基于TextCNN模型的电子期刊文献推荐方法研究
2024-09-11刁羽薛红






摘 要 论文提出基于TextCNN模型的电子期刊文献推荐方法,旨在更好地精确把握文献内容的本质特征与用户文献需求的深层关系,实现电子期刊文献推荐服务的个性化和精准化。使用word2vec对文献题录信息进行向量化,使用TextCNN模型训练文献推荐模型,最后主动将符合用户需求的文献推送给科研用户。实践证明,论文设计的推荐模型能够为用户推荐电子期刊文献,效果良好。
关键词 TextCNN;文本分类;电子期刊文献推荐;行为数据
分类号 G250
DOI 10.16810/j.cnki.1672-514X.2024.07.009
Research on the Method of Electronic Literature Recommendation Based on TextCNN Model
Diao Yu, Xue Hong
Abstract This paper puts forward the method of electronic journal literature recommendation based on TextCNN model, aiming to better accurately grasp the deep relationship between the essential characteristics of literature content and the demands of users, and realize the personalization and precision of electronic journal literature recommendation service. The word2vec is used to vector quantify the literature title information, the TextCNN model is used to train the literature recommendation model, and finally the literature that meets user needs is actively pushed to scientific research users. Practice has proved that the recommendation model designed in this paper can recommend electronic journal literature for users with good results.
Keywords TextCNN. Text classification. Electronic literature recommendation. Behavior data.
0 引言
文献推荐研究一直是图书馆学、情报学中的重要内容。Kuai H等[1]指出文献推荐是缓解“信息过载”的有效途径之一,可以提高科研用户效率。电子期刊文献推荐是指将高质量的电子期刊推荐给相关领域的用户。现如今,由于基于传统机器学习的电子期刊文献推荐方法难以有效学习用户文献需求的深层特征,在应用和推广上皆存在一定的局限性[2]。如何有效利用用户访问电子资源行为特征数据、待推荐文献特征数据及两者之间的交互数据实现电子期刊文献推荐,已成为缓解当前“信息过载”时代用户“信息需求焦虑”的重要途径。因此,为了更精确地把握期刊文献内容的本质特征与用户文献需求的相关关系,本文以高校数字图书馆中的电子期刊文献资源与同一学科范畴下的用户为研究对象,以推荐用户需求期刊文献为目的, 结合基于卷积网络神经的文本分类的原理和方法,利用用户在使用电子资源时产生的行为数据进行文献推荐研究,旨在探索一条更加贴合用户需求的电子期刊文献推荐之路,并为其提供可靠的依据和发展方向。
1 研究综述
