基于用户画像的图书推荐算法实证研究
2024-04-30潘文佳费立美
潘文佳 费立美


摘 要:个性化推荐算法能够帮助读者从图书馆海量馆藏中发现所需图书,有助于提高馆藏利用率和读者服务效率。文章以高校图书馆图书数据、读者数据和借阅数据为数据源,从中抽取关键词构建图书画像和读者画像;利用向量空间模型计算图书与读者之间的相似度,向读者推荐与其相似度排名靠前的图书;并进行推荐算法效果实证分析,揭示著录数据、读者类型、推荐窗口等变量对推荐准确率的影响。
关键词:高校图书馆;用户画像;推荐算法;个性化推荐
分类号:G252;G250.7 文献标识码:A
An Empirical Study of Book Recommendation Algorithm Based on User Profile
PAN Wenjia, FEI Limei
Abstract: The personalized recommendation algorithm can help readers find the books they need from the massive collection of the library, and help improve the utilization rate of the collection and the efficiency of reader service. This paper takes the book data, reader data and borrowing data of university libraries as the data source, and extracts keywords from them to construct the book portrait and reader portrait, uses vector space model to calculate the similarity between books and readers, and recommends the books with the highest similarity ranking to readers, conducts an empirical analysis of the effect of recommendation algorithm to reveal the influence of variables such as recorded data, reader type and recommendation window on recommendation accuracy.
Keywords: university library; user profile; recommendation algorithm; personalized recommendation
0 引言
在信息爆炸的年代,人们普遍处于信息“过载”和信息“饥渴”的矛盾状态中。信息推荐被认为是缓解这一矛盾的有效方法。图书馆读者同样面临着“被图书淹没,却饥渴于知识”的困境。一方面,图书馆拥有丰富的馆藏图书,可供选择的图书浩如烟海,读者拥有“过载”的图书资源;另一方面,纸质图书仍是读者阅读的主要载体,但是他们去图书馆借阅图书的次数越来越少,甚至于部分读者“无书可读”,处于知识“饥渴”状态。其实并非真正无书可读,而是读者感兴趣的、所需要的图书被淹没在茫茫书海之中而难以发现。基于用户画像的推荐算法能够帮助读者发现所需图书,降低读者图书搜寻难度,是提升图书馆馆藏利用率和读者服务效率的有效方法。
1 相关研究评述
