM或NVM可以最大程度地利用DRAM和NVM通道提供的总带宽。因此热页面通常被分配在DRAM中,而出于节省功耗和为热页面尽可能地留出DRAM空间的目的,冷页面通常被分配在NVM中[33]。
文献[34]介绍了一种名为RTHMS的数据放置工具。该工具结合单一对象分配规则和全局数据放置决策,给出内存对象放置建议。首先,RTHMS单独分析每个内存对象,为每个内存对象与每个内存技术之间的匹配分配一个分数。这个分数表示将这个内存对象放置在这个内存技术上是否会带来性能收益,以确定是否推荐该内存对象存储在该内存技术中。之后,全局分析应用程序中所有内存对象并根据它们的期望性能影响对它们进行排序,以确定它们在可用内存中的存储位置。RTHMS还考虑了内存对象的生命周期以更好地优化内存对象的分配。通过这种方式,RTHMS可以提高应用程序的性能,减少内存访问延迟和提高内存带宽利用率。
Servat等人[35]提出了一个自动化的框架,用于自动识别和放置与应用程序最相关的内存对象到混合内存中。该框架首先探索应用程序行为,使用基于硬件的采样机制收集内存对象的度量指标和跟踪文件,随后分析LLC缺失最多的对象及其大小,根据内存配置报告内存对象在快速内存中的最佳放置,为给定的内存配置分配对象从而替换动态内存分配,实现基于配置文件的执行。该框架可以在不修改应用程序源代码的情况下自动化地完成内存优化。
对于可变对象,OAM[22]的内存访问频率会随着不同执行阶段的变化而发生变化,利用静态代码插桩工具在应用程序源代码中添加对象迁移指令,使应用程序在运行时执行动态对象迁移,而无须操作系统干预。
基于动态分析的数据放置策略适用于具有变化的工作负载和系统需求的场景,能够动态地适应不同的数据访问模式和负载特征,提供灵活且高效的数据管理。
2.6 基于机器智能的数据放置
对于访问模式频繁发生改变的应用程序,使用机器智能可以捕获短期和长期页面访问模式的数据,在预测未来页面访问行为方面表现出很大的潜力。Doudali等人[36]介绍了一种基于机器智能的混合内存管理方法,涉及Kleio、Cori、Coeus、Mnemo和CoMerge等技术[37~41]。该方法通过一系列创新机制和优化策略实现了对机器智能的有效集成,降低了相关开销。
Kleio[37]是一种混合内存页面调度器,对页面进行机器智能管理,利用循环神经网络(recurrent neural networks,RNN)来学习内存访问模式,识别页面访问频率的突然变化,从而在使用基于历史记录的管理方法时,实现了大部分应用性能的提高。
Cori[38]通过调整数据移动频率实现DRAM容量的最大化利用以及整个系统资源的高效利用。该策略通过分析应用程序的数据重用趋势,指导频率调整过程。Cori从应用程序中提取必要的应用级数据重用信息。这些信息可以帮助Cori确定数据移动的时机和频率。频率生成器基于数据重用信息,计算出一系列候选的数据移动周期,得到候选频率。智能算法可以根据应用程序的特征和系统资源状况,预测不同频率下的应用程序性能,并选择最优的频率。
Coeus[39]是一种基于机器智能的页面分组机制。Coeus利用数据重用信息,创建访问行为相同的页面的大集群。与使用K-means等数据聚类方法相比,Coeus几乎没有额外的执行成本,降低了机器智能混合内存管理器的学习开销。
Mnemo[40]作为一种内存大小和数据分层顾问,可以快速探索不同混合内存组件配置的成本和效益的权衡。 Mnemo能够显著降低应用的硬件成本并对应用性能几乎没有影响,从而提高了整个系统的内存成本效益。
CoMerge[41]作为内存共享方案,将每个应用的数据分层与先验决定的优先级放置相结合,以实现高效的内存利用并减缓共享应用的降低速度。
2.7 数据放置中触发方式的选择
在数据放置中,如果触发频率太高,将可能导致不必要的迁移和开销激增。如果触发频率太低,可能影响到必要的迁移。混合内存数据放置策略大多使用考虑不同因素计算的阈值来触发迁移,如访问次数[21,23,24]、写强度[42]、行缓冲区缺失次数[26]和效用[12,22]等,通过计算来决定是否触发迁移。
UIMigrate[23]通过计数器跟踪访问次数,同时采用一种访问计数器衰减的方法来识别长时间未访问的数据。SRS-Mig[42]的页面迁移基于NVM页面的写强度。当NVM页面的写强度超过迁移阈值时,该页面成为迁移候选页面。在每个周期内,UH-MEM[12]更新页面的效用值并与迁移阈值进行比较,只有当效用值大于阈值时,页面才会从NVM移到DRAM。OAM[22]采用的效用值是基于效用函数计算能量延迟积(energy-delay product,EDP)。如果效用值大于某个阈值,则将对象放在DRAM中,否则放在NVM中,而阈值会根据对象的效用值动态更新。
