面向复杂工业过程的虚拟样本生成综述
2024-04-30崔璨麟乔俊飞
汤 健 崔璨麟 夏 恒 乔俊飞
信息技术的不断发展和工业自动化进程的不断 深入,利用多类型传感器采集的海量多模态数据能够支撑构建“工业大数据”驱动模型,这已成为复杂工业过程实现智能控制、决策与优化的重要手段[1-4].然而,复杂工业过程的产品质量、污染物排放等难测关键运行指标和异常故障的建模数据依然存在量少稀疏、分布不平衡以及内涵机理知识匮乏等问题,难以支撑构建准确且鲁棒的检测与识别模型[5-7].以城市固废焚烧(Municipal solid waste incineration,MSWI)过程为例,该过程排放的痕量有机污染物二噁英(Dioxin,DXN) 因受限于在线检测技术的复杂度和离线化验技术的高成本,使得具有真值的建模样本数量极少[8-9];此外,已有的真值样本通常是在某种稳定的次优运行工况下获得的,极优工况和潜在异常工况下的样本数据是缺失的.这些有限数量的真值样本中显然缺乏有助于洞悉运行指标的相关机理,造成与建模相关的内涵知识匮乏.为解决上述问题,从扩增建模样本数量的视角,早期模式识别领域的研究学者Poggio 和Vetter 提出虚拟样本生成(Virtual sample generation,VSG)的概念[10],其核心思想是基于已有数据通过某种方式生成并不存在的样本以扩充数据空间,其目前已广泛地应用于图像处理[11]、人脸识别[12]以及可靠性分析[13]等领域.图1 给出了近20 年内与VSG 相关的文献发表数量与被引频次的变化情况.
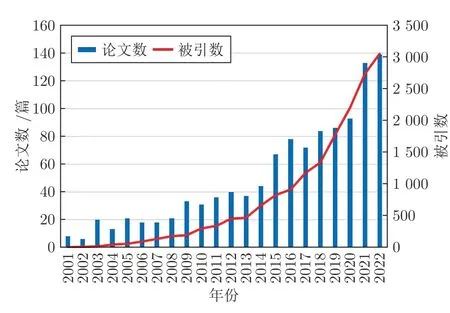
图1 Web of Science 上的VSG 论文数量与被引频次Fig.1 Number and citation frequency of articles on VSG in Web of Science
由图1 可知,有关VSG 的论文发表量和被引量在总体上呈现上升趋势,表明该技术已逐渐受到研究学者的重视.虽然,Niyogi 等从数学视角证明了虚拟样本等价于将先验知识合并为正则化矩阵[14],但复杂工业过程固有的机理不清、强耦合和非线性等特性,使得从该类过程获得明确的先验知识存在难度大和耗时长等问题,这导致目前研究学者大多聚焦于如何从小样本中学习知识进而生成虚拟样本的研究[15].随着变分自编码器(Variational autoencoder,VAE)[16-18]、生成对抗网络(Generative adversarial network,GAN)[19-20]等生成模型的发展,使得VSG 的研究热度得到进一步的提升[15].随着工业数字孪生[21-22]、元宇宙[23-24]等概念的发展和日趋成熟,笔者认为,VSG 技术将成为上述技术发展中不可或缺的元素之一.综上,VSG 技术的逐步完善与成熟,能够为实际复杂工业过程的运行指标建模和异常故障识别乃至工业数字孪生和元宇宙提供有效支撑,有必要对当前VSG 的研究动态与未来趋势进行总结与展望.
本文以工业过程为背景,全面综述VSG 在工业过程中的研究现状及未来的发展方向,主要工作如下: 第1 节从样本稀缺、样本分布完备性差和样本内涵机理知识匮乏共3 个视角总结工业过程VSG 所面临的问题,并梳理虚拟样本定义、输入/输出空间虚拟样本内涵以及面向工业过程的实现流程;第2 节根据目前的研究成果和实际工业过程的特点,从样本覆盖区域、实现流程与推广应用共3个方面进行综述;第3 节给出相关的数据集和开源软件;第4 节进行对比与讨论,并分析下一步的发展方向;第5 节对全文工作进行总结并给出未来挑战.
1 面向工业过程的VSG 技术
1.1 运行指标和异常故障建模存在的问题
目前,对系统性能、生产质量和经济效益的高要求使得现代工业过程的复杂度、包含的设备类型和数量也迅速增加,多类型传感器和自动化系统的应用促成了“工业大数据”以及工业过程建模、控制与优化研究[25].相应地,基于数据驱动的运行指标和异常故障建模技术也得到迅速发展[26].但是,技术上仍难以在线检测的部分运行指标和难以再现的异常故障却导致可用建模样本量稀缺的现象[27].此外,复杂工业过程机理不清难以建模的特性和工业现场以确保安全稳定运行为目标的次优运行状态,使得建模数据还存在着分布不平衡以及内涵机理知识匮乏等问题.
1.1.1 样本稀缺
针对难测运行指标而言,以MSWI 过程的DXN排放浓度检测为例,其可采用离线直接检测法和在线间接检测法进行测量,但存在过程繁琐、价格昂贵、设备复杂和时间滞后等局限性;企业以月或季为间隔的不定期检测导致建模样本极为稀缺[8].这需要采用适合于小样本数据的学习算法[28].
针对复杂工业过程的故障检测与诊断(Fault detection and diagnosis,FDD)模型而言,异常故障样本属于“可遇不可求”,同时工业现场也是极力避免出现这样的故障,即会在异常出现前通过定期维修、降低生产效率等方式予以预防,因而导致样本缺失,增加了故障分类模型的构建难度[29-30].
文献[31]指出,当在工程应用和学术研究中采用的建模样本数量分别少于50 和30 时,所面对的机器学习问题即被称为小样本学习问题;进一步,文献[32]将该问题表示为下式:
式中,nsample为样本数,pfeature为特征数,α的典型取值为 {2, 5, 10}.显然,α过小的数据集难以为构建可靠的学习模型提供支撑.
1.1.2 样本分布完备性差
为保证工业全流程的运行安全性,实际工业过程常工作在折衷的稳定状态,甚至以牺牲经济性确保安全性为代价使工业过程长期运行在次优状态[33].因此,即使采集了大量的过程数据,但其所涵盖的工况波动范围和所具有的代表性样本数量也是有限的,即多数为常规次优工况数据和少数为极优与潜在异常工况数据.这些数据难以表征期望建模样本空间中所需要的完备分布.本文将上述问题归纳为样本分布完备性差,这会导致所构建的模型仅适用于稳定的次优运行过程,难以适用于存在工况动态漂移变化的实际过程[34].
在故障诊断中,正常样本和异常故障样本间呈现的是长尾分布,即正常运行与常见故障为头部多数类而罕见故障为尾部少数类,这也是样本分布完备性差的体现,其会严重影响故障诊断的结果.度量少数异常类和多数正常类之间不平衡度的指标,即不平衡比(Imbalance ratio,IR)[35]如下所示:
式中,Nmajority和Nminority分别为多数正常类和少数异常类样本的数量.显然,IR 值越大表示建模样本集的不平衡程度越严重.在文献[36]所构建的感应电动机故障诊断模型中,IR 的值达到了10.
虽然目前已有针对少样本或零样本的故障诊断研究成果[37-39],但其在本质上并未解决样本分布完备性的问题.
1.1.3 样本蕴涵机理知识匮乏
用于难测运行指标与异常故障建模的过程数据所蕴涵的机理知识匮乏的原因在于: 首先,样本数量稀缺;其次,样本分布不完备使得从数据中获取机理知识难,尤其是在数据均源于单一工况的情况下;再次,工业过程的机理复杂不清导致知识理解难.
文献[40]指出,针对在生产阶段早期采集的过程数据而言,其所蕴涵的知识有限,难以为推理样本分布提供支撑.文献[34]认为,虽然现代工业的规模在不断扩大,但可用的过程信息却极为稀缺.进一步,文献[41]利用迁移学习从类似工况或设备的历史数据中获取知识,将其用于当前过程关键工艺参数的预测;文献[42]指出,进行跨阶段(Crossphase)、跨状态(Cross-state)、跨实体(Cross-entity) 和跨领域(Cross-domain)的迁移学习,是工业过程中获取知识的途径之一.但是,如何基于有限的建模样本和复杂工业过程的经验知识,获得建模样本所蕴含的知识依然是一个开放性的问题.
1.2 虚拟样本的定义及内涵
1.2.1 虚拟样本的定义
虚拟样本的概念由Poggio 和 Vetter 于1992年提出并用于模式识别领域[10],但并未给出明确定义.文献[43]给出了如下所示的较为通用定义.
定义1.对于给定训练样本 (xi,yi),若由变换(T,fT) 得到的样本(,) 也是一个合理的样本,那么就称新样本 (,) 是由变换 (T,fT) 所生成的虚拟样本.
基于定义1,文献[6]给出如下的推论:
1.2.2 虚拟样本输入空间内涵
由于难测运行指标和异常故障建模样本的分布完备性差,即样本分布在某个或某几个区域,导致样本间存在大量间隙,因此需要考虑对原始域样本空间进行有效填充.此外,原始域样本空间之外也可能会存在符合实际数据分布的扩展域,需对原始域进行有效扩展,但扩展后可能会超出完备域(期望域)样本空间.从可视化的角度,图2 给出了二维平面内原始域、扩展域和完备域(期望域)样本空间之内的虚拟样本和真实样本的相互关系[44].

图2 样本输入空间内虚拟与真实样本间的关系Fig.2 Relationship between virtual samples and real samples in sample input space
由图2 可知,生成的虚拟样本共有4 类: 1) 在原始域样本空间内部填补真实样本间隙的合格虚拟样本;2) 在原始域样本空间外完备域(期望域)样本空间内的扩展域空间的合格虚拟样本;3) 在扩展域样本空间外、完备域(期望域)样本空间内的合格虚拟样本;4) 在完备域(期望域)样本空间外需剔除的不合格虚拟样本.
进一步,文献[45]给出了三维空间视角下的不同虚拟样本输入生成方法的局限性,如图3 所示.
