基于YOLOv5s网络改进的钢铁表面缺陷检测算法
2024-03-14杨涛刘美孟亚男张斐刘世杰莫常春
杨涛,刘美,孟亚男 ,张斐 ,刘世杰 ,莫常春
(1.吉林化工学院信息与控制工程学院,吉林吉林 132022;2.广东石油化工学院自动化学院,广东茂名525000;3.东莞理工学院机械工程学院,广东东莞 523419;4.湖南科技大学机械设备健康维护湖南省重点实验室,湖南湘潭 411201;5.大连交通大学机车车辆工程学院,辽宁大连 116028)
0 前言
钢铁是国家基础设施必不可少的材料,在建筑、桥梁及机场、手术刀、轴承滚珠以及精密部件中均可见其应用。然而从生产过程中操作不当到自然界氧化腐蚀,再到使用过程中造成的自然磨损,钢铁表面的缺陷伴随着钢铁存在,一些微小的表面缺陷可能导致重大的事故,确保钢铁表面质量尤为重要。因此,针对检测精度高、速度快和模型体积小的钢铁表面缺陷检测方法的研究具有重要意义。
传统钢铁表面缺陷检测方法包括人工抽检法、红外检测法和基于图像处理的方法。人工抽检法是质检工人以目测的方式随机抽取样本判断钢铁表面缺陷,该方式效率低、漏检率高、误检率高。沈立华等[1]在红外热像仪分辨率允许的前提下,采用单面法红外检测钢板内面损伤情况;吴秀永等[2]基于Gaber小波KLPP算法提出一种特征提取方法;赵久梁等[3]为了解决钢铁表面缺陷图片边缘难以检测到的问题,提出基于小波变换模极大值的多尺度边缘检测算法;杨永敏等[4]提出一种基于超熵和模糊集理论的图像分割算法。尽管传统方法对钢铁表面缺陷检测做出了贡献,但仍存在检测效率和检测精度低等问题。
近年来,深度学习技术快速发展,采用目标检测算法的钢铁表面缺陷检测方法相继被提出。基于深度学习的目标检测算法分为两类:(1)是双阶段目标检测算法,代表算法有Faster R-CNN[5];(2)是单阶段目标检测算法,代表算法有SSD[6]、YOLO[7]系列。韩强等人[8]基于Faster R-CNN算法,采用检测网络对区域建议框进行分类回归;LI等[9]基于YOLO网络模型改进钢铁表面缺陷检测的模型,该模型能够有效提高钢铁表面缺陷的召回率;李维刚等[10]基于YOLOv3目标检测算法进行网络结构的改进,采用K-means聚类获得数据集的初始锚框,将浅层特征信息和深层特征信息融合,改进后模型的mAP值明显提升;叶欣[11]基于YOLOv4目标检测模型进行改进,通过替换损失函数为EIoU,同时采用自适应空间特征融合结构,提高了冷轧带钢表面缺陷的检测精度。