2.8 数据放置中数据粒度的选择
粒度的选择会影响数据放置的效率。在混合内存系统中,DRAM和NVM之间的数据移动粒度可以是DRAM行、LLC块、页面或对象等[8]。不同的应用程序将受益于不同的粒度,因此使用通用粒度可能并不是理想的选择[13]。现有的混合内存数据放置研究主要关注页面粒度和对象粒度。页面粒度涉及页面级别的数据管理和迁移。对于页面粒度,需要合理控制页面迁移策略在时间和空间上的开销。因为一个页面可能包含多个数据,但只有小部分数据会被频繁访问。采用过大的迁移粒度可能浪费内存带宽和容量,特别是对于具有良好局部性的应用程序[17]。因此,在混合内存系统中支持小粒度数据迁移至关重要。对象粒度关注程序中具体的数据结构和变量,内存开销较小。对于对象粒度,需要深入理解对象的访问特征以及对象的分配和迁移过程,才能进行精细的内存管理。
3 混合内存数据放置优化目标分类
混合内存系统具有不同的特性,如性能、功耗、耐久性等,关键问题在于如何管理不同内存技术之间的数据分配和移动,以便能够达到所需的最佳性能指标[43,44]。通常,NVM的内存容量是DRAM的数倍,但目前NVM还无法完全替代DRAM,否则将会导致三个问题:a)写延迟高,相较于DRAM,NVM的写延迟更高;b)写功耗高,在执行写操作时NVM比DRAM功耗高;c)耐久性有限,如果对NVM的某些存储单元过度频繁写入,将对NVM的整体寿命产生严重影响。通过数据放置策略可实现对混合内存性能、功耗和寿命的优化。
3.1 性能优化
由于NVM自身的特性,其写延迟相较于DRAM更高,所以优化混合内存系统的性能主要在于减少NVM的写操作。
APP-LRU[14]通过引入一个元数据表来记录页面的访问历史,并基于预测的页面访问模式来选择将页面放在NVM或DRAM中。除了LRU之外,它还使用两个额外的列表来跟踪读密集型和写密集型页面。页面根据它们的读/写计数进行分组。Salkhordeh 等人[45]分别在DRAM和NVM中使用LRU。当页面到达NVM的LRU列表顶部并且超过阈值时,则迁移到DRAM;当计数器值超过阈值时,将页面迁移到DRAM。
Lee等人[46]发现页面的写频率比数据访问的时间局部性更重要,由此提出了一种名为CLOCK-DWF的页面置换算法。CLOCK-DWF使用两个CLOCK算法,分别管理DRAM和NVM。CLOCK-DWF通过准确预测未来的写操作将NVM中频繁的写操作转移到DRAM中。TA-CLOCK[47]通过分析页面的读/写计数对页面的访问倾向分类,并确定页面的位置,将写密集型页面保留在DRAM中,将读密集型页面保留在NVM中,从而减少了不必要的页面迁移。
李琪等人[48]提出了一种高效的混合内存页面管理机制。该机制根据不同内存的写入特性,将不同访问特征的页面进行合理分配,以减少系统中的数据迁移次数,从而提升系统性能。
直接迁移可能影响常规内存访问的响应时间。SRS-Mig[42]选择写强度大于阈值的页面作为迁移候选页并且规划了候选页迁移到DRAM的时间,以此减少迁移开销,改善应用程序的执行时间和内存响应时间。
传统NUMA内存管理策略在混合内存系统中无法有效工作,甚至可能导致应用性能下降。HiNUMA[49]利用NUMA感知内存分配和不对称页面迁移机制,实时监测数据访问情况,并根据数据访问热度和节点之间的距离等因素,动态地调整数据的存放位置,以最大限度地减少远程访问延迟和内存带宽消耗,从而提高系统性能。
3.2 功耗优化
虽然NVM的静态功耗极低,但频繁的写操作会导致NVM动态功耗的上升,成为限制系统能效的主要因素。因此,优化NVM写功耗对于提高系统的能效至关重要。
曲良等人[50]通过选择性分配目标程序到混合内存中来克服NVM写功耗高和写速度慢的问题。此方案将可执行目标程序中有读权限而没有写权限的段分配到NVM的地址空间内,将其余既有读权限又有写权限的段分配到DRAM的地址空间内,以此来降低系统功耗。
Zhang等人[51]提出能量感知的页面置换策略EAPR,根据内存访问计算DRAM和NVM中的页面访问能耗,并且将具有连续地址的类似页面作为一个页面组进行访问,并根据其能耗选择页面组进行迁移,从而确定页面是从NVM迁移到DRAM,还是从DRAM迁移到NVM。
