基于特征融合Transformer的EfficientNet v2网络对马铃薯叶片病害的识别
2024-06-03孙剑明毕振宇牛连丁
孙剑明 毕振宇 牛连丁

摘要:马铃薯叶片病害是影响马铃薯质量和产量的主要因素,为了能够快速准确地识别马铃薯叶片病害并采取对应的防控和救治措施,本研究提出一种新型马铃薯叶片病害识别方法。该方法利用EfficientNet v2网络提取图像特征,通过4个不同尺度的网络层进行金字塔融合,从而捕捉不同尺度下的图像细节和上下文信息,并在金字塔融合中的每个下采样环节都添加1个CBAM注意力机制模块,且每个CBAM模块后都加入Vision Transformer的Encoder模块进行特征增强,帮助提升所提取特征的丰富性和抽象能力,最后使用softmax进行分类。研究提出的模型识别准确率达到98.26%,相比改进之前提升3.47百分点,且其loss收敛更快,宏平均值与加权平均值都有明显提升。消融试验表明,该模型在各项指标上的表现最优,超过基线模型和融合模型,大幅提高图像分类识别任务模型的性能表现。该方法可有效提高病害区域的识别能力和检测准确率,且能在强干扰的环境下做到高精度识别,具有良好的鲁棒性和适应性,同时能解决病害识别中泛化能力弱、精度低、计算效率低等问题。
关键词:农业;马铃薯叶片病害;图像识别;卷积神经网络;特征融合;Transformer模型
中图分类号:TP391.41 文献标志码:A
文章编号:1002-1302(2024)08-0166-10
收稿日期:2023-05-15
基金项目:国家自然科学基金(编号:32201411)。
作者简介:孙剑明(1980—),男,山东黄县人,博士,教授,主要从事模式识别智慧农业、机器视觉、图像信息处理及自动控制方向的研究。E-mail:sjm@hrbcu.edu.cn。
通信作者:毕振宇,硕士研究生,主要研究方向为模式识别智慧农业。E-mail:15776480171@163.com。
马铃薯因高产稳产、适应性广、营养成分全、产业链长,受到全世界的高度重视,随着需求量的增加,其种植面积也在不断扩张,同时马铃薯的病害发病率也在不断增高,直接影响马铃薯的产量和质量。但是,对于大面积农田种植的马铃薯,单靠人力来识别其病害,费时费力、效率低下。及时、准确识别马铃薯病害,尽早做出相对应的防控和救治措施,从而减少农药使用,减轻对田地的伤害,可在保证产量的同时提高质量,并减轻农户的经济支出[1]。
近年来,卷积神经网络在不断地改进和创新。卷积神经网络是神经网络中的一个分支,在这个分支下有很多优秀的图像分类检测模型[2]。在图像识别任务中,从最早的LeNet-5一直发展到2017年ImageNet大赛冠军模型SeNet[3-4]。在目标检测任务中,从使用selective search类暴力搜索模型 Fast RCNN,到现在已可利用APN构建快速模型YOLO v3[5-6]。Liu等提出一种基于DCNN的苹果树叶病识别方法,对4种常见苹果叶病在给定样本数据集进行试验,结果显示模型具有较快的收敛速度和较高的准确度[7]。Zhang等利用AlexNet模型构建全局池化扩张卷积神经网络,为减少训练时间和提高识别精确度,将全连接层替换为全局池化层以增加卷积感受域,采用扩张卷积层以恢复空间分辨率,完成6种常见黄瓜叶片的疾病识别[8]。Too等直接对VGG16、Inception-v4、ResNet、DenseNet 网络调优,将这些神经网络用于训练和测试PlantVillage 图像集中 14 种植物的病害图像,并对比在不同迭代次数下的试验结果[9]。郭小清等提出了一种多尺度检测的卷积神经网络模型,可以在一定程度上缓解图像数据稀疏的问题[10]。任守纲等利用VGGNet计算多分类交叉熵损失,对番茄叶病害进行分类训练,实现植物叶部病斑分割和病害种类识别,构建基于反卷积引导的 VGG网络模型[11]。
