基于深度学习的中文文本分类综述*
2024-04-23李世杰蔡志平
高 珊,李世杰,蔡志平
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
文本分类是指为文本指定预定义标签的过程,是许多自然语言处理NLP(Natural Language Processing)应用程序中的一项重要任务,具有众多的应用场景,例如情感分析[1]如图1所示;问答系统[2,3]的基本流程如图2所示;对话行为分类[4]、话题分类[5]等。
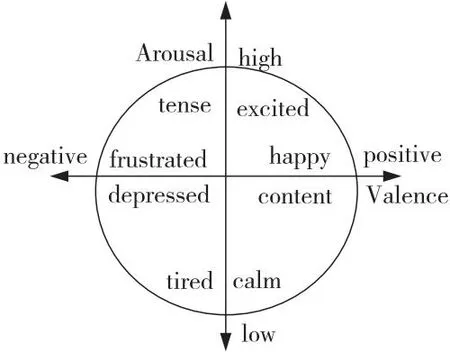
Figure 1 Sentiment analysis

Figure 2 Basic process of question and answer system
近年来,国内外的文本分类研究者在传统机器学习和深度学习2个方向对文本分类问题做了许多探索和研究。本文将简要介绍传统机器学习的文本分类方法,详细阐述使用深度学习的文本分类方法。
2 文本特征表示
文本特征表示是对原始文本进行预处理,以便训练分类模型。文本特征表示通常包括分词、数据清理和统计,是文本分类的基础。
2.1 中文文本预处理的特殊挑战
和英文文本处理分类相比,中文文本的预处理是关键技术。中文文本预处理通常要进行分词、去除停用词、过滤低频词等。其中,最重要的是分词部分。在中文表达中,词是表达完整含义的最小单位。由于汉字的粒度较小,在大部分情况下,无法表达完整的含义,如图3所示,“鼠”可以是“老鼠”,也可能定义为“鼠标”,而句子的粒度又较大,承载的信息量过多,难以复用。

Figure 3 Example of Chinese word segmentation
中文语句需要通过分词,构成词的集合,为后续文本分类奠定基础。在分词上,中文文本与英文文本有很大的不同。中文分词难点主要体现在3个方面:分词的规范、歧义词的切分和未登录词识别。英文文本使用空格作为分隔符,中文文本没有该特点,切分时需要根据语义,因此如何切分中文文本成为一个难点,例如“兵乓球拍卖完了”,不同的分词方式可表达出不同的涵义:
乒乓球 拍卖 完了
乒乓 球拍 卖 完了
随着网络社交的不断发展,人类处于信息爆炸的时代,在网络上新出现了一些网络流行语,如“蓝瘦香菇”“房姐”“奥特”“累觉不爱”等,这些网络流行语也给中文的分词技术加大了难度。此外,中文词在文本中的前后关系复杂,不同词在不同的语境中具有不同的含义,中文里也常见一词多义的情况,导致分词易出现歧义。
中文分词方法常见为3大类:基于词典匹配的方法、基于统计的方法和基于深度学习的方法。基于词典匹配的分词方法,基本思想是基于词典匹配,将待分词的中文文本根据一定规则切分和调整,根据词典中的词语进行匹配,如果该词语在词典中,则分词成功;否则继续拆分匹配直到成功,然后进行反复循环。代表性的方法有:基于正向最大匹配方法、基于逆向最大匹配方法和双向匹配方法。基于统计的方法统计由相邻单词组成的单词出现的概率。相邻单词的出现次数和出现概率都很大。根据概率值进行分割,主要有隐马尔科夫模型HMM(Hidden Markov Model)[6]和条件随机场模型 CRF(Conditional Random Field)[7]。比如Stanford和HanLP[8]分词工具都是基于CRF算法的。
近年来,随着基于深度学习算法的中文分词方法的提出,其分词效果在一定程度上优于传统的分词方法,使用深度学习算法进行中文分词的基本思想是同步进行分词、语句、语义以及语法的分析。Peng 等人[9]采用长短时记忆网络LSTM(Long Short-Term Memory)提取中文分词特征,使用 CRF对标签进行联合解码,其本质上为序列标注。此外,还有常用的Python中文分词工具jieba等方法。
中文文本相对于英文文本,通常存在大量的“的”“和”等副词,以及量词、感叹词和数词等与理解语义无关的词组且出现频率较高,容易带来噪声。去停用词可以减少特征词的数量,提高文本分类的准确性。可通过建立中文的停用词表,扫描分词词典进行字符匹配。
对于分词后的中文文本,还可以根据不同的任务进行词性标注,比如情感分析、舆情挖掘等任务。
