基于机器学习算法的甘肃省草原地上生物量
2024-03-28刘兴明姜佳昌俞慧云吴丹丹杜笑村王红霞贾晶晶杨红梅
李 霞,刘兴明,孙 斌,姜佳昌,俞慧云,吴丹丹,杜笑村,王红霞,贾晶晶,杨红梅
(甘肃省草原技术推广总站, 甘肃 兰州 730010)
草原植被长势监测是草原管理的基础性工作,是构建新时期草原监测评价体系,践行“山水林田湖草”一个生命共同体理念的具体体现,草原地上生物量是草原资源合理利用和载畜平衡监测的重要依据,也是草原退化、草原生态系统健康评价、生态系统服务功能评价和碳汇研究的关键指标[1-3]。野外实测数据与遥感数据相结合是大范围草原生物量估算的常规方法[4-5],基于地面实测的草原地上生物量数据,选取单个遥感因子(如植被指数)与草原地上生物量建立回归模型,反演研究区的草原地上生物量。这类方法估算模型形式简单,参数也易于获取,但只有遴选出最优植被指数,建立高精度反演模型,才能进行较为准确地估测[3,6-7]。当区域或样本发生变化时,就需要重新遴选最优参数与最优统计模型,模型的外推性与扩展性较差[8-10]。
近年来机器学习模型在生态等多个领域得到广泛应用,其自动检索和解释数据的方法,灵活性高,可满足各种训练要求,在估算草原地上生物量方面也有一定的应用,已有研究基于机器学习模型分别对三江源地区、青藏高原、内蒙古锡林郭勒盟和黄土高原草原地上生物量进行了估算,结果表明机器学习模型在草原地上生物量估算方面表现良好[10-15]。
在此背景下,充分利用卫星遥感数据与气象数据,构建高精度的草原地上生物量模型,创新草原监测的方式方法已成为草原监测工作的必然趋势[16]。本研究基于甘肃省2005-2018 年草原地上生物量实测数据以及MODIS 数据和气象数据等变量,探索适宜于甘肃省草原地上生物量高精度反演的机器学习算法模型,对实现甘肃省草原地上生物量的高精度监测具有重要的意义。
1 研究区概况与数据获取
1.1 研究区概况
甘肃省(92°13′~108°46′ E,32°11′~42°57′ N)拥有丰富的草原资源,草原面积1 430.71 万hm2(第三次全国土地调查),是耕地面积的2.75 倍,是林地面积的1.80 倍。草原作为甘肃省乃至西北地区重要的生态屏障,具有涵养水源、防风固沙、绿化环境等一系列重要作用。
1.2 数据获取
1.2.1 草原生物量地面调查
2005 年以来甘肃省草原技术推广总站组织在各县(市)连续开展了天然草原野外调查工作,具体监测方案如下:
地面样地布设以草原类型为基础,根据不同草原类型面积大小,选择样地,样地面积大于0.5 hm2,样地内布设3~9 个样方,样方间距离不小于250 m,草原样方大小为1 m2,灌木及高大草本类植物草原样方大小为100 m2。调查7 月中旬至8 月上旬植物生长旺季的产草量、盖度、频度、高度。
