基于改进自编码器的转炉炼钢工艺模式提取方法
2024-05-03董倩倩胡帅杰谷茂强
董倩倩,胡帅杰,黎 敏,于 艳,谷茂强
1) 北京科技大学钢铁共性技术协同创新中心,北京 100083 2) 宝山钢铁股份有限公司中央研究院,上海 201900
转炉炼钢在钢铁生产全流程中占据着重要的生产地位,其目标是通过终点控制技术获得温度和成分含量均满足要求的钢水.终点控制技术包括静态控制和动态控制,静态控制是动态控制的基础,如果静态控制方法过于简单,则需要大量的人工经验参与控制过程工艺参数,不仅给冶炼后期的动态控制带来极大挑战,而且容易导致终点碳的质量分数和终点钢水温度不命中.因此,利用数据挖掘技术建立完善的转炉炼钢静态控制模型,对于转炉终点控制有重要的研究意义.
传统转炉炼钢静态控制模型常采用机理模型[1-2]、统计模型[3]、增量模型[4]和智能模型[5-6].已有学者分别在供氧、造渣和底吹方面取得了一定的研究成果,文献[7]结合机理模型和增量模型,预测吹炼全程耗氧量、造渣料加入总量和冷却剂加入总量,该方法可以满足终点碳的质量分数和终点温度分别在±0.02%和±20 ℃的范围,平均命中率达到70%以上.文献[8]通过建立机理模型,研究不同的铁水条件对吹炼枪位的影响,针对某炼钢厂120 t转炉建立了“低—高—低”和“高—低—低”两种氧枪枪位操作模式.文献[9]通过数值模拟,分析不同底吹强度对熔池搅拌效果的影响,针对某炼钢厂210 t转炉,底吹强度的控制范围在0.10~0.15 m3·t-1·min-1之间时更有利于熔池的混匀,对终点碳的质量分数和终点温度的控制具有重要意义.
上述静态控制模型的不足之处在于:一方面,在吹炼过程中,供氧、造渣和底吹等多种工艺参数通常需要联合控制,现有模型缺乏对强耦合关系的工艺参数进行协同分析;另一方面,现有模型未考虑以原料为主的标量型数据和以工艺参数为主的时序型数据之间的强耦合性,以及时序型数据前后时刻的依赖性,导致原料条件和工艺操作模式的适配性不高.为了克服现有方法的局限性,需要从实际生产数据出发,研究适用于具有多变量强耦合性、时序强相关性、标量数据与时序数据混合性等特点的转炉炼钢数据的静态控制模型.
无监督聚类是一种有效的数据挖掘手段,聚类分析以相似性为基础,同一类别中的工艺参数之间比不在同一类别中的工艺参数之间具有更强的相关性.目前,已有一些聚类算法应用于地源热泵[10]、焦炉生产[11]、交通工程[12]和电力系统[13]等领域的工艺模式提取中.因此,可以将聚类方法用于转炉炼钢生产过程,从不同的聚类类别中获得不同原料条件所对应的工艺操作模式,建立静态控制模型.
传统的无监督聚类方法[14-16]通常包括基于层次的聚类方法、基于密度的聚类方法、基于模型的聚类方法和基于划分的聚类方法等.文献[17]通过K-Means方法对高炉冷却壁温度进行聚类分析,用于表征高炉操作炉型的变化,指导高炉实际生产.然而,上述方法虽然具有较好的聚类效果,但仅使用了标量型数据进行聚类,在面向既有标量型也有时序型的混合数据时,无法提取隐藏在多元时间序列内部的时序特征,因此很难直接衡量时间序列的相似度,往往不能表现出最优性能.为此,文献[18]提出了一种基于托普利兹逆协方差矩阵的聚类方法,该方法利用相关网络和马尔可夫随机场来提取汽车驾驶信号这一时间序列中不同观测值之间的时序依赖性,构建逆协方差矩阵度量不同信号之间的差异来完成聚类.然而,该方法假设时间序列数据的逆协方差结构是稳定的,并符合托普利兹矩阵的特点.这一假设对于像转炉生产过程这样包含标量型和时序型的混合数据不友好,而深度学习方法具有很强的灵活性,且在非线性特征提取方面有强大的优势.因此,越来越多的聚类方法与深度学习方法相结合,形成了以深度神经网络为基础架构的一系列深度聚类模型,如基于自编码器(Autoencoder, AE)[19-20]、基于变分自编码器[21]、基于生成对抗网络[22]和基于孪生网络等[23]结构的深度聚类算法.因此,可以结合炼钢复杂生产过程的数据特点,开展深度聚类算法应用于转炉炼钢生产过程的深入研究工作.随着钢铁企业信息化建设的发展,转炉炼钢厂积累了大量的原辅料、工艺参数和终点质量等数据,可以通过大数据挖掘技术,从终点碳温均命中的炉次中,根据不同的原料和终点质量要求,提取吹炼过程的供氧、造渣和底吹等工艺操作模式.其中,供氧模式包括氧枪高度、氧气压力和供氧强度;造渣模式是指造渣剂加入量和冷却剂加入量;底吹模式涵盖了底吹气体类型和底部供气强度2个工艺参数.