孙浩等人[52]提出了一种面向边缘计算的低功耗混合内存系统。为了实现低功耗管理,作者引入了内存控制器扩展,并通过一种改进的双队列算法筛选出NVM中写请求较多的内存页面,并通过地址映射模块和迁移控制模块将这些页面从NVM迁移到DRAM中,从而回避了NVM写操作的缺陷。
Kim等人[53]提出了一种用于混合内存系统的对象放置策略eMap。eMap考虑对象访问模式和能耗,为对象提供理想的放置策略,以提高性能和降低功耗。eMap包含了两个模块,eMPlan和eMDyn。两者都基于整数线性规划(integer linear programming,ILP),并综合考虑决策、容量和功耗三个主要约束条件。
3.3 寿命优化
NVM耐久性有限的问题严重影响使用寿命。在混合内存系统中,主要有两种策略来克服NVM有限的写耐久性。一种是减少NVM的写操作,另一种是磨损均衡(wear leveling)。前者主要通过数据迁移和缓存来实现。后者则通过在NVM上均匀分布写操作,以确保所有存储单元都获得相对均等的使用,从而延长NVM的使用寿命。
磨损均衡技术大致可分为基于年龄的方法和基于随机化的方法两大类[54]。基于年龄的方法通过跟踪写操作计数来区分NVM中严重磨损和轻微磨损的区域,将严重磨损的NVM区域与轻微磨损的NVM区域交换,并尽可能将新的写操作放置在轻微磨损的区域。通常,基于年龄的方案使用基于采样的方法来获取页面的年龄。 Huang等人[54]通过有界尾部磨损均衡和轻量级磨损增强两个关键模块,有效延长了NVM的寿命。有界尾部磨损均衡通过动态提升和降低不同年龄段的页面来保持页面的年龄差距相等,以达到磨损均衡的效果。轻量级磨损增强则通过利用虚拟内存空间中的局部性原理来提高低频采样方案的准确性。多路磨损均衡(multi-way wear-leveling)[55]将逻辑地址空间划分为子区域,然后对每个区域应用磨损均衡。
基于随机化的方法将写操作分布在内存区域中的随机位置。细粒度磨损均衡(fine-grained wear-leveling)[56]技术将NVM页的缓存行以旋转方式存储在NVM中。对于一个有16行的NVM页,旋转值为0~15。在0~15随机生成一个旋转值便可以用来表示移位的位置。
不同于将写操作均匀分布在NVM上,Azevedo等人[57]利用禁用页面中的备用块为工作页面提供更多的纠错资源。从软件的角度来看,内存占用是以页面为单位组织的,因此包含有故障单元的整个页面会被禁用。然而,如果提供了一些备用单元来替换故障单元,那么页面将被再次使用。这些备用单元被称为纠错资源。作者利用禁用页面中留存的大量纠错资源与工作页面配对,有效地实现了磨损均衡,从而提高了NVM的整体寿命。
4 混合内存数据放置的分析与展望
4.1 当前有关混合内存数据放置研究的问题
通过上述相关工作的分析和总结,可以看出在混合内存系统中数据放置的研究已经取得了一定成果, 但是依然存在着一些问题,具体来说有以下几点:
a)内存架构:混合内存架构设计上的复杂性使数据放置策略的决策变得更加复杂。研究人员需要考虑如何在不同架构的内存中有效地放置数据,以最大程度地提高性能和降低功耗。
b)数据迁移:在混合内存系统中,数据迁移是不可避免的,数据可能需要在内存介质中移动以满足系统性能需求。这将引发延迟、功耗、资源利用等问题。如何以最小的开销来进行数据迁移是一个富有挑战性的问题。
c)计算成本:高效的数据放置策略可能需要更复杂的计算和算法,这将会增加系统的计算成本。
d)全局优化:一些数据放置策略可能对特定工作负载表现出色,但在其他情况下可能并不理想,未能实现充分的效能优化。例如,在工作负载变化频繁的情况下,数据放置策略可能失效。因此,数据放置策略需要根据不同应用和工作负载的特点进行调整以获得更全面的系统优化。
4.2 混合内存数据放置研究展望
基于混合内存系统的数据放置具有很大的发展前景,未来在混合内存系统中数据放置策略的研究有以下方向值得探索和实践。
a)混合内存架构设计:未来NVM将成为内存系统中极具潜力的产品,因此需要充分利用其高密度、低成本和非易性等优点,解决其写延迟高、写功耗高和耐久性有限的问题,根据NVM的内存特性改进现有内存系统的架构。
b)操作系统内存管理:针对NVM技术的特点,需要重新设计操作系统的内存管理机制,充分利用其可字节寻址和非易失性的特性以提升现代计算机系统的整体效能。
