用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法
2024-10-31暴琳齐亮吴杨陈佳佳
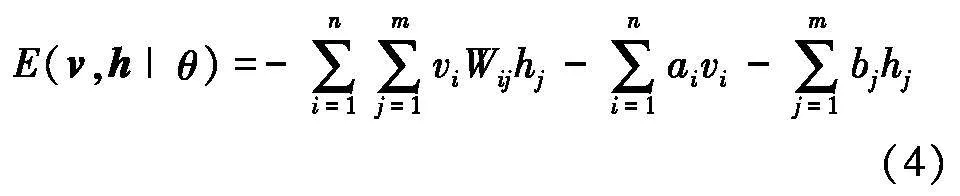

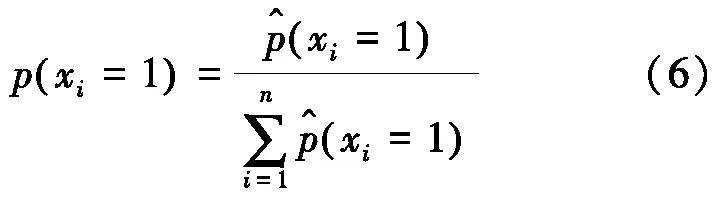


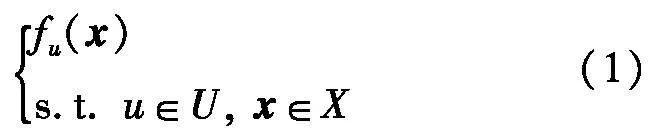
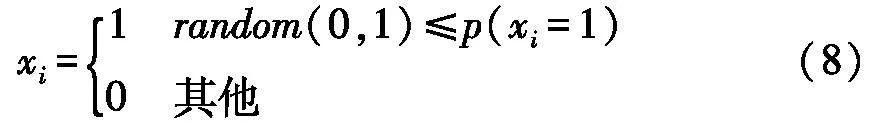
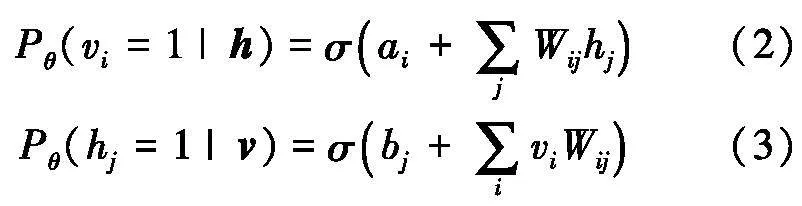
摘 要: 随着互联网用户数量迅猛增长,产生了大量用户生成内容,出现了信息过载现象.考虑用户生成数据,建立用户兴趣偏好模型,同时联合交互式进化计算,提出用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法,帮助用户从海量搜索空间中搜寻符合用户潜在需求和兴趣偏好的项目或内容.利用用户交互行为、评分数据和项目类别信息,构建基于受限玻尔兹曼机的用户偏好感知模型,抽取用户偏好特征;从进化优化的角度,设计基于用户偏好的代理模型及其进化策略,生成含用户偏好的新个体,并预测进化个体适应值,引导进化优化过程;根据新增用户生成内容和模型管理机制,动态更新各模型,及时跟踪用户偏好,顺利完成个性化进化搜索.通过大量真实世界数据集的实验,验证了所提算法处理动态个性化搜索和推荐任务的可行性及有效性.
关键词: 交互式进化计算;代理模型;用户生成内容;受限玻尔兹曼机;个性化搜索
中图分类号:TP391"" 文献标志码:A"""" 文章编号:1673-4807(2024)02-065-08
Preference surrogate-assisted interactive personalized evolutionarysearch algorithm based on user behaviors
Abstract:With the rapid growth of the number of users on internet, a lot of user-generated contents (UGCs) has been generated, and there has been information overload. This paper makes full use of UGCs to build a user interest preference model, and proposes a preference surrogate-assisted interactive personalized evolutionary search algorithm based on user behaviors. Combing the interactive evolutionary computing, it helps users search for the items that meet their potential needs and interest preferences from a massive search space. By using interaction behaviors, ratings and item category information, a user preference perception model based on restricted Boltzmann machine is constructed to extract the user preference features. From the perspective of evolutionary optimization, a surrogate model based on the user preference and its evolutionary strategies is designed to generate new individuals with the user preference, and predict the fitness value of new individuals to guide the evolutionary optimization process. Meanwhile, according to new UGCs and model management mechanism, these models are dynamically updated to timely track the user preference for the personalized evolutionary search. Through a large number of experiments in the real-world datasets, the feasibility and effectiveness of the proposed algorithm are verified in dynamic personalized search and recommendation tasks.
Key words:interactive evolutionary optimization, surrogate model, user-generated contents, restricted Boltzmann machine, personalized search
随着互联网和电子商务技术的蓬勃发展,用户数量呈现快速增长的态势,产生了各式各样的海量数据,蕴含了丰富的用户兴趣爱好及个性化信息[1-3].个性化搜索和推荐算法充分挖掘用户历史行为数据,建立用户兴趣模型与行为模式,帮助用户从海量搜索空间中搜寻符合用户潜在需求和兴趣偏好的项目或内容,将用户可能感兴趣的内容(如:商品、音乐、微博、新闻等)以个性化项目列表的形式推荐给用户,提升用户的使用体验与电子商务平台的商业利益,实现供需双赢.
面向含用户生成内容(user-generated content, UGCs)的个性化搜索问题中,用户偏好和意图难以建立明确定义的数学模型或目标函数描述表示,需依据用户的认知经验和个性化偏好,对待搜索任务进行定性分析、评价和决策,且用户满意解的界定是非常主观且因人而异的,其搜索结果和推荐效果则完全由用户偏好主观决定,展现了该类问题具有主观性、模糊性、不确定性及不一致性.此外,用户的兴趣偏好是多种多样的,可能将随着时间推移、环境迁移和信息量增加等多种因素影响,用户需求和兴趣偏好逐渐清晰,甚至有可能发生动态变化.用户参与个性化搜索过程的交互式进化计算(interactive evolutionary computations, IECs)能够有效利用用户对于具体优化问题的主观评价与决策,将人类智能信息与传统进化计算相结合,是处理上述这类复杂定性指标优化问题的有效途径及可行方法.