针对钢铁表面缺陷检测的现实需求,本文作者提出基于YOLOv5s算法的钢铁表面缺陷检测改进算法。通过改进骨干网络、颈部网络和替换损失函数,以提高算法检测精度、检测速度并降低模型复杂度,最后在NEU-DET数据集上进行实验验证。
1 YOLOv5s理论基础
YOLO系列算法中性能最优良的一类算法为YOLOv5系列,它是基于卷积神经网络搭建模型进行一系列改进,使得算法既能实现较快的检测速度,也能达到较高的检测精度。YOLOv5系列算法包括YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其中YOLOv5s体积最小,但检测精度较低。随着模型体积的增大,YOLOv5系列的检测精度逐级提高,体积最大的是YOLOv5x,其精度也最高。文中旨在获得一个轻量化且精度较高的目标检测算法,因此采用YOLOv5s作为改进的基准模型。
YOLOv5s模型由4个部分组成:输入端、骨干网络、颈部网络和检测头。输入端将图片进行预处理操作方便网络处理,图片送入骨干网络中进行特征提取。骨干网络主要由Focus模块、卷积模块、CSP(n)模块以及空间金字塔池化(Spatial Pyramid Pooling,SPP)[12]模块构建而成。Focus模块对输入的特征图进行切片操作,以减少参数计算和CUDA的内存使用;CSP(n)结构中有2个特征通道,分别进行Bottleneck操作和卷积操作,2个特征通道的输出经过Concat处理使模型学习更多特征;SPP模块有3个不同尺度的MaxPooling(5×5,9×9,13×13),保证网络在输入图像大小随机的情况下输出固定大小的特征图。
颈部网络包括特征金字塔网络(Feature Pyramid Ne-tworks,FPN)[13]和金字塔注意力网络(Pyramid Attention Networks,PAN)[14],通过结合这2个网络,颈部网络更好地融合了浅层特征信息和高层语义信息;检测头输出3个尺度的模型预测信息,包括预测框的坐标信息、类别信息以及置信度信息。图1所示为YOLOv5s模型结构。
2 算法优化改进
2.1 融合SE通道注意力模块
