Sora:文生视频模型的突破与启示
2024-06-21
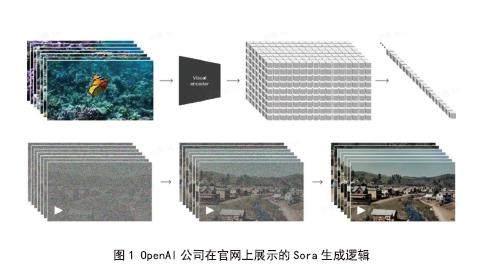
Sora是OpenAI继文字、图像之后,在内容生成领域的又一创新,强大的视频生成和模拟能力标志着AI在多模态领域实现重大突破。Sora的视频生成不仅仅是对人类语言的理解,而且是人对AI世界规律的更深认知
2023年是属于大语言模型的一年,而2024年,以Sora为首的多模态大模型,将带领我们走向超乎想象的远方。Sora是OpenAI继文字、图像之后,在内容生成领域的又一创新,强大的视频生成和模拟能力标志着AI在多模态领域实现重大突破。
从技术原理看,Sora模型不是一次全新的底层技术创新,而是大语言模型技术的集大成者
目前,OpenAI没有公布Sora的训练细节,只在技术报告中提到Transformer(谷歌团队2017年提出的一种经典模型)、扩散模型、Patch等,这些都不是新技术。初步判断,Sora不是全新的底层大模型,而是建立在OpenAI一系列坚实的技术沉淀上,包括视觉理解Clip、Transformers模型和ChatGPT、Video Caption(DALL·E3)等,是基于“语言大模型训练思路+模型创新”的一次进步。
深度神经网络依然是Sora的基础,将视觉数据转化为统一的表示形式,运用带有Transformer框架扩散模型Diffusion,给定输入的噪声块+文本prompt,来预测原始的“干净”分块,AI从数据中学习并执行复杂的任务。同时,OpenAI引入了视觉领域的Patch,将各种不同尺寸、分辨率、长宽比、时长的视觉数据转化为统一的表示形式,极大扩展了训练样本的来源和数量,提升了丰富度。类似语言模型,经过大规模样本训练后,Sora展现出模拟现实世界某些属性的“涌现”能力。同时,根据用户喜好,Sora运用DALL·E3等“文生图”应用,修改出不同的视频风格。
Sora可生成分辨率1920×1080的视频,也可基于静止图片创建视频,使用新素材扩展现有素材。比如,用户给它一张森林图片,它可以帮你加上鸟、兽、人;给它一张汽车行驶图,它能加上道路、交通灯、沿途建筑物和风景。Sora类似语言模型,经过大规模样本训练后,展现出模拟现实世界的“涌现”能力。
从发展进程看,Sora是视频领域的ChatGPT时刻
Sora目的是创建能够“模拟物理世界”的通用工具,Sora离真正的“世界模拟器”还有相当的距离,效果虽然不完美,但证明了这条路的可行性。Sora的视频生成不仅仅是对人类语言的理解,而且是人对AI世界规律的更深认知。
Sora目的是创建能模拟物理世界的通用工具
在Sora之前,并不清楚长期的一致性能否独立出现,或者它是否需要复杂的主题驱动生成流水线,甚至是物理模拟器。GPT—4必须隐式地学会Python基本知识,才能生成Python代码,并不是直接存储符号化的Python语法知识。同样,Sora必须学习一些隐式的文本到3D、3D变换、光线追踪渲染和物体运动等物理规则,才能精确地模拟视频像素。
Sora是通过数据学习和直观感受来实现,模拟现实世界中的人、动物和环境,不需要对三维空间、物体等有任何特定的人工建模,而纯粹由大规模的数据驱动。OpenAI把视频生成模型称作“世界模拟器”,认为持续扩展视频模型是一条模拟物理和数字世界的希望之路。当然,Sora离真正的“世界模拟器”还有相当的距离,其技术路径是否正确,业界还有不同声音。
Sora在生成效果上与之前的技术拉开了显著差距
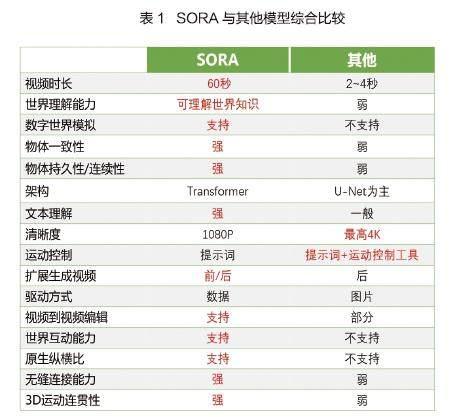
在视频时长上,以前的视频生成模型,只能生成固定尺寸、时长几秒钟的视频。Sora能生成各种尺寸视频(最大2048×2048),时长达到60秒。
在视觉效果上,Sora同样表现优越,视频中的人物和场景元素能够在三维空间中保持连贯移动,并能有效处理短距离和长距离的依赖关系。同样,Sora能在同一视频样本中多次展示同一角色,确保其外观贯穿始终。甚至能模拟出简单的影响世界状态的行为。
值得注意的是,Sora的关注点是创建模拟物理世界的通用工具,并不特别注重画质、细节,但其视觉效果仍然非常优秀。
从价值意义看,Sora将重新定义人类与AI的交互关系
“真实”和“虚拟”的界限将变得模糊
Sora不仅仅是“视频模型”,而且是“世界模拟器”,是OpenAI“教AI理解和模拟运动中的物理世界”计划中的一步,目的是帮助人们解决需要现实世界交互的问题。
