面向无人机集群察打场景的PPO 算法设计
2024-04-16李俊慧张振华聂天常车博山
李俊慧,张振华,边 疆,聂天常,车博山
(北方自动控制技术研究所,太原 030006)
0 引言
军事作战概念从“军种联合”到“跨域”,再到“全域作战”的演变过程中,无人机集群充当至关重要的角色[1]。无人机集群作为新的作战力量,在未来战场上发挥重要价值[2]。无人机集群通常执行侦察、打击等任务。执行侦察打击任务需要进行合理决策,将任务分配给不同的无人机,并规划它们的行动路径,使其能够高效地完成任务。目前,无人机集群的任务分配与运动规划方法主要可分为规则算法、启发式算法与深度强化学习算法3 类。其中,规则算法和启发式算法受高维非线性、局部最优、先验知识依赖问题的限制。与此同时,由于战场环境的不确定性、复杂性和动态性,规则和启发式方法效果不佳。深度强化学习是一种激励学习,通过奖励或惩罚引导智能体学习从状态空间到动作空间的映射,在激励中不断试错纠正,甚至探索创新行为,最终根据可获取的状态给出最优的策略。该算法能够处理高维非线性问题,不需要对状态进行预测,不显性建模行动和环境的相互影响,也可以不依赖先验信息,是解决复杂不确定条件下自主学习的有效手段[3]。因此,本文选用深度强化学习算法应用到无人机集群任务分配和路径规划研究中。采用DRL 方法进行无人机集群任务分配与运动规划的研究已经取得一定的进展。文献[4]采用Actor-Critic 强化学习结构,网络以NRBF 神经网络拟合,通过控制3 个变量实现了无人机的机动决策;文献[5]选用软行动者-评论家算法(soft actor-critic,SAC)结构,价值策略网络均选用多层感知机拟合,通过控制前进后退力度与朝向控制坦克的速度。文献[4-5]控制的作战单元少,决策的量少,任务复杂度低。文献[6]通过多智能体近端策略优化方法研究了实战中常见的动态火力分配的决策问题。文献中毁伤概率仅与来袭目标相关,忽略了战场其他因素的影响。文献[7]研究了不清楚威胁数量、位置和策略的条件下巡飞弹的突防问题,通过深度确定性策略梯度算法,巡飞弹实现了以同一高度固定速度进行自主躲避蓝方火力。该文献一定程度证明了在动态对抗环境下的运动自主性。在现实作战中,更具实际意义的决策问题往往具有复杂性、动态性、不确定性等特点[3]。侦察打击作战中,通常包含多个单元移动、侦察、打击、规避等决策点,同时由于天气的随机性和蓝方兵力部署的不确定等因素的影响,侦察概率与毁伤概率往往动态变化,任务难度大。
综上所述,如何在动态复杂不确定条件下进行集群的任务分配与运动规划仍然是研究的难点和热点。本文以无人机集群在不清楚蓝方数量和位置的区域内执行侦察打击任务为想定场景,主要的贡献和创新点总结如下:
1)为更真实反映战场环境的不确定性,主要包括自然环境的随机性和蓝方兵力部署的未知性,通过在仿真平台对战场自然环境如天气、地势等进行参数化建模,同时主要建模了环境对无人机传感器侦察的影响,另外通过仿真平台作战规则模拟了蓝方兵力部署的未知性,实现较大程度模拟了真实作战场景。
2)针对集群在不确定察打对抗环境中的复杂决策问题,提出了较为通用的状态空间、奖励函数、动作空间与策略网络设计方法,实现了基于PPO 的集群察打智能体的有效学习训练,解决了决策的复杂性。状态空间从多个角度设计并提取特征,捕捉多维度战场态势信息,具有灵活性与可扩展性;奖励函数的设计紧密结合察打任务的作战效果指标,以实现察打任务最优化;动作策略采取主谓宾的形式,以更好地表达无人机集群的复杂决策动作;策略网络选用编码器-时序聚合- 注意力机制- 解码器结构,降低优化问题的复杂性,促进训练收敛。