结合深度学习方法优势和转炉生产数据的特点,本文提出了一种基于改进自编码器的转炉炼钢工艺模式提取方法(Process model extraction method of converter steelmaking based on improved autoencoder, IAE),首先建立IAE模型,将炼钢原料条件、终点质量要求和工艺参数等数据作为模型的输入,针对包含标量型和时序型2种数据类型的输入数据,该模型在编码器中使用全连接模块提取标量型数据的非线性特征,使用长短期记忆(Long short-term memory, LSTM)网络模块和一维卷积(One-dimensional convolution, Conv1d)模块分别提取时序型数据的全局特征和局部特征;利用编码器将原始高维数据映射到低维特征空间获得隐藏向量,再将隐藏向量输入到批量K-Means聚类模块用于更新聚类中心并计算聚类损失;在此基础上,解码器将提取的隐藏向量重构回原始空间得到重构数据,联合重构损失和聚类损失实现IAE模型的训练;最后,模型在提取数据有效低维特征的同时获得最佳聚类效果,在属于不同聚类类别的数据中,寻找离各个聚类中心最近的样本,将最近样本的供氧、造渣和底吹工艺操作作为该类样本的工艺操作模式.本文方法的优势在于:(1) 全连接模块用于处理标量型数据,长短期记忆模块和一维卷积模块用于处理时序型数据,有利于充分发挥神经网络的非线性特征提取能力,因此可以适应复杂生产过程中既有标量型又有时序型的多类型输入数据;(2) 利用LSTM捕捉时间序列中的长期依赖关系,即全局特征,一维卷积主要用于捕捉时间序列中的短期依赖关系,即局部特征,两者联合使用有利于捕捉吹炼过程工艺参数内部复杂的时序相关性.利用转炉炼钢实际生产数据验证了本文方法的有效性.
1 方法原理
转炉炼钢静态控制模型是在已知铁水等原料条件和终点质量要求的前提下,获得供氧、造渣和底吹等各个工艺参数的控制方式.为了从终点碳温均命中的炉次中,提取出最优的工艺参数控制模式,本文提出了基于改进自编码器的转炉炼钢工艺模式提取方法,将工艺模式的提取问题转换为无监督聚类问题,该方法的原理如图1所示.
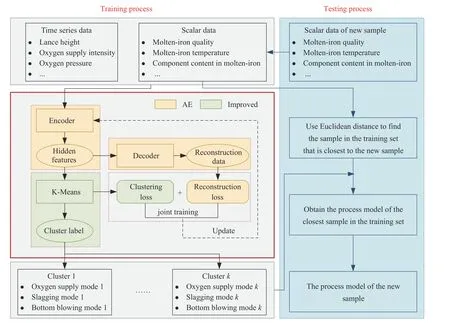
图1 IAE方法原理图Fig.1 Principle of the IAE method
IAE方法将批量K-Means聚类方法内嵌入传统的自编码器中,利用编码器良好的特征提取能力,从转炉炼钢复杂混合数据中获取标量型数据和时序型数据的低维特征表示,即隐藏特征向量,再使用批量K-Means方法对隐藏特征向量进行聚类;为了建立隐藏向量和聚类中心的联系,联合重构损失和聚类损失完成IAE模型的训练;最后,根据聚类结果,获取不同原料条件和终点质量要求下对应的吹炼过程的供氧、造渣和底吹工艺模式.