2005-2018 年共调查样方12 141 个,样地2 636个,样地空间分布图如图1 所示。删除不完整或经纬度有误的记录,最终保留样本11 408 个。
1.2.2 遥感数据获取及处理
覆盖甘肃省的MODIS 遥感数据为美国国家宇航局(NASA) 的MODIS MOD13Q1 产品集,依据野外采样调查的时间,下载2005-2018 年影像,提取与地面采样时间相应的MODIS 各项数据。
用于建模的参数包括Red、NIR、Blue、MIR 波段反射率,以及基于已有研究成果利用该产品中的波段反射率(Red、NIR)数据构建的4 种与草原生物量密切相关的植被指数(表1)。
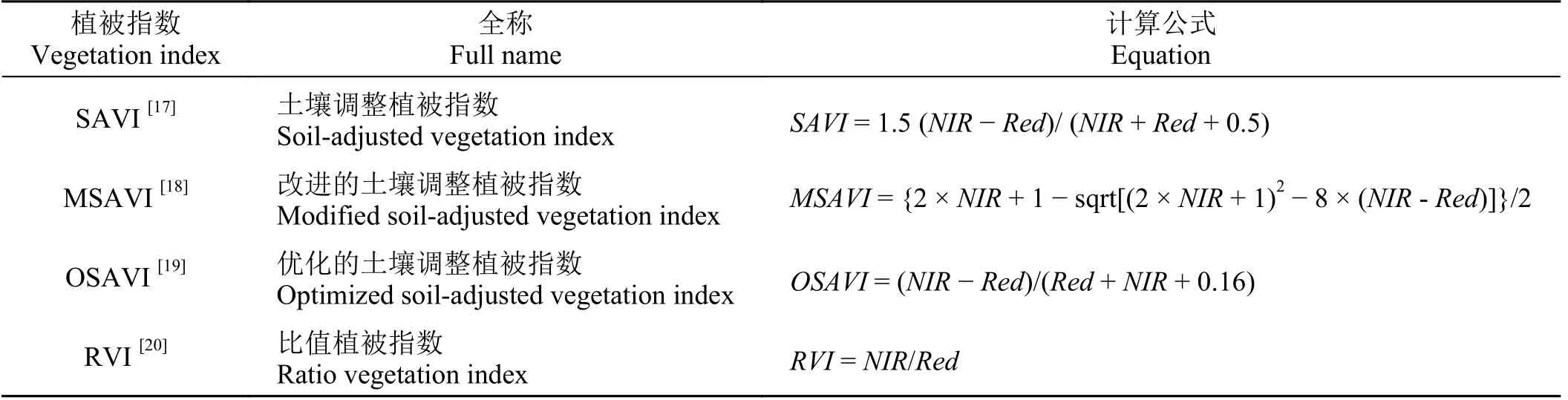
表1 MODIS 植被指数计算公式Table 1 Vegetation indices used in this study
1.2.3 气象数据处理
气象数据采用国家地球系统科学数据中心2000-2018 年逐月气象插值数据集,包括空间分辨率为0.008 333 3° (约1 km)的12 个月逐月平均气温(℃)、最低气温 (℃)、最高气温(℃)和降水量 (mm)数据[21]。
2 研究方法
2.1 模型构建
基于甘肃省2005-2018 年实测草原地上生物量数据以及相应时间的Red、NIR、Blue、MIR 波段反射率以及NDVI、EVI、SAVI、MSAVI、OSAVI、RVI 植被指数,各月平均气温、各月最低气温、各月最高气温、年均温度、年均最高温度、年均最低温度和各月累计降水量、年降水量63 个变量,借助R 软件及caret 包构建了贝叶斯规整神经网络(Bayesian regularized neural networks, brnn)、径向基函数核支持向量机 (support vector machines with radial basis function kernel,svmRadialSigma)、极端的梯度增加(extreme gradient boosting,xgbDART)、分位数随机森林(quantile random forest,qrf)、RRF 规整随机森林(regularized random forest,RRFglobal)、基于random Forest 和RRF 的规整随机森林(regularized random forest,RRF)、ranger 随机森林(random forest,ranger)、Rborist 