3)在构建的典型察打任务场景中,通过大规模并行仿真推演生成的数据进行训练学习,赋予了无人机集群运动规划和任务分配的智能性。通过实验验证了面对未知威胁时自主规避的运动规划的智能性与面向最大化毁伤能力的任务分配的智能性。
1 复杂不确定性分析
为构建典型集群察打想定场景,使用了支持战场环境模型参数化建模的仿真推演平台。战场环境模型主要指仿真模型库和推演引擎中各种用于模拟实战而建立的数学模型。该仿真推演平台具备一定程度专业的可参数化战场环境模型,能够还原出实战任务中决策的复杂性。
1.1 战场环境模型参数化设计
仿真模型库中包含实体模型和组件模型,其中实体模型有飞机、战场设施、武器等,组件模型有传感器、推进系统、战斗部、挂载方案等。对于实体模型,该平台支持物理属性和运动与动力学的建模。其次,作战实体模型通常配备各种传感器和挂载方案,可通过参数化建模模拟组件的性能和配备效果。另外,仿真中涉及的作战实体可模拟损伤和恢复过程。平台还模拟了环境模型,环境因素对作战实体的性能和行为都会产生影响。通过准确建模仿真模型库,可以使仿真平台更真实地模拟作战场景,并为实际作战提供有价值的参考和决策支持。
模型的真实性促使众多因素互相影响,侦察打击任务面临着复杂不确定性的挑战。其中,引起侦察任务中不确定性的因素涉及了传感器模型、目标类型以及天气条件等方面,这些因素导致目标的探测和识别概率变化不定,增加了任务的挑战性。为在不同环境条件下获得更全面的感知能力,红方使用了雷达和光电传感器模型,雷达模型负责长距离、受天气影响小的目标探测,而光电模型则在近距离和良好光照条件下提供更高分辨率的目标信息。同样地,打击任务影响因素有武器效能和精度、火力密度、目标类型、打击时间以及蓝方反应等,这些因素造成任务中红方执行能力的不确定与蓝方反击的不确定,从而打击的毁伤概率不确定。
这里挑选了4 种典型的不同类型的战场环境模型,并展示了其可参数化建模的关键属性,如表1所示。

表1 模型参数Table 1 Model parameters
为更真实模拟实际战场的复杂性和不确定性,每回合随机设定天气、蓝方单元位置部署和蓝方实力。通过这种方式增加了博弈对抗因素,提升智能体面对未知和不确定性的应对能力,使训练出来的智能体更具有实战价值。
1.2 想定场景介绍
红方派出数架无人机前往某区域范围内执行侦察打击任务,且收到的情报中没有关于蓝方的兵力部署情况。具体的任务内容如下:无人机进入区域后对蓝方目标进行搜索,明确目标位置与类型。此外,无人机需要完成对特定目标的打击毁伤。任务执行过程中,若遭遇蓝方防空火力的袭击,无人机需要快速规避,避免被击落。因此,无人机集群需要进行有效及时的智能决策,任务复杂度高。
2 深度强化学习决策算法设计
2.1 状态空间设计
深度强化学习状态空间的设计力求简洁、高效。因此,状态信息的筛选尤为重要。在训练过程中,深度神经网络需要从状态信息中提炼出与长期回报高度关联的特征。状态信息的变化对奖励的反馈越及时越容易建立决策相关性[8]。因此,需要选择尽可能与奖励即时联动的信息。同时为了更好地帮助智能体全面建模和理解实体、任务、环境,以及它们相互之间的关系等信息,需要构建多元的状态信息,且要提升信息表达的通用泛化性。