已有个性化搜索和推荐算法的相关研究具有一定的参考价值及借鉴作用.文献[4]利用贝叶斯模型描述用户偏好分布,使用区间数值化表示用户偏好关系,训练径向基函数神经网络,提出交互式进化计算处理个性化搜索.文献[5]整合用户历史交互行为,提出基于注意力机制的用户行为模型框架,有效处理推荐问题.文献[6]根据用户隐式偏好信息的不确定性,考虑推荐过程和结果的精确性与多样性,提出基于贝叶斯Mallows模型的多样性个性化推荐算法.文献[7]利用知识图提取项目属性作为边信息,用户和项目由一组属性嵌入表示,并建立属性级协同注意力机制,捕获不同属性间的相关性,增强用户表示与项目表示,提出知识增强的推荐模型.文献[8]考虑时间动态性,利用时间窗口设置不同粒度的时间因子,进行动态建模,并设计样本数据生成和存取策略,提出基于时间动态性的场感知分解机模型.文献[9]采用遗传算法处理用户与项目隐因子优化问题,将增强指数机制融入个体选择策略,并依据寻找重要隐因子的思想设计变异过程,提出满足差分隐私保护的矩阵分解推荐算法.文献[10]利用轻量级图卷积方法,建模用户和项目的异构交互,并整合邻域信息,提出基于异构邻域聚合的协同过滤推荐算法.上述研究工作从不同方面试图改进现有个性化搜索和推荐算法的不足.这些方法均假设所有数据是已知且充足的,整合UGCs数据建立用户兴趣模型,而模型训练复杂度较大.另一方面,相比于海量UGCs,相关有用信息过于稀疏,同时用户的兴趣偏好具有动态演化特性,所构建的模型将对于用户行为的理解有较大的片面性,不能完全准确地代表用户真实意图,从而难以适应实际个性化搜索和推荐任务的应用场景.
文中挖掘并利用历史用户交互行为和含用户偏好的项目属性信息,构建描述用户潜在需求及个性化偏好的基于受限玻尔兹曼机(restriced Boltzmann machines, RBM)用户偏好感知模型,抽取用户偏好特征;在分布估计算法(estimation of distribution algorithms, EDA)框架下,利用已训练好的RBM用户偏好感知模型,设计基于用户偏好的EDA采样概率模型,表达待搜索项目与用户偏好之间的非线性关系,驱动进化优化过程生成含用户偏好的新个体;同时,根据用户偏好感知模型的能量函数,设计基于用户偏好的代理模型,有效预测用户偏好行为,部分代替用户真实评价,估计进化个体适应值;根据新增用户交互行为和相关信息,利用模型管理机制,动态更新用户偏好感知模型及其相应模型,提出了用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法,处理复杂网络环境下面向含UGCs的个性化搜索和推荐任务.将所提理论与方法应用于真实世界数据集,通过大量实验展示了所提算法的可行性及有效性.
1 面向含用户生成内容个性化搜索问题的数学描述
面向含UGCs的个性化搜索任务是在海量多源异构用户生成数据构成的动态演化可行域空间中,搜寻符合用户潜在需求和个性化兴趣偏好的优化目标,为用户进行个性化项目推荐,即其本质上是一类复杂动态定性指标优化问题.这里,面向含UGCs的个性化搜索问题的目标函数fu(x)定义为:
式中:U=u1,u2,…,uU是用户集合,U为用户数量;X={x1,x2,…,x|X|}为项目集合(可行解空间),通常X很大且稀疏,|X|表示项目数量;项目(解)xi含有n个决策变量,表示为xi={xi1,xi2,…,xin};用户u对于项目x的偏好程度为fu(x),其无法用具体数学函数精确表示,由用户u的认知经验和兴趣偏好决定,且在个性化搜索过程中可能发生动态变化.
2 用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法
2.1 算法框架
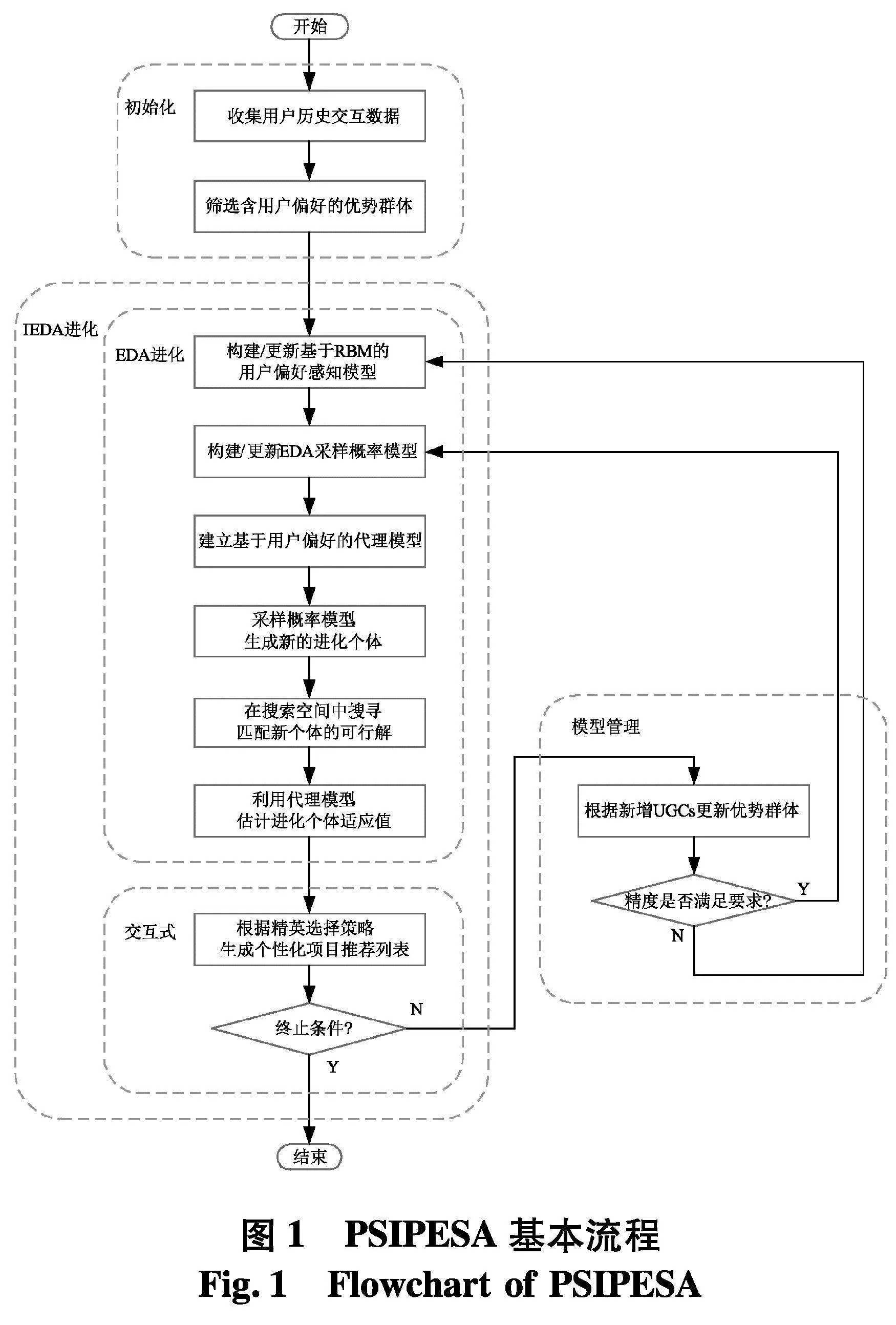
用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法(preference surrogate-assisted interactive personalized evolutionary search algorithm based on user behaviors, PSIPESA)的基本流程如图1.