2.2 中文文本表示
文本表示旨在以一种对计算机来说更容易且最小化信息损失的形式来表达预处理的文本,例如BOW(Bag Of Words)[10]、N-gram、词频逆文档频率TF-IDF(Term Frequency-Inverse Document Frequency)、word2vec[11]以及单词表示的全局向量GloVe(Global Vectors)[12]。
BOW的思想是创建一个含有来自于训练语料库全部词语的字典,每个词语都与其独特的识别编号一一对应。其中,One-Hot可对中文文本进行字符级编码,即存在的词语用1表示,不存在的用0表示。BOW只关注了词语出现的次数,无视句子或者文档中的语法、语序关系和顺序。
与BOW相比,N-gram考虑了相邻的中文文本信息,并通过考虑相邻中文文本来构建词典。N-gram常用于计算句子的概率模型。句子的概率表示为句子中每个文本的联合概率。
TF-IDF使用单词频率并反转文档频率来建模文本。统计文本词频,生成文本的词向量空间。TF是特定文章中某个词的词频,IDF是包含该词的文章占语料库中文章总数的比例的倒数,TF-IDF是两者的乘积。TF-IDF用于评估一个单词对一组文件或语料库中一个文档的重要性。一个单词随着它在文档中出现的次数成比例地增加。然而,它在语料库中的频率总体上呈反比下降。TF-IDF没有考虑词的上下文和重要性,单纯以“词频”衡量一个词的重要性,不够全面。
word2vec使用2个基本模型CBOW(Continuous Bag Of Words)和Skip gram,如图4和图5所示。前者是在已知当前单词的上下文的前提下来预测该词,FastText[13]是基于CBOW模型提出的快速文本分类方法。后者是在已知当前单词时预测上下文。word2vec在对大量的语料进行训练之后,使用给定维度的向量来对每个单词进行表示,单词之间的语义和语法相似度均可用向量的相似度表示。由于词和向量是一对一的关系,所以多义词的问题无法解决。此外,word2vec是一种静态的方式,如图6展示了使用word2vec进行中文文本表示的示例,其具有较强的通用性,但是无法根据指定任务进行动态处理和优化。

Figure 4 CBOW model
Figure 5 Skip gram model
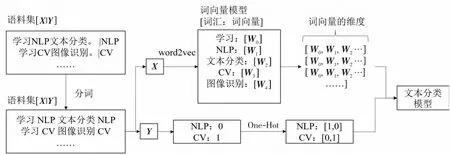
Figure 6 Example of word2vec Chinese representation
GloVe通过局部上下文和全局统计特征来训练单词,单词属于共现矩阵中的非零元素。它使词向量能够包含尽可能多的语义和语法信息,以语料库为基础,建立词汇的共现矩阵并结合 GloVe模型进行词向量学习。最后,根据所选特征将所表示的文本反馈到分类器中。
3 中文文本分类的传统机器学习方法
使用传统的机器学习对文本进行分类,主要是进行文本特征表示(包含文本预处理、特征提取、文本表示3个部分)、构造分类器、分类结果的评估与反馈等过程。文本表示主要以布尔模型 (Boolean Model)、概率模型(Probabilistic Model) 和向量空间模型(Vector Space Model) 3种模型为代表。构造分类器是传统机器学习进行文本分类的核心之一,通过使用提取词频或者词袋特征的方法,将提取出的特征放入模型中进行训练。
对于传统模型,朴素贝叶斯NB(Naive Bayesian)[14]是用于文本分类任务的第一个模型,如图7及式(1)所示,其中文本T=[T1,T2,…,Tn]独立。
y∈{T1,T2,…,Tn}
(1)

Figure 7 Naive Bayes
随后,研究者提出了通用分类模型,K值邻近算法KNN(K-Nearest Neighbor)[15]如图8所示、支持向量机SVM(Support Vector Machine)[16]、随机森林RF(Random Forest)[17]、决策树DT(Decision Tree)、中心向量法以及Ada Boost技术[18]等,广泛地用于文本分类。最近的研究发现,极限梯度增强XGBoost(eXtreme Gradient Boosting)[19]和光梯度增强机LightGBM(Light Gradient Boosting Machine)[20]具有优异的性能。