1.1 编码器
转炉生产数据包含以原料为主的标量型数据和以工艺参数为主的时序型数据,将训练数据集表示为1,2,···,N,S∈RN×Ds表示标量型变量的向量空间,其中,N表示数据集包含的样本个数,Ds表示标量型变量的维度.令X={x1,···,xt,···,xT},X∈RN×T×Dt表示时序型变量的向量空间,其中,xt=[xt1,xt2,···,xtDt]T表示第t个时刻所有时序型变量的观测值,T表示时序型变量的时间长度,Dt表示时序型变量的维度.
针对标量型变量,采用全连接层和非线性Sigmoid激活函数结合的方式来提取数据内部的非线性特征,如图2 (a)中编码器左侧支线模块所示.

图2 IAE方法的网络结构图.(a) 编码器网络结构图; (b) 解码器网络结构图Fig.2 Network structure of the IAE method: (a) encoder network structure; (b) decoder network structure
图2(a)中,全连接模块用于标量型数据的特征表示,该层的输出H1可以表示为:
其中,W1和b1分别表示Linear1的权重矩阵和偏置系数,Sigmoid( )表示激活函数.
对于时序型变量,采用LSTM和一维卷积模块来分别提取时间序列在时间维度上的复杂信息,LSTM网络通过输入门、遗忘门和输出门来控制时序信息的传递,可以捕捉时序数据中的长期依赖关系;在一维卷积模块中,一维卷积层利用卷积核沿着时间维度进行卷积操作,着重于局部特征的提取,使用ReLU激活函数来引入非线性因素,使得网络能够充分学习输入数据的复杂特征,具备更强大的表征学习能力.此外,引入批归一化层(Batch normalization,简称为BatchNorm)和丢弃层(Dropout),目的是减少模型参数,防止出现过拟合,如图2(a)中右侧支线模块所示.值得说明的是,为了增加网络的深度,更好地提高模型学习特征的能力,一维卷积模块通常需要堆叠多个,根据模型的损失值来确定堆叠的个数,本文通过试错法,确定堆叠3次最佳.LSTM模块和一维卷积模块的输出H2和H3分别写作:
其中,*表示一维卷积运算,UE和vE分别表示编码器中一维卷积层的权重和偏置,B( )表示批归一化层,ReLU( )表示激活函数,D( )表示Dropout层.
将输出结果H1,H2,H3进行拼接,并进入Linear2输出得到低维空间的隐藏向量矩阵H:
其中,W2和b2分别表示Linear2的权重矩阵和偏置系数,cat()函数表示拼接.
1.2 解码器
原始数据经过编码器得到低维空间的隐藏向量,隐藏向量作为解码器的输入,解码器的输出是与原始数据对应的重构数据,重构数据用于计算重构损失.解码器包含3类网络结构,包括LSTM模块、一维卷积模块和全连接模块,网络结构如图2(b)所示.其中,一维卷积模块由上采样层(Upsample)、一维卷积层、批归一化层和ReLU激活函数组成,上采样用于增加时间维度上的信息,从而捕捉细粒度的特征.通过试错法实验,解码器中的一维卷积模块堆叠4次最佳.解码器中LSTM模块和一维卷积模块的输出H4和H5分别写作:
其中,S( )表示上采样,UD和vD分别表示解码器中卷积层的卷积核和偏置.
全连接模块位于解码器的末端,用于拼接LSTM模块和一维卷积模块输出的特征映射,并将拼接向量映射为与原始数据形状一致的重构数据.将输出H4和H5进行拼接以后分别进入Linear3和Linear4,得到:
其中,Srec和Xrec分别表示标量型变量和时序型变量的重构数据,W3、b3和W4、b4分别表示Linear3和Linear4的权重矩阵和偏置系数,Reshape()函数用于改变时序型重构数据的维度,使得其与原始时间序列的维度相同.
1.3 批量K-Means聚类模块
在1.1中利用编码器获得原始数据在低维空间对应的隐藏向量,将隐藏向量输入到批量K-Means方法中得到聚类中心,在模型的训练过程中,聚类中心随着迭代轮数的增加不断迭代更新,其更新方式如下:将包含N个样本的训练集分成若干批次,每个批次大小为batch_size,针对每一轮中第i个批次,计算批次内各个样本到第i-1个批次获取的聚类中心的距离,将第i个批次内的样本分别分配到与其距离最近的簇,则第i个批次的聚类中心计算方式如下:
其中,cij-1和cij分别表示第i-1和第i个批次的第j类聚类中心,hin,n=1,···,batch_size表示第i个批次内的第n个隐藏向量,β表示聚类学习率,nj为分配给聚类中心cij的样本数量.