当前,国内外将深度学习应用到文献推荐的研究方兴未艾。Shen X[3]等提出了一种学习资源推荐方法,该系统利用卷积神经网络预测文本信息的隐语义。在训练过程中,使用L1范数正则化解决过拟合问题。Saraswat M等[4]通过比较图书书评之间词向量的相似性进行推荐。同时,为了克服因词语之间缺乏语义而导致推荐不理想的问题,引入了循环神经网络(RNN)。如此一来,以前神经元的信息将得到维护,同时也将书评中的词语关联起来。刘爱琴、李永清等[5]利用SOM(Self-Organizing Maps)神经网络聚类算法的无参数、精度高、客观性强的特点对高校图书馆的借阅记录进行聚类,将用户个人特征信息、用户行为数据及文献数据库等相关数据资源进行筛选整合,并结合语义检索和属性值匹配等技术来构建图书馆个性化推荐系统,在推荐精准度上有着较好的表现。电子期刊文献作为电子文献中一项重要组成部分,代表着各个研究领域的发展动向,体现了学者们最新的研究成果,是科研用户获取科研信息的重要来源。朱祥等[6]通过DPRel相关性度量算法计算作者与文献间的相关性,并在此基础上向作者推荐相关性高的文献。Pan C等[7]利用协同过滤挖掘学术论文的主题相似性并进行推荐。Tao M等[8]通过LDA对论文进行主题和词语的概率分布计算并提取关键词。同时,利用word2dec表示主题向量,利用doc2vec表示论文向量,通过计算论文与主题的相似度得到与用户输入的主题最相似的top N篇论文,最后利用PageRank算法对选项重新排序并得到最终的推荐结果。李阔[9]针对电子文献资源存在多种数据类型的情况,结合多源异构数据嵌入框架异质图神经网络(HetGNN),在用户—文献网络中生成多种类型的节点,建立用户—文献关系和文献—文献内在联系,为用户推荐其感兴趣的文献资料。刘韵毅、梁樑[10]通过自建的在线论文评级系统收集用户对基准集论文的评分,然后基于模糊联想记忆神经网络学习用户的主题偏好,并通过学习的偏好为用户推荐论文。从目前的研究成果来看,虽然将深度学习运用到电子期刊文献推荐的研究已成为学术界突破传统推荐方法局限性的重点方向,但鲜有将其理论与实践相结合的深层次研究。利用深度学习的研究成果提取用户、文献的属性特征及对两者匹配程度建模的系统研究也尚处于探索阶段。
除此之外,深度学习在学习文本内容的深层特征方面也具有显著的优势,如RNN、CNN、图神经网络、注意力机制等各种模型纷纷应用于文本分类,其中CNN在从空间序列的角度捕捉文本的关键短语上尤为出色[11]。Wu等[12]提出基于卷积神经网络、循环神经网络等深度学习的文本分类在文本情感分析、新闻分类、主题分类等方面皆有优异表现。Johnson R等[13]运用了一种词级的深度金字塔状卷积神经网络进行文本分类,并使用无监督嵌入的文本区域嵌入提高模型精准度。Youssef ElErain等[14]介绍了使用深度学习算法进行文本分类的过程和方法,并强调了深度学习在处理文本数据时的优势。Asudani等[15]探讨了词嵌入在文本表示和分析中的重要性,并阐述了使用深度学习算法来实现词嵌入的方法。鉴于此,笔者认为只要能够准确地对符合用户需求的电子期刊文献进行标注,则可将文献推荐视为匹配用户需求和不匹配用户需求的文本内容的二分类逻辑回归问题。围绕这一思想,本文通过采选用户访问电子资源校外访问系统行为数据,运用TextCNN文本分类模型构建电子期刊文献推荐模型,并主动将匹配用户需求的文献推送给科研用户,进而最大程度地促使图书馆电子资源能够在电子期刊文献推荐实际应用中发挥作用。
2 研究思路及关键技术
如何判断文献是否符合用户需求是本研究的关键之一。为此,本研究的基本思路是:首先,将符合用户需求的文献数据视为正类数据,反之则为负类数据;其次,对题录数据进行分词和向量化;第三,运用卷积神经网络进行训练,学习文献内容的深层特征与用户需求的匹配程度之间关系的模型;第四,根据该模型预测文献内容属于是否符合用户需求的类别。为挖掘用户需求与文献特性之间的关系,可根据Adomavicius G等归纳的推荐算法的形式化定义公式,表达如下[16]:
(1)
