叙事结构理论视角下数据故事模型构建研究
2024-07-01宿倩纪雪梅
宿倩 纪雪梅

关键词: 叙事结构; 叙事要素; 数据故事; 数据叙事; 山东省农业碳排放
DOI:10.3969 / j.issn.1008-0821.2024.07.002
〔中图分类号〕G250.73 〔文献标识码〕A 〔文章编号〕1008-0821 (2024) 07-0013-09
数据故事化是指为了提升数据的可理解性、可体验性及可记忆性, 将“数据” 还原或关联至特定情景, 并以叙述方式呈现的过程[1] 。数据故事化作为大数据时代下的新型活动, 已成为数据科学及相关领域的热门话题之一。作为新型的数据呈现方式,数据故事不仅具有易于认知、易于记忆和易于体验的特质, 还能够折射出数据背后的内在逻辑和语义关联[2] 。数据故事模型能够规范数据故事要素及其呈现过程, 对数据故事的制作具有指导意义。相关研究从不同视角出发对数据故事模型进行了构建,如用户交互视角[3-4] 、传播学视角[5-6] 和叙事者视角[7] 等。目前, 数据故事模型的研究更加关注实践应用层面, 对数据故事自身的结构要素关注较少,明晰数据故事结构要素可为数据故事模型构建提供理论基础。
叙事结构理论旨在解构叙事的组成部分以及了解各部分之间的联系[8] , 已被相关学者引入档案叙事[9] 、数字人文[10] 、文本叙事元素抽取[11] 和智能叙事[12-13] 等数据科学领域。数据故事根本上是基于叙事的原则[14] , 将数据和叙事结合。数据故事和文学叙事在表现手法上也具有一致性[15] , 所以叙事结构理论能为数据故事模型构建提供丰富的理论基础。本研究基于叙事结构理论对数据故事结构及要素进行分析, 进而构建数据故事模型, 指导数据故事的创作。
1 叙事结构理论概述
1.1 叙事具有结构性
叙事结构理论受结构主义的启发, 以形式主义为特征, 关注阐释文艺作品的整体结构。瑞士语言学家索绪尔(Saussure)是结构主义语言学的代表,他将语言结构看作能指与所指, 历时与共时, 内涵与外延的二元结构, 认为言语活动(Langage)是一个结构整体, 可划分为语言(Langue)和言语(Pa?role)[16] 。皮亚杰(Piaget) 受索绪尔结构语言学的影响, 在《结构主义》一书中指出, “结构” 是由具有整体性的转换法则构成的一个本身有调节性质的体系, 必须包含转换性、整体性以及自身调整性这3 种特性, 为“叙事是一个结构” 提供了理论依据[17] 。叙事结构研究沿袭了结构主义语言学的二元对立思想, 其形式主义特征主要体现在对叙事情节的关注, 如埃尔利赫(Erlich)将叙事结构分为“本事” (Fable)和“情节” (Plot), 认为本事是内容, 情节是形式[18] 。结构主义和形式主义的思想为叙事结构的研究提供了理论来源。