首先,每个作战单元有自己的独立属性,多个单元的属性特征建模为序列(sequence)特征。序列特征除了红方单元外,也需要包含侦察到的蓝方单元状态信息。此外,在推演中由于毁伤的原因,单元的数量可变,因此,该序列特征长度可变。本文红方单元属性状态变量包含经纬高度、速度、毁伤情况、弹药装载量、执行任务类型。蓝方单元属性变量有经纬度、类别和毁伤情况。
其次,任务通常在三维空间中执行,在涉及空间决策的任务中,空间信息的缺失可能导致智能体在环境中无法准确地执行任务。本文建立了空间三维状态信息,在栅格化空间区域累计红方被击中和被毁伤的次数以标记威胁程度,帮助红方更好地实现规避。
本文还采用一维特征用于捕捉任务环境中的一些重要变量,如时间、天气条件、任务进度等。这些变量作为决策的依据,影响智能体的策略选择。
同时,为提高状态空间的灵活性与可扩展性,对状态信息进行归一化。常用的归一化方法有Min-Max 归一化、Z-Score 归一化、范围放缩法等。这里选用了Min-Max 归一化如式(1),将状态信息映射到[0,1]。
2.2 奖励函数设计
奖励函数的设计需要围绕察打作战业务指标设计,从而最优化作战效能。这里考虑的作战效能主要包括侦察任务完成度、毁伤任务完成度、时间效率以及己方损失。奖励的设计包含即时奖励和任务完成奖励。
任务执行过程中的即时奖励为探索方向提供指导。即时奖励统一采用范围缩放法进行归一化,如式(2),将奖励映射到[-1,1],避免不同类型奖励差异过大。
这里的即时奖励主要有3 个,发现蓝方目标时给予正向奖励、无人机被击落时给予惩罚奖励,以及造成蓝方目标毁伤时给予正向奖励。
式中,rd、B,b(t)、wd分别为侦察奖励、蓝方总数量、t时刻以前共识别目标的数量和侦察奖励权重。
式中,ru、N、dn(t)、wu分别为无人机躲避奖励、红方无人机总数量、t 时刻第n 架无人机的损伤程度和无人机躲避奖励权重。
式中,ra、M、Omax、om(t)、wa分别为打击奖励、需要打击目标的总数量、目标最大毁伤点、t 时刻打击目标m的毁伤点以及打击奖励权重。
式中,rt、t、ts、tduration、wt分别为任务结束时间奖励、仿真当前时间、仿真开始时间、仿真持续时间和任务结束时间奖励权重。
任务成功完成后给予较大额度的奖励,保证智能体的行为向着主线任务完成的趋势靠近。
式中,r 为所有即时奖励与任务完成奖励之和,其中re1和re2分别表示侦察任务和打击任务完成时给予的奖励。
2.3 动作空间设计
动作空间的设计原则包含功能完备、高效性设计以及合法性设计。
本文设计了“指挥官模式”的智能体,通过该智能体下达命令使红方作战单元完成任务。现实中指挥官在任务分配时需综合考虑任务执行者、动作类型和作用对象等因素。为使上述智能体动作空间具备现实指挥官的全部能力,同时使决策具有更好的可解释性和表达复杂动作的能力,本文将动作输出表示为自然语言结构,输出设计采用主谓宾的形式,即执行者、动作类型和作用对象。这里执行者是红方无人机,动作类型分为侦察与打击,当动作为侦察时,作用对象为无人机所需侦察的经纬度和移动时的高度速度;当动作为打击时,作用对象为打击目标,以及无人机释放弹药所需到达的经纬度和投弹高度速度。其中,执行者和打击目标属于离散的动作指令,而位置如经纬高以及速度属于连续的动作指令。连续空间拟合难度大,过细的动作粒度通常是冗余无必要的,文献[9]表明离散化动作空间以解决连续控制问题是一种简单而强大的策略优化技术。因此,将连续的动作进行离散化,同时选择的离散化粒度需要平衡控制精度与解空间探索效率。