其中,c属于用户集合C,s属于项目集合S,u为效用函数,可以衡量用户需求与项目之间的匹配度,即u=C×S→R,R为全序集合。在推荐系统中,效用函数是通过评级的方式判断用户需求与文献之间的匹配度。当匹配度达到某一阈值时则可将文献划分为符合用户需求的类别。同理,文献推荐算法可以通过效用函数确定待推荐文献与用户需求的关系,即用户需求与文献内容的匹配程度。具体来说,主要涉及以下关键技术。
2.1 根据用户行为特征标注数据
用户访问电子资源校外访问系统行为数据(以下简称“行为数据”)是用户获取电子文献资源时与平台自然产生的最为客观的数据,它可以帮助推荐算法迅速挖掘出用户或文献的潜在共性特征,从而提高推荐性能[17]。该数据具体是指用户在访问电子资源过程中浏览、检索、下载等历史行为数据的集合。本文采选该数据来源的原因有二:一是笔者在前期研究成果已经实现了该数据的采集技术与方法[18],二是电子资源校外访问系统详细记录了用户的相关行为线索,如用户浏览文献URL或下载文献的题名、责任者等,这些线索有助于获取用户实际感兴趣的文献题录信息。高质量的数据标注能有效提高模型训练的质量,以下则是根据用户行为特征标注的数据分类。
2.1.1 正类数据
本研究将行为数据中记录的用户浏览、下载文献数据作为正类数据的数据源。该类数据源自本校电子资源校外访问系统的各类行为日志,并以JSON格式进行记录。日志的主要元素及其取值的含义如下:(1)元素ACTION的子元素TYPE的值,代表用户访问电子资源时的操作类型。当TYPE的值等于1时,表示用户的操作类型是浏览文献;当其值等于2时,表示用户的操作类型是检索文献;当其值等于3时,表示用户的操作类型是下载文献。(2)元素ACTION的子元素INFO的值,代表用户操作时产生的具体数据。根据操作类型的不同,与TYPE取值为1、2、3时对应的INFO的值分别代表了用户浏览文献题录信息时访问的URL、用户提交的检索词、用户下载文献的题名和责任者。(3)元素ACTION的子元素RID的值,代表用户访问的电子资源数据库ID。结合这三种数据,则可以方便地从电子资源数据库网站中抓取用户浏览、下载文献的题录数据。
2.1.2 负类数据
本研究将用户专业领域中的《中文核心期刊要目总览》收录期刊和“中文社会科学引文索引”(CSSCI)来源期刊中已经发表但未被用户浏览、下载的论文作为负类数据源。该数据可通过各电子资源平台提供的导出功能获得。
2.2 确定推荐对象
众所周知,陷入信息茧房中的个体受困于自己感兴趣的同质信息,阻碍了他们接触更多元化的信息,并在一定程度上限制了其研究视野。个性化推荐、个体特征、环境特征等是形成信息茧房的重要原因。虽然个性化电子期刊文献推荐是一种基于用户需求实现有效文献分发的推荐服务,其推荐算法也有利于扩展个体对信息接触的广度和深度[19]。但是,为减轻信息茧房的负面效应,打破其中用户与用户之间的交流屏障,选取属于同一学科范畴且用户所在专业或研究领域具有“差异化”的群体作为电子期刊文献的推荐对象,不仅有利于帮助用户突破固定的信息圈,促进不同研究领域用户之间的交流,还能帮助其拓宽研究思路,发掘新的研究方向。为此,本研究选择同一学科范畴的用户作为整体进行文献推荐。
2.3 TextCNN模型
目前,卷积神经网络(Convolutional Neural Network,CNN)广泛应用于视觉处理和自然语言处理领域,它将较小的卷积核在较大的输入特征矩阵上滑动并进行卷积运算,从而在不损失输入数据信息的前提下提取其重要特征[20]。在CNN的基础上,Kim Y提出了一种简单可靠的文本分类模型[21]。该模型由四部分组成。(1)输入层。输入向量为矩阵,其中n为文本包含的单词数量,k为词向量维度。(2)卷积层。利用h的卷积核对输入层的特征矩阵作卷积操作。(3)最大池化层。最大池化层的作用在于通过保留最大值以达到保留关键特征和降低维度的作用。(4)输出层。使用压扁后的全连接层和softmax函数对池化后的向量进行分类并输出结果。根据实际场景的不同,在Kim Y的TextCNN模型的基础上,出现了加入注意力机制、与其他神经网络模型相结合等方案改进模型。因本研究涉及的数据量较少且数据结构相对简单,故只对原始TextCNN模型进行了微调。