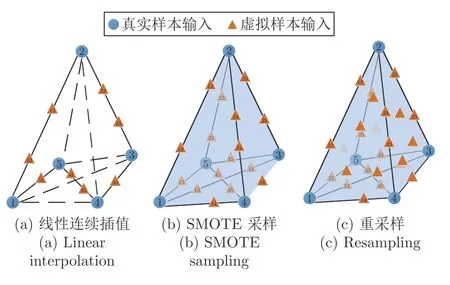
图3 三维空间下的不同虚拟样本输入生成方法示意图Fig.3 Diagram of different virtual sample input generation methods in 3D space
在图3 中,标记的数字是真实和虚拟样本编号,以数字“12”为例,其表示虚拟样本12 是在真实样本1 和2 的连线上生成的.具体而言,图3(a)所示为依据样本顺序采用线性连续插值法依次在真实样本间插值生成虚拟样本输入,即其仅分布在真实样本输入的顺序连线上;图3(b) 所示为合成少数类过采样技术(Synthetic minority over-sampling technique,SMOTE),其表示随机选择两个真实样本并在其间进行线性插值的方式,显然其丢失了真实样本间可能存在的时序关系与物理含义;图3(c) 所示为重采样法,其能够在真实样本的连接“面”上生成虚拟样本输入,但在由真实样本组成的空间内部并未生成虚拟样本,即存在样本“空洞”.
由上可知,虚拟样本输入的生成方式需要依据待解决问题而异,因此结合机理知识和经验知识是必要的.
1.2.3 虚拟样本输出空间内涵
针对样本输出空间而言,回归和分类问题具有完全不同的方式,下文分别描述.
1) 回归问题
如何为虚拟样本输入匹配高精度的输出是面向回归的VSG 需要面对的关键问题,其在极大程度上决定了虚拟样本的优劣.
目前,一般通过构建基于小样本的映射模型生成虚拟样本输出.Li 等[46]提出当映射模型的平均绝对百分比误差(Mean absolute percentage error,MAPE)不超过10%时,其可用于生成虚拟样本输出.基于映射模型生成虚拟样本输出的流程如图4所示.

图4 映射模型生成虚拟样本输出流程图Fig.4 Flow chart of virtual sample output generation based on mapping model
针对不同的映射模型结构,通过调整参数虽然可达到上述要求,但由于模型自身的差异性,由相同虚拟样本输入所映射的输出间也存在不同.因此,为得到更佳的虚拟样本输出,映射模型需对数据集具有较好的适应性.
2) 分类问题
相较于回归问题,面向分类的虚拟样本输出所面临的问题是类间不平衡,即某些类的样本数量远少于另外一些类.
针对故障诊断模型而言,充足的训练样本和完备的故障类型是需要满足的两个基本条件[47].受工业过程复杂性和检测环境不稳定性等限制,异常故障数据采集困难,某类故障甚至不可再现[48].图5给出了多数正常类和少数异常类真实样本与虚拟样本间的关系.
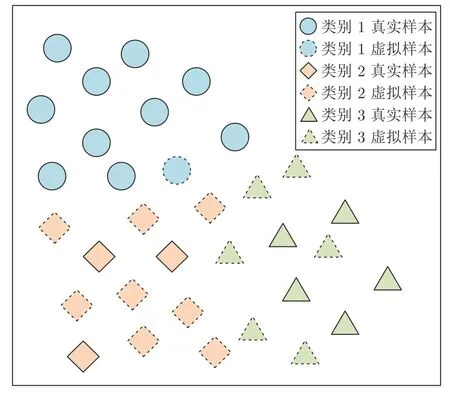
图5 面向分类问题的虚拟与真实样本间的关系Fig.5 Relationship between virtual samples and real samples for classification problem
由图5 可知,面向分类问题的VSG 的特点为:a) 数量少的类别(少数类)需要生成更多的虚拟样本,数量多的类别(多数类)只需生成少量甚至不生成虚拟样本;b) 少数类虚拟样本主要生成稀疏区域以填补信息空缺;c) 多数类和少数类都需要在分类边界上生成一定量的虚拟样本.此外,因工业过程的动态变化,还可能存在不能采集到样本的未知类,这需要机理知识与经验知识支撑.
从本质上,回归问题和分类问题中的VSG,都很难从复杂工业过程获得清晰机理知识和领域先验知识.从理论支撑方面而言,Niyogi 等通过数学推导证明了虚拟样本等价于合并先验知识以作为正则化矩阵[14],但是,在期望分布、虚拟与真实样本相似度以及混合样本组成等方面的研究还缺乏理论支持.
1.3 面向工业过程的VSG 实现流程
基于小样本建模数据的工业过程VSG 实现流程如图6 所示.
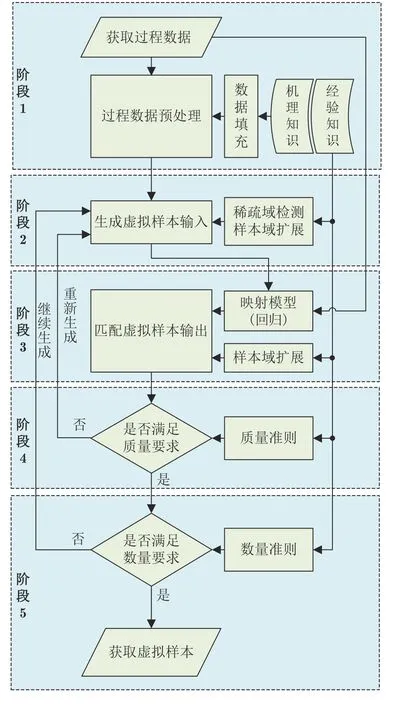
图6 面向工业过程的VSG 实现流程图Fig.6 Flow chart of VSG for industrial process
如图6 所示,步骤如下:
1) 第1 阶段为过程数据预处理,包括高维数据降维、缺失数据填补和过程数据标准化等操作以及机理与经验知识获取.
2) 第2 阶段为生成虚拟样本输入,对于回归问题而言要求能够填补完备域样本空间,对于分类问题而言要求保证少数类和多数类间的平衡性.
3) 第3 阶段为匹配虚拟样本输出,对于分类问题而言,因其类别标签是预设的和确定的而相对简单.对于回归问题而言,其输出真值需通过映射模型进行匹配而相对复杂.但分类问题可能需要考虑未知类.
4) 第4 阶段为生成虚拟样本质量筛选,通过相似性度量以及建模结果误差等准则进行筛选以保证虚拟样本质量.
5) 第5 阶段为生成虚拟样本数量确定,通过获得理想的期望数量以减少计算成本和提高模型精度,目前还缺少理论支撑.
在上述流程中,第1 阶段是VSG 的必要操作,第2 和3 阶段是VSG 的基础操作,第4 和5 阶段是生成高质量虚拟样本的重要保障.
此外,在已有研究成果中,存在先进行阶段3再进行阶段2 的VSG 流程,如文献[20]和文献[49]等.这类方法相对较少,本文在后文综述时也予以说明.
2 VSG 的研究现状
本节将面向工业过程数据的VSG 研究现状从样本覆盖区域、实现流程和推广应用共3 个方面进行综述,之后针对每个方向再进行展开叙述,具体如图7 所示.

图7 VSG 的研究现状结构图Fig.7 Structure diagram of VSG research status
2.1 基于样本覆盖区域分类的研究现状
2.1.1 基于原始域样本空间的VSG
基于原始域样本空间的VSG 通过挖掘原始样本间的分布关系以生成虚拟样本,其重点关注的是原始域样本空间的稀疏区域,目的是通过虚拟样本填补真实样本间的空隙.下文针对回归和分类问题分别从特征工程和样本工程2 个视角进行描述.
1) 面向回归问题的VSG
a) 特征工程
复杂工业过程的运行指标建模数据具有高维度特性[50-51],对应的稀疏区域难以识别,这导致直接进行VSG 存在困难.因此,先进行特征工程是广泛采用的解决方法.下面从特征变换、特征选择和两者综合共3 个方面进行综述.
特征变换是指通过线性或非线性的方式将原始数据变换至新的低维或高维空间.Zhu 等[52]先采用局部线性嵌入(Locally linear embedding,LLE)算法对高维数据进行降维,再基于随机插值生成虚拟样本输入,最后通过反向传播神经网络(Back propagation neural network,BPNN)映射模型得到虚拟样本输出.Zhang 等[53]基于等间隔映射 (Isometric feature mapping,Isomap) 对高维数据进行可视化以寻找稀疏区域后采用插值法和映射模型生成虚拟样本.文献[54]采用t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法,在提取原始高维特征后再插值生成虚拟样本输入,通过随机森林(Random forest,RF)映射模型得到虚拟样本输出.上述这些方法的本质是在变换后的特征空间中获得易生成虚拟样本的区域,但并未考虑原始特征中可能存在的冗余和变换后特征失去的原有物理含义等问题.
相较于特征变换,特征选择虽然会舍弃掉部分特征,但能够保留清晰的物理含义,更适合于在输入输出间具有较强因果关系的工业过程.陈忠圣等[55]基于精对苯二甲酸生产过程的机理,选择影响醋酸消耗的17 个因素作为输入特征后采用分位数回归条件GAN 生成虚拟样本.该方法适用于减少特征后可清晰地获得易生成区域的建模样本,但也存在约简后仍然难以分辨稀疏区域以及忽略的特征在未知工况下可能造成的未知影响等问题.
此外,现有研究成果中也存在串联特征变换和特征选择两种方式生成虚拟样本的策略[56],该研究根据专家经验和MSWI 过程DXN 排放机理选择输入特征后再基于改进大趋势扩散和隐含层插值生成虚拟样本.这类方法需结合具体工业过程予以应用,具有较强的定制化特性.
b) 样本工程
样本工程旨在直接学习原始真实样本所表征的分布关系,基于样本“间隙”生成虚拟样本.根据所选用模型的不同,可分为基于函数模型插值和基于对抗模型生成两种方式.
基于函数模型插值的VSG 是指通过某种函数表征原始真实样本的间隙,基于该函数生成虚拟样本输入后再结合映射模型生成虚拟样本输出.典型方法包括分段线性插值、径向基函数(Radial basis function,RBF)插值和三样条插值(Cubic spline interpolation,CSI)等.Zhu 等[57]采用空间投影法进行稀疏性检测以得到原始样本间的空隙,利用中点插值和RBF 映射模型生成虚拟样本.进一步,Chen 等[49]基于稀疏性假设和中心假设确定虚拟样本数量,基于CSI 生成虚拟样本输出后再经过输入训练神经网络(Input-training neural network,ITNN) 获得虚拟样本输入,结果表明可有效地提高模型性能.Sutojo 等[58]采用总线拓扑结构,在原始样本间连接后再在连接线上插值生成虚拟样本的策略.
