基于HRNet的高分辨率遥感影像道路提取方法
2024-03-27陈雪梅刘志恒周绥平刘彦明
陈雪梅, 刘志恒,*, 周绥平, 余 航, 刘彦明
(1. 西安电子科技大学空间科学与技术学院, 陕西 西安 710126; 2. 自然资源部矿山地质灾害成灾机理与防控重点实验室, 陕西 西安 710054)
0 引 言
随着遥感技术和分辨率的快速发展和提高, 道路信息被视为遥感领域不可或缺的一个方面,在测绘、救灾、军事等领域有重要用途[1-2]。因此,如何从高分辨率遥感影像中自动、快速地提取高精度的道路信息是一个重要的挑战[3-4]。遥感道路分割模型目前面临的主要难点有:① 遥感图像的光谱信息有限[5],致使道路与具有相似光谱特征的其他特征(如停车场或建筑物)难以区分,这可能会导致道路提取过程中的错误。② 道路信息复杂,易受周围地物和天气的影响,难以从遥感图像中准确提取道路信息[6],导致预测效果较差。
目前,道路提取方法通常分为传统和深度学习两种方法[7]。基于传统的方法主要有模板匹配法[8-9]、知识驱动法[10-11]和面向对象法[12-13]等。文献[14]使用Kullback-Leibler散度作为相似性度量的模板匹配自动跟踪道路,能够自动、准确、快速地从高分辨率遥感图像中提取道路信息。文献[15]提出基于自适应形态学的知识驱动遥感图像道路提取方法,来实现道路提取的完整性。文献[16]基于高分三号卫星,采用面向对象法,利用光谱特征、形状特征等信息实现提取道路的边界平整。虽然传统的道路提取方法是有效的,但也有一些缺点,例如模板匹配法需要创建模板,非常耗时并且由于光照、比例等的变化,导致结果准确度不高;知识驱动法依赖于先验知识的指导,不适用于未知数据并会受到现有知识数量的限制;面向对象法侧重于检测和分割单个对象,对于复杂、混乱的对象边界难以准确分离。
基于深度学习的道路提取方法[17-19]灵活、准确并且高效。其中,一类方法基于编解码结构,例如U-Net[20]、嵌套UNet(nested UNet, UNet++)[21],大多是利用部分收缩的路线来捕捉上下文。另一类方法基于空洞卷积结构,例如金字塔场景解析网络(pyramid scene parsing network, PSPNet)[22]和DeeplabV3+[23]使用扩张卷积来增加感受野的分割网络。然而,上述网络容易导致边界和小目标附近空间细节丢失,而且浅层网络无法有效地区分不同特征。为解决上述问题,研究人员提出了不同的道路分割网络模型。文献[24]提出改进DeeplabV3+的高分辨率遥感影像道路提取模型,原始的主干网络Xception被替换为MobileNetV2[25],模型提取效率得到了提升。文献[26]开发了一种基于预测训练卷积和空洞卷积的神经网络(linknet with pre-trained encoder and dilated convolution, D-LinkNet)和注意力机制的图像分割算法,有助于提高上采样时子模块的利用率。尽管这些方法提高了道路提取的准确性和效率,但在道路提取方面仍然存在着如下挑战:① 在深度学习前向传播中,重复的最大池化层[27]会降低特征图的分辨率,导致详细的道路信息丢失。② 由于像素的感受野不同,不同深度的卷积层产生的特征图含有不同大小的特征信息。不同尺度上特征的整合值得进一步研究,以提高道路提取的准确性。
本文提出了改进高分辨网络(high-resolution net, HRNet)[28]在高分辨率遥感上进行道路分割的应用。HRNet可以在整个过程中保持高分辨率表示,并通过反复交换平行流中的信息来执行迭代式多分辨率融合。本文对HRNet进行改进,通过将浅层特征与深层特征融合,经过非局部块[29],再进行上采样,使输出结果既拥有浅层次的空间细节信息,也拥有深层次的语义信息,优化了输出结构,并提高了分割的精度。
1 HRNet改进方法
1.1 HRNet介绍
传统的深度学习模型在对特征层进行上采样之前对各层进行下采样,以恢复各层的大小直至初始值。然而,这增加了模型的复杂性和计算机操作。HRNet的并行连接也可以通过重复整合同级、多级特征来进行多尺度特征整合操作。
HRNet V1[30]最初用于人类姿势检测,通过融合不同分辨率分支来保留高分辨率图像并增强高分辨率表示。但是,HRNet V1只输出最高分辨率的卷积,而HRNet V2[28]集成了所有并行卷积,以支持高分辨率的表达。HRNet V2的这种扩展将原来的3分辨率表示形式增加到4分辨率,从而增强了特征表示形式,如图1所示。这种调整在语义分割和人脸关键点检测等视觉任务中有非常重要的作用。