基于深度学习的注意力模仿人类视觉注意力机制。人观察某个对象时会自动忽略背景中的无关信息而将注意力集中在观察对象上。在自然语言处理领域,注意力机制的运用取得了巨大成功,因此,学者们开始研究它在视觉领域应用的可能性。通道注意力机制SENet[15]是注意力机制在视觉领域应用的重大突破,它赋予特征通道中某些通道更大的权重,抑制特征通道中无用的干扰信息,以增强网络特征提取能力。在2017年ImageNet大赛中,SENet荣获冠军,其Top5 error 仅有2.251%。目前,SENet已经成为分类、检测、分割任务中最经典最常用的注意力网络。基于以上原因,文中在YOLOv5s网络的特征提取中融入SE通道注意力模块,以增强网络对钢铁表面缺陷特征的提取能力。
图2所示为SE通道注意力模块结构。输入图像x经过骨干网络中卷积等模块处理后输出H×W×C大小的特征图u,其中(H,W)表示特征图的高宽,C表示特征图通道数,随后u被送入SE通道注意力模块中做处理。SE通道注意力模块主要包括3个操作,首先是Fsq(·)操作(Squeeze),将输入特征图沿着空间维度做全局平均池化,输出特征通道变成一个具有全局感受野的实数,通道数不变,如公式(1)所示:
(1)
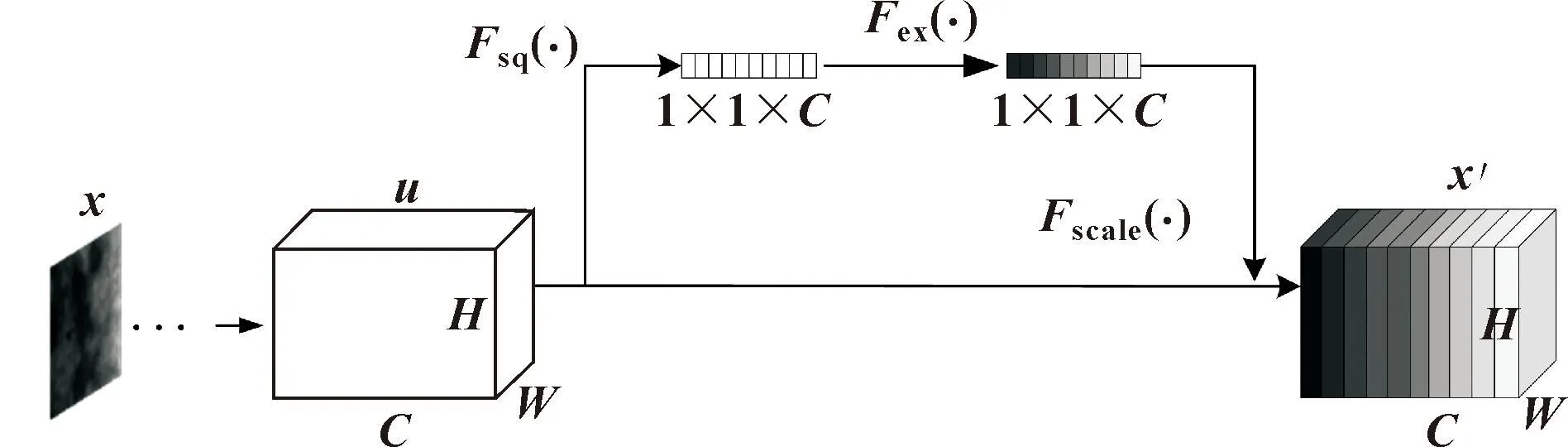
图2 SE通道注意力模块结构
式中:uc表示通道数为c的特征图;(i,j)表示特征图坐标;H、W分别表示特征图长、宽;zc为输出的结果。
经过Squeeze处理,Fex(·)对输入做Excitation操作。基于特征通道间的相关性,zc通过一层全连接操作将通道数变为原来的1/r,送入ReLU激活函数增加非线性,再经过一层全连接层处理恢复为输入通道数,经过Sigmoid激活函数生成每个特征通道权重,如公式(2)所示:
s=Fex(zc,W)=∂(g(W1zc))=∂(W2(δ(W1zc)))
(2)
式中:W1为第一层全连接层权重;δ为ReLU激活操作;W2为第二层全连接层操作权重;∂为Sigmoid激活操作;r为缩放因子;s为输出的每个特征通道的权重。
在模块的最后,对两路输入做Reweight操作Fscale(·),将求得的每个通道特征的权重加权到原特征图上得到x′,如公式(3)所示:
x′=Fscale(uc,s)=s·uc
(3)
2.2 融合STR多头自注意力模块
多年以来计算机视觉(Computer Vision,CV)领域的主导网络模型一直为CNN,在自然语言处理领域(Natural Language Processing,NLP),Transformer以其优异的性能已经成为主导模型[16],学者们尝试将之前NLP领域中的transformer模型运用到CV领域中。