c)机器智能数据放置:机器智能已在混合内存数据放置领域取得初步应用,在一定程度上为解决混合内存管理的研究提供了新的思路。探索更为成熟的基于机器智能的混合内存数据放置策略,以实现更为智能和高效的数据管理。
5 结束语
随着高性能计算、人工智能、大数据和云计算等领域的蓬勃发展以及数据密集型应用程序不断涌现,通用计算程序的访存变得愈发密集。传统内存系统已经无法满足计算机系统的处理需求。内存墙问题使得传统内存系统在容量、性能和功耗等方面都面临着严峻的挑战,由NVM和DRAM构成的混合内存系统便应运而生。然而,如何将数据合理放置在混合内存系统中,数据放置的触发方式和数据放置粒度是研究需要考虑的重要因素;如何从全局的角度综合优化数据放置,从而提高内存资源利用率和系统效能是未来仍需解决的问题。但可以预见,混合内存系统和数据放置策略的创新和发展将为计算机系统性能提升和混合内存架构的成熟发展提供强有力的支持,也是未来计算机体系结构研究的重要方向。
参考文献:
[1]de Moura R C,Schneider G B,de Souza Oliveira L,et al. f-Hybridmem: a fuzzy-based approach for decision support in hybrid memory management [C]// Proc of IEEE International Conference on Fuzzy Systems. Piscataway,NJ: IEEE Press,2020: 1-8.
[2]Liu Haikun,Chen Di,Jin Hai,et al. A survey of non-volatile main memory technologies: State-of-the-arts,practices,and future directions [J]. Journal of Computer Science and Technology,2021,36(1): 4-32.
[3]Guo Yuhua,Xiao Weijun,Liu Qing,et al. A cost-effective and energy-efficient architecture for die-stacked dram/nvm memory systems [C]// Proc of the 37th IEEE International Performance Computing and Communications Conference. Piscataway,NJ: IEEE Press,2018: 1-2.
[4]Wang Bo,Tang Jie,Zhang Rui,et al. Energy-efficient data caching framework for spark in hybrid DRAM/NVM memory architectures [C]// Proc of the 21st IEEE International Conference on High Performance Computing and Communications; the 17th IEEE International Conference on Smart City; the 5th IEEE International Conference on Data Science and Systems. Piscataway,NJ: IEEE Press,2019: 305-312.
[5]Lu Yanchao,Wu Donghong,He Bingsheng,et al. Rank-aware dynamic migrations and adaptive demotions for DRAM power management [J]. IEEE Trans on Computers,2015,65(1): 187-202.
[6]Boukhobza J,Rubini S,Chen R,et al. Emerging NVM: a survey on architectural integration and research challenges [J]. ACM Trans on Design Automation of Electronic Systems,2017,23(2): 1-32.
