基于YOLOv8s改进的小目标检测算法
2024-07-17雷帮军余翱余快











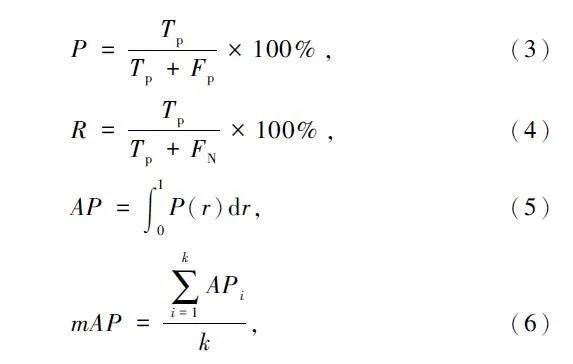
摘 要:针对目标检测任务中小目标尺寸较小、背景复杂、特征提取能力不足、漏检和误检严重等问题,提出了一种基于YOLOv8s 改进的小目标检测算法———Improvedv8s。Improvedv8s 算法重新设计了特征提取和特征融合网络,优化检测层架构,增强浅层信息和深层信息的融合,提高了小目标的感知和捕获能力;在特征提取网络中使用部分卷积(PartialConvolution,PConv) 和高效多尺度注意力(Efficient Multiscale Attention,EMA) 机制构建全新的F_ C2 f_ EMA,在降低网络参数量和计算量的同时,通过通道重塑和维度分组最大化保留小目标的特征信息;为了更好地匹配小目标的尺度,优化调整SPPCSPC 池化核的尺寸,同时引入无参注意力机制(Simpleparameterfree Attention Module,SimAM),加强复杂背景下小目标特征提取;在Neck 部分使用轻量级上采样模块———CARAFE,通过特征重组和特征扩张保留更多的细节信息;引入了全局注意力机制(Global Attention Mechanism,GAM) 通过全局上下文的关联建模,充分获取小目标的上下文信息;使用GSConv 和Effective SqueezeExcitation (EffectiveSE) 设计全新的G_E_C2 f,进一步降低参数量,降低模型的误检率和漏检率;使用WIoU 损失函数解决目标不均衡和尺度差异的问题,加快模型收敛的同时提高了回归的精度。实验结果表明,该算法在VisDrone2019 数据集上的精确度(Precision)、召回率(Recall) 和平均精度(mean Average Precision,mAP) 为58. 5% 、46. 0% 和48. 7% ,相较于原始YOLOv8s 网络分别提高了8% 、8. 5% 和9. 8% ,显著提高了模型对小目标的检测能力。在WiderPerson 和SSDD 数据集上进行模型泛化性实验验证,效果优于其他经典算法。
关键词:小目标检测;YOLOv8s;全局注意力机制;CARAFE;损失函数
中图分类号:TP391. 4 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3016(2024)04-0857-14
0 引言
目标检测是计算机视觉领域中一项重要而有挑战性的任务,旨在自动识别和定位图像或视频中的特定对象。随着计算机视觉技术的迅猛发展和深度学习算法的广泛应用,目标检测被广泛应用在人脸识别[1]、身份认证系统[2]和自动驾驶等领域。当前,以深度学习为代表的大目标检测已经取得了理想的效果,但是对微小目标检测还处于探索阶段。由于小目标尺度小、分辨率低、上下文信息不足、目标与背景之间的尺度失衡、缺乏位置的准确性,导致小目标检测非常困难,误检和漏检严重。小目标的定义目前有2 种:一种是相对尺寸大小,根据国际光学工程学会的定义,将图像中物体的尺寸小于原始图像大小0. 12% 的看作是小目标;另外一种是绝对尺寸大小,在MS COCO[3]数据集中将尺寸小于32 pixel×32 pixel 的目标视为小目标。目标检测算法中对于小目标检测的算法可以分为2 类:一类是传统的目标检测算法;另一类是基于深度学习的目标检测算法。传统目标检测算法可以分为3 个步骤,首先通过特定方法生成一系列的候选框,然后提取目标的特征信息,最后设计合适的分类器,但是这类方法特征表示能力有限、缺乏上下文信息、计算复杂度高、难以应对小目标复杂场景。基于深度学习的算法又可以细分为两阶段目标检测(Twostage)算法和一阶段目标检测(One-stage)算法。Two-stage算法生成一系列目标候选区域,通过卷积神经网络对目标区域进行特征提取以分类和定位。这类经典算法的代表有R-CNN[4]、Fast R-CNN[5]和Faster R-CNN[6],优点是精度高检测效果好,但由于计算量大、运行速度慢、实时性不高等问题难以在移动端设备上部署。One-stage 算法省略了先验框的生成,通过回归分析直接产生目标类别概率和预测框坐标信息。这类算法的代表有YOLOv1[7]、YOLOv2[8]、YOLOv3[9]、YOLOv4[10]、YOLOv5[11]、YOLOv8[12] 和SSD[13]等。由于计算量小、实时性高,应用更加广泛。
近年来在小目标检测算法的研究中,吴明杰等[14]在YOLOv5s 中加入双层路由注意力机制并采用动态目标检测头,解决小目标特征信息丢失和漏检的问题,但是计算量和参数量增加较大。贾晓芬等[15]将深度可分离卷积和ECA 注意力机制结合设计轻量化的卷积模块ECAConv,并在骨干网络中引入跳跃连接构建特征综合提取单元EC3 ,有效增加了浅层信息的提取,降低网络的参数量,但是检测精度提升不明显。余俊宇等[16]在YOLOv7 中加入集中特征金字塔和混合注意力模块ACmix,加强网络对小目标的敏感度,解决在检测过程中受遥感目标尺度差异显著和检测背景复杂带来的影响,但是存在一定的漏检和误检。张徐等[17]在YOLOv7 中添加小目标检测层,利用余弦注意力机制和后正则化方法设计了cosSTR 模块,解决尺度变化范围大以及目标特征信息过少的问题,但是对特征不明显的目标仍然存在漏检的情况。李子豪等[18]在主干网络和特征增强网络部分嵌入自适应协同注意力机制模块,同时优化检测头设计,提升对小目标区域的关注度和检测性能,但是对目标遮挡的情况还有待提高。这些方法都存在着一些不足,例如以参数量换取精度的提升、面对复杂场景小目标漏检严重、实时性有待提高等。
