国家级大数据综合试验区设立对城乡收入差距的影响研究
2024-09-24侯杨未胡安



摘 要: 文章基于国家级大数据综合试验区设立的准自然实验,使用2010—2019年中国202个地级市面板数据,构建多期双重差分模型,实证分析国家级大数据综合试验区设立对城乡收入差距的影响及其作用机制。研究发现:国家级大数据综合试验区设立显著缩小了城乡收入差距,该结论经一系列稳健性检验后仍成立。机制检验表明,加快数字基础设施建设和提高城镇化水平是大数据综合试验区设立缩小城乡收入差距的两个重要机制。异质性分析发现,国家级大数据综合试验区设立缩小城乡收入差距的效应主要集中在东部地区和行政等级低的城市,而在中西部地区和行政等级高的城市未见显著影响。研究结论为推动数字经济发展助力实现共同富裕提供了经验证据。
关键词: 国家级大数据综合试验区;城乡收入差距;共同富裕;多期双重差分
中图分类号: F 49
文献标志码: A
Research on the Impact of the Establishment of NationalBig Data Comprehensive Pilot Zone on the Income Gapbetween Urban and Rural Areas
Abstract: The article is based on a quasi-natural experiment set up by the national big data comprehensive pilot zone, using panel data from 202 prefecture level cities in China from 2010 to 2019. By constructing a multi-period double difference model, the article empirically analyzes the impact and mechanism of the establishment of the national big data comprehensive pilot zone on the urban-rural income gap. Research has found that the establishment of national big data comprehensive pilot zone can significantly reduce the urban-rural income gap, and this conclusion is still valid after a series of robustness tests. The mechanism test found that accelerating the construction of digital infrastructure and improving the level of urbanization are two important mechanisms for the construction of big data