基于锚框自适应和多尺度增强的SAR舰船检测
2024-03-27邵子康张晓玲张天文曾天娇
邵子康, 张晓玲,*, 张天文, 曾天娇
(1. 电子科技大学信息与通信工程学院, 四川 成都 611731; 2. 电子科技大学航空航天学院, 四川 成都 611731)
0 引 言
合成孔径雷达(synthetic aperture radar, SAR)是一种先进的地球观测遥感工具[1]。相比于光学传感器,SAR具有全天时、全天候工作的能力。因此,SAR被广泛应用于农业管理、海洋监视等领域。海洋舰船检测作为一项基本海洋监视任务,在多个领域都具有广泛的应用[2]。在民用领域,SAR舰船检测在渔业管理、港口调度等方向发挥着重要作用。此外,SAR舰船检测对国防安全、边境管理等具有重要意义。因此,SAR舰船检测受到了学者们的广泛关注[3]。
传统SAR舰船检测算法通常基于专家经验来分析SAR图像中海面舰船的特点,采用手工方式定义舰船特征,最后基于所定义的特征在SAR图像中搜索舰船[4]。常见的传统SAR舰船检测算法包括基于恒虚警率的算法[5]、基于极化分解的算法[6]、基于变换域的算法[7],以及基于视觉显著性的算法[8]。这些方法依赖于手工特征,在面对复杂的海洋环境时,存在泛化能力较差、对复杂场景适应性不强等问题[9]。
近年来,基于深度学习的SAR舰船检测方法因其具有对复杂场景适应能力强、泛化能力优秀等优点,受到了学者们的广泛关注[10-14]。文献[10]基于YOLO(you only look once)模型[11],实现了无锚框SAR舰船检测。文献[12]基于RetinaNet模型[13],引入分离卷积和空间注意力机制提高检测精度。文献[14]基于RetinaNet模型,提出了一种使用旋转检测框的SAR舰船检测模型。以上方法均未能实现锚框自适应学习,这可能导致锚框无法适应多形态舰船目标,从而可能导致检测精度下降。
因此,本文提出了一种基于自适应锚框和多尺度增强网络(adaptive anchor multi-scale enhancement network, AA-MSE-Net)的SAR舰船检测方法,该方法的主要贡献如下:
(1) 引入了自适应锚框机制,来生成适应目标形态的高质量锚框,增强了舰船形态描述能力;
(2) 提出了多尺度增强特征金字塔网络(multi-scale enhancement feature pyramid network, MSE-FPN)来融合增强多尺度特征,增强了多尺度描述能力;
(3) 引入了变形卷积(deformable convolution, D-Conv)来提取舰船形变特征,进一步提高检测精度。
1 方法原理
AA-MSE-Net的结构如图1所示,其由骨干网络、特征金字塔、区域建议网络(region proposal network, RPN)和检测头构成。首先由骨干网络提取输入SAR图像的多尺度特征图,然后在特征金字塔中进行融合增强,接着将融合增强的特征图输入RPN和感兴趣区域对齐(region of interest alignment, ROIAlign)模块提取特征子集。ROIAlign可将RPN生成的不同尺度的候选框映射为大小统一的候选框[15],最后将特征子集输入检测头中,以获取SAR舰船检测结果。图1中红色字体表示AA-MSE-Net的各项改进。

图1 AA-MSE-Net结构图Fig.1 Structure of AA-MSE-Net
1.1 自适应锚框
大多数目标检测模型,例如Faster区域总卷积神经网络(region convolutional neural network, RCNN)[16]、YOLO[11]以及Cascade RCNN[17]等模型均基于锚框实现目标检测。锚框是一组人工设计的矩形框,具有固定尺寸和长宽比,作为分类和回归的基准[18]。然而,如图2所示,舰船长宽比差距较大,使用人工设计的固定长宽比锚框可能与舰船实际形态有较大偏差,无法准确预测舰船形状[19]。