[7]冒伟,刘景宁,童薇,等. 基于相变存储器的存储技术研究综述 [J]. 计算机学报,2015,38(5): 944-960. (Mao Wei,Liu Jingning,Tong Wei,et al. A review of storage technology research based on phase change memory [J]. Chinese Journal of Computers,2015,38(5): 944-960.)
[8]Rai S,Talawar B. Challenges in design,data placement,migration and power-performance trade-offs in DRAM-NVM-based hybrid memory systems [J]. IETE Technical Review,2023,40(4): 498-520.
[9]Kim J G,Kim S D,Yoon S K. Q-selector-based prefetching method for DRAM/NVM hybrid main memory system [J]. Electronics,2020,9(12): 2158.
[10]Liu Haikun,Chen Yujie,Liao Xiaofei,et al. Hardware/software coo-perative caching for hybrid DRAM/NVM memory architectures [C]// Proc of International Conference on Supercomputing. New York:ACM Press,2017: 1-10.
[11]Hassan A,Vandierendonck H,Nikolopoulos D S. Energy-efficient hybrid DRAM/NVM main memory [C]// Proc of International Conference on Parallel Architecture and Compilation. Piscataway,NJ: IEEE Press,2015: 492-493.
[12]Li Yang,Ghose S,Choi J,et al. Utility-based hybrid memory management [C]// Proc of IEEE International Conference on Cluster Computing. Piscataway,NJ: IEEE Press,2017: 152-165.
[13]Ryoo J H,John L K,Basu A. A case for granularity aware page migration [C]//Proc of International Conference on Supercomputing. New York: ACM Press,2018: 352-362.
[14]Wu Zhangling,Jin Peiquan,Yang Chengcheng,et al. APP-LRU: a new page replacement method for PCM/DRAM-based hybrid memory systems [M]// Network and Parallel Computing. Berlin: Springer,2014: 84-95.
[15]Niu Na,Fu Fangfa,Yang Bing,et al. PRO: a periodical reset optimized page migration scheme for hybrid memory system [J]. Journal of Systems Architecture,2020,111: 101786.
[16]Cha S,Kim B,Park C H,et al. Morphable DRAM cache design for hybrid memory systems [J]. ACM Trans on Architecture and Code Optimization,2019,16(3): 1-24.
[17]Chi Ye,Yue Jianhui,Liao Xiaofei,et al. A hybrid memory architecture supporting fine-grained data migration [J]. Frontiers of Computer Science,2024,18(2): 182103.
[18]Jin Hai,Chen Di,Liu Haikun,et al. Miss penalty aware cache replacement for hybrid memory systems [J]. IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems,2020,39(12): 4669-4682.
[19]Vasilakis E,Papaefstathiou V,Trancoso P,et al. Hybrid2: combining caching and migration in hybrid memory systems [C]// Proc of IEEE International Symposium on High Performance Computer Architecture. Piscataway,NJ: IEEE Press,2020: 649-662.
[20]Kotra J B,Zhang H,Alameldeen A R,et al. Chameleon: a dynamically reconfigurable heterogeneous memory system [C]// Proc of the 51st Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway,NJ: IEEE Press,2018: 533-545.
[21]Bock S,Childers B R,Melhem R,et al. Concurrent migration of multiple pages in software-managed hybrid main memory [C]// Proc of the 34th IEEE International Conference on Computer Design. Piscataway,NJ: IEEE Press,2016: 420-423.
[22]Liu Haikun,Liu Renshan,Liao Xiaofei,et al. Object-level memory allocation and migration in hybrid memory systems [J]. IEEE Trans on Computers,2020,69(9): 1401-1413.
[23]Tan Yujuan,Wang Baiping,Yan Zhichao,et al. UIMigrate: adaptive data migration for hybrid non-volatile memory systems [C]// Proc of Design,Automation & Test in Europe Conference & Exhibition. Piscataway,NJ: IEEE Press,2019: 860-865.
[24]Islam M,Adavally S,Scrbak M,et al. On-the-fly page migration and address reconciliation for heterogeneous memory systems [J]. ACM Journal on Emerging Technologies in Computing Systems,2020,16(1): 1-27.
[25]Sun Hao,Chen Lan,Hao Xiaoran,et al. An energy-efficient and fast scheme for hybrid storage class memory in an AIoT terminal system [J]. Electronics,2020,9(6): 1013.