所提算法主要包括4部分:
(1) 基于用户交互行为的RBM用户偏好感知模型:根据UGCs信息,构建含用户偏好的优势群体,训练基于RBM的用户偏好感知模型,抽取用户偏好特征.
(2) 基于用户偏好的EDA采样概率模型:在IEDA进化框架下,设计基于用户偏好的采样概率模型,生成含用户偏好的新个体,并在搜索空间中匹配新的可行解,构成下一代种群,推进进化优化过程.
(3) 基于用户偏好的代理模型:根据用户偏好感知模型,设计用户评价代理模型,估计进化个体的适应值,并依据精英选择策略,生成用户可能感兴趣的项目推荐列表,提交给用户进行评价.
(4) 模型管理模块:根据新增UGCs,利用模型管理机制,动态更新优势群体、用户偏好感知模型、概率模型及代理模型,有效引导个性化进化搜索过程.
2.2 基于用户交互行为的RBM用户偏好感知模型
在个性化搜索过程中,考虑用户偏好的不确定性及动态性,充分挖掘这些用户生成数据,分析用户兴趣偏好的发展与演化,建立表达用户需求和爱好的用户偏好感知模型,提取用户偏好特征,为个性化搜索和推荐服务.
根据用户历史交互行为数据,筛选含当前用户偏好的项目集合构成优势群体D,如:若用户对于某项目的评分或排名高于阈值,通常意味着用户喜欢该项目,则将该项目归入优势群体;若用户浏览项目,获得较长浏览时间的项目划入优势群体.将优势群体D作为EDA进化优化框架下的初始种群Pop(0)={xi,i=1,2,…,|D|},种群规模为|D|.关于种群中进化个体的编码,项目(个体)x由n个属性描述,表示为决策变量的二进制编码x=x1,x2,…,xn,其中,第i个决策变量xi取值为1或0,1表示该项目具有该属性,0表示无该属性.项目(个体)包含了用户的兴趣偏好,若进化个体x的第i个决策变量xi=1,表示用户对于含有属性i的项目感兴趣.
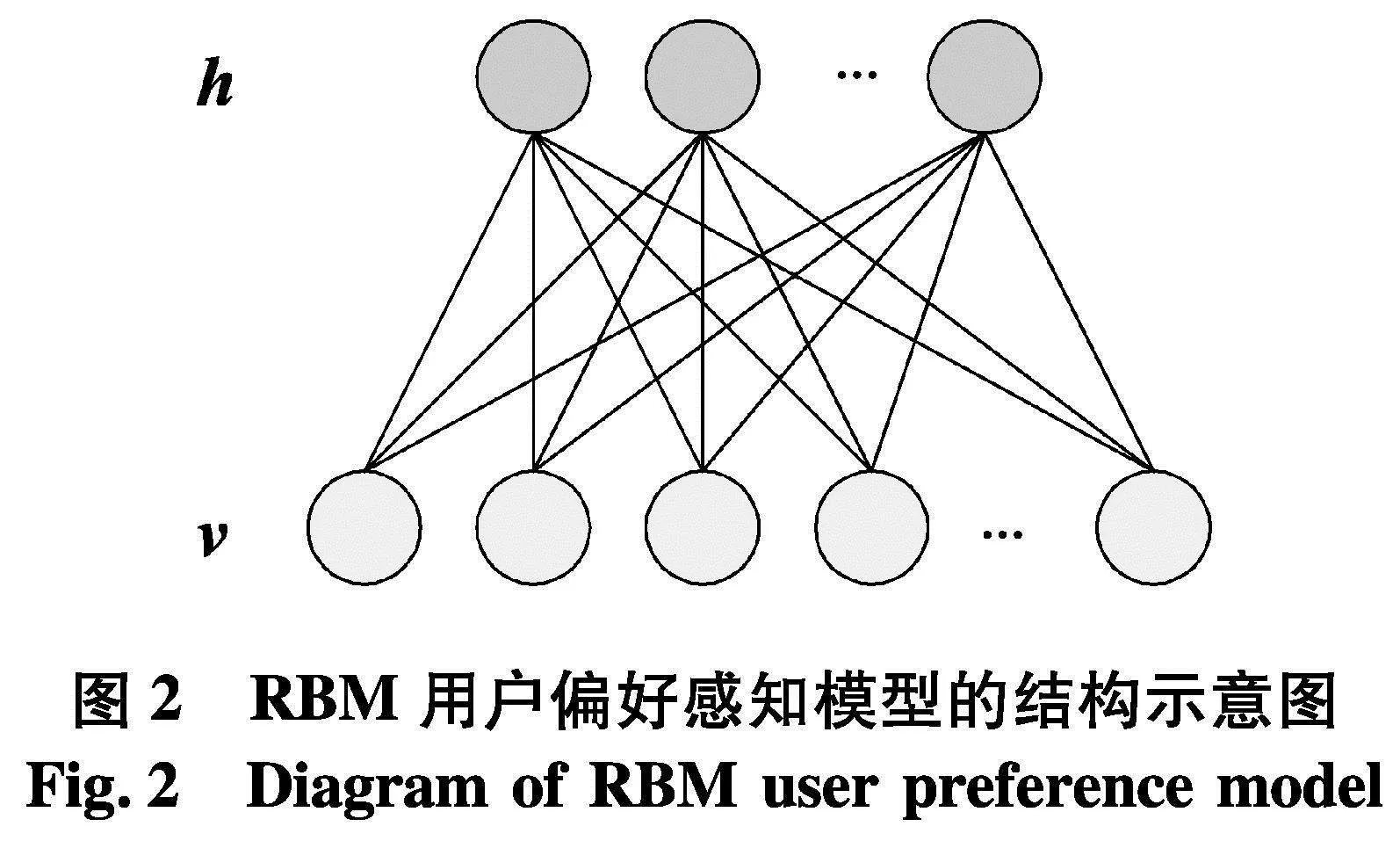
根据优势群体在搜索空间中的决策变量属性分布信息,利用RBM模型的隐式表达能力和特征提取能力,拟合基于用户交互行为的定性指标决策变量之间的高阶非线性关系,构建RBM用户偏好感知模型,捕捉用户偏好特征.基于用户交互行为的RBM用户偏好感知模型的结构示意图如图2.
