基于改进YOLO v5s的温室番茄检测模型轻量化研究
2024-06-03赵方左官芳顾思睿任肖恬陶旭
赵方 左官芳 顾思睿 任肖恬 陶旭

摘要:番茄检测模型的检测速度和识别精度会直接影响到番茄采摘机器人的采摘效率,因此,为实现复杂温室环境下对番茄精准实时的检测与识别,为采摘机器人视觉系统研究提供重要的参考价值,提出一种以YOLO v5s模型为基础,使用改进的MobileNet v3结构替换主干网络,平衡模型速度和精度。同时,在颈部网络引入Ghost轻量化模块和CBAM注意力机制,在保证模型检测精度的同时提高模型的检测速度。通过扩大网络的输入尺寸,并设置不同尺度的检测网络来提高对远距离小目标番茄的识别精度。采用SIoU损失函数来提高模型训练的收敛速度。最终,改进YOLO v5s模型检测番茄的精度为94.4%、召回率为92.5%、均值平均精度为96.6%、模型大小为7.1 MB、参数量为3.69 M、浮点运算(FLOPs)为6.0 G,改进的模型很好地平衡了模型检测速度和模型识别精度,能够快速准确地检测和识别复杂温室环境下的番茄,且对远距离小目标番茄等复杂场景都能实现准确检测与识别,该轻量化模型未来能够应用到嵌入式设备,对复杂环境下的温室番茄实现实时准确的检测与识别。
关键词:番茄;小目标检测;YOLO v5s;轻量化网络;注意力机制
中图分类号:S126 文献标志码:A
文章编号:1002-1302(2024)08-0200-09
收稿日期:2023-06-05
基金项目:江苏省高等学校基础科学(自然科学)研究面上项目(编号:22KJB140015);江苏省无锡市创新创业资金“太湖之光”科技攻关计划(基础研究)项目(编号:K20221043);教育部产学合作协同育人项目(编号:220604210140248)。
作者简介:赵 方(1997—),男,山东临沂人,硕士,主要从事嵌入式人工智能。E-mail:zhaofang_1997@163.com。
通信作者:左官芳,硕士,高级工程师,主要从事嵌入式设计研究。E-mail:zgf@cwxu.edu.cn。
近年来,自高性能、低功耗、嵌入式处理器出现以来,越来越多的视觉检测任务可以在嵌入式系统上实现,这使得农业机器人变得更加先进。在智慧农业背景下,用番茄采摘机器人代替人工采摘、降低人工成本、提高劳动生产率成为发展趋势[1]。目前国内外相关文献针对番茄检测算法研究主要分为传统目标检测算法与深度学习目标检测算法。
李寒等使用红绿蓝深度(RGB-D)相机捕捉图像,对图像进行预处理,得到水果轮廓,分离重叠水果的轮廓,并将其拟合成圆圈,将k均值聚类(KMC)与自组织映射(SOM)神经网络算法相结合,对番茄进行识别,结果表明,轮廓提取受到光照的影响,对番茄的识别率仅为87.2%[2]。孙建桐等提出一种基于几何形态学与迭代随机圆的番茄识别方法,利用Canny边缘检测算法获得果实边缘轮廓点,并对果实边缘轮廓进行几何形态学处理,最后对果实轮廓点分组后进行迭代随机圆的处理,试验结果表明,对番茄识别的正确率为85.1%[3],但该研究没有解决自然环境下番茄遮挡严重的问题。
传统番茄检测算法对番茄检测的结果很容易受到光照、遮挡等影响导致番茄识别率低,同时传统识别算法无法较好地达到精度和实时性平衡的要求,难以满足实际需求。