针对小目标像素少、分辨率低、表达能力弱、背景信息复杂、误检和漏检严重等问题,本文提出了一种基于YOLOv8s 改进的算法Improved-v8s,主要创新如下:
① 针对小目标尺度小、特征表达能力弱,重新设计了特征提取和特征融合网络,删除大目标检测层新增小目标检测层,实现浅层信息和深层信息的充分融合,加强小目标特征的表征能力,实现小目标感受野的加权。
② 在特征提取部分,使用部分卷积(PartialConvolution,PConv ) [19]和高效多尺度注意力(Efficient Multi-scale Attention,EMA)机制[20]构建了全新的F_C2 f_EMA 模块,利用PConv 的特性有效降低了网络的计算量和参数量,引入EMA 机制,通过通道重塑和维度分组最大化保留小目标的特征信息,提高检测性能。
③ 使用无参注意力机制(Simple-parameter-freeAttention Module,SimAM)[21]和SPPCSPC 构建了全新的SM_SPPCSPC 多尺度结构,针对小目标空间位置范围小,重新调整了池化核的大小,适应小目标的尺度,之后嵌入SimAM 进一步加强复杂背景下密集小目标特征提取能力,提升模型的鲁棒性。
④ 在Neck 部分,为了进一步降低模型的参数量,使用鬼影混洗卷积(GSConv)[22]和EffectiveSE(Effective Squeeze-Excitation)注意力机制[23]构建G_E_C2 f 模块,在轻量化的同时降低小目标漏检率和误检率。
1 YOLOv8s 算法
YOLOv8 是目前YOLO 系列中最新的One-stage算法,相较于其他主流目标检测算法,其速度更快、精度更高、性能更好,在众多任务上取得了SOTA 的成绩。YOLOv8 目前一共有5 个版本:YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l 和YOLOv8x,考虑到计算速度、实时性和精度,本文选择YOLOv8s 作为Baseline,在此基础上改进和创新满足小目标检测的任务。相较于YOLOv5,YOLOv8 主要有两大改进,首先检测头部分换成了当前主流的解耦头,同时从Anchor-Based 变为Anchor-Free;其次抛弃了以往IoU 匹配或者单边比例的匹配方式,而是使用了Task-Aligned Assigner 正负样本匹配方式,并引入了DFL loss。在数据增强部分借鉴了YOLOX[24]的思想,在最后10 个epoch 关闭Mosaic 数据增强,有效提升了精度。
2 Improved-v8s 总体网络介绍
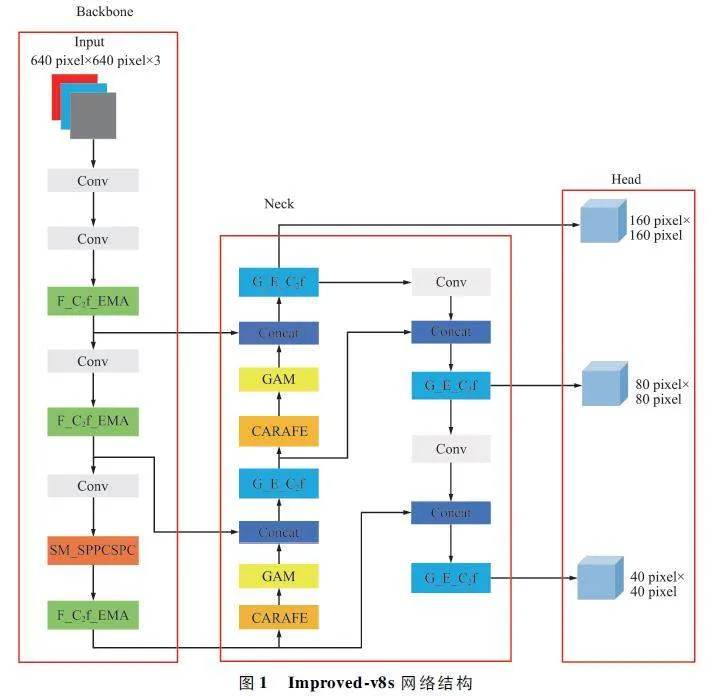
Improved-v8s 网络结构如图1 所示,由Backbone、Neck 和Head 三部分构成,其中Backbone负责特征信息的提取;Neck 增强骨干网络提取的特征,引入多尺度信息,提高模型对小目标的感知能力;Head 生成目标检测的最终输出。Improved-v8s 共有4 个创新模块和3 个现有工作改进点。首先针对小目标的特性,重新设计了特征提取和特征融合网络,丰富不同阶段信息的融合,在原始网络上删除大目标检测层,新增小目标检测层,在大幅降低参数量,保证模型轻量化的同时,显著提高了小目标检测的精度;之后在Backbone 特征提取网络使用PConv 和EMA 机制结合C2 f 设计了全新的F_C2 f_EMA 模块,在有效降低网络参数量和计算量的同时,跨空间处理短期和长期依赖,通过重塑通道和维度分组,保留更多小目标的信息。针对小目标空间位置小的特性,使用SimAM 和SPPCSPC 结构设计了多尺度结构SM_SPPCSPC,通过重新设计池化核的大小,适应小目标的空间尺度,SimAM 的引入进一步加强了复杂场景下密集小目标特征信息的提取。最后为了降低小目标的漏检和误检率,在Neck 部分使用GSConv 和EffectiveSE 注意力机制结合C2 f 精心设计了G_E_C2 f 模块。
为了进一步提升网络的性能引入了3 个现有改进点,分别是使用轻量级上采样模块CARAFE[25]替换普通上采样;之后连接全局注意力机制(GlobalAttention Mechanism,GAM)[26]增强小目标的上下文信息;使用WIoU[27]损失函数替换原始CIoU[28]损失函数,加快了模型的收敛,提高了回归速度。
实验表明,Improved-v8s 在VisDrone2019 数据集上精确度(Precision,P )和平均精度均值(meanAverage Precision,mAP)达到58. 5% 、48. 7% ,相较于YOLOv8s 提升了8% 和9. 8% ,显著提高了对小目标的检测能力,并且FPS 达到116,实时性较高。后文将重点介绍4 个创新模块。