2021年,钟昌源等融合不同水平特征构建新模型,该模型在作物病害叶片语义分割的效率和准确性之间具有良好的平衡[12]。彭红星等提出一种基于多重特征增强与特征融合的SSD模型,能够更精准有效地检测无人机拍摄的荔枝图像,可为小目标农作物的检测开拓思路[13]。受Transformer模型在自然语言处理领域成功应用的启发,Transformer模型视觉转换器(ViT)在许多计算机视觉基准测试中取得了很好的结果;Borhani等提出一种基于ViT的轻量级深度学习方法,用于实时自动化分类植物病害[14-15]。
上述利用各神经网络模型虽然取得了较好的识别精度,但计算效率、高精度、泛化能力仍有提升空间。本研究以马铃薯的健康叶片和患有晚疫病、早疫病的叶片为研究对象,在EfficientNet v2网络中加入金字塔特征融合,并结合CBAM注意力机制和Vision Transformer的Encoder模块,提高对特征的判断和利用能力,在分类决策过程中更加准确可靠。研究设计的模型具有高效的特征提取能力和加权融合能力,同时也在模型轻量化方面有很好的表现。
1 马铃薯叶片病害数据集
1.1 数据集介绍
试验所用到的数据集源于Kaggle网站上基于PlantVillage的公共数据集。PlantVillage是一个公开的农作物病害数据集,其中针对马铃薯叶片的病害类别有早疫病、晚疫病2种疾病,原数据集图片中包含早疫病叶片1 000张、晚疫病叶片1 000张、健康叶片152张。试验先对数据集进行数据增强,按照8 ∶2比例将其分成训练集、测试集。同时将数据集中的原始图像归一化为 256×256×3,使其適应模型的输入。PlantVillage数据集中的部分样本图像如图1所示。
1.2 数据预处理与数据增强
预处理能优化图像的识别效果,所以在大多数图像研究中都会加入预处理这个过程。在获取数据的过程中,会产生各种影响因素,比如数据缺失、噪声的产生、试验不均衡等。故使用深度学习来进行图像识别分类预处理是十分必要的,可以降低环境因素对图像的影响。
对数据集图像进行遮挡和调暗处理,以增加图像的复杂性,可以对模型的鲁棒性进行比较全面的提升。在实际应用中往往会遭遇到各种因素的干扰,如光照条件的变化、遮挡、各种噪声等,这些因素会导致原始图像的特征信息发生变化,使得模型的性能下降。通过数据增强方法,模拟真实情况下的图像,增加模型训练的难度,从而可以使模型学习到更丰富的特征信息,提高模型的识别能力,增强模型的鲁棒性。
进行数据增强时,将调暗系数设置为0.2,以创造一个更加黑暗的环境,同时再对数据集图片进行随机遮挡处理,遮挡概率设置为0.5,遮挡框(相对于图片大小)最小为0.02,最大为0.4,遮挡框的最小、最大宽高比分别设置为0.3、3.3,经数据增强处理后的数据集中包含早疫病2 000张,晚疫病2 000张,健康叶片304张。部分增强图片如图2所示。
2 模型与方法
2.1 EfficientNet v2网络
EfficientNet v2是新一代高效神经网络模型,由Google Brain在2021年提出。该模型采用Compound Scaling、多阶段、优化高级模块、EMA权重平均等多项创新技术,实现更高的准确度和效率,同时具备更少的参数。Compound Scaling综合考虑深度、宽度、分辨率的缩放,实现更好的性能和更高的能效比;多阶段采用不同的深度、宽度、分辨率,提升模型性能;优化高级模块则加强特征提取和模型优化。此外,EfficientNet v2还采用大量的进阶优化技术,如Swish激活函数、 Squeeze-and-Excitation模块、EMA权重平均等,以提高模型的性能和泛化能力。通过这些创新技术的引入,EfficientNet v2在图像分类、目标检测、分割等各个领域的任务中都能取得出色表现,成为当前最先进和高效的神经网络模型之一[16-17]。