2.3.1 输入层
神经网络无法直接计算文本数据,因此需要使用数值表示文献题录的有效特征。目前,文本表示技术主要划分为词袋模型(Bag-of-Words,BOW)和词嵌入模型(Word Embedding)两个类别。因为BOW存在着维度灾难、无法保留词序信息及存在语义鸿沟等方面的问题[22],词嵌入模型越来越受到自然语言处理(Natural Language Processing,NLP)领域研究者的重视。如,Po-Sen Huang等提出Word Hashing方法将英文单词映射为向量。该方法基于n-gram模型,采用letter-trigram模式,统计单词三分段后的词频,再将词频转化为向量,最后通过词向量计算单词之间的相似度。该方法比one-hot模式的维度降低了四倍左右[23]。随后,Word2Vec成为了此研究方向的主流。
word2vec[24]使用CBOW(Continuous Bag-of-Words)和Skip-Gram这两种神经网络模型分别实现了基于上下文预测中心词和根据中心词预测上下文。广泛应用于NLP各类下游场景的词向量,是word2vec在完成上述预测任务训练神经网络模型时隐藏层的参数矩阵。它在确保计算效率和运算结果的精确性的同时,解决了大规模数据集中词的连续向量表示(Continuous Vector Representations)问题,同时word2vec的连续向量表示是基于分布式表示(Distributed Representation)假说,即相似词具体相似的向量表示[25]。因此,word2vec可有效克服BOW的语义鸿沟难题,使语义相近的词的词向量在向量空间上具有相近的位置。研究结果证实,通过词的word2vec词向量之间的余弦距离,可以十分准确地预测出词与词之间的相似度。比如:vector(‘Paris’)-vector(‘France’)+ vector(‘Italy’)的运算结果与vector(‘Rome’)之间具有较高的相似度;vector(‘king’)-vector(‘man’) +vector(‘woman’)的运算结果与vector(‘queen’)之间具有较高的相似度[26]。同时,相较于BOW使用的离散表示方法,word2vec使用的分布式表示将词映射到由实数构成的连续、低维和稠密的向量,克服了BOW的维度灾难问题。
2.3.2 卷积层
在本研究中,文献由摘要分词后的词条构成。由于文摘篇幅长短不一,故分词后词条的数量各不相同,而卷积神经网络要求输入的每篇文献的特征值的维度必须统一才能进行计算,因此对它们作如下处理:首先,统一每篇文献的摘要分词的数量;其次,为了更加逼真地模拟图像数据,将二维矩阵扩展为深度为1的三维矩阵。则有,设X为文献摘要向量,M为文献的单词数量,N为每个单词的word2vec词向量,;设W为卷积核,U和V为卷积核的维度,则。一般情况下,卷积神经网络使用互相关代替卷积运算,即不翻转卷积核。邱锡鹏[27]对输入的特征值进行卷积操作的互相关运算公式表达如下:
(2)
卷积运算后输出的矩阵为:。
设卷积核的数量为p,卷积运算后的特征映射可表示为:
(3)
其中,表示卷积运算,为非线性激活函数,bp为偏置。
2.3.3 池化层
目前有两种常见的池化层,即最大池化层和平均池化层。顾名思义,最大池化层的取值是子区域内神经元的最大活性值;平均池化层的取值是子区域内神经的平均活性值。因为word2vec词向量的几何意义是词在向量空间的映射,其值大小与向量是否更能代表这个词的语义没有关系,所以本研究采用平均池化层,而非最大池化层。
2.3.4 输出层
经过卷积层和池化层运算的特征值需要通过全连接层综合所有的局部信息,便于CNN通过逻辑回归进行分类。
3 实证研究