实战任务是在一系列作战规则约束下进行的。本文采用作战规则和深度强化学习相结合的决策方式。无人机在三维战场空间的运动轨迹是在深度强化学习和规则两者作用下生成。将三维经纬高空间转化为xyz 轴的三维空间,在研究中,深度强化学习决策无人机的动作包括经度、纬度、高度和速度大小,这些因素对作战效能起到关键影响,而具体无人机的运动轨迹通常使用运动规划技术实现,并结合自带的飞行控制器进行跟踪,这里运动规划采用5 次多项式曲线插值,使得实际运动的速度和加速度平滑连续,易于跟踪。飞控使用常见的设定三维位置点和速度的控制接口。其中,x 轴分量的运动轨迹设为式(8),方程组(9)利用路径点约束和最小二乘方法求解x 轴运动轨迹。

图1 多项式求解运动轨迹示意图Fig.1 Schematic diagram of polynomial solution for motion trajectory
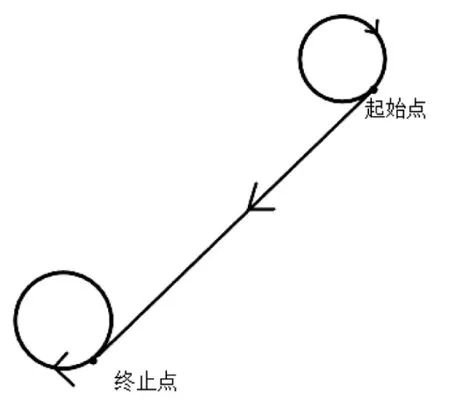
图2 运动轨迹xy 平面投影图Fig.2 Planar projection of motion trajectory xy
无人机运动轨迹描述:当无人机处于盘旋状态,接收到指挥官智能体的指令,首先在xy 平面继续顺时针盘旋,调整无人机朝向,计算起始位置与终点位置的盘旋圆在二维的公共切线,当无人机朝向与切线方向一致,无人机沿切线方向进入飞行状态,到达目标位置后以智能体给定的速度大小进行顺时针盘旋。当无人机正处于飞向某目标点的状态时接收到临机指令,无人机以当前速度转为盘旋状态,然后按照无人机处于盘旋状态的轨迹进行变化。
另外,有些规则由仿真平台交战设置。图3 中传感器开关状态由作战电磁管控模块负责,作战任务所需雷达一直处于开启状态。图4 设置红方对地目标确认为蓝方目标后,红方无人机才能开火。
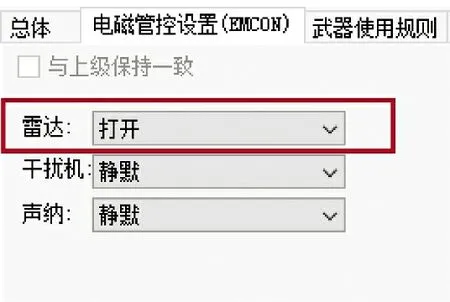
图3 传感器设置Fig.3 Setting of sensors
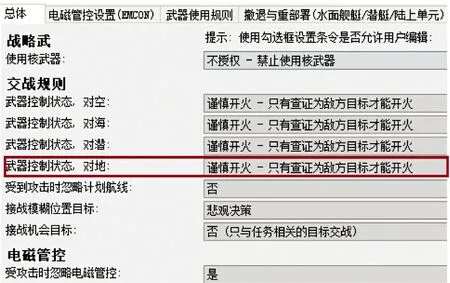
图4 开火规则Fig.4 Firing rules
2.4 策略网络架构
整体的策略网络结构如下页图5 所示。策略网络结构选用编码器-时序聚合- 注意力机制- 解码器结构。策略网络结构中各模块功能与整体工作流程如下:
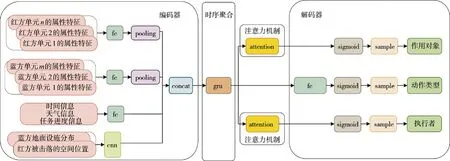
图5 策略网络Fig.5 Strategy network
1)编码器将状态值进行特征提取和降维转换。其中,作战单元序列特征通过全连接神经网络(FC)和池化层(pooling)来提取特征和除去冗余信息;全局一维信息如天气信息、任务进度等经过全连接神经网络进行特征提取;空间特征如威胁分布经过卷积神经网络(ANN)进行特征提取与选择。然后使用拼接操作(concat)得到一个高维特征表示,从而更好地学习与融合任务环境与实体等多元特征;
2)时序聚合是通过将上述融合的高级特征输入门控神经网络(GRU),挖掘长期依赖性,从而建模历史信息对当前作战任务的影响;
3)执行者和作用对象的获取需要使用注意力机制(attention)模块,动态地分配注意力,使网络注意力集中在重要性更高的信息上[10],从而选择性地关注那些在当前任务中更适合的无人机和当前更适合的打击目标等;