随机森林(random forest,Rborist)、randomForest随机森林(random forest,rf)、并行运算随机森林(parallel random forest,parRF)、k 最近邻算法(k-Nearest neighbors,kknn) 的甘肃省草原地上生物量反演模型,各个方法实现过程见caret 包的说明文档(https://topepo.github.io/caret/index.html)。
2.2 变量筛选
本研究使用R 包中前向特征选择方法(the forward feature selection,ffs)对63 个变量进行筛选,该方法是依次在当前集合中加入一个集合中没有的属性,然后用交叉验证等方法对新的集合进行评估,找出评估结果最佳的属性加入当前集合。不断重复上面的步骤,直到加入任何新的属性都不能提高评估结果算法即停止,最终得到最优特征变量组合。此算法可能找到局部最优的属性集,但不一定是全局最优。
2.3 全变量模型与筛选变量模型精度评价
采用10 折交叉验证的方法对模型精度进行评估。选择平均误差(mean absolute error,MAE)、模型的决定系数(determination coefficient,R2)和均方根误差(root mean square error,RMSE) 3 个评价指标,每次使用90%的数据进行建模,剩余10%的数据进行验证,重复10 次,将10 次验证结果的均值作为最终验证结果。
2.4 草原地上生物量变化趋势分析
利用最优模型反演得到甘肃省2000-2018 年逐年草原地上生物量数据集,采用Theil-Sen median趋势分析、Mann-Kendall 非参数检验法研究甘肃省草原生物量时间变化趋势和特征[22]。
3 结果与分析
3.1 模型优选
3.1.1 模型评价及初选

图2 基于机器学习和全变量的甘肃省草原地上生物量反演模型精度对比Figure 2 Accuracy comparisons for aboveground biomass inversion models based on machine learning using all variables in Gansu Province
3.1.2 筛选最优建模变量
基于机器学习的全变量模型虽然能够较好地反映甘肃省天然草原地上生物量变化情况,但首先基于全变量的模型数据量太大不便于应用,其次虽然保留所有的变量能保证预测模型一定的鲁棒性,但变量冗余会降低模型的运行速度和预测精度,因此有必要对变量进行筛选[23]。本研究采用基于前向特征选择算法(ffs)对变量进行筛选。通过该方法的分析,当在63 个变量中选取17 个变量时,模型的决定系数可达到0.757 以上,并且继续增加变量,拟合结果的决定系数不再增加,因此选取了17 个变量作为最终筛选出的变量(图3)。
