基于深度学习的粗骨料在线检测分割方法研究
2024-04-30冀效胜房怀英杨建红黄骁民张宝裕黄斐智
冀效胜,房怀英,2,杨建红,黄骁民,张宝裕,黄斐智
1.华侨大学机电及自动化学院;2.福建省移动机械绿色智能驱动与传动重点实验室;3.福建南方路面机械股份有限公司
0 引言
骨料是混凝土中不可或缺的组成部分,其性能与混凝土的强度和耐久性密切相关。骨料粒径作为一项重要的质量指标,对于混凝土的性能具有重要影响。合理的骨料级配可以在降低成本的同时提高混凝土的性能。因此,骨料粒径的检测在混凝土工程中具有十分重要的作用。
随着科技的发展,数字图像处理技术凭借其快速处理的优势正在逐渐取代传统的检测方法。在过去的研究中,主要研究不粘连的粗骨料图像,很少涉及到堆叠状态下骨料级配的在线测量。然而,在实际应用中,对堆叠骨料进行在线测量具有更大的价值。为了获得准确的级配结果,必须先对图像进行分割,而图像分割的质量直接影响后续的结果分析。一些学者对图像分割方法进行了广泛的研究。Q.Yao等[1]通过检测粘连颗粒的凹角点,并利用最短欧几里得距离找到角点对,然后连接角点对将粘连颗粒进行分割,一定程度上解决了粘连颗粒的分割问题。刘娜[2]提出了一种结合数学形态学和形态分水岭算法的方法,有效避免了仅使用形态学分割的过度分割现象。文献[3]将改进的分水岭分割算法应用到实际的矿石颗粒检测中,具有较好的应用价值。董柯等[4]提出了一个结合局部自适应阈值和改进的流域变换的算法。通过对积分图像的自适应阈值化分离区域,并对二值图像进行距离变换和双边滤波,提高了算法的速度和对光照的适应性。李希等[5]针对图像处理中存在的误分割问题,提出了一种基于局部极大值点采集的图像处理方法,并成功应用于粘连颗粒图像的处理中,能够有效地将粘连颗粒进行分割。然而传统的图像分割大多采用分水岭或其改进算法,检测速度快但易受到光照、噪声等的影响,导致分割效果不稳定且容易过分割。对于物体堆积严重的图像,传统分割方法和分水岭算法难以满足精确分割的要求,并且严苛的检测条件限制了它们在复杂实际工况中的应用。
目前,深度学习技术在图像分割和目标检测领域取得了显著成果,一些学者将注意力转向了该领域。文献[6]提出了一种基于深度学习的分割方法,用于解决矿石图像相互粘连和图像阴影导致的分割不准确问题。该方法利用整体嵌套边缘检测(HED)模型提取图像的边缘特征,并采用表格查找方法来提取细化的边缘信息,通过区域标记得到最终的分割结果。M.Tao等[7]针对盐矿图像识别问题,对U-Net[8]进行改进,并根据数据特征进一步优化模型,增加了辅助功能、超列和深度监督等机制,并采用多个损失函数来提高模型的泛化能力,使模型在盐矿图像分割任务上取得了较好的效果。李鸿翔等[9]提出了一种基于GAN-UNet的矿石图像分割方法,用于解决矿石图像棱线容易引起矿石边缘错误识别的问题。他们采用生成对抗网络进行图像分割,减小了图像分割误差,提高了分割的精度。X.Hu等[10]提出在骨料分割中采用Mask R-CNN网络模型,并与传统的分水岭分割算法进行了对比,实验结果显示,相比于传统分割方法,Mask R-CNN网络模型在骨料分割任务上表现更好,具有更高的准确性和鲁棒性。以上研究表明,深度学习技术在颗粒分割方向的应用逐渐发展成熟,成为解决颗粒分割在实际工况应用上的新思路。然而使用深度学习算法进行颗粒分割时,仍然存在一定的欠分割和过分割等问题,另外,由于骨料堆叠的特性,堆叠在下方显示不完整的颗粒会对级配计算产生影响。因此需要进一步研究和改进算法,以解决欠分割和过分割等问题,并提高对于堆叠颗粒的识别和分割能力。