1.4 联合损失函数
IAE模型的训练过程主要包含聚类任务和重构任务,聚类任务的优化目标是最小化每个隐藏向量与其所属聚类中心的欧氏距离.针对第i个批次,其聚类损失的目标函数Lclust可以定义为下式:
其中,k表示聚类类别的个数,‖hin-cij‖2表示欧氏距离函数.
重构任务的优化目标是最小化重构数据和原始数据的距离,针对复杂生产过程的混合类型数据,标量型数据的重构损失Lrec_s采用均方误差损失函数(Mean squared error, MSE):
其中,sn和srnec分别表示第n个样本的原始数据和重构数据的标量型数据.
时序型数据的重构损失Lrec_t采用软动态时间规整(Soft dynamic time warping, Soft-DTW)方法计算[24],Soft-DTW是一种基于动态时间规整(Dynamic time warping, DTW)的损失函数,Soft-DTW将 DTW中的硬对齐策略变为软对齐策略,使得时间序列之间的对齐更加灵活,同时增加正则化项来控制过度拟合,计算公式如式(12)所示:
其中,Xn和Xnrec分别表示第n个样本的原始数据和重构数据的时序型数据.
因此,本文方法的重构损失Lrec由标量型数据和时序型数据对应的重构损失组成,即:
其中,η≥0是平衡标量型数据重构损失和时序型数据重构损失的超参数.
联合重构损失和聚类损失进行特征学习与聚类过程的训练,联合损失函数可以写作:
其中,λ≥0是平衡聚类损失和重构损失的超参数.
一般而言,超参数η和λ采用对数坐标搜索超参数的方法来选取,即超参数依次取0.0001,0.001,0.01,0.1,1和10等数值,观察损失值收敛情况并确定合理的超参数取值.
综上,本文以自编码器为基础结构,使用全连接模块、长短期记忆网络模块、一维卷积模块和批量K-Means模块构建了IAE无监督聚类方法,并联合重构损失和聚类损失完成模型的训练过程,获得训练集的聚类中心及各个样本所属的聚类类别,在属于不同聚类类别的数据中,寻找离各个聚类中心最近的样本,样本离聚类中心越近,则其工艺参数控制得越好,同时,在相同聚类类别内的样本在工艺操作上更加接近.因此,可以将最近样本的供氧、造渣和底吹工艺控制方式作为该类样本的工艺操作模式.
1.5 算法流程
本文提出的IAE方法的训练过程具体如下:
(1) 对训练集样本Atr进行归一化处理,以消除量纲的影响;
(2) 初始化模型参数,包括:聚类预设范围k,最大迭代次数epoch,样本批次大小batch_size,隐藏向量维度h_dim,损失函数超参数η和λ,学习率lr和权重衰减系数wd;
(3) 对自编码器进行预训练,预训练过程的损失函数仅包含重构损失,如式(13);
(4) 利用编码器提取混合输入数据的特征,获得输入数据对应的隐藏向量;
(5) 利用式(9)更新隐藏向量的聚类中心;
(6) 利用隐藏向量与其所属聚类中心的欧氏距离计算聚类损失,如式(10);
(7) 将隐藏向量输入到解码器输出重构数据,如式(7)和式(8);
(8) 利用欧氏距离和Soft-DTW距离计算重构损失,如式(11)和式(12);
(9) 联合聚类损失和重构损失,如式(14),通过Adam优化器反向更新网络模型;
(10) IAE模型训练完成后,可以获得训练集的聚类结果,根据距离聚类中心最近的样本来获得典型工艺模式;
本文提出的IAE方法的测试过程具体如下:
(1) 测试集Ate的变量仅包括以原料条件和终点质量要求为主的标量型数据,利用训练集各个变量的最大值最小值对测试集进行归一化;
(2) 计算测试集新样本与训练集所有样本的欧氏距离,在训练集中寻找离测试集新样本最近的样本;
(3) 判断离新样本最近样本所属的聚类类别,如果最近样本属于第j,j=1,···,k类,则测试集新样本采用工艺模式j进行吹炼.
