一种深度学习结合后处理的车道线检测方法
2024-10-31刘卫康刘昱杉刘庆华张鸿鑫








摘 要: 近年来随着深度学习技术在图像识别、图像处理等领域取得了显著的进展,使得无人驾驶技术中的环境感知成为可能.结合现有的深度学习技术研究复杂的交通场景中实时车道识别,提出了一种基于深度学习语义分割算法结合后处理的车道线检测方法.对EfficientNetV2网络进行卷积结构优化,并引入了双分支共享低级特征的信息融合结构,使其适应语义分割任务,同时,设计一种新的多尺度卷积融合模块,将该模块作为加强特征提取结构,进一步提出车道线识别网络Eff-SCNN,最后对识别结果进行后处理以检测车道线实例.实验结果表明该方法能够在不同的交通场景中正确预测车道线.
关键词: 无人驾驶;深度学习;语义分割;EfficientNetV2;车道线检测
中图分类号:TP391"" 文献标志码:A"""" 文章编号:1673-4807(2024)02-058-07
Lane detection method based on deep learning combined with post-processing
Abstract:In recent years, deep learning technology has made remarkable progress in image recognition, image processing and other fields, making it possible to perceive the environment in driverless technology. Combined with the existing deep learning technology, the corresponding research on the realization of real-time lane line recognition in complex traffic scenes is carried out, and a lane line detection method based on deep learning semantic segmentation algorithm combined with post-processing is proposed. This paper optimizes the convolutional structure of the EfficientNetV2 network, and introduces an information fusion structure with dual branches sharing low-level features to make it suitable for semantic segmentation tasks. At the same time, a new multiscale convolution fusion module is designed, which is used as an enhanced feature extraction structure, and a lane line recognition network Eff-SCNN is further proposed. Finally, the recognition results are post processed to detect lane line instances. Experimental results show that the method can correctly predict lane lines in different traffic scenarios.
Key words:driverless, deep learning, semantic segmentation, EfficientNetV2, lane detection
车道线检测是智能驾驶系统的核心技术之一,对整个系统的鲁棒性和实时性起着重要作用[1-2].目前车道线检测方法主要基于机器视觉进行检测,根据使用的技术大致可分为基于特征的检测方法[3]和基于深度学习的检测方法[4].基于特征的方法主要依赖于手工提取车道线与路面和周围环境之间的特征差异,并通过阈值化处理将车道线从图像中分割出来.然而,这些方法的鲁棒性差,对图像清晰度要求高,且容易受到外界干扰的影响[5-6].
随着深度学习在图像处理、机器视觉等领域都取得了不错的应用,越来越多的学者研究使用深度学习的方法来实现鲁棒性更好、精度更高的车道线检测.文献[7]设计了一种特殊的卷积结构,该结构使提取到的特征更具有空间连续性,可以更好的分割车道线这种细长的结构对象.
语义分割常作为视觉感知系统中重要的预处理环节,其输出结果是为像素空间的掩码图,常被智能驾驶领域用于后续感知算法的输入.随着FCN[8]等基于深度学习像的素分割技术提出与使用,使得语义分割的鲁棒性与精度得到进一步提升.文献[9]设计了一种将语义分割与线性回归相结合的网络模型,可以实现端到端检测到车道线.
基于卷积结构的语义分割模型通常采用编-解码结构,从而在上采样阶段融合多尺度特征以保留图像细节特征.
文献[10]使用多尺度图像输入的多分枝编码结构,用于车道线识别模型的设计,然而,这种方法在每个分支初始层提取到的低级特征相似,导致了计算开销增加.文献[11]提出了一种双分支共享低级特征的信息融合方法,较深的网络结构可以共享浅层网络提取到的低级特征,从而在保留全局特征的同时,在浅层空间共享编码计算,减少计算开销,实现算法的实时性.
EfficientNetV2[12]是谷歌团队提出的最新型CNN模型,具有参数利用率高、网络训练速快的特点,常被用于特征提取任务中.然而CNN在特征提取任务上常因感受野受限不利于捕获全局特征,因此研究人员会使用膨胀率(rate)不同的空洞卷积[13],来获取不同尺度的感受野.为了能够在感受野提升的同时,能更好的克服空洞卷积kernal不连续导致不能充分利用每一个像素的问题,文献[14]提出多尺度卷积模块(receptive field block,RFB),可以有效的结合大尺寸卷积和空洞卷积,增加有效的感受野尺寸.
文中对EfficientNetV2_s网络模型进行卷积结构优化,引入双分支共享低级特征的特征融合方法,提出了一种新的多尺度卷积融合模块(receptive field block pyramid,RFB-p)作为加强特征提取结构,设计出一种用于复杂交通场景下实现车道线像素识别的高效语义分割神经网络(efficient semantic segmentation convolutional neural network,Eff-SCNN),最后通过对网络输出进行后处理以划分车道线实例,实现车道线检测.
