基于距离信息的追逃策略: 信念状态连续随机博弈
2024-04-30陈灵敏李永强
陈灵敏 冯 宇 李永强
近年来,追逃问题在飞行器、移动机器人等领域一直广受关注,如无人机围捕搜查[1]、机器人协同对抗[2]、搜索救援[3]等.在典型追逃问题中追捕方试图快速捕获或逼近逃逸方,而逃逸方则试图远离追捕方以避免被捕获.自二十世纪六十年代提出一对一追逃问题以来[4],学术界对其进行了充分探索[5-8],并逐步演变为当下的多对一[9-11]、多对多[12-14]对抗问题的研究.
追逃问题可视为智能体间的对抗与合作问题,因此博弈论[15-17]被广泛用于此类问题的求解[18-20].文献[21]在追逃双方具有无限视野下建立了线性二次型微分博弈模型,将多追捕者与多逃逸者问题转化为多组两人零和微分博弈.文献[22]基于非零和博弈框架,研究了针对三种不同类型追捕者的追逃问题,并分析了可捕获性、纳什均衡以及捕获时间.文献[23]在确保每个时刻都至少有一个追捕者具有全局视野的情况下,提出了基于微分模型的追捕策略.不同于无限视野的结果,文献[24]在有限视野下设计了追捕群体快速逼近逃逸者的分布式算法,并根据初始分布及速度比推导了捕获条件.文献[25]采用图论方式研究了有限感知的追捕问题,为每个智能体求解了分布式最优策略.
上述研究均基于模型求解追逃策略,然而现实中由于不确定因素的存在,构建准确的模型极为困难,而强化学习可通过无模型的方式寻求最优策略,因此其与追逃问题的结合也成为当下研究热点[6-7,26].针对某一方使用固定策略的追捕问题,文献[8]利用视野图像引入逃逸者位置的信念状态,并基于Soft actor-critic 算法获取最优追捕策略.文献[27]基于深度Q网络,并借助人工势场法对奖励函数进行改造以获取逃逸策略.而对于追逃双方通过对抗学习进行智能追捕的问题,文献[28]在无限视野下,提出了Q(λ) -learning 算法以求解追逃策略.文献[29]则在有限视野下基于深度确定性策略梯度,提出了两种网络拓扑结构来快速求解策略,降低了多智能体算法的复杂度.文献[30]对深度确定性策略梯度公式进行向量化拓展,提出了一种多智能体协同目标预测网络,保证了追捕群体对目标轨迹预测的有效性.
上述绝大多数追逃问题求解均基于定位信息,但在特定环境下此类信息无法获取.如水下航行器在固定海域中执行巡航与入侵驱逐任务时,由于无线电信号在海水中迅速衰减,此时航行器无法借助无线电导航系统对入侵者实现水下远距离、大范围的定位[31-32],在此情况下,借助轻便且低频的测距传感器实现追捕的研究是极为重要的.文献[33]研究了单个追捕者基于距离构造几何图形以估计逃逸者的追逃问题,并提出了在三维环境下使用两个追捕者估计逃逸者位置的方法.在固定信标的帮助下,文献[34]基于三角定位进行逃逸者位置估计,并提出了对测量距离进行去噪处理的方法以获得精准定位.文献[35]借助凸优化方法,提出一种基于测量距离的梯度算法实现对逃逸者的定位.文献[36]针对固定规则下的单移动机器人目标跟踪问题,提出了一种利用测量距离与距离变化率求解追捕策略的方法.此外,文献[37]基于距离变化率提出了自适应切换算法,证明了该算法稳定性与收敛性,并在距离变化率不可用时将其扩展为使用观测器补偿的算法,通过移动机器人围捕实验验证了其有效性.