视觉自注意力机制(Vision Transformer,ViT)成为了该工作的基础,它在图像分类问题任务中取得了很好的效果,但由于没有考虑文本信号和视觉信号的差异,并不适合目标检测任务[17]。滑窗自注意力机制(Swin Transformer,STR)在ViT的基础上考虑视觉信号的特点,使得网络可以应用于复杂的视觉任务[18]。在基于COCO数据集的目标检测任务中,采用STR构建的网络在多个维度性能优于采用CNN构建的网络。
经过骨干网络提取特征后,钢铁表面缺陷的边缘纹理等细节特征信息丢失严重,考虑STR架构性能优于CNN架构,因此文中选择STR作为一种探索式应用,以增强颈部网络部分缺陷边缘纹理等细节特征的比重。图3所示为 STR结构。
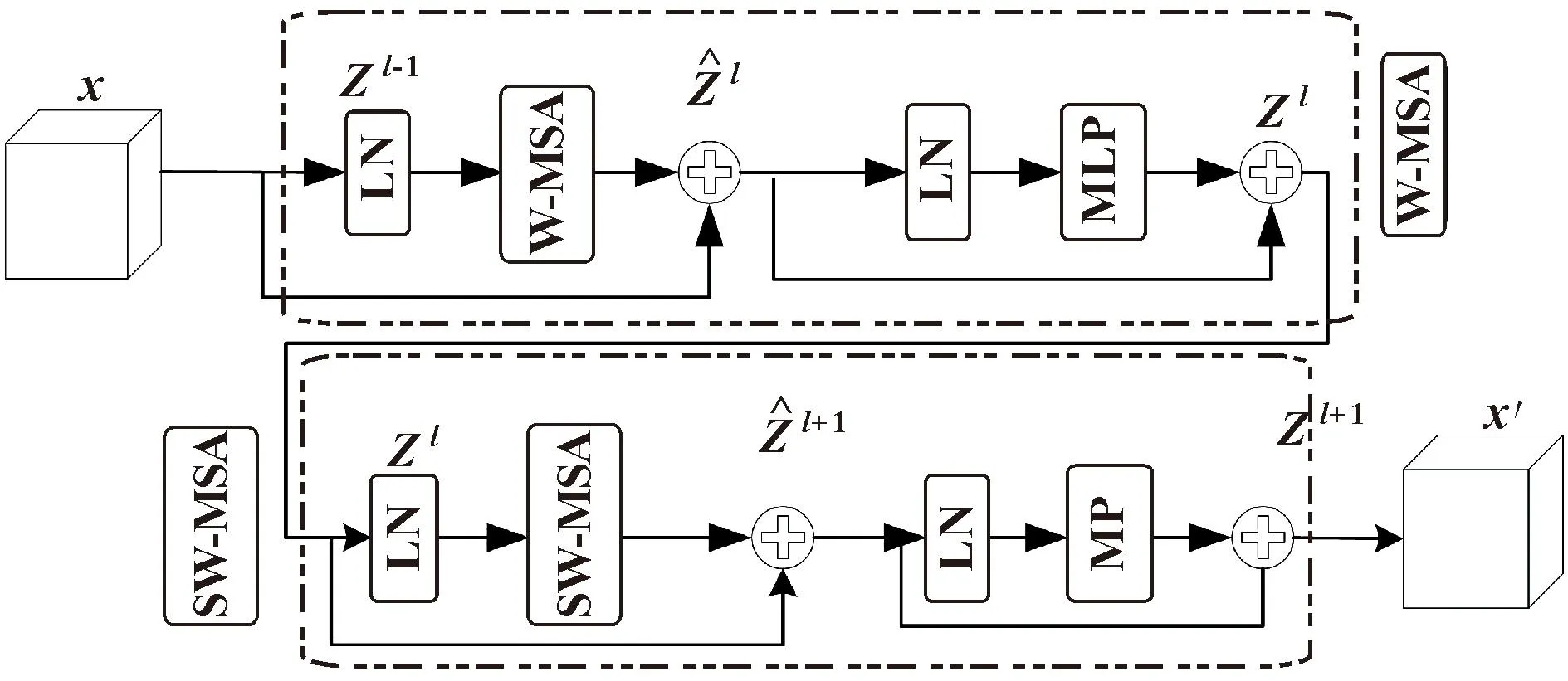
图3 STR结构
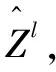
(4)
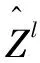
(5)
W-MSA的输出结果Zl进入SW-MSA模块,通过LN层归一化进入SW-MSA层做窗口信息交互后计算注意力,如公式(6)所示:
(6)
输出结果在SW-MSA模块最后经过MLP层处理输出结果Zl+1,如公式(7)所示:
(7)
2.3 改进损失函数
定位框回归预测是目标检测的主要任务之一。YOLOv5s的分类损失函数采用二元交叉熵(Binary Cross-Entropy,BCE),置信度损失采用Logits损失函数,定位框损失函数采用CIoU。尽管CIoU使得预测框回归更为精确,但基于距离、重叠区域以及长宽比的设计没有考虑预测框与真实框中心点的方向问题,二者相对位置存在很大自由,导致预测框和真实框回归收敛速度较慢,进而影响模型的整体性能。SIoU考虑两框中心点角度因素和两框形状因素,重定义距离公式[19],有效加快预测框回归收敛速度,提升模型检测精度。因此文中采用SIoU替代CIoU。图4所示为预测框与真实框相对位置。
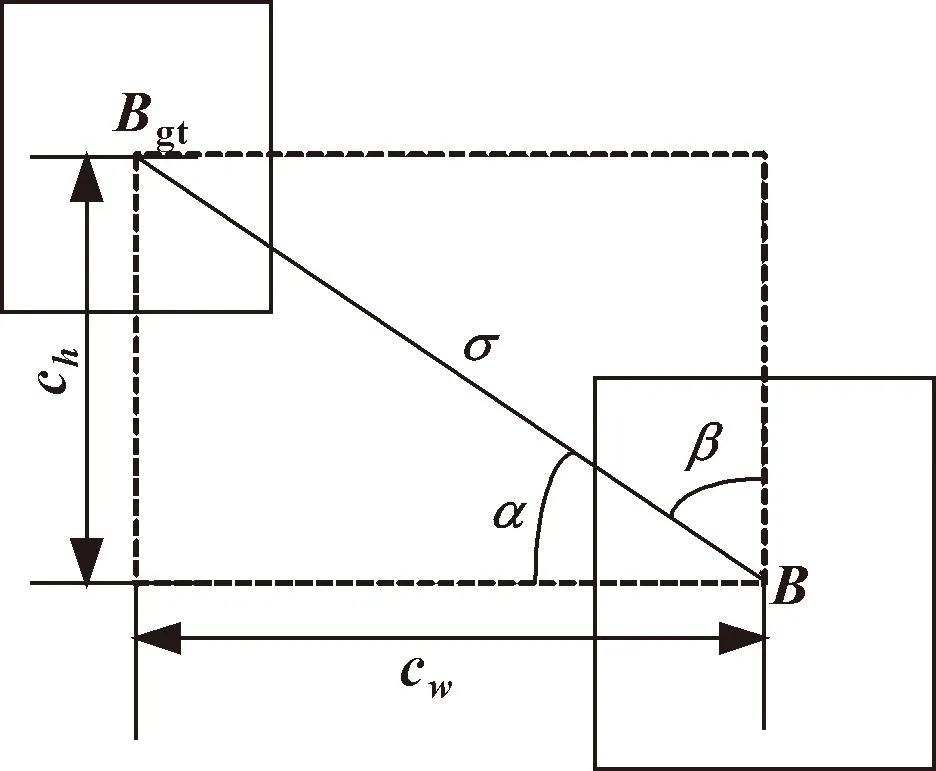
图4 预测框与真实框相对位置
图中:Bgt表示真实框;B表示预测框;α为预测框与真实框中心点的角度;ch、cw分别表示两框中心点构成矩形的长、宽;σ表示中心点的距离。
以下是SIoU的计算过程,如公式(8)—(11)所示:
δSIoU=1-δIoU+(Δ+Ω)/2
(8)
(9)
(10)
Δ=∑t=x,y(1-e-γρt)=2-e-γρx-e-γρy