针对以上问题,本研究对ISTR(end-to-end Instance segmentation with transformers)网络进行了优化,命名为ISTR-V。同时提出了一种评价指标,以便于评价网络模型的优劣,并对优化前后的网络模型进行了分割效果的对比。通过实验证明了所提出的方法在骨料检测分割任务中的可行性与有效性。
1 实验设备与方法
1.1 实验设备
基于深度学习的粗骨料检测分割方法流程主要包括图像采集、网络模型训练和图像分割。首先,使用图像采集系统获取骨料实际工况的图像,并使用标注工具(如Labelme)对图像进行标注,制作训练样本。然后,通过对标注样本进行网络模型训练,得到实例分割模型。接下来,将实例分割模型部署到工控机中,利用图像采集系统获取实时图像,并对图像进行分割,得到粗骨料颗粒的掩膜轮廓。最后,利用相机标定系数和等效粒径[11]的方法计算出粗骨料的级配。
粗骨料在线测量系统如图1所示,主要由CCD工业相机、传送带和LED灯、计算机处理系统组成。粗骨料被运送到传送带上的检测区域,CCD工业相机被放置在传送带正上方,垂直拍摄粗骨料图像。为了得到均匀的光照,LED灯被布置在传送带上方,以避免粗骨料的阴影对骨料图像的分割产生影响。

图1 粗骨料在线测量系统
1.2 粗骨料分割模型构建方法
1.2.1 粗骨料分割模型
计算机的视觉任务主要包括图像分类、目标检测、语义分割、实例分割等,然而,由于骨料具有堆叠和粘连的特性,并且需要对骨料轮廓进行准确检测,最适合的方法是实例分割。ISTR是一种实例分割Transformer[12],它是同类首个端到端框架[13]。ISTR使用循环优化策略进行检测和分割,相比于现有的自上而下[14]和自下而上[15]的方法,它提供了一种实现实例分割的新方法,在使用相同Backbone的基础上,ISTR分割精度超过了Mask R-CNN、BlendMask、CenterMask等方法,展现出卓越的性能。ISTR的算法框架如图2所示。
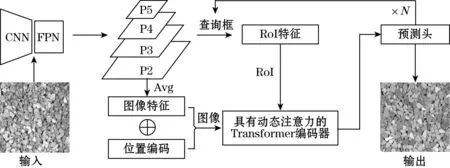
图2 ISTR算法框架图
其主要流程如下:ResNet[16]网络与 FPN[17]结合提取预处理后的图片特征金字塔的P2到P5级的特征,然后,利用初始化K个可学习查询框覆盖整个图像,通过带有RoIAlign的可学习查询框进行裁剪和对齐,提取K个RoI特征,形成对应的特征图(feature map),通过对特征图求和与平均得到图像特征。然后通过具有动态注意力的 Transformer编码器融合图像和预测头的RoI 特征,预测的边界框、类别和掩码在N个阶段中反复细化。最后将多个候选框进行分类、边框回归和掩码生成。
