基于证据推理的隧道坍塌多源信息融合评估
2024-03-25丘伟兴赵炼恒吴波单凌志徐世祥
丘伟兴 ,赵炼恒 ,吴波 ,单凌志 ,徐世祥
(1.中南大学 土木工程学院,湖南 长沙,410075;2.广西大学 土木建筑工程学院,广西 南宁,530004;3.东华理工大学 土木与建筑工程学院,江西 南昌,330013;4.中咨规划设计研究有限公司,北京,100020)
对于大多数国家来说,公路是极其重要的基础设施.它确保了不同地区之间的沟通和发展,特别是在山区和丘陵地区.然而,当公路通过山区时,公路隧道的建设也带来了巨大的挑战.通常采用钻爆法进行山岭隧道的开挖.然而,它涉及许多风险因素和复杂的施工程序,导致坍塌事故的发生率相对较高[1].一旦在施工过程中发生隧道坍塌,将造成人员伤亡、经济损失和工期延误.为了减少对基础设施、人类和环境的破坏,人们付出了巨大的努力来控制灾害.
近年来,传统的机器学习方法被用于风险评估和控制,例如支持向量机[2]、神经网络[3]以及高斯回归方程[4]等.然而,使用单一信息源分析隧道坍塌风险产生的结果与实际情况略有偏差.由于单一来源的信息不能充分反映实际施工情况,评价结果不准确,不能为决策者提供准确的建议.相比之下,融合模型对风险因素有更好的理解,可以大大提高评估结果的准确性[5].例如,Peng 等[6]基于边坡稳定机制集成多源信息,对边坡的安全性进行评估.Zhang等[7]应用多层信息融合框架感知地铁隧道管片损伤的安全风险.Pan 等[5]通过传感器数据与仿真数据的融合提高了结构安全风险评估的准确性.Li等[8]提出了一种预测突发灾害风险的融合模型.
为了提高评估的准确性和可靠性,学者们提出了许多信息融合的方法,如粗糙集[9]、Dempster-Shafer(D-S)证据理论[10]、最大熵方法[7]等,并将融合方法运用到实际工程中,取得了较好的结果,例如:Li 等[11]提出了一种基于同质观测的多源数据聚类方法,用于复杂背景下的多目标检测.Saadi 等[12]提出了一个多源信息融合框架,允许智能合并多个数据源,并应用于城市交通.Guo 等[13]提出了一种结合BIM 以及D-S 证据理论的混合方法,以支持地下隧道的系统风险评估和可视化.在这些信息融合方法中,由Dempster 提出并由Shafer 完善的D-S 证据理论是解决信息融合领域实际问题的常用有效方法.与贝叶斯理论不同,D-S 证据理论可以处理不完整数据,并能表示不精确性和不确定性[7].然而,D-S证据理论有两个假设可能不适用于实际情况:1)概率分布基于用户定义的函数或分布,这对于实际情况来说太理想了;2)每个判断都假定具有相同的可靠性和重要性,这就忽略了判断的质量.为了解决上述问题,本文在信息融合的框架中采用了考虑重要性权重和可信度的证据推理(Evidence-Based Reasoning,ER)规则.然而,在大多数情况下,可信度和重要性权重的确定仍然是一种主观选择.在概率风险融合的过程中会出现以下问题:一是如何客观地确定每个信息源结果的可信度,二是如何在信息融合过程中兼顾重要性权重和证据的可信度.
针对上述问题,本研究提出了一种基于证据推理规则的信息融合模型,该模型可以估计可信度和重要性权重.目视检查和监控量测数据作为坍塌风险评估的信息来源,然后根据不同的信息源构建相应的风险评估模型,对模型进行训练,得到坍塌风险的概率分布.根据模型的性能,以可信度和重要性权重为特征,对各模型的判断进行评价.最后,融合各个分类器的判断,得到整体坍塌风险值.该模型旨在实现以下目标:1)根据监测数据和目视检查,提出了坍塌风险评估模型;2)量化判断评估模型的性能;3)将模型的判断与确定的重要性权重和可信度相融合,得到最终的坍塌风险评估结果.