2 案例分析
2.1 数据来源
从某钢厂炼钢部一座260 t转炉收集现场部分生产过程的数据,这批数据涉及的钢种均采用低拉碳工艺.首先对原始数据进行数据预处理,包括剔除缺失值和异常值,针对低碳钢种,筛选出终点碳温均命中的炉次,完成上述步骤后共获得471炉次生产数据.每一炉次即一个样本,每个样本有16个自变量,包含9个标量型变量和7个时序型变量,2个因变量,如表1所示.其中,造渣剂包括轻烧白云石、活性石灰和白云石等,冷却剂包括矿石等.底吹气体的类型包括氩气和氮气,该变量为2值型变量,数值0表示吹氮气,数值1表示吹氩气.利用副枪检测手段(Temperature sampling oxygen, TSO)来获得终点碳的质量分数和终点温度.时序型工艺参数的采样周期为2 s,平均吹炼时间为16.33 min,可以采用线性插值手段,将不同吹炼时长的各个炉次的时序型数据对齐为980个采样点.因此,标量型数据的维度为(471, 9),时序型数据的维度为(471, 980, 7).为了消除工艺参数之间的量纲影响,将数据归一化到区间(0, 1]中参与建模,在生产实际应用中将数据反归一化.
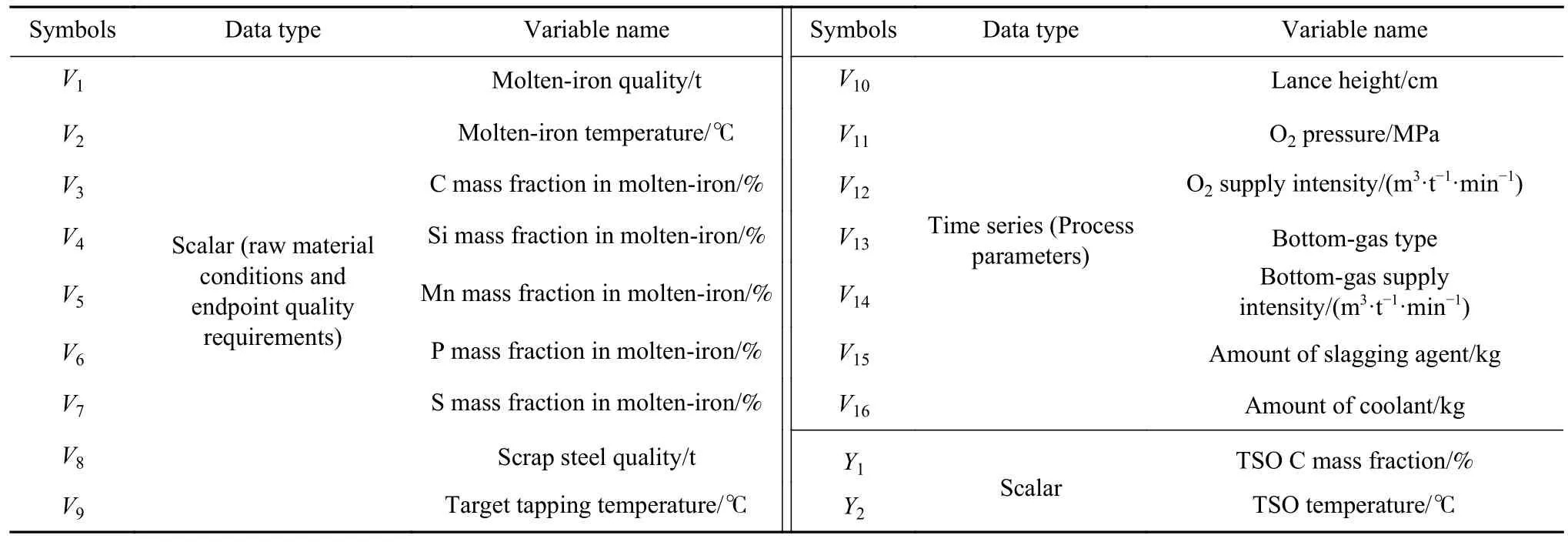
表1 转炉炼钢过程变量Table 1 Process parameters of converter steelmaking
随机选取471炉次中的80%样本用于构造训练集,剩余的20%用于构建测试集.因此,训练集共包含376个样本,测试集共有95个样本.