基于用户交互行为的RBM用户偏好感知模型具有两层网络结构:可见层v包含n个可见单元,表示项目(个体)的n个属性,vi为第i个可见单元状态;隐层h含有m个隐单元,表示用户偏好特征,hj为第j个隐单元状态.其中,可见单元和隐单元均为二值变量.
可见单元和隐单元的条件分布概率分别为:
式中:Wij为可见单元i与隐单元j之间的连接权重;ai和bj分别为可见单元i和隐单元j的偏置.
对于一组给定状态(v,h),基于用户交互行为的RBM用户偏好感知模型的系统能量函数为:
式中:θ={W,a,b}表示模型参数,均为实数.
通过RBM模型CD学习算法[11],将种群中进化个体的二进制基因编码x={x1,x2,…,xn},作为训练数据集T={(xi,f(xi)),i=1,2,…,|D|},输入基于用户交互行为的RBM用户偏好感知模型的可见层单元v={v1,v2,…,vn},训练用户偏好感知模型,捕捉用户偏好信息的高阶非线性关联关系,获得含优良解基因分布特征表示的RBM模型参数θ={W,a,b}.
2.3 基于用户偏好的EDA采样概率模型
在IEDA进化优化框架下,构建基于用户偏好的EDA采样概率模型Pu(x)为:
Pu(x)=[p(x1=1),p(x2=1),…,p(xn=1)](7)
通过对可观察用户生成数据的概率估计,基于用户偏好的EDA采样概率模型Pu(x)建模用户兴趣偏好选择倾向,将个性化搜索问题转化为用户偏好行为发生概率最大化问题.
随机采样概率模型Pu(x),生成含用户偏好的新个体.随机采样公式为:
式中:xi是新个体x的第i个决策变量属性值;random(0,1)是取值在0,1之间的随机数.
此外,在更新进化种群的过程中,分配一个较小的概率(如:10%),采样非优势群体,与上述生成的新个体共同构成下一代进化种群Popg={xi,i=1,2,…,D},避免过早产生进化早熟现象.在保证种群信息多样性的同时,驱动种群朝着优良解集的方向进化.
由于在进化计算中使用了进化个体编码解技术,使得采样生成的许多新个体可能无法匹配搜索空间中的实际项目.因此,需根据新个体与待搜索项目的基因相似性,匹配相同或相似的项目可行解,构成待推荐项目集合S.
2.4 基于用户偏好的代理模型
式中:Eθ(x,h)表示进化个体x在RBM用户偏好感知模型中的能量函数值;maxEθ和minEθ分别为待推荐项目集合S中个体的最大和最小能量函数值.
值的N个优良个体,生成满足用户需求且用户可能感兴趣的个性化项目推荐列表TopN,提交给用户进行交互式评价.
在个性化进化搜索过程中,收集真实交互式用户评价信息,衡量代理模型的预测精度,并根据新增用户生成数据,更新用户偏好感知模型、概率模型和代理模型,及时跟踪用户偏好的动态变化,指导交互式个性化搜索的方向,顺利完成个性化搜索和推荐任务.
3 实验结果与分析
3.1 实验环境
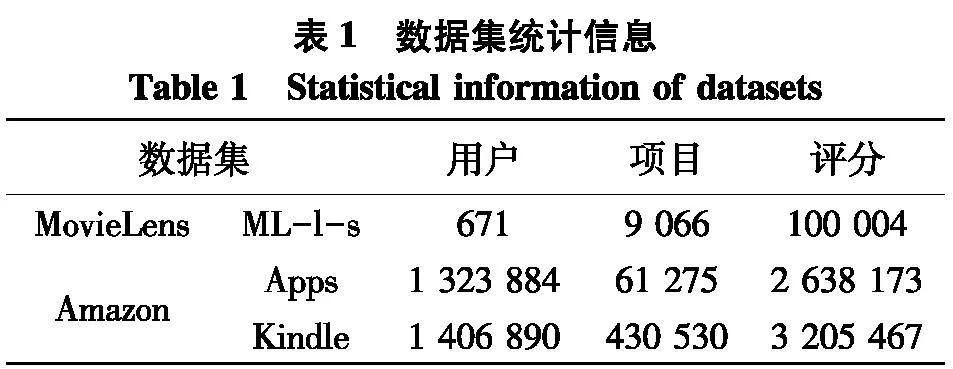
为了验证所提个性化搜索算法的综合性能,采用真实世界通用数据集MovieLens[12]和Amazon [13]进行实验与分析.数据集统计信息描述如表1.
实验环境中处理器为Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz和256GB RAM,实验平台使用Python 3.8开发.采用均方根误差(root mean square error, RMSE)[14-15]、命中率(hit ratio, HR)[15]、平均准确率(average precision, AP)和平均准确率均值(mean average precision, MAP)[15]等评价指标,客观展示个性化搜索和推荐算法的预测精度与推荐性能.