comprehensive pilot zone to narrow the urban-rural income gap. The heterogeneity analysis found that the effect of narrowing the urban-rural income gap in the national big data comprehensive zone is mainly concentrated in the eastern region and low administrative level cities, while there is no significant impact in the central and western regions and high administrative level cities. The research conclusions provide empirical evidence for promoting the development of digital economy to help achieve common prosperity.
Key words: national big data comprehensive pilot zone; urban-rural income gap; common prosperity; multi-period double difference
0 引言
党的二十大报告指出:“要坚持以推动高质量发展为主题,着力推进城乡融合和区域协调发展。”国家统计局数据显示,近年来我国城乡收入差距有所缩小,但城乡协调发展水平仍有待提高。相较于城市地区的快速发展,农村地区的居民生活水平提升、医疗教育发展等依然偏慢。农村地区传统的低效率、粗放型经济发展模式已无法满足现阶段城乡协调发展的要求。随着信息技术的发展,以数字、技术等为主要驱动力的集约型发展方式成了破局关键。2015年8月,国务院印发《促进大数据发展行动纲要》,明确提出“开展区域试点,推进贵州等大数据综合试验区建设”。同年9月,首个国家级大数据综合试验区建设在贵州省启动。由此,国家级大数据综合试验区在我国多个地区相继成立。那么,旨在促进数字经济发展的大数据试验区能否缩小城乡收入差距,助力实现共同富裕,促进我国城乡协调发展呢?
现有研究主要讨论数字技术与城乡收入差距的关系,但并未得出一致结论。这些研究的观点可以分为以下几类:(1)数字技术可能扩大城乡收入差距。有学者认为,数字技术发展带来的收益分配并未实现公平共享,城乡数字基础设施和信息技术差距所导致的“数字鸿沟”可能使得信息技能不足的弱势农户陷入新的信息贫困,引起信息富有者和信息贫困者之间的分化效应,加剧社会群体间的收入不平等和贫富分化(Keniston,2004)。(2)数字技术能够缩小城乡收入差距。数字普惠金融通过降低门槛效应、缓解排除效应、发挥减贫效应缩小城乡收入差距(宋晓玲,2017)。数字金融能够缓解传统金融发展中存在的信息不对称问题,通过为农村地区提供金融服务,提高农村金融可得性,赋予弱势群体更多的发展机会,让资源和技术在城乡之间趋于均等,在农地流转、促进农户的创业行为和提高农业生产效率等方面产生积极影响(翁飞龙等,2021)。