本研究以四川轻化工大学法学院研究生为研究对象,虽然他们所研究的专业领域有所不同,但同属于相同的一级学科,且研究方向的种类较少,符合本研究推荐对象确定方式。与用户需求匹配的数据是从校外访问系统中提取法学院研究生2017—2021年的行为数据,并从中提取用户的浏览文献的URL,以及下载文献的文献名和责任者。最后,根据URL等信息从电子资源网站上爬取文献的题录信息。这些文献视作与用户的需求匹配,以Du表示。此类文献的选取范围既是2017—2021年法学专业期刊文献,同时也是北大核心和CSSCI来源期刊文献。从电子资源的网站上检索出这些文献并导出题录数据,以Dr表示。
3.1 数据预处理
第一步,从Du和Dr剔除无用数据,如Du中的重复数据、无摘要的数据,Dr中的投稿指南、注释体例等;第二步,数据标注。首先,Du为用户浏览、下载的文献,符合用户需求,视为正类数据,以0标注;其次,从Dr中剔除与Du重合的数据。剩余数据为用户未浏览、下载文献,视为负类数据,以1标注;第三步,合并Du和Dr,形成新的数据集D。经过数据预处理后,D的数据分为了两个类别,类别0表示符合用户需求;类别1表示不符合用户需求。
3.2 训练word2vec词向量
第一步,对文献摘要进行分词。摘要分词的质量直接影响推荐模型的训练质量。为保障专业名词分词准确性,本研究将论文中的关键词和《清华大学开放中文词库》[28]分别作为第一和第二顺位的自定义分词词典。同时,调用《百度停用词表》《哈工大停用词表》《中文停用词表》和《四川大学机器智能实验室停用词库》,去除虚词、助词、介词等无意义的词[29]。
第二步,训练摘要的词的word2vec词向量。调用gensim.models.word2vec的word2vec类训练词向量,主要参数如下[30]。
(1)vector_size:此参数表示词向量的维数,其实质是word2vec神经网络模型隐藏层的神经元个数,本研究取值为100,训练结束后单词的词向量维度为100;
(2)windows:当前词与预测词之间间隔的词语数量,本研究取值为5;
(3)sg:模型训练算法,本研究取值为0,表示采用CBOW模式,即通过一句话的上下文内容预测目标词。
第三步,word2vec对象的save_word2vec_format
方法保存训练好的word2vec词向量模型,以备需要之时多次使用。
3.3 建立CNN模型
(1)输入特征数据。对数据集中摘要分词后的单词的数量进行统计后可知,其中75%分位的数值为72,即有75%的文献摘要单词数量少于或等于72。因此,本研究将文献摘要的单词数量在72的基础上稍微放大为100,将该数字作为每篇文献包含的单词个数。这样既确保有86.29%的文献能选取全部的摘要单词进行运算;同时,又避免了因个别文献的摘要单词数过大(单词数量超过1000的有7篇文献,最多单词数量达1606)影响计算精确度和运算效率。具体的处理办法是,当单词数量超过100时,就只选取前100个,截断其余单词;当单词数量少于100时,则用10-10这个趋于0的数值进行填充,以模拟单词的word2vec词向量。其次,为了更加逼真地模拟图像数据,使用numpy库的expand_dims方法将二维矩阵扩展为三维矩阵。最终,论文P可表示为:。其中,第一个100代表每篇论文包含的单词数量,第二个100代表每个单词的word2vec词向量维度,1代表输入数据的通道为1。
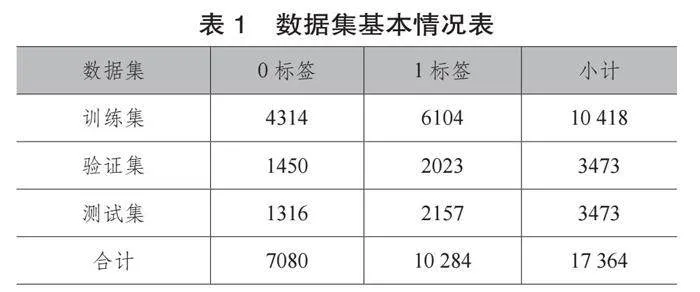
(2)拆分数据集。将数据集拆分为训练集、测试集和验证集。拆分后的数据集基本情况如表1所示。
表1 数据集基本情况表
数据集 0标签 1标签 小计
训练集 4314 6104 10 418
验证集 1450 2023 3473
测试集 1316 2157 3473
合计 7080 10 284 17 364
(3)TextCNN模型。如图1,给定一篇论文,经过由32个的卷积核进行步长为1的卷积运算,激活函数采用如下公式:
(4)
公式具有有效缓解神经网络中常见的梯度消失问题及提升神经元的激活率等优点[27]83。为防止出现训练集过拟合问题,在卷积层使用L2正则化对损失函数进行惩罚,公式[31]表达为:
(5)