使用用户画像做个性化推荐由来已久。早在20世纪90年代,Pazzani等就提出了通过用户画像帮助人们寻找他们感兴趣的网站[1],其实质就是做网站的个性化推荐。Amato等提出将用户画像应用到数字图书馆,认为用户画像能够准确地表达用户信息需求,在精准了解用户信息需求基础上能够更好地为用户提供信息服务[2]。他们提出了推和拉的两种服务模式,其实质都是利用用户画像过滤用户不需要的信息。在国内,黄文彬等提出移动用户画像构建模型,用于显示用户的频繁活动规律、周期性行为及出行方式[3],该模型可以为个性化服务提供更完整丰富的信息。曾建勋提出精准服务需要用户画像,认为数字图书馆服务必须统一认证和管理用户,从多维度认识用户的自然属性、社交属性、兴趣属性和能力属性,在用户的知识创造过程中强化精准服务[4]。韩梅花等提出利用用户画像识别具有抑郁倾向的用户并为其推送相应的图书以实现阅读治疗[5]。王仁武等通过图书馆用户的Web日志构建了学术用户画像并将其用于学术资源推荐[6]。王庆等构建了图书馆用户画像模型,并提出用户画像视角下的资源推荐流程和模式,为如何开展基于图书馆用户画像的信息资源推荐活动提供了参考[7]。杨帆介绍了国家图书馆大数据项目,提出基于读者画像和资源画像构建图书馆大数据分析平台,用于图书馆业务分析和精细化读者服务[8]。上述文章就如何构建图书馆用户画像并开展个性化推荐展开了充分论述,为實证研究工作的实施提供了强有力理论支撑。本文借鉴了国家图书馆大数据项目中对读者和资源画像的思想,同时构建读者和图书的画像,通过计算画像之间的相似度,向读者推荐与之最相近的图书。
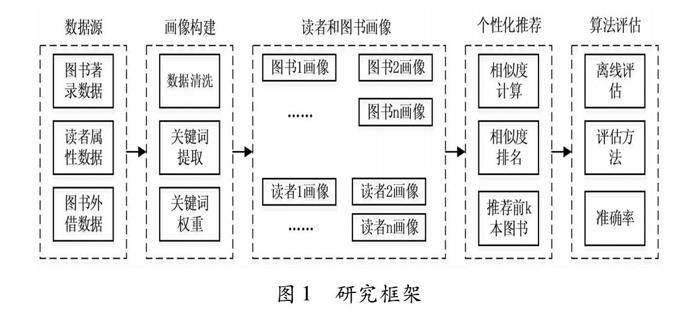
2 研究框架设计
本文设计了如图1所示的研究框架,主要包括数据源、画像构建、个性化推荐和算法评估四部分。实验数据源由南京大学图书馆提供,包括三类数据:①图书著录数据,包括图书的标题、作者、出版社、出版年、分类号等元数据,总共有40余万种图书;②读者属性数据,包括读者入学年份、所属学院和所属类型(本科、硕士、博士和教职员工),总共有5万余名读者;③图书外借数据,每条记录包含有借阅者、借阅图书、借阅时间和归还时间等信息,总共有150余万条记录。
画像构建环节利用分词技术从数据源中提取关键词作为画像标签,并计算标签权重。个性化推荐环节利用向量空间模型计算读者与图书的语义相似度,向读者推荐相似度排名前k本的图书。最后利用读者真实借阅数据评估推荐算法效果。
3 用户画像构建
用户“画像”是一种比喻,泛指一切对用户特征的描述,因此其技术方案和应用范围比较广泛。本文使用常见的标签技术为读者和图书“画像”,以关键词作为读者和图书的特征标签,以关键词权重区分标签的重要程度。因此,标签提取和权值计算是画像构建的关键环节。
3.1 标签提取和权值计算
标签分为静态标签和动态标签两种类型,静态标签表示读者和图书的固有属性,不会随着时间的变化发生改变;动态标签会随着时间的变化而改变。本文选取的读者和图书的静态、动态标签来源情况如表1所示。
读者的静态标签来源于入学年份、所属院系和读者类型三个固有属性。图书的静态标签来源于纸质图书固有元数据,本文选用标题和作者作为图书静态标签的数据来源,出版社、出版年等属性对图书的内容揭示程度不高,不作为标签来源。
读者的动态标签包括年级和借阅兴趣(源于图书静态标签)。年级是表征学生在校学习时长的特征,可以通过学生当前借阅时间和学生入学年份动态计算得到。借阅兴趣标签通过读者的借阅记录动态计算得到。假设读者借阅了一本书,那么这本书的静态标签将成为表示读者借阅兴趣的动态标签,读者借阅的图书越多,被贴上的动态兴趣标签越丰富,对读者兴趣的揭示程度越高。与读者的借阅兴趣动态标签类似,图书的动态标签来源于读者的静态标签和年级标签。当图书被一位读者借阅时,该书将被贴上这位读者的静态标签和年级标签,图书被借阅的人次越多,其动态标签越丰富。
每名读者和每本图书都会被贴上几个乃至几十上百个标签(根据借阅量的不同而有所差异),这些标签并不均等地标识读者或图书特征。本文选用TF·IDF值表征标签特征。TF指标签频率(Term Frequency),即该标签在某本书或某位读者的标签集合中出现的次数。通常来讲,标签频率越高,标签越能够代表读者或图书的特征;但并不绝对,比如“应用”、“研究”等标签虽然容易成为读者标签中的高频标签,但是其代表性并不强。因此需要引入IDF值修正。IDF值即反比文档频率(Inverse Document Frequency),用于表征标签在所有读者或所有图书中出现的频率,如果一个标签只在少数的几本书或几名读者中出现,IDF值较高,就更有代表性。读者静态标签或年级标签i的IDF值计算方法如公式(1)所示,其中N是读者总人数,ni是包含有标签i的读者人数。ni值越小,其IDF值越大,该标签的代表性越显著。图书静态标签j的IDF值计算方法如公式(2)所示,其中M是图书种数,mj是包含有标签j的图书种数。最终的标签权重计算方法如公式(3)所示,其中f是标签的TF值。