EfficientNet v2-B0是EfficientNet v2模型系列中的基础模型,相比于EfficientNet v2-S等其他模型,它拥有更少的层数和更小的参数量,因此计算速度更快,内存消耗更少,训练速度更快,能够在更为复杂的计算任务中获得更好的表现。研究采用EfficientNet v2-B0网络作为基线网络进行试验,其网络结构如表1所示。
EfficientNet v2-B0采用MBConv3、MBConv5结构,包括具有不同变化的多个阶段和不同数量的MBConv层,以提取不同级别的特征,并逐步提高模型的深度和宽度。模型精度和推断速度的升级效果得到显著提高,同时适用于更小的设备。EfficientNet v2-B0网络结构如图3、图4所示。
2.2 多尺度特征融合
多尺度特征融合是一种将不同尺度的特征图进行融合的方法,用于提升模型在各种尺度下的检测和识别性能。在图像处理方面,多尺度特征融合广泛应用于目标检测、图像分类、语义分割等任务中,模型可以在多种尺度下更好地捕捉图像中的物体信息。金字塔特征融合是一种常见的多尺度特征融合方法,其思想是通过构建一组不同尺度的特征图,从而提供更加全面和丰富的图像信息,使得模型具有更好的鲁棒性和泛化能力[18]。
金字塔特征融合可以通过对原始图像进行多次下采样(或上采样),将不同尺度的特征图进行融合,得到整个金字塔中所有尺度的特征图。金字塔特征融合的优点在于,它可以通过构建一组不同尺度的特征图,从而提供更加全面和丰富的图像信息,使得模型具有更好的鲁棒性和泛化能力[19]。
本研究提取MBConv3模块的第1个Swish激活层block2b_expand_activation(64×64×128)、MBConv5模块的第1个Swish激活层block4a_expand_activation(32×32×192)、MBConv5模块的第2个Swish激活层block6a_expand_activation(16×16×672)、top_activation(8×8×1 280),金字塔特征融合结构如图5所示。
2.3 CBAM注意力机制
CBAM(convolutional block attention module)是一种注意力机制模块,它可以自适应学习特征图中不同部分的重要程度,通道注意力、空间注意力机制都是CBAM模块用于提高图像特征表示的有效方法。这些注意力机制不仅可以识别有用信息,还可以抑制无关信息。通过学习每个通道和空间位置的重要性,注意力机制可以使网络更好地识别输入图像中的关键特征,从而提高模型的性能[20]。CBAM模块结构如图6所示。
CBAM的通道注意力提取如公式(1)表示:
Mc(F)=σ{MLP[AvgPool(F)]+MLP[MaxPool(F)]}
=σ{W1[W0(FCavg)]+W1[W0(FCmax)]}。(1)
其中:σ表示sigmoid函數;W0∈RC/r×C;W1∈RC×C/r;MLP 的权重W0、W1是共享的,用于2个输入,并且ReLU激活函数接在W0后面。
CBAM的空间注意力提取如公式(2)表示:
Ms(F′)=σ(f7×7{[AvgPool(F′);MaxPool(F′)]})
=σ(f7×7([F′savg;F′smax]))。(2)
其中:f7×7表示卷积核大小为7×7的卷积操作。
2.4 Vision TransformerEncoder模块
在Vision Transformer模型中,Encoder模块是模型的核心之一,它的主要作用是为计算机的机器视觉任务提取特征, 如图像分类、目标检测、图像分割