综上所述,基于距离的追逃问题已有较多研究成果,但部分结果仍基于模型求解[32,35-37],或只针对固定策略的逃逸者[36],亦或是需要借助额外设备如信标等[34].因此在无模型情况下针对智能逃逸者,仅利用距离信息来实现追捕的问题仍有待于进一步探索.本文将基于距离信息的N对 1 围捕问题与随机博弈相结合,研究最优追逃策略.在此问题中,追捕群体仅领导者可测量与逃逸者间的相对距离,其他跟随者通过领导者的共享获取此信息,而逃逸者则拥有无限视野.为求解追捕策略,将环境分割引入信念区域状态以估计逃逸者位置.同时根据相对距离,对信念区域状态进行修正.领导者借助信念引入想象逃逸者,建立了信念区域状态下的连续随机追博弈,并使用不动点定理证明此博弈平稳纳什均衡策略的存在性.为求解逃逸策略,由于逃逸者具有全局信息优势,在追捕群体最优策略的基础上,建立基于混合状态的MDP 与相应最优的贝尔曼方程.最后给出了基于强化学习的追逃策略求解算法.
本文结构安排如下: 第1 节对追逃问题作出具体描述;第2 节证明基于信念区域状态的追博弈存在平稳纳什均衡策略,并构建逃逸者的混合状态MDP 与最优贝尔曼方程;第3 节给出求解追逃问题平稳策略的算法;第4 节通过数值仿真与对比,验证本文方法的有效性;第5 节是全文总结.
符号说明.Rm表示m维欧几里得空间;ei表示第i个元素为 1,其余为 0 的列向量;‖·‖ 表示欧几里得范数;∆ (A) 表示在集合A上概率测度的集合.
1 问题描述
本文研究N对1 追逃问题,将N个追捕者表示为Pi,i=1,···,N,其中P1是领导者,其余为跟随者,逃逸者表示为E.令第i个追捕者和逃逸者在k阶段的位置分别为Pi(k) 和E(k).具体描述如下:
1) 环境: 如图1 所示,二维地图环境由不规则边界和障碍物组成.追逃双方均可获知环境信息,且追捕群体和逃逸者都被禁止触碰边界与障碍物.

图1 追逃问题环境Fig.1 Environment of pursuit-evasion problem
2) 信息: 追捕群体仅领导者配备测距传感器,用于测量其与逃逸者间的相对距离d(P1,E)=‖P1-E‖,追捕群体间可共享此信息与各自的位置;而逃逸者具有全局视野,可获得追捕群体的定位信息.为方便起见,假设即使被障碍物遮挡,领导者仍可测量相对距离.
3)捕获条件:k阶段任意一个追捕者与逃逸者间的相对距离小于设定值ℓ,即d(Pi(k),E(k))=‖Pi(k)-E(k)‖<ℓ,则追捕群体捕获逃逸者.
4) 速度与方向约束: 使用vPi(k) 表示第i个追捕者在阶段k的速度,vPi(k)∈VP:={=1,···,M1}.类似地,逃逸者速度为vE(k)∈VE:={=1,···,M2}.追逃双方运动速度具有以下约束: a) 不同追捕者每阶段可选择不同速度;b) 追捕群体和逃逸者在每阶段中的速度是常数;c)此外,追捕者与逃逸者移动方向的选择被限定为D1和D2个,即
5) 目标: 追捕群体目标为尽快捕捉到逃逸者,而逃逸者目标为避免被追捕群体抓获.
注 1.论述4) 中的约束b) 限定了双方在每阶段中使用匀速运动进行追逃.当需考虑变速运动的情况时,可通过在动作集中引入额外的加速度来实现,这只会扩大双方的动作集,对本文结论并无本质影响.上述追逃问题被定义在二维环境中,但通过改变相应动作与状态,可直接将本文结果扩展到三维.
2 非完全信息追逃问题
本节针对此追逃问题,给出基于信念区域状态的连续随机博弈框架与马尔科夫决策过程.其中第2.1 节通过对环境进行区域分割以估计逃逸者的位置,并令跟随者采取包围行动;第2.2 节建立连续随机博弈框架求解追捕策略,并证明了此博弈平稳纳什均衡策略的存在性;第2.3 节建立基于混合状态的马尔科夫决策过程与相应最优贝尔曼方程求解逃逸策略.
2.1 信念区域状态和重心距离
由于追捕群体无法对逃逸者作出定位,因此对地图进行分割以估计逃逸者位置.如图2(a) 所示,在地图中沿横向和纵向作平行线,将其分割成L个区域.令逃逸者所处的区域作为状态,则状态集合S:={s1,···,sL,si=ei,i=1,···,L},其中si表示第i个区域.但仅通过测距仍无法获知其具体状态,因此引入信念区域状态.