近年来,随着图形处理器(GPU)计算能力的提升,深度学习被广泛应用于各个领域,特别为智慧农业领域带来了创新的解决方案[4]。目前基于深度学习算法的目标检测算法主要可分为2类:one-stage与two-stage。One-Stage目标检测方法的核心思想是使用单个卷积神经网络(CNN)直接处理整个图像来检测物体并预测物体类别,它通常比two-stage更快,代表性的方法有单次多框检测器(SSD)[5]和单次目标检测器(YOLO)[6]。two-stage目标检测方法的核心思想是首先生成候选区域,然后通过卷积神经网络对区域进行分类,代表方法有基于区域的卷积神经网络(R-CNN)[7]、快速区域卷积神经网络(Fast R-CNN)[8]、更快的区域卷积神经网络(Faster R-CNN)[9]、掩膜基于区域的卷积神经网络(Mask-RCNN)[10]。
针对番茄生长环境复杂,枝叶对番茄遮挡影响番茄检测与识别问题,张文静等提出一种基于Faster R-CNN的番茄识别检测方法,结果表明,平均精度达到83.9%,单样本图像处理时间为245 ms[11]。总体来看,该方法检测时间过长且精度不高。为减少光照、遮挡的影响,Yuan等提出了一种基于SSD温室场景樱桃番茄检测算法,试验结果显示,平均精度为98.85%[12]。但该模型耗时过长,难以满足实时性要求。针对夜间光照不足影响检测算法准确性问题,何斌等提出了一种改进YOLO v5的夜间番茄检测模型,通过改进损失函数来构建检测模型,结果表明,该模型的平均精度达到96.8%[13]。但该模型缺乏对枝叶遮挡以及番茄重叠问题的研究。
在复杂温室环境中,番茄果实的姿态、大小、稀疏度和光照条件各不相同,在许多情况下,果实被枝叶严重遮挡,且当前算法对远距离小目标番茄和轻量化番茄检测模型的研究仍然不足。基于以上问题,本研究在自然光条件下收集了未成熟的绿色番茄和成熟的红色番茄图片构建数据集,使用改进MobileNet v3对YOLO v5s主干进行改进,在颈部网络引入Ghost卷积和CBAM注意力机制,并改变网络输入大小和输出网络尺度大小,最后对原损失函数进行改进。
1 建立数据集
1.1 数据集采集
本研究的数据集拍摄于山东省兰陵县温室大棚,拍摄时间为2023年1月5日09:00—16:00。番茄品种为爱吉158,所有图片在距离番茄0.5~2 m 处进行多角度和不同光照条件下拍摄。选择 1 200 張番茄图片,存储格式为.jpg,制作数据集,其中包含不同的光照条件、遮挡、重叠、远距离小目标等复杂环境。
1.2 数据增强
为解决番茄受光照、遮挡等因素的影响,同时为了增强模型对小目标检测能力及模型的鲁棒性和泛化性,防止模型学习与目标无关的信息,避免样本不平衡和过拟合现象,本研究采用数据增强技术[14]扩增数据集容量,对图片进行裁剪、平移、改变亮度、加噪声、旋转角度、镜像操作,使用Lableimg标注成熟的红色番茄和未成熟的绿色番茄。由于绿色番茄在温室环境下和绿色枝叶颜色相似,会造成目标检测模型识别率低甚至漏检的现象,所以本研究通过在数据集中增加绿色番茄图片的比重,提高模型对绿色番茄的识别能力,将1 200张原始图片按照1 ∶4扩展至6 000张图片,训练集、验证集、测试集按照8 ∶1 ∶1进行分配,最终的数据集包含训练集4 800张图片、验证集600张图片、测试集600张图片。对番茄进行图像增强后的结果如图1所示。
2 基于改进YOLO v5s的番茄识别网络
2.1 YOLO v5s算法基本原理
