基于自适应门限融合策略的语音去噪算法
2024-07-17薛芸师晨康白静赵建星汪思斌
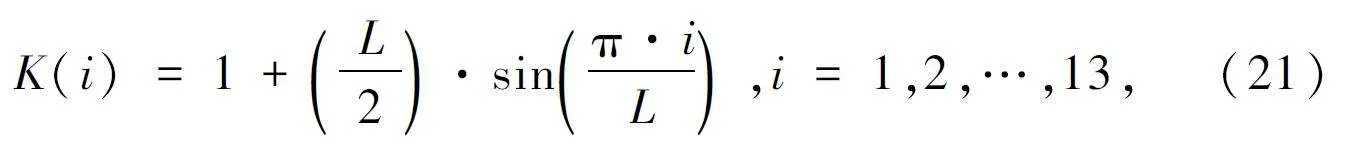




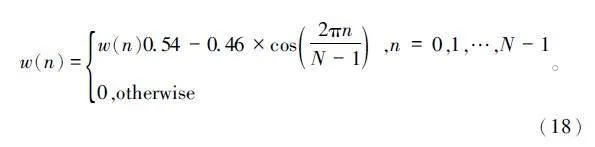

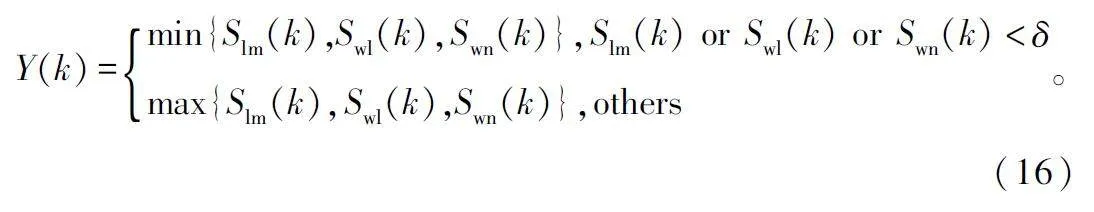

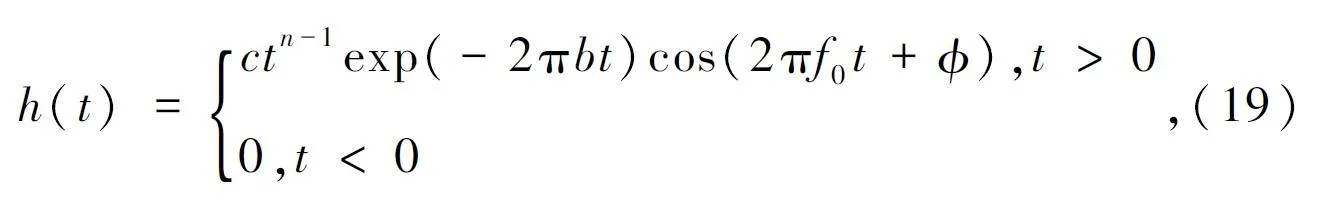



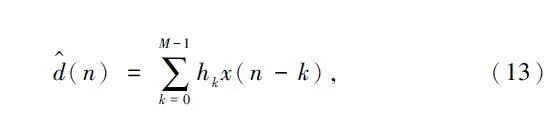


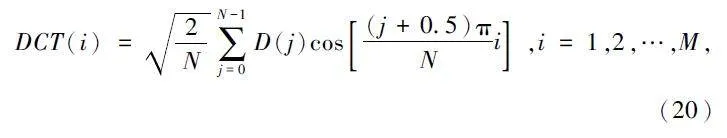




摘 要:针对单个语音去噪算法在去噪过程中关注点较为单一,而多个语音去噪算法在融合时存在细节信息被削弱、融合效果不理想的问题,提出一种多个语音去噪算法下的自适应门限融合策略,将带噪信号分别经过3 种不同的去噪算法得到3 个去噪信号;根据自适应门限值以帧为单位进行帧筛选,得到自适应门限融合策略下的去噪信号;为提高识别效果,采用倒谱提升器对Gammatone 频率倒谱系数(Gammatone Frequency Cepstrum Coefficient,GFCC) 进行改进,并联合支持向量机进行噪声环境下的语音识别。实验结果表明,在5、10、15、20 dB 四种信噪比下,通过该融合策略所得到的去噪信号与目前主流的顺序融合及多级融合方式相比,在语音识别率方面平均提高3. 6% ,融合倒谱提升器的GFCC 特征相比于GFCC 特征平均提高了2. 2% 。
关键词:语音去噪;自适应门限融合;带噪语音;帧筛选;Gammatone 滤波器
中图分类号:TN912. 35 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3106(2024)04-1026-08
0 引言
语音去噪是指当语音信号被噪声干扰后,降低带噪语音信号中的噪声,恢复纯净语音的技术[1]。语音去噪主要采用频域处理方法,其中基于短时谱估计的语音去噪方法应用最为广泛,主要有谱减法[2]、维纳滤波法[3]等,但这些技术在处理复杂环境下的语音信号时,往往容易出现语音失真、残留大量音乐噪声等现象。多个语音去噪算法的融合可以将关注点不同的多个去噪算法进行优势互补,可以对带噪语音信号进行有效处理,因此成为语音去噪方向的研究热点[4]。Yang 等[5]采用改进谱减法对含噪语音信号进行去噪,然后对处理后的信号进行改进阈值小波变换进行语音去噪,与传统的谱减法相比,融合阈值小波变换后的去噪算法,不仅仍具有谱减法处理速度快的优势,而且能够有效抑制单一谱减法产生的音乐噪声,但是其融合方式为顺序连接,语音信号的细节信息容易被忽略。