(3)数字技术与城乡收入差距之间存在非线性关系。部分研究认为数字技术与城乡收入差距之间呈现先扩大后缩小的倒U型关系。在发展初期,由于数字鸿沟的存在,数字经济发展对城市居民的增收效应要大于农村居民,从而导致城乡收入差距扩大。但随着农村数字基础设施的不断完善和农民数字化素养的逐渐提高,数字技术发展的红利惠及农村地区,农民收入显著提高,进而有助于缩小城乡收入差距(李晓钟,2022)。
综上所述,本文可能的边际贡献主要体现在两个方面。第一,本文从制度性视角补充了数字经济与城乡协调发展的相关文献。现有研究多聚焦于数字技术、数字普惠金融、数字化转型这类数字化发展新模式对城乡协调发展的影响,而对数字经济相关的制度性因素关注不足。本文以国家级大数据综合试验区为例,从政府主导的制度性干预视角补充了现有研究的不足。第二,本文提供了数字技术与城乡收入差距之间关系的可靠经验证据。以往研究采用不同测度方法评估数字技术发展水平,但限于测度方法的准确性与实证策略的有效性而未能得出一致结论。本研究借助大数据综合试验区设立这一政策冲击进行探讨,为理解数字技术对城乡收入差距的影响提供了较为可靠的经验证据。
1 政策背景与研究假设
1.1 政策背景
随着大数据技术与社会经济的不断交融,数据已成为新一轮产业变革中具有战略性意义的生产要素。为深入挖掘数据要素价值,加快建设数据强国,国务院于2015年8月颁布《促进大数据发展行动纲要》(以下简称《纲要》)。《纲要》指出,通过开展区域试点,在不断的实践中总结出一系列可推广复制的发展经验。2015年9月,贵州省大数据试验区正式获批建设。2016年,包括京津冀、广东、上海、河南、重庆、辽宁以及内蒙古在内的第二批国家级大数据综合试验区建设陆续展开。大数据综合试验区主要围绕数据资源共享、数据中心整合、数据资源应用、数据要素流通、大数据产业集聚、大数据国际合作以及大数据制度创新等七大任务开展系统性试验,旨在打通数据要素整合与流动的关键节点,实现大数据红利的共享。
1.2 研究假设
大数据综合试验区致力于推进民生领域的大数据应用,通过信息化手段有效提升社会治理效率,帮助政府部门实现科学决策,构建数字化、智能化的公共服务系统,使城乡公共服务供给更加均等化,有效缓解“城市偏向”问题(苏锦旗等,2023),最终有助于农村居民从数字技术中获益。与此同时,试验区建设推动数字新基建均衡化布局,数字基础设施能够发挥其数字属性,实现各类要素资源的有效配置与开放共享,加强城镇和农村地区的合作交流,打破空间限制,带动偏远农村地区产业发展,进而缩小城乡收入差距。因此,文章提出假设:
H1:国家大数据综合试验区设立能够缩小城乡收入差距。
诸多研究指出,造成我国城乡居民收入差距的主要原因是城乡分割的二元体制,城镇化的发展能够帮助改善收入不均等状况(万广华,2013)。目前我国城镇化率远远落后于经济发展水平,城镇化滞后是城乡收入差距持续扩大的原因,持续推进城镇化是改善城乡收入分配状况的重要抓手(陈斌开等,2013)。大数据综合试验区打造由城市延伸到农村的数据统一开放平台,建立区域间信息关联的通道,促使城乡之间的生产要素发生流动,要素报酬趋于均等化。大数据试验区设立有助于破除城乡要素双向流动的壁垒,辐射带动周边地区的大数据发展,加速地区城镇化进程,优化城镇空间格局,城镇化水平的提升会加剧城镇劳动力市场的竞争,催生出大量就业岗位,改善农村居民的收入结构,改善城乡不平等状况。由此,文章提出假设:
H2:大数据综合试验区设立可以提高当地城镇化水平,缩小城乡收入差距。
此外,大数据综合试验区设立也能够进一步完善农村地区数字基础设施建设,为农村地区发展提供机会,缩小城乡收入差距。梳理各试验区政策文本可以发现,虽然各试验区的定位和目标存在一定的差异,但各试验区都聚焦于积极完善大数据相关基础设施建设。试验区一系列配套设施的逐渐完善能够促进落后地区信息基础设施更新和进步,提高农村地区互联网等数字资源的普及和应用水平,农村居民借助互联网可以有效地降低信息搜寻成本,获取更广泛的市场交易信息,提高农产品的销售价格,进而优化生产决策。同时,试验区建设过程中通过数字基建资源下沉能创造大量非农就业岗位和农村家庭创业机会,农村剩余劳动力会向二、三产业集聚,激发农村多元就业机遇,拓宽农村居民的收入来源(陈阳,2022)。通过数字基础设施建设,城乡之间的数字接入鸿沟有所弥合,数字红利不断向农村地区扩散,实现发展成果在城乡居民间的共享,从而缩小城乡收入差距。由此,文章提出假设:
H3:大数据综合试验区设立可以加强数字基础设施建设,缩小城乡收入差距。
2 研究设计
2.1 模型设定
本文构建的多期双重差分模型如下:
GAPit=α0+β×policyit+δ×controlit+μi+γt+εit(1)
其中,i代表地级市,t代表年份。被解释变量GAP为地级市的城乡收入差距,policyit为大数据综合试验区试点政策虚拟变量。如果大数据综合试验区设立能够有效缩小城乡收入差距, β应该显著为负。controlit为一系列控制变量,μi代表城市固定效应,γt代表时间固定效应,εit为随机误差项。
2.2 变量描述
核心解释变量:大数据综合试验区设立的政策虚拟变量policy。变量根据试验区的设立时间进行赋值。若城市i在第t年设立大数据综合试验区,则 policy在t年及之后的年份中赋值为1,否则为0。
被解释变量:已有研究主要采用城乡居民收入比、泰尔指数、基尼系数等指标衡量城乡收入差距,本文参考雷卓骏等(2023)的做法,用城镇居民人均可支配收入与农村居民人均可支配收入的比值反映城乡收入差距,并在后续的稳健性检验中采用基尼系数替换该指标进行估计。
控制变量:参考以往研究,本文选取如下控制变量:(1)经济发展水平,用各地级市人均GDP的自然对数表示。(2)对外开放程度,以地区进出口总额与地区生产总值的比值衡量。(3)金融发展水平,用各地级市金融机构年末贷款余额的自然对数表示。(4)教育投入,采用教育支出占财政支出的比例来衡量。(5)财政支出水平,采用财政支出占 GDP 的比重表示。(6)产业结构,采用第三产业产值与第二产业产值的比值表示。
2.3 数据说明