1.2 叙事的结构要素研究
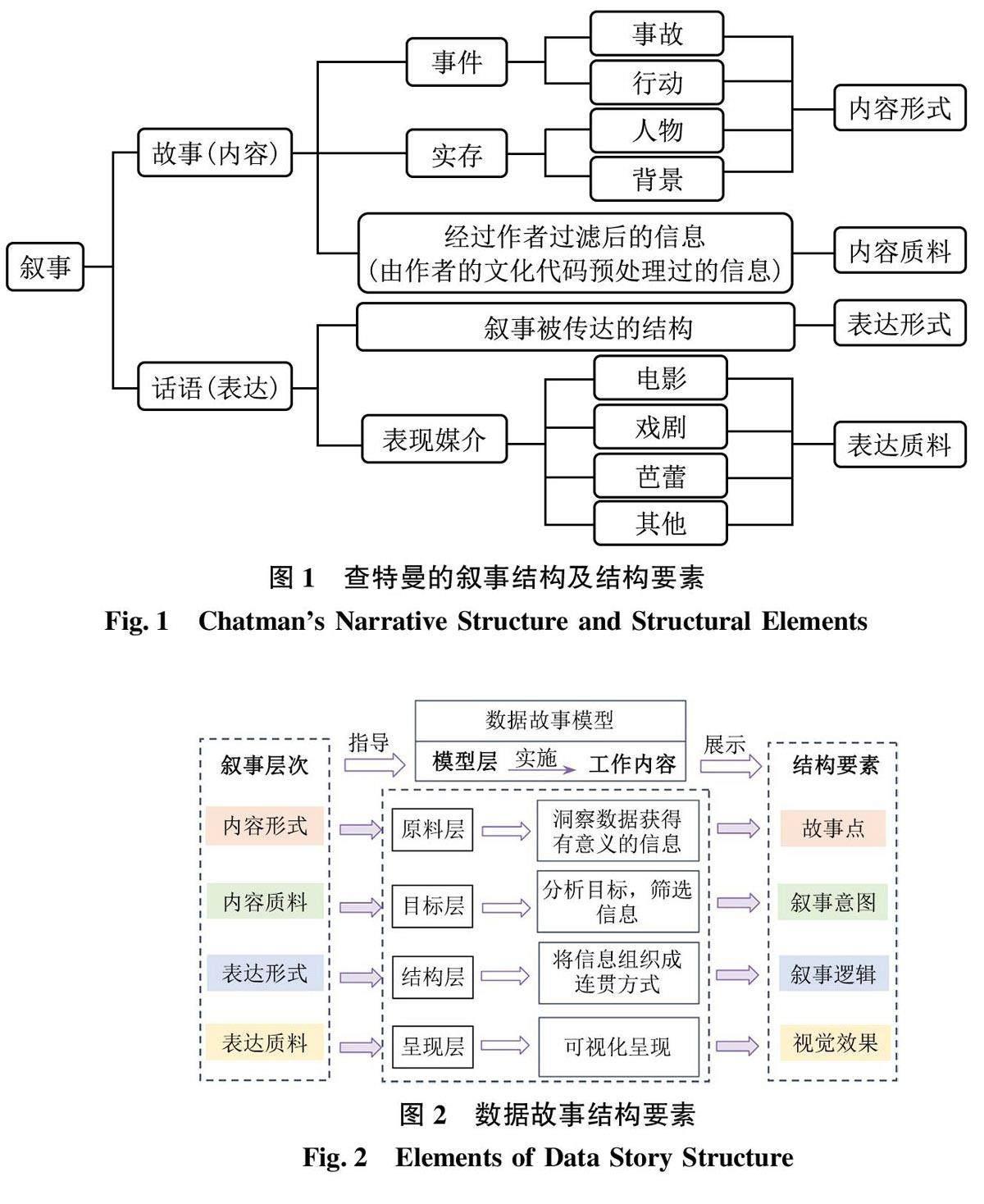
叙事结构研究的代表人物有查特曼(Chatman)、热奈特(Genette)、普罗普(Пропп)、巴特(Bar?thes)等。西蒙·查特曼[19] 认为, 叙事结构由故事和话语构成, 故事即“发生了什么内容”, 话语即“如何表达叙事内容”。热拉尔·热奈特[20] 将叙事分为故事(Story)、叙事(Narrative)与叙述(Narration)3个结构, 故事是指小说或叙事本身的文本; 叙事是指要叙述的内容信息, 包含按时间顺序组织的事件;叙述是指叙事者进行叙述的行为。弗拉基米尔·雅可夫列维奇·普罗普[21] 指出, 故事是由事件组成的,类似植物形态一样, 不同事件之间也存在相互关系。巴特认为, 叙事作品包括功能级、行动级和叙述级,分别指向建构的意义、人物关系处理和意义建构方式等环节[22] 。在上述理论中, 查特曼对叙事结构的划分与数据故事的“数据+故事” 结构具有较高的适配性。张晨等[23] 也指出, 数据故事化涉及数据和故事两大主体, 可归纳为“数据+故事→数据故事” 的实现过程。因此, 本研究选择以查特曼的叙事结构理论为基础进行数据故事结构要素分析。
1.3 查特曼的叙事结构理论概述
西蒙·查特曼[19] 在结构主义和形式主义的基础上, 重新探讨“情节” “本事” 等概念并对叙事结构进行划分, 将叙事结构分为“故事” 和“话语”两部分, 故事是叙事的内容层面, 话语是叙事的表达层面。西蒙·查特曼[19] 又在内容和表达两个层面下划分出形式和质料两个亚层次, 形成内容形式、内容质料、表达形式和表达质料4 部分。内容形式, 主要指叙事的故事成分, 包括事件(行动、事故)、实存(人物、背景)以及他们之间的关系; 内容质料, 是经过作者过滤后的信息(经由作者的文化代码预处理过的信息); 表达形式, 即叙事被传达的结构(由任意一种叙事媒介所共同拥有的因素构成的话语); 表达质料, 是指能够传达叙事的媒介[19] 。查特曼的叙事结构及结构要素如图1 所示。
2 基于查特曼叙事结构理论的数据故事要素分析
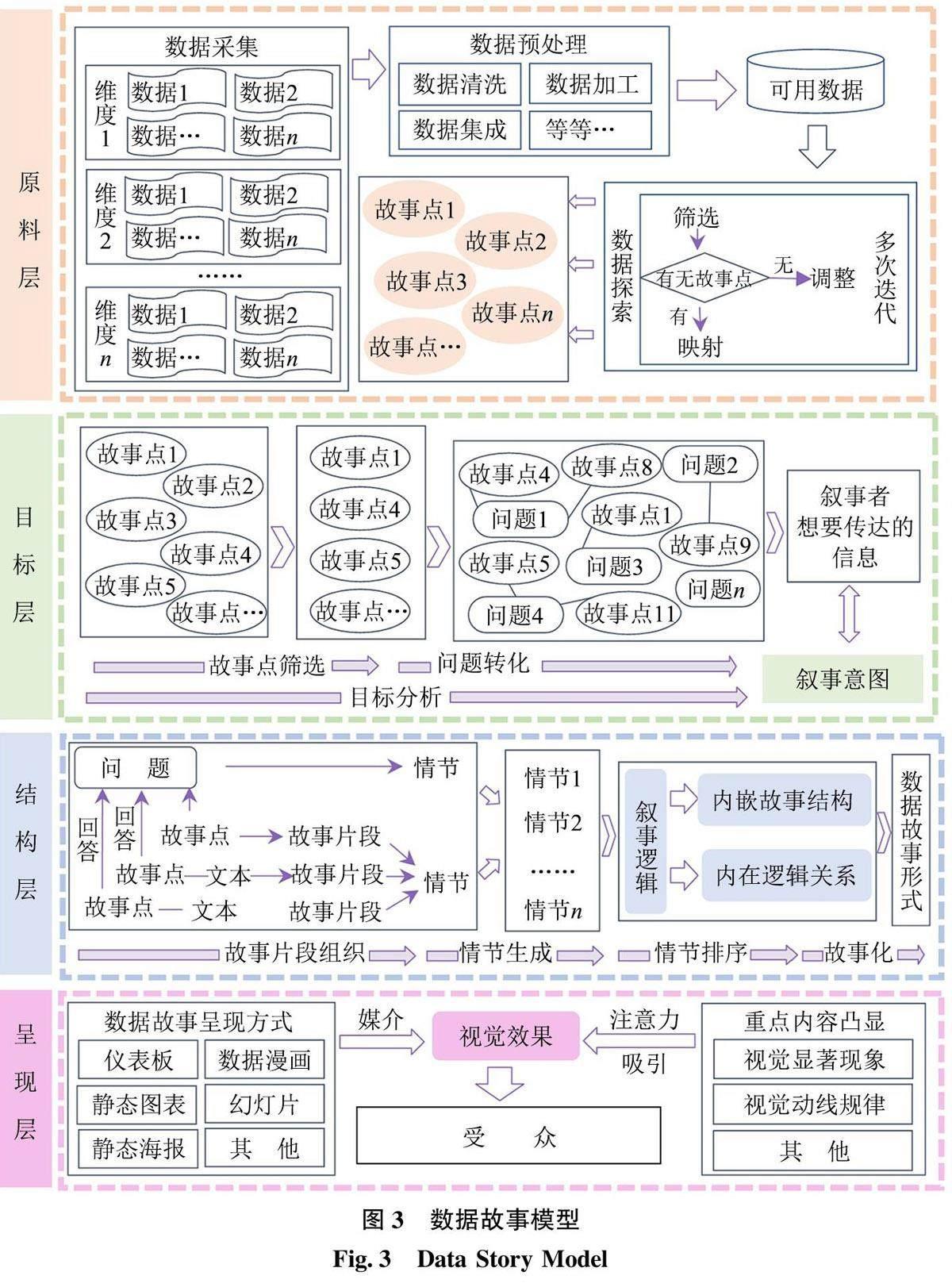
依托于查特曼的叙事结构理论, 将数据故事的结构要素分为故事点、叙事意图、叙事逻辑、视觉效果4 个层次, 故事点和叙事意图属于故事内容层面, 叙事逻辑和视觉效果属于话语表达层面。数据故事结构要素通过模型层实现, 数据故事结构要素及其与数据故事模型之间的关系如图2 所示。