应用ISTR进行骨料分割时,存在未分割的骨料较多的问题,为了解决这个问题,本文将VoVnet作为特征提取网络,选择ISTR作为全局和局部尺度的特征提取模型,并对该方法在骨料检测领域的适用性和有效性进行了分析。
1.2.2 特征提取网络设计
1.2.2.1 特征提取主干网络
ISTR网络通常采用ResNet(deep residual network,深度残差网络)和SwinT(swin transfor-mer)[18]作为其特征提取的主干网络。由于SwinT的检测耗时是ResNet的4倍,在实际应用中可能会存在效率问题。综合考虑分割精度和分割效率,本文选择ResNet作为主干网络进行研究。ResNet虽然一定程度上解决了网络退化和梯度消失问题,但它使用了很多超参数,计算过程复杂。因此,本文提出以VoVNet[19]为主干网络代替ResNet进行特征提取,相比于ResNet更偏向于精度模型的特点,VoVNet兼顾了精度和效率,在推理速度、内存占用、GPU使用率和精确率等方面都比ResNet更具优势。
本文主要对比了ResNet50和VoVNet39 2种网络结构。除了卷积层的分布不同外,VoVnet相比于ResNet在每个阶段多1个Concat操作,表示执行了一次 OSA[19]模块,OSA模块用于聚集在各个层提取到的特征,并最终进行Concat连接,这种设计简化了Bottleneck结构,减少了模块的碎片化程度,从而在性能相差不大的情况下,减少计算量。此外,使用OSA模块使得每个阶段内部的通道数不变,可以降低内存访问成本,提高计算效率。通过使用OSA模块,VoVNet在保证精度的同时,显著提高了运算效率。
在卷积神经网络中,经过多次进行卷积后,获得的特征具有较大的感受野,更适合检测大物体,但对于小物体的检测效果不佳[20]。为了解决这个问题,ISTR将ResNet与特征金字塔模型 (feature pyramid network,FPN)进行了融合。FPN网络模型将深层的强语义特征与浅层的集合信息进行了合并,能够实现对不同尺度目标的检测,并且几乎没有增加检测时间。FPN通过将ResNet生成的特征图与FPN进行上采样后相加,得到了P2、P3、P4、P5等特征图,用于预测物体的边界框、类别和掩码。为了消除上采样过程中的混叠效应,还使用了3*3的卷积核进行处理。通过这种方式,FPN在保持检测精度的同时,能够有效地处理不同尺度的目标。
本文中采用了VoVnet作为特征提取的主干网络,相比于ResNet,VoVnet在小物体检测方面性能显著提高,但对于大物体的检测提升不足。因此修改后的ISTR-V参考了RetinaNet[21]的网络结构对FPN进行了优化,与RetinaNet相比,ISTR-V保留了P2特征图。与ResNet相比,ISTR-V通过在P5之后加3*3的卷积层来实现下采样,增加了P6与P7特征图,去掉了池化操作,并增加了卷积操作。保留P2增加P7的原因是P2更适合小物体的检测,而P7更适合大物体的检测,使用卷积将P6和P7 2个特征图调整为与其他特征图相同的通道数,额外的P6和P7特征图更适用于多尺度的目标检测,可以减少未分割骨料的数目。通过对网络结构的修改,使得ISTR-V在处理尺度跨越较大的骨料图像分割任务时更加适用。在保持小物体检测性能提升的同时,也能更好地处理大物体的检测。修改后网络结构如图3所示。