1 算法研究
1.1 改进的多尺度卷积融合模块
如图1,RFB-p模块引入残差连接和Dropout正则化,由于利用RFB-p作为加强特征提取结构,网络层次较深,因此相比原RFB模块增大了卷积核数目,以提取更丰富的全局语义信息,并使用swish函数替换relu函数对数据进行激活,降低模型由于层次加深而难以训练的影响[15].各分支首先通过点卷积整合通道间的数据,减少至原来通道的1/4,配合大尺度的一般卷积和相应膨胀系数的空洞卷积实现了感受野的增大,各分支选用空洞卷积扩张率分别为1、3、5,对应感受野范围分别为3×3、7×7、11×11,输出的特征通道数分别为原始输入特征的1/2,随后通过特征拼接融合多尺度信息,利用点卷积调整通道数目,以便与原始特征相加,点卷积起到压缩作用,点卷积后增加Dropout正则化,防止部分属性依赖,保留了更多有效的高级语义.
RFB-p采用了多尺度串并行融合操作提取表征能力更强的全局特征,其串并行操作如下:
(1) 大尺寸卷积与空洞卷积依次提取特征信息:利用膨胀率较大的空洞卷积增大理论感受野的范围,搭配大尺寸卷积充分利用感受野范围内的像素信息,以提升实际感受野.
(2) 多尺度特征并行融合:RFB-p对同一特征图在并行上进行不同尺度特征提取,并融合各分支提取到的特征.
(3) 多尺度串行融合:利用跳跃连接,将输入的特征与多尺度提取到的深层次特征进行融合.
1.2 Eff-SCNN车道线识别网络
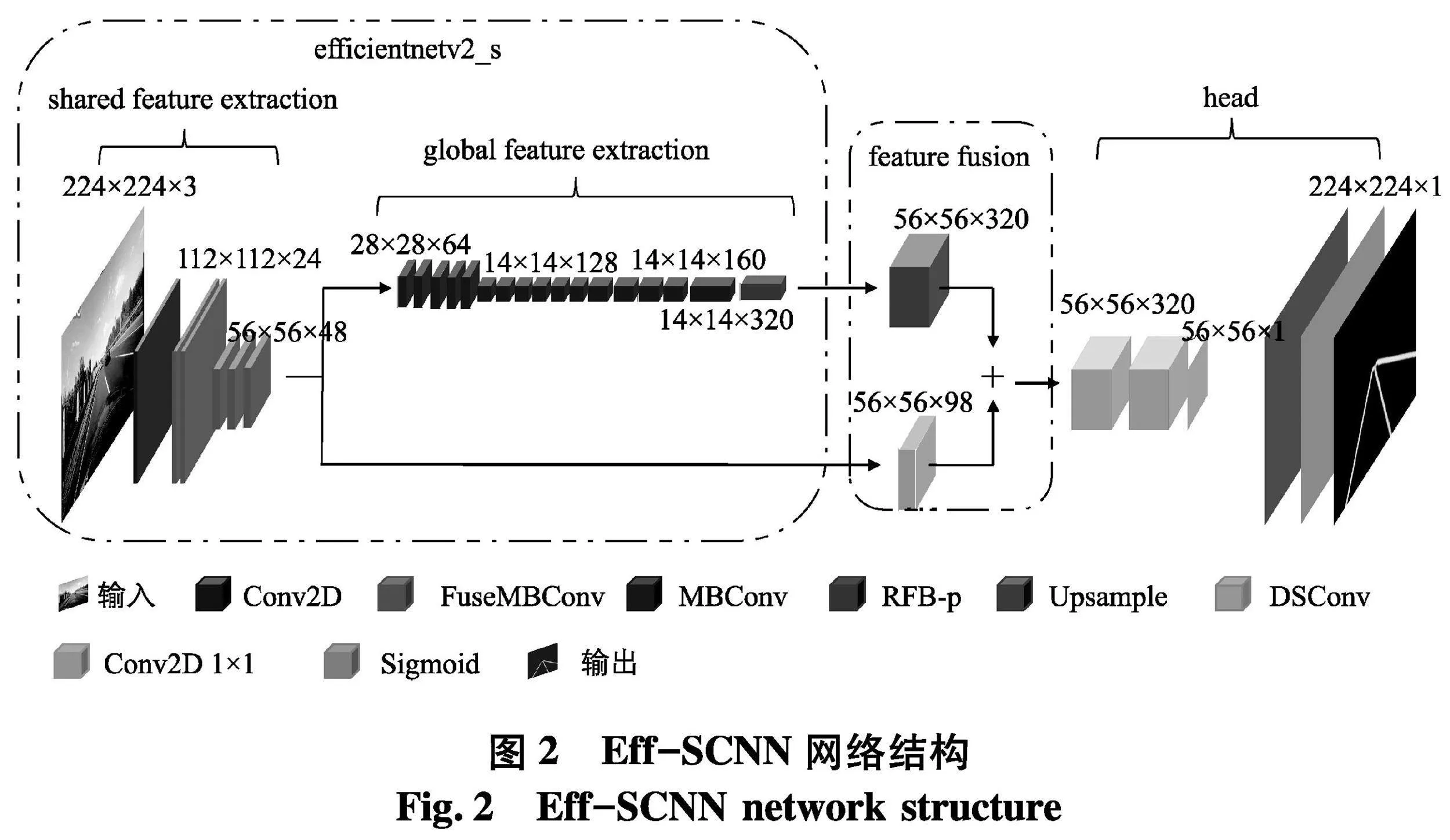
文中车道线识别网络是在轻量级注意力网络模型EfficientNetV2_s的基础上,对其主干部分进行卷积结构优化,作为特征提取网络.优化操作包括对EfficientNetV2_s第三次下采样卷积模块的网络深度和第四次下采样的channel宽度进行加深,对第四次下采样后的网络深度进行剪枝.因为车道线结构细长,在水平方向上目标较小,下采样次数过多容易丢失位置信息,所以取消EfficientNetV2_s中的第五次下采样,使用所提出的RFB-p模块作为加强特征提取结构,使其适应语义分割的任务.最后结合双分支共享低级特征的融合方法,设计出车道线识别网络Eff-SCNN.