等任务[21]。该模块的结构基于Transformer模型,通过注意力机制实现不需要局部卷积操作就可以处理空间特征的能力,并且具备良好的扩展性[22]。该模块的工作流程包括将输入的像素数据(二维图像)转化为向量表示,通过多层Encoder将特征优化和抽象,最后输出得到图像的特征表示。该模块在解决长序列的处理能力、建模全局特征依赖、提高数据利用率等方面,具备很多优势[23]。相对于传统的卷积神经网络,使用Vision Transformer Encoder模块能够提取更明确的特征表示,并更好地应用于文本识别、自然语言处理等计算机视觉任务中[24]。Vision Transformer Encoder模块结构如图7所示。
在输入到本研究的Encoder模块之前,先将提取的2个特征层融合,然后使用一个叫Reshape的层,将输入的张量x转化为2D矩阵,其中第1维是(-1),该维的大小根据张量中“非1”元素的总数计算得出,第2维则等于原始张量中每个元素的大小x.shape[-1]。转化成符合Encoder模块输入的二维张量,也就是其中的融合张量(fusion tensor)模块。
标准化处理(Norm)层对输入的张量进行标准化处理,确保数据特征在一定的范围内。
Norm(x)=LayerNorm[x+Attention(x)]。(3)
通过多头注意力机制层(Multi-Head Attention)對标准化后的张量进行全局关系的建模,
捕捉特征张量中各部分之间的依赖关系,从而得到一个新的高维特征表示,用于输入特征的下一步处理。在Multi-Head Attention中,输入的特征张量为x,包括N个特征向量,每个向量的长度为d_model。将x通过线性投影变换为3个张量,分别表示Query、Key、Value。将Query、Key、Value分别输入到num_heads个独立的注意力头中,计算得到num_heads个注意力张量,再将其按通道维度进行合并,从而得到1个张量,最后通过线性投影得到输出。
Query=x×Wq;Key=x×Wk;Value=x×Wv;(4)
Attention(Q,K,V)=softmax[QKT/sqrt(d_k)]×V;(5)
MultiHead(Q,K,V)=concat(head1,…,headh)×Wo。(6)
其中,Wq、Wk、Wv、Wo分别表示针对Query、Key、Value和输出的线性变换矩阵;head表示注意力头数量;d_k表示每个Query、Key矩阵中元素的维度大小;sqrt(d_k)为缩放因子,能够控制结果的范围和分布。
将Multi-Head Attention层的输出、输入张量进行相加(Add层),以便使当前层处理后的特征与原始特征发生变化,并通过Norm层进行标准化处理,确保不同维度之间的变化具有相似的尺度。
在多层感知机(MLP)层中使用带有激活函数的Dense层对标准化后的特征张量进行变换,从而进一步提取特征。再次对输出特征张量进行标准化处理。
MLP(x)=Gelu(xW1+b1)W2+b2。(7)
其中,x表示输入张量;W1、b1分别表示第1个 Dense 层的权重、偏置;W2、b2分别表示第2个 Dense 层的权重、偏置。公式(7)将标准化后的特征张量通过2个 Dense 层进行变换,并使用Gelu激活函数进行非线性变换,得到1个新的张量作为当前层处理后的特征。
最后将第1个Add层的输出和MLP层的输出进行相加,以得到最终的输出向量,并同时进行残差连接,确保多层处理后的特征仍然包含原始特征信息。
2.5 本研究模型识别方法