目前,在如何选取合适的用于产生虚拟样本输出的映射模型方面还不存在统一定论.相关研究包括: 通过随机权神经网络(Random weight neural network,RWNN)模型学习样本间的非线性关系后在其隐含层插值以生成虚拟样本的策略[59],其首先在真实样本输出之间插值生成虚拟样本输出,然后在隐含层插值得到新隐含层并反向求出虚拟样本输入,最后组合虚拟样本输入和输出;进一步,朱宝等[60]提出在自联想神经网络(Auto-associative neural network,AANN)的隐含层插值生成虚拟样本以消除样本间的噪声;再随后,乔俊飞等[56]提出基于等间隔插值和正则化RWNN 隐含层插值获取虚拟样本并删除冗余样本,进而增强了虚拟样本的稳定性和互补性;进一步,汤健等[61]提出基于粒子群优化(Particle swarm optimization,PSO)算法优化选择上述方法所生成的虚拟样本以降低虚拟样本之间的冗余性;为了有效地均衡虚拟样本数量和模型泛化性能,文献[15]提出基于多目标PSO 混合优化的VSG,其采用RF 和RWNN 集成模型作为非线性映射模型.
近些年,深度学习在学术界发展迅速并在工业界广泛应用,体现出极强的处理复杂任务的能力[62].GAN 是目前深度学习中最为热门的研究方向之一[19],其虽已广泛应用于图像生成领域,但在工业过程VSG 中的研究才刚刚起步[63].GAN 的基本原理是:通过生成器和判别器的博弈对抗使得生成的虚拟样本越来越接近真实样本,生成器的目标是生成判别器无法判别的样本,判别器的目标是准确识别真实样本和虚拟样本,其结构如图8 所示[63].
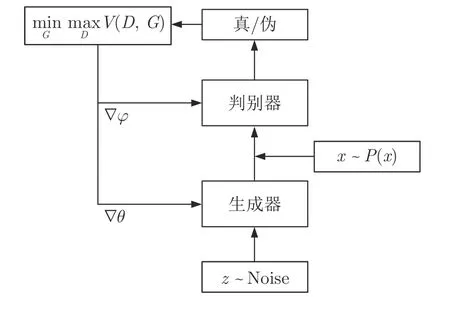
图8 GAN 模型的结构Fig.8 Structure of GAN model
GAN 的目标函数表示如下:
式中,pdata为原始小样本的分布;pz为随机噪声的分布;D(x) 和G(z) 分别表示判别器和生成器的输出.
面向回归问题,针对基于GAN 的VSG,如何为其所生成的虚拟样本输入映射合理的输出是目前的研究难题.对此,Zhu 等[20]通过计算局部异常因子(Local outlier factor,LOF)确定稀疏区域,采用K-means++算法计算簇的中心后插值生成虚拟样本输出,将其作为条件GAN (Conditional GAN,CGAN)的条件变量生成相应的虚拟样本输入;在此基础上,文献[64]提出基于循环结构CGAN (Cycle structure CGAN,CS-CGAN)的VSG,采用最近邻距离确定离群点以获得稀疏区域边界,通过WGAN-GP 在稀疏区域生成虚拟样本输入,之后利用CS-CGAN 生成和选择虚拟样本输出;进一步,He 等[65]通过GAN 内嵌分位数回归器生成与虚拟样本输入相匹配的虚拟样本输出.上述方法均未考虑如何结合具体工业过程领域知识进行区域扩展和确定虚拟样本数量.
2) 面向分类问题的VSG
a) 特征工程
目前,面向分类问题的VSG 多应用于故障诊断领域,采用特征工程进行处理的故障样本大多为机械振动信号.这类VSG 的特点是: 先采用快速傅里叶变换(Fast Fourier transform,FFT) 将时域信号转换至频域再在生成模型中对特征进行处理,如: 添加卷积层提取特征[66-67]、采用编码器提取特征[68]以及添加自注意力模型增强特征[69]等.
b) 样本工程
从函数模型插值和对抗模型生成两个方面进行介绍.相较于回归问题而言,因无需考虑生成虚拟样本输出,已有的面向分类问题的VSG 更关注类与类之间的关系以及类间数据的平衡.
SMOTE 通过在邻近少数类样本间的随机线性插值生成少数类的虚拟样本,进而实现不平衡数据集的均衡化[70],如下所示.
式中,xi为第i个少数类样本,为xi的第j个K近邻样本,为生成的虚拟样本,rand(0,1)为服从(0,1)范围均匀分布的随机数.
SMOTE 可归类为基于分段线性插值的VSG方法.在此基础上,Mathew 等[71]提出基于加权核的SMOTE,其通过在支持向量机(Support vector machine,SVM)的特征空间中进行插值生成虚拟样本的方式解决算法在高IR 下的非线性可分离问题;进一步,Maldonado 等[72]提出面向高维数据集的改进SMOTE,通过特征排序法选择相关特征后采用Minkowski 距离替换欧氏距离以生成高维虚拟样本;谢桦等[73]先通过SMOTE 生成虚拟样本,再采用决策树算法提取有关变压器状态的评估知识;随后,刘云鹏等[74]针对变压器非正常状态的样本数量稀少的问题,提出基于SVM 和SMOTE 的变压器故障诊断方法,其核心理念是在支持向量近似的分类边界上采用最近邻决策机制生成虚拟样本输入;Soltanzadeh 等[75]针对噪声样本偏移和边界样本重叠等问题,提出可以识别类类边界和控制生成范围的SMOTE.
针对多类数据混杂问题,文献[76]提出采用组发现技术对原始样本进行预分类以生成指定类的虚拟样本,其过程为: 先任选样本点P1,将与P1同类和不同类样本点间的最小距离记为R1;接着再以P1为球心和R1为半径构建超球体;之后进行判断,若在超球体内存在与P1同类的样本P2,则P1和P2为同组;最后,以P2为球心重复上述操作,直至超球体不包含新的同类样本,进而完成预分类.随后,文献[77]在组发现技术的基础上采用纯化过程剔除相近的非同类样本以保证分组的准确性,之后再通过构造超球以生成虚拟样本输入,实验表明该策略能够有效地提高接地网络的故障识别率.
由于面向分类问题的虚拟样本输出为类别标签,故其可作为已掌握的条件信息控制生成模型以获得指定类型的虚拟样本.例如,文献[78]将少数类的标签作为条件信息输入CGAN,结构如图9 所示.
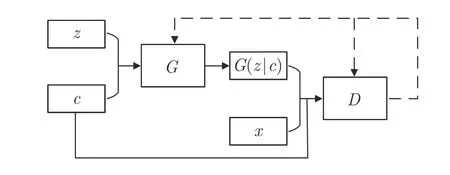
图9 基于CGAN 的VSG 模型结构Fig.9 VSG model structure based on CGAN
在图9 中,随机噪声z和类别标签c共同注入生成器G,其中c作为条件信息控制G生成对应的虚拟样本输入G(z|c);将真实样本输入x和虚拟样本输入G(z|c) 注入判别器D后根据判别结果更新D和G.
基于上述模型结构,黄南天等[79]构建基于辅助分类器GAN (Auxiliary classifier GAN,ACGAN)的风机主轴承故障诊断模型,提出通过添加Dropout层防止过拟合以减少重复样本生成的策略;Li 等[80]采用具有梯度惩罚的辅助分类Wasserstein GAN(Auxiliary classier Wasserstein GAN with gradient penalty,ACWGAN-GP)生成具有高质量的少数类虚拟样本以提高模型准确率;Dixit 等[81]提出采用模型无关元学习(Model agnostic meta learning,MAML)算法替换常规的随机梯度下降算法进而初始化和更新网络参数的条件辅助分类GAN,提高了生成模型的稳定性;Yang 等[82]采用基于GAN的VSG 解决谐波传动故障数据不平衡问题后利用多尺度卷积神经网络(Convolutional neural network,CNN)进行故障诊断;Wang 等[67]采用深度卷积生成对抗网络(Deep convolutional GAN,DCGAN)生成虚拟样本平衡训练集后通过K-means聚类算法构建改进CNN 诊断模型;Zareapoor 等[83]提出采用判别器既判断样本真假又充当分类器和故障检测器的少数类过采样GAN (Minority oversampling GAN,MoGAN) 策略,有效地提高了虚拟故障样本的质量;之后,Li 等[84]和Li 等[85]对WGAN进行改进以稳定生成的故障样本质量;李东东等[86]基于贝叶斯优化策略自适应调节GAN 的判别器参数和采用Wasserstein 距离作为损失函数提高模型的泛化性能,结果表明其能够有效提高虚拟样本的质量;此外,也有研究人员组合多个GAN 进行VSG后,再通过筛选提高虚拟样本的质量[82].在上述研究中,仅是考虑了依据已知的类别生成虚拟样本输入,但如何面对动态环境下的未知类别进行VSG 还有待于研究.
GAN 的本质是基于博弈对抗的训练框架,其能够训练任意类型的生成模型.自编码器(Autoencoder,AE)作为一种非线性无监督神经网络[87],通过非线性变换将输入数据投影至潜在特征空间中.变分AE (Variational AE,VAE)是以AE 结构为基础的深度生成模型[88].将编码器与GAN 进行组合可得到基于编码器的GAN,其在VSG 领域的研究成果包括: 戴俊等[89]将AE 的解码器嵌入至GAN中作为生成器,并通过编码-解码-编码过程后的特征差异判断是否存在异常;Wang 等[68]建立基于条件变分自编码器GAN (Conditional VAE GAN,CVAE-GAN)的不平衡故障诊断模型,通过CVAE获取故障样本分布作为生成器输入,利用博弈对抗机制对生成器、判别器和分类器的参数进行优化;Liu 等[90]将编码器合并到GAN 中,通过学习真实数据的深度特征以提高数据生成质量,通过深度遗憾分析算法对判别器施加梯度惩罚以避免模式崩溃,实验表明具有较好的鲁棒性;Wang 等[91]设计具有传输层的改进型AE 以消除数据噪声,采用暹罗编码器结构计算潜在特征之间的残差,引入最小二乘GAN (Least squares GAN,LSGAN)学习健康数据分布以生成虚拟样本,结果表明可提前检测潜在异常;Liu 等[92]将自调制嵌入到GAN 的生成器中,使其能够同时依靠输入和判别器反馈进行参数更新;Rathore 等[93]提出结合堆叠AE 和WGAN的VSG 策略,提高了虚拟样本的质量.可见,如何获得具有可解释性的GAN 还有待深入研究,例如基于模糊或决策树算法.此外,面向回归问题的基于编码器的GAN 还有待进一步研究.