Eff-SCNN网络结构如图2,由共享特征提取模块(shared feature extractor)、全局特征提取器(global feature extractor)、特征融合模块(feature fusion)和头部分类器(head)组成.该网络输入的是RGB三通道行车图像,除了点卷积与RFB-p模块,整个网络所使用卷积核尺寸均采用3×3大小,使用Swish函数进行激活.shared feature extractor和global feature extractor分别使用2个大的FuseMBConv(fused mobile inverted bottleneck convolution)结构快和4个大的MBConv(mobile inverted bottleneck convolution)结构块,区别于原EfficientNetV2_s所使用的3个大的FuseMBConv结构块,且仅在MBConv中使用压缩和激励网络(squeeze and excitation,SE)注意力机制,目的是在加快模型的训练速度的同时保证算法的实时性.shared feature extractor包括一次普通卷积操作、5次FuseMBConv操作,global feature extractor包括16个MBConv操作和一个RFB-p模块,feature fusion部分则采用了最简单的特征融合方式,两个分支分别通过上采样和点卷积的方式调整分辨率和通道数,经过concat操作进行信息融合,由于待预测的车道线目标极易受环境干扰,需要保留更多的高级语义信息,因此低级特征通道深度小于高级特征,区别一般通道数匹配的特征融合操作,最后将融合完成后的特征送入头部分类器,由FCN像素分割技术,通过全卷积实现对车道线像素割,并通过上采样恢复至网络输入图像大小.此外,为了进一步轻量化模型,采用双线性插值方法进行上采样.
2 网络的训练与预测
网络模型由Tensorflow2框架实现,并在cuDNN内核进行计算.硬件设备主要包括一台台式机,配置参数如下:Intel(R)Core(TM)i5-11600KF@3.90GHz处理器、16GB内存、GTX1070显卡.
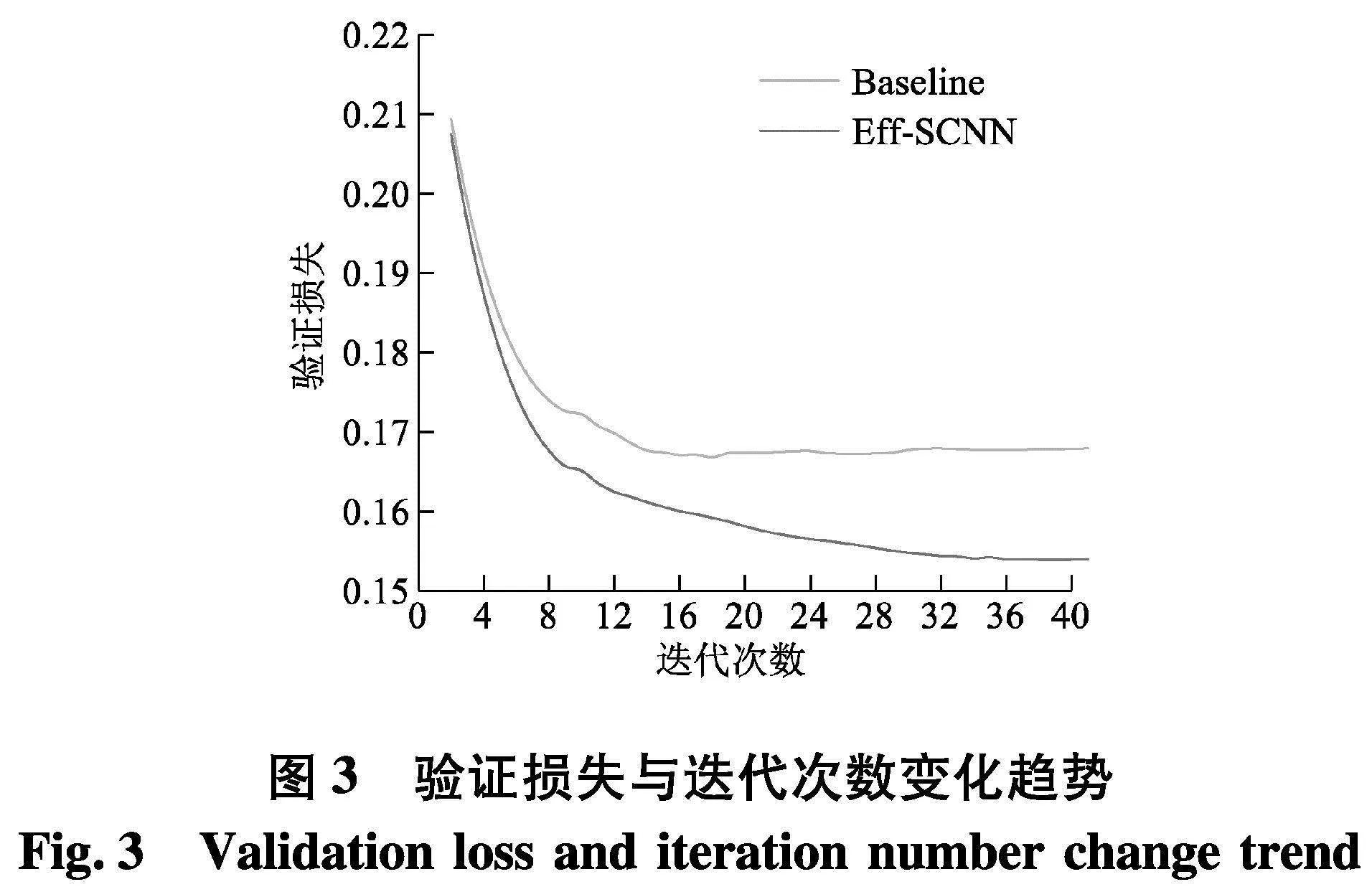