3.2 用户偏好感知模型和偏好代理模型的性能
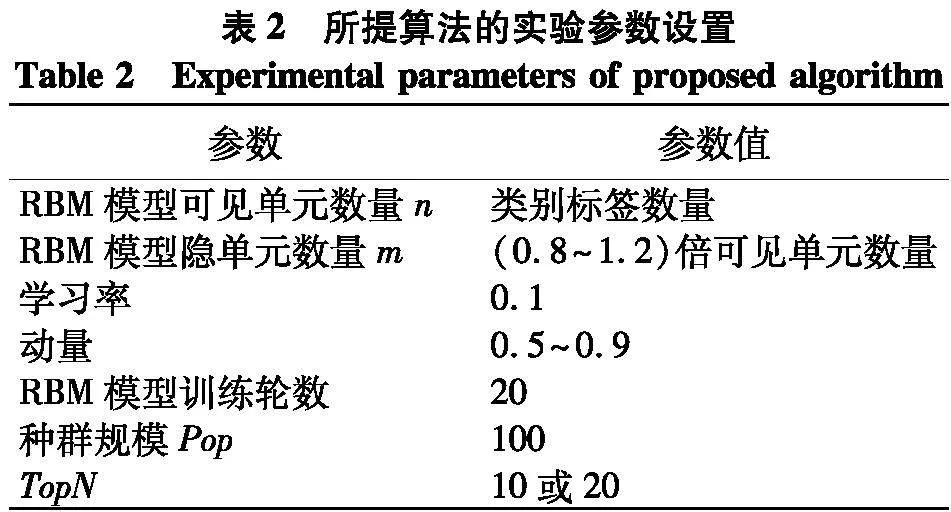
将所提算法去除进化优化框架,简化为用户行为驱动偏好代理模型辅助的个性化进化搜索算法(preference surrogate-assisted personalized evolutionary search algorithm based on user behaviors,PSPESA),与其他推荐方法进行对比实验.对比算法包括:随机推荐算法(Random)、基于项目流行度的推荐算法(Popularity)、基于用户的协同过滤算法(user-based collaborative filtering,UserCF) [16]、基于项目的协同过滤算法(item-based collaborative filtering,ItemCF) [16]、BPR [17]、SVD [18]和RBM[19]算法.协同过滤算法的相似用户(项目)数量设置为10.BPR和SVD算法的隐因子数量分别设置为64和20.所提PSIPESA算法的实验参数设置如表2.实验参数根据经验值或实验设定.
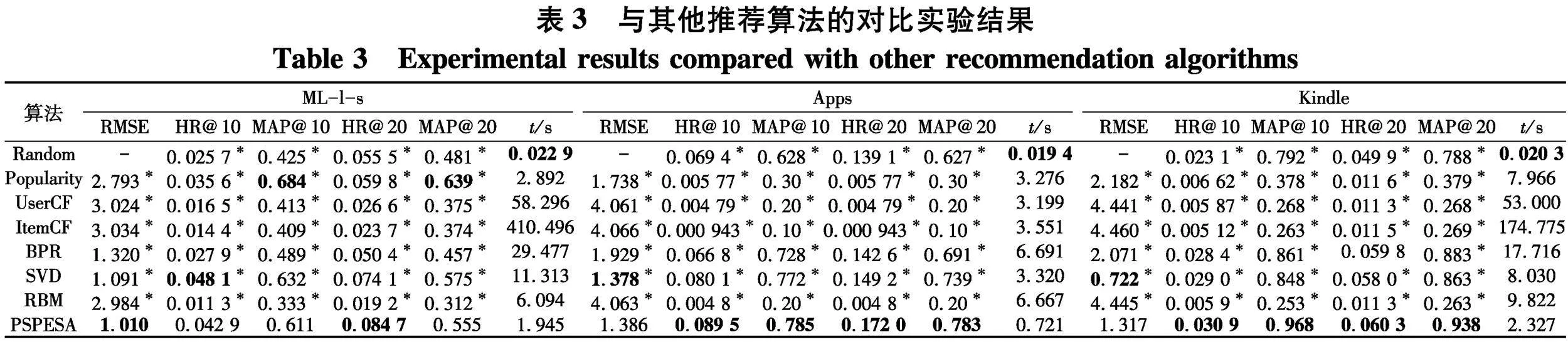
为了保障对比实验的客观性和公正性,在各实验数据集中选择较为活跃的1 000名用户及其相关信息.随机选取10名测试用户进行个性化搜索和推荐实验,按照时间戳顺序重新排列测试用户的交互行为数据,以前70%和后30%的比例划分训练和测试数据集.实验中,各算法独立运行10次,使用RMSE、HR@10、MAP@10、HR@20、MAP@20和时间花费(s)6种性能评价指标,计算所有测试用户的平均评价指标.统计平均实验结果如表3.
利用Bonferroni校正进行Kruskal-Wallis检验,分析各组实验结果之间的分布差异.若所提算法与对比算法具有显著性差异(渐进显著性plt;0.05),则将该对比算法的实验结果标记为“*”,最优值加粗表示.
通过观察对比实验结果,得出以下结论:
(1) 对比实验中,PSPESA算法总体上取得了相对较好的预测准确性和推荐效果.在ML-l-s数据集中,所提算法取得了最优RMSE值,而在其他数据集中SVD算法获得了最小RMSE值.这主要是因为SVD通过训练集中的实际项目评分进行了有监督学习,使得其获得较高的预测准确性,而PSPESA采用了未使用实际用户评分值的无监督训练,因而,所提算法关于RMSE指标的表现不如SVD,但是也取得了能够与基于有监督学习的推荐算法相比较的实验结果.除了SVD外,PSPESA的RMSE值明显优于其他对比算法.基于协同过滤的推荐算法(包括基于用户和基于项目的协同过滤)的评分预测误差RMSE最大,主要是数据集的稀疏性严重影响了协同过滤算法的预测准确性.另外,虽然Popularity算法是一类简单的非个性化搜索算法,但是在各数据集实验中取得了甚至比协同过滤和基于RBM推荐算法高的预测准确率,展示了本实验将其作为基线算法的必要性.
(2) 所提算法能够将待搜索项目进行良好排序,其将用户感兴趣的项目排在推荐列表的前面,给予用户优良的搜索浏览体验,获得了较好的命中率和平均准确率均值.例如,在Kindle数据集中,相比与其他对比算法,PSPESA获得了最优HR@10、MAP@10、HR@20和MAP@20值.所提算法取得了最优HR@10值0.030 9,高于次优SVD算法6.55%,且高于Random算法33.77%,高于Popularity算法366.77%,高于UserCF算法426.41%,高于ItemCF算法503.52%,高于BPR算法8.80%,高于RBM算法423.73%;[JP3]同时,也取得了最优MAP@10值0.968.基于无监督学习的PSPESA算法训练时不依赖于用户具体评分值,充分利用用户隐式偏好行为,获得了良好的搜索性能、推荐效果及用户满意度.