2. 1 网络重设计增加小目标检测层
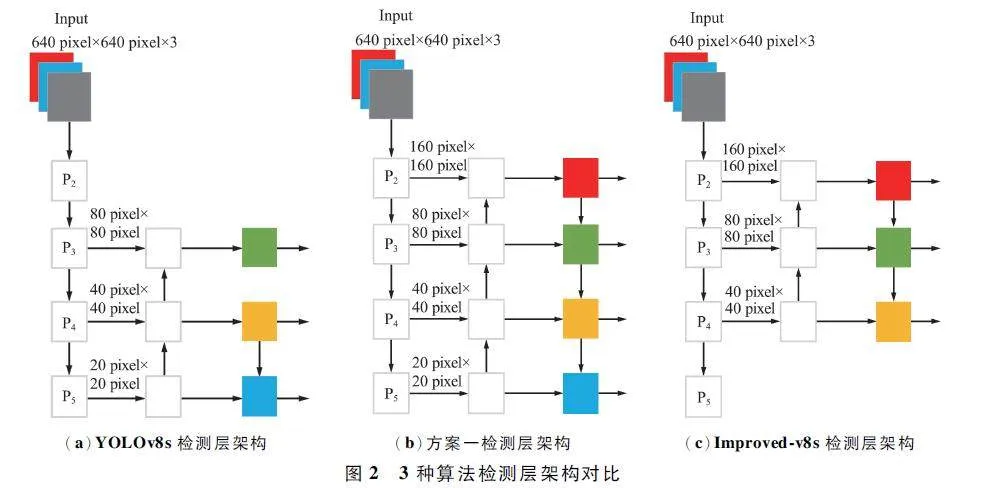
YOLOv8s 网络检测层架构如图2(a)所示,P3 、P4 、P5 检测层输出特征图的尺度分别为80 pixel×80 pixel、40 pixel×40 pixel、20 pixel×20 pixel,依次对应检测小、中、大目标。其中P3 检测层输出的特征图尺寸为80 pixel×80 pixel,每个像素点表示原始图像8 pixel×8 pixel 区域的信息,但是实际上很多小目标的尺度比8 pixel×8 pixel 更小,这就导致了小目标检测准确率不高、漏检严重。基于此,刘展威等[29]提出新增特征图尺度为160 pixel×160 pixel 的小目标检测层来解决无人机航拍图像小目标信息特征捕获不足的问题,如图2(b)所示,这种方法在性能上虽然有一定提升,但是网络的参数量大,计算开销也大。基于此,Improved-v8s 改进YOLOv8s,删除20 pixel× 20 pixel 大目标检测层,新增160 pixel ×160 pixel P2 小目标检测层,实现了微小目标的捕获,在大幅度降低参数量的同时,精度保持较高。如图2(c)所示,在特征融合阶段首先进行深层语义信息向浅层语义信息的流动,实现了40 pixel ×40 pixel、80 pixel×80 pixel、160 pixel×160 pixel 的特征融合,然后进行浅层语义信息向深层语义信息的流动,实现了160 pixel×160 pixel、80 pixel×80 pixel、40 pixel×40 pixel 的特征融合,减少了小目标特征信息的丢失。Improved-v8s 检测层架构如图2 (c)所示。
为了验证网络重新设计的合理性,将文献[29]额外添加小目标检测层的网络记为方案一并在YOLOv8 上进行实验,与Improved-v8s 进行对比。实验结果如表1 所示,从表1 可以看出,Improved-v8s,相比方案一,在参数量下降一半的情况下,漏检率降低3. 5% ,平均检测精度高出4% ,模型体积降至12. 8 MB,FPS 达到116,实时性更高;相比YOLOv8s,P、mAP 分别提高了8% 和9. 8% ,说明Improved-v8s 网络设计合理,对小目标检测效果提升明显。
2. 2 F_C2 f_EMA 模块
随着卷积神经网络层数的增加,特征图的语义信息逐渐提取和聚合,导致深层特征图中往往包含许多相似的信息。另外由于卷积层的权重共享机制,深层特征图的不同位置会共享卷积核参数,导致特征图信息的冗余。基于此,文献[19]使用PConv构建轻量化网络FasterNet 减少内存访问和开销,同时减少特征图信息的冗余,加强表征能力。针对小目标特征信息容易丢失、尺度捕获能力不强的问题,本文提出使用PConv 和EMA 模块构建Faster-EMABlock,并结合C2 f 设计了全新的F_C2 f_EMA 模块,在有效降低模型参数量和浮点计算量的同时,对全局信息进行编码以重新校准每个并行分支的权重,突出强调小目标的特征。之后通过跨维度交互进一步聚合并行分支的输出特征,跨空间处理短期和长期依赖关系,增强不同通道之间信息的融合,保留更多的上下文信息。
EMA 模块采用并行子结构减少网络深度,在不降低通道维度的情况下,为高级特征图产生更好的像素级关注。如图3 所示,将图3 中黄色部分XAvg Pool、Y Avg Pool、3×3 卷积所在的分支记为1×1分支、1×1 分支、3×3 分支。其中2 个1×1 分支位于上面,一个3 ×3 分支位于下面。EMA 使用1 ×1 分支、1×1 分支、3×3 分支3 条平行线路来提取分组特征图的注意力权重。在1×1 分支中,对x 和y 方向进行自适应全局平均池化对信道进行编码,从而对跨通道信息交互进行建模,之后在h 方向将2 个编码特征连接起来,共享1×1 的卷积。在1×1 的卷积输出2 个向量之后,使用Sigmoid 非线性激活函数拟合。之后在通过全局平均池化对1 ×1 分支中输出的全局空间信息进行编码,并且将最小分支的输出直接在信道特征的联合激活函数之前转化为相应的形状,进一步实现了跨空间信息的聚合。3 ×3 分支使用3×3 的卷积核捕获多尺度特征表示,类似1×1分支,同样使用全局平均池化编码3×3 分支输出的全局信息,经过联合激活函数转化为相应的形状。之后导出保留了整个精确空间位置信息的注意力图。最后每组输出的特征图会被计算为2 个生成空间空间注意力值的权重,经过Sigmoid 函数,突出显示像素的全局上下文。