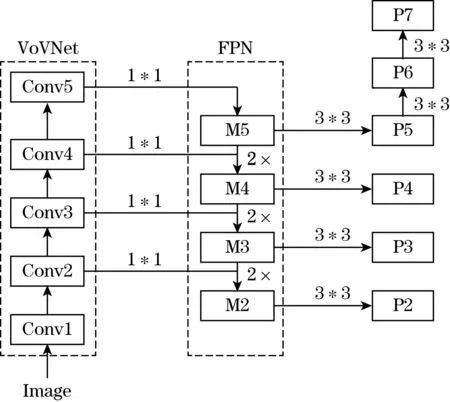
图3 FPN 与VoVNet网络连接示意图
1.2.2.2 感兴趣区域校准
感兴趣区域校准(RoI align)是一种区域特征聚集方法,取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,将整个特征聚集过程转化为一个连续的操作,很好地解决了RoI Pooling操作中2次量化导致的区域不匹配问题,提高了分割掩码的精度。本文中采用的RoI AlignV2与RoI Align相比将所有RoI都移动了半个像素,能够创建更好的图像特征图对齐方式并且不影响性能。
1.2.3 训练网络
训练前,使用Labelme工具对图像进行标注,以获取目标信息,包括每个目标的分类标签、边框和掩码。在训练时,损失函数由回归损失、分类损失、分割损失组成,其定义如式(1)所示:
L=Lbax+Lcls+Lmask
(1)
式中:Lbax为回归损失;Lcls为分类损失;Lmask为分割损失。
回归损失函数目前大多使用的是GIoU[22],如式(2)所示:
(2)
式中:Ac为最小闭包区;U为预测框和真实框的并集。
GIoU与IoU类似,是一种用于度量检测框与真实框之间重叠程度的指标,它的优点是引入最小外接框解决检测框和真实框没有重叠时Loss等于0的问题,缺点是当检测框包含真实框时,GIoU退化成IoU,并且2个框相交时,在水平和垂直方向上收敛慢。为了克服GIoU的缺点,本文提出以SIoU代替GIoU作为回归损失函数,SIoU损失函数由4个成本函数组成,包括角度成本、距离成本、形状成本和IoU成本。计算方式如式(3)所示:
(3)
式中:Δ为距离成本;Ω为形状成本。
SIoU在定义距离成本时考虑了角度成本,相比于GIoU还添加了形状成本,这样的改进使预测框能更快地移动到最近的轴,并随后进行坐标X或Y的回归,从而实现更快的收敛,并且在推理阶段也能够展现出更好的性能。
1.3 粗骨料分割模型评估方法
在实例分割任务中,通常使用均值平均精度(mean average precision,MAP)进行评价,然而MAP并不能准确地反映出分割掩码的质量好坏,为了解决这个问题引入平均交并比(mean intersection over union,MIoU)进行评价,在使用MIoU 进行评价时,由于骨料图像的密集性,不同类型的欠分割和过分割会对MIoU产生不同程度的影响,并且为了统计未分割的粗骨料和在下方显示不完整却被分割出来的骨料的比例,将欠分割率和过分割率细分为4类:
1)未分割率:指在GT(ground truth)中存在,在预测出来的掩码(DT)中不存在的骨料占GT总数的比例;
2)过度分割率:指堆叠在下方显示不完整,不应分割,但在DT中分割出来的骨料占GT总数的比例;
3)过分割率:指在GT中一个骨料被模型分割为多个骨料占GT总数的比例;
4)欠分割率:指在GT中多个骨料被模型分割为一个骨料占GT总数的比例。