(3) 从搜索时间花费来看,除了Random算法,PSPESA算法的时间花费显著低于其他对比算法.说明所提算法利用基于RBM的用户偏好感知模型和基于用户偏好的进化优化策略,有效降低了计算代价及运行时间,而同时并未明显降低算法的预测性能、寻优能力和推荐效果.UserCF和ItemCF算法的时间消耗总体上高于其他算法,主要是因为基于协同过滤的推荐方法需计算所有用户或项目间的相似性,会消耗大量计算时间,[JP3]且随着数据集中用户或项目数量的增加,协同过滤算法的运行时间将急剧增加.BPR算法在个性化推荐过程中需要增加额外信息,如:遵循一定的采样策略获得用户不喜欢的项目,因而其训练数据集增多,运行时间也将加长.SVD和RBM算法将花费大量时间计算用户和项目的隐表示,其时间消耗也相对较大.因此,尽管所提算法在一些评估指标中未取得最优值,但总体上具备较好的预测准确性和搜索效率,且当可行域搜索空间十分巨大时,所提算法时间花费的优势将会更加显著.
综上所述,PSPESA算法利用用户交互行为数据,构建RBM用户偏好感知模型,抽取用户偏好特征,并联合用户偏好代理模型,预测待推荐项目的评分,花费了较少时间进行有效的个性化项目推荐.
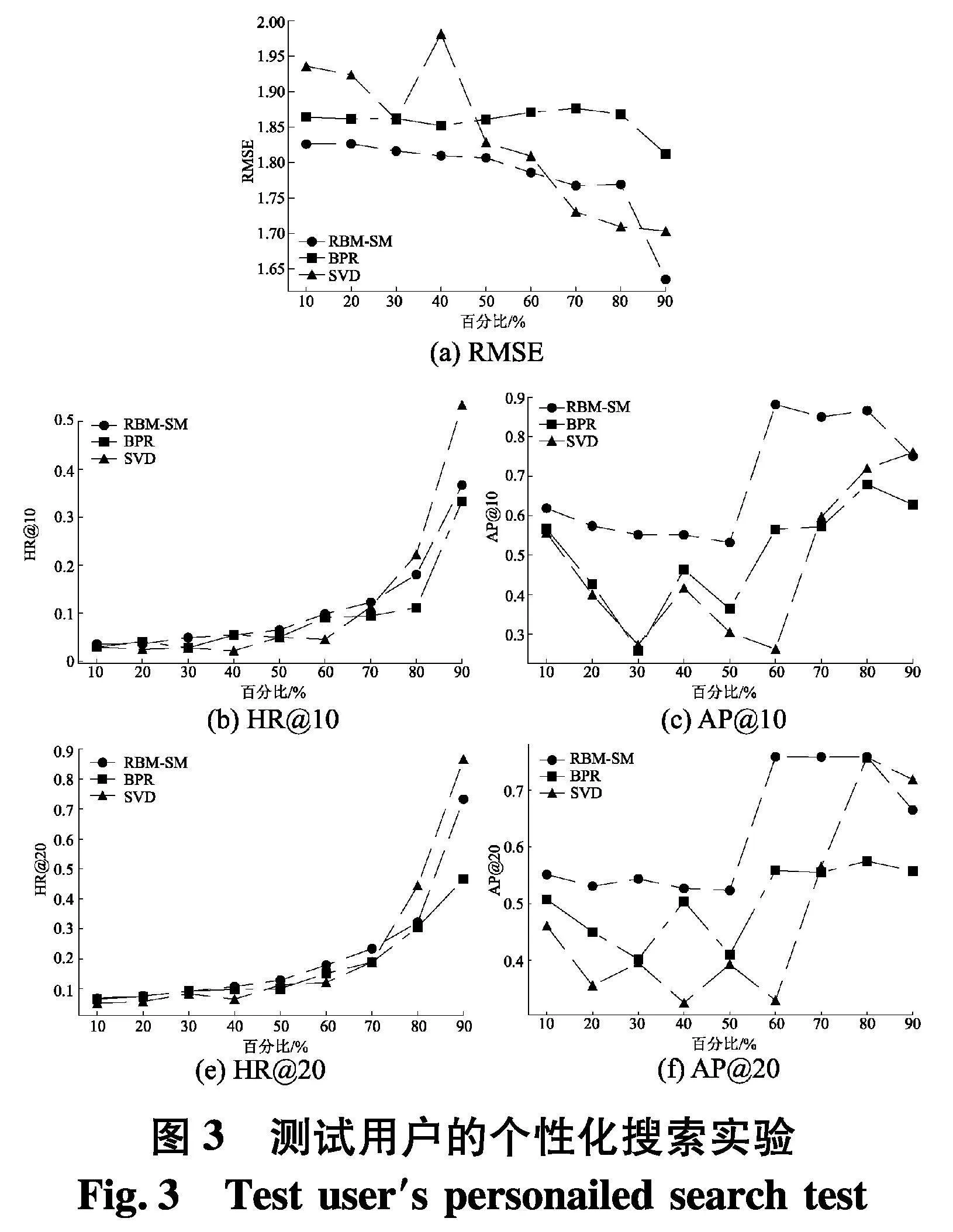
在Apps数据集中,以测试用户“ASXYFYCPIP232”为例,进一步展示BPR、SVD和PSPESA算法分别进行个性化搜索和推荐过程,实验结果如图3.
从图3可以看出,用户交互行为驱动的PSPESA算法的预测性能和个性化推荐效果总体上优于BPR和SVD算法.另外,当训练数据量逐渐增加时,各类个性化推荐算法的预测精度与推荐性能都有一定程度的提升,说明充分挖掘用户历史交互行为数据能够有效提高个性化搜索和推荐算法的综合性能.