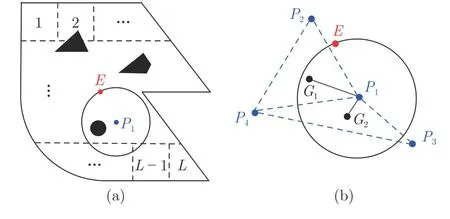
图2 (a) L 个区域;(b) 追捕群体的划分Fig.2 (a) L regions;(b) Division of pursuit group
定义 1.信念区域状态集合B=∆(S) 表示在区域状态集合B上的概率分布集合,则k时刻下信念区域状态Bk ∈B表示追捕群体对逃逸者所处区域的概率估计.
追捕群体使用信念区域状态估计逃逸者位置,然而跟随者未配备测距传感器,无法测量自身与逃逸者间的距离,因此它们在追捕过程中使用包围的方式来协助领导者达到捕获的目的.为实现包围,将追捕群体划分为多个三角形,每个跟随者Pi与其最近的两个跟随者及领导者构成两个三角形,即Pi和P1是两个三角形的公共点.如图2(b),跟随者P4与P2、P3以及领导者P1形成三角形△P4P1P2和△P4P1P3.整个追捕群体可构成f个三角形,其中f的取值如下
根据追捕群体位置可计算出所有三角形的重心Gi,i=1,···,f.需要注意的是,如果某一跟随者Pi与任意一个邻居以及领导者P1共线,则相应的三角形重心变为线段重心.
定义第i个重心与领导者间的距离为重心距离,即 ‖Gi(k)-P1(k)‖,i=1,···,f.显然每个跟随者均存在两个与自身相关的重心距离.可知当三角形重心越接近上述以领导者位置P1(k) 为圆心,相对距离d(P1(k),E(k)) 为半径的圆,跟随者包围效果越好.因此每阶段任意跟随者Pi都试图最小化相应的两个重心距离与d(P1(k),E(k)) 的差值.令此差值为ϕi,显然其与跟随者的移动方向和速度相关.
此外,为避免追逃双方触碰边界及障碍物,引入如图3 中所示的黄色警戒区域.地图边界的警戒区域是沿边界向内延伸相应智能体的一步最大距离,即;而障碍物的警戒区域则是向外延伸相应一步最大距离.由于追逃双方知道环境信息和自身位置,因此警戒区域的信息是公开的.第2.2 节将通过对警戒区域内智能体奖励的设置,来规避其碰撞边界及障碍物的风险.

图3 警戒区域Fig.3 Warning area

图4 第 m 个区域Fig.4 The m -th area
2.2 基于信念区域状态的追博弈
由于双方获知的位置信息不对称,因此追捕群体借助信念区域状态引入一个想象逃逸者,由此建立连续随机追博弈来求解追捕策略.
其次,k阶段基于信念区域状态Bk和想象逃逸者的概率动作,可计算出区域状态转移概率 Pr(sn|sm,).即在概率动作下,追捕群体认为想象逃逸者从状态sm(第m个区域)到sn(第n个区域)的概率为
信念区域状态更新机制.
基于区域状态转移概率 P r(sn|sm,) 与测量距离d(P1(k),E¯(k)),可进行信念区域状态的更新,其分为修正与估计两个过程.具体来说,追捕群体根据测量距离对信念区域状态进行后验修正,再使用P r(sn|sm,)估计下一阶段的信念区域状态.为给出信念区域状态修正机理,做出如下定义.
定义 2.假设逃逸者均匀分布在区域m中,k阶段的预测距离表示追捕群体和逃逸者分别做出纯动作后,逃逸者与领导者间的期望距离.