Figure 8 K-value proximity algorithm (K=3)
传统机器学习方法都具有一定的优缺点,比如朴素贝叶斯算法,对小规模的数据表现很好但对缺失数据不敏感,算法思想较为简单,通过先验和数据来决定后验的概率从而决定文本分类。朴素贝叶斯算法需要数据集属性之间的关系相对独立,对输入数据的表达形式较为敏感。因此,在属性数量较多或者属性之间相关性较大时,其分类效果较差;基于KNN文本分类算法具有稳定、准确率较高的优点,但其预测的结果容易受到含噪声数据的影响,并且对样本均衡的要求较高。
目前,传统机器学习表现出的分类效果相对较低,这是因为传统机器学习是浅层次的特征提取,忽略了词与词之间以及句子和句子间的关系,对于文本背后的语义、结构、序列和上下文理解不够,对高维数据的处理和泛化能力较差,模型的表征能力有限。
随着研究者的不断探索,2006年Hinton等[21]提出了深度学习(Deep Learning)的概念。自此,文本分类问题的重心逐渐从传统机器学习转向基于深度学习的研究,并成为了文本分类领域的主流研究内容。
4 中文文本分类的深度学习方法
相较于传统的机器学习,深度学习可利用其自身的网络结构进行学习,从而获得数据特征。例如,卷积神经网络CNN(Convolutional Neural Network)[22]、循环神经网络RNN(Recurrent Neural Network)[23]等。
图9展示了利用传统机器学习和深度学习进行文本分类过程的流程图。文本数据不同于数字、图像或信号数据。第一个重要步骤是为模型预训练文本数据。传统模型通常需要通过人工方法获得良好的样本特征,然后用经典的机器学习算法对其进行分类。因此,特征提取在很大程度上限制了该方法的有效性。然而,与传统机器学习模型不同,深度学习通过学习一组用于将特征直接映射到输出的非线性变换,将特征工程集成到模型拟合过程中[24]。

Figure 9 Traditional machine learning and deep learning text classification processes
4.1 CNN
CNN因其卷积滤波器可以提取图像的特征,最初被提出用于图像分类。CNN能对多个序列块进行多核的卷积运算。因此,神经网络在很多 NLP问题中得到了应用。
首先,将输入文本的单词向量拼接成矩阵。然后,矩阵被送入卷积层,卷积层包含几个不同维度的滤波器。最后,卷积层的结果经过池化层并连接池化结果,以获得文本的最终矢量表示。类别由最终向量进行预测,如图10所示。
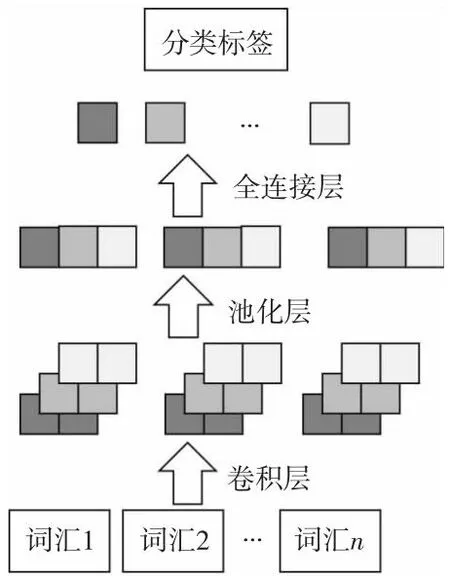
Figure 10 CNN text classification
在CNN网络的基础上,Kim[25]提出了一种卷积神经网络的无偏模型TextCNN。它可以通过一层卷积更好地确定最大池化层中的区分短语,并通过保持单词向量静态来学习除单词向量之外的超参数。仅对标记数据进行训练对于数据驱动的深度模型是不够的。因此,一些研究人员考虑利用未标记的数,与传统图像的 CNN 网络相比,TextCNN保持原有网络结构,简化了卷积层,使其具有网络结构简单、参数量少、计算量少和训练速度快的优点。
CNN以及TextCNN都为浅层网络,Alexis等人[26]在此基础上,对深度网络在文本分类任务上的问题进行了研究,提出了字符级的深层卷积神经网络VDCNN(Very Deep Convolutional Neural Network for Text Classification);Johnson 等人[27]在2015年提出了一种基于两视图半监督学习进行文本分类任务的模型;在此基础上,Johnson等人[28]又提出了一种深度金字塔卷积神经网络DPCNN(Deep Pyramid Convolutional Neural Networks for Text