3.3 RBM偏好代理IEDA算法的综合性能
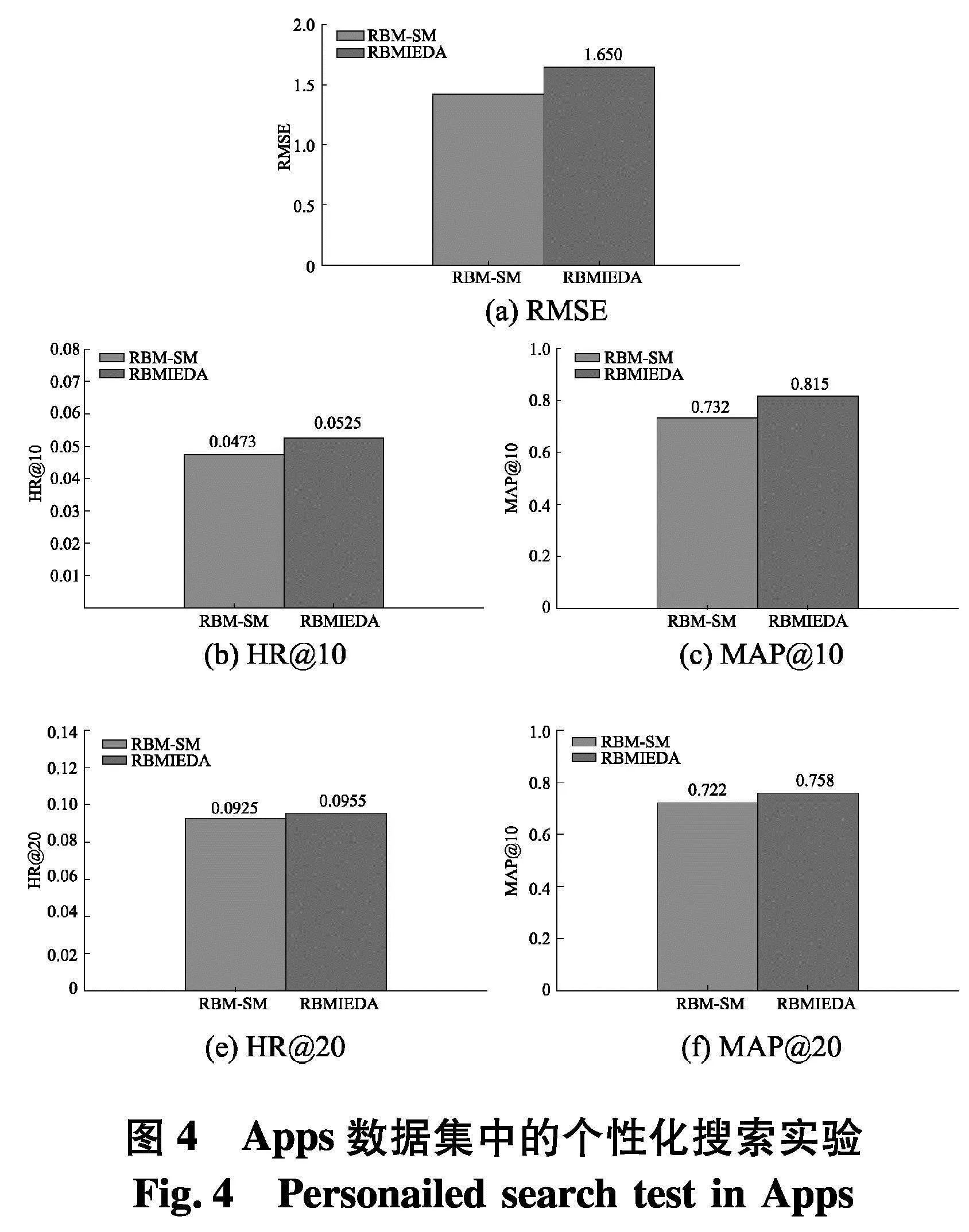
为了展示交互式个性化进化搜索算法的性能,将PSPESA算法与联合交互式进化计算的PSIPESA算法进行对比实验.在数据集中,随机选择10位用户进行交互式个性化搜索过程,将用户交互行为数据的前50%作为训练数据集,剩余50%作为测试数据集.另外,对于PSIPESA算法,训练数据集的前20%作为初始历史交互数据,后30%分割为10份作为每次进化迭代的新增用户交互行为数据.实验中,PSPESA和PSIPESA算法分别独立运行10次,计算平均性能评价指标.图4为Apps数据集中的实验结果.
从图4看出,PSIPESA算法总体上优于PSPESA算法.虽然PSIPESA算法的RMSE值略有不足,但是其HR@10和HR@20分别提高了10.99%和3.24%,MAP@10和MAP@20分别提高了11.34%和4.99%.实验结果说明联合交互式
EDA的PSIPESA取得了推荐准确率和用户满意度的提升,这是合理且有效的.此外,在个性化搜索实验过程中,实际上PSPESA比PSIPESA算法使用了更多的训练数据,从而其评分预测准确率较高也是可以理解的.
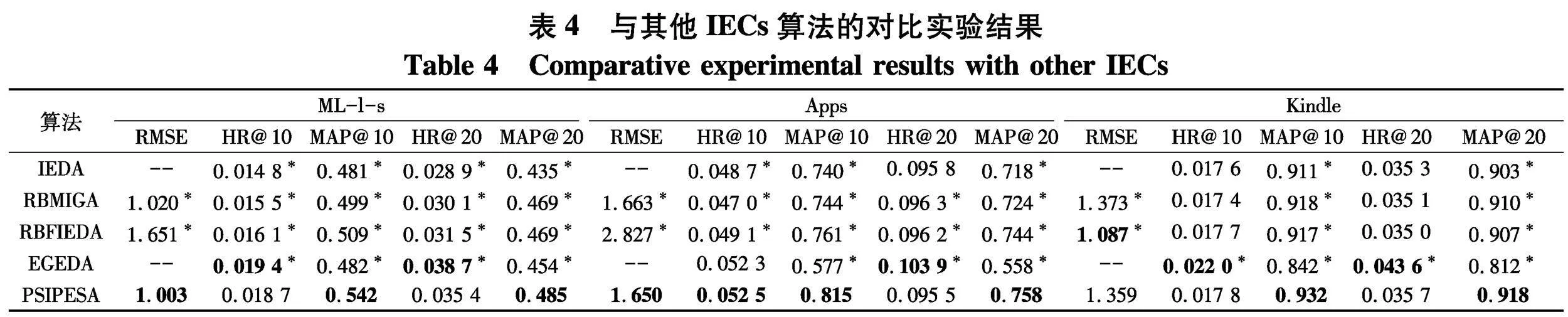
为了进一步验证PSIPESA算法处理个性化搜索和推荐任务的综合性能,将所提算法与其他IECs算法进行对比实验,如:传统IEDA、RBM辅助的交互式遗传算法(RBM-assisted interactive genetic algorithm,RBMIGA)、RBFIEDA[4]和EGEDA[20]算法.RBMIGA采用中间交叉(交叉概率为0.8)和单点变异(变异概率为0.3).各算法分别独立运行10次,计算平均评价指标.利用Bonferroni校正进行Kruskal-Wallis检验,分析各组实验结果之间的分布差异,方法同上小节.实验结果如表4.由于在IEDA和EGEDA算法中未构造代理模型预测项目评分,所以这两种算法的实验结果中没有平均RMSE值.