(11)
其中:δIoU表示预测框与真实框的交并比;Δ为将角度成本考虑在内的距离公式;Ω表示形状成本。
(12)
(13)

文中基于YOLOv5s算法进行改进。改进点有以下3点:(1)为了增强算法对钢铁表面缺陷特征的提取能力,在骨干网络融入SE通道注意力模块;(2)骨干网络特征提取后,特征图浅层缺陷边缘纹理等细节信息丢失严重,因此融入STR模块以增强颈部网络缺陷边缘纹理等细节特征的比重;(3)为了缩短网络预测框回归收敛过程,引入SIoU替换CIoU。改进算法如图5所示,图中分别使用①②③指明改进点在网络中的位置。
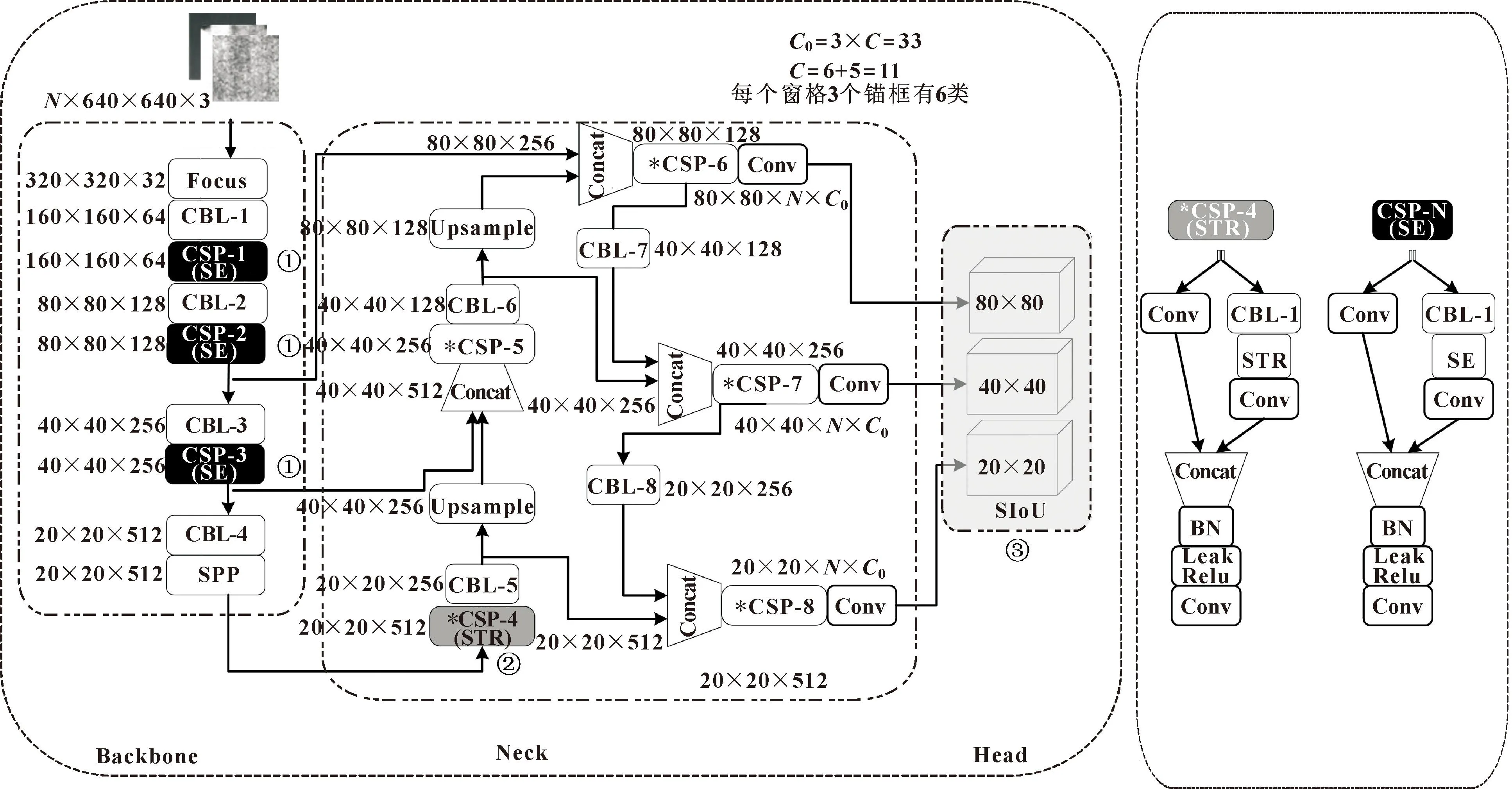
图5 改进算法模型结构
3 实验与结果分析
3.1 实验环境与数据集
文中实验环境采用Windows10操作系统,内存为32GiB,CPU型号为12th Gen Inter(R) Core(TM) i9-12900 3.19 GHz,显卡型号为NVIDIA GeForce RTX 3090,采用PyTorch1.11.0作为深度学习框架,Python版本为3.8.13,CUDA版本为11.3,cuDNN版本为8200。实验使用东北大学宋克臣团队[20]制作的NEU-DET数据集,共有1 800张钢材表面缺陷图像。模型训练过程中将数据集分为训练集、验证集和测试集,比例为8∶1∶1。使用Labelimg标注工具对数据集进行标注,数据集有裂纹(Crazing,Cr)、 夹杂(Inclusion,In)、 斑块(Patches,Pa)、划痕(Scratches,Sc)、麻点(Pitted_surface,Ps)、氧化铁皮(Rolled-in_scale,Rs)等6类缺陷类型。
3.2 性能评估指标
文中采用mAP@0.5(IoU阈值为0.5时各个类别平均AP值)评价模型的检测精度,采用每秒检测图像数(FPS)评估模型的检测速度。其他评估指标有:模型权重体积(Weights)、GFLOPs、精确率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP),表达式如公式(14)—(16)。模型权重体积表示模型权重数大小,GFLOPs表示10亿次浮点运算,用于衡量模型计算量,FPS表示模型每秒处理图片的数量;P表示所有预测为正样本的结果中预测正确的比率;R表示所有正样本中被正确预测的比率;AP表示在不同召回率下精确率的平均值。对各个类别的AP求均值得到mAP(所有类别的平均精度),如公式(17)所示。
