改进的轻量级行人目标检测算法
2024-03-20任婷婷张立国闫梦萧沈明浩
金 梅, 任婷婷, 张立国, 闫梦萧, 沈明浩
(燕山大学 电气工程学院,河北 秦皇岛 066004)
1 引 言
目前静态图像检测和动态目标检测被广泛应用于行人检测技术[1]方面,是计算机视觉研究中最基本、最核心、最具挑战性的技术之一。在现实生活中,由于行人图像的背景复杂,以及受到姿态、穿着和遮挡等不利因素的影响,行人检测的难度大大增加。因此在保证检测实时性的前提下,研究如何在现实复杂场景中提高对行人目标检测的准确性是一个急待解决的难题。
行人检测方法大都源自目标检测方法,主要分为传统方法和基于深度学习的方法2大类。传统目标检测方法先是基于被检测物体的HOG(histogram of oriented gradient)、SIFT(scale invariant feature transform)或SURF(speed up robust features)[2~4]等显著特征,手工设计特征提取算法,然后使用AdaBoost、支持向量机(support vector machine,SVM)等[5, 6]分类器对特征进行分类,从而达到检测的目的。由于传统方法采用人工设计的特征,泛化能力较差,检测精度的高低很大程度上取决于人的认知水平,使得检测效果与实际需求存在一些差距。基于深度学习的目标检测方法在一定程度上避免了人工对目标特征提取的干预,深度学习方法一般采用卷积神经网络(convolutional neural network, CNN)自动获取特征。现今基于深度学习的目标检测方法可以从检测方式上分为2类:两阶段检测和单阶段检测。其中,R-CNN系列[8~10]是最典型的两阶段目标检测算法,Girshick等首次提出基于深度学习进行目标检测的R-CNN[8]算法,为后续基于深度学习的目标检测算法奠定了基础,但其最大的缺点是训练和检测速度慢。随着深度学习的发展,R-CNN系列优秀代表作Faster R-CNN[10]大幅提高了目标检测的性能,文献[11]在此基础上进一步提出利用多尺度融合的方法提高检测精度,但检测的实时性仍很难达到要求,检测速度仍有很大提升空间。基于对速度的改进,单阶段目标检测算法开始崛起,出现了以SSD[12]和YOLO系列[13~15]为代表的单阶段目标检测方法。