2.1.2 基于扩展域样本空间的VSG
理论上,由真实小样本组成的原始域样本空间是完备(期望)域样本空间的子集[44],其蕴含信息有限.从实际工业过程视角,所采集的真实小样本多源自于某种平稳工况,但完备域样本空间需要同时覆盖平稳与非平稳工况.因此,研究人员开始关注在原始域样本空间(易获取数据)上进行扩展以得到扩展域样本空间(难获取数据),并在其上生成虚拟样本,进而能够接近完备域样本空间[15].理论上,扩展域可分为可扩展域和未知域,后者无数据可用,即不存在真值或是未知类别.针对工业过程的多输入单输出回归和分类问题,面向VSG 的原始域、可扩展域和未知域的示意图如图10 所示.
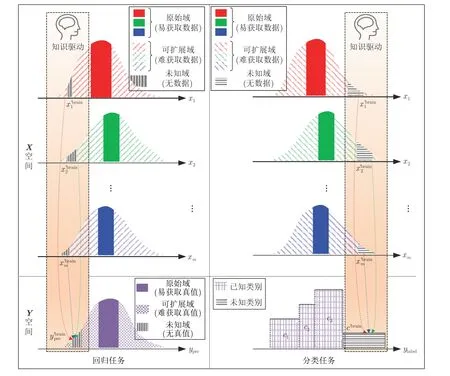
图10 面向VSG 的原始域、可扩展域和未知域的示意图Fig.10 Schematic diagram of original,extension,and unknown domain for VSG
笔者将基于扩展域样本空间的VSG 分为面向集合理论、面向分布假设和基于知识共3 类,从回归和分类2 个方面进行综述.
1) 面向回归问题的VSG
a) 集合理论
工业过程的真实小样本携带的有限信息导致进行VSG 存在不可避免的不确定性.模糊集理论是处理具有随机和不确定特性数据的有效手段.鉴于此,Huang[94]提出通过模糊数学进行样本集值化的处理方法,即信息扩散,其原理为: 通过三角、正态以及梯形等隶属度函数确定样本所蕴含信息的扩散范围.在此基础上,Huang 等[95]将正态扩散函数与神经网络相结合提出扩散神经网络(Diffusion neural network,DNN),但该方法仅适用于特征间的相关系数大于0.9 的情况.随后,Li 等[96]在DNN的基础上提出大趋势扩散(Mega-trend-diffusion,MTD)技术,如图11 所示.
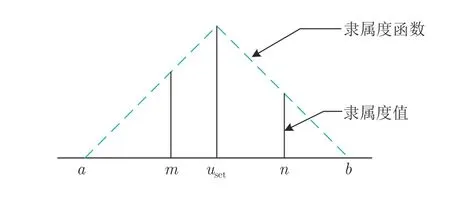
图11 大趋势扩散技术Fig.11 Mega-trend-diffusion technology
在图11 中,m和n表示2 个给定数据,b和a表示扩散函数的上界和下界,uset表示样本变量取值的中心.
由上可知,MTD 假设特征变量间相互独立和能够不对称地扩展特征范围,进而能够在可扩展域上基于采样方式生成虚拟样本;进一步,Lin 等[97]提出广义趋势扩散(Generalized-trend-diffusion,GTD)技术,即通过计算连续数据之间的趋势以获得序列数据的时间依赖性,并采用所生成的虚拟样本解决柔性制造系统调度建模问题.此外,Li 等[98]通过集成MTD 和树模型提出基于树结构趋势扩散(Tree structure based trend diffusion,TTD)的VSG,在多层陶瓷电容的介电系数预测实验中验证了其有效性.Rahimi 等[99]提出基于神经网络的MTD,采用生成的虚拟样本构建聚合物CO2预测模型.朱宝等[100]提出采用三角分布和均匀分布共同表征小样本特性的多分布MTD (Multi-distribution MTD,MD-MTD)技术,如图12 所示.
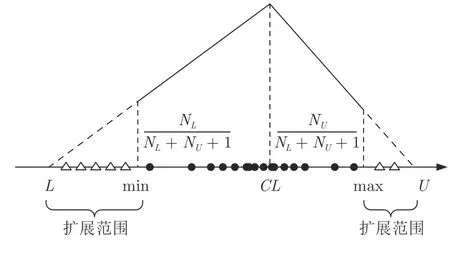
图12 MD-MTD 示意图Fig.12 Schematic figure of multi-distribution MTD
在图12 中,MD-MTD 采用三角分布在原始域样本空间表示真实小样本的分布情况,采用均匀分布在可扩展域样本空间生成虚拟样本.
Sivakumar 等[101]提出基于K近邻(K-nearest neighbor,KNN)的MTD,其通过原始样本的KNN计算扩展范围以确保虚拟样本的合理分布.Khamis 等[102]提出基于K-means 的改进MTD,主要创新在于解决隶属度函数构建过程中的属性冗余问题.此外,也有研究人员采用组合多种信息扩散技术的策略生成混合虚拟样本,如: 高克铉等[103]提出改进型MTD (Advanced MTD,AD-MTD),结合文献[100] 所提出的MD-MTD 获得混合整体MTD (Hybrid-MTD),充分利用各自优势.研究人员也提出结合MTD 与其他插值方式的策略,如乔俊飞等[56]同时采用了MTD 和隐含层插值.
与直接在可扩展域样本空间内以采样的方式获取虚拟样本不同,Li 等[46]在采用MTD 确定扩散范围后,先基于遗传算法(Genetic algorithm,GA)生成虚拟样本输入,再通过基于可行性的规划(Feasibility-based programming,FBP)模型生成虚拟样本输出;Chen 等[104]先提出基于三角隶属度的信息扩散(Information-expanded based on triangular membership,TMIE)技术,再在确定的范围后采用PSO 算法获得虚拟样本输入,最后通过RWNN得到虚拟样本输出.此外,针对不同VSG 所产生虚拟样本间存在的冗余性与互补性,汤健等[61]采用PSO 算法对基于领域专家知识和MTD 生成的虚拟样本进行优化选择.
粗糙集理论是由Pawlak 提出的处理具有模糊、不一致和不确定等特性数据的数学理论[105],其核心思想是从近似空间导出上近似算子和下近似算子(又称上、下近似集),将知识空间划分为上近似域、下近似域和边界域,其中: 上近似域是由知识空间内与某一概念有非空交集的知识粒的并集构成的集合,下近似域是由知识空间内包含某一概念的知识粒的并集构成的集合.目前,粗糙集理论已广泛应用于工业制造[106]、废水处理[107]以及优化控制[108]等领域,但将粗糙集理论直接应用于回归VSG 的研究还未见报道.
b) 分布假设
高斯分布是工业过程数据最为符合的假定分布.文献[109]通过划分区间提出改善核密度估计(Improved kernel density estimation,IKDE)并生成虚拟样本以解决制造系统早期阶段样本少的问题;随后,文献[110]将IKDE 扩展为通用模型,应用于具有时间依赖性的小样本建模问题并生成虚拟样本.Li 等[111]采用小型约翰变换方法(Small Johnson data transformation,SJDT) 使得小样本数据趋近正态分布,进而生成虚拟样本.但是,实际工业过程数据的期望分布不但未知且在小样本情况下也难以确定.
相较于高斯分布,威布尔(Weibull)分布在工业制造、可靠性分析等领域的应用更为广泛.Li 等[112]针对产品寿命性能评估样本数量少的问题,基于双参数Weibull 分布选择最大p值(Maximalpvalue,MPV)的反直觉假设检验方法近似估计非线性和非对称的小样本分布,并采用从分布中随机采样的策略生成虚拟样本,但其实用性有待验证;接着,Li 等[113]为解决TFT-LCD 制作领域中的多模态小样本问题,先用赤池信息准则(Akaike information criterion,AIC)的改进版AICc (Corrected version of the AIC)对聚类结果进行评价,再通过MPV 计算多峰分布的参数以确定虚拟样本数量,最后生成虚拟样本,但其适用性有待评估.
c) 基于知识
面向回归问题,针对如图10 所示的可扩展域和未知域,可能存在不合理的虚拟样本和无法生成的虚拟样本;此时,需要借助工业过程自身机理知识和其他相似过程的经验知识予以辅助.
目前,已有的基于领域知识的研究仅见于文献[15],其依据MSWI 过程DXN 值的下限范围进行可扩展域真值的修订.如何借助工业过程的机理知识辅助回归问题VSG 的研究还未见报道.
2) 面向分类问题的VSG
a) 集合理论
文献[114]采用基于模糊的信息分解(Fuzzybased information decomposition,FID) 为少数类生成虚拟样本以平衡训练数据并对缺失值进行填充.Ramentol 等[115]基于SMOTE 和粗糙集理论生成虚拟样本以处理不平衡数据集;在此基础上,胡峰等[116]提出基于三支决策的不平衡数据过采样策略,首先依据样本总体分布定义正域、边界域和负域后,再在边界域和负域生成虚拟样本,结果表明可有效地解决不平衡数据的二分类问题,但如何解决多分类问题仍有待研究.由上可知,基于集合理论面向分类问题VSG 的研究还有待深入.
b) 分布假设
Yang 等[43]在假设过程数据符合高斯分布的基础上,在计算其均值和标准差后采样生成虚拟样本,实验表明采用适当数量的虚拟样本能够提高分类器泛化性能,但如何确定数量未予以考虑;进一步,Shen等[117]在采用最大期望算法计算高斯模型的参数和采用AIC 与贝叶斯信息准则(Bayesian information criterion,BIC)自适应确定模型高斯分量的最佳数量后,通过采样获得虚拟样本.文献[118]采用SVM 的状态函数近似样本分布并通过采样输出虚拟样本.文献[119] 采用K均值聚类法检测多模态Weibull 分布,利用真实和虚拟样本间Weibull 偏度的误差变化作为虚拟样本数量的评估标准.
c) 基于知识
面向分类问题,在实际过程中存在无目标类别的样本用于模型训练的情况,即零样本问题,例如:故障诊断领域存在特殊故障的样本无法获得的问题.笔者认为,类似于回归问题,向生成过程添加机理或经验知识是解决VSG 中未知领域零样本问题的有效手段.