Thimmaraja等[6]从编码和增强语音数据的角度出发,提出了一种结合线性预测编码(Linear Predictive Coding,LPC)和语音活动检测(SSVoice Activity Detection,SSVAD)方法的谱减法,其结合方式为将带噪语音数据作为SSVAD 算法的输入,SSVAD 的输出作为LPC 编码器的输入,但LPC 估计量对量化噪声具有很高的敏感性,不适用于泛化。Mourad 等[7]提出了平稳仿生小波变换(Stationary Bionic Wavelet Transform,SBWT)与幅度平方谱的最大后验估计量(MSSMaximum A Posteriori,MSSMAP)的语音去噪算法,该方法集成了SBWT 的信号重建优势及MSSMAP 的降噪和提升清晰度的特点,去噪后的信号不会造成相当大的失真和音乐背景噪声,其融合方式采用多级融合。Xue 等[8]提出了一种基于改进小波阈值和最小均方算法(Least Mean Square,LMS)自适应噪声消除的语音去噪算法,利用LMS 得到高信噪比的语音信号,再利用小波分析进行去噪重构,但该去噪算法会造成原始信号失真。
通过以上分析,提出在多个语音去噪算法下的自适应门限融合策略来改善去噪算法融合的局限性。首先,文中采用3 个语音去噪算法,分别为对数谱幅度估计算法、小波阈值去噪算法与维纳滤波算法,对带噪信号进行去噪处理,得到3 个去噪信号;其次,以帧为单位截取去噪信号的帧分量并进行归一化处理,同时设立一个门限值用于对3 个去噪信号进行帧筛选,在一帧信号中,若有一个及以上去噪信号的帧分量处于门限值以下,则该帧信号选取三者中值最小的信号,若3 个帧分量都大于门限值,则该帧信号选取三者中值最大的信号,门限值根据信噪比的不同而变换,最终输出自适应门限融合策略下的去噪信号,该融合方法可较全面地结合语音信息,提高语音质量;另一方面,在提取Gammatone 频率倒谱系数(Grammatone Frequency Cepstrum Coefficient,GFCC)特征时,由于离散余弦变换(DiscreteCosine Transform,DCT)会使大部分有效数据聚集在低频区,从而降低识别效果,因此引入倒谱提升器来提升语音识别模型的性能,最后通过设计实验,验证该方法的有效性。
1 自适应门限融合策略下的语音去噪算法
1. 1 对数谱幅度估计算法
假设带噪语音信号为y (n)由纯净语音信号s(n)与噪声信号d(n)相加而成,由于语音信号具有短时平稳特性[9],对带噪语音信号进行短时傅里叶变换及幅度谱估计后,得到:
Yk,m(ω) = Sk,m(ω)+ D(ω), (1)
式中:Yk,m(ω)、Sk,m(ω)分别表示y(n)、s(n)第m 帧的短时幅度谱,D(ω)表示d(n)的短时幅度谱。
采用后验信噪比的方法进行降噪,有:
γk,m = |Yk,m(ω) |2 /| D(ω)| 2 , (2)
式中:γk,m 为带噪信号y(n)与噪声信号d(n)的后验信噪比。
为抑制音乐噪声,提高去噪效果,引入先验信噪比,并采用判别引导法[10]进行估计,可得:
式中:ξk,m 表示先验信噪比,为纯净语音信号在频域中的信噪比;λd(k,m-1)表示噪声频域中第k 个频谱分量,第m-1 帧的方差;a 表示权重因子。
线性幅度谱的计算在数学上易于处理,但应用在听觉上效果并不理想[11],故采用对数幅度谱估计对带噪语音信号进行处理,采用对数最小均方误差(Minimum Mean Squared Error,MMSE)估计器得到增益函数:
1. 2 小波去噪算法
1. 2. 1 小波变换
小波变换是信号处理中的一种分析方法,解决了傅里叶变换在时频域变化中对局部关注较少、对非平稳信号处理效果不理想的问题,其通过采用长度有限、不断衰减的小波基实现,当小波进行平移伸缩后与信号波形出现重合时,既可得到信号的频率成分,也可明确信号在时域的位置信息,所以小波在时频域具有表达信号局部特征的特点[12],具体计算流程如下。
小波变换是将基本小波函数φ(t)做位移τ 后,在不同尺度a 下,与待分析信号f(t)做内积,即:
1. 2. 2 小波阈值去噪算法
小波阈值去噪的基本原理:根据噪声与信号在不同频带上的小波分解系数具有不同强度分布的特点,采用小波对信号进行三级分解,并计算噪声阈值,即可得到小波分解系数,之后根据频带与强度筛除噪声对应的小波系数,对去除噪声后的语音信号进行小波重构,可得到去噪语音。具体计算流程如下。
假设s(t)表示带噪信号,f(t)表示原始信号,n(t)表示噪声信号:
s(t) = f(t)+ n(t)。(10)
由于语音信号具有短时平稳特性,而噪声信号S 通常表现出高频特性,因此选定一种小波,经过三级分解,分解出D1 、D2 、D3 三个高频分量及一个A3低频分量:
S = A3 + D1 + D2 + D3 。(11)
在分解后的信号中,纯净语音对应的系数很大,而噪声对应的系数很小,因此采用连续性更好的软阈值函数对分解信号进行处理,如式(12)所示,设定一个阈值thr,若输入信号w 的绝对值大于阈值thr,则令其绝对值减去阈值,保留信号,反之则视为噪声,将其置为零。
对处理完的小波系数进行反变换,即可重构出去噪的语音信号,小波去噪算法的流程如图1 所示。
1. 3 维纳滤波算法
在语音去噪方向中,维纳滤波算法能够在带噪信号中将纯净语音信号提取出来,由于语音信号具有短时平稳特性,而维纳滤波又是一种在处理平稳随机信号的均方误差方面具有很大优势的滤波器,维纳滤波在提出之时并没有给出具体的滤波器,而是通过计算LMS 来计算得到去噪后的信号。维纳滤波算法流程如图2 所示。
图2 中,x(n)为输入语音信号,当信号通过线性时不变滤波器后得到输出信号d^ (n),d(n)为理论计算的输出值,e(n)为实际输出与理论输出的误差,维纳滤波的目的是将这个误差最小化,其中线性时不变滤波器通常采用FIR 滤波器,得到的输出信号如下:
式中:{hk }为FIR 滤波器系数,M 为系数个数。需要计算滤波器系数{hk}以最小化估计误差e(n):
e(n) = d(n)-d ^ (n)。(14)