2.1 故事点
在内容形式层面, 叙事由事件和实存等要素构成, 而这些要素与它们所构成的叙事又有区别, 事件和实存都是离散的和单独的, 而叙事是一个连续的综合体, 事件和实存倾向于被联系起来组成叙事[19] 。故事点是构成数据故事内容的基本要素[24] ,它们是由真实存在的数据支撑的解释或模式等, 也都是零散和单独的, 可以经过筛选修饰后被组织起来描述一个连续的数据故事。
数据故事区别于其他类型故事的典型特征就是以数据为基础[15] 。故事内容通常来源于数据探索分析过后发现的新的关系、模式、趋势或异常等[25] ,这些数据关系、模式等都可称为故事点, 构成了数据故事的内容。故事点包括故事内容中的事件、行动、人物主体和背景等, 其中事件是故事的主要内容, 通常包括描述性事件、解释性事件和预测性事件等, 分别对应“是什么” “为什么” 和“下一步是什么”。如在碳排放数据分析中, 描述性事件主要介绍碳排放现状和规律, 解释性事件围绕碳排放影响因素进行探究, 预测性事件是洞察未来碳排放的趋势和采取的措施等。一个数据故事通常包含了多种类型的故事点。
2.2 叙事意图
叙事在内容质料层面主要是对故事内容进行筛选过滤, 作者选出对故事表达有必要意义的内容,这个过程离不开作者自身的文化代码[19] 。同样, 在数据故事中需要叙事者根据目标分析筛选出足以解释数据故事主题的故事点, 将无关内容过滤, 明确叙事意图。叙事意图是指叙事者想要表达的信息内容, 是形成意义或建构意义的过程。叙事意图决定了数据故事的目的性、方向性和凝聚力[26] 。数据探索产生的故事点都具有价值, 但并非所有故事点对同一个数据故事都有意义, 叙事者结合明确的叙事目标选择故事点, 将无关紧要的、多余的、模棱两可的故事点剔除, 使得数据故事内容具体化和清晰化。叙事意图是故事点和叙事逻辑之间的桥梁。
2.3 叙事逻辑
叙事的表达形式主要是指“叙事被传达的结构”,即事件的安排, 并通过逻辑连结实现[19] 。在数据故事中也需要通过叙事逻辑来组织情节之间的顺序,将故事内容组织成连贯的形式。叙事逻辑是数据故事各情节之间的完整逻辑链条, 故事情节通过各种逻辑结构关系, 形成清晰、有序的叙事脉络和叙事结构。如马提尼玻璃结构、文学故事的劳雷尔情节结构、亚里士多德结构或是Freytag 金字塔结构等。文学叙事结构能够承载丰富的故事情节, 而且能传达清晰的逻辑, 易于认知, 符合读者阅读习惯, 已被学者应用到数据故事的研究中[27] 。文学叙事结构通过故事情节自身存在的逻辑关系构建有意义的片段序列[28] , 如故事情节之间存在的因果关系、演化关系、空间关系以及时间序列关系等。典型的叙事逻辑结构及其图式解释如表1 所示。