实际工业过程中,领域专家借助于对复杂机理的认知,再辅以长期的工作实践和经验积累,对已经出现的或可能出现的各种异常故障形成了相应的知识体系[120-121].研究表明,将专家知识转换为属性、文本/语义、知识图谱、规则以及本体等融入到模型训练中,可有效提高模型的泛化性和可解释性[122].对此,Link 等[121]采用基于专家知识定义的由故障位置、影响和原因等属性组成的故障描述确定故障类型,相关的属性知识可从其他易获取的故障中预先学习和迁移,故无需额外的训练数据.但这种方法并无虚拟样本产生.Zhuo 等[123]提出基于故障属性GAN (Fault attributes GAN,FAGAN)的任意样本学习策略,本质上是将专家知识定义的故障属性作为辅助信息使得生成样本更接近真实样本,实现对未知故障的诊断.
相较于领域专家直接提供的专家知识,模型知识是通过对模型的学习和推导所提取出的隐含知识[124].Yao 等[125]提出结合联邦学习和迁移学习的缺失数据填充策略,目的是使不同边缘设备上的模型能够互相传递和利用所学习到的知识,从而提高数据填充的准确性.Feng 等[126]提出基于多头语义表示和层次对齐技术的语义细化WGAN (Semantic refinement WGAN,SRWGAN),其通过细化粗粒度语义描述消除类别之间的偏差,进而提高特征生成和知识转移的效果.目前暂无基于模型知识驱动的工业过程VSG 成果报道.
如何获得相关领域的专家知识和如何利用数值仿真模型提取符合工业过程的知识,是未来支撑知识驱动VSG 和解决未知域故障诊断的重要研究方向.
综上可知,基于模糊集理论VSG 的成果较为丰富,特点是: 面向回归问题的研究多于分类问题,面向虚拟样本输入空间的研究多于输出空间.此外,目前的信息扩散技术缺少工业过程机理知识的支撑.相较于模糊集理论,粗糙集理论在VSG 领域的研究较少,所提知识空间的3 个域并未给出相应的域扩展计算方法,这将是未来基于粗糙集理论VSG的研究方向之一.此外,如何基于知识确定符合复杂工业过程的分布类型及相关参数是基于分布假设VSG 的未来重要研究方向.基于知识的VSG 还处于辅助阶段,相对而言在分类问题上更易研究.
2.2 基于VSG 实现流程分类的研究现状
2.2.1 面向回归问题的VSG 实现流程
1) 过程数据预处理阶段
对过程数据进行预处理的目的是使得原始域样本空间的稀疏区域易于发现以降低VSG 的难度.首先进行对数据缺失值的处理,如: 文献[15]和[61]对MSWI 过程DXN 数据中的缺失值进行删减和人工填充,文献[64]和[127]对化工过程数据的异常和缺失值进行识别和去除,文献[125]利用联邦学习和迁移学习进行缺失值填充.然后,采用特征工程进行数据处理,如: 文献[52]和[53]采用LLE和Isomap 从高维数据中提取2 维特征,文献[54]采用t-SNE 提取3 维特征,文献[59]和[128]基于化工机理选择与运行指标相关的特征,文献[61]基于专家经验选择与DXN 排放浓度相关的特征.最后,进行标准化或归一化处理,目的是消除不同特征上差异化数量级所造成的影响.
2) 虚拟样本输入生成阶段
针对原始域样本空间而言,通常是先采用某种方法识别原始域样本空间的稀疏区域后再采用各种策略生成虚拟样本输入,如: 文献[127]采用欧氏距离识别稀疏区域后采用插值策略,文献[57]通过对投影点的最大间距进行稀疏检测后采用中点插值;文献[52-54]提取过程数据特征后通过可视化样本分布确定稀疏区域.针对不同区域,文献[49]提出稀疏假设和集中假设,指出相较于在密集区域生成虚拟样本而言,在稀疏区域生成虚拟样本更有必要,但这需要权衡两个区域所生成的虚拟样本数量.此外,文献[64]和[65]通过WGAN-GP 和CWGAN学习原始样本分布后生成虚拟样本输入.
针对扩展域样本空间而言,采用信息扩散和分布假设等方法先确定可扩展区域后再生成虚拟样本输入,如: 文献[96]采用基于三角隶属度函数的MTD获得扩展范围后采用基于插值的生成策略;文献[104]采用基于非对称三角隶属度函数的信息扩散技术获得扩展域范围,通过PSO 在该范围内生成虚拟样本输入;文献[129]采用流形子空间对原始域真实样本进行分组并基于MTD 确定扩展范围,根据两者构建超球体方程后在球面和球内通过采样生成虚拟样本输入.
3) 虚拟样本输出生成阶段
通常采用原始域的真实小样本训练的映射模型为虚拟样本输入匹配输出,常用的映射模型包括RWNN[59,104,129]、BPNN[52]、RF[54]和RBF[57]等.面向GAN 策略,文献[64]基于CS-CGAN 和一致性检验为WGAN-GP 所生成的虚拟样本输入匹配输出;文献[65] 将基于深度神经网络的回归器与生成器以及判别器共同训练以生成虚拟样本输出;文献[55] 采用分位数回归网络,在一定置信度下为CGAN 生成合适的虚拟样本输出,进而减少生成器和判别器的训练难度.
4) 虚拟样本质量筛选阶段
常见的虚拟样本质量筛选方法如下:
a) 相似性度量: Kullback-Leibler (KL)散度[55]和Wasserstein 距离[64]等方法因不能同时考虑输入和输出之间的关系而只能用于虚拟样本输入的度量,不能直接用作回归问题中输入/输出虚拟样本对的筛选标准;
b) 优化算法: 文献[61]采用PSO 算法对虚拟样本进行优化选择以提高样本质量;
c) 模型误差: 文献[46]指出合格虚拟样本构建模型的相对误差应小于10%.其他的相关研究包括:文献[130]基于隶属度函数值的似然评估机制进行筛选,文献[49]基于领域专家判断虚拟样本的合理性等.综上,笔者认为,针对输入/输出虚拟样本对的筛选准则的研究还有待深入,并且需要结合质量判别准则进行优化选择.
5) 虚拟样本数量确定阶段
常用确定虚拟样本数量的方式是凭借经验或者依据逐批添加虚拟样本至真实小样本后所构建不同模型的泛化误差.
在此基础上,文献[131]根据真实小样本的方差上限,提出先采用信息熵理论确定虚拟样本数量再建立最优虚拟样本生成数量的概率模型的2 步策略.具体的,确定虚拟样本数量的公式如下:
式中,σ0为真实样本的标准方差;n1为原始样本的数量.面向噪声0.95 置信水平的最优虚拟样本概率模型的公式如下:
式中,µ0为真实小样本的均值,C0为虚拟样本产生的总噪声.文献[49]根据其所提的稀疏假设和集中假设,给出如下的虚拟样本数量确定公式:
式中,n为训练样本数量;nv为添加虚拟样本数量.
6) 特殊阶段
目前,已有研究学者提出,先生成虚拟样本输出再匹配生成虚拟样本输入的“反向” VSG 策略,如: 文献[20]利用LOF 获得原始样本输出的稀疏区域并通过K-means++获得中心点,利用中点插值生成虚拟样本输出后将其作为CGAN 的条件信息以生成虚拟样本输入;文献[49] 在获得原始样本输出的密集和稀疏区域并利用三样条插值生成虚拟样本输出后,基于ITNN 生成虚拟样本输入.
综上可知,采用不同策略的VSG 具有差异化的特性.如何面向特定应用领域进行选择和改进是应用时需关注的问题.
2.2.2 面向分类问题的VSG 实现流程
针对不存在未知类的分类问题而言,VSG 将类别信息直接作为先验用于虚拟样本输入的生成.因此,本节将从过程数据预处理、虚拟样本输入生成、虚拟样本质量筛选和虚拟样本数量确定等阶段进行综述.
1) 过程数据预处理
由于采用VSG 技术的故障数据多为机械信号,常用方法是采用FFT 将时域数据转换为频域数据.也有学者将一维时域信号转换为二维图像后进行处理,如: 文献[85]和[132]将振动信号切为若干片段,依次归一化并取整后转换为灰度图进行VSG.研究学者提出根据计算机视觉领域的数据增强策略对机械信号进行处理以缓解生成模型过拟合现象的策略,如: 文献[133]采用重叠分割、旋转和抖动的数据增强策略对故障样本进行处理,文献[92]对故障样本进行平移和缩放处理等.
2) 虚拟样本输入生成
SMOTE 作为针对少数类样本进行随机线性插值的VSG 技术,已广泛应用于解决类不平衡问题,如: 文献[115]结合粗糙集理论生成少数类虚拟样本,文献[73]对电力变压器非正常状态的样本进行补充,文献[74]在支持向量近似的分类边界生成非正常状态的虚拟样本,文献[72]采用Minkowski 距离代替传统SMOTE 中的欧氏距离,文献[75]通过控制生成范围减少重叠样本等.
随着深度学习的发展和GAN 的提出,对抗模型已成为面向分类问题VSG 的研究热点.为保证训练过程的稳定性和虚拟样本的质量,目前研究主要集中在改进损失函数和模型结构.改进损失函数的研究成果包括: 采用Wasserstein 距离替换传统交叉熵损失函数的WGAN[84],在WGAN 损失函数的基础上增加梯度惩罚项的WGAN-GP[85],采用Pull-away 损失函数的改进GAN[69]等.改进模型结构的成果包括: 文献[79] 在ACGAN 中添加Dropout 层以缓解虚拟样本生成过程中的模式崩溃问题,文献[68]采用CVAE 取代ACGAN 的生成器,文献[90]采用VAE 作为GAN 的生成器并将遗憾算法用于判别器,文献[83]采用包含具有真假判断、故障诊断和故障分类3 种功能的判别器,文献[92]采用CVAE 作为WGAN 的生成器并通过自调制算法进行更新以提高模型稳定性,文献[19]采用并行GAN 生成虚拟样本等.上述这些研究,在如何扩展虚拟样本输入的边界方面的研究较少,原因在于分类问题在输出空间上相对于回归问题的特殊性.
此外,受限于原始域样本空间所蕴含的机理知识匮乏的问题,部分学者采用迁移学习从相似领域中提取知识用以辅助生成虚拟样本.基于样本进行迁移的研究包括: Zhang 等[134]提出结合SMOTE和迁移学习的VSG 以处理不平衡数据,采用源域样本和目标域原始样本加权的方式生成虚拟样本,结果表明能够有效提高分类器的准确性;Liu 等[135]采用自适应混合方法生成虚拟样本,包括基于迁移学习策略保证生成样本的数量与多样性和通过进化算法提高故障诊断精度;贾欣等[136]提出将多数类样本迁移为少数类边界样本的均衡方案,这有利于学习类别决策边界.从模型角度进行迁移以生成虚拟样本的研究包括: 廖一帆等[137]通过Fine-tuning 方法将由临界和非临界样本所训练的预测模型嵌入WGAN 中以辅助生成非临界样本;兰健等[138]通过GAN 学习电力系统各种运行方式的共性特征,之后基于微调得到高性能的典型运行方式生成模型,为运行方式的分析提供支撑.由上可知,目前迁移学习已经成为VSG 的研究热点之一,但迁移后的可靠性方面还有待验证.