图2 不同舰船长宽比Fig.2 Different ship’s aspect ratio
因此,受文献[20]启发,在RPN中引入自适应锚框机制,以在RPN中生成高质量的位置自适应和形状自适应锚框。锚框自适应生成网络的结构图如图3所示。
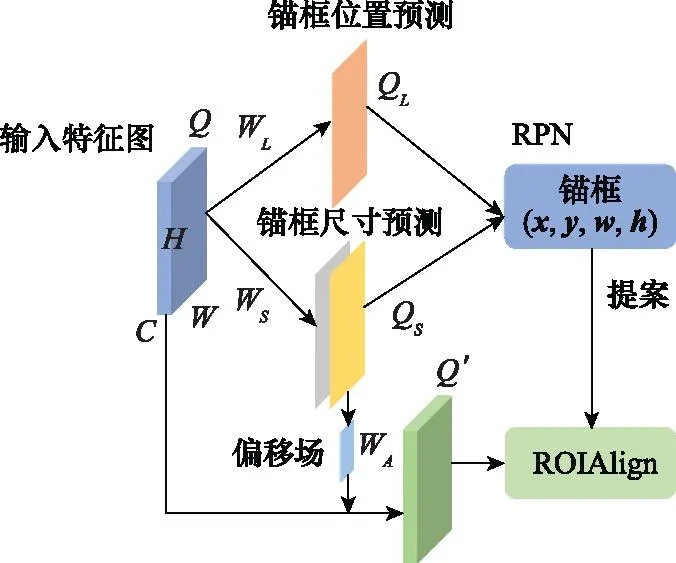
图3 自适应锚框生成网络结构图Fig.3 Structure diagram of adaptive anchor generator network
锚框自适应生成网络含有两个并行的分支,分别用于预测锚框尺寸和锚框位置。对于大小为H×W×C的输入特征图Q,首先,使用一个1×1卷积层(记为CL)预测锚框位置,并使用Sigmoid函数激活:
CL(Q)=WL·Q
(1)
QL=Sigmoid(CL(Q))
(2)
式中:WL为1×1卷积层CL的权重系数。Sigmoid激活函数定义如下:
(3)
1×1卷积层CL和激活函数Sigmoid输出大小为H×W×1的特征图QL。QL上的每个位置的值表示锚框产生在当前位置的概率。设位置阈值为εL,对于QL上的任意位置(x,y),当QL(x,y)>εL时,网络在该位置生成锚框,否则不生成。εL设置过高会导致生成锚框过少,进而导致目标漏检。εL设置过低会导致生成锚框过多,干扰检测精度。因此,根据文献[20]和文献[21],将位置阈值εL设置为0.01。由于含舰船目标位置仅占SAR图像中的一小部分,使用焦点损失[13]作为位置预测分支的损失函数,以避免产生大量负样本,干扰检测精度,即:
lossFL(pt)=-at(1-pt)γlog2pt
(4)
(5)
式中:y表示真值,y=1表示正例,否则为负例;p表示预测概率,取值范围为[0, 1];at表示加权因子,设置为经验值0.25。
接着,如图3所示,另使用一个1×1卷积层(记为CS)预测锚框尺寸。该过程可描述为
CS(Q)=WS·Q
(6)
QS=CS(Q)
(7)
式中:WS为1×1卷积层CS的权重系数。
CS输出大小为H×W×2的特征图QS。输出特征图通道数设置为2表示分别预测锚框宽度w和锚框高度h。因此,QS上的每个位置的值均表示当前位置锚框的宽度和高度。考虑到锚框形状预测分支对锚框的空间位置较为敏感,使用交并比(intersection over union, IOU)损失[22]作为该预测分支的损失函数。IOU定义为真值框和预测锚框的交集,与真值框和预测锚框的并集之比,即有
(8)
式中:G表示真值框;P表示预测锚框。
根据文献[22],IOU损失定义如下:
(9)
最后,将QL和QS结合得到自适应锚框。此外,考虑到尺度较大锚框应对特征图较大区域编码,尺度较小锚框则对应特征图较小区域[20],添加了特征图偏移场,使得不同大小的锚框与所对应的特征图区域相匹配。该过程可描述为
(10)
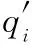
综上,通过基于自适应锚框生成网络,产生了基于舰船实际形态的自适应锚框,随后通过ROIAlign将其映射至匹配转换后的特征图,以提取其对应的特征区域,并用于后续检测头。
1.2 多尺度增强金字塔
如图4所示,由于卫星拍摄视角不同、舰船自身尺寸不同、雷达观测构型不同、系统参数和成像分辨率不同等多方面原因,SAR图像中舰船呈现出多尺度的特点[23]。星载SAR图像中的SAR舰船,往往具有尺度较小的特点[24]。相对地,机载SAR图像中的舰船往往尺度更大。不同种类的船只本身尺度差异也很大,渔船、货船具有较小的尺度。军舰、货轮具有较大的尺度。舰船间较大的尺度差异给舰船检测带来阻碍[25]。