估计误差e(n)的均方值通常被用作最小化判断依据,最优滤波器系数{hk }通常可以在时域或频域进一步计算。
2 基于自适应门限融合策略的带噪语音识别
2. 1 自适应门限融合策略
由于单个语音去噪算法对带噪语音信号进行去噪时关注点较为单一,而多个语音去噪算法的融合可以从多个角度对带噪信号进行去噪处理,但是传统的顺序融合、多级融合等,在融合时存在细节信息被削弱、融合效果不理想的问题,因此考虑到多种语音去噪算法的优势,提出一种自适应门限融合策略。
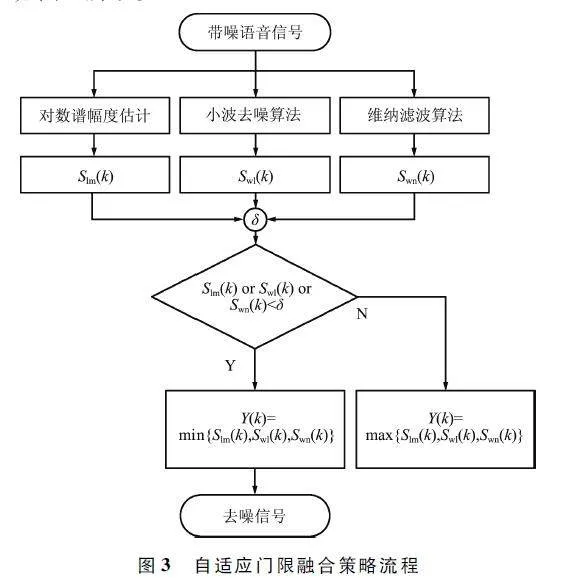
首先,对数谱幅度估计算法在处理带噪信号时,具有信号失真度小、去噪效果好的特点;小波阈值去噪算法在低信噪比下去噪效果较好,去噪后的语音识别率较高,特别针对时变及突变信号去噪效果明显,且在非平稳信号和提取信号局部特征方面具有良好的表现;维纳滤波算法在处理平稳随机信号的均方误差方面具有很大优势。为充分结合三者的优势,采用自适应门限融合策略对三者进行融合,流程如图3 所示。
自适应门限融合策略的具体实现方法如下:
设带噪语音信号长度为N 帧,则对数谱幅度估计算法、小波阈值去噪算法和维纳滤波算法第k 帧的输出分别为Slm(k)、Swl(k)和Swn(k),为更好地结合三者的特性,首先进行帧归一化操作,便于后续计算,归一化如式(15)所示:
式(15)仅介绍了对数谱幅度估计算法的归一化方法,其余2 种方法同理。
针对同一帧去噪信号,对3 个去噪算法的输出进行帧筛选,并引入自适应门限阈值δ。
针对自适应门限融合算法的第k 帧信号Y(k),若Slm(k)、Swl(k)和Swn(k)有一个信号小于门限阈值δ 时,则取三者中的最小值,目的是选取三者中对噪声抑制效果更好的帧信号;其余情况,则取三者中的最大值,目的是最大限度地保留纯净语音信号。自适应门限融合策略示意如图4 所示。
图4 中最左侧的语音信号为带噪声的N 帧语音信号,经过3 种去噪算法后,得到3 个N 帧去噪信号,自适应门限融合策略对三者进行归一化及帧筛选,并根据阈值的大小进行决策融合后,得到N 帧去噪信号。由于这些信号是经过3 种去噪算法的帧信号进行交叉结合后的结果,因此可以考虑到多种去噪算法的优势,使不同的去噪算法能够充分结合,提高去噪效果。该策略也可针对不同的信噪比改变不同去噪算法得到的帧信号在N 帧信号中的占比,比如,当信噪比较低时,N 帧信号中小波去噪算法得到的帧信号占多数。
2. 2 融合倒谱提升器的改进GFCC 语音特征提取
带噪语音信号进行去噪处理后,需要提取语音特征再进行语音识别。Gammatone 滤波器是一组模拟耳蜗频率[13]分解特性的滤波器模型,当外界的声音进入人耳的基底膜后,将根据频率进行分解并产生行波振动,从而刺激听觉细胞[14],通过该滤波器组所提取出的GFCC 语音特征参数在频域中与人耳听觉特性较为符合[15],由于传统GFCC 语音特征的有效数据大部分都集中在低频区,因此引入倒谱提升器进行改进,融合倒谱提升器的改进GFCC 语音特征提取算法如下:
① 预加重。由于语音高频信号储存能量较少,因此需要进行预加重处理,预加重函数如下所示:
y(n) = x(n)- αx(n - 1), (17)
式中:预加重系数α 取0. 95。
② 分帧、加窗。将语音信号按照帧长25 ms,帧移15 ms 的标准分成若干帧信号,上下帧之间的重复结构有助于提升帧与帧之间的连贯性。
将语音信号分帧后,为避免频谱泄露,需要为每一帧信号代入窗函数,采用汉明窗函数,如下:
③ 快速傅里叶变换(Fast Fourier Transform,FFT)。对信号进行时频域变换,对加窗后的信号进行FFT,并计算功率谱S(i)。
④ Gammtone 滤波器组。将信号功率谱通过Gammatone 滤波器组[16]进行滤波处理,滤波器组的时域表达式如下:
式中:c 为滤波器系数,n 为滤波器阶数,b 为时间衰减系数,f0 为中心频率, 为滤波器相位,h(t)为滤波器组的输出。
⑤ 对数变换。为增强Gammatone 滤波器组的抗干扰能力,将信号进一步采用对数变换,得到一组对数谱D(i),用于提升非线性特性
⑥ DCT。为了去除信号相关性及降维[17],需对信号进行DCT:
式中:N 为Gammatone 滤波器组的个数,M 为特征维度。
⑦ 倒谱提升器。由于大部分信号数据集中聚集在DCT 变化后的低频区,为提升高频DCT 系数的大小,采用倒谱提升器K(i):
式中:L 为升倒谱系数,一般取22。
⑧ 融合倒谱提升器的GFCC 语音特征。将离散余弦变换与倒谱提升器相乘即可得到融合倒谱提升器的GFCC 语音特征参数:
GFCC(i) = DCT(i)K(i),i = 1,2,…,13。(22)
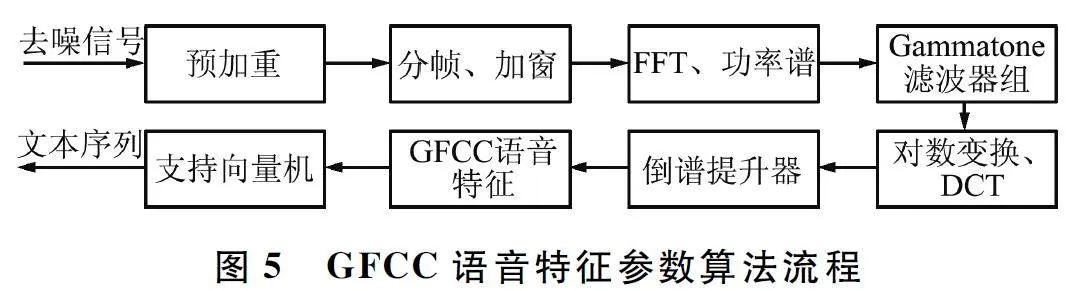
最后,GFCC 将作为支持向量机的输入进行语音识别,GFCC 语音特征参数算法流程如图5 所示。
3 仿真实验与结果分析
3. 1 实验数据
为验证所提出算法的有效性,采用针对非特定人的UASpeech 数据库,选取1 650 条纯净语音,实验将纯净语音在不同信噪比(5、10、15、20 dB)下的发音作为语音数据,组成6 600 条语音数据,其中6 000 条语音作为训练集数据,600 条语音作为测试集数据。
3. 2 仿真实验与结果分析
实验首先采用2 种去噪算法进行实验,以验证自适应门限融合策略在2 种算法下是否有效。带噪语音信号经对数谱幅度估计算法及小波去噪算法进行去噪后,采用自适应门限融合策略,得到去噪后的语音信号;其次采用支持向量机作为语音识别模型,并提取融合倒谱提升器的GFCC 语音特征参数作为支持向量机的输入,进行噪声环境下的语音识别实验;最后,在5、10、15、20 dB 四种不同的信噪比下设计5 组试验来验证自适应门限融合策略在语音去噪及语音识别中的优越性。