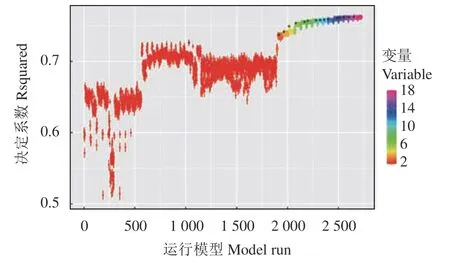
图3 基于 ffs 筛选后的模型精度Figure 3 Model accuracy based on forward feature selection
最终筛选出的17 个变量:近红外(NIR),短波红外(MIR),1 月、2 月、3 月、5 月、7 月、8 月、10 月、11 月及全年降水量、1 月和11 月最高温、1 月和2 月最低温、4 月和5 月均温。
3.1.3 最优模型选取
基于上述17 个变量构建的变量集,重新拟合的11 个机器学习模型整体精度较全变量模型均有不同程度的提高,由此可见,变量筛选可以有效地降低冗余变量对模型精度的影响,提高模型模拟精度。在11 种机器学习模型中,随机森林类机器学习模型的精度依旧较高(表2),其中Rborist 模型的R2最高,为0.758,RMSE 最低,为541.90 kg·hm-2。其次是RRF、ranger、RRFglobal、RF、parRF、qrf、kknn,决定系数均在0.72 以上,其余3 种方法精度较低。因此最终选取随机森林Rborist 模型作为甘肃省草原地上生物量最优模型。
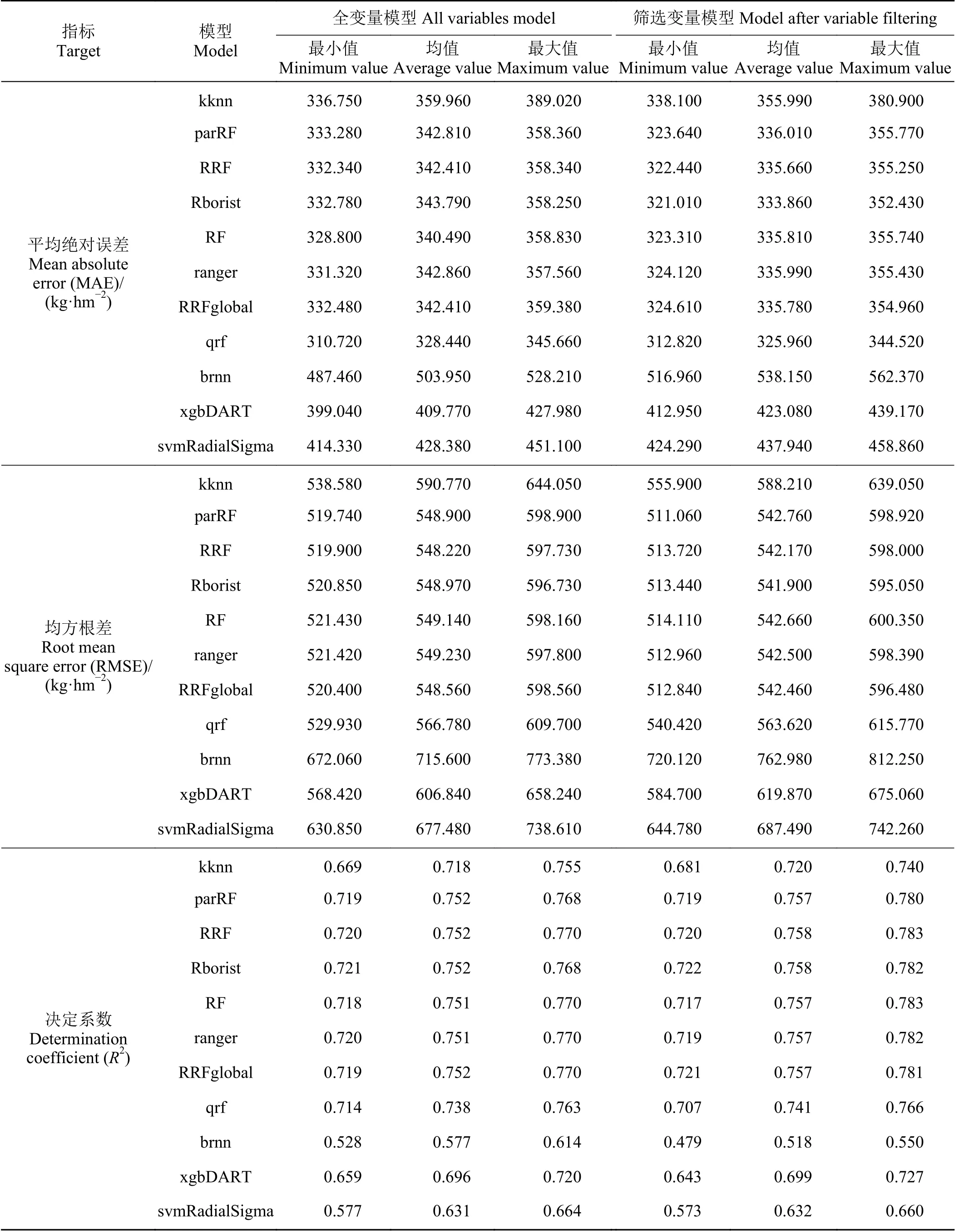
表2 筛选变量前后的模型反演情况Table 2 Model accuracies using all variables and after variable screening
对比精度最高的前8 种模型可以看出,各模型模拟结果与实测值一致性较高(图4),7 种随机森林类模型模拟值与实测值绝大多数点分布在1 ꞉ 1 线附近。同时,实测值的绝大多数点分布在0~3 000 kg·hm-2。对生物量低值区的模拟效果要好于高值区。
3.2 甘肃省草原地上生物量变化趋势分析
3.2.1 甘肃省草原地上生物量空间分布
基于最优机器学习模型(Rborist) 和筛选出的17 个变量,通过反演得到甘肃省2000-2018 年逐年草原地上生物量数据集。甘肃省草原地上生物量均值介于828.21~1 118.71 kg·hm-2(图5)。就空间分布而言,甘肃省草原地上生物量表现出明显的地域差异,将甘肃省从西到东划分为河西地区(包括酒泉市、嘉峪关市、张掖市、金昌市和武威市)、陇中地区(包括白银市、定西市、兰州市、临夏回族自治州和定西市)、甘南藏族自治州、陇南地区(包括平凉市、陇南市和天水市)以及庆阳市,高值区主要分布在甘南州、陇南地区和庆阳市以及祁连山一带。低值区主要分布在河西地区。就不同地区而言,陇南和甘南地区草原地上生物量最高,其次是庆阳市,河西地区草原地上生物量最低。