YOLOv1[13]算法采用端到端的回归思想,检测速度大大提高且泛化性能好,但是对小物体的检测精度较低。随着算法的不断改进,后来提出的YOLOv3[14]和YOLOv4[15]极大提高了检测精度同时也保持较快的检测速度,但在现实复杂场景中对行人的检测仍存在某些不足。
为了满足实时检测同时提高行人目标在诸多复杂场景下的检测精度,本文做出如下工作:(1)为了解决主干特征提取网络过于简单而导致的特征提取能力弱的问题,在主干网络中添加包含注意力机制的特征提取模块(REM模块),聚焦行人目标的同时有效增强网络特征提取能力。(2)为进一步解决小目标检测精度低的问题,对TinyYOLOv4的特征融合网络进行改进,原网络使用2个YOLO Head输出,仅融合了13×13特征层和26×26特征层信息,对浅层细节信息丢失严重,于是引入52×52浅层信息,有效地增强了小目标检测效果。(3)为了更好地丰富深层语义信息同时防止图像失真,在空间金字塔池化模块(spatial pyramid pooling,SPP)[16]和残差模块的启发下,设计添加注意力机制的特征融合模块(RM-block模块),增强感受野信息,提升检测精度。
2 TinyYOLOv4网络
TinyYOLOv4是YOLOv4算法的简化版,是一个优秀的轻量化行人检测网络。该算法通过简化网络参数将原有的6000多万参数减至不到600万参数,在检测精度满足现实需求的前提下,检测速度得到极大提升。TinyYOLOv4网络如图1所示。网络可分为3部分:主干网络(CSPDarknet53-tiny)、特征融合网络FPN[17](feature pyramid network)、预测网络(YOLO head)。首先,通过主干网络进行特征提取,本文统一使用416×416大小的图片作为输入,最终获得13×13和26×26这2种维度的有效特征层;其次,通过FPN结构对这2个有效特征层进行特征融合;最后,利用YOLO Head进行输出,获得最终检测结果。
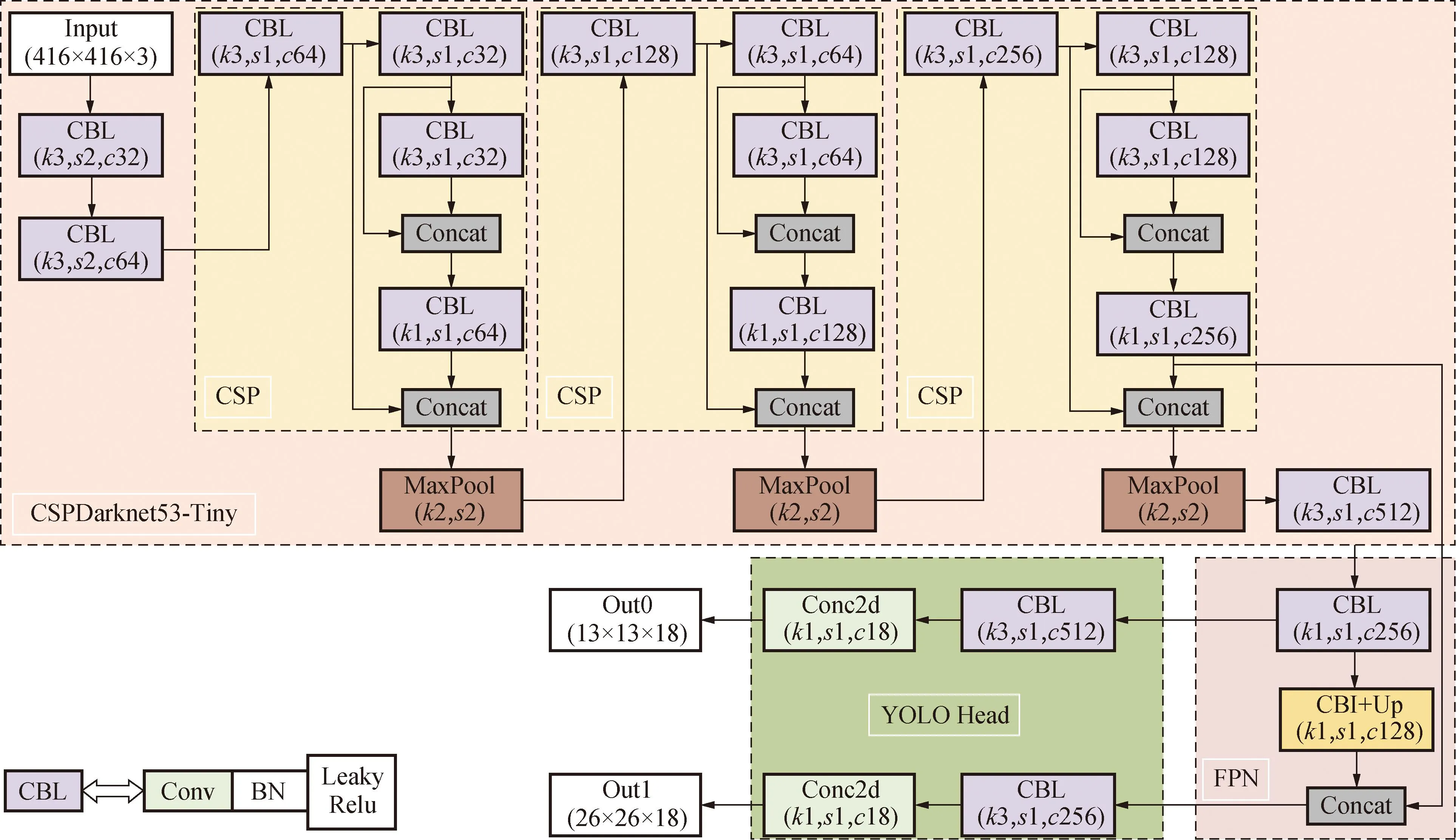
图1 TinyYOLOv4网络Fig.1 TinyYOLOv4 network
2.1 主干网络