P=PT/(PT+PF)
(14)
R=PT/(PT+NF)
(15)
(16)
(17)
式中:P表示精确率;R表示召回率;N表示总类别个数;PT表示正样本预测出正样本数量;PF表示负样本预测出正样本数量;NF表示正样本预测出负样本数量。
3.3 实验方案
文中以YOLOv5s算法作为改进基准算法。首先采用初始超参数、初始锚框组合和初始权重实验,实验结果显示:mAP@0.5较低,原因可能是初始超参数组合不适合此数据集。因此在实验过程中,采用遗传算法迭代5次获得基于此数据集的一组超参数,如表1所示。mAP@0.5值为77.1%,如表2所示。最后基于钢铁表面缺陷检测任务设计消融实验改进算法,并对实验结果进行对比,整体实验方案如图6所示。

表1 进化超参数

表2 改进点消融实验
表中的批次大小和训练轮次根据实验效果设定。
3.4 实验结果分析
3.4.1 改进点消融实验
为验证单个改进点对模型性能的影响,文中进行了消融实验,对每个改进点在相同条件下进行训练、测试,得到5种改进模型的性能,如表2所示。
G1表示原算法未作改动;G2表示在原算法基础上使用进化后的超参数;G3表示在G2的基础上替换CIoU为SIoU;G4表示在G3的基础上在颈部网络添加STR模块;G5表示在G4基础上在骨干网络中融合SE模块。
由表2可知:采用进化后的超参数,mAP值从74.9%提升至77.1%,但模型检测速度下降,说明模型精度提升,但网络计算量增大。在G3中,模型mAP值从77.1%提升至77.9%,模型检测速度达到111FPS,说明引入SIoU后模型的精度略微提升,但大幅加快了预测框回归收敛的速度。在G4中,模型mAP值从77.9%提升至79.1%,提升幅度为1.2%,表明STR模块有优良的提取细节特征信息的能力,但网络趋向复杂。在G4中,模型mAP继续提升,从79.1%提升至80.4%,引入SE模块进一步加强了骨干网络提取特征的能力,虽然检测速度低于G4但仍高于YOLOv5s算法。
3.4.2 检测精度对比实验
图7所示为改进算法与YOLOv5s在各个类别上检测性能的对比。可知:与YOLOv5s相比,改进算法在多种缺陷类别中的检测精度提升显著,尤其对于缺陷Cr和Rs。Cr的检测精度从47.8%提升至59.0%,提升了11.2%,Rs的检测精度从51.6%提升至69.2%,提升了17.6%。算法的mAP值较YOLOv5s提升了5.5%。