图4 不同舰船尺度Fig.4 Ship with different scales
先前已有一些对多尺度SAR目标检测的研究,文献[26]提出了一种改进的YOLOX网络,以改善多尺度检测精度。文献[27]使用多个跨尺度连接的特征层增强尺度信息交互。文献[28]利用密集连接感受野模块增强多尺度特征。本文从特征融合的角度出发,为了增强多尺度特征,提高网络多尺度描述能力,设计了MSE-FPN。
图5展示了MSE-FPN的网络结构。由图5所示,MSE-FPN主要包含两个部分:路径增强和空间融合。路径增强的核心在于增加了一条自底而上的路径聚合支路,以补充特征金字塔中高层空间位置缺失的信息。大多数金字塔网络使用自顶而下的路径,将高层语义信息传递到低层。然而,低层空间信息未能充分融合,易导致检测框位置的偏差[29]。因此,低层空间信息对检测精度的提高具有重要的意义。如图5所示,为了增强低层空间信息的向上融合,MSE-FPN增加了一条自底而上的路径聚合支路。
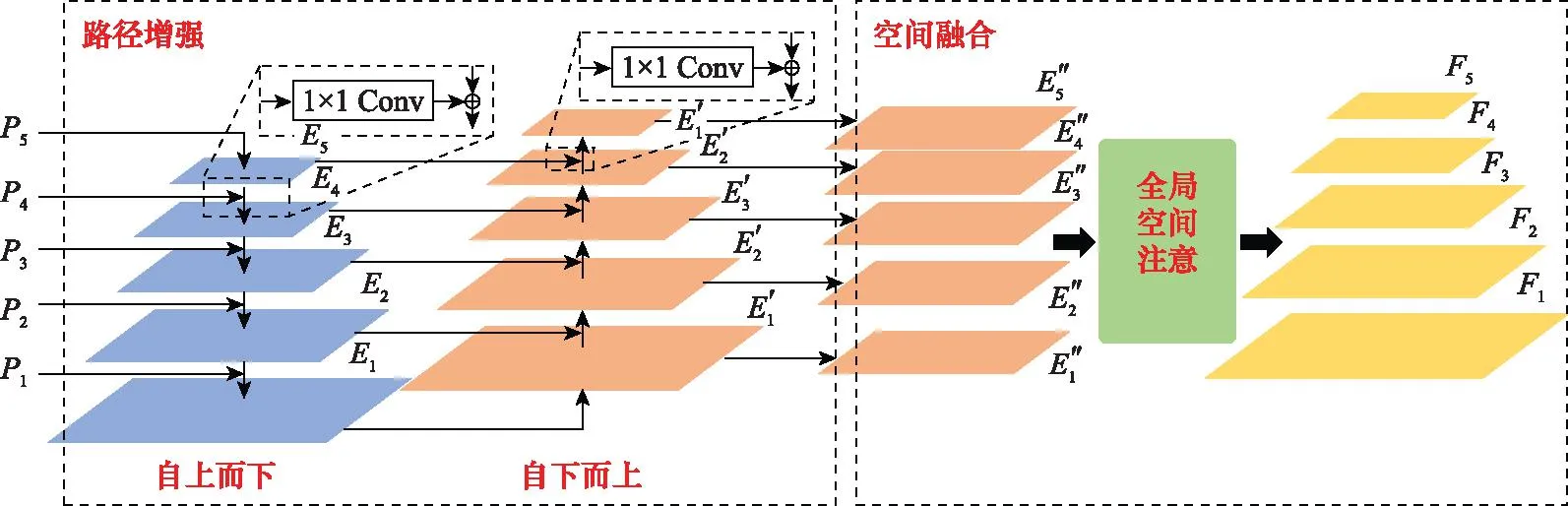
图5 MSE-FPN结构图Fig.5 Structure of MSE-FPN
此外,为了平衡来自多个尺度的信息特征,MSE-FPN还加入了空间融合模块[30],将多尺度信息融合增强,如图5所示。首先,路径增强后的特征图E″被整形为大小一致的特征图,为了使融合效果更好,选择整形后大小与E3一致[31]。接着,通过全局注意力增强模块建立空间自注意,减少因融合带来的信息干扰。全局注意力增强模块可描述为
(11)

1.3 基于可变形卷积的骨干网络
如图6(a)和图6(b)所示,使用标准3×3卷积对形态各异的舰船提取特征存在局限,无法对船的形状信息建模,不利于后续网络对舰船形状的预测。因此,受文献[32]的启发,在骨干网络中引入了可变形卷积,在特征提取阶段对舰船的形状信息建模并融合至多尺度特征图中,以便后续处理。图6(c)和图6(d)展示了基于可变形卷积的特征提取,可以自适应地拟合舰船形状,并避免背景干扰。