CSPDarknet53-tiny主干网络用于提取有效的行人特征,主要包括卷积模块(CBL)、残差块(CSP[18])和下采样(Maxpool)3大模块。
卷积模块(CBL)由3部分组成:卷积层(convolution)、批量标准化(batch normalization)和激活函数(Leaky ReLU)。卷积过程中使用3×3或者1×1大小的卷积进行特征提取或者通道数的调整;经过卷积操作后,采用批量标准化处理使得输入层更加规范、加快了网络学习的收敛速度、避免了梯度消失等问题;最后使用Leaky Relu激活函数,达到避免神经元失活的目的,该函数可以在值出现负值的情况下施加一个非零斜率,加快网络的训练和计算速度。
残差块的堆叠采用了CSP结构,残差块在堆叠过程中分为左右2路分支:右路的主分支进行残差块的堆叠;左路的副分支如同一个大残差边,最后将经过左右2路分支得到的特征进行拼接。
下采样模块使用的是最大池化(max pooling)操作,将特征图缩为原来一半。
2.2 特征融合网络
经过主干网络对原图进行下采样后,选取26×26和13×13两种比例的特征图进行特征融合。26×26浅层特征层包含更多的细节、位置信息,语义信息相对较弱;13×13深层特征层有着更强的语义信息,但细节和位置信息丢失较多。
为了平衡语义信息跟细节信息,TinyYOLOv4网络在进行特征融合时使用了图2所示的FPN结构,该结构是一种加强主干网络特征表达的方法,通过结合自下而上和自上而下的方式得到不同层次的特征图信息,最终获得强有力的综合特征。
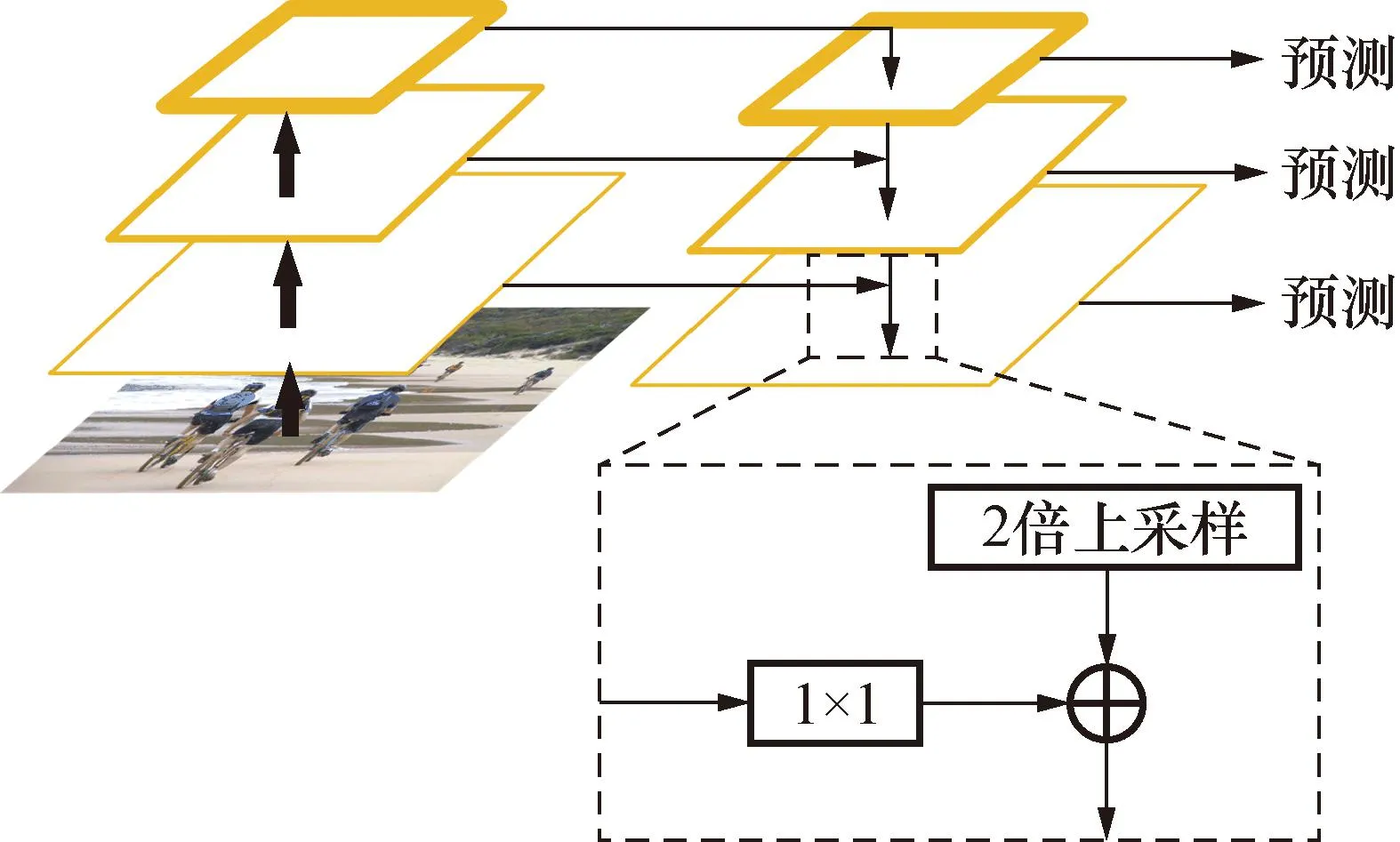
图2 FPN结构Fig.2 FPN structure
3 改进的TinyYOLOv4网络
所提出的改进TinyYOLOv4算法整体框架如图3所示,主要对3个方面进行改进:(1)改进主干网络。原网络属于轻量化网络,用于特征提取的卷积层少,导致网络对行人数据的有效特征提取不足,本文在主干部分添加2个改进的特征提取块REM模块),为了更好地聚焦行人特征,在模块中引入CBAM(convolutional block attention module)注意力机制[19],该机制很好地起到了抑制背景噪声的效果,还能赋予行人目标特征更高的权重,经实验得出该模块确实起到了较好的特征提取效果。