4)解码器将注意力机制的输出表示和时序聚合产生的特征表示转换回到动作空间。注意力机制的输出经过激活函数(sigmoid)和概率采样(sample)获取执行者(主语)和作用对象(宾语),时序聚合的输出经过全连接、激活函数和采样得到决策的动作类型(谓语)。
3 基于近端策略优化的求解方法
本次研究选用了深度强化学习中的近端策略优化算法。PPO 在2017 年由SCHULMAN J 等提出,是一种基于策略梯度的强化学习算法,旨在解决深度强化学习中的稳定性问题[11]。PPO 引入剪切系数可以确保策略更新不会过于剧烈,不会引起策略不稳定,可以更好地适应环境的变化,符合无人机集群由于行动前不清楚蓝方目标的位置和类型而需要频繁地调整策略。
值网络损失函数用于优化值网络估计值与真实累积奖励之间的误差。PPO 利用式(14)作为值网络损失函数计算梯度,更新值网络参数,优化值网络的评价能力。
基于近端策略优化算法的无人机集群执行侦察打击任务的决策算法,如算法1 所示。

算法1 无人机集群执行侦察打击任务的决策算法1)初始化新旧actor 网络参数θπ、θπold,critic 网络参数θQ 2)采样部分将状态信息输入到新actor 网络输出action,采样获取一个action,输入环境中获取r 与下一个状态s,以此循环存储episode 3)训练部分①从存储的样本中获取一个batchsize 大小的样本量将每个样本中的状态s 输入到critic 网络中输出v 值,计算优势函数如式(12)、式(13)②使用优势函数计算值网络损失如式(14),通过反向传播更新值网络参数θQ③计算当前策略与旧策略的比值如式(11)④计算策略网络损失如式(10),反向传播更新新actor网络参数θπ,从而更新旧actor 网络参数θπold,
4 仿真实验
4.1 实验场景参数设置
实验场景中对抗主体为红方无人机集群和蓝方地面设施。其中,红方共16 架无人机,蓝方有7种类型,共13 个地面设施。具体类型和数量如下页表2 所示。其中,无人机速度范围为0~300 km/h,调整高度范围为0~8 km。其中,雷达察打无人机的侦察范围为15 km,光电察打无人机的侦察范围为10 km,无人机最大攻击距离为5 km。蓝方SAM 地空导弹的最大攻击距离是10 km,复仇者防空导弹的最大攻击距离为10 km。

表2 对抗双方兵力情况Table 2 The forces situation of opposing sides
下页图6 是上帝视角下的作战双方兵力分布情况。双方作战的区域长约79 km,宽约88 km。区域内环境因素考虑了平均气温、降水量、云量和风力/海况。任务完成需要侦察到大于80%的蓝方目标数量,同时对特定目标跑道1、跑道2 和航空汽油油箱场站进行毁伤。

图6 侦察打击想定示意图(上帝视角)Fig.6 Schematic diagram of reconnaissance and strike scenarios(god perspective)
本次仿真基于ubuntu 系统完成了仿真推演和智能体训练。仿真基础条件设置:想定推演速度为1 s,即仿真推演时间与实际时间一致;每轮仿真训练时长上限为2 h;每轮训练以规定时间内红方完成任务或规定时间内未完成任务或达到仿真上限时间3 种情况结束;仿真每50 s 进行一步决策。网络超参数设置:单次采样样本量batch_size=1 024,策略熵损失系数entropy_coef=0.1,学习率lr=2e-4,剪切系数ε 采用原PPO 论文建议的数值0.2[11],优势函数gae 的时间步长gae_ length=128。具体的仿真的运行流程如图7 所示。