图6 标准卷积和可变形卷积示意图Fig.6 Schematic diagram of standard convolution and deformable convolution
图7展示了基于可变形卷积的骨干网络结构。骨干网络基于经典的深度残差网络-50(Residual network-50, ResNet-50)[33],将其卷积层均替换为可变形卷积层,并在骨干网络的输出端加入1×1大小的可变形卷积层。可变形卷积增强了骨干网络的特征提取能力,使其能自适应提取舰船形变特征,以提高检测精度。

图7 可变形卷积的骨干网络结构图Fig.7 Structure of deformable convolution backbone network
基于可变形卷积的骨干网络核心是可变形卷积,图8展示了可变形卷积的基本结构。如图8所示,记输入特征图为X,大小为W×H×C,首先使用3×3卷积层学习每个卷积区域的N个位置偏移量(N等于输入特征图中的元素数)。由于每个位置偏移由x方向偏移和y方向偏移构成,因此输出特征图大小为W×H×2N。然后,将学习得到的卷积核偏移量Δpn作用于原始卷积区域,并通过卷积运算得到每个位置的输出。对输入卷积层的所有位置执行上述操作,即可获得可变形卷积的输出X′。该过程可描述为
图8 可变形卷积结构图Fig.8 Structure of deformable convolution
(12)
式中:X′为可变形卷积的输出;w为网络权重参数;X为输入特征图;R为指定卷积区域;p0为可变形卷积核的中心位置;pn遍历整个卷积区域R;Δpn为卷积核偏移量,由网络学习获得,且为浮点型小数。
因此,添加偏移量的位置p=p0+pn+Δpn,也为浮点型小数。为了使新位置p能嵌入特征图中(要求位置为整数),对输入特征图在位置p进行双线性插值:
(13)
式中:q为输入特征图X的整数位置;G(·)为二维双线性插值核,由两个一维插值核构成:
G(q,p)=G(qx,px)·G(qy,py)
(14)
g(a,b)=max(0,1-|a-b|)
(15)
式中:qx和px表示x方向插值位置;qy和py表示y方向插值位置。
2 实验数据及配置
2.1 实验数据
本文在公开数据集BBox-SSDD[34]上进行实验。BBox-SSDD数据集上含有来自Radarsat-2、TerraSAR-X和Sentinel-1卫星的1 160张样本,共计2 587艘舰船。图像平均尺寸为500像素×500像素,图像中舰船尺度分布广泛,最小舰船尺寸为5像素×4像素,最大舰船尺寸为180像素×308像素。图9展示了BBox-SSDD数据集舰船尺度分布。由图9可知,BBox-SSDD中的舰船具有多尺度特点。舰船尺寸集中分布在左下角,表示小尺度舰船较多;部分较大舰船尺寸分布在图上其他位置,表示尺度分布不均。
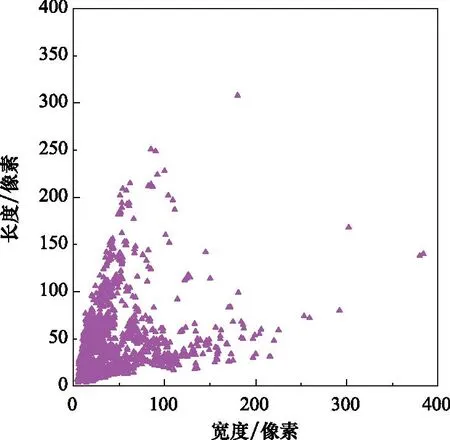
图9 BBox-SSDD数据集舰船尺度分布图Fig.9 Distribution of ship scales in BBox-SSDD dataset
2.2 实验设置
AA-MSE-Net训练及测试图像大小均使用经典双线性插值,调整大小为512×512。优化器选用随机梯度下降(stochastic gradient descent, SGD),学习率设置为0.01,动量设置为0.9,权重衰减设置为0.000 1[35]。训练迭代次数设置为12,在第8次迭代和第11次迭代时学习率衰减为原本学习率的1/10。受限于硬件,训练批次大小batchsize设置为2。程序运行的计算机平台使用i7-10700 CPU,显卡为Nvidia 2080Ti。使用Windows操作系统,程序编写语言为Python,编程框架为Pytorch。
AA-MSE-Net训练检测头网络的损失函数分为分类损失LCLS和回归损失LREG:
(16)
(17)