(2)改进SPP网络。RM-block特征融合模块在SPP模块改进的基础上结合了CBAM注意力机制,横向增加了网络宽度,对检测速度影响小,可以达到增大感受野、扩展主干网络对特征的映射和接受范围的效果,从而提高检测精度。(3)引入浅层特征。原网络进行高低层级特征融合的过程中仅使用最后2层(13×13和26×26)的深层特征信息进行融合,忽略了浅层信息,导致网络对行人小目标的检测精度变低,为了解决该问题,引入浅层(52×52)特征信息,对特征融合网络进行重构,形成新的特征融合网络IFFM。同时为保证模型轻量化,改进后的网络仍保持2个特征输出层,实验证实了该方法的有效性。

图3 改进的TinyYOLOv4网络Fig.3 Improved TinyYOLOv4 network
3.1 特征提取模块REM
TinyYOLOv4原网络的主干网络较浅,难以提取足够的行人特征,从而影响了行人目标检测的精度。因此,对特征提取网络进行了加深,在原网络的基础上增加2个特征提取模块,以进一步增强行人特征提取能力,模块见图4。
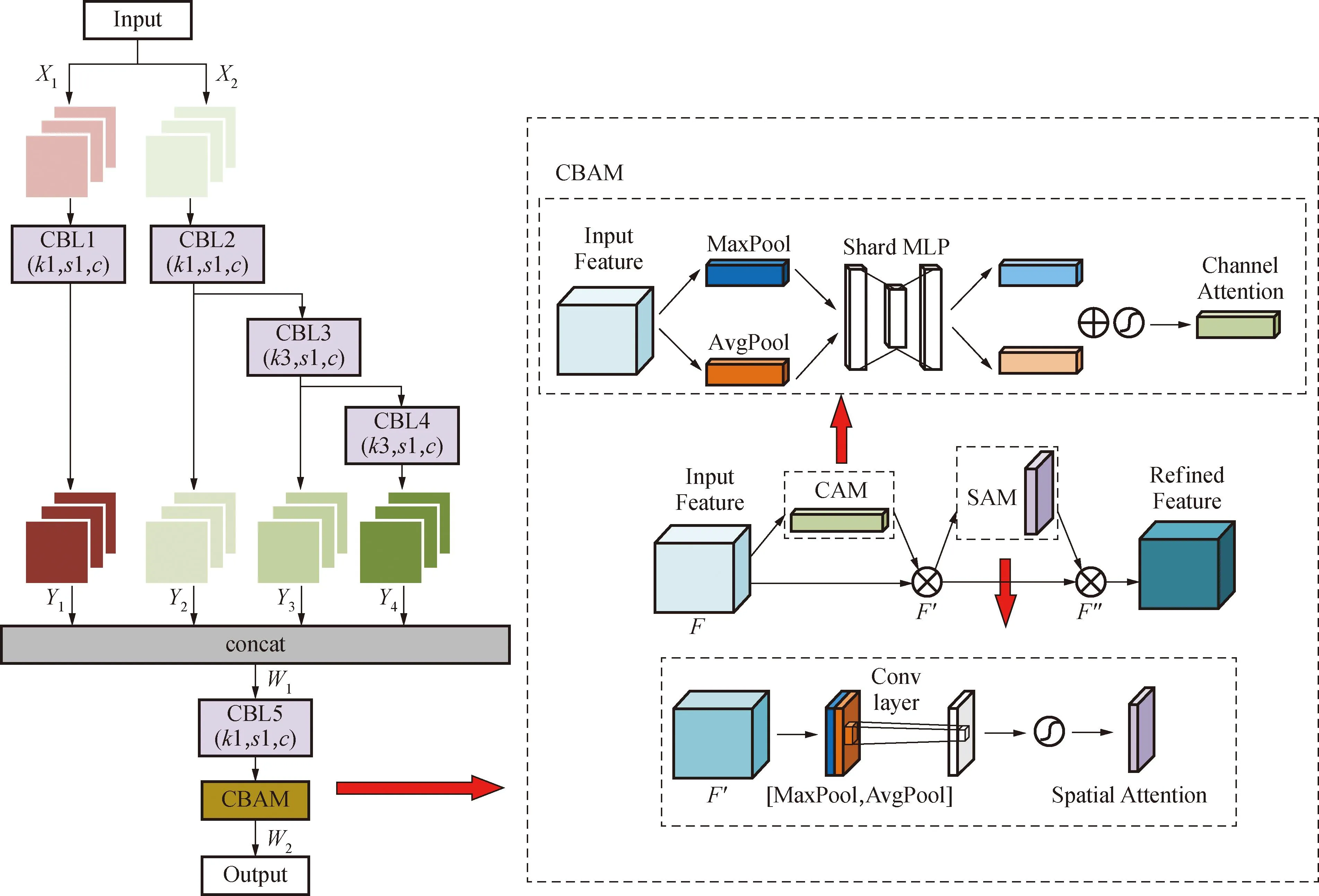
图4 REM模块Fig.4 REM module
考虑到在实际的行人检测识别过程中,目标往往会包含大量混淆的背景信息,原网络无法剔除该无效信息,从而导致训练后得到的权重包含大量背景信息,影响检测性能。受注意力机制的启发,在新增的模块中引入CBAM注意力机制来减弱背景信息的干扰。CBAM模块可以分为2部分:一部分是通道注意力块(channel attention module, CAM),负责增强特征图在通道维度上对重要特征的关注度;另一部分是空间注意力块(spatial attention module, SAM),负责增加特征图在空间维度上对重要特征的关注。输入的特征图先通过CAM将特征的空间维度进行压缩,然后经过SAM对特征的通道进行压缩,最终达到关注重点特征和抑制非必要特征的目的,增加表现力。实验得出,REM模块可以有效增强网络的特征提取能力,提高检测的准确性和鲁棒性。
特征增强模块REM具体计算过程如下:
(1)
(2)
(3)
(4)
W1=Cat(Y1,Y2,Y3,Y4)
(5)
(6)