YOLO v5网络包括4种网络模型:YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x。YOLO v5s是其中网络深度和宽度最小的模型,越小的网络模型对移动端的性能要求也越低,符合轻量化、实时性要求,因此本研究选择在YOLO v5s网络模型的基础上进行改进。
YOLO v5s网络分为4个部分:输入、主干网络、颈部和输出。输入端使用马赛克数据增强、自适应锚框计算、自适应图像缩放等方法。
主干网络是一个可以提取图像特征的CNN,它集成了Conv、C3、SPPF和其他特征提取模块用于特征提取,其中Conv是YOLO v5s的基本卷积单元,依次对输入进行二维卷积、正则化和激活操作。C3模块采用残差连接的设计思路,其结构分为2个分支,一支使用了卷积和Bottleneck,另一支仅经过基本卷积模块,将2支进行Concat操作,最后经过基本卷积模块。SPPF是基于SPP(spatial pyramid pooling)空间金字塔池化提出的,速度优于SPP,所以叫SPP-Fast,SPPF模块使用3个不同的池化層,在特征图执行这些池化操作之后,得到的结果将级联在一起,形成一个固定大小的特征图。它可以提高检测精度,并且对不同大小的目标具有很好的适应性。
颈部采用FPN+PAN结构,FPN结构采用自顶向下的方法,利用上采样将高层特征图与低层特征图融合,增强语义特征,提高对不同尺度物体的检测。PAN结构采用自底向上路径增强方法,将低层位置信息传输至高层,实现多尺度特征融合。FPN+PAN结构将提取的语义信息和位置信息融合,大大提高了模型的特征提取能力。
输出端是一个包含3个不同尺度检测头的卷积层,它将网络特征图转换为目标检测结果。
2.2 改进YOLO v5s算法
番茄采摘机器人设计的难点在其视觉系统能否检测和识别番茄目标,但是番茄生长在复杂环境下,番茄采摘机器人面临光照变化、枝叶遮挡、重叠和远距离小番茄难以识别的问题,同时番茄采摘机器人的工作效率与其视觉系统的检测速度和识别精度有直接关系。因此,在复杂的环境下,研究快速、精确的识别和检测番茄果实技术具有重要意义。
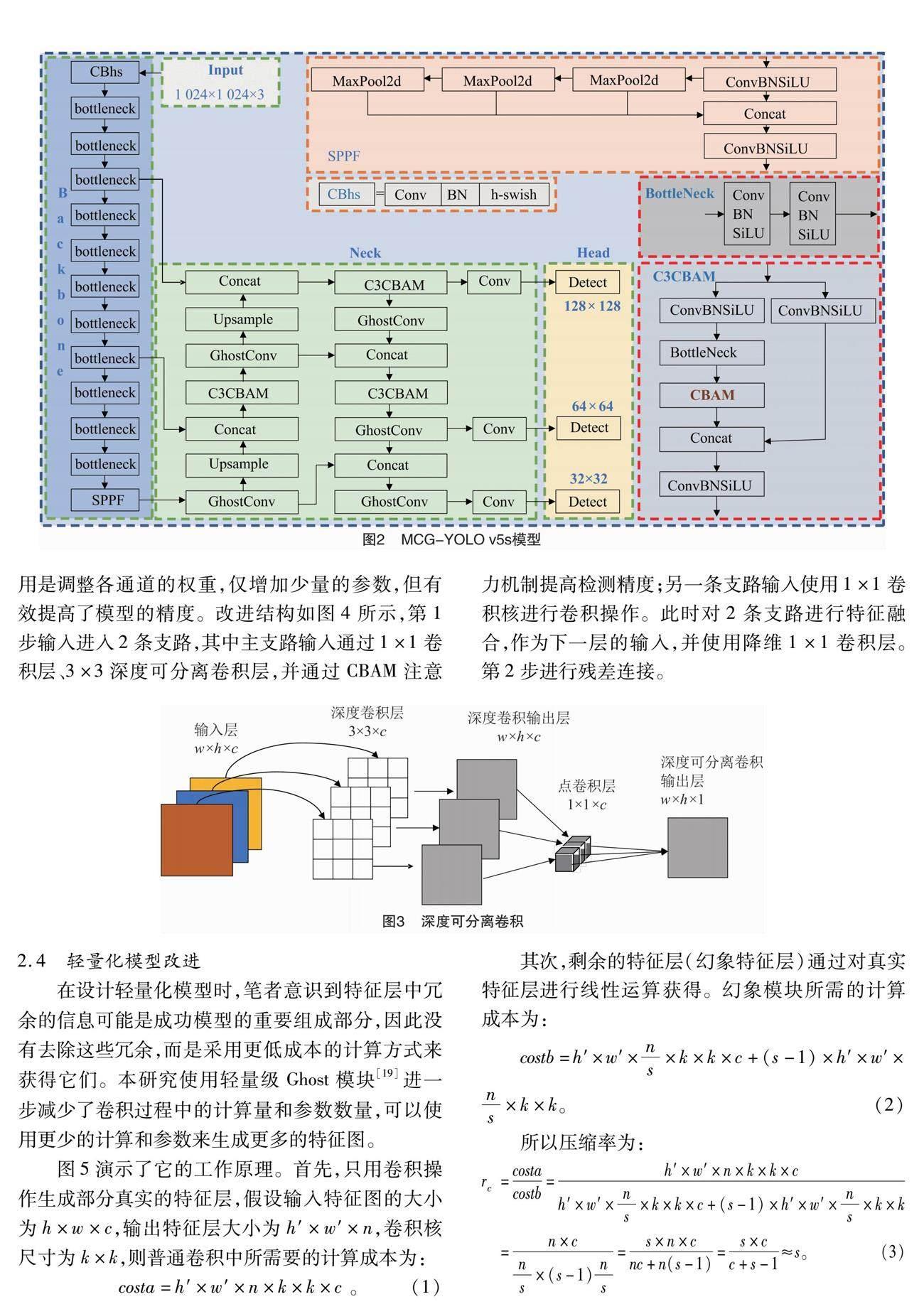
为构建轻量、高效的番茄检测模型,本研究提出了MCG-YOLO v5s轻量化番茄检测模型,模型如图2所示。本研究对以下几方面进行改进:首先,为实现番茄检测速度与识别精度的平衡,使用改进的MobileNet v3取代YOLO v5s骨干网络。其次,为进一步减少模型部署时所需的计算资源,提高模型的检测速度,在颈部通过使用少量卷积与线性变换运算相结合的GhostConv代替颈部网络中的普通卷积,实现进一步轻量化改进;使用C3CBAM代替原始C3,提高网络对番茄特征提取能力,在空间和通道维度上更进一步准确提取番茄特征,使模型能准确定位和识别番茄;YOLO v5网络的输入图像尺寸为640×640,预测头部的输出尺寸为80×80、40×40、20×20,由于远距离小目标番茄图像中目标特征较少,因此本研究为提高对小目标番茄的检测精度,将网络的输入大小从640×640增加到1 024×1 024,将输出的特征图大小分别设置为128×128、64×64、32×32,通过扩大网络的输入大小和改变输出网络尺度的大小,克服远距离图像中番茄小目标漏检问题。最后,SIOU作为改进算法的损失函数进一步提高模型训练的收敛速度。
2.3 主干网络改进