实验一:为确定自适应门限融合策略中门限值的大小,根据4 种不同的信噪比(5、10、15、20 dB)来确定不同的门限值,实验采用语音识别率作为评价指标,实验结果如图6 所示。
从图6(a)可以看出,当信噪比为5 dB、门限值为0. 086 时,语音识别率达到87. 5% ;从图6(b)可以看出,当信噪比为10 dB、门限值为0. 034 5 ~0. 036 时,语音识别率达到88. 8% ;从图6(c)可以看出,当信噪比为15 dB、门限值为0. 007 6 时,语音识别率达到91. 3% ;从图6(d)可以看出,当信噪比为20 dB、门限值为0. 005 时,语音识别率达到91. 5% 。分析数据可得,随着信噪比的提高,噪声功率不断衰减,门限值也随之降低,语音识别率不断提升。
实验二:为确定GFCC 特征及融合倒谱提升器的GFCC 特征对语音识别模型识别效果的影响,实验将从4 种不同的信噪比(5、10、15、20 dB)下展开实验,门限值分别取实验一中得到的最优门限值,并采用语音识别率作为评价指标,实验结果如表1 所示。
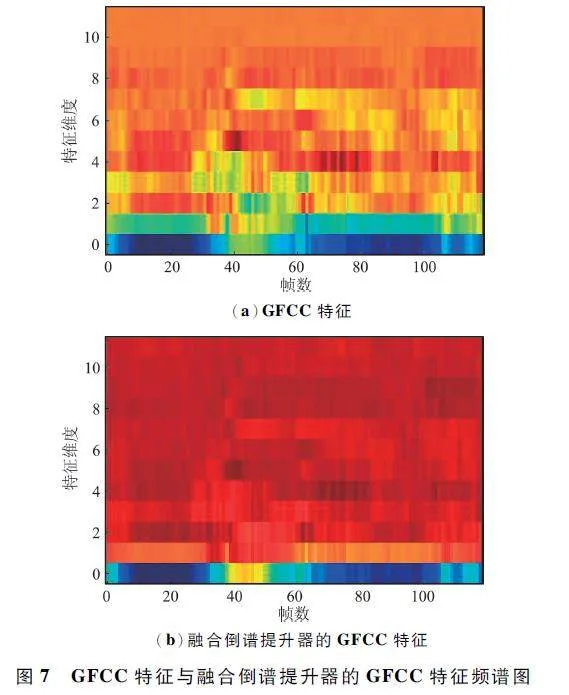
由表1 可得,在5、10、15、20 dB 四种不同的信噪比下,融合倒谱提升器的GFCC 特征相比于GFCC特征在语音识别率上分别提升了3. 69% 、1. 83% 、1. 77% 和1. 50% ,主要原因是DCT 会使大部分有效数据聚集在低频区,而倒谱提升器可以提升高频DCT 系数的大小。为更直观地表明倒谱提升器带来的变化,GFCC 特征及融合倒谱提升器的GFCC特征频谱如图7 所示。
经过倒谱提升器的作用后,高频部分的系数大小得到提升,对应到图中显示为特征维度大的地方,亮度被提高、低维的有效信息被扩散至高维,从而使语音识别模型可以更充分地提取GFCC 的有效特征。
实验三:为实现门限值跟随信噪比变换的自适应策略,实验三将根据实验一中5、10、15、20 dB 四种信噪比及相应的门限值数据进行非线性曲线拟合,拟合后的自适应函数如下:
y = 4. 84 × 10 -4 x2 - 17. 51 × 10 -3 x + 16. 15 × 10 -2 , (20)
式中:x 为信噪比,y 为门限值。为验证自适应函数的有效性,假设信噪比为8 dB,则相应的门限值通过理论计算为0. 052,其实验结果如表2 所示。
由表2 可得,门限值的取值间隔为0. 002,在不同门限值下,识别率不同。当门限值为0. 052 时,识别率为最高的88. 13% ,这与8 dB 信噪比下的理论门限值一致,进一步证明了自适应函数的有效性。
实验四:为验证自适应门限融合策略的有效性,将带噪信号分别通过对数幅度谱估计算法、小波去噪算法、Yang 等[5] 所采用的顺序融合方法及Mourad 等[7]所采用的多级融合方法进行识别率比较试验,实验结果如表3 所示。