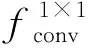
3.2 特征融合模块RM-block
为了更全面地学习多尺度目标特征,进一步增大感受野,达到提升检测精度的目的,试图在主干网络CSPDarknet53-S与特征融合网络间添加SPP模块,但该模块大大增加了网络的学习参数,故对SPP模块进行了改进,提出了新的特征融合模块(RM-block模块),详见图5。该模块相比原SPP模块不仅有更少的参数量,同时使网络有更高的检测精度。
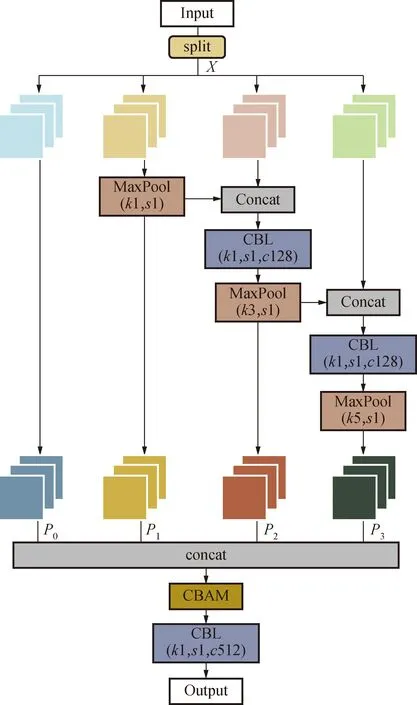
图5 RM-block模块Fig.5 RM-block Module
该模块先对输入图像进行通道分离split操作,将原来512的通道数进行4等分获得4条并行分支,各分支通道数是128。通过卷积和池化操作后,得到被增强的特征图P0、P1、P2和P3。最大池化操作中池化核大小分别为1×1、3×3和5×5,该操作起到扩大感受野的效果。图中每2个分支在进行concat拼接后,都会先利用1×1的卷积进行通道数的调整。最后将4条分支所提取到的特征进行融合。融合后经过CBAM注意力机制,该机制对于任务中较难识别的重叠、遮挡目标分配高权重来增加关注度,对不感兴趣的自然背景分配低权重加以抑制,提高不同环境下行人的识别精度。最后经过CBL模块输出特征。相比较原网络直接将行人特征送入FPN进行特征融合的策略,该模块更加充分地利用了输入的特征层信息。
RM-block模块计算流程如下:
P0=split(X)
(7)
P1=MaxPool1[split(X)]
(8)
(9)
(10)
(11)
式中:X表示输入的特征图;split表示将原通道数四等分进行通道分离操作;P0、P1、P2和P3分别表示输入特征图在经过各通道后形成的新的特征图;MaxPool表示最大池化操作,各池化核见图5;X1表示输出特征图。
3.3 特征融合网络IFFM
在对检测结果的分析中发现,小目标的检测精度极低。考虑到原网络为了更加轻量化,采用的是两个输出的方式,仅使用13×13和26×26这2个深层特征层信息,导致浅层细节信息丢失严重,然而对中小目标的检测主要依赖于浅层特征,于是本文对高低层级特征融合结构进行了重构,引入浅层特征信息,搭建了新的特征融合网络IFFM网络,该网络如下图6所示。