2.4 视觉效果
在表达质料层面, 文学叙事和数据叙事都是要将故事内容传达给受众。相较于文学叙事来说, 数据叙事的表现形式由语言转变为数据, 对数据进行视觉描述使得故事内容能够直观化呈现。视觉是人类主要感受和理解周围世界的感官, 超过50%的大脑皮层致力于视觉信息的处理[34] 。在数据故事中,对数据进行视觉描述, 比文字或数字带来的优势更明显, 视觉效果不仅能够吸引注意力、帮助理解和回忆, 也更具说服力[26] 。叙事者可使用可视化图表呈现数据的关键属性, 借助颜色、形状等来引导受众的注意力, 完成数据故事视觉效果呈现。
3 数据故事模型构建与分析
叙事结构视角下的数据故事模型本质上是将数据故事视为一个整体, 将整体进行结构划分, 各结构层负责不同结构要素的展示, 结构之间相互联系。依据查特曼叙事结构理论将数据故事模型划分为原料层、目标层、结构层和呈现层, 反映了从原始数据到视觉呈现数据故事的过渡。该模型旨在支持数据故事构建的整个生命周期。叙事结构视角下的数据故事模型如图3 所示。
3.1 原料层
数据是数据故事的基石, 原料层主要是在数据源中洞察、分析数据以获得故事点的过程, 主要从数据采集与处理、数据探索两个方面作为切入点。
1) 数据采集与处理。原料层需要对不同维度的数据进行提取, 相同维度的数据展现数据故事的某一片段或情节, 不同维度的数据互相补充, 从而对数据故事内容有更本质、更客观、更全面的认识。数据预处理主要对缺失、重复、噪声数据以及不相关信息进行清洗, 对数据进行语义语种归一、重名数据进行区分等。有时还需要对数据进一步加工,如在探究碳排放量数据时, 部分数据只提供甲烷、一氧化氮气体含量等, 需要结合气体之间的增温势系数转化为碳排放量, 对数据进行二次加工。每个数据源都单独提供有价值的信息, 进行多个数据源集成能够发现数据之间的显性或隐含关系, 会获得更大的价值[35] 。可用数据是可以直接进行探索的数据, 是进行分割或聚类等操作的基础。
2) 数据探索。数据探索的目的是发现数据中包含的故事点, 包括事件和实存等故事内容。西蒙·查特曼[19] 指出, 事件是事故(Happenings)和行动,二者都是状态的改变, 其中行动就是由一个行动原引发的或对一个被动者造成影响的一种状态的改变。在数据探索阶段需要对数据状态的改变进行探索,如可借助时间序列分析探索数据的演化; 借助对比分析、方差分析和相关分析方法探索数据之间的相关关系; 借助回归分析探索数据之间的因果关系等。查特曼认为实存主要包括故事主体和背景。在数据探索阶段可对数据项及其描述性信息进行加工处理,抽取数据项中的主体、时间和地点等信息, 并结合相关文献和政策文本进行背景信息的加工。数据探索是一个多次迭代的过程, 可能需要对分析方法或数据进行多次调整, 最后进行数据可视化映射。