1 多源信息融合评估模型构建
ER 规则是一种将多个证据与可信度和重要性权重相结合的融合方法.目前,对于重要性权重和可信度的确定,还没有统一的方法.本研究从构造概率分类器开始,目标是从模型评估结果中获得其重要性权重和可信度.利用目视检查和实测位移数据作为信息源,通过评估模型获取坍塌风险.然后根据其可信度和重要性权重将不同模型得到的风险概率进行融合,得到总体坍塌风险值.该方法的框架如图1所示.

图1 基于ER的隧道塌方风险评估模型流程图Fig.1 Flow chart of the tunnel collapse risk assessment model based on ER
1.1 证据推理(ER)规则的基本原则
ER 规则用于将证据的可信度和重要性权重相结合[14].本文采用ER 规则对不同分类器的判断进行融合,得到隧道坍塌风险评价.假设Θ={h1,h2,…,hn},Θ中的元素相互排斥.在风险等级评估中,Θ代表风险识别框架,hi(其中i=1,2,…,n)代表评估等级.Θ的幂集由P(Θ)或2Θ表示,由所有的子集组成.一个证据被一个信念分布描述,如式(1)所示.
式中:(θ,pθ,j)是一个证据的要素ej,表示证据指向命题θ的概率为pθ,j,θ可以是Θ的任意子集.
在ER 规则中,定义了证据ej的可信度rj和权重wj.可信度rj代表信息源的能力.证据的可信度是证据的固有属性.证据的权重wj可以用来反映其相对于其他证据的重要性.加权置信分布对可信度的重要性定义如式(2)所示.
式 中:mθ,j=wjpθ,j,crw,j=1∕(1+wj-rj)为归一化因子,并满足是证据ej的重要性权重,rj∈[0,1]是证据ej的可信度.
如果两项证据e1和e2相互独立,通过ER 融合规则得到e1和e2共同支持命题θ的组合信念度为pθ,e(2),如式(4)和式(5)所示.
式中:D为所有子集;B和C为两项独立的证据.
1.2 置信度学习
置信度学习可以转化为构造基本概率赋值的问题.本文将使用概率支持向量机(Probabilistic SVM)和云模型(CM)分别对现场风险因素和监测数据进行处理,得到基本概率值.
1.2.1 概率支持向量机(Probabilistic SVM)
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,传统的线性支持向量机通过超平面进行线性分割.这个超平面是通过最大化分离边界来找到的,分离边界是超平面和最近数据点之间的距离.利用核函数将原始数据从低维空间映射到高维空间的特征空间,可以获得更好的分类精度.此外,误差项的惩罚参数C对分类精度也起着关键作用,C值越高,表示分类器越严格,不允许有很多错误分类点[15].判别函数为:
式中:m为训练数据集的大小;αi为拉格朗日乘子;K(xi,x)为核函数;b为基于训练集的阈值参数.
然而线性支持向量机只给出一个“是”或“否”的类预测输出.为了从支持向量机输出中提取相关概率,已经有学者提出了多种方法.本研究采用Platt的方法[16],该方法使用Sigmoid 函数将支持向量机的输出映射到区间[0,1],如式(7)所示.
式中:a和b为对一组训练示例进行负对数似然函数最小化计算得到的参数.
1.2.2 云模型
正态云模型是李德毅院士提出的一种新的不确定性认知模型[17].它能综合描述元素的随机性和模糊性,实现定性概念与定量值之间的不确定性转换.正态云模型可由数值特征(期望Ex,熵En,超熵He)确定.正态云的定义如下:
在给定定量论域X时,若B是X上的一个定性概念,x满足:1)x∈X;2)x是概念B的随机实例化;3)x满足式(8),x属于概念B的确定度可由式(9)求得.