文中采用用于车道检测学术研究的大规模公开挑战数据集CULane进行训练,使用度量集合相似度的语义分割损失函数DiceCoefficientLoss,为了保证算法的实时性,模型输入大小为均为224×224,batch大小为16(实验发现,batch大小为16时,训练速度最快).Adam的初始学习率为5×10-4,每次迭代训练结束学习率衰减一次,衰减因子为0.9,共迭代训练40次.训练过程中分别记录经过曲线平滑处理后的验证损失值与迭代次数的变化趋势,曲线图如图3.
其中Baseline是EfficientNetV2_s取4次下采样作为特征提取结构的语义分割模型,既没有使用双分支共享低级特征的信息融合方法,也没有使用RFB-p模块.可以发现文中算法具备很强的特征提取能力,损失值持续下降.
模型的预测效果如图4.图4(a)为输出图片,可以看到该交通场景存在马路隔离栏的轮廓、指示箭头等类似车道线的细长结构干扰,且车道线特征并不明显.两个模型预测均没有出现误检情况,但Baseline由于缺乏强全局特征学习技术,像素间的空间信息不紧密,预测出的车道线像素区域连续性不强,反观Eff-SCNN的预测结果与实际标签基本吻合,说明文中算法在复杂交通场景中对车道线识别是可行的.
3 网络输出后处理
文中利用形态学方法划分车道线实例,提出一种快速的图像后处理方法,如图5.
图5(a)为输入图片,图5(b)为语义分割的输出.首先,根据车道线在远处消失处位置,对语义分割的输出结果进行候选区域划分,去掉远处车道线像素连结处以及车道线无关区域,为了防止候选区域存在噪声,可能影响后面的实例划分,所以还需要腐蚀处理和中值滤波处理,去除掩码空间中的孤立点,同时,考虑到有些场景识别更加困难,可能会出现预测出的像素区域不连续但又属于同一车道线的情况,因此还需要膨胀处理操作,且膨胀程度需大于腐蚀处理,使处理过后的车道线像素区域尽可能的紧密、粗壮,如图5(c).其次,由于摄像装置捕获的图像都是非鸟瞰图,每条车道线近似一条细长的矩形框,因此可以利用形态学方法寻找车道线像素最小面积轮廓,分割出车道线实例部分,如图5(d).此时矩形框相当于拟合出车道线大概的形状和方向,因此可以通过矩形的顶边中点与底边终点相连的直线来拟合车道线,处理结果如图5(e),最终检测效果如图5(f).