由表3 可得,在4 种不同的信噪比环境下,对数谱幅度估计算法的去噪效果普遍比小波去噪算法要好,顺序融合方法在一定程度上能够提升识别率,但在5 dB 及15 dB 的情况下出现了识别率下降的现象,说明顺序融合方式对识别率的提升存在一定的局限性。多级融合方法在4 种信噪比的环境下都出现了识别率下降的现象,说明多级融合方式对去噪效果产生了负影响,而针对自适应门限融合策略,从整体上看,无论信噪比如何变化,文中提出的融合策略识别率最高,相比其他算法,识别率最大可提升7. 4% ,因此结合针对不同信噪比所变化的门限融合策略可以构造更好的语音去噪算法。
实验五:为验证多个去噪算法是否适用于自适应门限融合策略,实验采用3 种语音去噪算法,分别为维纳滤波法[18]、对数谱幅度估计法及小波去噪法,将这3 种方法分别采用传统的顺序融合、多级融合及自适应门限融合方法在5、10、15、20 dB 四种信噪比下进行噪声环境下的语音识别实验,实验结果如表4 所示。
由表4 的实验结果可得,相比于2 种语音去噪算法,在3 种语音去噪算法下,顺序融合方式分别在5、10、20 dB 的噪声环境下,都出现了识别率下降的现象,多级融合方式在一定程度上也有所提高,自适应门限融合策略算法,在4 种信噪比环境下语音识别准确率提升最多,识别效果最好。
4 结束语
为充分结合不同去噪算法的优势,提出一种自适应门限融合策略下的语音去噪融合算法,首先采用多种语音去噪算法分别对带噪信号进行去噪及帧归一化对齐处理,将对齐后的帧信号根据自适应门限值进行帧筛选处理,以充分结合不同去噪算法的优势;其次采用倒谱提升器,改善传统GFCC 特征存在的有效数据聚集在低频区的问题,从而提升识别效果;最后通过支持向量机进行噪声环境下的语音识别。实验结果表明,自适应门限融合算法在不同信噪比下,能够有效结合多种去噪算法的特性,且融合倒谱提升器的GFCC 特征能够有效提升语音识别效果。
参考文献
[1] DAS N,CHAKRABORTY S,CHAKI J,et al. Fundamentals,Present and Future Perspectives of Speech Enhancement [J]. International Journal of Speech Technology,2021,24(1):883-901.
[2] 白静,史燕燕,薛 芸,等. 融合非线性幂函数和谱减法的CFCC 特征提取[J]. 西安电子科技大学学报,2019,46(1):86-92.
[3] NUHA H H,ABSA A A. Noise Reduction and Speech Enhancement Using Wiener Filter[C]∥2022 InternationalConference on Data Science and Its Applications (ICoDSA). Bandung:IEEE,2022:177-180.
[4] 杨海红,王琳娟. 强混响及噪声相关背景下说话人跟踪方法[J]. 无线电工程,2021,51 (9):963-970.