基于预测距离与相对距离两者间的差异来修正信念区域状态.如图5 所示,令领导者与想象逃逸者在k阶段做出动作前的位置分别为和(x,y),因此预测距离为
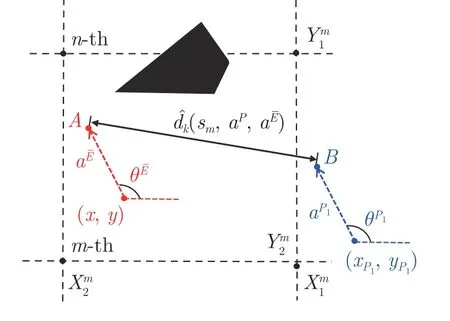
图5 预测距离Fig.5 Prediction distance
令k阶段的信念区域状态为Bk=b,则k阶段逃逸者位于m区域的先验概率为
令k阶段追捕群体的纯动作为aP,想象逃逸者的概率动作为,做出此动作后领导者与想象逃逸者之间的距离为dk=d(P1(k),(k)).基于此,可获取信念区域状态的后验概率,即
引理 1.k阶段信念区域状态的后验概率为
证明.根据信念区域状态后验概率的定义,可得
第三个等式由贝叶斯公式得出,其中Pr(sm,dk|b,aP,) 表示在信念区域状态b下,追捕群体与逃逸者分别做出动作aP,后,逃逸者位于m区域以及其与领导者间的距离为dk的概率;使用条件概率公式可得第四个等式;根据式 (4),可知逃逸者位于m区域的先验概率值仅与b有关,因此Pr(sm|b,aP,)=Pr(sm|b)=b(sm),所以第五个等式成立.
对于 P r(dk|sm,b,aP,),其值与预测距离和测量距离间的差异有关,即
基于区域状态转移概率可获取下一信念区域状态,因此k+1 阶段的信念区域状态Bk+1为
其中 P r(sn|sm,) 为式 (2).
连续随机追博弈框架.
信念区域状态的转移满足马尔科夫特性[38].将追捕群体视为一个整体,并且由于信念区域状态与追捕群体位置的连续性,因此可建立由六元组组成的基于信念区域状态的连续随机博弈G=(I,A,U,,T,R).不失一般性,假设所有追捕者和逃逸者是完全理性的,并且互相知道其他人是完全理性的[15].以下是追博弈六元组具体信息.
1) 参与人: 令I={} 表示理性玩家集合,其中P={Pi,i=1,···,N} 和分别表示追捕者群体和想象逃逸者.
2) 动作:A=AP×表示在追捕群体和逃逸者纯动作集上的联合概率分布集合,其中元素σ=(σP,)∈A被称为追捕群体和逃逸者的联合概率动作.
3) 联合状态: 联合状态集合U={Pos,B} 由追捕群体位置集合Pos和信念区域状态集合B组成,其中Pos=(XP,YP) 为追捕群体横坐标与纵坐标集合.
4) 联合状态修正概率: 根据修正机制可得联合状态修正概率,即()=Pr(==u,Ak=σ,d(P(k),(k))=dk),这表示k阶段基于测量距离dk,联合概率动作σ ∈A,状态u ∈U转移到修正状态u˜∈U的概率.
5) 联合状态转移概率: 根据k阶段联合概率动作σ ∈A,已修正的联合状态∈U转移到下一联合状态u′∈U的概率为T(u′|)=Pr(Uk+1=u′|==σ).
其中γ1∈{0, 1} 表示领导者是否触碰边界及障碍物,若领导者发生碰撞则受到惩罚φ.跟随者Pi单阶段收益为
其中γi ∈{0, 1} 表示跟随者是否触碰边界及障碍物,ϕi(aP)表示跟随者的包围目标.追捕群体的损失为想象逃逸者的收益,因此逃逸者单阶段收益为
根据追博弈框架中联合状态修正概率与转移概率定义,可得出如下引理.
引理2.k阶段联合概率动作为σ={σP,},联合状态u转移到下一状态u′概率为
证明.由更新机制可知状态u转移到u′分为两个部分: 修正与更新,并且联合状态u′={pos′,b′},={pos,},pos ∈Pos,pos′∈Pos,b ∈B,b′∈B.因此u转移到u′的概率为
其中联合状态的修正过程只涉及到信念区域状态b,因此如下等式成立
同时,修正过程仅与领导者纯动作有关,所以基于想象逃逸者概率动作与测量距离dk,将式(15)转化为
然后在状态更新过程中,追捕群体位置状态pos与信念区域状态b是互相独立的,因此
其中第二个等式中 Pr(pos′|pos,,σP,) 为追捕群体的位置状态转移概率,由于位置状态只与追捕群体自身动作有关,因此Pr(pos′|pos,,σP,)=σP(aP);而 Pr(b′|pos,,σP,) 则表示修正的信念区域状态到下一阶段状态的转移概率,由于追捕群体无法获知想象逃逸者的纯动作,因此使用全概率公式,由此第三个等式成立.