3.2 目标层
目标层主要是确定叙事者想要传达的特定信息,即叙事意图, 反映了叙事者对故事内容的建构。叙事目标与数据探索密切相关, 目标可能在数据探索时形成, 也可能为了明确目标而进行数据探索。数据探索过程中发现的故事点为数据故事构建提供了内容, 基于发现的故事点可能会提出新的问题, 为了寻找支持性证据会再次返回数据探索。叙事者对叙事目标进行分析并筛选故事点, 将目标具体转换为几个问题, 每个问题对应特定子目标, 回答问题的故事点数量不定。筛选后的问题以及回答问题的故事点是叙事者想要表达的内容, 即叙事结构中的内容质料层面。
3.3 结构层
结构层主要确定数据故事的表达形式。数据在呈现给受众前, 需要将数据相关的内容进行组合,形成一个富有逻辑的、科学的故事[28] 。数据故事由若干故事情节构成[36] , 情节生成与排序直接影响受众对故事的感知, 需要叙事者具有故事表达能力[37] 。故事情节包含若干故事片段, 数据故事片段组织以目标层中的问题和回答问题的故事点为基础, 包含特定问题及回答问题的若干故事点。故事片段的组合使故事情节得以生成。故事情节产生后, 需对故事情节进行序列化, 将故事情节嵌入叙事结构, 典型的叙事结构如表1 所示。
3.4 呈现层
呈现层主要是将结构层的结构化故事以视觉形式呈现给受众, 数据故事视觉呈现媒介包括静态图表、幻灯片、数据漫画、视频、交互式仪表板、静态海报等。目前, 交互式仪表板是数据故事呈现的流行方式, 主要有两个原因: 一是仪表板技术快速发展, 能够满足叙事者进行叙事表达的需求。二是仪表板支持用户交互, 能够很好地平衡用户驱动和作者驱动之间的关系[2] 。一个仪表板包含若干组件, 仪表板组件包括文本、图片、地图等形式, 支持向下钻取、缩放等操作。大多数故事片段的表达都包含可视化部分与文本内容, 文本内容主要包括注释和旁白, 起到解释、强调和避免歧义的作用[4] 。在数据故事中并不是所有的故事内容都同等重要,叙事者需要对重要内容进行凸显, 优先吸引读者注意力, 如心理学中的视觉显著现象[38] , 通过颜色、大小和方向等视觉特征中的异常值优先吸引注意力。故事内容呈现时需遵循视觉动线(从左至右, 从上到下)的规律进行页面设置和故事内容引导[39] 。
4 实例分析
为了验证数据故事模型对数据故事制作的指导性, 本文基于已构建的数据故事模型制作山东省农业碳排放数据故事, 主要步骤包括数据探索、明确叙事意图、故事内容结构化和故事呈现4 个步骤。