通过观察实验结果,得出以下结论:
(1) PSIPESA算法获得了较好的预测准确性和推荐效果,相比与其他对比算法,在各评价指标上具有显著提升.例如:在Apps数据集中,所提算法取得最优平均RMSE值1.650,优于次优算法0.78%;平均HR@10、HR@20和MAP@20分别取得了0.052 5、0.815和0.758,高于次优算法0.38%、7.10%和1.88%.在部分数据集中,虽然所提算法的一些评价指标未取得最优值,但综合比较其仍旧获得了最优综合性能.
(2) 大部分情况下,PSIPESA算法的平均HR和MAP值优于其他对比算法,说明在交互式评价环境中所提算法能够帮助用户尽快搜寻到其满意解,进行良好的个性化项目推荐列表排序,提高了搜索效率、推荐效果和用户满意度.
综上所述,所提算法为个性化搜索和推荐任务建立了一整套体系,分析用户交互行为数据,构建用户偏好感知模型,挖掘深层次的潜在用户偏好特征及其动态演化规律;建立基于用户偏好的EDA采样概率模型和评价代理模型,预测项目评分,进行个性化项目推荐;根据用户体验、反馈评价等客观评估指标,利用模型管理机制,引导交互式个性化进化搜索的前进方向,具备良好的有效性、稳定性及可扩展性.
4 结论
文中以面向含UGCs的个性化搜索和推荐任务为背景,联合推荐技术中的用户兴趣建模和基于代理模型的IECs算法,以用户体验为中心,研究用户行为驱动偏好代理模型辅助的交互式个性化进化搜索算法,将其应用于个性化搜索这类复杂动态定性指标优化问题.后续将进一步深入挖掘UGCs信息,构建更精确的用户偏好感知模型和基于用户偏好的进化优化策略,提高个性化进化搜索算法的探索能力、寻优效率和推荐效果.
参考文献(References)
[1] 吴信东, 盛绍静, 蒋婷婷, 等. 从知识图谱到数据中台:华谱系统 [J].自动化学报, 2020, 46(10): 2045-2059.
[2] 吴信东,李娇,周鹏,等.碎片化家谱数据的融合技术[J].软件学报, 2021, 32(9): 2816-2836.
[3] 于皓,张杰,吴明辉,等.领域知识图谱快速构建和应用框架[J].智能系统学报, 2021, 16(5): 871-884.
[4] CHEN Y, SUN X Y, GONG D W, et al. Personalized search inspired fast interactive estimation of distribution algorithm and its application [J]. IEEE Transactions on Evolutionary Computation, 2017, 21(4): 588-600.
[5] ZHOU C, BAI J, SONG J, et al.ATRank: An attention-based user behavior modeling framework for recommendation [C]∥ Thirty-Second AAAI Conference on Artificial Intelligence.USA:ACM, 2018.
[6] LIU Q, REINER A H, FRIGESSI A, et al. Diverse personalized recommendations with uncertainty from implicit preference data with the Bayesian Mallows Model [J]. Knowledge-Based Systems, 2019, 186: 104960.
[7] YANG D, SONG Z, XUE L, et al. A knowledge-enhanced recommendation model with attribute-level co-attention[C]∥ Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.USA:ACM," 2020: 1909-1912.
[8] 燕彩蓉,黄颜,徐光伟,等.基于时间动态性的场感知分解机模型[J].控制与决策, 2020, 35(1): 169-173.
[9] 王永,冉珣,尹恩民,等.满足差分隐私保护的矩阵分解推荐算法[J].电子科技大学学报, 2021, 50(3): 405-413.
[10] 夏鸿斌,陆炜,刘渊.基于异构邻域聚合的协同过滤推荐算法[J].模式识别与人工智能, 2021, 34(8): 712-722.
[11] HINTON G E. Training products of experts by minimizing contrastive divergence [J]. Neural Computation, 2002,14(8):1771-1800.
[12] HARPER F M, KONSTAN J A. The movielens datasets: History and context [J]. ACM Transactions on Interactive Intelligent Systems, 2016, 5(4):1-19.
[13] LI J, WANG Y, MCAULEY J. Time interval aware self-attention for sequential recommendation[C]∥Proceedings of the 13th International Conference on Web Search and Data Mining. USA:ACM, 2020: 322-330.
[14] RICCI F, ROKACH L, SHAPIRA B. Introduction to recommender systems handbook [M]. Recommender Systems Handbook. Boston :Springer, 2011: 1-35.
[15] PARRA D, SAHEBI S. Recommender systems: Sources of knowledge and evaluation metrics [M]. Advanced Techniques in Web Intelligence-2. Berlin: Springer, 2013: 149-175.
[16] CREMONESI P, KOREN Y, TURRIN R. Performance of recommender algorithms on top-n recommendation tasks [C]∥ Proceedings of the Fourth ACM Conference on Recommender Systems. USA:ACM, 2010: 39-46.
[17] RENDLE S, FREUDENTHALER C, GANTNER Z, et al. BPR: Bayesian personalized ranking from implicit feedback [C]∥ Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. Corvallis :AUAI Press, 2009:452-461.
[18] 王晓耘, 李贤, 袁媛. 基于因子分解机和隐马尔可夫的推荐算法[J]. 计算机技术与发展, 2019, 29(6): 85-89.
[19] SALAKHUTDINOV R, MNIH A, HINTON G. Restriced Boltzmann machines for collaborative filtering [C]∥ Proceedings of the 24th International Conference on Machine Learning. Corvallis, USA:ACM, 2007: 791-798.
[20] LIANG Y, REN Z, YAO X, et al. Enhancing Gaussian estimation of distribution algorithm by exploiting evolution direction with archive [J]. IEEE Transactions on Cybernetics, 2020, 50(1):140-152.