4 结果分析
4.1 模型间性能对比
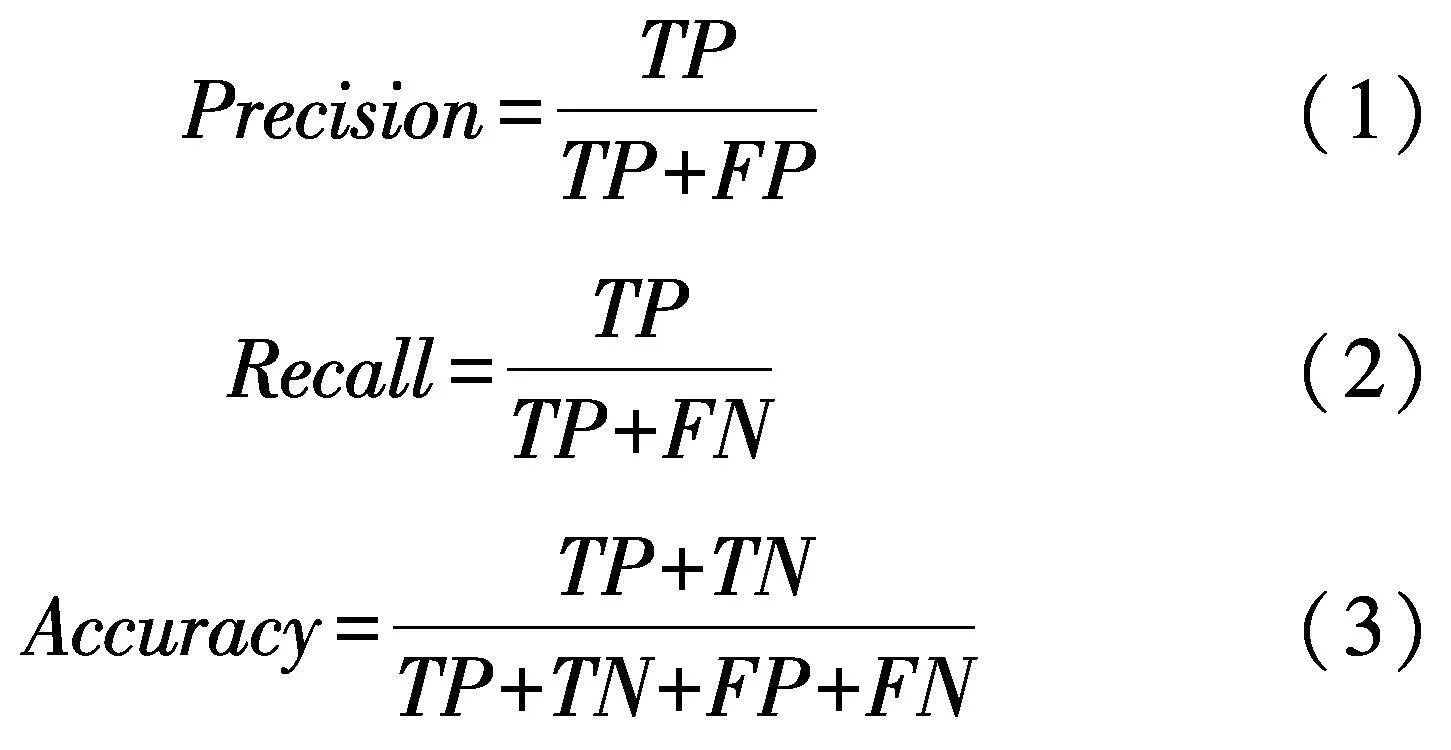
文中主要采用精确率(Precision)、召回率(Recall)和准确率(Accuracy)等严格的评价指标对算法进行评估,其中,车道线像素为正样本,背景像素为负样本.具体公式如下:
式中:T/F为True/False,表示预测结果正确与否;P/N为Positive/Negative,表示预测结果是正样本或负样本.
召回率可以很好的衡量算法找出正样本的能力,精确率可以衡量算法预测为正样本正确的能力,但都不能综合评价算法性能的好坏,因此还需要计算Precision和Recall的加权调和平均值Fmeasure作为综合评价指标,具体公式如下:
式中:β值取1.