令连续随机博弈G中平稳策略为π={πP,},其表示联合状态到联合动作的映射,即π:U →A.则在联合状态u下,π(u) 实际上是在追捕群体和想象逃逸者联合纯动作空间AP×上的概率分布.设初始联合状态为u0,在平稳策略π下追捕群体目标函数表达式如下
其中 0<ρ<1 为折扣因子.根据想象逃逸者奖励函数定义,它的收益是追捕群体的损失,因此
定义 3.若存在一个平稳策略π∗={πP∗,}使得追捕群体与想象逃逸者累积期望收益分别满足
则称π∗是博弈G的平稳纳什均衡策略[15].
追捕群体与想象逃逸者都是最大化自身累积收益的理性参与人,因此解决此最大化问题就转变为寻求连续随机博弈G的平稳纳什均衡策略问题,定理1 证明了此博弈存在平稳纳什均衡策略.
定理 1.追博弈G存在平稳纳什均衡策略.
证明.追捕群体使用平稳策略π,k阶段联合状态为u,获得联合概率动作σ,可写出追捕群体的折扣收益
其中JP(u′) 表示联合状态为u′时追捕群体的累积期望收益,σ={σP,}.将转移概率 (13) 代入,因此等式二成立;在当前联合状态u确定时,下一联合状态u′由追捕群体与想象逃逸者的纯动作决定,且追逃双方纯动作集有限,则下一联合状态u′是有限的,因此等式三成立.
由于区域状态集合S是有限集,它的子集是有限的.令S为在区域状态集合上的 B orel-σ代数,则S中具有有限个元素,同时在S上定义一个概率测度p,因此 (S,S,p) 表示概率测度空间.(S,S,p) 的任意开覆盖都存在有限子覆盖,因此概率测度空间(S,S,p)是一个紧度量空间,上文定义信念区域状态集合B是S上的概率分布集合,由此可知B是一个紧度量空间.类似地,可证得连续随机博弈中动作空间AP和也是紧度量空间.又因为坐标空间Pos是二维有限连续区域,也为紧度量空间,而联合状态空间U={Pos,B} 是Pos空间与B空间的乘积,因此U是紧度量空间.
因此Q(JP(u)) 是连续有界的,即算子Q是自映射的.又折扣因子 0<ρ<1,容易看出算子Q是M(u) 上的一个压缩映射.又空间M(u) 是所有有界Borel函数的集合,因此其是完备度量空间.根据Banach 不动点定理[39],算子Q存在一个唯一的不动点JP∗(u),并且满足.
AP和分别是集合AP和上面的概率分布,因此AP和分别是M1D1和M2D2维单纯型,显然它们是紧凸集.并且零和博弈下,(u,·,·) 是双线性函数,即FP(u,·,·) 在AP上是凸的,在上是凹的,根据最大最小定理得
而平稳策略π是联合状态空间U到动作空间A的可测映射,根据选择定理[39],可知
注 3.本文采取连续随机博弈框架与分级制决策过程的主要原因是,追捕群体无法获得逃逸者位置信息,而逃逸者则拥有全局信息,追逃双方信息不对称.追捕群体通过引入想象逃逸者来构建基于信念区域状态的连续随机博弈框架,以此实现自身利益最大化.逃逸者由于信息占优,可在获取追捕群体均衡策略的基础上,进一步通过构建马尔科夫框架求解最优策略.
经典贝叶斯博弈亦可处理本文追逃问题,然而每阶段最多会产生种区域状态,并且追逃过程是多阶段持续进行的,因此k阶段可能出现与成比例的状态数量,这显然会导致维度灾难.故本文使用基于信念区域状态的随机博弈以避免此类情况发生.