MobileNet v3[15]是一种轻量级的网络架构,它结合NAS(neural architecture search)自动搜索技术和NetAdapt自适应算法来提高模型的性能和效率。首先,MobileNet v3使用了MobileNet v1[16]中的深度可分离卷积(depthwise separable convolution,DSC)。深度可分离卷积运算如图3所示,分为深度卷积(depthwise convolution,DW)和逐点卷积(pointwise convolution,PW)2个步骤,深度卷积通过减少模型的参数量和计算量,使模型轻量化,逐点卷积将每个通道之间的信息进行交互和组合,从而提高网络的表达能力。其次,MobileNet v3通过使用MobileNet v2[17]中的倒残差结构使特征传输能力更好,并通过引入轻量化SE(squeeze and excitation)[18]注意力机制,更有利于通道信息来调整每个通道对应的权重。最后,MobileNet v2将原有的swish函数替换为h-swish激活函数,确保在参数数量一定的情况下,计算量大大减少,有效提高了模型的识别精度。本研究引入MobileNet v3模型主要是为了减少计算量,减小模型的尺寸,提高检测精度。
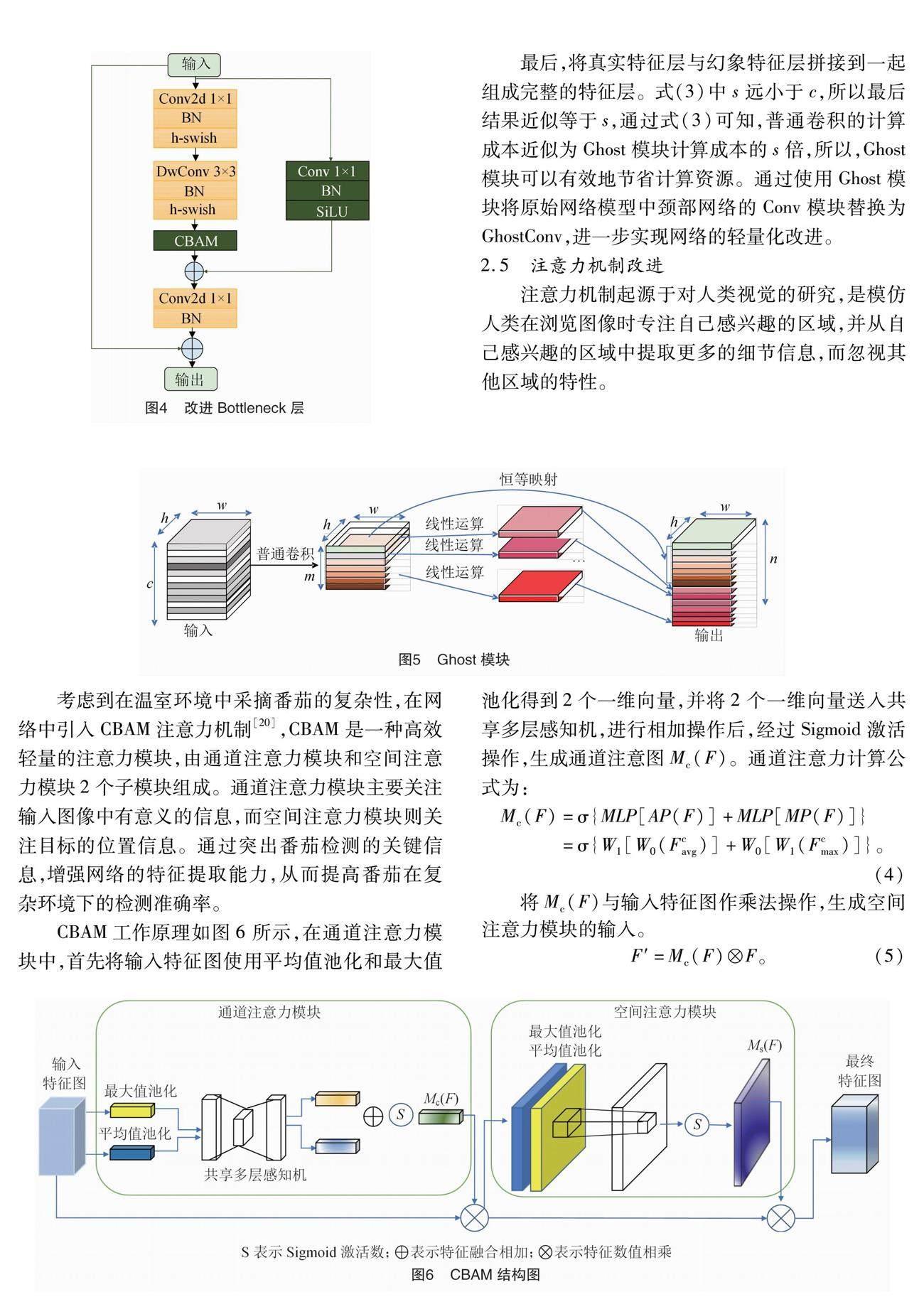
从YOLO v5s中的C3设计模块得到灵感,对原始MobileNet v3的bottleneck增加1个含有1×1卷积层的并行支路,目的是为了提高对小目标番茄的检测精度,提高绿色背景下对绿色番茄特征提取能力,同时,由于2条支路的特征提取方式不同,可以使模型学习到不同的特征,提高模型的表达能力。考虑到CBAM模型将通道维度与空间维度结合,相比于只关注通道维度的ECA模型和SE模型,可以获得更好的结果,所以本研究使用CBAM注意力机制将原MobileNet v3中的SE注意力机制替换,其作
用是调整各通道的权重,仅增加少量的参数,但有效提高了模型的精度。改进结构如图4所示,第1步输入进入2条支路,其中主支路输入通过1×1卷积层、3×3深度可分离卷积层,并通过CBAM注意力机制提高检测精度;另一条支路输入使用1×1卷积核进行卷积操作。此时对2条支路进行特征融合,作为下一层的输入,并使用降维1×1卷积层。第2步进行残差连接。
2.4 轻量化模型改进
在设计轻量化模型时,笔者意识到特征层中冗余的信息可能是成功模型的重要组成部分,因此没有去除这些冗余,而是采用更低成本的计算方式来获得它们。本研究使用轻量级Ghost模块[19]进一步减少了卷积过程中的计算量和参数数量,可以使用更少的计算和参数来生成更多的特征图。
3.4 消融试验
为了验证各个改进模块的作用,本研究进行消融试验。从表1可以看出,该模型轻量化主要是因为使用改进MobileNet v3模块替换原模型主干网络,原模型主干网络中的C3结构有较大参数量,增加了模型的復杂度,而MobileNet v3模块中运用了深度可分离卷积而减少了模型参数量,同时改进的MoblieNet v3增加了1×1卷积模块分支,提高了模型精度,与原始模型相比,均值平均精度提高了1.7百分点,参数减少了2.54 M,浮点运算减少了9.0 G,因此,使用改进MoblieNet v3替换主干网络进行轻量化操作的同时,仍能保证精度。在模型的颈部中使用C3CBAM模块,不但均值平均精度提高了2.8百分点,而且参数减少了0.49 M,浮点运算减少了 1.0 G,所以C3CBAM对提高模型精度起到了很大的作用。