IDFi=logNni(1)
IDFj=logMmj(2)
TF?IDF=(1+logf)×IDF(3)
3.2 用户画像可视化展现
利用词云对提取后的标签组合做可视化展现,直观显示读者画像和图书画像。词云也称标签云[9],最初是一种信息组织与检索工具,用于揭示网站的信息特征,帮助用户发现感兴趣的内容;随后被用于文本主题特征的可视化呈现。典型的做法是提取文本中的关键词和词频,然后将词频作为度量关键词重要性的指标。在可视化展现中,一般通过词的字号、颜色和布局位置表达其重要性,通常权值较大的词字号更大、颜色更突出、位置更居中;反之权值较小的词则使用较小的字号、颜色暗淡、位置更偏。本文使用TF·IDF值作为词的权重指标,能够更准确地刻画词的重要性。通过词云,可以给图书管理员和读者以直观的方式呈现读者和图书画像。目前已经有各种类型的词云绘制工具,本文使用基于Python语言的WordCloud开源软件包绘制词云。该软件包的关键调用函数是generate_from_frequencies,即根据词频绘制词云。图2(a)是图书的画像展现,从图中可以直观地看出,大一本科生是借阅该书的主要读者群体,尤其是技术科学试验班和自然科学试验班。图2(b)是某个读者的标签画像,同样可以直观地发现读者的借阅兴趣聚焦在医学、解剖学、生理学和药理学等学科。
4 基于用户画像的推荐算法研究
4.1 算法思想
读者画像揭示了读者的兴趣特征和身份特征,图书画像揭示了图书的主题特征和已借读者的身份特征,两类画像特征的匹配程度可以作为向读者推荐图书的依据,匹配策略如图3所示。图书的主题特征与读者的兴趣特征越相近,读者越有可能借阅这本图书;读者的身份特征与借阅过这本图书的读者身份特征越相似,说明读者的“同类”对这本图书感兴趣,读者也更有可能借阅这本图书。因此,图书推荐算法的关键是计算读者与图书的相似度,然后推荐相似度较高的图书给读者。
4.2 读者与图书相似度计算
选用向量空间模型计算读者与图书之间的相似度。将读者和图書画像建模为N维向量,其中N是标签总数。对标签从1到N编号,每个标签xi对应编号i。本文根据IDF值对标签由高到低排序得到编号。编号是为了给标签一个唯一标识,编号数值大小对算法没有影响。一名读者或者一本图书的画像被表示成向量d,如公式(4)所示,其中wi是编号为i的标签xi的权重。当标签xi在这位读者(或图书)的画像中出现时,权重wi是该标签的TF·IDF值;如果没有出现在画像中,那么权重wi为0。假设表示读者r画像的向量是dr,表示图书b画像的向量是db,那么读者与图书的相似度计算方法如公式(5)所示,式中wi,r是读者r第i个标签的权重,wi,b是图书b第i个标签的权重。分子是读者与图书的绝对相似程度,分子是对相似程度的归一化处理。
d=(w1,w2,…,wn)(4)
simr,b=dr?dbdr×db=∑Ni=1wi,r×wi,b ∑Ni=1wi,r2× ∑Ni=1wi,b2(5)
公式(5)虽然能够度量图书和读者之间的相似度,但是在计算机程序设计时却会占用较大的内存空间。因为高校图书馆的藏书规模较大,所以表示图书特征的标签数量也会比较多,进而导致向量过长而占用过多内存空间。本研究采用的数据集中,总共提取出约30万个标签,表示单个读者或单本图书的向量长度N为30万。总共有40余万种图书,5万余名读者,总共有45万个向量,存储图书和读者特征的向量需要占用约135GB内存空间,难以被高校图书馆接受。实际上,一本图书或一名读者的标签数量通常在几十或几百个,向量中绝大多数标签的权值为0,不必存储。改用哈希表存储标签能够有效降低存储空间复杂度。假设读者r的画像标签选用哈希表Hr存储,图书b的标签画像选用哈希表Hb存储,那么读者r与图书b的相似度计算方法如公式(6)所示。其中Cr是读者r的标签集合,Hr[c]是读者r的标签c的权值;其中Cb是图书b的标签集合,Hb[c]是图书b的标签c的权值。哈希表H仅存储权值非0的标签,没有被存储的标签权值默认为0,不必存储,将极大地降低存储空间,节省计算机硬件购置成本。