在决策过程中分析了各种隧道坍塌风险因素Bi.为了从多个来源挖掘有用信息,每个风险因素应进一步划分为不同的风险状态Bij(i=1,2,…,M;j=1,2,…,N).每个风险状态可以对应一个特定的双极限区间,记为[bij(L),bij(R)].通过式(10)将双极限区间[bi(jL),bi(jR)]转化为正态云模型(Exij,Enij,Heij).
式中:Exij为期望;Enij是Exij的熵;Heij是超熵.常数h的取值范围为0~Enij,适用于反映这些因素的不确定性程度.根据文献[18],本文h取0.002.
在CM 框架中,相关性可以度量因子Bi的观测值bij与特定风险状态Bij的云模型之间的相对隶属度.影响因素在不同风险状态下的基本概率分布(BPA)可由式(11)得到.
式中:mi(B)j表示影响因素在不同风险状态下的BPA值;Enij'表示满足条件En'~N(En,He2)的随机数;mi(Φ)表示不确定情况下的BPA 值,即在Bi指标下无法确定的焦点元素,所有元素都包含在内.
1.3 证据可信度和重要性权重的确定
1.3.1 可信度确定
证据的可信度代表了正确评估的能力[19].当两个或以上的类别有相同程度的概率时,就会产生不确定性.可信度相当于不确定度的补充部分,即不确定度越高,可信度越低.目前,不确定度的测量方法有冲突测量和混淆测量等[20-21].本文采用聚合不确定性[16](Aggregate-Uncertainty,AU)计算从概率分类模型中学习到的每个证据体的信任度水平,如式(12)所示[16].最大不确定度为焦点元素个数的对数函数,如式(13)所示.为使不确定度与焦点元素个数无关,通过不确定度最大值的归一化系数将聚合不确定度归一化,如式(14)所示.
式中:pθi是焦点元素θi的信任度;G是归一化因子;n是焦点元素的总数.
式中:rj是证据ej的可信度.
根据表4,我们可以看出总资产增长率、总利润增长率、净资产增长率在2012年到2013年迅速增长,说明企业资产规模在此期间扩张迅速,规模增长的速度很快,企业的竞争力增强。主要是本期非公开发行股份、股权激励对象行权形成股本溢价所致。伊利实业集团股份有限公司于2012年12月12日核准非公开发行不超过29,500万股新股。发行数量及金额:不超过2.95亿股(原为3.1亿股),募资金额不超过50亿元。资本公积增加导致总资产增长迅速。然而在此期间主营业务收入增长率却呈下降趋势,主要是因为“奶荒”和奶粉质量问题导致的销售收入减少导致。
1.3.2 重要性权重
重要性权重代表每个证据体的感知贡献.在无模型的情况下,根据证据之间的相似性度量来确定重要性权重.相似性权重的确定,假定证据越多,结果越准确.然而,在大多数情况下,基于数量的质量假设很难检验.而在模型学习和验证的环境中,重要性权重直接由其对模型准确性的贡献来决定.在本文中,选择了0.01 的阈值来维持每一个选定的证据的存在.最低的class-wiseF1-score 来限制低质量证据的贡献.最后,将概率分类器中每个证据的重要性权重设置为max{min{class-wiseF1-scores},0.01}.class-wiseF1-score 是结合了精确率和召回率的指标,由式(15)~式(17)可得.
式中:Pθi表示class-wise精确率;Rθi表示class-wise召回率;Fθi表示class-wiseF1-score;TP 表示预测准确案例.
2 应用研究
2.1 工程概况
鱼塘溪隧道是位于福建省三明市的一条双管公路隧道.本文以右线(K244+885~K245+840)为研究对象,鱼塘溪隧道右线纵截面如图2 所示.鱼塘溪隧道Ⅴ级围岩段为465 m,Ⅳ级围岩段为435 m.岩体主要由残余粉质黏土、花岗岩全风化层和破碎的强风化层组成.隧道中还包含了两个断层破碎带,分别为L1(K244+950~K245+010)和L2(K245+280~K245+320).在隧道开挖经过断层破碎带时,极易造成隧道坍塌.因此,迫切需要对该隧道段进行坍塌风险评估,以减少隧道坍塌造成的损失.