以PConv 和EMA 构建Faster-EMA Block 替代C2 f 的Bottleneck 结构,具体如图4 所示,输入端经过PConv,PConv 在1 / 4 通道上进行卷积,剩下3 / 4的通道保持不变,之后将卷积的结果和上述未卷积的通道进行Concat 连接,减少冗余信息。紧接着经过CBS 模块,将上层输出特征图的通道数扩充为原来的2 倍,保持特征的多样性实现更低的延时。CBS 模块由1 ×1 的卷积、正则化和激活函数组成,其中1×1 卷积主要起到升、降维的作用。经过1×1的卷积降维使通道数和输入保持一样,再接入EMA模块,对全局信息编码,实现跨空间信息的聚合,建立短期和长期依赖关系,获取多尺度特征表示,增强小目标的上下文信息。F_C2 f_EMA 以Faster-EMABlock 作为Bottleneck 结构,首先通过CBS 模块将输出通道数变为2c,再经过Split 操作切分为2 份,将输出的结果串联n 个Faster-EMA Block,在降低参数量和计算量的同时获得了梯度流更加丰富的结构。之后将上述n 个串联的Faster-EMA Block 与经过切分的通道特征图Concat 得到输出为(n+2)×c 的特征图,再经过CBS 模块将通道数变为c2 。如图5 所示,以n =3 即Faster-EMA Block 使用个数3 为例,展示了设计的F_C2 f_EMA 结构。
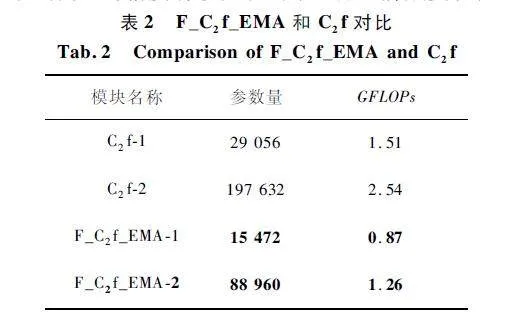
将Improved-v8s 特征提取网络中第一层和第二层F _ C2 f _ EMA 模块的参数量和计算量与原始YOLOv8s 第一层和第二层C2 f 进行对比,C2 f-1 表示第一层C2 f,后面依次类推。实验结果如表2 所示。可以看出,改进后的模块相比原C2 f,参数量和计算量大幅减少,精度有较大提升(见后面消融实验)。
2. 3 SM_SPPCSPC
为了增强对小目标区域的关注度,解决背景复杂、小目标遮挡严重的问题。使用SimAM 和SPPC-SPC 设计了SM_SPPCSPC 结构。SimAM 建立在神经科学的基础理论上,类似于人脑中的神经元传递信息一样,SimAM 为每一个神经元赋予了三维注意力机制权重,表示小目标关键特征信息的重要性,同时将复杂背景区域和小目标区域进行像素划分,增强复杂背景小目标密集区域的敏感度。针对小目标空间位置小、对周边信息感知不强的问题,将SPPCSPC 中池化核大小由(5,9,13)优化调整为(5,7,9),匹配小目标的感受野,更好地感知目标周围的局部细节信息,丰富多尺度融合的信息。
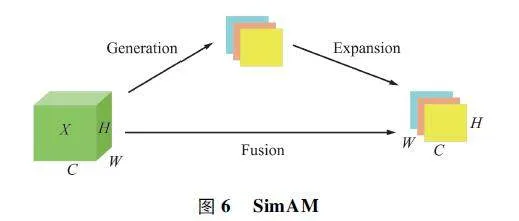
SimAM 如图6 所示。C 代表输入特征图的通道信号与信息处理数,H 代表高度,W 代表宽度。SimAM 通过神经元感知生成三维注意力机制权重,更加精确地提取小目标特征。
SM_SPPCSPC 结构如图7 所示,首先输入特征图经过SimAM,对小目标关键特征赋予三维权重,将复杂背景区域和小目标区域进行像素划分。之后经过5×5、7×7、9×9 三个不同尺寸大小的池化核,在不同空间尺度上进行特征提取,进一步捕获小目标特征信息,实现多尺度感知。在多尺度拼接之后使用PConv 进行通道调整,减少浮点运算量。再和捷径分支进行Concat 融合,丰富特征表示。最后的SimAM 进一步关注密集小目标区域,弱化复杂背景的影响,提升模型的鲁棒性。
2. 4 G_E_C2 f 模块
GSConv 是Li 等[22]提出的一种新型卷积方式,是由标准卷积、深度可分离卷积和随机排列组成的混洗卷积。虽然深度可分离卷积可以有效降低网络的参数量,但是会带来通道间特征信息的丢失,而GSConv 则在减少参数量的同时,最大化保留特征图之间信息的连接,增强小目标信息的提取。基于此,在Neck 部分使用GSConv 和EffectiveSE 注意力机制,结合C2 f,设计了全新的G_E_C2 f,在轻量化网络的同时,精确地对特征图通道之间的依赖性进行建模,增强特征表示,有效减少小目标漏检率和误检率,进一步提升了网络总体的检测性能。
EffectiveSE 注意力机制如图8 所示,输入特征图在h 和w 方向上经过全局平均池化和全连接层,保留通道之间的信息,再经过Sigmoid 激活函数(符号表示为σ),生成通道注意特征权重,作用于输出特征图,使小目标特征信息更加多样化。EffectiveSE注意力机制只使用一个全连接层就巧妙解决了SE注意力机制由于采用2 个全连接层时先降维后升维带来的通道信息丢失问题。EffectiveSE 注意力机制用公式表达如下,其中Xdiv 表示输入特征图,Favg 表示经过全局平均池化,Wc 表示经过全连接层,σ 表示激活函数,AeSE 表示通道注意力权重。
AeSE(Xdiv ) = σ(Wc(Favg(Xdiv ))), (1)
Xrefine = AeSE(Xdiv )"ⓧXdiv 。(2)
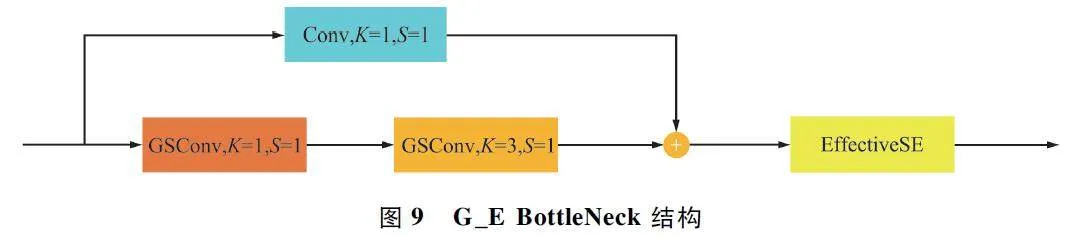
设计的G_E BottleNeck 结构如图9 所示,首先下分支进行2 次GSConv,降低网络的参数量,最大化保留通道之间的特征信息;之后与上分支的卷积进行通道上的拼接,保证通道的正确性;最后经过EffectiveSE 注意力机制,进一步保留强化小目标的纹理细节信息。
设计的全新的G_E_C2 f 结构如图10 所示,用上述G_E BottleNeck 替换C2 f 中的BottleNeck 结构,通过融合不同阶段的特征信息,丰富梯度流表示,提升网络学习之间的多样性。由于GSConv 和EffectiveSE 注意力机制的引入,网络参数量减少,特征信息进一步保留,误检和漏检减少,更加适应多样化的小目标场景。
3 实验结果与分析
3. 1 实验环境。