2.2 模型网络结构与参数设置
本文方法需要预设聚类类别个数,通过工艺先验知识可知[25],常用的氧枪高度控制模式有5种,底吹供气模式有3种,辅料在3个吹炼阶段分多批次加入.因此,将聚类类别个数k预设为3~10,建立IAE模型,该模型采用Adam优化器,迭代轮数epoch一般设为200~400,批量样本个数batch_size一般设为32的倍数,初始学习率lr一般设在0.001~0.01之间,衰减学习率wd一般设为1×10-6~1×10-4之间.经实验验证,聚类类别个数k预设为3~10,隐藏向量的维数h_dim设为50~150时,对模型损失值的鲁棒性影响较小,而损失函数中超参数η和λ的大小对模型的鲁棒性有显著影响.因此,可以利用权重缩放手段,将其他参数固定,分别设置为:k= 3,epoch = 300,batch_size =64,lr = 0.002,wd = 5×10-4,h_dim = 100,η= 1,来对参数λ进行寻优.
利用对数坐标搜索超参数的方法,将超参数λ的取值依次取0.0001、0.001、0.01、0.1,1和10,分别计算得到标量型数据的重构损失、时序型数据的重构损失和聚类损失的最后一轮的平均损失值,如图3(a)所示.
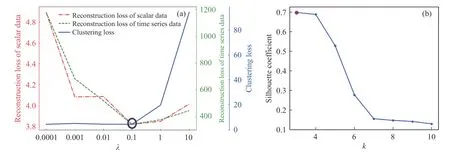
图3 IAE模型参数选择.(a) 损失函数超参数λ选择; (b) 聚类类别个数k选择Fig.3 Selection of IAE model parameters: (a) selection of loss function hyperparameter λ; (b) selection of the number of clustering classes
从图3(a)可以看出,当λ=0.1时,训练集的标量型数据的重构损失、时序型数据的重构损失和聚类损失收敛达到最优,如图3(a)中黑色圆圈处所示,因此,确定λ=0.1为最优参数.
IAE模型的参数确定好以后,计算聚类类别个数k分别取3~10时对应的训练集的轮廓系数[26],从图3(b)可以看出,当聚类个数设为3时,训练集的轮廓系数最大,为0.698.聚类模型的轮廓系数越高表明聚类效果越好.因此,最终确定聚类类别个数k= 3.
2.3 聚类结果分析
使用IAE模型对训练集进行聚类,各个聚类类别的样本数量如表2所示.

表2 训练集各聚类类别样本个数Table 2 Number of samples in each class of the training set
在3类数据中,选择离各自聚类中心最近的样本,使用最近样本的工艺参数代表其所在类别的典型工艺模式.因此,针对某钢厂转炉,冶炼钢种为低碳钢,采用单渣法和低拉碳工艺的冶炼过程,本文从供氧、底吹和造渣制度上分别给出了3种工艺模式,如图4至图6所示.
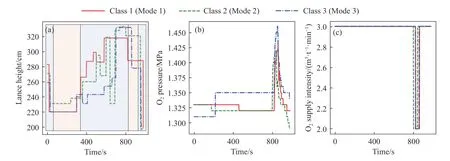
图4 供氧工艺模式.(a) 氧枪高度; (b) 氧气压力; (c) 供氧强度Fig.4 Oxygen supply process model: (a) lance height; (b) oxygen pressure; (c) oxygen supply intensity
针对供氧模式,由于最近样本的氧枪高度和氧气压力曲线跃迁较为频繁,不符合实际控制情况,本文根据曲线变化情况进行了分段,并取每一段的出现频次最多的值来替代整段的原始值,如图4(a)和4(b)所示.从图4(a)中可以发现,在吹炼周期内,3类模式的枪位均符合“高—低—高—低—低”原则,不同点在于枪位高度变换的时刻以及恒枪位的时间不同.3类模式的氧气压力在吹炼过程中均基本不变,是由于氧枪均采用恒压变枪操作,即通过氧枪高度变化来控制氧气流与熔池的相互作用以控制吹炼过程.此外,3类模式的供氧强度基本一致.值得说明的是,在吹炼后期利用副枪定碳测温,即大约第800个采样点附近,为了避免氧气损耗,会在下副枪时停吹氧气,使得图4(b)中的氧气压力和图4(c)中的供氧强度在吹炼后期会有一个较大的突变值.
针对底吹模式,如图5(a)和(b)所示,模式1和3均先吹氮气再吹氩气,模式2全程吹氩气.随着气体类型的变化,模式1和3的底部供气强度会有所调整,而模式2的底部供气强度基本恒定.对比图4和图5可以发现,供氧模式和底吹模式互相配合,高枪位配合弱底吹强度,低枪位配合强底吹强度,吹炼过程中依据渣料的融化情况适当调整枪位和底吹强度,采用复合吹炼模式,有利于碳氧反应趋于平衡,防止炉渣氧化铁增加,减少吹损.

