一种基于深度学习的档案文件齐全性检验方法
2024-05-03肖雪丽廖常辉李惠仪
肖雪丽,廖常辉,李惠仪
(广东电网有限责任公司东莞供电局 广东 东莞 523109)
0 引言
在深度学习技术快速发展的当下,其对于文本、图像和语音等多种类型数据的处理能力已经在各个领域取得了显著的突破。对于档案领域而言,如何借助深度学习技术优化档案文件齐全性检验的效率已成为迫在眉睫的问题[1]。面对不断增长的档案检验需求,找到一个结合深度学习与档案管理的有效方法显得尤为关键[2-4]。因此,本文旨在研究并构建一个以深度学习为基础的档案文件齐全性检验方法,希望通过此途径,提高传统档案检验的工作效益。
1 研究现状
当前,档案文件齐全性检验主要依赖于传统文本分词和匹配技术。其中,文本分词主要采用基于统计学习的方法[5-6],如隐马尔可夫模型和最大熵模型,以及基于词典的方法[7],如前向最大匹配法[8]和双向最大匹配法[9]。文本匹配研究则集中在表示型和交互型模型[10]。
而传统技术在处理档案文件完整性检验时面临巨大的挑战,尤其是对于具有强烈专业性和领域性的文本。词典分词方法在处理歧义和新词上不足。档案文本涵盖行业术语、缩略词等,增加了处理难度,导致基于规则的技术可能出现偏差。同时,档案数据的不均衡性,如齐全与不齐全档案数量差异,也可能导致模型的预测不准确。
近期的研究趋势是结合深度学习分词技术和预训练语言模型如BERT(bidirectional encoder representations from transformers)[11]和RoBERTa(BERT 的改进版)[12],以提升档案文件检验的效率。有研究者已尝试使用深度学习的自然语言处理技术解决档案文本的特殊性问题,例如采用分词模型进行关键词提取并计算文本相似度。
2 档案管理的关键步骤与全流程
档案文件齐全性检验是档案管理的关键环节,其目的在于确保档案文件的完整性和准确性。相比传统的、依赖人工的方法,本文提出了一种结合深度学习、自动化与智能化的档案文件完整性检验策略,为现代档案管理带来了创新和高效。该方法主要包括以下步骤:①深度学习文本分词与关键词提取。利用BiLSTM-CRF[13]模型进行文本处理,该模型可以准确地进行关键词提取。②构建关键词库。研究人员创建了一个全面的关键词库,结合预定规则,以确保高效和灵活的档案文件完整性检验。③深度学习文本匹配。通过Sentence-BERT[14]模型,可以精确计算文本间的相似度,在档案文件之间进行比对。④自动评估流程。本方法通过自动化流程,迅速且准确地评估档案文件的齐全性,从而为档案管理工作提供支持。该方法的处理全流程如图1 所示。

图1 档案齐全性检验方法处理流程
3 文本分词处理
3.1 基于BiLSTM-CRF 的文本分词技术
在本方法中,采用的文本分词模型是基于双向长短期记忆网络(bidirectional long short-term network,BiLSTM)与条件随机场(conditional random field, CRF)的结构设计。详细的模型架构可以参见图2。
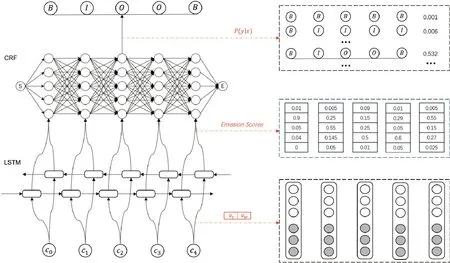
图2 BiLSTM-CRF 模型结构
模型首先通过嵌入层(embedding layer)进行输入处理,将单一字符转化为对应的向量形式,其中,该向量编码了字符的深层语义属性,并作为模型的初始输入数据。其次,输入向量经过双向长短期记忆网络层(BiLSTM layer)计算处理。而BiLSTM 层由两部分LSTM 单元组成,两个单元分别以从左至右和从右至左的方向处理输入数据,旨在捕获文本中的双向上下文信息[15]。最后,条件随机场层基于BiLSTM 层生成的上下文向量,执行标注决策。此结构不仅保证了文本的精确分词,还确保了其上下文信息的有效捕获。
为了优化BiLSTM-CRF 分词模型在电网档案文件的应用鲁棒性,研究人员针对性地收集了大量电网领域的档案数据,并据此构建了一个大规模的、具备丰富注释的文本数据集。