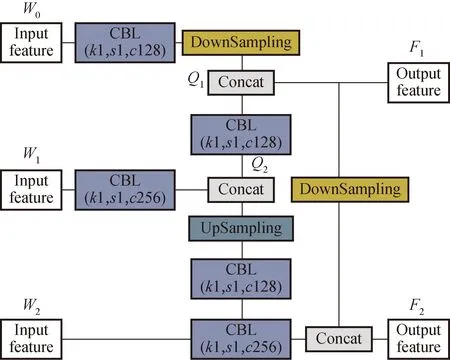
图6 IFFM网络Fig.6 IFFM network
IFFM网络使用了3个不同的特征层信息作为输入,将主干网络第2个CSP模块输出的浅层特征图W0(52×52)、第3个CSP模块输出的较深层特征图(26×26)和经RM-block模块处理后的深层特征图(13×13)作为IFFM网络的输入特征。首先对深层特征图W2进行两倍上采样,得到与特征图W1同样尺寸大小的特征图进行融合,形成新的特征图Q2;随后将浅层特征图W0进行2倍下采样,形成与Q2尺寸相同的特征图进行融合,将得到第1个输出特征图F1(即Q1);接着将特征图Q1进行2倍下采样与经过卷积处理后的W2进行融合,得到第2个输出特征图F2。该特征融合网络在将输入端的3个特征图进行融合的过程中有效引入了浅层特征,添加了更多细节信息,增加了网络对行人小目标特征的关注,达到了提升精度的效果。该网络计算过程如下:
(12)
(13)
(14)
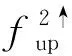
4 实验结果与分析
4.1 实验平台
使用的实验平台如表1所示。实验采用Python3.7语言编写,深度学习框架为pytorch1.7.1,实验软件为PyCharm2021。

表1 实验平台Tab.1 Experimental platform
4.2 数据集
使用的数据集选自PASCAL VOC2007和PASCAL VOC2012这2个数据集。这2个数据集包含相同的20类目标,共计21 504张图像。从2个数据集中提取了所有行人数据重新组成新的数据集VOC Person,共计8 566张图片。采用7:2:1的比例划分训练集、验证集和测试集,最终得到5 996张训练集图片、1 713张验证集图片和857张测试集图片。该数据集中行人姿态变化较大,同时背景也较为复杂,存在不同程度的遮挡,更接近现实场景,能够增强训练模型的泛化能力。
4.3 模型训练及评价指标