文章研究样本为2010—2019年中国202个地级市。数据主要来源于《中国城市统计年鉴》、各省统计年鉴以及各地级市统计年鉴。本文剔除了数据严重缺失的样本,并对个别年份缺失值进行了线性插值处理。为排除异常值对结果的干扰,对所有连续变量进行了1%和99%的缩尾处理。变量描述性统计见表1。
3 实证分析结果
3.1 基准回归结果
为了检验大数据综合试验区设立对城乡收入差距的影响,对式(1)进行回归估计,基准回归结果如表2所示。其中,列(1)仅控制了城市固定效应和年份固定效应,列(2)则在此基础上进一步纳入了所有的控制变量。可以看出,核心解释变量policy的系数均在1%的置信水平上显著为负,说明国家级大数据综合试验区设立可以显著缩小城乡收入差距,由此本文的H1得以验证。
3.2 稳健性检验
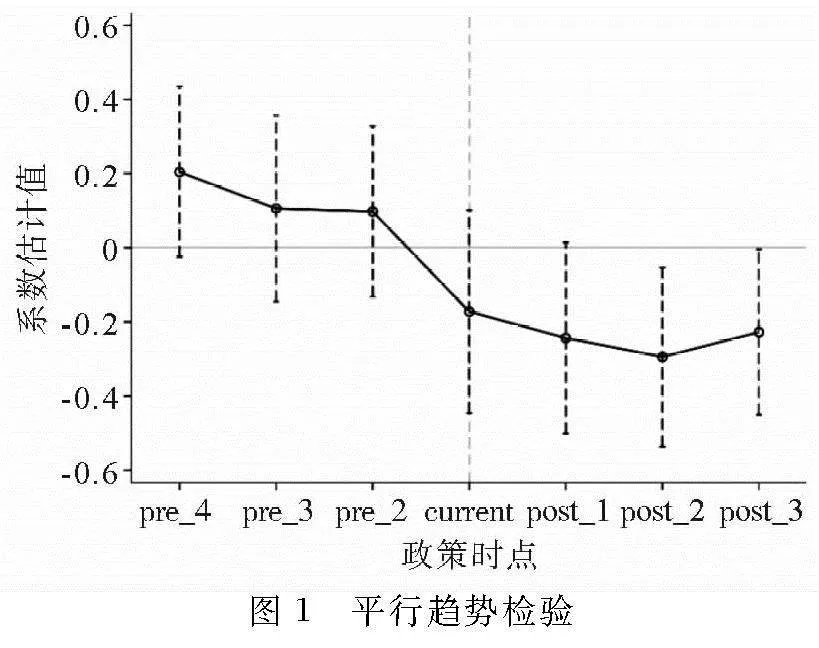
3.2.1 平行趋势检验
满足平行趋势假设是多期双重差分方法准确评估政策效应的前提,为验证大数据综合试验区设立前处理组和控制组的城乡收入差距是否存在系统性差异,本文参考Beck等(2010)的方法,设置一系列年份虚拟变量和处理组虚拟变量的交互项,并将政策实施前一期作为基期进行检验,结果如图1所示,在大数据综合试验区设立之前,核心解释变量的估计系数均不显著异于0,表明处理组和控制组的城乡收入差距在政策实施之前无显著差异,同时在国家级大数据综合试验区设立之后,城乡收入差距迅速缩小,再次验证H1。
3.2.2 安慰剂检验
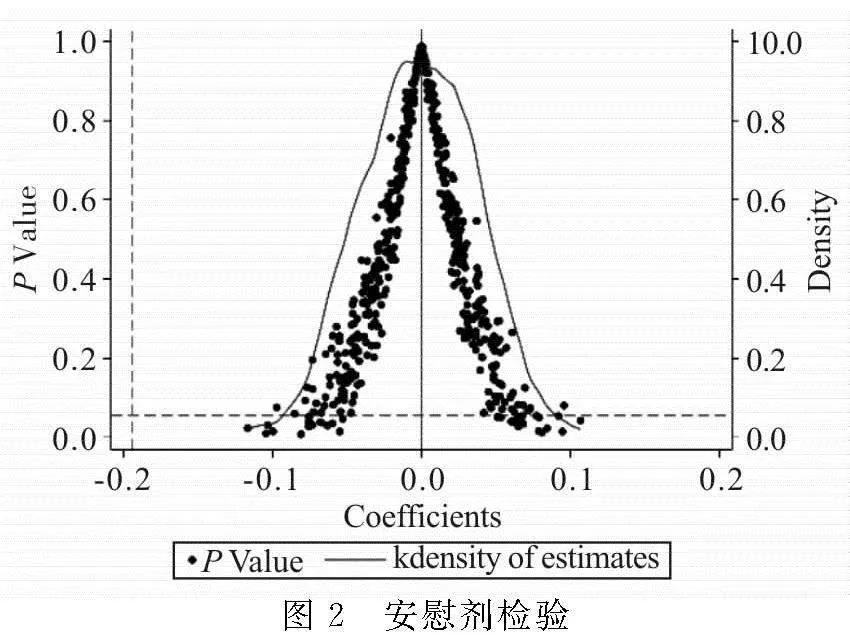
为了减少不可观测遗漏变量可能对基准回归结果的干扰,本文进一步通过构建“反事实”框架下的安慰剂检验方法进行检验。在样本数据中随机筛选与基准回归相同数量的城市作为虚假处理组,剩余未被抽到的城市为虚假控制组,将此过程重复500次,由此可以得到500个伪试点政策变量的估计系数及其对应的P值,见图2。由图2可以看出,伪试点政策变量估计系数集中分布在0附近,基本服从正态分布,同时对应P值大多大于0.1,可见不可观测变量对估计结果的影响较小,核心结论依旧稳健。
3.2.3 基于PSM-DID方法的估计
大数据综合试验区试点城市和非试点城市的初始条件可能存在较大的差异,这种系统性差异可能使得试点地区在选择上缺乏随机性,从而导致样本可比性较差。为此,本文采用倾向得分匹配法来缓解样本选择非随机导致的内生性问题。具体地,选取控制变量表征协变量,分别采用近邻匹配、核匹配、半径匹配3种方法匹配处理组和控制组样本。这种方法可以最大限度减少不同城市在初始条件上存在的系统性差异。文章基于匹配结果重新评估了大数据综合试验区建设对城乡收入差距的影响,结果如表3所示,可见无论采用哪种匹配方法,核心解释变量policy的系数依然显著为负。
3.2.4 排除同期重大政策干扰
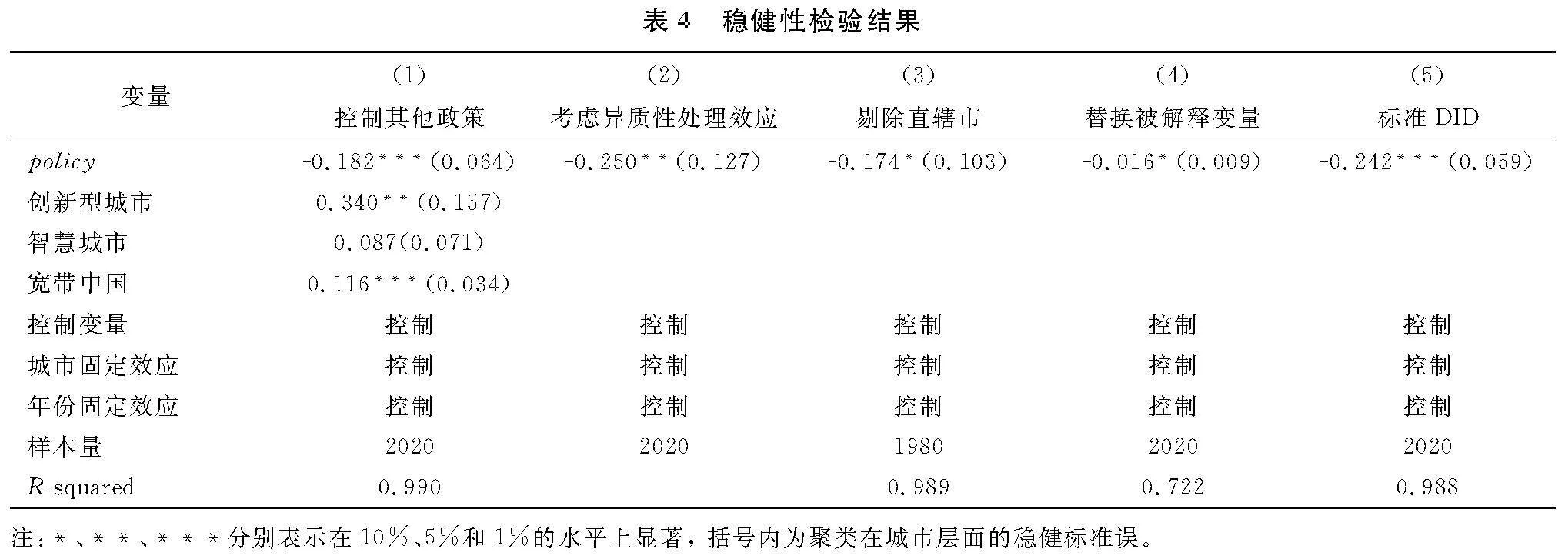
在研究时间区间内,不可避免地还存在一些可能对城乡收入差距产生潜在影响的重大政策,从而使得大数据综合试验区政策的估计效应产生高估或者低估。为了识别和排除这种相关政策导致的政策叠加效应的干扰,本文梳理了大数据试验区实施期间颁布的其他政策,重点考虑宽带中国、智慧城市、创新型城市可能对结果带来的干扰,具体做法为在基准回归中加入“宽带中国”“智慧城市”和“创新型城市”的政策虚拟变量 。表4列(1)的回归结果表明,在考虑上述政策影响后,大数据综合试验区建设对城乡收入差距的影响依然在1%水平上显著为负。