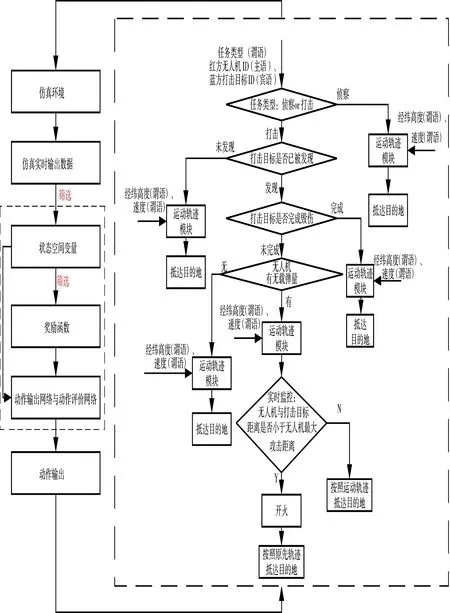
图7 仿真运行流程图Fig.7 Simulation running flow chart
首先从仿真环境加载预定义的想定场景,并从仿真环境中实时获取数据。筛选状态空间变量,构建奖励函数,优化强化学习模型的参数,使模型朝着红方累积奖励最大化的方向优化。模型包括一个用于输出动作的策略网络(动作输出网络)和一个用于评估状态值的价值网络(动作评价网络)。右虚线方框是智能体输出与作战规则结合的具体流程。方框中输入量为智能体输出的红方无人机ID(主语)、打击目标ID(宾语)、任务类型(谓语)、经纬高度(谓语)和速度(谓语)。中间过程是对主谓宾分配进行作战规则限制,其中,设置每个状态结束后即飞到目的地,在没有新的命令情况下,无人机进入原地盘旋状态等待。输出量是DRL 与作战规则结合的任务分配与运动规划。
4.2 仿真结果分析
实验从算法设计的合理性和作战任务指标两方面进行分析。曲线图的横坐标均是训练步数(learning step),纵坐标是相应的算法或任务监控指标。训练基于分布式架构,因此,算法类指标曲线图8~图10 呈现多曲线,表示不同训练容器生成的趋势;而作战任务指标呈现单曲线,是计算总体获取的平均值,如图11~图14。

图8 优势函数曲线Fig.8 Advantage function curve
4.2.1 算法设计合理性分析
图8 是优势函数曲线,可以看出曲线整体呈现逐渐上升的趋势,说明新策略比旧策略好。到训练后期,增加逐渐趋于缓慢,说明此时策略已经相对稳定。图9 中可以看出,策略损失网络随训练进行,逐渐维持在一个较小的范围内,说明策略在逐步优化并趋于稳定。图10 是值网络损失函数曲线,该曲线用于衡量值函数估计与真实累积奖励之间的误差。曲线呈现下降趋势,损失函数的值逐渐减小,说明值函数估计逐渐逼近真实累积奖励。
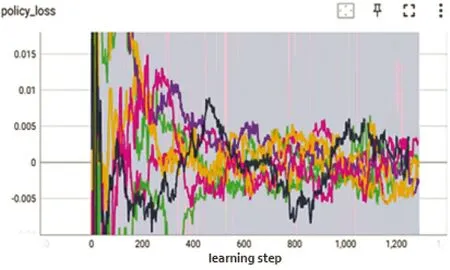
图9 策略损失函数曲线Fig.9 Strategy loss function curve
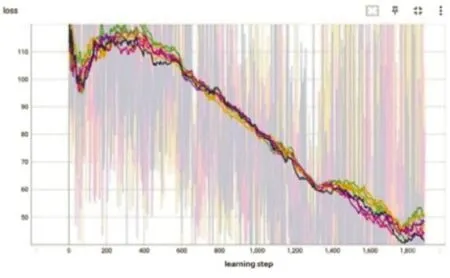
图10 值网络损失函数曲线Fig.10 Value network loss function curve
4.2.2 作战任务指标分析
从以下3 个指标的曲线变化情况可知,随着学习次数的持续增加,所训练模型在执行任务时的指标不断得到优化,最后保持稳定。
图11 是无人机集群执行侦察打击任务的总奖励曲线。总奖励整体呈现上升趋势,最后训练稳定收敛。
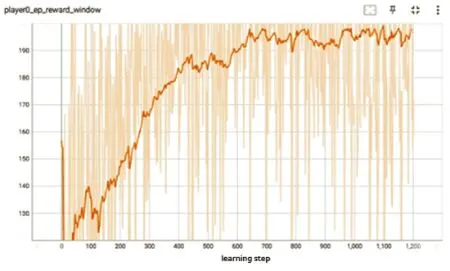
图11 总奖励函数曲线Fig.11 Total reward function curve
下页图12 是目标数量曲线。起初发现的目标数量大致为7,这是由于不具备反制行为的目标总数量为7,容易被侦察到,而剩余地面设施均有反制能力,无人机接近后易被击落,导致无人机不易侦察到目标。从曲线中可以看出随着训练的进行,侦察到的数量从7 增加到11 左右,说明无人机的侦察能力有所提升。