在模型的训练阶段,为了更加精确地计算预测与实际分布之间的差异,研究人员选择了负对数似然损失函数作为损失计算方法,如式(1)所示。为了高效地最小化损失并更新模型参数,研究人员结合了随机梯度下降方法和Adam 优化器,这两者均在深度学习中有着广泛的应用,并已被证明具有良好的收敛性。
式(1)中,PG(xi;θ) 为实际标签概率值,m为样本数量,∑表示所有样本求和。
3.2 文本分词技术应用
在档案文件完整性检验方法研究中,文本分词技术占据了核心地位,其能够精准地提取出文本中的关键信息,并为后续的文本匹配和深度分析创造有利条件。
以标题“中心输变电配套线路垫层分项工程质量验收记录表[电缆埋管子分部工程]”为案例,通过应用分词算法,得到以下分词序列:“中心/输变电/配套/线路/垫层/分项/工程质量/验收/记录表/[/电缆/埋/管子/分部/工程/]”。然后,依据预先设定的筛选机制,从中挑选出关键性词汇,即“垫层分项工程质量验收”,整体流程如图3 所示。此策略不仅显著地减少了数据处理的计算量,而且增强了匹配算法在面对文本差异时的鲁棒性。

图3 文本分词技术应用示意图
4 文本相似度匹配处理
4.1 基于Sentence-BERT 文本相似度匹配技术
在档案齐全性检验中,快速而准确地匹配文本相似度至关重要。面对众多档案文件,研究人员需高效地识别高度相似的文档。为此,采用了Sentence-BERT(SBERT)模型,其模型结构如图4 所示。
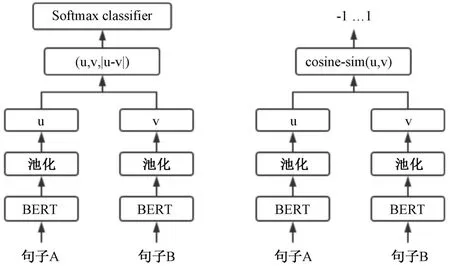
图4 Sentence-BERT 模型结构图
SBERT 是BERT 模型的优化,后者基于深度的Transformer 架构。与BERT 针对单词级别不同,SBERT 专为句子级任务设计,更好地捕获语义。它在BERT 基础上加入池化层,得到固定长度的embedding,再通过孪生和三胞胎网络结构生成语义丰富的句子嵌入。使相似语义的句子嵌入向量会距离更近,便于使用余弦相似度等方法进行相似度计算。
为了训练SBERT 模型,研究人员基于电网档案特性,构建了百万级别的实际业务文本数据集。经过数据清洗、分词和编码等预处理后,这些数据具备高度的实践价值。在模型训练阶段,为了优化模型参数并使模型更好地拟合训练数据,研究人员采用了平均绝对误差(mean absolute error, MAE)作为损失函数。MAE 是一种有效的损失函数,能够衡量模型预测结果与实际结果之间的偏差。其计算公式如式(2)所示:
式(2)中,h(x(i)) 代表模型的预测结果,y(i)代表实际结果,m代表样本总数。
4.2 文本相似度匹配应用
在本方法中,文本首先被输入到BiLSTM-CRF 分词模型中提取关键词。然后,利用Sentence-BERT 模型将这些关键词与预设关键词库进行向量化比对,流程如图5 所示。以“垫层分项工程质量验收”为待匹配标题和“垫层分项工程”为预设关键词为例,这两者都会被转化为特定的向量表征。通过计算这两向量间的余弦相似度,当该相似度值趋近于1 时,便可以认为这两个文本存在高度的相似性。此策略不仅提供了一种高度精确的文本匹配手段,而且显著提高了处理的效率和准确性。
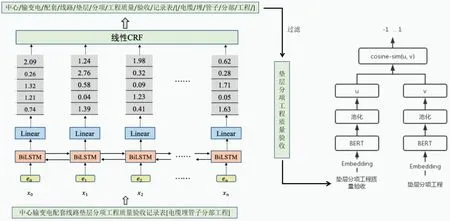
图5 文本相似度匹配应用示意图
5 结语
本文介绍了一种基于深度学习的档案文件齐全性校验方法。其核心流程包括利用BiLSTM-CRF 进行文本分词和采用Sentence-BERT 计算文本相似度。通过这些关键技术,研究者成功为档案文件的齐全性提供了准确的评估。
展望未来,为适应档案文件管理日益增长的需求,我们将进一步优化档案文件齐全性检验方法。具体而言,后期研究工作将聚焦于以下几个主要方向:第一,研究更为先进的文本处理技术,旨在提高关键词提取和文本匹配的效率和精度。第二,为了确保档案文件完整性,使检验方法更具灵活性,研究人员计划探索关键词库的动态更新与维护方式,从而更好地适应档案数据的变化趋势。