2.2 信息预处理
由于不同信息源的组成成分并不相同,很难用同一种评估方法进行处理.本文将对不同信息源分别运用合适的评估方法进行处理.其中,目视检查数据将使用支持向量机进行分析,监测数据将采用云模型进行评估.
2.2.1 目视检查数据
1)隧道坍塌中的风险因素识别.参考OU等[22]的研究,本研究共选取了13 个风险因素,如表1 所示.同时,将各隧道坍塌风险因素划分为4个等级.

表1 L1断层隧道坍塌风险因素Tab.1 Risk factor for tunnel collapse in the L1 fault
2)支持向量机模型构建.为了构建支持向量机模型,本研究收集了72 例山岭隧道坍塌案例数据集[22-23],按照表1对风险因素进行分类形成隧道坍塌数据库.将数据集作为训练数据(风险因素等级作为输入,坍塌风险值为输出),利用网格搜索方法找到SVM 模型的最优超参数(C,γ).由于输入数据有限,采用5 次交叉验证确定gamma 参数(γ)和惩罚参数(C)的最佳值.在SVM 模型中测试不同值的(C,γ)对,其分类准确率结果如图3所示.最优超参数(C,γ)的搜索范围为[2-8,28].当参数C=4,γ=0.25 时,分类准确率最高.模型构建好后,输入现场的目视检查数据即可得到隧道的坍塌风险值.
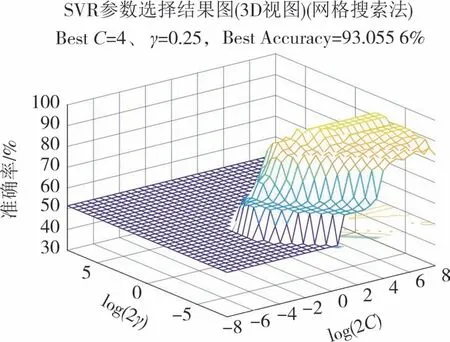
图3 基于(C,γ)的支持向量机分类准确率Fig.3 Classification accuracy of support vector machine based on(C,γ)
其中围岩等级根据我国采用的岩体基本质量法(BQ 法)进行分类.及时可靠的监测结果可以详细了解施工各阶段围岩和支护结构的动态变化.监测频率越高,结果就越可靠和有效.因此,使用频率监控来创建用于监控的评估指标.地形、地质和施工三种因素造成非均匀荷载作用于隧道断面,以及隧道支撑结构上的非均匀压力,导致了支撑结构的剪切破坏,本文从偏压角度进行考虑.
根据施工要求,利用综合地质预报系统对L1 断层进行了探测.TGP 检测结果如图4 所示,图4 显示了纵波绕射偏移图像、估计波速以及比速度与隧道里程的关系.根据TGP探测结果和工程地质分析,获得隧道掌子面(K244+995)前方约150 m 长的地质条件.预测断面整体地质情况如下:隧道掌子面岩性为强风化粉砂岩.从(1)区右界到(2)区右界,纵波和横波速度明显下降(图4),此外,迁移图像的色谱是负的.因此,可以推断该段已被压碎,发育的局部裂隙中充满了岩屑.断裂构造受构造影响较大,地下水丰富,围岩稳定性差,容易失稳坍塌.

图4 岩石物理性质的TGP检测结果Fig.4 TGP detection results of physical properties of rocks
在上述分析的基础上,建立了鱼塘溪隧道穿越L1 断层的坍塌风险指数和风险等级,如表2 所示.开挖过程中发生了小型坍塌,根据表1,该段的坍塌风险值为Ⅲ.