本研究首先使用EfficientNet v2网络对图像进行特征提取,为了能够更好地捕获不同尺度下的图像信息,使用了4个不同尺度的网络层进行金字塔融合,从而提高模型的分类准确率和稳定性。接下来,在特征融合的下采样环节添加3个CBAM注意力机制模块。这些模块能够动态地调整特征图中不同位置的通道权重,更好地捕获有用的特征信息。为了增强特征表达能力,每个CBAM模块后都添加了Vision Transformer的Encoder模块,从而提高了模型的分类准确率、稳定性、鲁棒性。最终的输出结果被送入softmax分类器进行分类。本研究改进模型网络结构如图8所示。
3 试验结果与分析
3.1 试验环境
试验采用 Windows 10操作系统,Python 3.9 作为开发语言,Tensorflow 2.11.0为深度学习开发框架,开发工具为Pycharm。硬件包括16 GB内存、Nvidia RTX-3060显卡,配备AMD RyzenTM 7 5800H with Radeon Graphics处理器。
3.2 训练过程
3.2.1 评价指标 精确率(Precision):指被分类器正确分类的样本数量占总样本数的比例,即
Precision=TPTP+FP。(8)
其中,TP表示真正例(分类器将正类正确分类的数量),FP表示假正例(分类器将负类错误分类成正类的数量)(表2)。
召回率(Recall):指分类器正确分类的正样本数量占真实正样本总数的比例,即
Recall=TPTP+FN。(9)
其中,TP表示真正例,FN表示假负例(分类器将正类错误分类为负类的数量)。
F1分数:综合考虑Precision 和 Recall,以一个综合的指标来评估模型分类效果,即
F1=2×Precision×RecallPrecision+Recall。(10)
准确率(Accuracy):指分类器将所有样本正确分类的数量占总样本数的比例,即
Accuracy=TP+TNTP+FP+TN+FN。(11)
其中,TP表示真正例,TN表示真负例(分类器将负类正确分类的数量),FP表示假正例,FN表示假负例。
宏平均(macro avg):对每个类别的评价指标(Precision、Recall、F1分数)求平均值,各类别的评价指标平等对待,适用于多分类模型样本分布均衡的情况。
加权平均(weighted avg):对每个类别的评价指标进行加权平均,其中权重为每个类别样本数在总样本数中所占的比例,用于多分类模型存在样本不均衡的情况。
3.2.2 不同网络模型性能对比
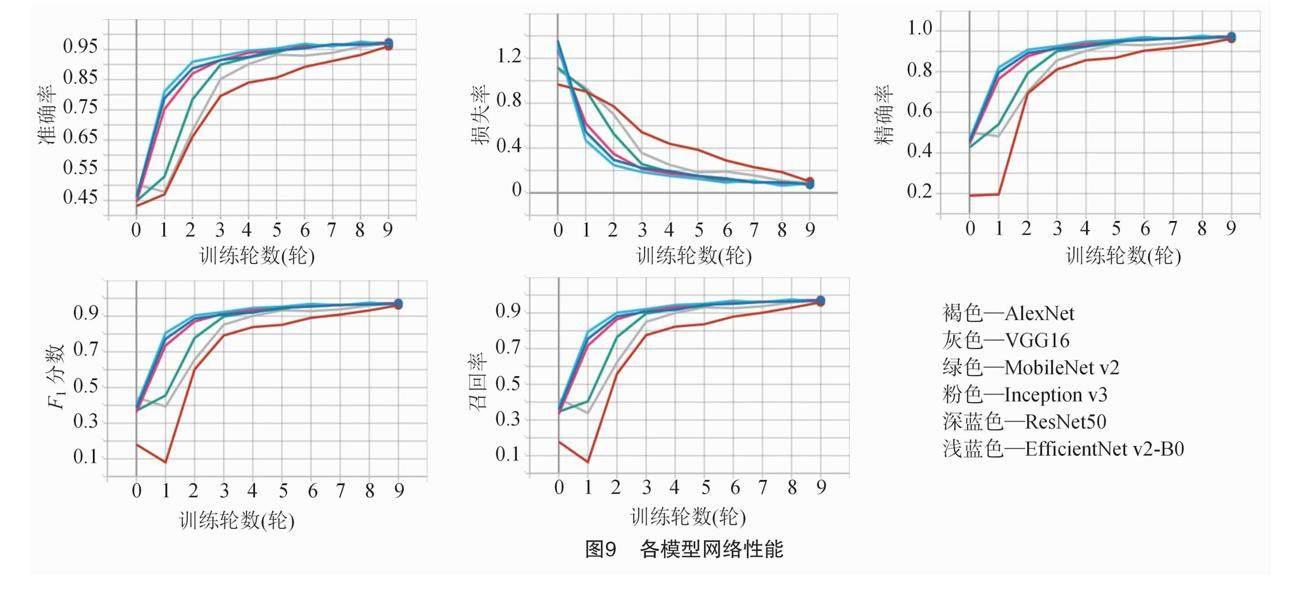
TensorBoard是由Google开发的机器学习可视化工具,主要用于追踪机器学习过程中的各项指标,如准确率、损失等变化。各模型训练结束后直接通过TensorBoard可视化显示各评价指标折线图。试验选取 EfficientNet v2-B0 作为基线网络, 该网络与常见分类网络模型AlexNet、VGG16、ResNet50、Inception v3、MobileNet v2采用相同数据集进行试验对比,且训练集 ∶测试集=8 ∶2,试验设置epoch为10、batch_size为16、学习率为0.000 1进行训练,其中褐色为AlexNet、灰色为VGG16、綠色为MobileNet v2、粉色为Inception v3、深蓝色为ResNet50、浅蓝色为EfficientNet v2-B0,各模型网络性能在训练集下的表现如图9所示。
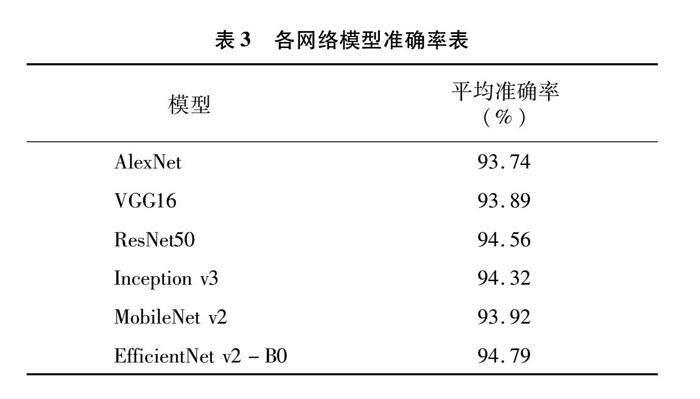
各网络模型在测试数据集上的分类准确率如表3所示。
由图9、表3可知,EfficientNet v2-B0相较于其他模型具有更高的识别准确率、更好的泛化能力和稳定性,这意味着在面对不同环境的图像时,其识别能力更好。且该模型具有更高的适用性,可以在更多的场景下应用。同时,EfficientNet v2-B0的loss收敛更快,这意味着训练成本更低,更节省时间和资源,故选取EfficientNet v2-B0为基线网络。