4.1 数据探索
4.1.1 数据来源
农业是碳排放的主要贡献源[40] , 实施农业低碳生产对于促进双碳目标的实现具有重要意义。山东省是我国的农业大省, 2021 年农业总产值为11 468 01亿元, 其中畜牧业和种植业共占比76%。综合考虑数据的可获得性以及相关文献中的农业源及影响因子选取, 确定从种植业和畜牧业两个维度采集山东省农业碳排放源数据(以下简称碳源数据)。其中, 种植业包括化肥折纯量、农膜当年实际使用量、农药当年实际使用量、农用柴油量、当年实际灌溉面积和当年播种面积6 类碳源数据; 畜牧业主要包括牛、羊、猪以及家禽的年饲养量数据。碳排放影响因素数据包括农地规模经营、城镇化水平、机械化水平、农业财政支持4 个维度, 分别涉及农作物播种面积和农业从业人员数据、城镇人口和总人口数据、农业机械总动力和农作物总播种面积数据、农林水事务支出和农林牧渔总产值数据等。数据来自山东省统计局及各地级市统计局历年的《统计年鉴》, 选取2011—2021 年山东省17 个地级市的上述10 类碳源数据和4 类影响因素数据, 初始数据共计2 052条。
4.1.2 数据处理与探索
首先, 清洗掉丢失以及无关内容, 因2012 年灌溉数据丢失, 故将其排除在分析之外; 其次, 进行数据合并和单位统一, 如莱芜市于2019 年并入济南市, 故将2019 年之前莱芜市的碳源数据归并到济南市; 第三, 各类碳源的排放系数不同, 导致这些碳源数据并不能直接反映碳排放量, 需要对数据进一步加工, 依据相关文献中的公式将各类碳源数据转化为碳排放量数据[40-41] ; 最后, 对数据进行探索, 发现山东省农业碳排放数据的相关故事点,如对碳排放量进行时序分析得出种植业、畜牧业、农业总排放量趋势和峰值点时间, 对各类碳源的排放量进行对比分析发现饲养牛、羊以及化肥使用是农业碳排放的三大来源, 使用相关分析方法探索碳排放量的影响因素, 发现城镇化水平、农地规模经营均能直接抑制碳排放量等。数据探索后将所发现的故事点进行可视化映射。
4.2 明确叙事意图
本故事的叙事目标是山东省农业碳减排。首先,围绕数据探索阶段发现的故事点进行目标分析和故事点筛选, 将目标转化为以下几个问题: 数据故事背景、山东省农业碳排放时序特征、结构时序特征、空间特征、影响因素、行动方案; 其次, 结合数据探索的故事点对这些问题进行回答; 最后, 确定该故事的主要故事片段包括山东省农业碳排放的背景、时空特征以及农业碳减排措施。山东省农业碳排放数据故事点目标转化示意图, 如图4 所示。
4.3 故事内容结构化