2.3 逃逸者的决策过程
与追捕群体使用连续随机博弈不同,由于真实逃逸者具有全局信息,因此它的最优策略求解可转变为一个马尔科夫决策过程.真实逃逸者纯动作集与想象逃逸者相同,AE=,用AE=∆(AE) 表示AE上的概率分布.用四元组,,>表示MDP,具体如下.
1) 混合状态: 混合状态H={U,PosE},由追博弈中联合状态U与逃逸者自身坐标PosE组成.
2) 动作:=AP×AE表示决策过程中的动作空间,概率动作={σP,σE}∈为动作空间中的元素,其中σE ∈AE.
3) 混合状态转移概率:k阶段概率动作∈,则混合状态h ∈H转移到下一阶段状态h′∈H的概率为(h′|h,)=Pr(Hk+1=h′|Hk=h,k=).
4) 收益: 令rE(h,)=rE(h,σP,σE) 表示逃逸者的期望收益,由与所有追捕者的相对距离和环境的触碰惩罚组成.
其中,d(Pi,E) 表示任意追捕者Pi与逃逸者间的相对距离,γE∈{0, 1} 表示逃逸者是否触碰地图边界及障碍物.
令逃逸者平稳策略为πE,它是混合状态H到动作空间AE的映射.在给定混合状态h时,πE(h)实际上等价于当前状态下的概率动作σE.基于连续随机博弈的追捕群体最优策略πP∗,给出逃逸者的累积收益函数
逃逸者寻求自身累积收益最大化,令πˇ∗={πP∗,πE∗}表示最优平稳策略,即满足
为获得马尔科夫决策过程中的相应的贝尔曼最优方程[38],给出如下定义
其中Q(h,σP∗,σE) 表示状态动作对价值函数,h为k时刻下的混合状态,h′为下一时刻的混合状态,JE∗(h′) 为逃逸者在状态h′下的期望累积收益.
引理 3.逃逸者的最优贝尔曼方程为
证明.由于概率动作={σP∗,σE},状态h={u,posE},h′={u′,pos′E},其中posE ∈PosE为k时刻下逃逸者的位置,pos′E ∈PosE为下一时刻的位置,因此混合状态h转移到下一状态h′的概率为
由于联合状态u的转移只与追捕群体与想象逃逸者的策略有关,因此第四个等式成立.将式(29)代入式(27) 可得
由于当前状态posE与u确定,所以下一状态是由追捕群体与逃逸者的纯动作决定,等式三成立.
3 策略求解
本节基于强化学习算法MAPPO (Multi-agent proximal policy optimization)[40],给出了追捕群体平稳纳什均衡策略与逃逸者最优策略的求解算法.与传统算法相比,M APPO 主要基于中心化训练,去中心化执行,每个智能体都具有单独的Actorcritic 结构.并且目标函数在训练中进行小批量更新,既避免了过多策略更新,又提高了训练稳定性.
真实逃逸者具有全局信息,根据追捕群体的平稳纳什均衡策略πP∗,进行MDP 最优策略求解.同理,逃逸者可定义出等参数,并不断更新网络,直至找到最优策略.
算法1 是追逃问题中追捕群体与逃逸者最优平稳策略的求解过程,第1)行到第14)行求解连续随机博弈中追捕群体的平稳纳什均衡策略.为通过数据抽样实现智能体的策略更新,将T条包含状态、动作、奖励、优势函数以及值函数的序列分别存入追捕者与逃逸者记忆库中,即第8)行所示.同时,为提高数据的可用性与训练效率,进行K次更新,如第9)行所示.基于策略,可进行逃逸策略的求解,即第15)行到第24)行.类似地,第19)行表示将序列存入记忆库中.
算法 1.最优平稳追逃策略求解算法.
4 数值仿真
本节通过三对一的案例来说明本文方法有效性.仿真环境为Windows10,搭载的CPU 为AMD Ryzen 4800H,显卡为AMD Radeon Graphics 512 MB.基于Python3.6 搭建封闭二维空间,同时使用Pytorch1.8 深度学习框架进行训练.追逃环境尺寸及障碍物如图6 所示,环境中存在三个黑色障碍物,逃逸者为红色质点E,追捕群体为蓝色质点P1,P2,P3.环境地图被切割为16 个区域,区域状态集为S={s1,···,s16},相应的信念区域状态是一个16 维的向量.追捕者运动方向被均匀划分为8 个:东、东南、南、西南、西、西北、北、东北;运动速度有两种: 0.4 m/s,0.5 m/s,因此结合静止动作,所有追捕者均可采取17 个动作.逃逸者运动方向与追捕者一致,而运动速度有三种: 0.4 m/s,0.5 m/s,0.6 m/s,因此结合静止动作,逃逸者可采取25 个动作.不失一般性,令追捕群体与逃逸者的初始位置分别在地图的四个方位内随机产生.抓捕成功的最短距离ℓ设置为追捕群体的最短步长,即0.4 m.