Categorization),通过提高网络深度来提高计算精度,DPCNN比残差网络ResNet[29]结构更为简单;2015年Zhang等人[30]提出的CharCNN,通过卷积的方式共享参数,可以有效地减少嵌入层需要训练的参数量,从而提高计算效率;Adams 等人[31]提出了一种字符级CNN模型,称为MGTC(Multilingual Geographic Text Classification),可以实现对多语言文本的分类;Kipf等人[32]在图卷积神经网络的基础上提出了GCN(Graph Convolutional Network)模型,后续的研究者对GCN模型进行了研究和变体,尤其是在文本分类任务上,又提出了TextGCN[33]、FastGCN[34]、TensorGCN[35]、Text-level GCN[36]、D-GCN(Dynamic-Graph Convolutional Network)[37]和GCNII[38]等模型。
4.2 RNN
循环神经网络RNN常用于通过递归计算来获取序列的演进方向。其中在深度学习中,门控循环单元GRU(Gate Recurrent Unit)[39]和LSTM较为常见。
RNN的核心为有向图,以循环单元为元素进行链式项链,易捕获文本分类任务的所有单词中的位置信息。图11展示了RNN文本分类模型。首先,使用词嵌入技术,将每一个词汇用特定的向量表示。然后,嵌入的词汇向量将连续反馈给循环单元(RNN Cell)。最后,可以通过隐藏层的输出来预测文本的分类标签。
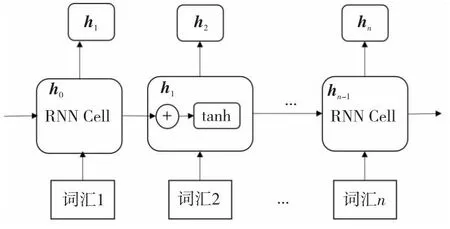
Figure 11 RNN text classification
Koutnik等人[40]为了克服RNN梯度爆炸或消失等问题,提出了CW-RNN(Clock Work RNN),通过时钟频率使RNN获得最佳效果;为了对具有长输入序列的主题标记任务进行建模,Dieng等人[41]提出了TopicRNN用于主题分类,其模型将RNN和文本的潜在主题结合起来,以此获得句法和语义之间的依赖关系;Schuster等人[42]在单向RNN的基础上,提出双向循环神经网络,模型可获取过去和未来2个方向上的信息,提高了文本分类任务的准确性;Wang等人[43]提出的胶囊结构的RNN模型,在情感分类任务上起到了很好的效果。
LSTM可以有效缓解因RNN在连续乘法中的梯度消失问题,为文本分类模型提供了基础,如Tai等人[44]提出的Tree-LSTM,即从树结构来改进语义表示;袁婷婷等人[45]基于微博上的性格情感分析提出了PLSTM(Personality-based LSTM)。
GRU作为LSTM的变体,在一定程度上对LSTM的结构进行了精简改进。2019年孙明敏[46]提出的基于GRU和Attention联合的中文文本分类,利用注意力机制,找出中文文本中的关键词。
4.3 Attention
CNN和RNN均在文本分类相关任务上展示出了优异的结果。然而,由于隐藏数据的不可读性,导致这些模型在分类错误的情况下难以解释。
在Bahdanau等人[47]提出的基于机器翻译注意力机制的基础上,Yang等人[48]提出了分层注意力网络HAN(Hierarchical Attention Network),可以对每个句子使用注意力机制提取出关键信息,进而对关键信息使用注意力机制并用其进行文本分类。
4.4 预训练模型
预训练语言模型[49]可以高效地学习全局语义,并显著提高NLP任务的效率和结果的准确率。预训练语言模型通常使用无监督方法自动挖掘语义知识以及并行化计算,从而提高文本分类的效率。
2019年,Devlin等人[50]提出了BERT(Bidirectional Encoder Representations from Transformers)模型,BERT应用双向编码器,通过联合调整所有层中的上下文来预训练深度的双向表示。在处理自然语言处理的下游任务时,只需要对其进行微调。