simr,b=∑c∈Cr∩CbHr[c]×Hb[c] ∑c∈CrHr[c]2× ∑c∈CbHb[c]2(6)
5 推荐算法效果实证分析
5.1 实证方法
面向高校图书馆真实使用场景评估推荐算法效果,根据读者借阅历史记录预测读者未来可能会借阅的图书。将一名读者在一天里借阅的所有图书视作一次借阅记录。要求算法通过读者前一次的借阅记录预测这名读者在下一次最有可能借阅的k本图书,如果下一次借阅的图书中有1本出现在这k本图书列表中,则视作一次成功推荐;如果下一次借阅的任何一本图书都没有出现在这k本中,则视作一次失败推荐。准确率的计算方式是成功推荐次数除以总推荐次数。对于只借过一次图书的读者和读者的最后一次借阅,由于无法验证推荐是否成功,不纳入测试范围。
将所有图书的著录数据和读者的属性数据分别作为图书和读者的静态标签,用于绘制图书和读者动态标签的图书外借数据在测试中需要区分对待。由于高校图书馆读者的借阅活动通常以学年为周期展开,因此将图书外借数据集划分为13-14学年、14-15学年、15-16学年和16-17学年,共四个学年。将前三个学年的图书外借数据作为训练数据,用于绘制图书画像的动态标签,将16-17学年的借阅数据作为测试数据,用于从中提取测试用例。一个测试用例是指一名读者前一次借阅记录和后一次借阅记录形成的借阅记录测试对,其中前一次借阅记录是预测后一次借阅记录的依据,后一次借阅记录是评判算法是否准确预测的标准。总共从16-17学年的借阅数据中提取出98692个测试用例,其中本科生45423个,硕士生31657个,博士生14845个,教师4506个,测试用例规模较大,测试结果具有较高置信度。
5.2 结果及其分析
运用相似度计算公式(6),对上述测试用例进行计算。设定推荐窗口k为10,即每次向读者推薦10本图书。面向全校所有读者的推荐准确率是20.4 0%。该准确率偏低,无法直接应用到高校图书馆的真实场景。导致准确率偏低的原因有以下三类:
5.2 .1 著录数据对推荐准确率的影响
本研究使用的数据集仅提供了图书的标题和作者两个字段,未能获取图书的主题词、内容简介等著录数据,导致对图书的内容特征揭示不充分。98692个测试用例中,只有34.3%的测试用例的前一次借阅记录和后一次借阅记录的画像之间有一个以上相同标签,其余65.7%的测试用例前后借阅记录的画像标签交集为空。在真实应用场景中,应当融合更多的图书著录数据以提升书目内容特征的揭示程度,增加推荐准确率。此外,读者兴趣特征揭示不充分也会降低推荐准确率。为便于测试,本研究仅选择了读者前一次借阅的图书作为揭示其兴趣特征的标签来源,并未把读者所有借阅历史记录用于揭示读者兴趣。实际上,有50.3%的测试用例的前一次借阅记录只有一本书,仅通过一本图书预测读者后续借阅记录的难度较大。在真实应用场景中,应当融合读者所有历史记录以充分绘制读者兴趣特征以提升推荐准确率。
5.2 .2 读者类型对推荐准确率的影响
高校图书馆的主要读者类型有本科生、硕士生、博士生和教师四类,他们的借阅偏好必然存在一定差异。从图4可以发现,不同类型读者的推荐成功率并不相同,且呈现出有规律的差异。即学历层次越低,推荐准确率越低;学历层次越高,推荐准确率越高。这一现象的形成与推荐算法特性和读者借阅偏好有关。基于画像的推荐算法将图书的内容特征和读者的阅读兴趣作为主要推荐依据,读者的借阅兴趣越集中,推荐算法的准确率越高;读者的借阅兴趣越分散,算法就越难预测读者可能会借阅的图书,推荐算法准确率就越低。高等院校中,本科生群体主要接受公共课和专业基础课教育,学习偏好更侧重广度,因此借阅兴趣比较分散,推荐准确率偏低。随着学历层次的提升,学习的专业性增强,读者的借阅兴趣更聚焦,推荐准确率更高,因此硕士、博士的推荐准确率随之增加。教师是所有读者中专业性最强的一类群体,他们通常聚焦于自己钻研的特定领域,兴趣最为聚焦;所以面向教师群体的推荐准确率远高出学生群体。