3) 虚拟样本质量筛选
目前通常采用组合多种评价指标的方式对虚拟样本质量进行评估,如表1 所示.
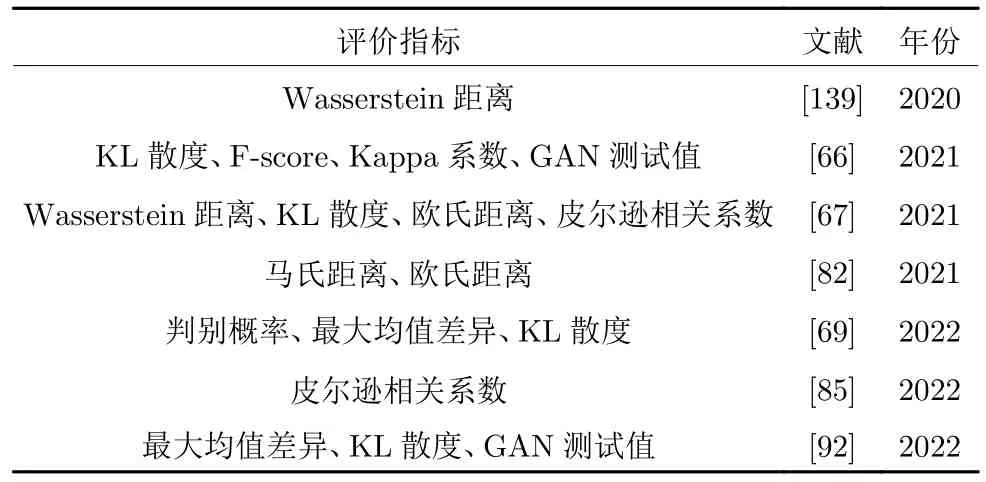
表1 面向分类问题的虚拟样本评价指标Table 1 Virtual sample evaluation index for classification problem
由表1 可知,用于分类问题VSG 的评价指标包括: Wasserstein 距离、欧氏距离、马氏距离、KL散度、F-score、Kappa 系数、皮尔逊相关系数、判别概率、最大均值差异和GAN 测试值等,这表明目前还不存在统一标准,相关的理论支撑也未见报道.相对而言,文献[82]和[69]给出了评价指标的具体阈值并据此进行样本筛选.
4) 虚拟样本数量确定
面向分类问题(以存在A 和B 两类为例,其中A 类数量远大于B 类数量),VSG 的目的是: 通过生成B 类虚拟样本降低数据集的不平衡比IR 直至其值为1,即实现从上述视角,虚拟样本的理想数量即为A (多数)类和B (少数)类样本的数量之差,可表示为:
其中,Nvir为虚拟样本的数量,分别为A (多数)类和B (少数)类样本的数量.
文献[140]指出,生成虚拟样本并不需要完全地消除少数类与多数类之间的数量差距,可通过类别之间的分类复杂度Hclass确定最终所需虚拟样本数量,如下:
综上所述,面向工业过程的VSG 需要根据具体任务和实际数据的特性设计相应的VSG 流程和采用适合的策略.
2.3 基于VSG 推广应用分类的研究现状
本文依据当前工业过程中VSG 的研究现状,从回归和分类两类问题对VSG 的推广应用情况进行综述.
2.3.1 面向回归问题的VSG 应用
目前VSG 主要应用于石油化工、固废焚烧、工业制造和矿业冶金等领域,其统计结果如图13 所示.
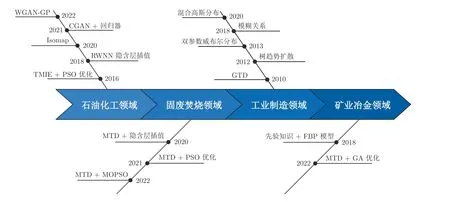
图13 面向回归建模问题的VSG 应用统计结果Fig.13 VSG application statistical results for regression modeling problem
如图13 所示,VSG 在工业制造和石油化工领域应用和发展时间较长,而在固废焚烧和矿业冶金领域的应用才刚刚起步.
面向化工过程,文献[104]提出基于信息扩散和PSO 优化的VSG,通过RWNN 为虚拟样本输入匹配输出,提高了精对苯二甲酸(Pure terephthalic acid,PTA)生产过程的醋酸消耗预测模型的性能;文献[59]通过在RWNN 隐含层间插值生成虚拟样本输出和虚拟样本输入,构建乙烯生产系统模型以为石化行业的能源管理提供指导作用;文献[53]针对PTA 生产过程的数据分布不完备问题,采用Isomap 流形学习进行降维并搜寻稀疏区域插值生成虚拟样本,结果表明该方法可有效提高软测量模型的性能;文献[55]将分位数回归神经网络嵌入至CGAN 内为虚拟样本匹配准确输出,采用实际过程数据验证了所提方法的有效性;文献[65]将回归器嵌入至CWGAN 中,针对PTA 生产过程的应用表明,所生成的虚拟样本质量优于常规方法.
针对MSWI 过程DXN 建模数据获取困难的问题,文献[56]提出基于改进大趋势扩散和隐含层插值的混合VSG,即生成的虚拟样本包含基于子区域欧氏距离改进的MTD 等间隔生成和基于正则化改进的RWNN 隐含层插值生成两类,通过混合样本构建DXN 排放软测量模型,但样本间的冗余性未予于考虑;接着,文献[61]基于领域专家知识和MTD技术对真实样本进行扩展,在生成虚拟样本输入和根据映射模型获得虚拟样本输出后,采用PSO 算法对虚拟样本进行优化选择,但该方法未能同时考虑虚拟样本数量和映射模型超参数对模型泛化性能的影响;对此,文献[15] 提出基于多目标PSO (Multi-objective PSO,MOPSO)混合优化的VSG,通过对虚拟样本数量和模型性能指标2 个目标进行混合优化的策略确保了VSG 的合理性和有效性.
在工业制造领域中,文献[97]针对柔性制造调度系统建模过程中存在的样本信息匮乏且与时间相关的问题,提出基于GTD 技术的VSG,结果表明混合样本有助于提高模型性能;在此基础上,文献[98]将趋势扩散和树算法结合,提出基于树结构的趋势扩散方法,用于扩充制造过程初期的样本数量;针对产品寿命性能评估问题,文献[112]在符合制造业的Weibull 分布中,以采样方式获得虚拟样本;文献[141]采用模糊c均值聚类算法将数据分为多个簇后赋予不同权重,通过箱型图估计特征的扩展范围后生成虚拟样本,构建的模型相较于对比方法具有更佳的性能;文献[117] 采用高斯混合模型拟合数据分布后采用网格搜索技术对模型进行优化,所提方法能够缓解橡胶加工耐磨性数据的缺乏和提高预测模型的精度.
针对磨矿过程采用非完备样本构建数据驱动模型困难的问题,文献[6]提出结合先验知识和FBP的VSG,对构建物理阐释明确的软测量模型具有重要的借鉴意义.针对稀土萃取过程中存在的小样本问题,文献[142]将基于MD-MTD 和RWNN 生成的虚拟样本与GA 优化MD-MTD 生成的虚拟样本混合后构建预测模型,结果表明可提高模型的稳定性和泛化性能.
针对其他领域回归问题的VSG 还包括: 锂电池剩余寿命预测[143]、蒸馏塔煤油凝固点预测[144]和血液光谱分析[103]等.
2.3.2 面向分类问题的VSG 应用
已有研究成果主要集中在故障诊断领域,即用于轴承、齿轮以及电机等机械设备诊断模型的故障样本生成.与传统过程数据不同,这类故障样本多为用于二分类问题的机械振动信号,特点是故障样本的数量明显少于健康样本,即存在类不平衡问题[145].基于这一特点,图14 给出了2019~ 2022 年间VSG技术在故障诊断领域的应用.
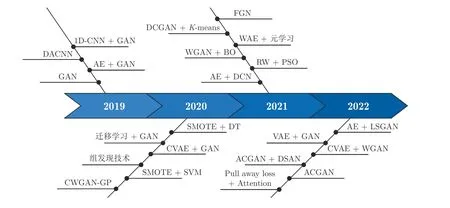
图14 2019~ 2022 年面向故障诊断领域的VSG 应用统计结果Fig.14 VSG application statistical results for fault diagnosis on 2019~ 2022
由图14 可知,近4 年故障诊断领域的VSG 研究成果主要集中于编码器、GAN 等深度学习方法,其本质是通过改进生成模型的结构、数量和损失函数等方式保证虚拟样本的质量.
在滚动轴承故障诊断领域中,文献[146]提出结合迁移学习和GAN 的VSG,其基于设备故障机理对特征进行迁移并通过GAN 学习设备监测数据的分布特征进而生成虚拟样本,具有较好的变工况迁移能力;文献[147]提出融合用于生成虚拟故障样本的去噪自编码器(Predictive generative denoising AE,PGDAE)和进行故障诊断的深度珊瑚网络(Deep coral network,DCN)的统一框架,结果表明可有效生成虚拟故障样本并准确识别滚动轴承故障;为提高生成模型性能,文献[66]采用元学习增强Wassersterin AE (WAE)策略提升先验分布与滚动轴承振动信号间的映射能力,结果表明生成的虚拟样本质量优于对比方法;文献[92]将自调制、CVAE 和WGAN 相结合以增强博弈对抗过程的稳定性,进而生成高质量的虚拟故障样本;文献[132]将一维信号数据转换成二维灰度图像后基于ACGAN生成虚拟故障样本,通过自注意力机制深度子域适应网络(Deep subdomain adaptation network,DSAN)提高故障特征的非线性拟合能力;文献[148]利用常数Q 转换将机械信号转为频谱图像后输入GAN,并采用均方误差替换交叉熵作为损失函数;文献[149]通过度量判别器与生成器间的相对性能后自适应调节生成器的损失值,结果表明对抗学习过程的收敛更快,所生成样本的质量更好;文献[69]提出深度特征增强生成对抗网络以提高不平衡故障诊断的性能,建立自动数据过滤器以保证生成样本的准确性和多样性;文献[150]提出深度特征生成网络(Deep feature generating network,DFGN)用于面向零样本的滚动轴承故障检测,实验结果表明能够有效地检测典型故障.