经过卷积运算后,提取到32幅的特征图。卷积层后是步长为4的4×4平均池化层。经过3次卷积与池化计算后,在最后一个平均池化层之后对输出的特征图以概率为0.4进行Dropout操作,随机删除网络中的部分节点,以进一步降低过拟合的可能性。随后,将输出的32幅特征图转换为1维数据,之后再经过一个由128个神经元并采用relu的全连接层综合局部特征,最后经过softmax层计算输入的数据处于标签0(p0)或标签1(p1)的概率。具体结构如图1所示。
3.4 实证结果
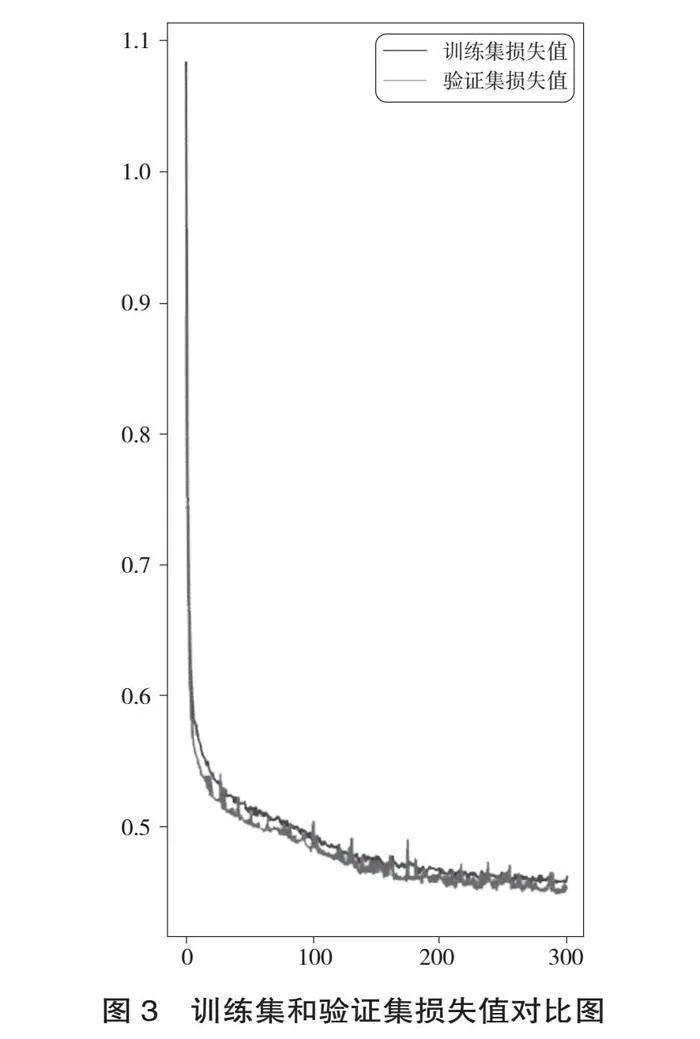
训练集数据经过300轮训练后,损失值和精度皆比较平稳且具有良好的效果。训练集和验证集的准确度、损失值对比图如图2、图3所示。
训练结果显示,训练集的精度达到79.99%,训练集的损失值为0.4753;验证集的精度达到79.9%,验证集的损失值为0.4676。使用训练成功后的模型对测试集数据进行预测,预测结果的精度达到了79.99%,损失值为0.4753,具体见表2。
表2中,TP(True Positive)表示通过训练模型预测的测试集中的正类数据(即将符合用户需求的文献标识为0)正确地识别为标签0,即有1053条数据;FN(False Negative)表示通过训练模型预测的测试集中的正类数据错误地识别为标签1,即有432条数据。
同理,FP(False Positive)表示将负类预测为正类,即将与用户需求相悖的文献(标识为1) 错误地识别为标签0,即有263条数据;TN(True Negative)表示将负类预测为负类,即将不符合用户需求的文献(标识为1)正确地识别为标签1,即有1725条数据。
综上所述,根据查准率的计算公式Precision=
TP/(TP+FP)100%,本研究在测试集上的查准率为:80.02%;根据召回率的计算公式Recall=TP/(TP+FN) *100%,本研究在测试集上的召回率为:70.91%。可见,本研究训练的模型不论是在训练集、验证集还是测试集上都具有良好的精准度,该训练模型可以应用于实际的电子期刊文献推荐。
4 结语
在“十四五”时期倡导激活数据潜能,释放数据要素价值,培育发展数字新动能的大背景下,本文立足关键技术与数据驱动服务相结合的新发展阶段,贯彻创新理念,对深度学习视域下电子期刊文献推荐方法进行深入研究,提出构建基于卷积网络神经的文献推荐模型,该方法实用性强,且能高效精准地满足用户文献需求。在研究过程中,行为数据的规范采集及合理利用均涉及到用户权益保障问题,与此同时,推荐模型的设计及超参数的取值等也需要随着实际使用效果的变化而调整,为此,笔者后续还将对以上问题作进一步的完善和思考。总之,将本研究成果运用到图书馆的电子期刊文献推荐的实际工作中,可以进一步丰富和完善文献推荐方法的理论与实践体系,同时对于形成可普及、推广的文献推荐范式具有重大意义。
参考文献:
KUAI H, YAN J, CHEN J, et al. A knowledge-driven approach for personalized literature recommendation based on deep semantic discrimination[C]//Proceedings of the International Conference on Web Intelligence. 2017: 1253-1259.
黄立威,江碧涛,吕守业,等.基于深度学习的
推荐系统研究综述[J].计算机学报,2018,41(7):
1619-1647.
SHEN X, YI B, ZHANG Z, et al. Automatic recommendation technology for learning resources with convolutional neural network[C]//2016 international symposium on educational technology (ISET). IEEE, 2016: 30-34.