[26]Yoon H B,Meza J,Ausavarungnirun R,et al. Row buffer locality aware caching policies for hybrid memories [C]// Proc of the 30th IEEE International Conference on Computer Design. Piscataway,NJ: IEEE Press,2012: 337-344.
[27]Wei Wei,Jiang Dejun,McKee S A,et al. Exploiting program semantics to place data in hybrid memory [C]// Proc of International Conference on Parallel Architecture and Compilation. Piscataway,NJ: IEEE Press,2015: 163-173.
[28]Hassan A,Vandierendonck H,Nikolopoulos D S. Software-managed energy-efficient hybrid DRAM/NVM main memory [C]// Proc of the 12th ACM International Conference on Computing Frontiers. New York: ACM Press,2015: 1-8.
[29]Olson M B,Zhou T,Jantz M R,et al. Membrain: automated application guidance for hybrid memory systems [C]// Proc of IEEE International Conference on Networking,Architecture and Storage. Piscataway,NJ: IEEE Press, 2018: 1-10.
[30]Long Linbo,Du Jinpei,Deng Xuxu,et al. Optimizing data placement and size configuration for morphable NVM based SPM in embedded multicore systems [J]. Future Generation Computer Systems,2022,135: 270-282.
[31]de Moura R C,de Souza Oliveira L,Schneider G B,et al. Intf-HybridMem: page migration in hybrid memories considering cost efficiency [J]. Sustainable Computing: Informatics and Systems,2021,29: 100466.
[32]Liu Lei,Yang Shengjie,Peng Lu,et al. Hierarchical hybrid memory management in OS for tiered memory systems [J]. IEEE Trans on Parallel and Distributed Systems,2019,30(10): 2223-2236.
[33]邱杰凡,华宗汉,范菁,等. 内存体系划分技术的研究与发展 [J]. 软件学报,2022,33(2): 751-769. (Qiu Jiefan,Hua Zonghan,Fan Jing,et al. Evolution of memory partitioning technologies: Case study through page coloring [J]. Journal of Software,2022,33(2): 751-769.)
[34]Peng I B,Gioiosa R,Kestor G,et al. RTHMS: a tool for data placement on hybrid memory system [J]. ACM SIGPLAN Notices,2017,52(9): 82-91.
[35]Servat H,Pe?a A J,Llort G,et al. Automating the application data placement in hybrid memory systems [C]// Proc of IEEE International Conference on Cluster Computing. Piscataway,NJ: IEEE Press,2017: 126-136.
[36]Doudali T D,Gavrilovska A. Machine learning augmented hybrid memory management [C]// Proc of the 30th International Symposium on High-Performance Parallel and Distributed Computing. New York: ACM Press,2021: 253-254.
[37]Doudali T D,Blagodurov S,Vishnu A,et al. Kleio: a hybrid memory page scheduler with machine intelligence [C]// Proc of the 28th International Symposium on High-Performance Parallel and Distributed Computing. New York: ACM Press,2019: 37-48.
[38]Doudali T D,Zahka D,Gavrilovska A. Tuning the frequency of periodic data movements over hybrid memory systems [EB/OL]. (2021-01-15). https://arxiv.org/abs/2101.07200.
[39]Doudali T D,Gavrilovska A. Coeus: clustering (a) like patterns for practical machine intelligent hybrid memory management [C]// Proc of the 22nd IEEE International Symposium on Cluster,Cloud and Internet Computin. Piscataway,NJ: IEEE Press,2022: 615-624.
[40]Doudali T D,Gavrilovska A. Mnemo: boosting memory cost efficiency in hybrid memory systems [C]// Proc of IEEE International Parallel and Distributed Processing Symposium Workshops. Piscataway,NJ: IEEE Press,2019: 412-421.
[41]Doudali T D,Gavrilovska A. CoMerge: toward efficient data placement in shared heterogeneous memory systems [C]// Proc of International Symposium on Memory Systems. New York: ACM Press,2017: 251-261.
[42]Aswathy N S,Bhavanasi S,Sarkar A,et al. SRS-Mig: selection and run-time scheduling of page migration for improved response time in hybrid PCM-DRAM memories [C]// Proc of Great Lakes Symposium on VLSI. New York: ACM Press,2022: 217-222.
[43]Cai Miao,Huang Hao. A survey of operating system support for persistent memory [J]. Frontiers of Computer Science,2021,15: 1-20.