在对比实验和消融实验中,输入图片大小统一设为416×416;为了使模型具有更好的鲁棒性和更丰富的数据,训练过程中对数据集采用Mosaic数据增强和Mixup数据增强操作。对总损失函数进行训练优化时使用了SGD优化器,在训练过程中当计算网络损失时,采用的二值交叉熵损失(binary cross entropy,BCE)来计算置信度损失和类别损失,使用CIOU[20]计算位置损失。同时为了使网络具有更好的泛化性能、更高的准确率和防止过拟合,使用lable smooth标签平滑策略。
分别对检测精度和检测速度进行评估,使用精确率P、召回率R和平均精度AP作为评估精度的指标,使用每秒帧数FPS作为评估速度的指标。在对行人目标进行检测的过程中,TP(表示被正确识别的行人数量,FP表示将背景预测为行人的图片数量,FN表示将行人预测
为背景的图片数量。计算公式如下:
(15)
(16)
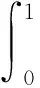
(17)
式中:P(R)代表精确率与召回率的关系曲线;下标IOU用来评价预测结果位置信息的准确程度,代表检测框与真实框之间的交并比。
4.4 消融实验结果
为了更充分、合理地验证本文算法的有效性,对改进后的REM模块、IFFM网络和RM-block模块这3部分进行消融实验。通过对测试集图片进行检测,分别计算其AP0.5、P、R和FPS,实验结果如表2所示。所提出的网络与原网络相比,整体精度提升了6.7%。其中REM模块对检测精度的提升贡献最大,精度提升了4.1%;单独引入浅层特征或使用RM-block模块使精度分别提升了1.7%和3.0%。综上,所改进的3个模块在保证实时性的前提下,均可有效提高检测精度。
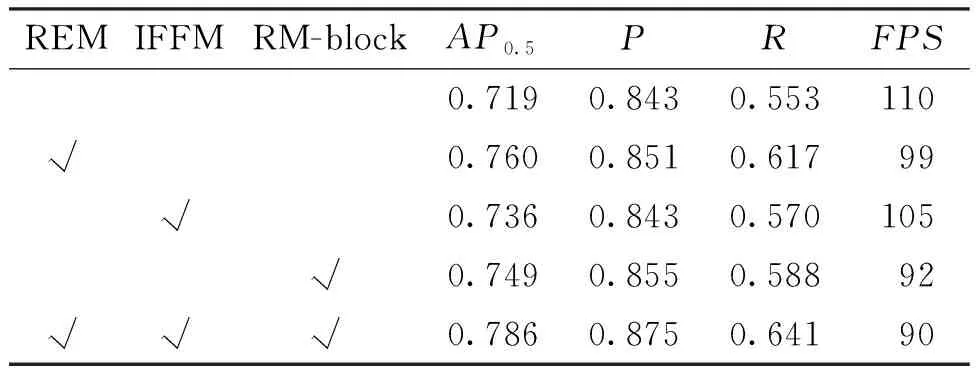
表2 检测结果消融性分析Tab.2 Ablation analysis of test results
4.5 对比实验结果
为进一步验证所提算法的有效性,基于VOC Person数据集,将所提算法与当下用于行人检测的主流算法(Faster R-CNN[10]、SSD[12]、YOLOv3[14,21]、TinyYOLOv7[22]、TinyYOLOv4[23])进行比较,对比结果见表3。可以看出,所提算法的检测精度最高,达到了78.6%。从整体上看,所提算法在检测速率方面也具有很大优势,FPS高达84 帧/s,满足实时检测需求。