3.2.5 考虑异质性处理效应
近年来不断涌现的理论文献表明,使用多期DID模型进行政策效应评估时,处理时点不同将会使交叠DID模型的估计结果出现偏误,如将相对较早受政策处理的样本作为控制组,就会出现估计偏差(Baker,2022)。为判断异质性处理效应是否会影响本文的研究结果,本文借鉴 Callaway & Sant’Anna (2021)的方法,得到了考虑异质性处理效应的回归结果,表4列(2)结果表明系数仍显著为负,因此异质性处理效应并未对本文的回归结果产生显著影响。
3.2.6 其他稳健性检验
为了进一步增强研究结论的可靠性,本文还进行了一系列其他稳健性检验。第一,调整样本范围。鉴于直辖市在经济规模与资源禀赋上与普通地级市存在较大的差异,本文剔除样本中的直辖市数据后重新进行回归。第二,改变被解释变量测算方法,参考雷卓骏(2023)的做法,使用基尼系数衡量城乡收入差距。第三,更改计量模型设定,在基准回归中,采用多期DID方法进行回归。由于2015年仅有贵州一个试点地区,其他试验区均于2016年开始推广,本文将2016年设定为该政策的起始年份,将第一批试点城市从样本中剔除,按照标准DID模型重新进行估计。回归结果如表4列(3)至(5)所示,大数据综合试验区的估计系数均显著为负,表明核心结论依然稳健。
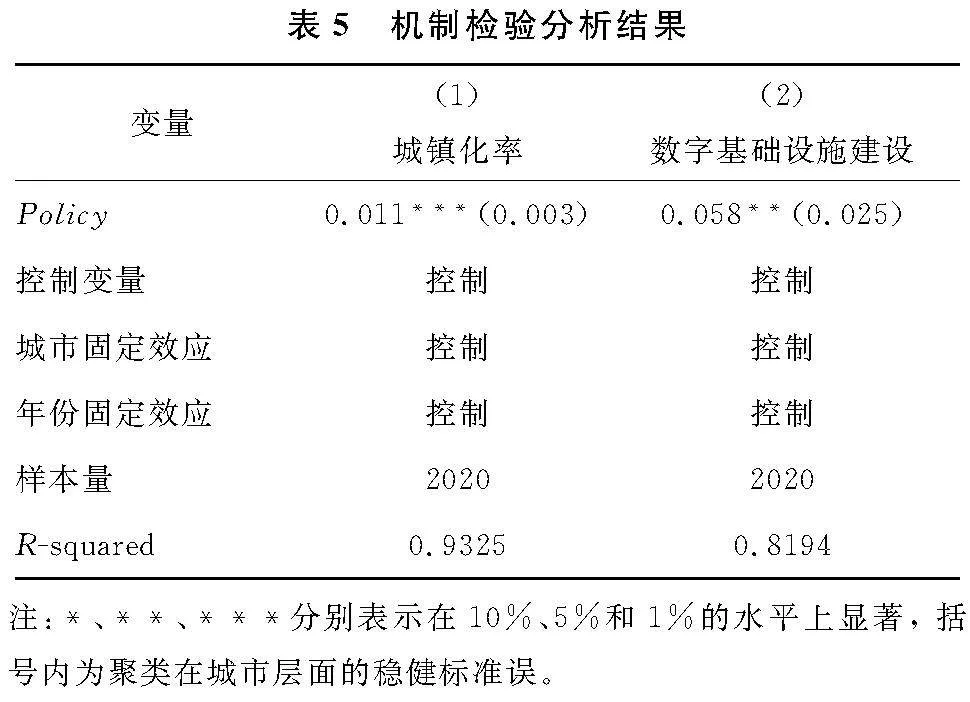
3.3 机制检验
为验证大数据综合试验区对城镇化水平的影响,本文以各地级市城镇化率表征城镇化水平。表5列(1)结果显示,核心解释变量policy的估计系数显著为正,表明大数据综合试验区设立能够显著提高试点城市的城镇化水平。大数据综合试验区设立通过引进大数据相关产业等政策吸引周边地区的剩余劳动力持续向城市迁移,人口迁入会提高地区城镇化率,大数据技术的迅速应用和普及使迁入城镇的农村劳动力有更多的机会学习新知识和新技术,在此过程中可以直接或间接地增加其收入水平,实现城乡居民的利益共享,进而缩小城乡收入差距,H2得以验证。
为验证大数据综合试验区对数字基础设施建设的影响,本文选取互联网普及率衡量数字基础设施建设水平(侯林岐等,2022)。表5列(2)的结果表明大数据综合试验区建设能够通过完善数字基础设施提高互联网普及率。在大数据战略实施期间,信息化服务从城市向农村延伸,助力农村地区突破信息困境,使得弱势农户能充分享受数字技术发展带来的红利,以此缩小城乡收入差距,H3得以验证。
3.4 异质性检验
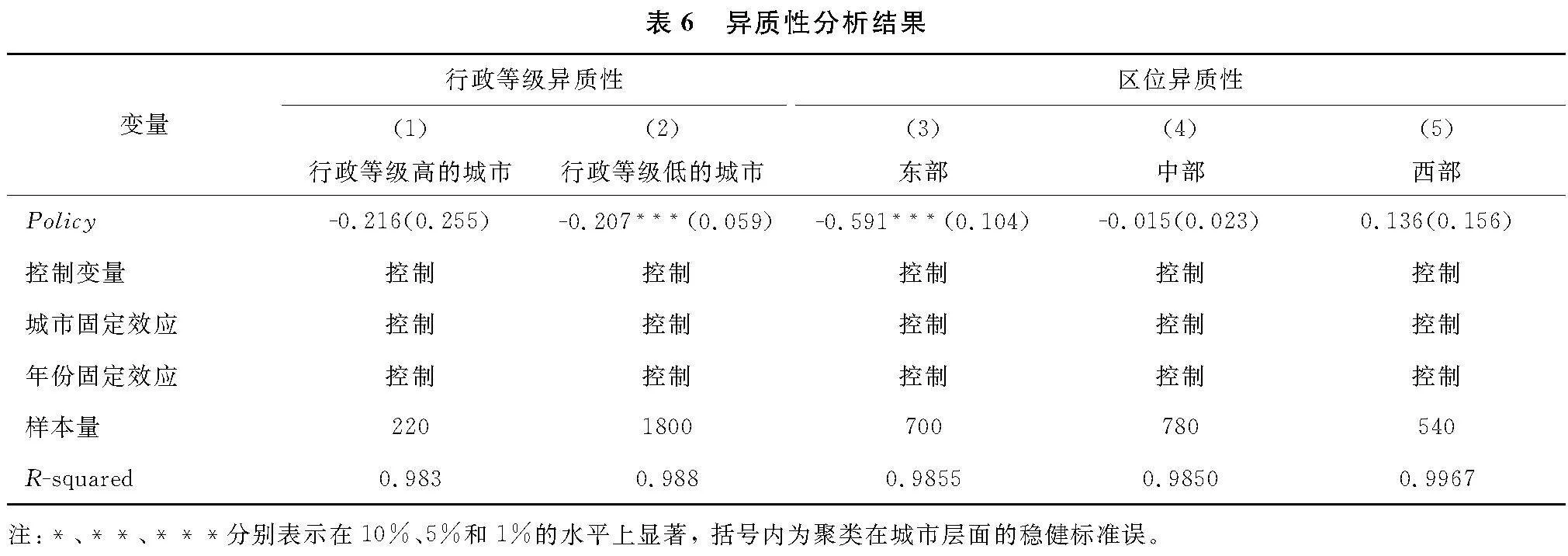
3.4.1 城市行政等级异质性