图6 地图尺寸Fig.6 Size of map
为获取追逃问题的最优策略,使用算法1 进行求解.在此算法中 A ctor 网络与 C ritic 网络使用两个全连接层作为隐藏层,每层神经元个数分别为64,32,神经网络使用 A dam 的梯度更新方式,学习率为0.000 1.算法中追捕群体与逃逸者的记忆库均为500,策略更新次数K=20,折扣因子ρ=0.99,切割系数ϵ=0.2.此外,对追逃问题重复训练20 000局,每一局最多运行400 个阶段,这样的训练独立进行20 次.
追捕策略的训练过程如图7 所示,红色曲线为追捕群体的平均累积收益曲线,阴影为其训练方差.可从图中看出,追捕群体累积收益呈上升趋势,在训练10 000 局时逐渐趋于收敛.同时未采取信念修正的追捕训练效果如图7 蓝色曲线所示.由图可知,追捕群体收益收敛后约为 -360,而未修正的收益约为 -420,修正状态的收益提升了近 15%,且红色阴影小于蓝色阴影,即修正状态的追捕训练更为稳定.
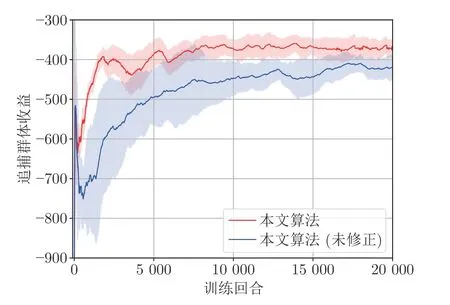
图7 追博弈中追捕群体的收益Fig.7 Pursuits' reward in the pursuit game
逃逸者策略的训练过程如图8 所示,其中红色曲线为逃逸者的平均累积收益,阴影为其训练方差.从图中可以看出逃逸者的收益在13 000 局时趋于收敛,最终稳定,收益约为380.而蓝色曲线为未修正状态的收益,稳定收益约为500.修正状态的收益较未修正的低了近 3 0%,则使用修正状态的逃逸者弱于未修正的,即修正状态的追捕群体强于未修正的.同时两条曲线方差阴影的对比,说明了使用修正状态的训练过程更为稳定.

图8 MDP 中逃逸者的收益Fig.8 Evader's reward in MDP
经统计,训练完成后追捕群体捕获成功的平均步数为41 步左右,成功率为 9 5%;未进行状态修正的追捕群体其捕获成功的平均步数为43 步,成功率为 8 7%,较修正机制下低了 8 %,可见使用测量距离进行信念修正是行之有效的.为进一步展示追捕训练的效果,在上述计算最优策略过程中,每隔100 局保存一次模型,即保存了200 个不同模型.同时,对每个模型进行1 000 局的追捕测试,具体测试结果如图9 所示.从图中可以看出,随着逃逸者训练的进行,其逃脱能力逐步上升,因此被成功捕捉步数相应增加,当对训练至15 000 局时保存的模型进行测试时,成功捕获步数已基本趋于稳定.

图9 算法测试过程Fig.9 Algorithm testing process
为了验证本文方法的优越性,使用如下几种算法进行对比: MAPPO[40],MASAC[41],MADDPG[42],几何估计追捕[33],基于三角定位追捕[34],至少一人全局视野追捕[23],自动追踪追捕[36],自适应切换追捕[37]以及随机策略.在对比中,固定所有算法中的逃逸者策略(本文算法1 所求得的逃逸策略).同时为了适应此三对一的例子,对上述部分算法做相应改进,具体如下.