同时,在颈部使用Ghost卷积替换普通卷积,均值平均精度提高了2.1百分点,参数减少了0.51 M,浮点运算减少了0.6 G,实现对模型进一步轻量化操作。对原模型的损失函数进行改进后,模型的均值平均精度提高了0.6百分点。将这4项改进融入模型中,与原始YOLO v5s模型相比,均值平均精度提高了6.0百分点,参数降低3.54 M,浮点运算减少了10.6 G。结果表明,MCG-YOLO v5s通过轻量化改进降低了模型的复杂性,对番茄目标具有更好的检测性能。
3.5 对比试验
为了验证本研究提出的轻量化番茄检测模型的性能,选择YOLO v3-tiny、YOLO v4-tiny、YOLO v5s与MCG-YOLO v5s进行比较和测试,所有模型都使用相同的番茄数据集进行训练和测试,选择精度、召回率、均值平均精度、模型大小、参数量和浮点运算作为评价指标,结果见表2。
表2显示,与YOLO v3-tiny、YOLO v4-tiny、YOLO v5s相比,MCG-YOLO v5s模型的精度分别提高6.1、5.8、4.9百分点,召回率分别提高5.8、7.3、3.9百分点,均值平均精度分别提高5.1、6.5、6.0百分点。与轻量化模型 YOLO v3-tiny、YOLO v4-tiny 模型相比,MCG-YOLO v5s模型大小分别减少22.97、17.97 MB,参数量分别减少5.21、4.21 M,浮点运算减少2.6、3.2 G。
MCG-YOLO v5s模型大小为7.1 MB,参数量为3.69 M,浮点运算为6.0 G。结果表明,MCG-YOLO v5s模型体积最小,参数量、浮点运算最小,非常适合部署至算力不高的嵌入式边缘设备,为番茄采摘机器人的视觉系统提供切实可行的参考方案,提高番茄采摘机器人自动采摘番茄的工作效率。
通过YOLO v5s与MCG-YOLO v5s模型对复杂温室环境下的番茄图片检测进行可视化测试,验证MCG-YOLO v5s模型的可行性。
可视化结果如图9、图10所示,对于多果、枝叶遮挡、光照不足的情形,YOLO v5s模型虽然能够检测与识别成熟的红色番茄和未成熟的绿色番茄,但相比于MCG-YOLO v5s模型,YOLO v5s模型的精度低6~20百分点。对光照充足、番茄重叠、背景相似情形,YOLO v5s漏检了图片中的绿色番茄,这是由于绿色番茄与枝叶有相同的颜色,所以增加了模型的识别难度,然而MCG-YOLO v5s对于相似背景的绿色番茄具有更好的特征提取能力,能够准确识别与检测。对于单果情形,从图9、图10中可以看到枝叶严重遮挡了图中的红色番茄,导致YOLO v5s出现漏检的情况,而MCG-YOLO v5s对严重遮挡的红色番茄更友好,在严重遮挡环境下仍能准确识别与检测。对于远距离小目标番茄,YOLO v5s漏检了图片中的红色番茄和绿色番茄;而MCG-YOLO v5s对于小目标番茄具有很强的识别能力,能识别与检测图中的远距离小目标番茄,虽然图中漏检了几个小目标番茄,但相比于YOLO v5s模型,MCG-YOLO v5s对小目标番茄的识别能力明显提高了。
4 总结