不同行政等级城市在经济管理权限、政策优惠、公共财政支持等方面存在差异,导致大数据综合试验区建设对城乡收入差距的影响可能会随着城市行政等级的不同而变化。本文将省会城市、副省级城市和直辖市界定为高等级城市,余下普通地级市则界定为低等级城市,进行分组回归分析。表6列(1)、列(2)回归结果显示,在行政等级低的城市样本中,试验区政策在1%的显著水平上缩小了城乡收入差距,而在行政等级高的城市中其政策效果不显著。其原因可能在于行政等级高的城市对大数据相关技术的应用较为充分,造成试验区建设产生的边际效用递减,大数据产业的进一步发展对城乡收入差距的缩小效应不明显。相比之下,低等级城市存在更大的发展空间,可以借助试验区政策实现跨越式发展,进而缩小城乡收入差距。
3.4.2 城市区位异质性
为进一步分析大数据综合试验区政策对城乡收入差距的影响在不同区域间是否存在异质性,本文将城市样本分为东、中、西三大区域,列(3)至列(5)的结果表明,试验区建设显著缩小了东部地区的城乡收入差距,但对中、西部城市的影响不具有统计学显著性。其原因可能在于,东部地区在数字基础设施建设、人才、技术等方面具备优势,可能会更高效地推进试验区建设的落地,进而试验区建设能够有效缩小城乡收入差距。而中西部地区数字化应用基础较为薄弱,且对互联网和信息制造等高新技术企业的吸引力也较弱,因此大数据试验区建设的红利尚未显现,对城乡收入差距影响不明显。
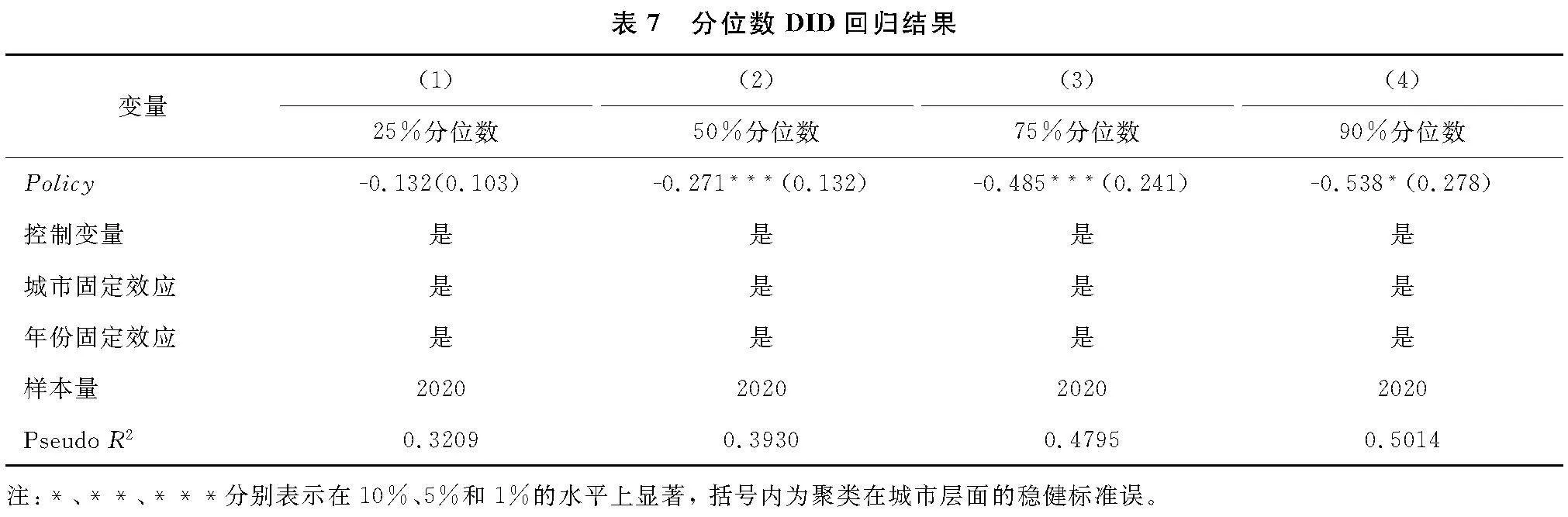
3.5 进一步分析
为考察在不同城乡收入差距水平下大数据综合试验区建设缩小城乡收入差距的作用是否存在异质性特征,表7汇报了在0.25、0.5、0.75、0.9分位点上大数据综合试验区建设对城乡居民收入差距的回归结果。列(1)结果显示政策变量的估计系数不显著,表明当城乡收入差距较小时,大数据综合试验区建设难以缩小城乡收入差距。列(2)至(3)结果显示,大数据综合试验区变量系数显著为负,且系数绝对值依次增大,说明当城乡收入差距较大时,大数据综合试验区建设能显著缩小城乡收入差距,且这一作用对城乡收入差距越大的城市作用愈发明显。以上结果表明,大数据综合试验区能够有效缩小城乡收入差距,促进城乡间协调发展。
4 结论与政策建议
本文将国家级大数据综合试验区设立视为准自然实验,基于2010—2019年地级市面板数据,采用多期双重差分的方法分析大数据综合试验区设立对城乡收入差距的影响,得到如下结论:首先,国家级大数据综合试验区设立能够显著缩小城乡收入差距,该结论在经过平行趋势检验、安慰剂检验、PSM-DID等一系列稳健性检验之后依然成立。其次,作用机制显示,大数据综合试验区建设能够通过提高城镇化水平、加强数字基础设施建设等机制缩小城乡收入差距。异质性分析显示,大数据试验区建设缩小城乡收入差距的作用主要体现在东部地区和行政等级低的城市,在中西部地区和行政等级高的城市作用不明显,且这一作用对城乡收入差距较大的地区愈发明显。
基于以上结论,本文提出如下政策建议:第一,继续推进大数据战略的实施,重点推动政策向农村地区倾斜,将试点推广到区县,通过以城带乡促进城乡融合,加快公共服务均等化进程,缩小城乡间发展差距。第二,大数据综合试验区建设应结合各试验区自身情况,因地制宜,精准施策。中西部地区要积极向东部地区学习先进经验,发挥数字经济的后发优势,同时总结和巩固东部地区的建设经验,以供其他地区借鉴参考。第三,进一步完善大数据相关基础设施建设,推动信息基础设施在农村有效覆盖,在硬件上弥合数字鸿沟。借助数字基础设施,提高农村居民的数字素养,推动开展大数据技术和农业生产的融合,让更多的居民享受到数字红利。推动数字经济发展红利惠及农村地区,将有效促进城乡协调发展,助力我国共同富裕目标的实现。