[44]Mutlu O. Main memory scaling: challenges and solution directions [M]// More than Moore Technologies for Next Generation Computer Design. New York: Springer, 2015: 127-153.
[45]Salkhordeh R,Asadi H. An operating system level data migration scheme in hybrid DRAM-NVM memory architecture [C]// Proc of Design,Automation & Test in Europe Conference & Exhibition. Piscataway,NJ: IEEE Press,2016: 936-941.
[46]Lee S,Bahn H,Noh S H. CLOCK-DWF: a write-history-aware page replacement algorithm for hybrid PCM and DRAM memory architectures [J]. IEEE Trans on Computers,2013,63(9): 2187-2200.
[47]Choi J H,Kim K M,Kwak J W. TA-CLOCK: tendency-aware page replacement policy for hybrid main memory in high-performance embedded systems [J]. Electronics,2021,10(9): 1111.
[48]李琪,钟将,李雪,等. 基于新型非易失存储器的混合内存架构的内存管理机制 [J]. 电子学报,2019,47(3): 664-670. (Li Qi,Zhong Jiang,Li Xue,et al. Memory management mechanism for hybrid memory architecture based on new non-volatile memory [J]. Acta Electronica Sinica,2019,47(3): 664-670.)
[49]Duan Zhuohui,Liu Haikun,Liao Xiaofei,et al. HiNUMA: NUMA aware data placement and migration in hybrid memory systems [C]// Proc of the 37th IEEE International Conference on Computer Design. Piscataway,NJ: IEEE Press,2019: 367-375.
[50]曲良,陈岚,郝晓冉,等. 基于混合内存的存储系统优化方案 [J]. 电子设计工程,2019,27(21): 140-145. (Qu Liang,Chen Lan,Hao Xiaoran,et al. Optimization scheme of memory system based on hybrid main memory [J]. Electronic Design Engineering,2019,27(21): 140-145.)
[51]Zhang Yiming,Zhan Jinyu,Yang Junhuan,et al. Energy-aware page replacement for NVM based hybrid main memory system [C]// Proc of the 23rd IEEE International Conference on Embedded and Real-Time Computing Systems and Application. Piscataway,NJ: IEEE Press,2017: 1-6.
[52]孙浩,陈岚,郝晓冉,等. 一种面向边缘计算的混合内存系统 [J]. 北京邮电大学学报,2020,43(2): 103-109. (Sun Hao,Chen Lan,Hao Xiaoran,et al. A hybrid memory system for edge computing [J]. Journal of Beijing University of Posts and Telecommunications,2020,43(2): 103-109.)
[53]Kim T,Jamil S,Park J,et al. Optimizing placement of heap memory objects in energy-constrained hybrid memory systems [J]. arXiv preprint arXiv: 2006. 12133,2020.
[54]Huang Jiacheng,Peng Min,Wu Libing,et al. Lamina: low oO8k2Qx7RDZr4LedOK0BOPQ==verhead wear leveling for NVM with bounded tail [C]// Proc of the 27th Asia and South Pacific Design Automation Conference. Piscataway,NJ: IEEE Press,2022: 377-382.
[55]Yu Hongliang,Du Yuyang. Increasing endurance and security of phase-change memory with multi-way wear-leveling [J]. IEEE Trans on Computers,2012,63(5): 1157-1168.
[56]Qureshi M K,Srinivasan V,Rivers J A. Scalable high performance main memory system using phase-change memory technology [C]// Proc of the 36th Annual International Symposium on Computer Architecture. New York: ACM Press,2009: 24-33.
[57]Azevedo R,Davis J D,Strauss K,et al. Zombie memory: extending memory lifetime by reviving dead blocks [C]// Proc of the 40th Annual International Symposium on Computer Architecture. 2013: 452-463.
收稿日期:2023-12-12;修回日期:2024-02-20 基金项目:中国高校产学研自然基金资助项目(2021FNA04016)
作者简介:林炳辉(1998—),男,福建泉州人,硕士研究生,主要研究方向为混合内存优化,软件工程等;张建勋(1978—),男,河北保定人,教授,硕导,博士,CCF会员,主要研究方向为混合存储优化(Zhangjx@tute.edu.cn);乔欣雨(1997—),女,江苏南京人,硕士研究生,主要研究方向为软件工程.