在BERT的基础上,RoBERTa[51]进行了改进,它采用动态掩蔽方法,每次生成掩蔽模式,并将序列送入模型;ALBERT(A Lite BERT)[52]通过减少了碎片向量的长度和与所有编码器共享参数的方式减少了BERT的参数,实现了跨层参数共享。GANBERT(Generative Adversarial Nets BERT)[53]使用生成对抗的半监督学习网络来增强BERT的训练;RoCBert(Robust Chinese Bert)[54]是一种经过训练的中文BERT,为了解决中文字形易受对抗攻击性的问题而提出的。Dai等人[55]分别使用标准字符级掩码、全词掩蔽以及两者的组合来训练3个中文BERT模型。Dict-BERT[56]通过利用字典中稀有单词的定义来增强语言模型的预训练。
对于将BERT进行精简上,DistilBERT[57]在减少了40%的参数基础上仍保留了97%的语言理解能力;TinyBERT[58]和LightMobileBERT[59]也通过不同的方法对BERT进行了精简;bert2BERT[60]通过递进式训练大模型的方法,提高了效率,也加快了收敛速度。
受到图像学习的启发,文本分类任务中也涌现出一大批语言模型,如:Glove[12]、ELMO(Embedding from Language MOdels)[61]、ULMFiT(Universal Language Model Fine-Tuning)[62]、XLNet(eXtreme multiLingunal pretraiNEd Transformer)[63]、TG-Transformer(Text Graph-Transformer)[64]、X-Transformer(eXtreme-Transformer)[65]、LightXML(Light eXtreme Multi-Label)[66]以及近期的研究热点OpenAI GPT(Generative Pre-trained Transformer)模型。
5 中文文本分类数据集
数据集的选择对文本分类实验结果有着重要的影响,目前文本分类常用的开源数据集如下:
Sogou数据集:Sogou 新闻数据集是Sogou CA和 Sogou CS新闻语料的混合。新闻的分类标签由统一资源定位符URL(Uniform Resource Locator)中的域名决定,常用于新闻分类。可从Sogou官网https://www.sogou/labs/resource/ca.php获取。
THUCNews数据集:THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏和娱乐。可从THUCNews官网http://thuctc.thunlp/中获取。
Datahub数据中心:包含文本分类、情感分析以及知识图谱的数据集,可从Datahub官网http://www.datahub.ileadall42中获取。
今日头条新闻文本分类数据集:数据来源于今日头条客户端,共382 688条数据,分布于15个分类中。 可从toutiao-text-classfication-dataset中获取。
复旦中文文本分类语料库:共20类,18 655条数据集。
6 结束语
6.1 总结
本文主要介绍了现有的文本分类任务方法,包括传统的机器学习方法和深度学习方法。传统方法主要通过改进特征提取方案和分类器的设计来提高文本分类性能。相比之下,深度学习方法通过改进演示学习方法、模型结构以及其他数据和知识来提高性能。本文着重介绍了中文文本分类任务中的文本表示部分以及常用的中文文本分类数据。
6.2 展望
对于中文文本分类方法的集成,RNN需要逐步递归以获得全局信息。CNN可以获得局部信息,并且可以通过多层堆栈增加感测场,以捕获更全面的上下文信息。注意力机制学习句子中单词之间的全局依赖性。Transformer模型依赖于注意力机制,以建立输入和输出之间的全局依赖关系的深度。因此,设计一个集成方法可能是未来发展的方向。
对于方法的效率,尽管基于深度学习的文本分类方法是非常有效的,例如CNN、RNN和LSTM,但是,这些方法仍存在许多技术限制,如网络层的深度、正则化问题、网络学习率等。因此,优化文本分类方法和提高模型训练速度仍有更广阔的发展空间。