图1 HRNet V2的网络结构Fig.1 Network structure of HRNet V2
1.2 HRNet的改进
本文对原有的HRNet进行了两个方面的改进:① 在特征提取过程中,融合分辨率相同的特征图,将浅层特征包含的空间信息传递给深层特征;② 利用非局部块处理分割模型网络输出的不同分辨率特征图。
(1) 特征图的拼接。HRNet使用并行连接将高分辨率子网链接到低分辨率子网,在网络特征提取中,虽然添加了不同分辨率特征之间的交互,但网络层数多致使输出层含有的空间位置和细节信息减少。子网在转换结构前会产生不同尺寸的特征图。在这些子网产生的特征图中,本文将尺寸相同的特征图进行拼接的方式包含以下优点:① 不同层的特征通常包含有关图像的不同信息。浅层特征通常包含有关图像的细节信息,而深层特征则包含有关图像的更高层次的结构信息。② 浅层特征对于精确地定位图像中的小对象和边界具有非常重要的作用,但很难识别图像中的大型连通区域。深层特征能更好地识别大型连通区域,但对细节的感知有限,难以准确地定位边界。将浅层特征与深层特征融合,可以提供更全面的信息,从而提高图像分割的准确性和精度。③ 将浅层特征与深层特征相结合,可以提高模型的泛化能力。因为浅层特征和深层特征都包含有关图像的不同信息,所以将其融合可以使模型更好地适应不同的图像。
(2) 非局部块的使用。非局部块是一种常用的深度学习模块,其结构如图2所示。其中,T、H、W和数字分别表示批大小、高度、宽度和通道数。非局部块的工作原理是对于每个输入数据,通过1×1卷积压缩通道数,得到θ,φ,g特征,将φ对应的特征图张量进行转置操作,将该结果与θ对应的特征图进行矩阵乘法,获得亲和矩阵,计算与所有其他位置的关联性。亲和矩阵经过Softmax操作,得到注意力权重。最后,将该自注意力权重乘以g对应的特征图张量,再经过另一个1×1卷积扩展为输出通道大小,并与网络的输入进行残差运算,获得模块输出。

图2 非局部信息统计注意力模块Fig.2 Block of non-local information statistics attention module
与另一种常用的基于通道和空间的卷积块注意力模块(convolutional block attention module, CBAM)[31]相比,CBAM模块的优点在于其通过对每个位置的注意力权重进行通道级和空间级调整,使网络更加灵活。因此,CBAM更适用于需要对通道和空间位置进行分别注意的任务。非局部块考虑每个像素与其他像素之间的关系,提高模型对图像细节的捕捉能力。非局部块更容易识别出物体的轮廓以及与背景的界限,并且提高模型的预测准确度。
改进的网络如图3所示,该网络将浅层特征和深层特征充分利用,可以提高模型的准确性。增加非局部块后,网络可以计算不同分辨率特征图的每个位置与特征图整体的关联性,帮助网络更好地理解图像的全局结构和语义。

图3 本文设计的网络结构Fig.3 Network structure designed by this paper
1.3 损失函数
损失函数是用来衡量预测值与真实值之间的差异的一种函数,是深度学习模型的核心部分[32]。因此,选择合适的损失函数对于模型的训练和性能而言都很重要。为了保留道路更多的细节特征,本文模型的损失函数使用包括交叉熵损失函数[33]和Dice Loss[34]损失函数的混合损失函数。
交叉熵损失函数被广泛用于分类任务,并且由于分割是像素级分类,可以有效地度量真实值与预测值之间的距离,其定义如下所示:
LCE=-[(yt)ln(yp)+(1-yt)ln(1-yp)]
(1)
Dice Loss损失函数是基于区域的损失函数,即给定像素的损失不仅依赖于像素本身的预测值,还依赖于其他像素的预测值。因此,Dice Loss损失函数在正样本和负样本之间存在显著不平衡的情况下(如道路数据集)表现非常好。Dice Loss损失函数的定义如下所示:
(2)
基于上述分析,本文模型使用的混合损失函数如下所示:

(3)
式(1)~式(3)中:yt是真实值;yp是预测值;r为大于0的超参数,用作损失函数的权重因子;本文r取0.5,以降低损失函数值并减少错误惩罚。
2 实验分析与讨论
2.1 实验设置
本文在CHN6-CUG道路数据集[35]上进行实验,以评估改进的HRNet的性能。CHN6-CUG包含4 511张分辨率为512像素×512像素大小的图像,其中3 247张用于模型训练,812张用于模型验证,452张用于测试以及结果评估,图像分辨率为50 cm/pixel。所有的实验都在NVIDIA RTX3090 GPU服务器上运行。图像的数据增强包含水平翻转、随机高斯模糊和图像标准化。
本文使用的评估算法包括U-Net、全卷积网络(fully convolutional network, FCN)[36]、PSPNet、DeeplabV3+、D-LinkNet50[37]和HRNet。所有提到的网络都遵循相同的训练策略。本研究使用均方根传播(root mean square prop, RMSprop)[38]优化算法,批大小设置为8,迭代训练为200个epoch,动量为0.9,权重衰减为5e-4。初始学习率为0.001,学习率使用poly策略进行动态调整。
实验选取的评价标准包括召回率(Recall)、精确率(Precision)、均交并比(mean intersection over union, MIoU)和F1分数,其计算分别如下所示:
(4)
(5)
(6)
(7)
式中:TP为真阳性;TN为真阴性;FP为假阳性;FN为假阴性。阳性和阴性分别代表道路和背景。
2.2 实验结果分析
(1) 消融实验
为验证本文所提出的改进HRNet中各模块的有效性,比较了HRNet、剔除非局部块的本文方法与本文方法的性能。如表1所示,剔除非局部块的本文方法比HRNet在Recall、MIoU和F1性能上分别提高了1.44%、3.97%和0.35%,表明本文方法在HRNet结构上增加了跳跃连接,增强了特征的重用,促进了特征传播。使用非局部块的本文方法比剔除该模块的本文方法在Recall、Precision、MIoU和F1上分别提高了1.02%、1.29%、1.66%和0.44%,说明非局部块有效增强了网络通道之间像素相关性的信息交流,提高了道路分割精度。