本研究为实现在复杂温室环境下对番茄进行准确实时检测,提出一种MCG-YOLO v5s的番茄检测模型,通过对YOLO v5s模型的改进,提高模型检测速度与识别精度。首先是对数据集进行数据增强,提高对小目标番茄的检测能力及模型鲁棒性。其次在YOLO v5s中使用改进的MobileNet v3,改进后的MobileNet v3结构很好地平衡了番茄检测模型的速度与精度;同时,使用Ghost模块减少番茄检测模型计算量,进一步实现模型轻量化,为提高模型的识别精度,引入CBAM注意力机制。最后对原损失函数改进,引入SIoU Loss,提高模型精度,同时也加快了模型的收敛速度。最终试验结果表明,MCG-YOLO v5s的番茄检测模型比原YOLO v5s模型,模型大小减少50.5%,参数量减少49.0%,浮点运算减少63.9%,均值平均精度提升6.0百分点。通过可视化检测结果可知,MCG-YOLO v5s模型对遮挡严重番茄、重叠番茄、相似背景、小目标番茄的检测与识别都有改善,鲁棒性较好,检测效果明显优于未改进YOLO v5s,改进后的模型适用于复杂环境下对番茄进行实时检测的任务,满足对番茄准确识别且实时检测的要求。
参考文献:
[1] 王海楠,弋景刚,张秀花. 番茄采摘机器人识别与定位技术研究进展[J]. 中国农机化学报,2020,41(5):188-196.
[2]李 寒,陶涵虓,崔立昊,等. 基于SOM-K-means算法的番茄果实识别与定位方法[J]. 农业机械学报,2021,52(1):23-29.
[3]孙建桐,孙意凡,赵 然,等. 基于几何形态学与迭代随机圆的番茄识别方法[J]. 农业机械学报,2019,50(增刊1):22-26,61.
[4]封靖川,胡小龙,李 斌. 基于特征融合的目标检测算法研究[J]. 数字技术与应用,2018,36(12):114-115.
[5]Liu W,Anguelov D,Erhan D,et al. SSD:single shot MultiBox detector[M]//Computer Vision-ECCV 2016.Cham:Springer International Publishing,2016:21-37.
[6]Redmon J,Divvala S,Girshick R,et al. You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,2016:779-788.
[7]Girshick R,Donahue J,Darrell T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.ACM,2014:580-587.
[8]Girshick R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. ACM,2015:1440-1448.
[9]Ren S Q,He K M,Girshick R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[10]He K M,Gkioxari G,Dollár P,et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision. Venice,2017:2980-2988.
[11]張文静,赵性祥,丁睿柔,等. 基于Faster R-CNN算法的番茄识别检测方法[J]. 山东农业大学学报(自然科学版),2021,52(4):624-630.