L1(x)=|x|
(18)
3 实验结果及分析
3.1 评价指标
本文采用PASCALVOC[36]格式数据集,因此采用基于PASCALVOC数据集的评价指标来衡量检测性能。评价指标主要包括召回率(Recall),准确率(Precision)和均值平均精度(mean average precision, mAP)。召回率定义为
(19)
式中:TP表示真正例,即正确的正样本;FN表示假负例,即错误的负样本。
准确率定义为
(20)
式中:FP表示假正例,即错误的正样本。
mAP通过对精度召回率曲线求积分得到,定义为
(21)
式中:N为类别数。在本文中仅有舰船一类目标,因此mAP等同于平均精度(average precision, AP)[37],本文中均以AP代替mAP。
3.2 对比实验结果
表1展示了在BBox-SSDD上,AA-MSE-Net与其他8种现有方法的SAR舰船检测定量对比结果,包括Faster RCNN[16]、YOLOv3[11]、高分辨率舰船检测网络(high resolution ship detection network, HR-SDNet)[38]、Cascade RCNN[17]、Libra RCNN[31]、Double-Head RCNN[39]、Free-Anchor[40]、Grid R-CNN[41]。上述方法参数设置尽量与其原始工作保持一致,以保证实验的公平性。由表1可知,相较于其他8种现有方法,AA-MSE-Net具有最高的SAR舰船检测精度,且高于次优模型Double-Head RCNN 1.87%。

表1 定性对比实验结果Table 1 Quantitative comparison results %
图10展示了在BBox-SSDD数据集上,AA-MSE-Net与次优模型Double-Head RCNN,以及初始模型Faster RCNN的检测结果对比。图10(a)展示了真值框,图10(b)展示了Faster RCNN的检测结果,图10(c)展示了Double-Head RCNN的检测结果,图10(d)展示了AA-MSE-Net的检测结果。如图10所示,AA-MSE-Net对于多尺度舰船具有更优秀的检测能力,例如对比图10中第1列图像,在近岸复杂场景、大小舰船混杂的环境下,Faster RCNN模型和Double-Head RCNN模型均存在小尺度舰船重复检测以及出现陆地虚警的现象,而本文所提出的AA-MSE-Net则准确检测到不同尺度的舰船,且没有出现虚警。这是因为AA-MSE-Net的多尺度增强金字塔能够增强多尺度特征,以及可变形卷积的引入增强了网络特征提取能力,并减少了背景干扰。此外,如图10中第2列图像所示,对于海面上的大尺度舰船,AA-MSE-Net能够提供更准确的检测结果。对比图10中第2列图像,Faster RCNN模型受背景干扰,在图像右侧产生了虚警。Double-Head RCNN模型则出现了重复检测的问题。而AA-MSE-Net模型未产生虚警以及复检问题,这是因为AA-MSE-Net引入了自适应锚框生成机制,可根据舰船实际形态产生质量较高的自适应锚框。此外,多尺度增强金字塔中的全局自注意力机制有效抑制了背景噪声,从而减少了海面虚警。如图10中第3列图像所示,对于海面上小尺度舰船,AA-MSE-Net能够提供更准确的检测结果。Faster RCNN模型产生了3个漏检,而AA-MSE-Net模型仅产生了1个漏检。这证明了AA-MSE-Net对小尺度舰船目标也具有更高的检测精度,同时证明了AA-MSE-Net对多尺度舰船目标都具有更高的检测精度。


图10 定性结果对比Fig.10 Comparison of qualitative results
3.3 消融实验结果
表2展示了AA-MSE-Net的消融实验结果。本文以Faster RCNN为基础模型,在其中加入自适应锚框、MSE-FPN以及D-Conv。由表2可知,在加入上述改进后,AP值逐渐提高,由89.74%逐渐提升至92.42%。首先,加入自适应锚框后,由于网络能够根据图像内容自适应生成尺度合适的锚框,检测精度AP上升至91.29%。其次,加入多尺度增强金字塔后,网络多尺度舰船检测能力增强,检测精度AP上升至91.66%。最后,在骨干网络中加入可变形卷积后,网络特征提取能力增强,检测精度上升至92.97%。因此,综上所述,本文提出的改进方法均能有效提高舰船检测精度。

表2 消融实验结果Table 2 Results of ablation experiment %
4 结 论
针对目前基于深度学习的SAR舰船检测锚框尺度固定以及多尺度检测性能较差的问题,提出了一种基于AA-MSE-Net的SAR舰船检测方法。首先,AA-MSE-Net引入了自适应锚框机制,增强了舰船形态描述能力。其次,AA-MSE-Net提出了多尺度增强金字塔,增强了多尺度描述能力。最后,AA-MSE-Net在骨干网络中引入了可变形卷积,进一步提高了检测精度。在数据集BBox-SSDD上的实验证明了AA-MSE-Net具有更好的舰船形态描述能力、更强的多尺度描述能力以及更高的检测精度。相较于8种对比模型,AA-MSE-Net的检测精度AP高于次优模型1.87%。