1)几何估计追捕算法: 文献[33]聚焦一对一追逃问题,为适应本算例,将其改写为三对一追捕问题,即追捕群体共享领导者所估计到的位置.
2) 基于三角定位的追捕算法: 文献[34]中追捕者利用信标,也就是说使用了额外的传感器对逃逸者进行定位.然而本文中不存在信标,为进行定位,准许每个阶段中领导者移动三次,以三次不同的测距信息进行定位,并将此信息共享给跟随者.
3)自动追踪追捕算法与自适应切换追捕算法:文献[36]和[37]研究了一对一追逃问题,为适应本文算例,将其改写为三对一追捕问题,即所有追捕者均使用距离与距离变化率构建模型以求解追捕策略.
表1 记录了使用不同算法的追逃测试结果.从此表中发现,当使用MAPPO、MASAC、MADDPG 算法时,智能体进行不断地试错与学习,虽具有一定的训练效果,但由于以上三种算法均未对距离信息进行有效的利用与处理,导致捕获平均步数较高,并且抓捕成功率低.其中MADDPG 算法使用同策略,并且因为以确定性策略的方式,无法获得随机均衡策略,而MAPPO 与MASAC 算法均使用异策略,并且采取了随机策略的方式,所以捕获步数多于其余两种算法.本文决策机制虽基于PPO算法,但其结果优越性主要源于建立了基于信念区域状态的博弈框架与马尔科夫决策过程,从表1 可知与仅使用MAPPO 相比,本文算法捕获平均步数减少了43 步,成功率提高了 3 6%.

表1 结果对比Table 1 Result comparison
同时,几何估计追捕算法[33]的成功率较本文算法低 2 3%,且所花费的步数是本文算法的近两倍,可见在本文环境下,该算法对逃逸者的位置估计效果较差.而使用三角定位的追捕算法[34]可精准定位逃逸者的位置,因此捕捉成功率与本文算法接近,但由于追捕群体为获得定位所需信息,进行了额外的运动,因此抓捕步数多于本文算法.至少一人全局视野的追捕算法[23]在视野范围内使用了最优追捕策略,使得捕获成功率较高,但对于视野范围外的情况,追捕群体没有作出更为有效处理,从而捕获步数高出本文算法21 步.并且,通过距离与距离变化率求解追捕策略的自动追踪算法[36]与自适应切换追捕算法[37],均未直接对逃逸者的位置做估计定位,导致追捕效果较差.最后使用随机策略进行测试,与预期一致,由于追捕群体未采取任何智能策略而导致其效果最差.此外,通过对比可知,即使是未进行信念状态修正的本文算法,其测试效果仍优于绝大部分对比算法,体现了使用博弈框架求解平稳纳什均衡策略的有效性.
最后,在本文算法的多次测试中随机抽取4 局,画出追逃双方的运动轨迹图,如图10 所示.图中蓝色三角形与红色三角形分别表示为追逃双方的初始位置,蓝色圆点与红色圆点则分别代表追捕群体与逃逸者的运动轨迹,颜色越深,代表轨迹越新.从图中看出追捕群体都在朝向逃逸者对其形成合围之势,而逃逸者为逃脱追捕,整体运动过程均朝着追捕群体相反的方向运动.

图10 追捕群体与逃逸者的运动轨迹图Fig.10 Trajectories of pursuits and evader
5 结论
本文针对仅有距离信息的多智能体追逃问题,提出了一种基于连续随机博弈与马尔科夫决策过程的最优策略求解方法.在求解追捕策略中,为了弥补位置信息的缺失,通过引入信念区域状态对逃逸者位置进行估计,并且使用测量距离对信念区域状态进行修正.由此搭建了基于信念区域状态的连续随机博弈,并证明了此博弈平稳纳什均衡策略的存在性.在求解逃逸者策略时,根据追捕群体的最优策略与混合状态,建立了最优贝尔曼方程,并给出了基于强化学习的追逃策略求解算法.通过与已有算法的对比,验证了本文方法的有效性.此外,通过追逃群体间简单的任务分配,可将本文算法直接应用于多对多的追捕问题.但如何在围捕过程中构建有效的智能体交互与任务切换机制,以实现多对多环境下的高效追捕还有待于进一步研究.