[12]Yuan T,Lyu L,Zhang F,et al. Robust cherry tomatoes detection algorithm in greenhouse scene based on SSD[J]. Agriculture,2020,10(5):160.
[13]何 斌,张亦博,龚健林,等. 基于改进YOLO v5的夜间温室番茄果实快速识别[J]. 农业机械学报,2022,53(5):201-208.
[14]Shorten C,Khoshgoftaar T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data,2019,6(1):60.
[15]Howard A,Sandler M,Chen B,et al. Searching for MobileNet v3[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul,2019:1314-1324.
[16]Howard A G,Zhu M,Chen B,et al. Mobilenets:effificient convolutional neural networks for mobile vision applications[EB/OL].(2017-04-17)[2023-04-24]. https://arxiv.org/abs/1704.04861.
[17]Sandler M,Howard A,Zhu M L,et al. MobileNet v2:inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,2018:4510-4520.
[18]Hu J,Shen L,Sun G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,2018:7132-7141.
[19]Han K,Wang Y H,Tian Q,et al. GhostNet:more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,2020:1577-1586.
[20]Woo S,Park J,Lee J Y,et al. CBAM:convolutional block attention module[M]//Computer Vision-ECCV 2018.Cham:Springer International Publishing,2018:3-19.
[21]Zheng Z H,Wang P,Ren D W,et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics,2022,52(8):8574-8586.
[22]Zheng Z H,Wang P,Liu W,et al. Distance-IoU loss:faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):12993-13000.
[23]Gevorgyan Z. SIoU loss:more powerful learning for bounding box regression[EB/OL]. (2022-05-25)[2023-04-24]. https://arxiv.org/abs/2205.12740.