模型评估的具体流程如下:首先根据每个预测框的置信度,按照从高到低进行排序,设置一个阈值,只保留置信度高于阈值的预测框,忽略其他的预测框。然后利用DT和GT的轮廓数据建立IoU矩阵,最后通过对矩阵进行处理得到以下5个指标,其中MIoU为主要评价指标,用于综合评估模型的性能,计算方式如式(4)所示。其余为次要评价指标,用于寻找模型存在的问题,计算方式如式(5)~式(8)所示。图4为常见的错误分割图。

(a)未分割 (b)过度分割 (c)过分割 (d)欠分割图4 常见的错误分割图
(4)
式中:A为IoU矩阵;AM为实际轮廓的个数;PM为预测掩码的个数。
(5)
式中:NR为未分割率;CM为矩阵列最大值接近于0的数目。
(6)
式中:SR为过度分割率;RM为矩阵行最大值接近于0的数目。
(7)
式中:OR为过分割率;CMM为矩阵列有多个相近值的数目。
(8)
式中:UR为欠分割率;RMM为矩阵行有多个相近值的数目。
2 实验结果与讨论
2.1 不同材质骨料的分割结果
不同材质的骨料在颜色、纹理、密度等方面具有很大的差异,为了更全面地对比2种网络模型,在这一部分选择了常见的2种材质的粗骨料进行实验,分别是玄武岩、石灰石。粒径保持一致,为10~20 mm。实验结果如表1所示,从表1可以看出,分割玄武岩材质的粗骨料图像,ISTR-V的MIoU相比于ISTR提升了2.8%,为81.5%,而NR相比ISTR降低了2%,为6.1%。分割石灰石材质的粗图像,ISTR-V的MIoU提升了3.1%,为76.8%,而NR降低了6.5%,为11.9%。综上所述,ISTR-V模型在分割不同材质粗骨料图像时精度都更高,这是因为VoVnet采用了多个分支结构,并在不同分支上学习不同的特征图,能够更好地提取丰富的特征表示,增强模型的鲁棒性。
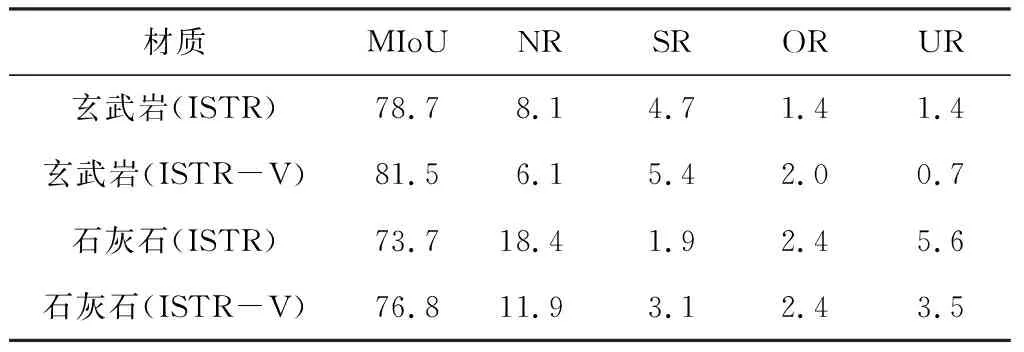
表1 不同材质骨料的分割结果 %
2.2 不同级配的分割结果
在本次实验中,石灰石粗骨料的颗粒尺寸分别为5~10 mm、10~20 mm和20~31.5 mm,分别使用ISTR和ISTR-V对图像进行分割,分割结果如图5所示。从图5可以观察到,在3种粒径范围内,ISTR-V的MIoU均高于ISTR,未分割粗骨料情况有明显改善,与ISTR相比,NR分别降低了4%、2.1%、0%,表明在粒径较大的情况下,ISTR-V与ISTR的分割精度相当,而在中小粒径的情况下,ISTR-V的分割精度有较大幅度提升。这是因为ISTR-V在不同的尺度上进行了特征融合,并增加了P6和P7 2个特征图,能够更好地捕捉不同尺度上的图像信息,进而降低了未分割率。

图5 不同级配的分割结果
2.3 不同工况的分割结果
鉴于不同地区检测粗骨料颗粒的工作环境存在差异,对检测系统的要求也有所不同。为了测试网络的稳定性与泛化能力,对不同工况下的骨料进行分割测试。本次实验中,粗骨料粒径范围为10~20 mm。
首先,对不同含水量的石灰石骨料进行分割测试,结果如图6所示。从图6可以观察到,随着含水量的增加,ISTR和ISTR-V的MIoU均呈下降趋势,而NR则呈上升趋势。然而,与ISTR相比,ISTR-V的MIoU下降幅度较小,NR上升幅度也较小。说明ISTR-V在查全率方面更强,具有更强的稳定性与泛化能力。