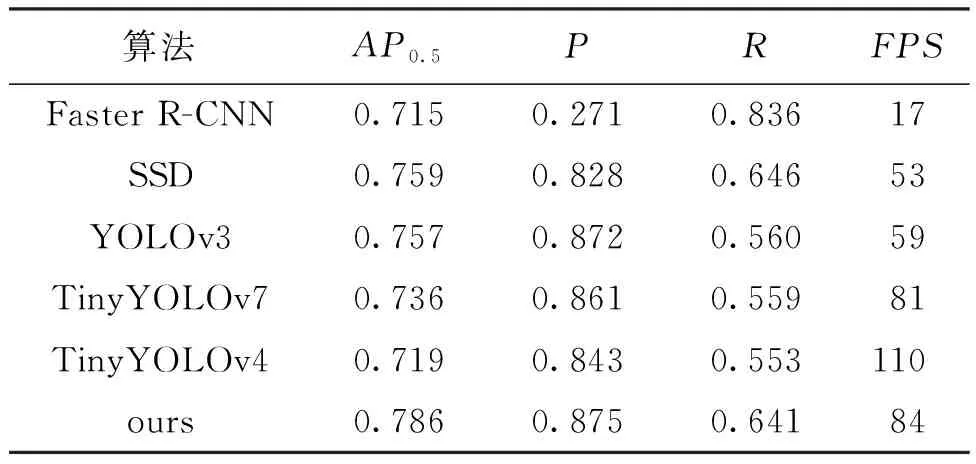
表3 各算法结果对比Tab.3 Comparison of results of various algorithms
为了直观地展示改进后的算法与表3中所列其它主流算法的行人检测效果,在VOC Person测试集中筛选出4幅较难检测的行人图片进行可视化,检测结果对比如图7所示。其中第1幅图中存在较难检测的行人小目标和背景干扰,Faster R-CNN误将白色障碍物检测为行人,其它主流算法无法将小目标有效地检测出来,从图中看出所提算法可以有效降低检错率和小目标漏检率。第2幅图中由于行人分布密集使得检测变得困难,Faster R-CNN等主流算法存在多处漏检情况,本文算法能够较好地提高密集场景下行人检出率。第3、4幅图中包含背景光照不一和人员遮挡等情况,从而导致较高的误检率和漏检率,对比所提算法可以更准确地将被遮挡的行人检测出来。综上,从图片可视化角度可以直观看出所提算法相较于表3其它主流算法有更好的检测效果。

图7 本文算法与其它主流算法检测结果对比Fig.7 Comparison of detection results between this algorithm and other mainstream algorithms
5 结 论
本文针对当前行人检测领域存在的由于背景光照强度不一、人员密集和行人目标尺度小而导致的检测率低的问题,在TinyYOLOv4的基础上,提出一种改进主干特征提取网络和特征融合网络的轻量级行人检测算法。首先通过在主干网络中引入包含注意力机制的REM特征提取模块聚焦行人特征同时抑制背景噪声,提升网络提取有效特征的能力。其次搭建新的特征融合网络IFFM,通过引入浅层特征增加细节信息,实现对小目标行人检测精度的提升。最后使用改进后的RM-block特征融合模块,在对特征图进行融合的过程中给予行人特征更高的权重和关注度,融合得到更有效的行人特征。在VOC Person数据集上进行实验表明,所提出的算法相比于原算法和其它经典算法均有一定的优势所在,准确率、召回率和平均精度分别达到了87.5%、64.1%和78.6%,同时保持84 帧/s远超实时要求的30 帧/s。在接下来的工作中将继续对精度的提升展开研究,在满足实时检测和轻量化的条件下,推动模型落地。
