基于动态专家会议算法的刀具磨损度在线识别
2024-03-14张峰陈乃超邢海燕
张峰,陈乃超,邢海燕
(山东劳动职业技术学院,山东济南 250300)
0 前言
数控机床被誉为工业母机,在数控加工过程中,刀具与工件的挤压与摩擦使刀具出现磨损、变形甚至断裂等问题[1]。刀具变形与断裂不仅影响工件的加工质量,而且可能导致停机甚至威胁工人生命安全[2]。因此,准确把握刀具的磨损状态、及时更换刀具具有重要的经济意义和安全意义。
刀具磨损状态监测方法可以分为机制建模法、经验推理法与数据驱动法等。机制建模法是基于大量的实验数据,建立切削参数与刀具磨损量之间的映射关系[3],该类方法的局限性较大,一是需要大量的实验数据支撑,二是模型仅针对某一工况适用,不具备普遍适用性,改变工艺参数后需重新实验和建模。经验推理法是将专家经验与知识转化为推理规则[4],并基于规则对刀具磨损状态进行识别的方法,最常见的经验推理法为专家系统[5]。数据驱动法是人工智能在刀具磨损状态监测中的应用成果,包括相对浅层的机器学习[6]和深度学习[7]网络2类。文献[8]基于专家经验和模糊理论设计了模糊专家系统,并将它应用于铣刀的磨损预测中,具有较高的预测精度。文献[9]基于马尔科夫模型、支持向量机与神经网络算法拟合了刀具磨损模型,该模型能够较为精确地预测出刀具磨损状态。文献[10]以自触发方法实现了振动信号、主轴频率等多源信号的同步采集,采用皮尔逊积矩相关系数选择了具有强关联的特征参数,并基于深度卷积神经网络识别刀具的磨损状态。上述研究在各自设定的背景下取得了较高的刀具磨损监测精度。
随机森林算法作为一种机器学习方法,在轴承故障诊断、刀具磨损度监测等分类问题中应用较为广泛[11-12],与支持向量机等方法相比,随机森林算法实现了由“独裁式”分类向“众人投票”民主式分类的转变,有效提高了分类系统的鲁棒性和准确性。但是随机森林算法中每个随机树在投票时具有相同的表决权,这是一种完全民主、无差别对待的投票方式,而在现实中,为了提高决策的准确度,专家表决权应当重于普通民众。
针对随机森林算法存在的问题,参照随机森林算法思想,本文作者提出一种新的决策算法,命名为动态专家会议算法。该算法将决策树视为决策专家,专家决策权重根据其历史决策正确率确定,即专家决策权是动态的、具有个体差异性的。并将动态专家会议算法应用于刀具磨损度识别中,最后通过实验验证该方法的可行性。
1 刀具磨损机制与监测信号确定
1.1 刀具磨损机制
刀具磨损分为非正常磨损和正常磨损两类。其中,非正常磨损是由冲击载荷不均匀、切削受热不均匀、切削液浇注不均匀及高温高压作用等导致的,主要表现形式为刀具崩碎、崩刃、热裂和坍塌等。刀具正常磨损主要表现为前刀面磨损、后刀面磨损、前后刀面同时磨损等。前刀面磨损是当切削深度过大或速度过快时,因热量散失不及时而产生的高温高压,使得前刀面出现月牙洼。随着月牙洼面积的增大,刀具面临断刃风险。后刀面磨损是由后刀面与工件表面强烈摩擦引起的,当切削速度慢或切削深度较浅时,前刀面磨损不一定存在,但是后刀面磨损贯穿于整个刀具寿命阶段。因此,一般基于后刀面的磨损情况划分刀具磨损阶段,如图1所示[13]。