[5] YANG Y,LIU P P,ZHOU H L,et al. A Speech Enhancement Algorithm combining Spectral Subtraction andWavelet Transform [C]∥ 2021 IEEE 4th InternationalConference on Automation,Electronics and Electrical Engineering (AUTEEE). Shenyang:IEEE,2021:268-273.
[6] THIMMARAJA Y G,NAGARAJA B G,JAYANNA H S.Speech Enhancement and Encoding by Combining SSVAD and LPC[C]∥2019 4th International Conference onElectrical,Electronics,Communication,Computer Technologies and Optimization Techniques (ICEECCOT). Mysuru:IEEE,2019:151-157.
[7] MOURAD T. Speech Enhancement Based on StationaryBionic Wavelet Transform and Maximum a Posterior Estimator of Magnitudesquared Spectrum [J]. InternationalJournal of Speech Technology,2017,20:75-88.
[8] XUE X S,JIANG D Z,HE Z H,et al. An Improved Unsupervised Singlechannel Speech Separation Algorithm forProcessing Speech Sensor Signals[J]. Wireless Communications and Mobile Computing,2021,2021(170):1-13.
[9] 程艳芬,陈篧鑫,陈逸灵,等. 嵌入注意力机制并结合层级上下文的语音情感识别[J]. 哈尔滨工业大学学报,2019,51(11):100-107.
[10] HOGLUND N,NORDHOLM S. Improved a Priori SNREstimation with Application in LogMMSE Speech Estimation[C]∥2009 IEEE Workshop on Applications of SignalProcessing to Audio & Acoustics. New Paltz:IEEE,2009:189-192.
[11] FENG X Y,LI N,HE Z W,et al. DNNbased Linear Prediction Residual Enhancement for Speech Dereverberation[C]∥2021 AsiaPacific Signal and Information ProcessingAssociation Annual Summit and Conference (APSIPAASC). Tokyo:IEEE,2021:541-545.
[12] OSADCHIY A,KAMENEV A,SAHAROV V,et al. SignalProcessing Algorithm Based on Discrete WaveletTransform[J]. Designs,2021,5(3):41.
[13] 柏梁泽,高勇. 结合卷积平滑耳蜗谱和深度网络的语音增强技术[J]. 无线电工程,2020,50(12):1055-1062.
[14] 姜顺明,王智锰. 采用听觉传感策略的声品质主动控制[J]. 机械工程学报,2019,55(23):147-153.
[15] DUA M,AGGARWAL R K,BISWAS. GFCC Based Discriminatively Trained Noise Robust Continuous ASRSystem for Hindi Language[J]. Journal of Ambient Intelligence and Humanized Computing,2019,10 (6 ):2301-2314.
[16] 余琳,姜囡. 基于Gammatone 滤波器的混合特征语音情感识别[J]. 光电技术应用,2020,35(3):50-58.
[17] ALGHABBAN J M,ALHABOOBI A,NASSAR Y S. QP“DCT and Wavelet Transfer (HAAR,DB)”QuantizationImplementation in the Frequency Domain [J ]. TurkishJournal of Computer and Mathematics Education (TURCOMAT),2021,12(12):152-158.
[18] MANAMPERI W,SAMARASINGHE P N,ABHAYAPALAT D,et al. GMM Based Multistage Wiener Filtering forLow SNR Speech Enhancement [C]∥2022 InternationalWorkshop on Acoustic Signal Enhancement (IWAENC).Bamberg:IEEE,2022:1-5.
作者简介
薛珮 芸 女,(1990—),博士,讲师。主要研究方向:语音信号处理、病理语音识别、语音可视化与人工智能等。
师晨康 男,(1999—),硕士研究生。主要研究方向:语音信号处理。
白 静 女,(1965—),博士,教授。主要研究方向:音频与视频技术、语音可视化、嵌入式系统和数据挖掘等。
赵建星 男,(1994—),硕士研究生。主要研究方向:语音信号处理。
汪思斌 男,(1999—),硕士研究生。主要研究方向:语音信号处理。
基金项目:山西省应用基础研究计划项目(201901D111094);山西省基础研究计划(20210302124544)