图5 底吹工艺模式.(a) 底吹气体类型; (b) 底部供气强度Fig.5 Bottom blowing process model: (a) bottom gas type; (b) bottom gas supply intensity
针对造渣模式,3类模式的造渣剂均在吹炼前期和吹炼中期分多批加入,加入总量差距较小,如图6(a)所示.冷却剂的加入量在吹炼中后期差距较大,冷却剂的加入时间及用量依据炉温情况决定,从提取的3类模式中可以发现,模式3在下副枪之后仍加入冷却剂,如图6 (b)中的蓝线所示.这时候,需要增加底部供气强度加强搅拌,如图5(b)的蓝线所示.由此可以看出,供氧、底吹和造渣模式的相互配合,对于控制好化渣过程,预防喷溅、避免返干,保证冶炼正常运行有重要作用.
2.4 评价指标
对于测试集新来样本,在吹炼开始前,仅能得到新样本的原料条件和终点质量要求,即如表1所示的标量型变量,为了获得新样本对应的工艺模式,可采用如下方式:首先,利用新样本的标量型数据,在训练集中寻找离新样本欧氏距离最近的样本;然后,判断最近样本所属的聚类类别,例如:最近样本属于聚类类别1,则测试集新样本采用模式1进行吹炼.测试集共包括95个样本,使用上述方式可以将测试集数据分为三类,样本个数分别为23,23和49.
针对训练集和测试集,将标量型数据和时序型数据输入到IAE模型的编码器中,可以获得对应的隐藏向量.利用t分布-随机邻近嵌入(t-distributed stochastic neighbor embedding, t-SNE)[27]非线性降维方法,将每个隐藏向量降至2维,获得和这两个成分来对聚类结果进行可视化分析,可视化结果如图7所示,其中聚类中心用五角星表示.
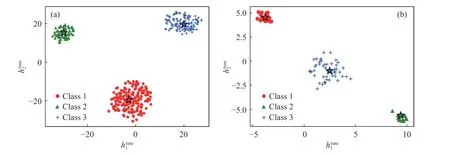
图7 t-SNE可视化图.(a) 训练集3类样本的t-SNE可视化; (b)测试集3类样本的t-SNE可视化Fig.7 t-SNE visualization: (a) t-SNE visualization of three classes in the training set; (b) t-SNE visualization of three sample types in the test set
从图7中可以看出,训练集和测试集的隐藏向量均可以很明显地被划分到3个独立的簇中,且每个簇仅包含一种数据点类型.这表明IAE模型可以从混合了标量型和时序型变量的数据中提取适合于聚类的特征,并将具有相似特征的样本划分到同一类中.
本文通过计算终点质量指标来评价提取的工艺模式的好坏.首先,利用训练集原始数据训练反向传播(Back propagation, BP)神经网络[28]建立终点预测模型,然后,针对测试集中的3类样本,将原料条件对应的标量型数据和工艺模式数据输入到训练好的BP模型中,得到终点碳的质量分数和终点温度的预测值,用于计算终点碳的质量分数在±0.02%和终点温度在±20 ℃误差范围内的终点命中率.测试集3类样本的终点碳的质量分数命中率、终点温度命中率和终点碳温双命中率的计算结果如表3所示.

表3 测试集的质量评价指标Table 3 Quality indicators of the testing set
从表3中可以得到,利用提取的工艺模式预测终点碳温,终点碳的质量分数在预测误差范围为±0.02%时的平均命中率为95.06%,终点温度在预测误差范围为±20 ℃时的平均命中率为91.48%,终点碳温的平均双命中率为90.80%.上述结果表明,IAE模型的聚类效果明显,且将提取的工艺模式用于实际生产中,有助于实现终点碳温命中.
2.5 讨论
针对转炉炼钢生产过程数据,分别使用KMeans[17],深度聚类网络(Deep clustering network,DCN)[29],深度卷积嵌入聚类(Deep convolutional embedded clustering, DCEC)[30],变分深度嵌入自编码器(Variational deep embedding, VaDE)[31]和聚类生成对抗网络(Cluster generative adversarial network, Cluster-GAN)[22]共5种方法对训练集数据进行聚类,根据测试集的标量型数据,获取测试集内各个样本对应的工艺模式,并利用BP神经网络计算不同类别终点碳和温度的平均命中率,计算结果如表4所示.