SARASWAT M, SARASWAT R, BAHUGUNA R. Recommending Books Using RNN[M]//Recent Innovations in Computing. Springer, Singapore, 2022: 85-94.
刘爱琴,李永清.基于SOM神经网络的高校图书馆个性化推荐服务系统构建[J].图书馆论坛,2018,38(4):95-102.
朱祥,张云秋,惠秋悦.基于学科异构知识网络
的学术文献推荐方法研究[J].图书馆杂志,2020,
39(8):103-110.
PAN C, LI W. Research paper recommendation with topic analysis[C]//2010 International Conference On Computer Design and Applications. IEEE, 2010, 4: V4-264-V4-268.
TAO M, YANG X, GU G, et al. Paper recommend based on LDA and PageRank[C]//Artificial Intelligence and Security: 6th International Conference, ICAIS 2020, Hohhot, China, July 17-20, 2020, Proceedings, Part III 6.xOLOuovdoGaoaA/sWsapb8et9dQiztSfYsnt6hl5dok= Springer Singapore, 2020: 571-584.
李阔.电子文献资源的推荐方法研究[J].电子技术与软件工程,2019(22):170-172.
刘韵毅,梁樑.基于用户偏好的文献推荐系统[J].情报理论与实践,2007(1):61-63,25.
MINAEE S,KALCHBRENNER N, CAMBRIA E, et al. Deep learning-based text classification: a comprehensive review[J]. ACM computing surveys (CSUR), 2021, 54(3): 1-40.
WU H, LIU Y, WANG J. Review of text classification
methods on deep learning[J]. Comput Mater Contin,2020,63(3):1309-1321.
JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categoriza-tion[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), 2017: 562-570.
YOUSSEF E. Deep learning for text classification: an overview[J]. Advances in Neural Information Processing Systems (NIPS), 2021,17(2):363-389.
ASUDANI D S, NAGWANI N K, SINGH P. Impact
of word embedding models on text analytics in deep learning environment: a review[EB/OL]. [2023-03-02]. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9944441.
ADOMAVICIUS G, TUZHILIN A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions[J]. IEEE transactions on knowledge and data engineering, 2005, 17(6): 734-749.
刁羽,薛红. 基于电子资源行为数据的TF-IDF
文献推荐方法研究:以电子资源校外访问系统为例[J].图书馆杂志,2022,41(12): 45-54.
刁羽,贺意林.用户访问电子资源行为数据的获取研究:基于创文图书馆电子资源综合管理与利用系统[J].图书馆学研究,2020(3):40-47.
杨雨娇,袁勤俭.个性化推荐的隐忧:基于扎根理论的信息茧房及其前因后果探析[J].情报理论与实践,2023,46(3):117-126.
MCGREGOR M. What is a convolutional neural
network? A beginner tutorial for machine learning and deep learning [EB/OL].[2022-03-21]. https://www.freecodecamp.org/news/convolutional-neural-network-tutorial-for-beginners/.
KIM Y. Convolutional neural networks for sentence classification[J]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014(8):1746–1751.
涂铭,刘祥,刘树春.Python自然语言处理实战核心技术与算法[M].北京:机械工业出版社,2018.
HUANG P S, HE X, GAO J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013: 2333-2338.
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. arXiv preprint arXiv:1301.3781, 2013. https://arxiv.org/pdf/1301.3781.
Word2vec[EB/OL].[2022-04-23].https://code.google.com/archive/p/word2vec/.
MIKOLOV T, YIH W, ZWEIG G. Linguistic regularities in continuous space word representations
[C]//Proceedings of the 2013 conference of the north
american chapter of the association for computational
linguistics: Human language technologies, 2013: 746-751.
邱锡鹏.神经网络与深度学习[M].北京:机械工业出版社, 2020.
孙茂松, 陈新雄, 张开旭, 等.THULAC:一个高效的中文词法分析工具包[EB/OL].[2021-03-15].http://thuocl.thunlp.org/.
中文常用停用词表[EB/OL].[2021-03-13].https://
github.com/goto456/stopwords.
Word2vec embeddings[EB/OL].[2022-04-10]. https://radimrehurek.com/gensim/models/word2vec.html.
陈云霁.智能计算系统[M].北京:机械工业出版社, 2020.