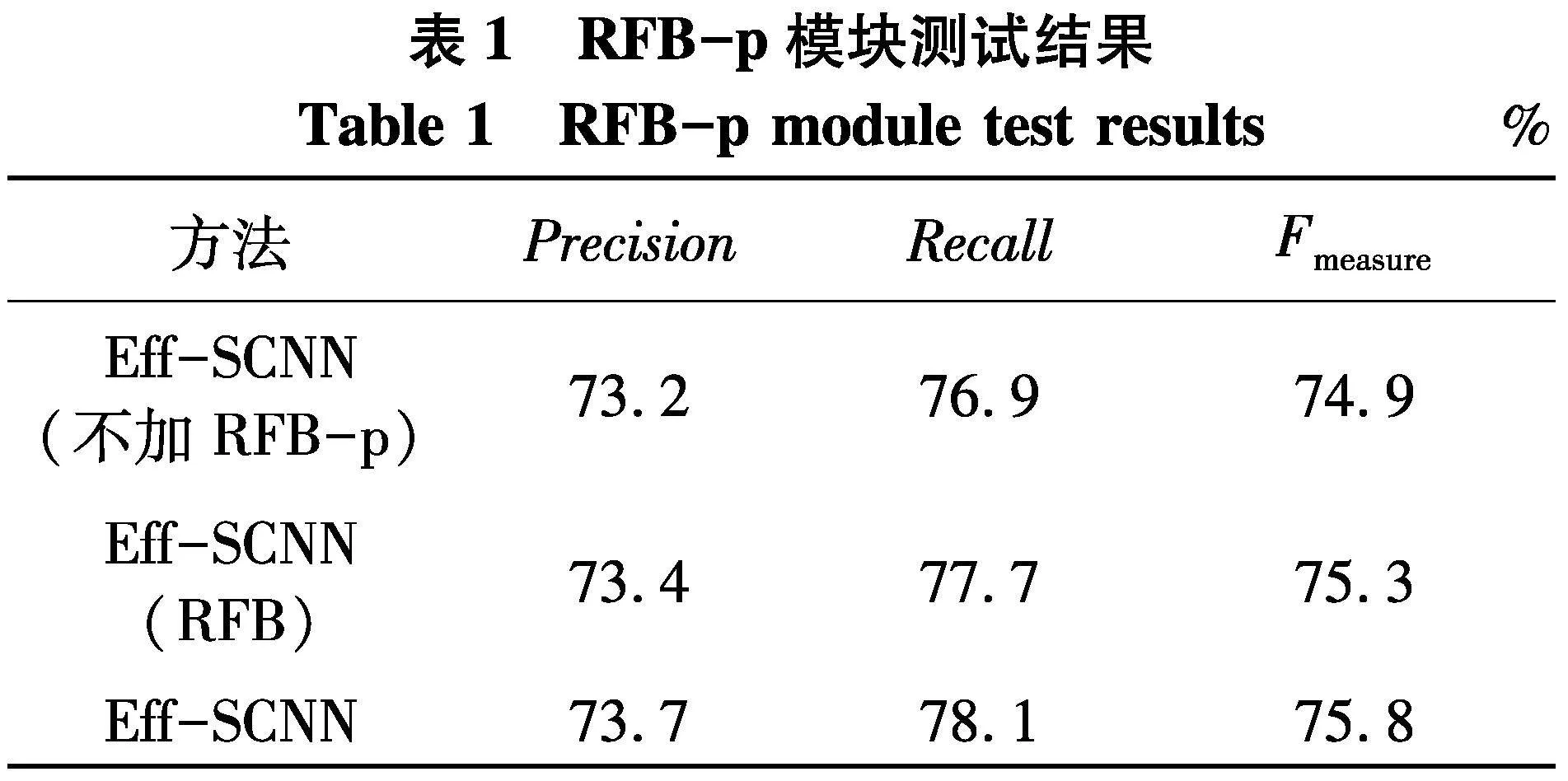
为了验证检测性能,采用场景种类更为丰富的CULane数据集进行验证.设置带有原RFB模块、RFB-p模块与不带有RFB-p模块的Eff-SCNN模型对比实验,实验结果如表1.实验结果表明提出的RFB-p模块可以较好的提升算法的性能.
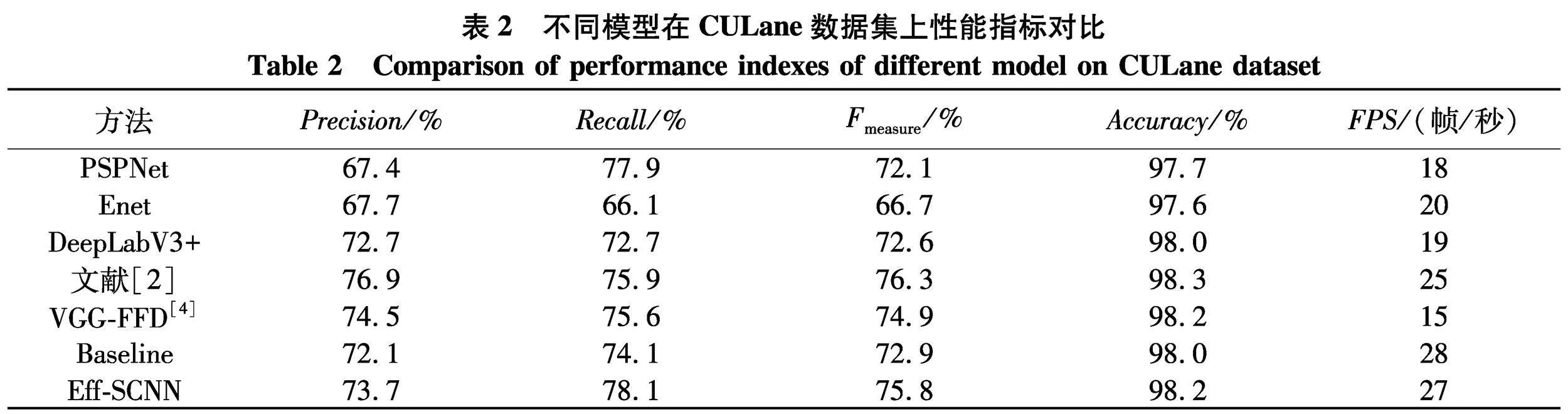
对比研究已有模型,以及与Baseline模型进行对比,实验结果如表2,其中FPS指标是在gpu设备上进行运算.文中算法和Baseline对比,帧率相对有所不足,但Fmeasure提升了约3%.与现有算法相比,文中模型在Precision、Fmeasure、Accuracy指标上较为接近,但在召回率和帧率指标上优于现有算法,其中召回率达到了78.1%.