本文实验环境为:NVIDIA GeForce RTX3090,显存大小为24 GB,Ubuntu 20. 04 操作系统,使用的编程语言为Python3. 8,CUDA 为11. 3,YOLOv8s 依赖库ultralytics 版本为8. 0. 157,初始学习率为0. 01,预热轮数为3,在最后10 轮关闭数据增强,早停设置为50。
3. 2 数据集介绍
为了保证实验数据的合理性,本文共选择了3 个具有代表性的公开数据集进行实验,分别为VisDrone2019、WiderPerson 和SSDD 数据集。Vis-Drone2019 为无人机航拍小目标数据集,小目标居多、背景复杂;WiderPerson 数据集是密集行人数据集,遮挡严重、目标密集;SSDD 舰船数据集中几乎都为小目标,尺度小、挑战性大。VisDrone2019 作为本次实验的主要数据集,在其上做了非常详细的对比实验和消融实验。为了验证模型的泛化性和普适性,在WiderPerson 和SSDD 数据集上进行实验验证。
3. 2. 1 VisDrone2019 数据集
VisDrone2019 数据集是天津大学机器学习与数据挖掘实验室收集并发布的,一共8 629 幅图片。其中,6 471 幅图片作为训练集,548 幅图片作为验证集,1 610 幅图片作为测试集。该数据集共包括日常场景的10 个类别:行人、人、自行车、汽车、面包车、卡车、三轮车、遮阳棚三轮车、巴士和摩托车。该数据集中,类别比例不均衡,并且图片中大多是以小目标的形式存在,给检测带来了极大的困难。
3. 2. 2 WiderPerson 数据集
WiderPerson 数据集为野外行人检测数据集,行人遮挡严重、目标密集,给检测带来了一定的挑战。由于部分图片不带标注,经过合理处理之后得到12 482 幅图片,其中7 290 幅图片作为训练集,810 幅图片作为验证集,4 282 幅图片作为测试集。
3. 2. 3 SSDD 数据集
SSDD 数据集由中国人民解放军海军航空大学发布,数据集一共包含1 160 幅SAR 图像,数据集只有一个类别即舰船,以微小和极小目标为主,检测较为困难,极易出现漏检的情况。按照8 ∶ 1 ∶ 1 的比例划分数据集、训练集与测试集,其中928 幅图片作为训练集,116 幅图片作为验证集,116 幅图片作为测试集。
3. 3 指标参数介绍
本文使用P、召回率(Recall,R)、mAP、模型体积(单位MB)和FPS 作为模型的评价指标。其中P、R 和mAP 的计算如下:
式中:Tp 表示真正例即预测正确,Fp 表示假正例即将不是小目标的预测为小目标,FN 表示假负例即将小目标预测为其他的类别,AP 表示单个类别的准确率,mAP 表示对PR 曲线下的面积进行积分得到的结果,是所有类别准确率的均值;k 表示类别数。
3. 4 消融实验
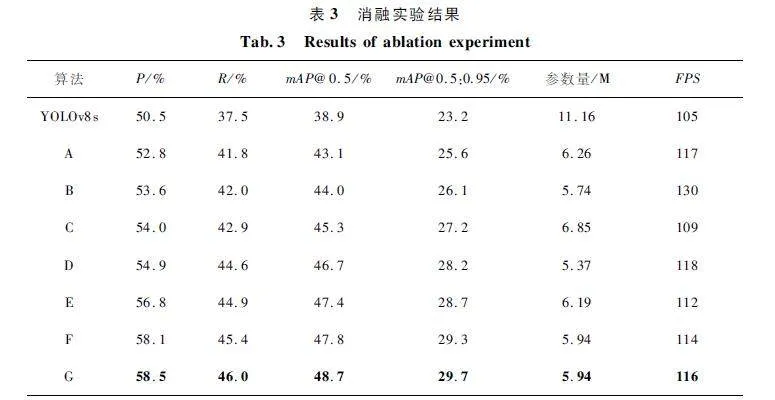
为了验证本文提出的算法对小目标检测性能提升明显,在VisDrone2019 上进行消融实验。由于Improved-v8s 网络架构与YOLOv8s 整体差异较大,将Improved-v8s 中添加的所有模块删除得到的基线网络记为A,在A 上进行消融实验验证。在A上依次加入F_C2 f_EMA、SM_SPPCSPC、G_E_C2 f、GAM、CARAFE、WIoU,将得到的网络依次记为B、C、D、E、F、G,实验结果如表3 所示。从表3 可以看出,重新设计的网络在参数量下降43. 9% 的情况下P、R、mAP @ 0. 5 相较YOLOv8s 分别提升了2. 3% 、4. 3% 、4. 2% ,FPS 提升了12,说明删除大目标检测层加入小目标检测层,大幅降低了模型的参数量,加强了模型对小目标的捕获能力,加入F_C2 f_EMA 之后,由于PConv 卷积的特性,网络参数量进一步降低,FPS 提升了11. 1% ,之后通过通道重塑和维度分组最大化保留小目标的特征信息,P 和mAP 有一定提升,经过SM _SPPCSPC 多尺度结构之后,感受野和小目标更加匹配,同时SimAM 进一步强化了小目标复杂背景特征信息的提取,P 和mAP 提升明显,由于多尺度结构复杂,参数量小幅上升,G_E_C2 f 模块精确地对特征图通道之间的依赖性进行建模,增强特征表示,大大降低了漏检率,mAP 提升幅度较大。GAM 通过全局建模,保留小目标信息,精度进一步提升。之后通过轻量级上采样CARAFE,利于细节特征重建,进一步提高检测的准确性。最后通过WIoU解决正负样本分配不均的问题,加快模型收敛速度。综上,Improved-v8s 相较于YOLOv8s 在P、R、mAP@ 0. 5% 、mAP@ 0. 5:0. 95、FPS 上分别提升了8% 、8. 5% 、9. 8% 、6. 5% 、10. 47% ,可以看到改进后的算法在大幅降低参数量的同时,网络总体性能有较大提升,对小目标检测效果提升显著。
3. 5 3 个数据集实验结果与分析
3. 5. 1 VisDrone 上对比实验结果及分析