3.2.3 消融试验
研究进行了3种消融试验,旨在优化目标识别任务模型的性能。首先进行基线试验,使用EfficientNet v2网络进行图像特征提取和分类,未进行额外优化,命名该模型为基线模型,对应图10中的绿色曲线。接着,在特征融合和CBAM模块添加试验中,为模型添加4个不同尺度的网络层进行金字塔融合,并在金字塔的融合下采样环节添加3个CBAM注意力机制模块,以进一步提高模型的性能表现, 命名该模型为融合模型, 对应图10中的灰色曲线。最后,再添加Vision Transformer的Encoder模块进行特征增强,命名该模型为本研究模型,对应图10中的橙色曲线。Encoder模块可以将输入序列进行多头自注意力计算和前馈网络计算,从而能够更好地捕捉图像特征之间的关系,提高准确度和泛化能力。试验设置epoch为50、batch_size为32、学习率为0.000 1进行训练。图10为3种模型的各项性能对比。
由表4可知,模型放进前识别准确率为94.79%,放进后达到98.26%,提升3.47百分点。在测试数据集上采用查准率 P、查全率 R、F1分数来进一步衡量本研究算法模型的识别性能。由于查准率和查全率一般相互矛盾,故常用F1调和平均数来对模型进行分析。表5至表8为各模型性能的评价指标。
根据图10与表4至表8分析可知,本研究的扩展试验模型均能够显著提升模型的性能表现,特别是在F1分数、召回率、精确率等指标方面。其中,本研究模型在各项指标上的表现最优,超过基线模型和融合模型,模型的loss收敛更快,准确率更高,宏平均值与加权平均值都有明显提升。消融试验结果表明,通过添加金字塔特征融合、CBAM注意力机制、Vision Transformer的Encoder模块,可以大幅度提高图像分类识别任务模型的性能表现。
混淆矩阵常用来可视化地评估模型的性能优劣。图11至图13给出了早疫病、晚疫病、健康类别的分类混淆矩阵。图11中,401张早疫病叶片中有368张被正确识别,其中33张被识别成了晚疫病;61张健康叶片中有53张被正确识别,8张被识别成晚疫病;401张晚疫病叶片中有397张被正确识别,4张被识别成健康叶片。图12中,401张早疫病叶片中有400张被正确识别,其中1张被识别成了晚疫病;61张健康叶片中有51张被正确识别,2张被识别成早疫病,8张被识别成晚疫病;401张晚疫病叶片中有381张被正确识别,18张被识别成早疫病,2张被识别成健康叶片。图13中,401张早疫病叶片中有399张被正确识别,其中2张被识别成了晚疫病;61张健康叶片中有52张被正确识别,9张被识别成晚疫病;401张晚疫病叶片中有397张被正确识别,2张被识别成早疫病,2张被识别成健康叶片。分析可知,本研究提出的模型针对早疫病和晚疫病有着极高的分类准确率,且具有较好的识别性能和鲁棒性,可以应用于复杂的自然环境中。预测效果如图14所示。
4 结论
本研究在马铃薯病害叶片的识别任务中应用
EfficientNet v2网络进行特征提取,并采用金字塔特征融合、CBAM注意力机制、Vision Transformer的Encoder模块进行模型的扩展与优化。试验结果表明,经过模型扩展和优化后,该模型不仅在干扰环境下具有高精度识别能力,而且表现出良好的鲁棒性和适应性,能够有效提高病害区域的识别能力和检测准确率,同时解决了病害识别中泛化能力差、精度低、计算效率低等问题。研究可以为农业信息化技术的可行性提供合理依据,在一定程度上可以增强马铃薯病害的预测和防控能力。
参考文献:
[1] 黄凤玲,张 琳,李先德,等. 中国马铃薯产业发展现状及对策[J]. 农业展望,2017,13(1):25-31.