凭借以假乱真的视频生成能力,Sora将为短视频和游戏行业带来新机遇。同时,传统影视制作和商业模式将面临重塑,可能会减少对人类演员、编导等创造性角色的需求。同时,基于AI技术强大的图片和视频生成能力,可能加剧虚假信息的泛滥,因此需要多角度地思考“真实”与“虚拟”交融带来的影响。目前,Sora正在进行评估关键领域潜在危害或风险的工作,OpenAI还邀请了一批视觉艺术家、设计师和电影制作人加入,届时Sora的能力将进一步完善。
人与AI之间的新交互与新关系
GPT和Sora的出现彻底变革了人机交互模式,让用户通过直接说话与AI交流,让自然语言交互成为可能,极大地提高了可操作性。相较于传统的图形用户界面,自然语言是人类最自然的交互方式,几乎不需要学习,且交互效率更高。
新的交互模型会如何影响组织中的人机协同?人类与机器的关系将何去何从?技术进步既是挑战也是机遇,需要更多地思考如何在AI时代定位自己,如何将AI技术为我所用。AI的意义在于让更多人从简单重复的劳动中解脱出来,以更高的效率去创造更大的价值。当自然语言的交互模式极大降低AI技术的应用门槛,任何人都能使用AI辅助自己的工作。
AI离物理世界更近了一步
GPT展现了强大的文本处理能力,但主要处理单一模态数据,而Sora预示着多模态模型在模拟物理世界时的巨大潜能。当然,目前的AI工具精细度仍然有限,如何高效地与AI沟通,将是未来必须学习和具备的技能。OpenAI给出简单的指令,如“一个身穿蓝色牛仔裤和白色T恤的女人在南非约翰内斯堡愉快地散步,在一场冬季风暴中”,Sora就能生成一个非常真实、流畅的短视频,而女人肤色、路人等细节都不在指令中。
从体验和娱乐角度看,Sora生成的视频非常惊艳且有趣,但生成具有科普性或商业化等专业性较高的视频时,仍需要满足更多内容和细节,一方面用户须提供尽可能详细的指令。另一方面,AI不能完全理解并实现用户提出的每一个指令细节。以GPT为例,如果给出一个较为复杂的指令,有时候GPT就会“自主”忽略指令中的几个细节要求,甚至似是而非。
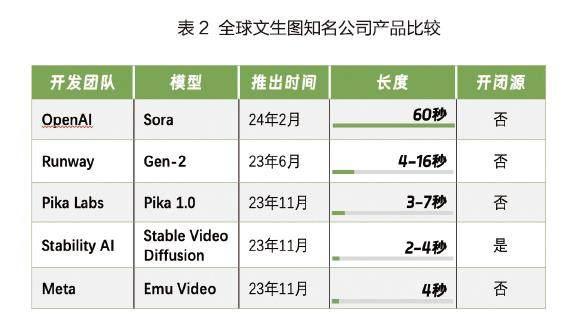
从国际竞争来看,国内企业与Sora有较大差距,但追赶的技术路径清晰
Sora具备多项创新功能,同业处于追赶状态
Sora具备多项创新:
一是Sora可输出长达60秒的一镜到底的文生视频,准确性、多样性和稳定性均有所提升;
二是多镜头切换,Sora可在单个视频中设计出多个镜头,并在多角度的镜头切换中能保持人物、逻辑等一致性;
三是Sora在理解用户Prompt(输入到文生图模型的文字)的同时,也同步分析该Prompt中事物身上的物理规律,如OpenAI展示的视频中,汽车在山路上的颠簸、火车车窗上的倒影等镜头符合物理规律,视频更接近于人类现实拍摄。
Sora的技术路径具备可复制性
Sora所依赖的技术,如Transformer和扩散模型、视觉理解模型、语言模型是过去几年广泛研究且公开发表的技术,更多是一种工程上的应用和优化,国内企业具备赶超的能力。如国内企业的扩散模型技术已广泛应用到图像生成、视频生成领域;视觉理解领域的零样本图像描述、通用视觉问答、文本导向的视觉问答、细粒度视觉定位等领域能力,整体上已接近GPT—4V,语言模型能力与GPT—4Turbo接近。但如何找到实现高质量文生视频的工程化方法和路径,仍需要艰辛的探索和试错。
Sora之后预示着大模型需要更多人才、算力和数据,这将加速AI基础大模型供给侧收敛的步伐
业界一种猜测是,GPT5具有接收全模态输入、产生全模态输出的能力,具备对物理世界的理解和建模能力,这也是Sora需要具备的能力。Sora就是GPT5的一部分,它们共同成长、演进和迭代。从ChatGPT到Sora,大模型为科技公司不断带来充满前景的新赛道,进一步验证了基础大模型产业是技术、资本、人才、算力、数据高度密集型产业。
Sora进一步提高了基础大模型的门槛,这意味着进入AI基础模型的竞争赛道,企业需要做好人才、算力、数据和资本长期高强度投入的准备,并能构建大模型商业化可行的路径和商业模式。这进一步加速了AI基础大模型供给侧收敛的步伐。从目前来看,美国正在形成以3家AI基础大模型为主导的市场竞争格局。
2023年中国涌现了254个大模型,有人说,中国迎来了“百模大战”。事实上,中国不存在“百模大战”,可能连“十模大战”也不存在。这就像几百人参加的田径赛场上,有人掷铁饼,有人扔标枪,有人在跳高,有人跑百米,但能进入10项全能的只有3—5个。未来3—5年,中国真正能在AI大模型赛道上具备追赶美国GPT技术步伐的企业,将是非常有限的。
(本文由阿里云科技研究中心供稿)