为了验证本文提出的算法在小目标检测上的优越性,在VisDrone2019 上将本文算法与当前先进的小目标检测算法进行对比,实验结果如表4 所示。对比其他优秀的小目标检测算法,Improvedv8s 算法在行人、人、自行车、汽车、面包车、卡车、三轮车、遮阳棚三轮车、巴士和摩托车这10 个类别上均取得了最佳的检测性能,精度均值分别为57. 3% 、46. 5% 、21. 4% 、85. 9% 、53. 1% 、43. 9% 、35. 4% 、20. 8% 、65. 1% 、57. 4% 。其中小目标类别行人、人、自行车、三轮车、遮阳棚三轮车相较YOLOv8s 提高了15. 1% 、14% 、10. 4% 、8. 4% 、4. 8% ;目标类别汽车、面包车、摩托车相较YOLOv8s 提高了6. 1% 、7. 7% 、12. 7% ,大目标类别卡车、巴士相较YOLOv8s 提高了8. 1% 、10. 3% 。以上实验结果说明Improvedv8s 在显著提高小目标检测精度的同时,对中、大目标的检测性能依然做出了较大的提升,兼顾了三者之间的平衡。相较于次优的YOLOv8m,Improved-v8s 的mAP 值高出5. 5% 。对比较新的文献算法1、2、3,Improved-v8s 的mAP 值比它们高出10% 左右,说明了Improved-v8s 算法优秀的检测性能。归因于本文算法重新设计了特征提取和特征融合模块,加强了小目标特征信息的提取和保留,再加上精心设计的F_C2 f_EMA、SM_SPPCSPC 等模块,进一步加强了应对复杂背景的检测能力,提升检测精确度的同时大大降低了漏检率,使得本文算法在应对小目标检测具有极大的优势的同时,对中、大目标检测效果提升明显,具有较好的鲁棒性。
为了验证本文算法在实际场景中的检测效果,选取了VisDrone2019 测试集中难度较大的图片进行可视化,检测效果对比如图11 所示,左侧为YOLOv8s 算法,右侧为Improved-v8s 算法,从第一行、第三行、第四行可以看出,本文算法在航拍多尺度小目标、夜间光照复杂场景、夜间密集人群场景下,能够检测出更远和更小的小目标,大大降低了漏检率,提升了模型在复杂场景下的抗干扰能力和提取特征的能力。第五行在海岸高空小目标场景下,YOLOv8s 由于对小目标尺度不敏感出现了误检的情况,而Improved-v8s 不仅没有误检,还把更多远距离极小目标精准检测出来。从第二行可以看出,对于较大的目标检测,Improved-v8s 误检和漏检的情况非常少,总体检测精度较高。以上结果表明,经过改进后的算法Improved-v8 在面对复杂场景、极小目标、密集人群和大目标检测等场景下,表现出了优越的性能,模型的精准率显著提升,误检和漏检率大大降低。
3. 5. 2 模型泛化性实验对比验证
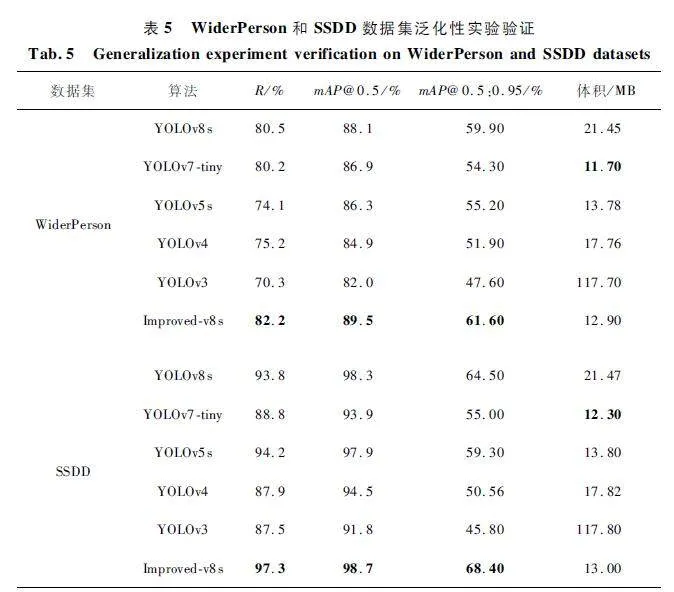
为了验证本文算法在其他小目标数据集上面检测效果显著、泛化性好。在WiderPerson 和SSDD 数据集上面进行实验,并与其他主流的经典算法进行对比,结果如表5 所示。从表5 可以看出,在WiderPerson 数据集上,Improved-v8s 在R、mAP@ 0. 5、mAP @ 0. 5:0. 95 上较YOLOv8s 提高了1. 7% 、1. 4% 、1. 7% ,平均检测精度提高,漏检率降低,相比YOLOv7-tiny、YOLOv5s 在mAP@ 0. 5上分别提高了2. 6% 、3. 2% 。在SSDD 数据集上,Improved-v8s 在R、mAP@ 0. 5、mAP@ 0. 5:0. 95 上比YOLOv8s 提高了3. 5% 、0. 4% 、3. 9% ,相比YOLOv7-tiny、YOLOv5s 在mAP @ 0. 5 上分别提高了4. 8% 、0. 8% 。综上,Improved-v8 算法在其他小目标数据集上面表现优异,精度高、漏检率低、模型尺寸小,具有通用性。
选取WiderPerson 和SSDD 测试集中挑战性较大的图片进行可视化效果对比验证,如图12 所示,左边为YOLOv8s 算法,右边为Improved-v8s 算法。从第一行可以看出,在WiderPerson 数据集上,Improved-v8s 算法在远距离微小目标场景下,检测出了很多YOLOv8s 算法漏检的目标;从第二行可以看出,在SSDD 数据集上,YOLOv8s 算法漏检严重,很多微小的舰船没有检测出来,而本文算法能够非常精确地将极其微小的目标全部检测出来,说明Improved-v8s 算法对小目标检测效果显著,漏检率低、泛化能力强,对小目标检测具有通用性。
4 结束语
针对小目标尺度小、特征提取能力不足、背景复杂、误检和漏检严重等问题。提出了一种基于YOLOv8s 改进的算法Improved-v8s。Improved-v8s通过合理增加小目标检测层,重新构建特征提取和特征融合网络,加强浅层信息和深层语义信息的融合。利用PConv 和EMA 机制构建全新的F_C2 f_EMA,降低网络参数量,对全局信息编码,实现小目标跨空间信息的聚合,建立短期和长期依赖,增强小目标特征提取能力。重新设计SPPCSPC 多尺度结构,适应小目标的空间尺度,同时引入SimAM,划分复杂背景和小目标像素区域并赋予三维注意力机制权重,加强复杂场景下密集小目标的表征能力。之后使用GSConv 和EffectiveSE 注意力机制设计了全新的G_E_C2 f,通过融合不同阶段的特征信息,提升网络学习之间的多样性,保留特征信息,减少误检和漏检率。使用轻量级上采样模块CARAFE 感知生成权重,聚合空间信息。最后使用WIoU 损失函数,平衡正负样本不均衡的问题,加快模型收敛,提高回归精度。实验表明,本文算法精度在VisDrone2019数据集上超越其他主流经典算法,具有精度高、参数量小和实时性高等优点。在WiderPerson 和SSDD数据集上进行泛化实验验证,效果较好。由此,本文提出的小目标检测算法可以看成一种通用小目标检测算法,效果显著。