[2]Lu J Z,Tan L J,Jiang H Y. Review on convolutional neural network (CNN) applied to plant leaf disease classification[J]. Agriculture,2021,11(8):707.
[3]Zhang J S,Yu X S,Lei X L,et al. A novel deep LeNet-5 convolutional neural network model for image recognition[J]. Computer Science and Information Systems,2022,19(3):1463-1480.
[4]Pragy P,Sharma V,Sharma V. Senet cnn based tomato leaf disease detection[J]. International Journal of Innovative Technology and Exploring Engineering,2019,8(11):773-777.
[5]Sardogˇan M,zen Y,Tuncer A. Detection of apple leaf diseases using Faster R-CNN “,” Faster R-CNN Kullanarak ElmaYapragˇ Hastalklarnn Tespiti[J]. Düzce üniversitesi Bilim Ve Teknoloji Dergisi,2020,8(1):1110-1117.
[6]Farhadi A,Redmon J. YOLO v3:an incremental improvement[C]//Computer vision and pattern recognition. Berlin/Heidelberg,Germany:Springer,2018,1804:1-6.
[7]Liu B,Zhang Y,He D J,et al. Identification of apple leaf diseases based on deep convolutional neural networks[J]. Symmetry,2017,10(1):11.
[8]Zhang S W,Zhang S B,Zhang C L,et al. Cucumber leaf disease identification with global pooling dilated convolutional neural network[J]. Computers and Electronics in Agriculture,2019,162(C):422-430.
[9]Too E C,Li Y J,Njuki S,et al. A comparative study of fine-tuning deep learning models for plant disease identification[J]. Computers and Electronics in Agriculture,2019,161:272-279.
[10]郭小清,范涛杰,舒 欣. 基于改进Multi-Scale AlexNet的番茄叶部病害图像识别[J]. 农业工程学报,2019,35(13):162-169.
[11]任守纲,贾馥玮,顾兴健,等. 反卷积引导的番茄叶部病害识别及病斑分割模型[J]. 农业工程学报,2020,36(12):186-195.
[12]钟昌源,胡泽林,李 淼,等. 基于分组注意力模块的实时农作物病害叶片语义分割模型[J]. 农业工程学报,2021,37(4):208-215.
[13]彭红星,李 荆,徐慧明,等. 基于多重特征增强与特征融合SSD的荔枝检测[J]. 农业工程学报,2022,38(4):169-177.
[14]Borhani Y,Khoramdel J,Najafi E. A deep learning based approach for automated plant disease classification using vision transformer[J]. Scientific Reports,2022,12:11554.
[15]LiXP,ChenXY,YangJL,etal.Transformerhelpsidentify
kiwifruit diseases in complex natural environments[J]. Computers and Electronics in Agriculture,2022,200:107258.
[16]Li X P,Li S Q. Transformer help CNN see better:a lightweight hybrid apple disease identification model based on transformers[J]. Agriculture,2022,12(6):884.
[17]Zhong Y W,Huang B J,Tang C W. Classification of cassava leaf disease based on a non-balanced dataset using transformer-embedded ResNet[J]. Agriculture,2022,12(9):1360.
[18]Luo Y Q,Sun J,Shen J F,et al. Apple leaf disease recognition and sub-class categorization based on improved multi-scale feature fusion network[J]. IEEE Access,2021,9:95517-95527.
[19]郭啟帆,刘 磊,张 珹,等. 基于特征金字塔的多尺度特征融合网络[J]. 工程数学学报,2020,37(5):521-530.
[20]Ma R,Wang J,Zhao W,et al. Identification of maize seed varieties using MobileNet v2 with improved attention mechanism CBAM[J]. Agriculture,2022,13(1):11.
[21]Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.December 4-9,2017,Long Beach,California,USA.ACM,2017:6000–6010.
[22]Xing L P,Jin H M,Li H A,et al. Multi-scale vision transformer classification model with self-supervised learning and dilated convolution[J]. Computers and Electrical Engineering,2022,103:108270.
[23]侯越千,张丽红. 基于Transformer的多尺度物体检测[J]. 测试技术学报,2023,37(4):342-347.
[24]Wang S S,Zeng Q T,Ni W J,et al. ODP-Transformer:interpretation of pest classification results using image caption generation techniques[J]. Computers and Electronics in Agriculture,2023,209:107863.