为了验证模型在后处理方法中的可行性,在TuSimple数据集上进行语义分割,由于TuSimple图像库的车道线标签是依据场景中的车道线标志进行标注,一张图片的车道线数目有可能大于4,无车道线路段也并不会给出标签,其标注方式区别于CULane数据集,模型需要重新训练.这里车道线标签宽度为15像素,测试结果如表3,可以观察到,针对场景并不复杂、车道线特征清晰的TuSimple数据集,各模型在车道线像素分割任务中,Fmeasure指标均能达到80%以上,可以支持后处理操作.
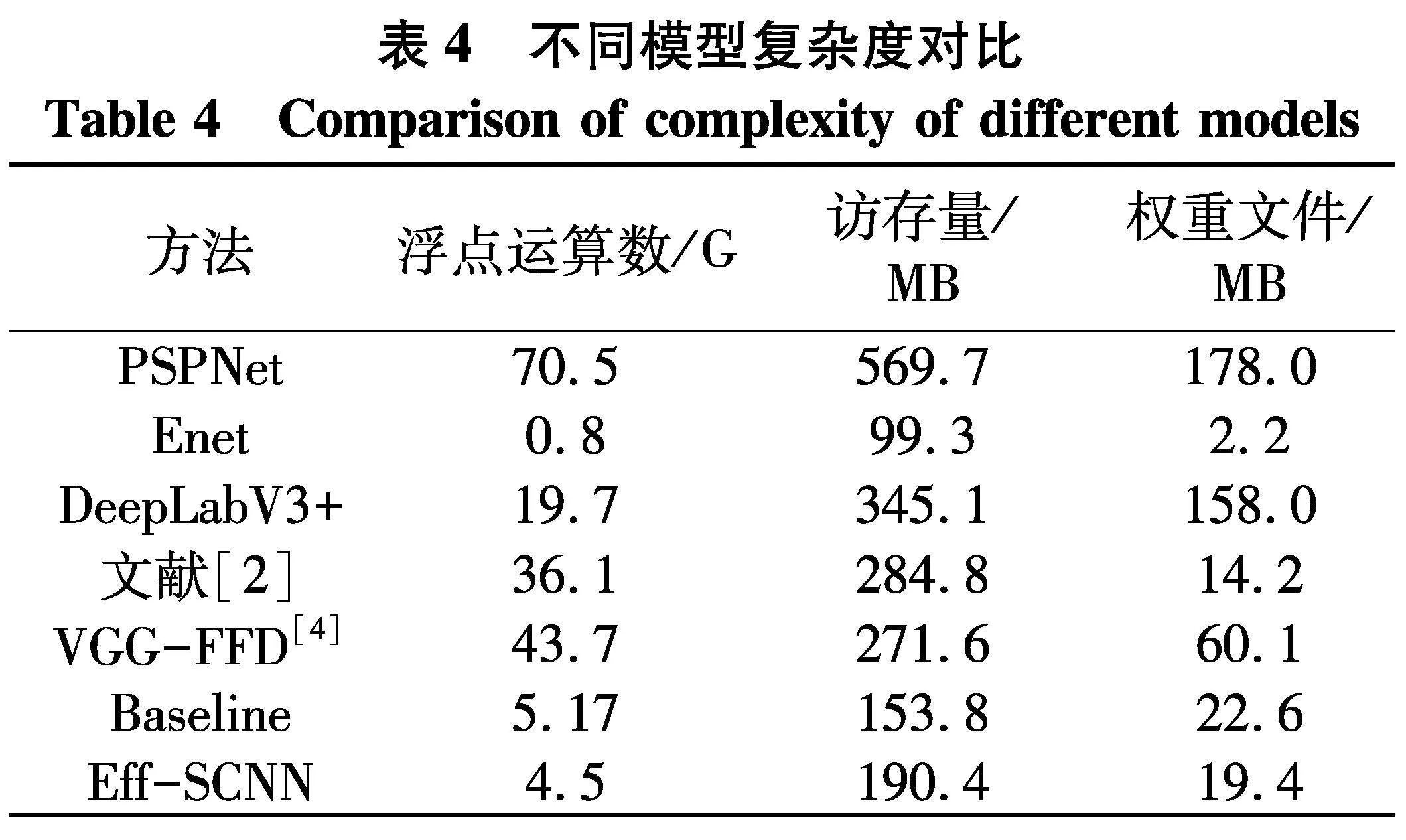
考虑到模型最终需要部署到计算资源受限的车载嵌入式设备中,更进一步,给出每个模型计算量和访存量数值,来衡量各算法时空复杂度,同时给出各模型权重文件大小,数据对比如表4.可以观察到,所提Eff-SCNN较为轻量化,权重文件大小和浮点运算数分别为19.4 MB、4.5 G,均小于Baseline,访存量为190.4 MB,可以应用到一般嵌入式设备中.