参考文献
[1] LI L X,MU X H,LI S Y,et al. A Review of Face RecognitionTechnology[J]. IEEE Access,2020,8:139110-139120.
[2] ISLAM S M M,BORIC' LUBECKE O,ZHENG Y,et al. Ra-darbased Noncontact Continuous Identity Authentication[J]. Remote Sensing,2020,12(14):2279.
[3] LIN T Y,MAIRE M,BELONGIE S,et al. MicrosoftCOCO:Common Objects in Context[C]∥Proceedings ofthe European Conference on Computer Vision. Zurich:Springer,2014:740-755.
[4] GIRSHICK R,DONAHUE J,DARRELL T,et al. RichFeature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]∥Proceedings of the IEEE conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[5] GIRSHICK R. Fast RCNN [C ]∥ Proceedings of theIEEE International Conference on Computer Vision. Santiago:IEEE,2015:1440-1448.
[6] REN S Q,HE K M,GIRSHICK R,et al. Faster RCNN:Towards Realtime Object Detection with Region ProposalNetworks[J]. IEEE Transactions on Pattern Analysis andMachine Intelligence,2017,39(6):1137-1149.
[7] REDMON J,DIVVALA S,GIRSHICK R,et al. You OnlyLook Once:Unified,Realtime Object Detection[C]∥Proceedings of the IEEE Conference on Computer Vision andPattern Recognition. Las Vegas:IEEE,2016:779-788.
[8] REDMON J,FARHADI A. YOLO9000:Better,Faster,Stronger[C]∥ Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. Honolulu:IEEE,2017:6517-6525.
[9] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement[EB / OL]. (2018 - 04 - 08)[2023 - 11 - 09].https:∥arxiv. org / abs / 1804. 02767.
[10] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection [EB /OL]. (2020 - 04 - 23)[2023 - 11 - 09]. https:∥ arxiv.org / abs / 2004. 10934.
[11] ZHU X K,LYU S C,WANG X,et al. TPHYOLOv5:Improved YOLOv5 Based on Transformer Prediction Headfor Object Detection on Dronecaptured Scenarios[C]∥2021 IEEE / CVF International Conference on ComputerVision Workshops (ICCVW ). Montreal:IEEE,2021:2778-2788.
[12] TERVEN J,CORDOVAESPARZA D. A ComprehensiveReview of YOLO:From YOLOv1 to YOLOv8 and Beyond[EB / OL]. (2023 - 04 - 02)[2023 - 11 - 09]. https:∥arxiv. org / abs / 2304. 00501.
[13] LIU W,ANGUELOV D,ERHAN D,et al. SSD:SingleShot Multibox Detector[C]∥Proceedings of the EuropeanConference on Computer Vision. Amsterdam:Springer,2016:21-37.