图1 刀具磨损阶段划分
图1中,在初始磨损阶段,新刀具的切削刃非常锋利,后刀面与工件接触面积小、接触应力大,另外新刀具表面相对粗糙,因此刀具磨损较快。在正常磨损阶段,刀具表面的不平整度得到改善,且刀具后刀面与工件表面接触面积增大,接触应力相对减小,因此处于平稳磨损阶段。在剧烈磨损阶段,由于刀具变钝,切削力、温度和摩擦都急剧增大,使得磨损速度加快。
1.2 监测信号确定
随着刀具磨损的不断加深,铣削加工过程中的切削力、温度、振动、切削功率等参数都会随之变化,且不同的物理信号、测试方向与刀具磨损状态的相关性也不同。
研究发现:从物理信号种类讲,与刀具磨损状态相关性由强到弱依次为切削力、切削功率、振动信号、声信号[14];从敏感方向讲,与刀具磨损状态相关性最强的方向为切削方向,其次为切削方向垂直方向。不同类型信号采集及优缺点如表1所示。

表1 监测信号优缺点分析
在选择监测信号类型时,应当考虑试验设备尺寸、实验室环境噪声、设备成本等诸多因素。
1.3 刀具磨损度识别框架
文中设计的刀具磨损度识别流程框架如图2所示,主要包括多源信号采集、多指标特征提取和基于专家会议的磨损度识别3个步骤。

图2 刀具磨损识别流程框架
步骤1,多源信号采集。设定采样频率、采样时长,采集刀具铣削过程中的切削力信号、振动信号等;
步骤2,多指标特征提取。对切削力信号、振动信号进行互补集合经验模态分解(Complementary Ensemble Empirical Mode Decomposition,CEEMD),并提取各IMF分量的多指标特征,根据多指标特征在刀具不同磨损程度下的区分度,确定多指标特征对刀具磨损度的敏感度;
步骤3,基于动态专家会议算法的磨损度识别。将训练集样本输入到专家会议算法中,训练专家会议算法参数。而后将测试集输入到专家会议算法中,得到测试集的磨损度识别结果。
2 基于CEEMD的多指标特征矩阵
首先对采集信号进行CEEMD分解,得到多个IMF分量,而后提取IMF分量中的I-kazTM系数、功率谱熵、标准差等参数组成多指标特征矩阵。
2.1 CEEMD分解原理
EEMD分解的前提假设是“多组白噪声叠加近似为0”,但是当叠加次数不够多时,白噪声无法忽略不计[15]。这必然增加了EEMD分解时的计算负担。为了解决这一问题,使用较少次数的叠加将白噪声降低到可忽略程度,CEEMD算法将互补的正负白噪声作为辅助噪声加入到源信号x(t)中,表达式为
(1)
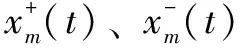
(2)

将2M次分解得到的IMF分量进行集合平均,得第k个分量为
(3)
按照上述分解方法,CEEMD分解得到的IMF分量为
(4)
式中:r(t)为源信号x(t)分解得到的余项。
2.2 多指标特征矩阵提取
2.2.1 改进I-kazTM系数
I-kazTM系数由I-kaz指数发展而来,可以用于表征数据分布的散度。首先将信号分解为低频(Low Frequency,LF)、高频(High Frequency,HF)、极高频(Very-high Frequency,VF)3个范围,对应频率f范围分别为0~0.25fmax、0.25fmax~0.5fmax、≥0.5fmax。则I-kazTM系数计算式为

(5)

(6)
式中:NL为低频范围数据量;xLn为低频范围信号;μL为低频范围信号均值。
为了将I-kazTM系数应用于CEEMD分解得到的IMF分量,对I-kazTM系数计算式进行适应性改进,将定义中的低频、高频、极高频改进为IMF分量各段频率,则I-kazTM系数为
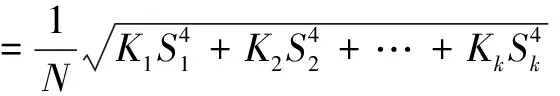
(7)