面向变压器的故障样本与健康样本不平衡的问题,文献[73]采用SMOTE 生成异常状态样本后,通过DT 提取变压器状态评估知识后将其转换为状态量和评估规则;文献[74]在支持向量近似的分类边界,根据最近邻决策机制采用插值方式生成虚拟样本,进而提高诊断模型的准确性;文献[151]采用基于梯度惩罚优化的CWGAN (CWGAN-GP)生成多类别故障样本,构建基于栈式自编码器的诊断模型,结果表明可有效改善模型分类偏好和提升分类性能;文献[91]设计包含孪生编码器、解码器和传输层的改进AE 以消除数据噪声,通过LSGAN生成高置信度的健康状态样本,结果表明能够及时检测发电机的潜在异常情况.
针对风力涡轮机故障样本稀少引起的信息缺失问题,文献[152]按照皮尔逊相关系数和最大信息系数,将生成的虚拟样本特征分组输入判别器后分别计算损失,以加权值作为总损失用于更新GAN,实验表明所生成的虚拟样本更为真实;文献[153]提出将对抗学习作为正则项引入CNN 的深度对抗CNN (Deep adversarial CNN,DACNN),结果表明提高了诊断模型的准确度;文献[89]针对机械系统的异常样本采集难的问题,提出结合GAN 和AE的机械系统异常检测方法,通过编码-解码-再编码的网络结构学习异常变化并生成虚拟样本,结果表明能够更稳定地表征故障演化过程;文献[154]提出将样本生成和故障诊断相结合的ASM1D-GAN(Assembled 1D CNN and GAN),通过对抗学习机制同时优化上述两个过程以达到同时提高生成样本质量和故障诊断精度的目的.
针对齿轮箱的故障诊断问题,文献[68]提出基于条件变分自编码器生成对抗网络的不平衡故障诊断方法,通过CVAE 提取故障样本分布以对抗方式生成虚拟样本,结果表明可生成不同工况下的故障样本,能够提高模型性能;针对GAN 调参复杂且具有随机性的问题,文献[86]通过贝叶斯优化(Bayesian optimization,BO)策略自适应地调节WGAN的判别器参数以提升虚拟样本质量,结果表明可有效提高故障识别精度;文献[67]采用深度卷积GAN(Deep convolution GAN,DCGAN)生成虚拟样本以解决数据集不平衡问题,通过K-means 聚类算法改进基于CNN 的机械设备故障诊断模型.
此外,VSG 在故障诊断中的应用还包括: 小电流接地系统故障线路检测[77]以及热电联产电厂给水泵[155]、磨矿机[156]和化工过程[157]等领域的故障诊断.
综合上述研究可知,VSG 正快速在缺失完备建模样本的复杂工业过程中获得应用,其在面向分类问题的研究深度和先进性等方面明显优于面向回归问题.本文虽然仅对常见的工业过程的VSG 典型应用进行了介绍,但这些结果在一定程度上表明,VSG 具有独特的优势和适应不同工业过程数据的良好性能.
3 数据集与开源软件
本节将对上述面向工业过程的VSG 研究所涉及的数据集和开源软件进行总结,包括用于虚拟样本实验评估的基准数据集和在VSG 算法实现过程中所用到的开源软件,进而为VSG 的研究提供基础支撑.
3.1 基准数据集
本节将从面向回归和分类问题两个方面对目前VSG 研究中采用的合成和公开基准数据集进行汇总,如表2 和表3 所示.

表2 面向回归问题VSG 的合成数据集Table 2 Synthetic datasets of VSG for regression problem

表3 面向分类问题的VSG 公开数据集Table 3 Public datasets of VSG for classification problem
由表2 和表3 可知,目前的VSG 研究大多是在传统的合成函数和公开的故障诊断数据集上开展的,基于实际工业过程的VSG 基准数据集还未见相关报道,尤其面向回归问题,甚至不存在由实际工业过程产生的数据集.因此,构建能够用于生成模型和虚拟样本质量评估的通用VSG 基准工业数据集也是未来的重要研究方向之一.构建面向实际工业过程的虚拟样本数据库更是值得深入研究的基础工作.
3.2 开源软件
合适的编程软件是实现VSG 的重要基础,目前主要分为Python 和Matlab 两类.
1) 基于Python 的开源软件
a) PyTorch,由Facebook AI Research 开发的深度学习库,支持基于CPU 和GPU 进行高效张量运算并提供可灵活修改模型结构的动态计算图,包含许多深度学习模型和算法,详见官网: https://pytorch.org/.
b) TensorFlow,由Google Brain 团队开发的机器学习平台,支持GPU 和TPU 等硬件加速计算并能够进行分布式的训练和推理,提供了丰富的工具和资源.除Python 外,TensorFlow 还支持Java、C++等编程语言,详见官网: https://www.tensorflow.org/.
c) Keras,由Python 编写的开源神经网络库,能够在TensorFlow、CNTK 以及Theano 上运行,支持快速实验和构建复杂模型,详见官网: https://keras.io/.
2) Matlab 的开源软件
a) Deep Learn Toolbox,其包含多种模型、算法和应用程序的深度学习框架,支持网络设计可视化和训练进度实时监控,详见官网: https://ww2.mathworks.cn/products/deep-learning.html.
b) Statistics and Machine Learning Toolbox,其提供多种用于数据描述、分析和建模的有监督、半监督和无监督机器学习算法,能够自动生成C/C++代码用于嵌入式部署,详见官网: https://ww2.mathworks.cn/products/statistics.html.
目前,VSG 研究正处于与统计学习、深度学习、迁移学习、联邦学习、集成学习等领域的新进展深度结合阶段,因此这些领域所采用的开源软件都可用于VSG 领域.进一步,后续研究可考虑构建由基础算法、基准数据集、标准评估算法以及可视化等组件组成的VSG Toolbox.
4 VSG 的比较与讨论
4.1 方法比较
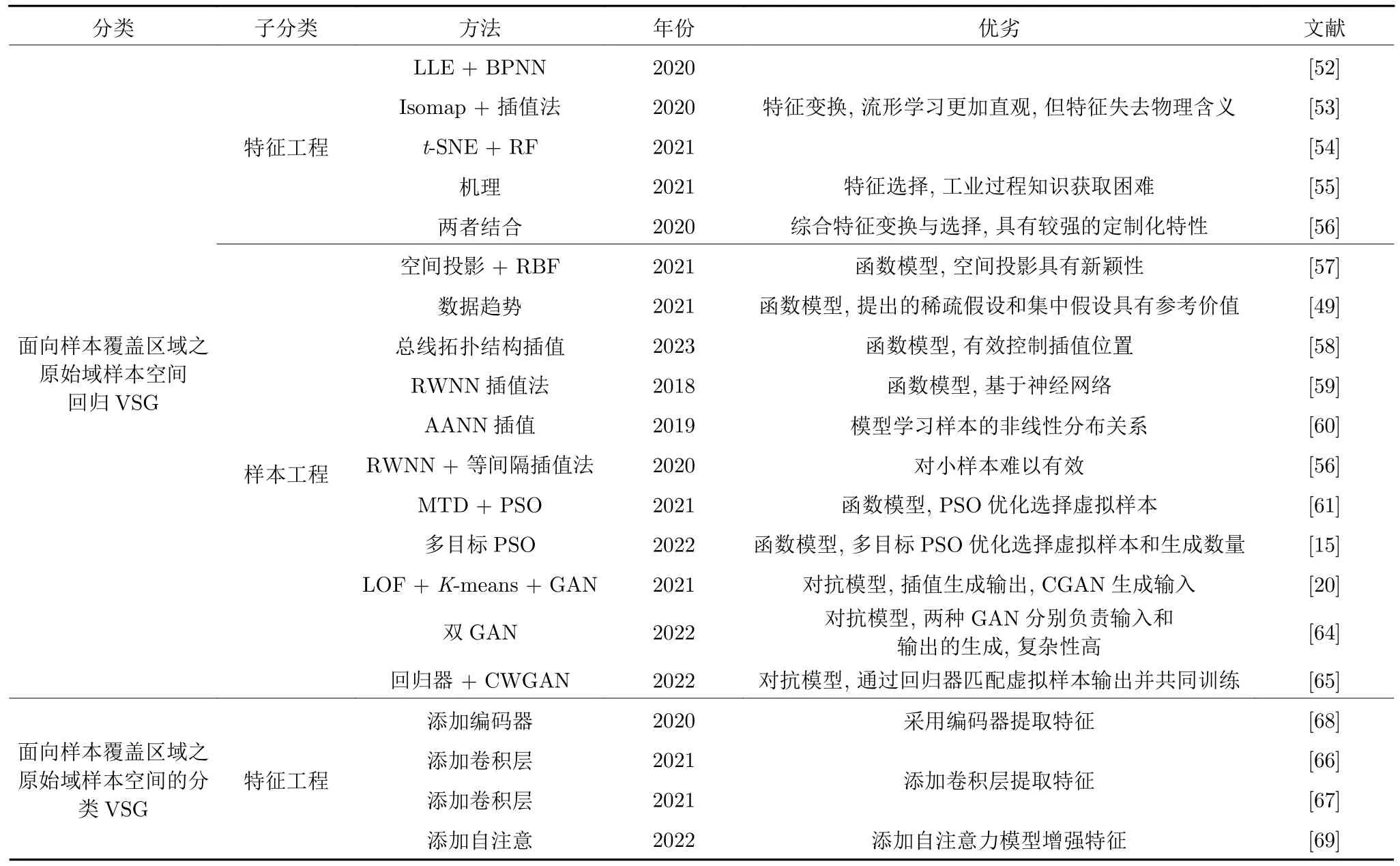
从样本覆盖区域、VSG 实现流程和推广应用3个方面,针对回归问题和分类问题VSG 的研究成果统计与对比如附录A 的表A1 所示.文中的符号说明如表A2 所示.