图7 检测精度对比
3.4.3 泛化能力对比实验
算法改进完成后进行了改进算法的泛化能力的验证。从数据集6种类别中随机挑选各一张缺陷图像,共6张,先后使用YOLOv5s算法和改进算法对6张图片进行测试,结果如图8所示。实验结果表明:相比YOLOv5s算法,改进算法表现出更好的泛化能力。

图8 检测结果对比
3.4.4 算法对比实验
为进一步验证改进算法在检测精度、检测速度以及模型复杂度等方面的优势,文中选择Faster R-CNN、SSD、YOLOv3以及YOLOv5系列在FPS、GFLOPs、模型体积以及mAP等多个维度展开实验,表3是实验结果。

表3 不同算法在NEU-DET数据集上性能对比
由表3可知:Faster R-CNN的mAP值为78.0%,模型体积大小为108 MB,模型计算量为307GFLOPs,检测速度仅有27FPS,符合双阶段目标检测算法的性能预期;SSD模型体积有所降低,检测精度较Faster R-CNN降低明显,检测速度达到148FPS;YOLOv3模型体积为235 MB,其检测精度并没有较大提升;随着模型体积增大,YOLOv5系列算法的检测精度提升,模型体积最小的为YOLOv5s,其检测精度也最低,模型体积最大的YOLOv5l精度达到78.1%。相比YOLOv5s,文中改进算法模型体积从14.4 MB降到了13.2 MB,降低了约8.3%,模型计算量降低约4.3%,检测速度提升了8.7%,mAP值提升5.5%。以上算法中,改进算法的检测精度最高,模型复杂度最低,检测速度虽比SSD低但仍能满足实时检测的要求。
改进算法在检测精度、模型体积以及检测速度等性能上得到了较大提升,可以满足实时条件下对钢铁表面缺陷做精准定位识别分类检测的任务。
4 总结
鉴于YOLOv5s算法在钢铁表面缺陷检测任务中检测精度低、检测速度较慢等问题,提出基于YOLOv5s的改进算法。由于SE通道注意力模块提取图像重要特征信息的优良表现,在骨干网络中融入该模块;在颈部网络中融入STR模块以加强高层特征中边缘纹理特征等缺陷细节的比重;与CIoU相比,SIoU在保证算法精度的同时能加快预测回归的速度,因此算法采用SIoU替换CIoU;提出的改进算法在检测精度、检测速度和模型复杂度等三方面都优于原算法,但改进算法对Cr和Rs的检测精度仍较低且算法鲁棒性有待提高,后续将针对这两点展开工作。总体而言,提出的改进算法可以满足实时条件下对钢铁表面缺陷做精准定位识别分类检测的任务。