2.2.2 监测数据
监测测量数据包括浅埋段地表沉降、拱顶位移、水平收敛位移等,这些数据可以反映初始衬砌后隧道支护的稳定性.在深埋隧道中,往往不需考虑地表沉降的影响,只选取拱顶位移和水平收敛位移进行坍塌风险分析.根据国家标准《公路隧道施工技术规范》(JTG∕T 3660—2020)[24],选取监测数据的每日沉降速率和累积变形量作为判断指标.监测点距离掌子面越远,累积位移极限值越大.因此,累积位移极限值需要乘一个因子.根据这两个判断指标将监控量测数据分为四个层次,如表3所示.

表3 监控量测数据的分类Tab.3 Classification of monitoring measurement data
其中,累积变形等级指标区间应根据测点到掌子面距离(D)乘系数(ζ),如表4 所示.表4 中的B为开挖隧道的跨度.

表4 累积变形等级指标区间的系数(ζ)Tab.4 Coefficient(ζ)for cumulative deformation class indicator intervals
隧道采用台阶法开挖,监测点布置如图5 所示.围岩位移监测早晚各一次,取其平均值作为当天的监测值.随着上下台阶的顺序开挖,水平收敛的测点需要水平向下移动.K245+300的监测数据如图6所示.

图5 监测点布置示意图Fig.5 Monitoring point layout diagram
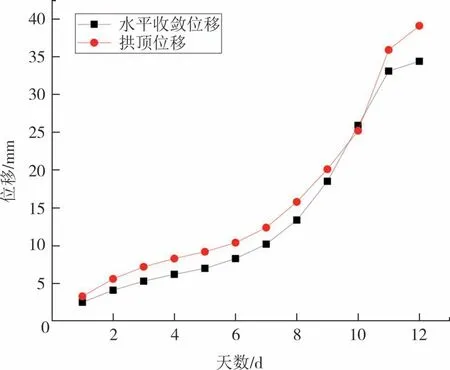
图6 监测数据Fig.6 monitoring data
根据式(10)和表3 得出两个监测指标的云模型参数值(Ex,En,He),如表5 所示.收集拱顶位移和水平收敛位移代入式(11)即可求得隧道坍塌各风险等级的BPA值.

表5 两个监控指标的云模型参数值Tab.5 Cloud model parameter values of two monitoring indicators
根据每日变形速率和累积沉降量将得到两组坍塌风险等级概率分配,为了更好地实现安全储备,本文采用较大的风险等级作为最终风险等级结果.
2.3 多源信息融合
为了解决单一信息源评价结果不可靠的问题,采用证据推理理论(1.1 节)对多源数据进行融合.该方法综合了上述三种单源信息评价模型(目视检查数据、拱顶位移、水平收敛位移)的不同结果.根据ER 规则通过MATLAB 软件进行融合.在K242+555~K242+925 开挖段中每隔5 m 选取一个训练样本,选取80 个隧道段面作为训练样本.根据式(15)~式(17),三种模型的训练结果如表6 所示.融合过程中各模型的重要性权重为[0.667;0.648;0.571].

表6 不同模型的训练结果Tab.6 Training results of the classifiers
为了说明融合过程,在挖掘断面K244+900~K244+925 每隔5 m 选取训练样本,选取5 个隧道断面作为测试样本,并将ER 规则与D-S 理论的融合结果进行比较,如表7 所示.表7 中E1为SVM 模型,E2为拱顶位移模型,E3为水平收敛位移模型,ER 为ER规则理论融合结果,D-S 为D-S 证据理论融合结果.可以得到以下结论:

表7 五个测试样本的融合结果Tab.7 Fusion results of five test samples
1)该多源信息融合模型具有良好的容错性.该模型可以根据分类器正确结果的重要权重和可信度对错误分类器结果进行修正.以测试样本No.4 隧道断面为例,三个模型得到的坍塌风险概率分别为E1=[0.10,0.20,0.70,0];E2=[0,0.56,0.44,0];E3=[0.99,0.01,0,0].根据概率决定理论,以最大概率的风险等级作为结果,该结果以带下划线的数据表示.重要权重w=[0.561;0.648;0.571];证据可信度r=[0.422;0.795;0.985].折减概率值为
根据式(5)计算得到考虑了可信度和重要性权重的概率分布
利用ER 规则对三种模型的概率分布进行融合,其融合后的概率值为
其中e(3)表示三项证据的结合.最后剔除幂集项,坍塌风险概率为
该截面的坍塌风险等级为I(安全).如表7所示,E1和E2都给出了错误的结果,其可信度也较低,E3具有较高的可信度并且给出了正确的预测,ER 融合规则同时考虑了三种模型的重要性权重和可信度,使得E3的正确预测结果将E1和E2的错误结果修正回融合模型中的正确结果.