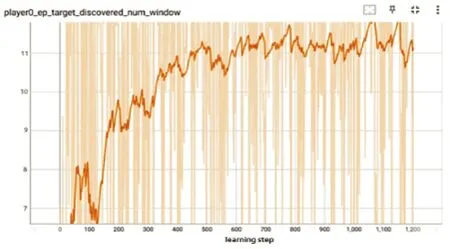
图12 目标数量曲线Fig.12 Target quantity curve
图13 是无人机损失数量曲线。曲线中无人机折损的初始数量为8,说明刚开始无人机面临突发的威胁不具备自主躲避火力攻击的能力。随着训练的进行,曲线呈现下降趋势达到3,说明无人机学到了快速侦察并撤离的策略,在尽快完成目标侦察后,通过调整速度、航向、高度等动作空间中关键动作立即撤离目标区域,体现了运动规划的智能性。
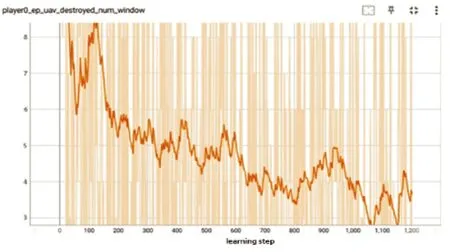
图13 无人机损失数量曲线Fig.13 Loss quantity curve of UAVs
图14 是目标毁伤分数。从曲线可以看出毁伤分数从160 上升到260。经过智能训练,在执行毁伤任务时,通过改变无人机打击时的速度高度航向,目标分配的合理性等关键影响因素,学习到了最大化毁伤的任务分配的智能性。
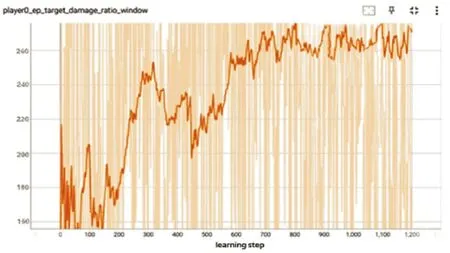
图14 目标毁伤分数Fig.14 Target damage scores
4.3 仿真结果验证
仿真训练设定训练步数learning step 每增加200,生成用于本地计算机执行的模型参数文本。仿真验证选用了learning step=1、1 000 和2 000 的训练模型,分别对三者仿真步长step=140。即仿真推演接近设定的作战结束时间2 h 进行了可视化界面展示,如图15~图17 所示。图中每个作战单元有对应血量显示,表现为单元附近的窄方块。

图15 Learning step=1Fig.15 Learning step=1
图15 中红方无人机侦察到蓝方6 个目标,重度毁伤了跑道1(血量颜色为红色),此时红方剩余3 架无人机;图16 中侦察到蓝方7 个目标,重度毁伤了跑道1,轻度毁伤了跑道2(血量颜色为黄色),无人机剩余9 架;图17 中红方无人机侦察到蓝方11 个目标,一架无人机正对蓝方航空汽油油箱场站进行完全摧毁,重度毁伤了跑道1,中度毁伤了跑道2(血量颜色为橙色),自身剩余无人机10 架。
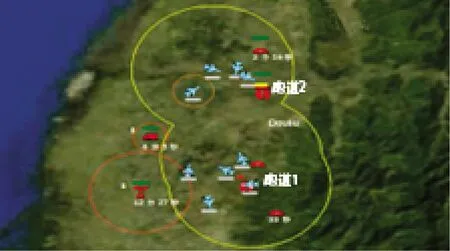
图16 Learning step=1 000Fig.16 Learning step=1 000

图17 Learning step=2 000Fig.17 Learning step=2 000
通过上述可视化界面可知,蓝方兵力部署具有对抗性。初始阶段的训练模型,红方无人机侦察蓝方目标数量少,且自身损毁数量多;后期稳定阶段的训练模型,红方无人机不但可以躲避蓝方的防空火力,而且可以侦察到较多数量的目标,并对目标的毁伤也大幅提高。由此可见,基于近端策略优化算法和规则的决策模型在无人机集群侦察场景中具有一定有效性。
5 结论
本文针对复杂不确定条件下构建的无人机集群典型侦察打击任务想定,通过设计状态空间、动作空间、奖励函数和策略网络,搭建了基于PPO 的深度强化学习框架。通过仿真实验结果表明,实现了察打任务的作战效能最优,体现了无人机集群运动规划和任务分配的智能性。该方法可为复杂不确定条件下大规模无人集群决策提供技术借鉴,同时该方法可以进一步丰富和接入更专业的武器装备参数和数据,对实战化环境中的无人机集群察打指挥决策具有重要意义。