标准差可以表征信号分布的离散程度,不同的刀具磨损状态信号在不同频段上的离散度不同,因此将标准差作为一个特征指标,表达式为
(8)
2.2.2 功率谱熵
从本质上讲,功率谱熵是频域的信息熵,用于表征功率谱分布的混乱度。在不同刀具磨损状态下,测量信号在不同频段上的规律性不同,因此使用功率谱熵对这种规律性进行度量。
计算功率谱的概率密度函数pa为
(9)
式中:S(fa)为频率为fa分量信号的光谱能量;A为快速傅里叶变换得到的频率数量;Na为数据长度;X(ωa)为源信号傅里叶变换的角频率ωa分量。
基于概率密度函数pa可以得到信号功率谱熵H为
(10)
功率谱熵H越大表示频率分布的不确定性越大,即越混乱;H越小表示频率分布的不确定性越小,即越有规律性。综合上述分析,提取源信号的改进I-kazTM系数、标准差、功率谱熵等组成多指标特征矩阵[Z∞,S,H]。
3 动态专家会议决策算法
3.1 随机森林算法分析
随机森林算法的基本结构是决策树,在决策时遵循少数服从多数的原则,其原理如图3所示。对于具有J个决策树的森林,首先使用Bootstrap随机、有放回抽样法从训练集抽样出J个训练子集,记为T1,T2,…,TJ。对于训练子集Tj,随机选择其特征子集,得到特征矩阵的随机子空间,并对决策树进行训练。
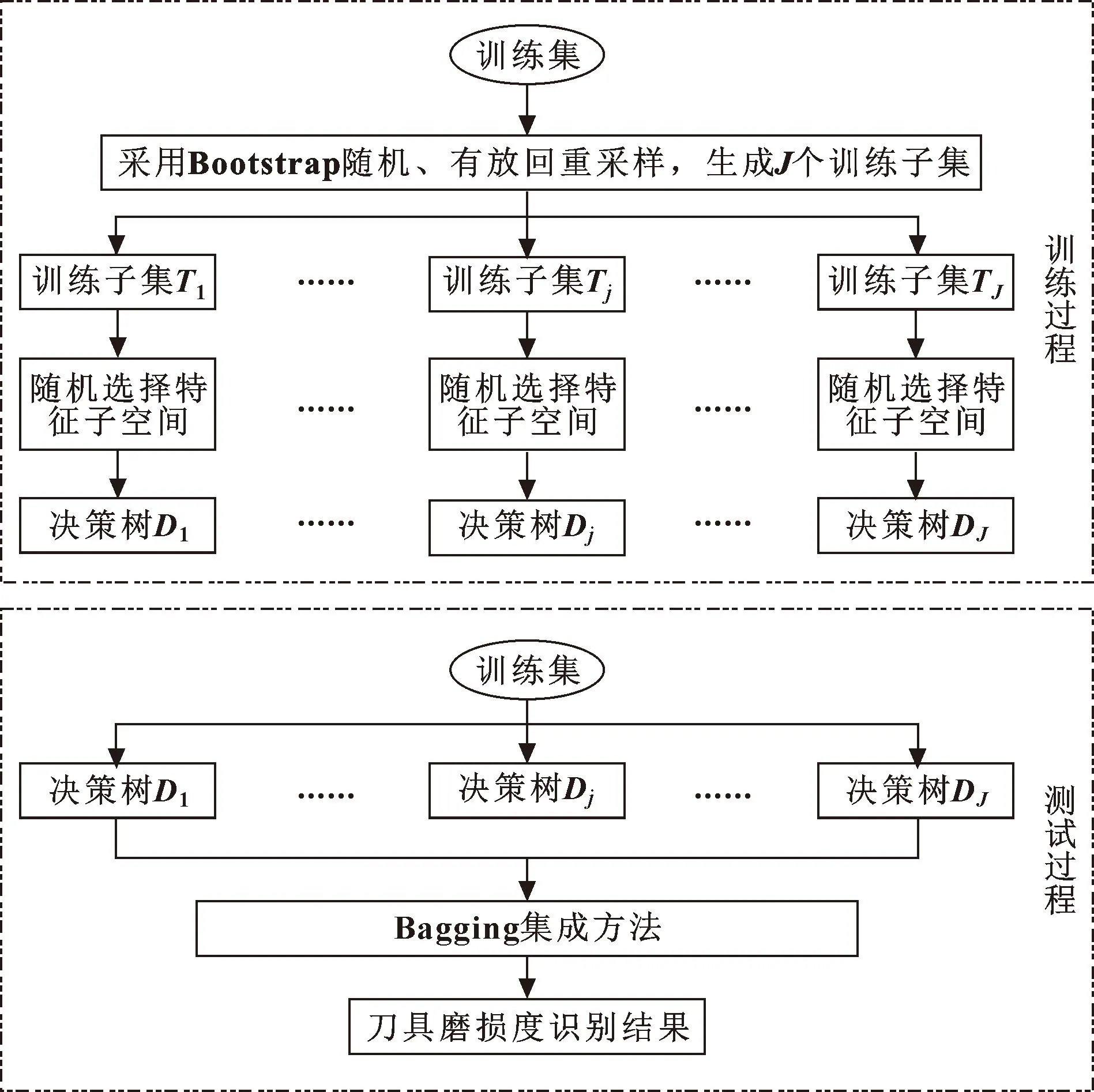
图3 随机森林算法原理
将测试样本输入到决策树中,使用Bagging集成法,即以少数服从多数的原则确定样本类别。随机森林算法中“随机特征子空间”和“Bagging集成”两个策略,有效克服了算法过拟合的问题,提高了算法的鲁棒性。