图5 2000-2018 年甘肃省草原地上生物量均值分布图Figure 5 Distribution of mean aboveground biomass of grassland in Gansu Province from 2000 to 2018
3.2.2 甘肃省草原地上生物量年际变化分析
将试样加工成如图1所示的薄片,再用水砂纸将其打磨至20#,并经过超声波清洗、用乙醇和蒸馏水清洗吹干,从而保证试样表面有统一的粗糙度与整洁度。实验前先称取重量,再将试样两端通过夹持装置固定在试验系统中,进行一定温度和硫酸浓度下的浸泡实验。每组试样腐蚀12h后清洗称重,切片封存,以便进行进一步的SEM和EDS检测。
2000-2018 年,甘肃省各地区草原地上生物量近20 年来整体呈逐年增加趋势,年均增加幅度约为8.13 kg·hm-2(图6)。由此可见,2005 年以来甘肃省天然草原长势整体呈现向好的趋势。其中陇南和陇东地区增加速率最高,年际增幅为41.11 和36.20 kg·hm-2,其次是甘南地区19.54 kg·hm-2,河西地区年际增幅最低,仅为0.72 kg·hm-2。就各市(州)而言,2000-2018 年草原地上生物量呈减少趋势的是白银市、嘉峪关市、酒泉市和武威市,其余各市(州) 草原地上生物量均呈增加趋势,陇南和天水市年际增幅最高。
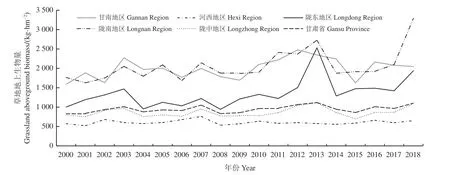
图6 2000-2018 年甘肃省不同地区草原地上生物量年际变化Figure 6 Interannual changes in aboveground biomass in different regions of Gansu Province from 2000 to 2018
就不同草原类型而言,19 年间低地草甸、温性荒漠草原、高寒草甸草原、温性草原化荒漠和温性荒漠的地上生物量呈减少趋势,其余草原类型的地上生物量均呈增加趋势(图7),其中暖性草丛、暖性灌草丛和温性草甸草原的地上生物量增加幅度最高。
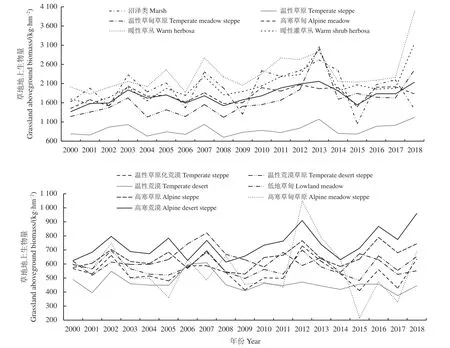
图7 甘肃省不同草原类型2010-2018 年地上生物量统计Figure 7 Aboveground biomass statistics of different grassland types in Gansu Province from 2010 to 2018