由表A1 可知: 从3 个不同视角综述的结果而言,面向回归和分类问题的VSG 在侧重点上是存在差异性的,具体表现为:
1) 样本覆盖区域视角.面向原始域样本空间的VSG 最早源于SMOTE 等插值算法,在GAN出现后其迎来了更高的研究热度,其中: 分类问题主要集中在故障诊断领域,采用卷积网络、编码器和注意力机制对故障数据进行特征提取和增强;回归问题采用流形学习、专家经验等处理高维过程数据;此外,由于在博弈对抗的过程中为虚拟样本输入匹配准确的输出存在困难,使得基于GAN 的回归问题VSG 研究较少.从通过VSG 完备样本分布的目的的视角,识别真实样本的稀疏区域是基于函数模型进行VSG 的关键,即首先通过稀疏区域确定需要生成虚拟样本的位置;但是,在基于对抗模型的VSG 过程中,可能会生成不属于完备域(期望域)样本空间的不合格虚拟样本,因此进行样本筛选很有必要.面向扩展域样本空间的VSG 最早源于信息扩散理论,在MTD 提出后获得广泛应用,其中: 基于模糊集理论的VSG 研究相较于粗糙集理论更加成熟;基于分布假设的VSG 针对不同工业过程需选择合适的分布以接近完备域的样本分布.从完备样本分布区域的目的而言,基于扩展域空间的VSG 既要考虑可扩展区域存在与否和存在时的区域范围,又要考虑扩展时虚拟样本的分布程度;同时,还需要结合知识对未知域进行认知.因此,已有研究通常为原始域和扩展域分别选择合适的VSG 策略.
2) VSG 实现流程视角.数据预处理阶段需要依据建模数据特性进行处理以便更好地开展后续工作,例如: 对异常和缺失值进行剔除和填充,对高维数据进行特征约简以及对机械信号进行FFT 处理等.针对分类问题,由于无需匹配输出,采用GAN在虚拟样本输入生成阶段的研究明显多于回归问题,这也导致基于扩展域样本空间的VSG 研究较少.在虚拟样本输出生成阶段,采用RF、RWNN和RBF 等映射模型均能够适应小样本建模,但如何基于有限的样本构建准确且鲁棒的映射模型仍是待解决的热点研究问题.在虚拟样本质量筛选阶段,通常采用的是相似性度量、优化算法和模型误差等方法,但如何确定统一的、有理论支撑的期望评价准则仍是一个未解决的开放性问题.在虚拟样本数量确定阶段,目前多依据实际问题特性采用试凑方式确定添加数量,虽有学者从数学理论和数据特性等角度探索确定方法,但仍待继续完善.
3) VSG 推广应用视角.面向回归问题的VSG主要应用在石油化工、固废焚烧、工业制造和矿业冶金等领域,其中: 石油化工领域多采用基于原始域样本空间的VSG;工业制造领域的VSG 研究多集中于扩展域样本空间;固废焚烧和矿业冶金的VSG 研究相对较少,处于起步阶段.面向分类问题的VSG 应用在轴承、齿轮、涡轮机以及变压器等机械或电力设备的故障诊断中,其中以面向机械信号采用GAN 的应用最为广泛.
综上可知,在上述3 个视角下,针对回归问题和分类问题的VSG 各具优势,有必要相互进行借鉴;同时,也有待于与迁移学习、集成学习、联邦学习等算法结合并与具体应用领域进行深度融合.
4.2 讨论与分析
结合以上分析,笔者总结了面向工业过程VSG的未来研究方向,如下所示.
1) 样本质量与生成模型协同优化
由式(1)可知,采用增加样本数量或减少特征维数均是获得较大α值的可行方案.在VSG 前基于特征工程降维以减少模型的训练难度是必要的,其中: 基于特征变换VSG 的难点在于如何重构虚拟样本,基于特征选择VSG 的难点在于如何平衡选择的特征数量和生成的虚拟样本质量等问题.虚拟样本输出的质量在很大程度上取决于生成模型的选择,但目前尚无统一的评估方式以分析模型结构或参数对虚拟样本的影响.针对某个工业过程的某个实际问题所设计的VSG 效果好但具有局限性,如何借鉴并提高普适性有待研究.因此,设计虚拟样本质量评价指标并与生成模型的结构和参数协同优化是未来的重要研究方向,同时也需要考虑如何提高优化效率、降低运行消耗等问题.
2) 基于对抗学习融合机理知识、经验规则和数据驱动模型的智能VSG
现有VSG 主要利用原始真实样本构建基于数据驱动的生成模型,存在蕴含机理知识缺乏和完备样本分布未知等问题.针对具体复杂工业过程而言,可利用数值仿真软件构建能够反映运行状态的近似机理可视化模型和利用专家经验知识构建反映运行规则的经验模型.因此,通过对抗学习等技术自行选择由机理知识、经验规则和数据驱动等构成的多类型生成模型并通过进化最优VSG 流程,将能够为生成模型的选择和构建提供指导作用和提升VSG的可解释性.
3) 基于合成数据集的VSG 理论分析
虽然VSG 已在复杂工业过程的各个领域得到迅速发展,但与其相关的理论分析却较为匮乏,例如: 扩展域样本空间的隶属度函数和分布函数的选择依赖于主观经验;用于信息扩散的三角隶属度函数和用于分布假设的正态分布函数并不适用于所有工业过程.在优化算法领域中,常采用多种基准函数进行算法设计、性能测试和方法比较,依据这些人为设定的基准函数能够较为客观地评价不同优化算法的各种性能.对此,也有学者设计测试函数并采样得到合成数据对VSG 性能进行评价[57,129].但是,在如何确定完备分布,如何确定不同分布下虚拟样本的数量和质量等方面的理论还缺失.因此,笔者认为,采用具有较好规范性和多样性的合成数据进行VSG 的理论分析是未来该领域偏向于学术方面的研究方向之一.
4) 借鉴相关领域知识的迁移VSG
不管是基于原始域样本空间还是基于扩展域样本空间的VSG,本质都是基于原始真实样本并从中挖掘样本间的联系或获取扩展范围,但受限于样本数量该过程存在多种困难.以GAN 为例,其作为一种本身需要数据支撑的神经网络,只有在存在充足数据时才能支持网络训练的收敛,在数据量较少的情况下难以达到纳什均衡且易陷入模式崩塌,此时的样本生成过程近似于对原始样本的简单复制,显然这对提高样本的多样性和进行区域空间扩充并无实质性的帮助[158].因此,除机理知识外,从外部的样本空间获取知识以提高生成模型的性能是VSG的重要研究方向.显然,这种外部的样本空间应与原始域空间具有相似性且数据量大,此处将其称为相似域空间.迁移学习旨在利用相关领域的知识提高学习性能或最小化目标领域所需的样本数[159].目前,基于相似域空间的VSG 尚处于起步阶段,还存在大量问题亟待解决,例如: 两个域之间存在相似性是知识迁移的必要前提,但相似性度量方法的优劣还未有统一标准;域间相似性对虚拟样本质量的影响程度也是值得研究的问题;如何从数据和模型两个层面同时进行迁移以达到更好的效果等.
5) 工业过程数字孪生系统驱动的VSG 完备样本分布研究
工业过程数据存在样本稀缺、分布完备性差和内涵机理知识匮乏等问题.如何获取具有完备样本分布的建模数据是未来VSG 实现落地应用的关键.近些年,数字孪生技术的出现以及其迅速的发展为解决上述问题提供了新的思路.文献[160]构建航天器电源系统的数字孪生模型,并对其注入虚拟故障以获得虚拟样本.文献[161] 通过采煤机摇臂机的数字孪生模型生成状态检测样本并构建预测模型,为复杂矿用设备的运维提供支持.虽然上述数字孪生系统多面向离散过程,但也能够为构建机理更加复杂的流程工业数字孪生系统提供借鉴.因此,基于物理几何模型和动力学模型以及多源数据构建复杂工业过程数字孪生模型,生成具有完备样本分布的虚拟样本库能够为VSG 提供机理知识,具体实现方式与可用性验证等问题还有待研究.
6) 基于监督和半监督学习的集成VSG
复杂工业过程的关键运行指标数量受限于检测技术的高成本和大时滞特性,导致存在大量未标记的过程数据和少量标记的建模数据共存的现象[162].半监督学习是综合有标记和无标记数据的建模方法,其能充分利用过程数据所表征的工业运行过程的特性[163].因此,借鉴半监督学习思想,在虚拟样本输入生成阶段可充分利用未标记过程数据所能表征的特征空间以提高生成样本的质量.结合上述样本的差异度与主动学习算法筛选合格输入数据,对其进行标记能够获得高置信度的伪标记样本和高质量的虚拟样本.笔者认为,从输入输出视角,真实样本可记为“真-真”样本,之前研究所生成的虚拟样本可记为“虚-虚”样本,此处采用半监督方式获得的样本可记为“真-虚”样本.因此,基于监督和半监督学习的集成VSG 能够基于“真-真”样本和未标记样本提高“虚-虚”样本可信度的同时通过“真-虚”样本进一步增加虚拟样本的数量.
7) 自适应更新的动态VSG
在实际的工业过程中,数据分布会随时间发生动态变化导致旧模型无法适用于新样本,该问题被称为概念漂移,产生原因通常是元器件老化或生产环境变化导致模型输入输出间的分布关系发生改变.如何进行概念漂移的检测、量化和处理也是学术界的开放性问题之一[164].基于历史真实数据的VSG 虽能够进行域扩展,但却难以表征工业过程未知漂移和难以确定未知域.因此,VSG 应能够根据工业动态环境的变化进行完备样本分布的实时更新,进而确保生成模型的性能和预测模型的精度,在该方向上的研究成果还未见报道.
5 结论
本文总结了针对复杂工业过程难测运行指标和异常故障进行建模的真实样本所存在的问题,梳理了虚拟样本的定义和内涵,给出了工业过程VSG的实现流程,综述了面向样本覆盖区域、实现流程与推广应用3 个方向的研究现状,讨论了未来研究方向.结合上述分析结果,笔者认为未来挑战包括:1) 构建合成数据集进行VSG 理论分析,进行样本质量与生成模型的协同优化;2) 利用对抗学习对机理知识、经验规则和数据驱动模型进行动态进化选择,构建具有最优生成流程的智能VSG;3) 同时从输入和输出角度评估本文所提出的相似域样本空间,采用基于样本和模型的迁移学习构建虚拟样本输入生成模型和输出映射模型;4) 面向工业过程的物理实体构建混合机理和数据驱动的数字孪生系统,依据实际工业数据的动态变化对数据孪生模型进行预测性调整以确保虚拟样本质量和预测模型性能;5) 利用未标记样本提升虚拟样本的可信度,结合监督和半监督学习算法的差异度和主动学习算法的灵活性,构建面向多视角学习机制的集成VSG和结合工业过程概念漂移的动态VSG.
附录A
表A1 VSG 的研究成果统计与对比Table A1 Statistics and comparison of VSG research results