随机森林算法作为一种典型的分类与回归算法,在故障诊断、刀具磨损识别等领域中得到了广泛应用,但是它存在以下问题:(1)决策树具有平等的表决权,没有进行个性化区分,类似于将专家意见和群众意见平等对待,显然不合理;(2)决策树的表决权是固定的,在现实中个体决策结果能否让人信服,取决于其历史表决正确率,因此决策树的表决权应当是动态的。
3.2 动态专家会议算法
为了解决随机森林算法中出现的上述问题,文中参考随机森林算法思想,提出了动态专家会议(Dynamic Expert Meeting,DEM)算法。其核心思想是:将决策树视为决策专家,构造由专家组成的会议制度,专家的表决权重取决于其历史表决贡献率,历史表决贡献率根据历史表决正确率确定。这意味着在专家会议算法中,专家表决权重根据其历史表现动态变化。这一方面解决了“表决权完全平等”带来的个体无差别问题,另一方面解决了权重恒定问题。
将训练样本分为训练组和预测试组,其中训练组占80%,预测试组占20%。训练组用于对决策树进行训练,预测试组用于对专家决策权重进行动态更新。专家i的历史表决正确率Ri为
(11)
式中:Ci为专家i历史表决中决策正确的次数;C为专家i历史表决次数。
根据专家i的历史表决正确率Ri,确定专家i的当前决策权重wi为
(12)
式中:I为参与会议的专家数量。
根据专家决策权重wi和投票结果,得到动态专家会议算法决策结果为
(13)
式中:x为源信号;fEM(x)为专家会议算法表决结果;Bi(c)为专家i的标识参数,当专家i决策结果为c时Bi(c)=1,当专家i决策结果不为c时Bi(c)=0。
4 实验与分析
4.1 实验设置
文中使用2010年PHM数据挑战赛中的铣刀磨损实验数据集[16]对文中的特征提取和识别方法进行验证,实验平台如图4所示。该实验在RFM 760高速数控铣床上进行,将镍基超合金718材料工件加工成60°斜面。