[14] 吴明杰,云利军,陈载清,等. 改进YOLOv5s 的无人机视角下小目标检测算法[J]. 计算机工程与应用,2024,60(2):1-12.
[15] 贾晓芬,江再亮,赵佰亭. 裂缝小目标缺陷的轻量化检测方法[J/ OL]. 湖南大学学报(自然科学版):1 -11.http:∥kns. cnki. net / kcms/ detail / 43. 1061. N. 20231008.1953. 002. html.
[16] 余俊宇,刘孙俊,许桃. 融合注意力机制的YOLOv7 遥感小目标检测算法研究[J]. 计算机工程与应用,2023,59(20):167-175.
[17] 张徐,朱正为,郭玉英,等. 基于cosSTRYOLOv7 的多尺度遥感小目标检测[J/ OL]. 电光与控制:1 -9. http:∥kns. cnki. net / kcms/ detail / 41. 1227. tn. 20230615. 1017.002. html.
[18] 李子豪,王正平,贺云涛. 基于自适应协同注意力机制的航拍密集小目标检测算法[J]. 航空学报,2023,44(13):244-254.
[19] CHEN J R,KAO S H,HE H,et al. Run,Don’t Walk:Chasing Higher FLOPS for Faster Neural Networks[C]∥Proceedings of the IEEE / CVF Conference on ComputerVision and Pattern Recognition. Vancouver:IEEE,2023:12021-12031.
[20] OUYANG D L,HE S,ZHANG G Z,et al. Efficient Multiscale Attention Module with Crossspatial Learning[C]∥Proceedings of the IEEE International Conference onAcoustics,Speech and Signal Processing. Rhodes Island:IEEE,2023:1-5.
[21] YANG L X,ZHANG R Y,LI L D,et al. SimAM:ASimple,Parameterfree Attention Module for ConvolutionalNeural Networks [C]∥ Proceedings of the InternationalConference on Machine Learning. [S. l. ]:PMLR:2021:11863-11874.
[22] LI H L,LI J,WEI H B,et al. Slimneck by GSConv:ABetter Design Paradigm of Detector Architectures for Autonomous Vehicles [EB / OL]. (2022 - 06 - 06 )[2023 -11-09]. https:∥doi. org / 10. 48550 / arXiv. 2206. 02424.
[23] LEE Y W,PARK J Y. Centermask:Realtime AnchorFree Instance Segmentation [C ]∥ Proceedings of theIEEE / CVF Conference on Computer Vision and PatternRecognition. Seattle:IEEE,2020:13903-13912.
[24] GE Z,LIU S T,WANG F,et al. YOLOX:Exceeding YOLOSeries in 2021[EB / OL]. (2021-07-18)[2023-11-09].https:∥arxiv. org / abs/ 2107. 08430.
[25] WANG J Q,CHEN K,XU R,et al. CARAFE:Contentaware Reassembly of Features [C]∥ Proceedings of theIEEE / CVF International Conference on Computer Vision.Seoul:IEEE,2019:3007-3016.
[26] LIU Y C,SHAO Z R,HOFFMANN N. Global AttentionMechanism:Retain Information to Enhance ChannelSpatial Interactions[EB / OL]. (2021 - 12 - 10)[2023 -11-09]. https:∥arxiv. org / abs / 2112. 05561.
[27] TONG Z J,CHEN Y H,XU Z W,et al. WiseIoU:Bounding Box Regression Loss with Dynamic FocusingMechanism[EB / OL]. (2023 -01 -24)[2023 -11 -09].https:∥arxiv. org / abs / 2301. 10051.
[28] ZHENG Z H,WANG P,LIU W,et al. DistanceIoU Loss:Faster and Better Learning for Bounding Box Regression[C]∥Proceedings of the AAAI Conference on Artificial InTelligence. New York:AAAI Press,2020:12993-13000.
[29] 刘展威,陈慈发,董方敏. 基于YOLOv5s 的航拍小目标检测改进算法研究[J]. 无线电工程,2023,53 (10):2286-2294.
[30] YU W P,YANG T J N,CHEN C. Towards Resolving theChallenge of Longtail Distribution in UAV Images for Object Detection [C ]∥ Proceedings of the IEEE / CVFWinter Conference on Applications of Computer Vision.Waikoloa:IEEE,2021:3257-3266.
[31] ZHOU X Y,WANG D Q,KR?HENBHL P. Objects asPoints[EB / OL]. (2019-04-16)[2023-11-09]. https:∥arxiv. org / abs/ 1904. 07850.
[32] DU D W,ZHU P F,WEN L Y,et al. VisDroneDET2019:The Vision Meets Drone Object Detection in Image Challenge Results[C]∥Proceedings of the IEEE / CVF International Conference on Computer Vision Workshops.Seoul:IEEE,2019:213-226.
[33] WANG C Y,YEH I H,LIAO H Y M. You Only LearnOne Representation:Unified Network for Multiple Tasks[EB / OL]. (2021 - 05 - 10)[2023 - 11 - 09]. https:∥arxiv. org / abs / 2105. 04206.
[34] 刘涛,高一萌,柴蕊等. 改进YOLOv5s 的无人机视角下小目标检测算法[J]. 计算机工程与应用,2024,60(1):110-121.
[35] 李校林,刘大东,刘鑫满,等. 改进YOLOv5 的无人机航拍图像目标检测算法[J / OL]. 计算机工程与应用:1 -13. http:∥ kns. cnki. net / kcms / detail / 11. 2127. TP.20231013. 0942. 002. html.
作者简介
雷帮军 男,(1973—),博士,教授,博士生导师,欧盟2020 计划特聘顾问,欧盟高级人才计划会审专家,IEEE 高级会员,湖北省楚天学者特聘教授,湖北省百人计划人才。主要研究方向:计算机视觉、图像处理、人工智能、模式识别。
余 翱 男,(1999—),硕士研究生。主要研究方向:计算机视觉、目标检测。
余 快 女,(1999—),硕士研究生。主要研究方向:深度学习、遥感影像建筑物提取。
基金项目:水电工程智能视觉监测湖北省重点实验室建设(2019ZYYD007)