3.2.3 甘肃省草原地上生物量年际变化特征分析
基于Theil-Sen median 趋势分析和Mann-Kendall检验的2000-2018 年甘肃省草原地上生物量的时空变化趋势分析结果表明(图8),甘肃省47.41%的草原呈恢复趋势,26.00%的草原保持稳定,而26.59%的草原呈不同程度的恶化趋势,草原恢复区域主要分布在甘南、陇东和陇南地区,恶化区域主要分布在河西地区的北部和东部区域。
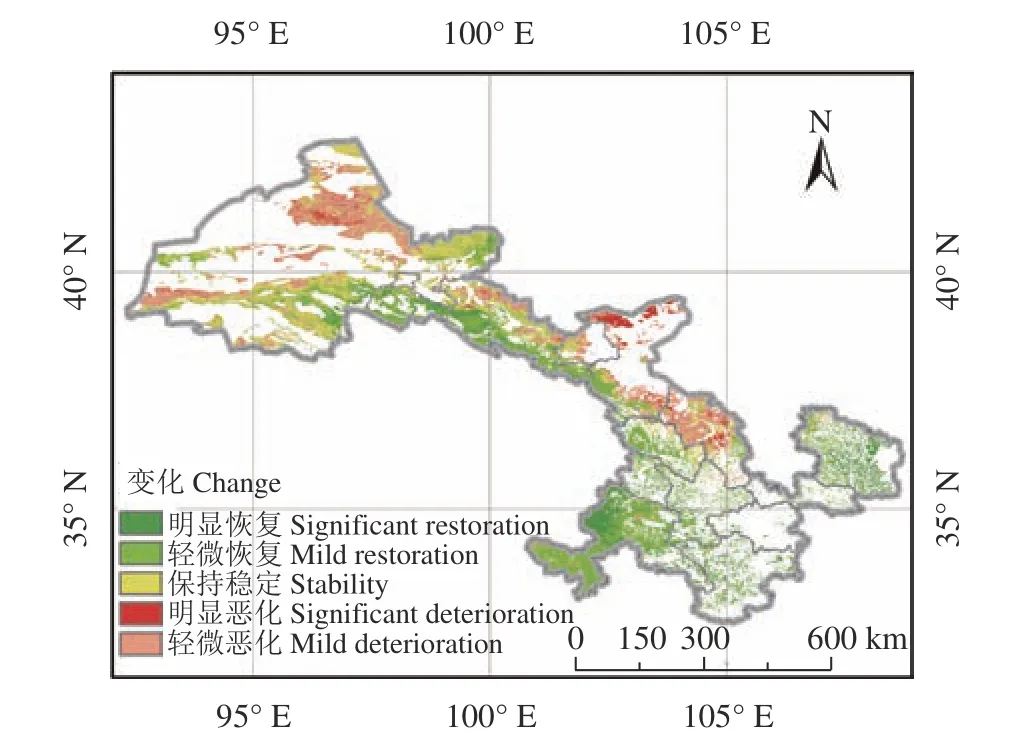
图8 2000-2018 年甘肃省草原地上生物量变化特征Figure 8 Characteristics of aboveground biomass change in Gansu Province from 2000 to 2018
就草原类型而言,温性荒漠类、高寒草甸草原类、温性草原化荒漠类、温性荒漠草原类呈恶化趋势的比例较高,其中温性荒漠类轻微恶化44.55%、明显恶化7.22%;高寒草甸草原类轻微恶化94.51%、明显恶化4.15%;温性草原化荒漠类轻微恶化56.58%、明显恶化2.28%;温性荒漠草原类轻微恶化35.82%、明显恶化5.46%。而沼泽类、暖性草丛类、暖性灌草丛类、温性草甸草原类呈恢复趋势的比例较高,其中沼泽类轻微恢复94.75%、明显恢复1.50%;暖性草丛类轻微恢复22.34%、明显恢复77.66%;暖性灌草丛类轻微恢复23.23%、明显恢复76.67%;温性草甸草原类轻微恢复30.16%、明显恢复69.12%。
4 讨论
4.1 随机森林算法在草原地上生物量估算的适用性
本研究通过比对11 种不同的机器学习模型,在未进行变量筛选时,随机森林类机器学习模型的精度较高,其中RRF 模型的拟合度最高,R2为0.752 2。基于前向特征选择算法进行变量筛选后,有效地提升了模型的运算速度,随机森林模型的精度依旧较高,其中Rborist 模型的拟合度最高,R2为0.758。随机森林算法可以快速处理海量数据,简便易用,具有高效、高包容性、高稳定性等优点,且对于预测变量与响应变量之间的分布及其关系、变量数量和类型都没有严格的要求,对数据容错度较高,对训练样本数据具有较好的拟合性,适用于样本量大的数据挖掘工作[24-25]。但随机森林模型虽然不会出现过度拟合[26],但高值区模拟效果还是没有低值区好,可能是由于多光谱传感器的过饱和现象造成的,这是使用光学传感器估算草原地上生物量的一个常见问题[27-28]。总体来说随机森林算法在草原地上生物量的估算具有较好的准确性和可行性,与郭超凡等[5]、邢晓语等[10]、Zeng 等[14]和Wang 等[15]的不同模型在草原地上生物量的模拟效果对比研究结果一致。