5.2 .3 推荐窗口对推荐准确率的影响
推荐窗口是指向读者推荐图书数量。推荐窗口越大,推荐的图书越多,读者发现感兴趣图书的可能性就越大,准确率自然越高。但是推荐窗口并非越大越好,过大的推荐窗口会再次导致二次信息“过载”,甚至引发读者对推荐系统的反感。推荐窗口的准确率如图5所示:横坐标为推荐窗口数量,纵坐标为推荐成功率。从图中可以看出,虽然推荐准确率整体上随推荐窗口的增加而增大,但增大的幅度却逐渐在减小。在推荐窗口较小时,每增加一本推荐图书,将带来推荐准确率较大幅度提升;随着推荐窗口增大,每增加一本推荐图书带来的准确率提升幅度却逐渐减小。该曲线上升斜率类似对数函数增长模式,说明不能盲目增大推荐窗口,应当根据实际情况设计合理的推荐窗口。典型的做法是利用“画象”相似度计算设定相似度阈值, 只选大于相似度阈值且排名前K的图书加入推荐窗口。
6 结语
本文以图书著录数据、读者属性数据、图书外借数据作为数据源,从中提取构建图书画像和读者画像的标签,并利用词云技术以可视化方式绘制图书画像和读者画像。利用向量空间模型计算图书与读者之间的相似度,并将相似度排名靠前的图书推荐给读者。在高校图书馆图书外借数据集上评估了效果,通过实验验证了图书推荐算法的可用性。实验结论如下:①认为算法推荐准确率偏低的主要原因是揭示纸质图书内容特征的元数据偏少,在实际应用中可以通过增加纸质图书的元数据提升推荐准确率。②发现算法推荐准确率随着读者学历层次的增加而增加,原因是读者的学历层次越高,读者的借阅兴趣越聚焦,越有利于预测读者的借阅偏好。③讨论推荐窗口对推荐准确率的影响,发现随着推荐窗口的增大,增加推荐窗口带来的推荐准确率提升越不显著。在真实环境中,应当设计合理的图书推荐窗口。
最后,需要强调指出:实验是基于用户画像对算法公式推导的实证研究,受限于实验数据缺失,仅仅通过少许“标签”很难准确地呈现推荐准确率。因此,在后续研究中应当融入更丰富的描述资源以提升推荐准确率。
参考文献:
[1]Michael Pazzani, Daniel Billsus.Learning and revising user profiles: The identification of interesting web sites[J].Machine learning,1997,27(3):313-331.
[2]Giuseppe Amato, Umberto Straccia.User profile modeling and applications to digital libraries[C].Springer,1999:184-197.
[3]黃文彬,徐山川,吴家辉,等.移动用户画像构建研究[J].现代情报,2016,36(10):54-61.
[4]曾建勋.精准服务需要用户画像[J].数字图书馆论坛,2017(12):1.
[5]韩梅花,赵景秀.基于“用户画像”的阅读疗法模式研究:以抑郁症为例[J].大学图书馆学报,2017,35(6):105-110.
[6]王仁武,张文慧.学术用户画像的行为与兴趣标签构建与应用[J].现代情报,2019,39(9):54-63.
[7]王庆,赵发珍.基于“用户画像”的图书馆资源推荐模式设计与分析[J].现代情报,2018,38(3):105-109,137.
[8]杨帆.画像分析为基础的图书馆大数据实践:以国家图书馆大数据项目为例[J].图书馆论坛,2019,39(2):58-64.
[9]倪娟.论标签云在高校图书馆学科知识服务中的应用[J].图书馆,2013(6):18-20.
作者简介:
潘文佳(1980— ),男,大学本科,馆员,任职于南京图书馆。研究方向:信息技术与图情服务。
费立美(1989— ),女,南京大学信息管理学院在职硕士研究生在读,馆员,任职于南京图书馆。研究方向:智慧图书馆与图书馆技术。