表1 消融实验的评价指标对比Table 1 Comparison of evaluation indexes of ablation experiment %
(2) 对比实验
为了综合评价改进后的HRNet模型的分割性能,选择了U-Net、FCN、DeeplabV3+、PSPNet、D-LinkNet、HRNet进行比较,并利用测试集对训练后的模型进行性能测试。本文改进的HRNet和其他网络分割结果的能力评估比较如表2和图4所示。本文改进的HRNet在Recall、MIoU、F1分数性能提升比例取得最高,分别达到了97.26%、84.91%、97.25%,与原始HRNet相比分别提高了2.46%、5.63%、0.79%。以上结果表明,本文改进的HRNet有助于提高道路分割的准确性。

表2 不同模型的道路分割评价指标对比Table 2 Comparison of road segmentation evaluation indexes of different models %
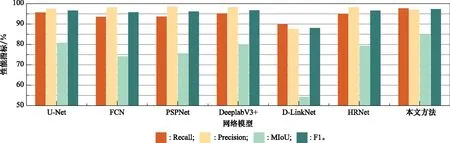
图4 不同模型的道路分割评价指标对比直方图Fig.4 Comparison histogram of road segmentation evaluation indexes of different models
本文方法与对比模型的道路分割结果如图5所示,由黄色方框指出的分割部分可以明显观察到本文方法实现的高分辨率遥感影像道路分割边缘具有更清晰、更准确、道路细节保留程度更高的特点。相比之下,其他分割方法,例如D-LinkNet,易受到类似道路目标像素(土地)的干扰,从而导致分割效果差。同样,其他语义分割网络表现出道路的不连贯特性,出现错分和漏分现象。实验结果表明,本文提出的改进HRNet并结合非局部块的分割网络模型,能够捕获更广泛的道路特征,从而获得更完整的分割结果。即使图像中存在大小和形状不同的道路像素,本文方法也可以生成包含连续线性道路的分割预测图。因此,本文方法对道路分割产生了最为有效的结果,并且保留了更完整的目标像素。

图5 本文方法模型与对比模型的道路分割结果图Fig.5 Road segmentation results of the method model in this paper and the comparison model
(3) 模型复杂度分析
本文方法与本文对比模型的复杂度比较如表3所示,其网络的输入数据大小为(1,3,512,512),预测时间为单张图像的平均道路预测时间。由表3可知,HRNet的参数量(9.64 MB)、计算量(18.66 GFLOPs)最小,这是由于HRNet并行了多个分辨率的分支,并保持特征图的高空间分辨率,同时与传统网络相比,减少了需要多层才能达到相同分辨率的参数数量。本文方法的参数量(12.38 MB)、计算量(60.46 GFLOPs)、预测时间(0.46 s)与其他对比模型相比都较小。D-LinkNet50的编码器基于ResNet50架构,并且使用了扩张卷积来增大感受野,因此其参数量(217.65 MB)、计算量(120.39 GFLOPs)、预测时间(0.78 s)与其他模型相比都是最大的。

表3 不同模型的复杂度对比Table 3 Comparison of complexity of different models
3 结 论
针对现有语义分割算法在高分辨率遥感图像道路分割中存在的道路不连续、细节丢失、阴影误分类等局限性,本文提出一种改进的HRNet新方法,并引入非局部块。该方法针对遥感道路分割背景复杂、目标遮挡高、道路目标像元少等特点进行了研究。具体而言,该方法通过融合HRNet中具有相同分辨率的子网输出和输出层结果,增加深层特征图的感知域,补充了语义和空间信息,提高了图像特征的鲁棒性。非局部块的引入帮助网络识别出了不同像素之间的关系,提升了图像道路特征像素的恢复能力。在高分辨率遥感道路数据集CHN6-CUG上进行了评估,并与同类方法进行比较,表明该方法在道路分割方面具有显著优势。该方法也可以推广应用至来自不同来源的遥感数据的其他类型目标分割。