2)通过单一信息源评估坍塌风险时,由于数据的不确定性,评估结果往往会出现偏差.本文提出的多源信息融合方法可以综合考虑所有类型的信息(包括冲突信息),对施工有全面的认识,从而降低数据的不确定性以提高评估的准确率.因此与单源信息评估方法相比,多源信息融合结果往往有更高的准确率.
3)当三个单一信息源的风险评估结果不同时(如No.4隧道断面),ER 规则的融合结果优于D-S 理论.D-S 理论只积累共识支持,如果一个命题被任何证据反对,尽管它从其他证据得到支持,它也将被完全拒绝.因此,当三种单一信息评价结果不同时,普通D-S 理论会给出与常识相反的融合结果.然而ER规则在合并高冲突信息源时充分考虑了模型的重要性权重和可信度,因此能判断出哪个模型更有可能代表实际情况,给出的结果也能更加贴近实际.
2.4 结果分析
毫无疑问,单源信息评估方法也可以对隧道坍塌风险水平进行评估.但是,单一信息来源并不能完全反映隧道施工环境,导致评估结果存在一定的偏差,准确性较低.为了比较单源信息评估方法和多源信息融合方法,分别采用单源信息模型和融合模型对坍塌风险进行评估.从鱼塘溪隧道中随机抽取40 个隧道断面进行风险评估.不同模型的评估结果如图7 所示.从图7 可知,单源信息评估方法[图7(a)、(b)、(c)]的准确率均小于70%,单源信息模型并不能为现场施工提供准确的决策意见.这是由于单一信息源没有充分考虑导致隧道坍塌的风险因素,且信息存在误差和不确定性,最终导致坍塌风险评估结果与实际略有偏差.而多源信息融合方法评估的准确率达到了87.5%[图7(d)].这是因为所提出的融合方法充分利用了可用信息,并考虑了冲突信息.该多源信息融合模型兼顾了目视检查和监测数据,使评估模型更贴近实际情况,提高了评估结果的准确性.