4.2 模型识别效果对比
图6(a,b)为交通堵塞的场景,由于车道线出现遮挡、消失,其特征不连续,因此模型对车道线的预测更加困难.从图6(g)可以观察到,ENet作为轻量级实时分割网络,由于结构简单,特征提取能力较弱,容易出现误检和漏检,对比图6(d、e、f)可以看出PSPNet、文献[2]、文献[4]在捕获全局上下文语义上效果稍好,车道线像素在空间上具有关联,但由于缺乏编解码器结构,对车道线细节恢复的并不好.从图6(h)可以发现Eff-SCNN对车道线的定位较为准确,证明所提出模型在交通拥堵这种车道线特征信息较少的场景中,依然可以正确预测车道线,且车道线轮廓边缘较为光滑,线条连续性更好,因此更适用于后处理操作.
更进一步,将不加RFP-p模块与加RFB-p模块算法在场景更加复杂的非结构化道路中进行预测结果对比,如图7.
图7(a)场景中无车道线标志,没有直观的车道线特征信息,且最左侧边缘有车辆停靠,环境感知要更加困难,对比图7(c、d),可以发现将RFB-p模块作为加强特征提取结构,可以有效的分析复杂道路场景,并对左侧遮掩处车道线位置进行预测,可见具有RFB-p模块的Eff-SCNN能更好的分析上下文语义,预测出的车道线像素区域在空间上具有连续性.
4.3 结合后处理的车道线检测实验验证
为了验证所提算法在不同交通场景中的鲁棒性,和结合后处理所实现的车道线检测方法的合理性,使用不同的交通场景进行验证.如图8,可以看出,所提出的网络模型均能正确预测车道线位置,证明其具有良好的抗干扰能力和泛化能力.
5 结论
(1) 基于轻量级注意力机制模型EfficientNetV2,对其结构进行优化,并设计出一种多尺度卷积融合模块RFB-p,作为加强特征提取结构,以提升全局特征提取能力,引入了双分支共享低级特征的信息融合方法,最终设计出Eff-SCNN车道线识别网络.
(2) 针对车道线像素语义分割结果,提出了一种快速的后处理方法,以划分车道线实例,实现车道线检测.
(3) 在CULane、TuSimple数据集上进行性能验证,对比已有算法,文中算法对车道线位置的预测具有良好的表现.结合后处理,该方法能够在复杂交通场景中,正确预测车道线位置,具有良好的鲁棒性与实时性.
(4) 所提出的RFB-p模块在全局特征优化上效果不错,但参数量较大,因此如何在保持识别精度的同时进一步减少模型参数,需要继续深入研究.
参考文献(References)
[1] 秦增科,郭烈,马跃,等.基于人机协同的车道保持辅助系统研究进展[J].工程科学学报,2021,43(3):355-364.
[2] HARIS M, HOU J, WANG X. Multi-scales patial convolution algorithm for laneline detection and laneoff set estimation in complex road conditions-science direct[J].Signal Processing: Image Communication,2021,99:116413.
[3] 孙宇飞.高级辅助驾驶中的车道线检测研究[D].北京:北京交通大学,2018.
[4] 高扬, 王晨, 李昭健. 基于深度学习的无人驾驶汽车车道线检测方法[J]. 科学技术与工程, 2021, 21(24): 10401-10406.
[5] SOMAWIRATAI K, UTAMININGRUM F. Road detection based on the color space and cluster connecting[C]∥2016 IEEE International Conference on Signal and Image Processing(ICSIP).Beijing, China:IEEE,2016:118-122.
[6] 刘源,周聪玲,刘永才,等.基于边缘特征点聚类的车道线检测[J].科学技术与工程,2019,19(27):247-252.
[7] PAN X, SHI J, LUO P, et al. Spatial as deep: Spatial CNN for traffic scene understanding[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. USA:AAAI,2018,32(1).
[8] LONG J, SHELHAMERE, DARRELL T. Fully convolutional networks for semantic segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE,2015: 3431-3440.
[9] NEVEN D, BRABANDERE B D, GEORGOULIS S, et al. Towards end-to-end lane detection:an instance segmentation approach[C]∥2018 IEEE Intel ligent Vehicles Symposium(IV). Changshu, China:IEEE,2018:286-291.
[10] 陈正斌,叶东毅.带语义分割的轻量化车道线检测算法[J].小型微型计算机系统,2021,42(9):1877-1883.
[11] POUDEL R P K, LIWICKI S, CIPOLLA R. Fast-SCNN: Fast semantic segmentation network[C]∥30th British Machine Vision Conference 2019. Cardiff, Britain: BMVC, 2019.
[12] TAN M, LE Q. Efficient netv2:Smaller model sand faster training[C]∥International Conference on Machine Learning .Baltimore, USA:ICML,2021:10096-10106.
[13] 李欢.基于Deeplab-LatNet网络和密度聚类的车道线检测及跟踪方法[D]. 西安:长安大学,2020.
[14] LIU S,HUANG D. Receptive field block net for accurate and fast object detection[C]∥Proceedings of the European conference on computer vision. Munich, Germany:ECCV,2018:385-400.
[15] 李振宇,邓向阳,张立民,等. 基于Swish激活函数的双通道CNN结构[J]. 计算机与数字工程,2020,48(6):1413-1416,1500.