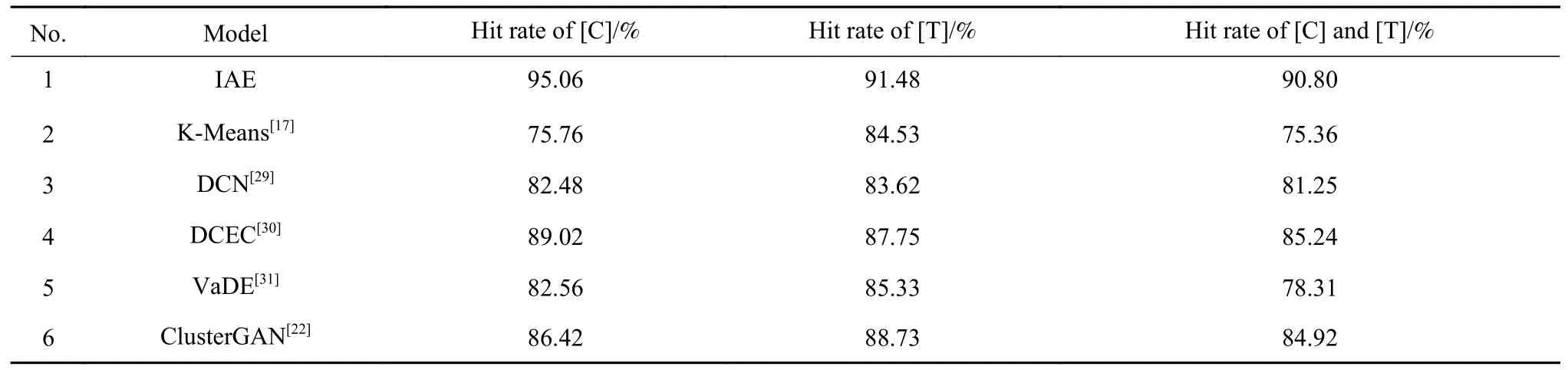
表4 不同聚类方法终点质量预测平均结果对比Table 4 Comparison of results of different clustering methods
从表4中可以看出,对比其他方法,IAE方法的终点碳的质量分数和终点钢水温度的平均命中率最高.上述6种方法的聚类结果具体分析如下:K-Means方法可处理的数据类型有限,尽管可以将包含多元长时间序列的复杂混合数据拼接变成二维矩阵,但这样的处理只考虑数据点在特征空间上的距离,忽略了数据点在时间维度上的依赖关系,不能很好地捕捉时间序列数据中的时序信息,如周期性、趋势等,因此,聚类效果不好;DCN方法使用基于全连接神经网络的自编码器,全连接神经网络由于参数共享的特性,不能很好地处理时间序列长期依赖的问题,导致无法提取有效特征,因此,聚类效果较差;DCEC方法在DCN的基础上,使用卷积网络替换了自编码器的全连接网络,直接对时间信息进行建模,但该方法将聚类任务和重构任务分离,导致编码器学习到的低维表示与聚类任务的最终目标不一致,从而影响聚类的准确性;VaDE方法和ClusterGAN方法在手写数字图像数据集上均取得了较好的聚类效果,然而,这两种方法均适用于有大量样本的场景,在小样本集上无法发挥明显的聚类效果.综上,本文方法适用于复杂工业生产过程的工艺模式提取.
3 结论
(1) 本文提出了基于改进自编码器的转炉炼钢工艺模式提取方法,将工艺模式的提取问题转换为无监督聚类问题,利用终点碳的质量分数和终点钢水温度均命中的历史炉次进行聚类,在属于不同聚类类别的数据中,寻找离各个聚类中心最近的样本,将最近样本的供氧、造渣和底吹工艺操作作为该类样本的工艺操作模式,实现复杂生产过程工艺模式的提取.
(2) 本文将原料等标量型数据和提取的工艺模式时序型数据输入到终点预测模型中,终点碳的质量分数在±0.02%误差范围内的平均命中率为95.06%,终点温度在±20 ℃误差范围内的平均命中率为91.48%,在终点碳的质量分数为±0.02%、温度的±20 ℃的误差范围内的平均双命中率为90.80%,进一步证明了本文方法的有效性.