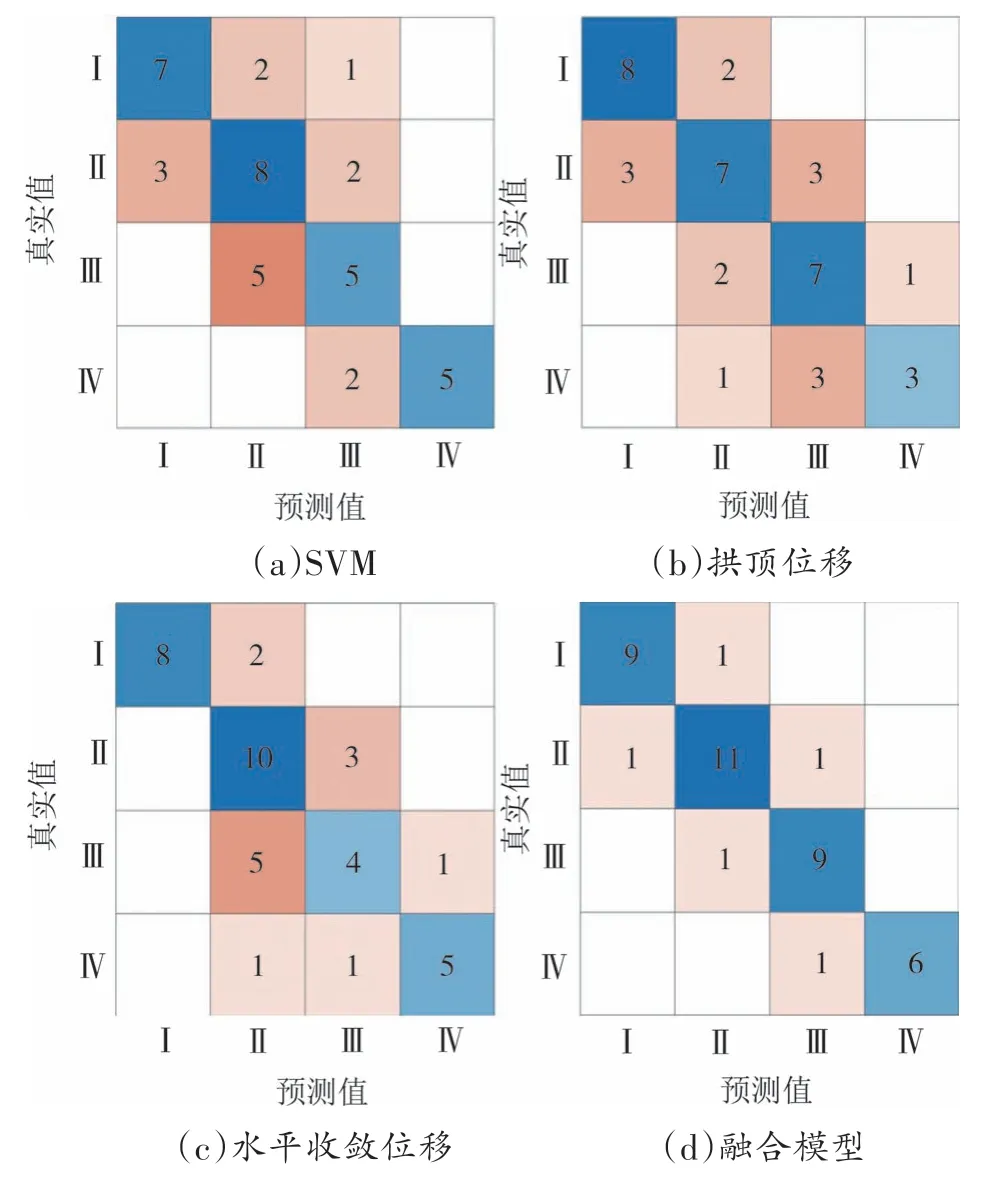
图7 不同模型的分类结果Fig.7 The classification results of the different model
3 结论
本研究提出了隧道坍塌风险评估的多源信息融合方法,为隧道开挖提供风险评估.通过对多信息源的分析,得到了不同的坍塌风险判断.通过可信度和重要性权重来估计每个判断的质量.然后将各信息源的结果进行融合,给出总体概率风险评估.通过评价结果的重要性、权重和可信度来量化评价的质量.所有这些结果都被纳入最终的风险评估,以提高整体评估准确率和鲁棒性.本文提出的评估方法具有以下优点.
1)综合多源信息,可以得到更准确的隧道坍塌风险评估结果.由于钻爆法施工影响因素众多,隧道坍塌风险评估是一个多属性决策问题.单源信息评估方法难以充分考虑所有的风险因素,导致评估结果存在偏差.融合模型的性能优于单信息源模型,具有较高的精度.
2)与D-S 理论相比,ER 规则在处理高冲突信息方面更有优势.当三个单一信息源的风险评估结果不一致时,采用ER 规则进行融合,考虑了评估结果的重要性权重和可信性,提高了最终评估结果的准确性.
本方法的缺点是,所得到的风险评价结果取决于风险指标和分类标准的选择.因为本研究选取的统计案例为山岭隧道,本文所采用的风险指数可能仅适用于山岭隧道的风险评估.