参考文献:
[1] KUMAR D,KENISTON K. IT experience in India: bridging the digital divide[M]. London: Sage Publication Ltd., 2004: 391-392.
[2] 宋晓玲. 数字普惠金融缩小城乡收入差距的实证检验[J]. 财经科学, 2017(6): 14-25.
[3] 翁飞龙,张强强,霍学喜. 互联网使用对专业苹果种植户农地转入的影响研究:基于信息搜寻、社会资本和信贷获得中介效应视角[J]. 中国土地科学, 2021, 35(4): 63-71.
[4] 李晓钟, 李俊雨. 数字经济发展对城乡收入差距的影响研究[J]. 农业技术经济, 2022(2): 77-93.
[5] 苏锦旗, 唐诗瑶, 张营营. 国家级大数据综合试验区能否促进区域经济高质量发展:基于试点区政策的准自然实验[J]. 现代财经(天津财经大学学报), 2023, 43(10): 56-73.
[6] 万广华. 城镇化与不均等: 分析方法和中国案例[J]. 经济研究, 2013, 48(5): 73-86.
[7] 陈斌开, 林毅夫. 发展战略、城市化与中国城乡收入差距[J]. 中国社会科学, 2013(4): 81-102,206.
[8] 陈阳, 王守峰, 李勋来. 网络基础设施建设对城乡收入差距的影响研究:基于“宽带中国”战略的准自然实验[J]. 技术经济, 2022, 41(1): 123-135.
[9] 雷卓骏, 黄凌云, 张宽. 市场准入管制放松与城乡收入差距[J]. 财贸经济, 2023, 44(5): 144-160.
[10] BECK T, LEVINE R, LEVKOV A. Big bad banks? The winners and losers from bank deregulation in the United States[J]. The Journal of Finance, 2010, 65(5): 1637-1667.
[11] BAKER A C, LARCKER D F, WANG C C Y. How much should we trust staggered difference-in-differences estimates?[J]. Journal of Financial Economics, 2022, 144(2): 370-395.
[12] CALLAWAY B, SANT’ANNA P H C. Difference-in-differences with multiple time periods[J]. Journal of Econometrics, 2021, 225(2): 200-230.
[13] 侯林岐, 程广斌, 王雅莉. 国家级大数据综合试验区如何赋能企业数字化转型[J]. 科技进步与对策, 2023, 40(21): 45-55.