图6 不同含水量的分割结果
其次,对不同含泥量的石灰石骨料进行分割测试,结果如图7所示。从图7可以观察到,随着含泥量的增加,ISTR和ISTR-V的MIoU下降幅度都较大。这是由于泥的干扰导致一部分骨料无法正确分割,从而使NR上升;同时,一部分泥被误分割为骨料,导致SR上升,进而导致MIoU急剧下降。然而ISTR-V的MIoU仍然高于ISTR。这是因为ISTR-V在不同的尺度上进行特征融合,并采用稀疏连接的方式,能够更好地适应不同数据分布和任务,从而增强鲁棒性。通过以上2个验证性实验可以证明ISTR-V更加适应复杂的生产环境,具有更强的稳定性与泛化能力。
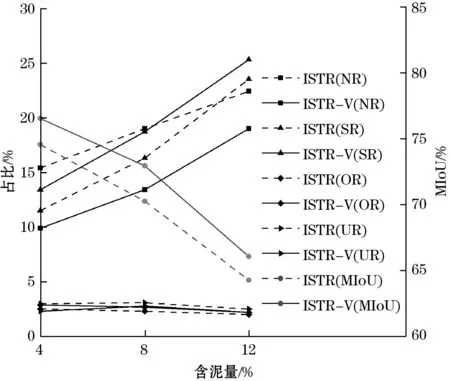
图7 不同含泥量的分割结果
2.4 混合骨料的分割结果
在之前的实验中,主要针对的是单级配的粗骨料,然而实际工况中均是多级配的骨料,相比于单级配的骨料,分布更为复杂,分割难度也相应增加。为了对模型进行更加全面的评价,对石灰石粗骨料的级配料(10~20 mm、20~31.5 mm各50%)分别使用ISTR和ISTR-V进行测试,分割结果如图8和表2所示。
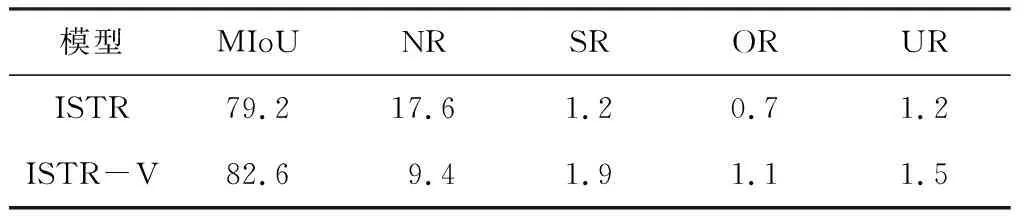
表2 混合骨料的分割结果 %

(a)原图 (b)ISTR(c)ISTR-V图8 混合骨料的分割结果
通过图8中(b)和(c)的对比可以看出,ISTR-V在未分割骨料较多的问题上有明显改善。表2中的数据也证明了这一点,与ISTR相比,ISTR-V的MIoU提升了3.4%,为82.6%,未分割率降低了8.2%,为9.4%。这一改善的原因在于,ISTR-V采用了SIoU计算方式,该方式不依赖于目标框的具体尺寸和比例,因此可以更准确地评估不同尺寸和比例的目标框之间的重叠程度,提高模型在处理不同尺寸和比例目标时的预测鲁棒性,从而显著降低了未分割率,提升了MIoU。
通过以上实验结果可以得出结论:ISTR-V在处理多级配的混合骨料时表现出更好的分割性能,进一步证明了ISTR-V在复杂骨料分割方面的优势。
3 结束语
为解决粗骨料分割中出现的欠分割、过分割等问题,本文对ISTR网络进行了改进和优化,并提出了一种评估方法对网络模型进行评估,实验结果表明:
1)采用实例分割模型可以准确地对粗骨料堆叠工况下的图像进行分割,并且能够适应不同条件下的复杂工况;
2)本文所提出的评估方法可以方便快捷地对网络模型进行总体分割评估,便于比较模型的分割效果,并对模型存在的问题进行量化,有利于后续的分割算法改进;
3)实验结果表明,改进后的ISTR-V网络模型提高了分割精度,与ISTR模型相比,ISTR-V在MIoU方面提升了3.4%,未分割率降低了8.2%,证明了改进网络模型的可行性与有效性。
改进后的ISTR-V提高了MIoU并显著降低了未分割粗骨料的比例,但仍存在9.4%骨料未分割,同时对于过度分割的骨料比例控制效果不明显,在后续的研究工作中,重点在于降低未分割率和过度分割率,进一步提高实例分割算法对粗骨料图像的分割精度和泛化能力。