4.2 基于多变量融合数据的大尺度生物量建模
本研究在变量的选择中主要考虑数据的可获得性,最终选择适用于大尺度研究的250 m 中分辨率的MODIS 遥感影像数据,2005-2018 年度的月气温、月降水、年平均气温、年降水数据,以及2005 以来甘肃省草原技术推广总站开展天然草原野外调查工作积累的草原生物量地面监测数据。
本研究相较仅使用遥感影像数据的黄土高原区域草原地上生物量随机森林模型[15]的精度高,较使用遥感影像数据的青海省海晏县境内小尺度随机森林模型精度[5]也略高。较使用经过野外验证的MODIS 植被指数数据、地形数据和气象数据建立的青藏高寒草原的地上生物量模型[29]精度略低,较使用遥感影像的小尺度如锡林郭勒盟的地上生物量反演模型[10]略差。说明随机森林的估算方法在不同研究尺度、不同数据集及不同特征选择的差异还是较大。甘肃省草原资源丰富,区划复杂,长时间尺度的地面调查数据与气象参数的加入,可以有效地提高模型的精度,但模型精度低于小尺度建模的精度,可能存在的原因主要是草原类型多样且不同草原类的生物量差异较大,样点分布不均匀等因素导致的。接下来需要探索针对不同草原类型分别建立随机森林算法的草原地上生物量估算模型,并探索人类活动影响的合理量化方式,将人类活动的影响因素有效地结合到模型中,充分发挥随机森林算法的优势,通过各个方面参数的增加,尽可能更好地反映草原地上生物量时空变化规律,以期提高大尺度、草原类型多样区域的草原地上生物量的估算精度[10]。
5 结论
本研究结合地面监测数据、遥感数据、气象数据,通过筛选最优建模变量和最优机器学习模型,将地面监测和遥感数据、气象数据、机器学习算法有力的结合起来,克服了基于单个遥感因子的常规估算模型变量单一、精度低等缺点,构建出适合甘肃省草原地上生物量监测的高精度反演模型,具有较高的应用价值。
主要结论如下:
1)基于机器学习的草原地上生物量模型分析结果表明,随机森林类机器学习模型的精度较高,Rborist 随机森林模型精度最高,R2为0.758,RMSE为541.90 kg·hm-2。
2)甘肃省草原地上生物量均值介于828.21~1 118.71 kg·hm-2,近20 年来整体呈逐年增加趋势,年均增加幅度约为8.128 kg·hm-2。
3)甘肃省47.41% 的草原呈恢复趋势,26.00%的草原保持稳定,而26.59%的草原呈不同程度的恶化趋势。高寒草甸草原、温性草原化荒漠、温性荒漠、温性荒漠草原呈恶化趋势的比例较高,而暖性草丛、暖性灌草丛、沼泽、温性草甸草原呈恢复趋势的比例较高。