将目标转化为问题及相应故事点, 形成故事片段, 对故事片段进行组合生成故事情节。本研究选择亚里士多德结构对情节进行组合排序, 该结构主要包括“阐述、上升故事情节、高潮和方案解决”4 个逻辑递进的内容[42] 。将山东省农业碳排放数据故事结构分为背景介绍(阐述)、主要情节汇集(上升阶段)、影响因素(高潮)和碳减排建议(方案解决)4 个阶段, 如图5 所示。
阐述阶段介绍当前碳排放的相关背景, 如全球气候变暖的危害、政府为应对碳排放出台的政策文件等, 让受众对故事有初步了解; 上升阶段则是汇集当前碳排放的时序特征、结构时序特征和空间特征3 个情节, 让受众了解山东省农业碳排放的变化趋势、结构以及空间分布等特点; 高潮阶段展示碳排放影响因素, 为农业碳减排提供理论依据, 如城镇化的推进使得农村劳动力减少, 剩余劳动力转向规模经营, 借助机械采取科学种植方式, 从而使得碳排放减少; 方案解决阶段则提出相关的农业碳减排建议或行动方案, 如针对化肥使用过量且利用率低的问题, 实施化肥减量增效, 普及科学施肥方法等。
4.4 故事呈现
采用交互仪表板呈现数据故事, 根据故事结构将故事呈现界面分为4 部分: 背景介绍、情节汇集、影响因素、农业碳减排建议。其中, 情节汇集包括山东省农业碳排放时序特征、结构时序特征以及空间特征, 这3 个情节为引出影响碳排放的因素作铺垫, 三者没有顺序之分, 读者可按需求点击不同导航按钮查看情节。数据故事的呈现能够实现缩放、滚轮滑动、筛选、跳转等互动功能。数据故事中的特殊或重点内容使用符号、方向等视觉特征进行标记, 吸引受众注意力。情节标题是情节内容的高度凝练, 将标题放在仪表板的上方, 符合视觉动线规律。故事情节大多都辅以旁白和注释, 能够使读者更快地理解故事内容。山东省农业碳排放数据故事局部示意图, 如图6 所示。
5结语
数据故事已成为数据洞察和数据价值发现的最优方式之一, 数据故事模型对故事的生成和呈现具有指导意义。本文基于经典叙事结构理论构建数据故事模型, 首先分析了数据故事的结构要素; 其次根据结构要素分析结果进行数据故事模型构建; 最后基于已构建的数据故事模型进行数据故事实例创作, 验证了该模型的可行性。在理论层面, 本研究厘清了数据故事内部结构和结构要素, 丰富了数据故事理论; 在实践层面, 从原料层、目标层、结构层和呈现层构建数据故事模型, 为数据故事的创作提供流程参考, 提升了数据呈现的可读性、可理解性和逻辑性。目前, 基于叙事学视角构建数据故事模型的研究文献较少, 有关理论与技术尚不成熟。本文仅侧重于故事模型构建的理论研究和可行性探讨, 构建的模型为数据故事通用模型, 后续可进一步探究不同领域数据故事模型的构建, 如政府开放数据故事模型、政民互动数据故事模型或科研数据故事模型等。