图4 实验平台
PHM2010实验平台所用机床型号、刀具型号、工件材料及主要加工参数如表2所示。
PHM2010实验平台共有3类传感信号,分别为1个三向测力计、3个加速度计、1个声发射传感器。Kistler三向测力计用于测量X、Y和Z向的切削力,加速度计用于测量X、Y和Z向的振动信号,AE传感器用于监测切削产生的高频应力波。每完成一次切削,使用莱卡MZ12显微镜测量刀具磨损度。以刀具C4为例,得到3齿磨损度真值如图5所示。
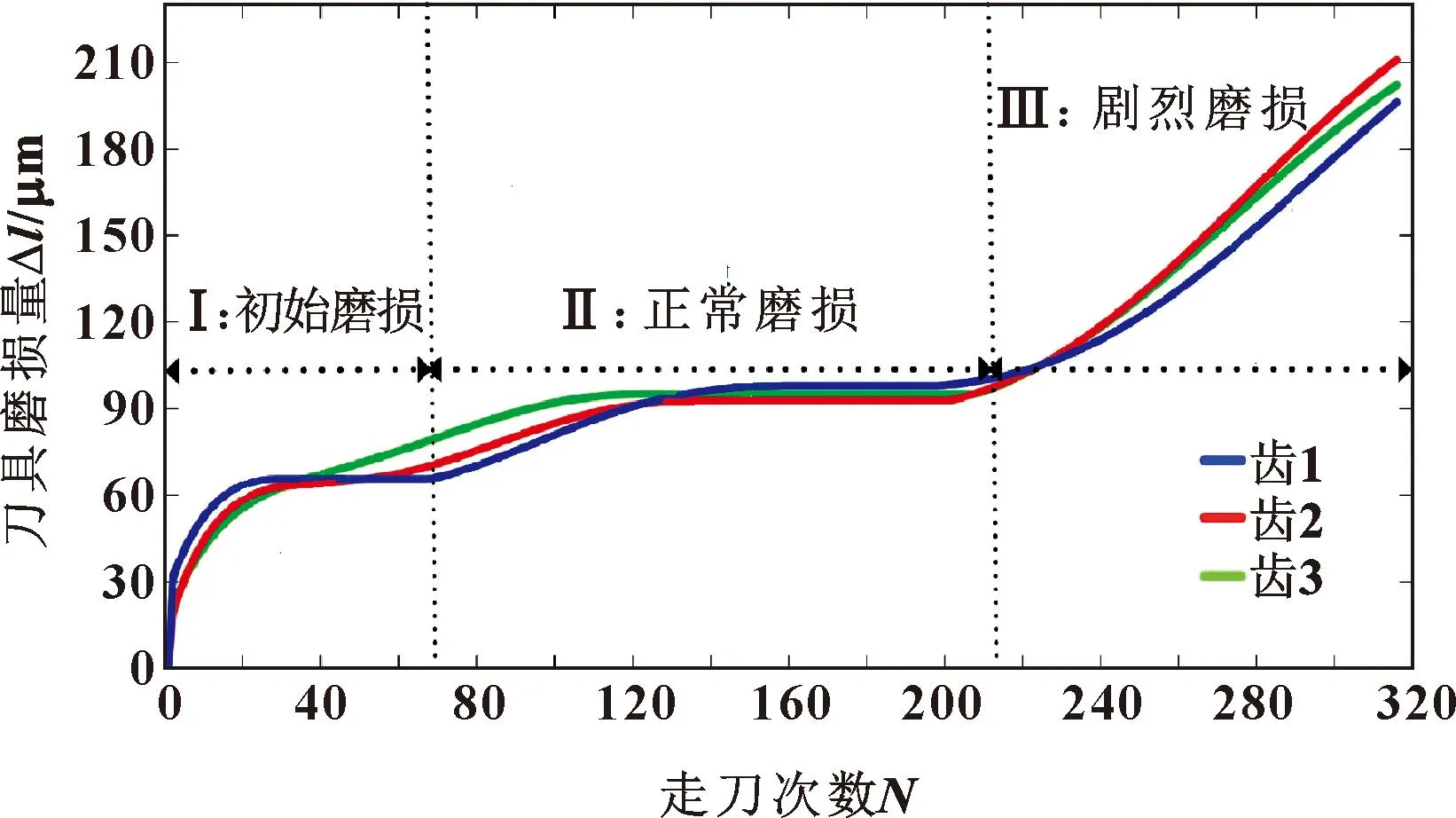
图5 刀具磨损过程
结合图5,设置刀具磨损度标签如下:磨损量在(0,80) μm区间时,标签为Ⅰ;磨损量在(80,115) μm区间时,标签为Ⅱ;磨损量大于115 μm时,标签为Ⅲ。
4.2 特性矩阵提取与分析
考虑到第2.2节中分析的信号与刀具磨损的关联度,基于切削方向的切削力信号、振动信号对文中方法进行验证。以振动信号为例,对特征提取过程和提取效果进行介绍。从刀具C4的初期振动信号中截取时长为35 s的振动信号,如图6(a)所示,对源信号进行CEEMD分解,得到IMF分量和分量信号频谱如图6(b)和图6(c)所示。

图6 振动信号CEEMD分解结果
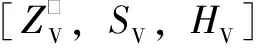
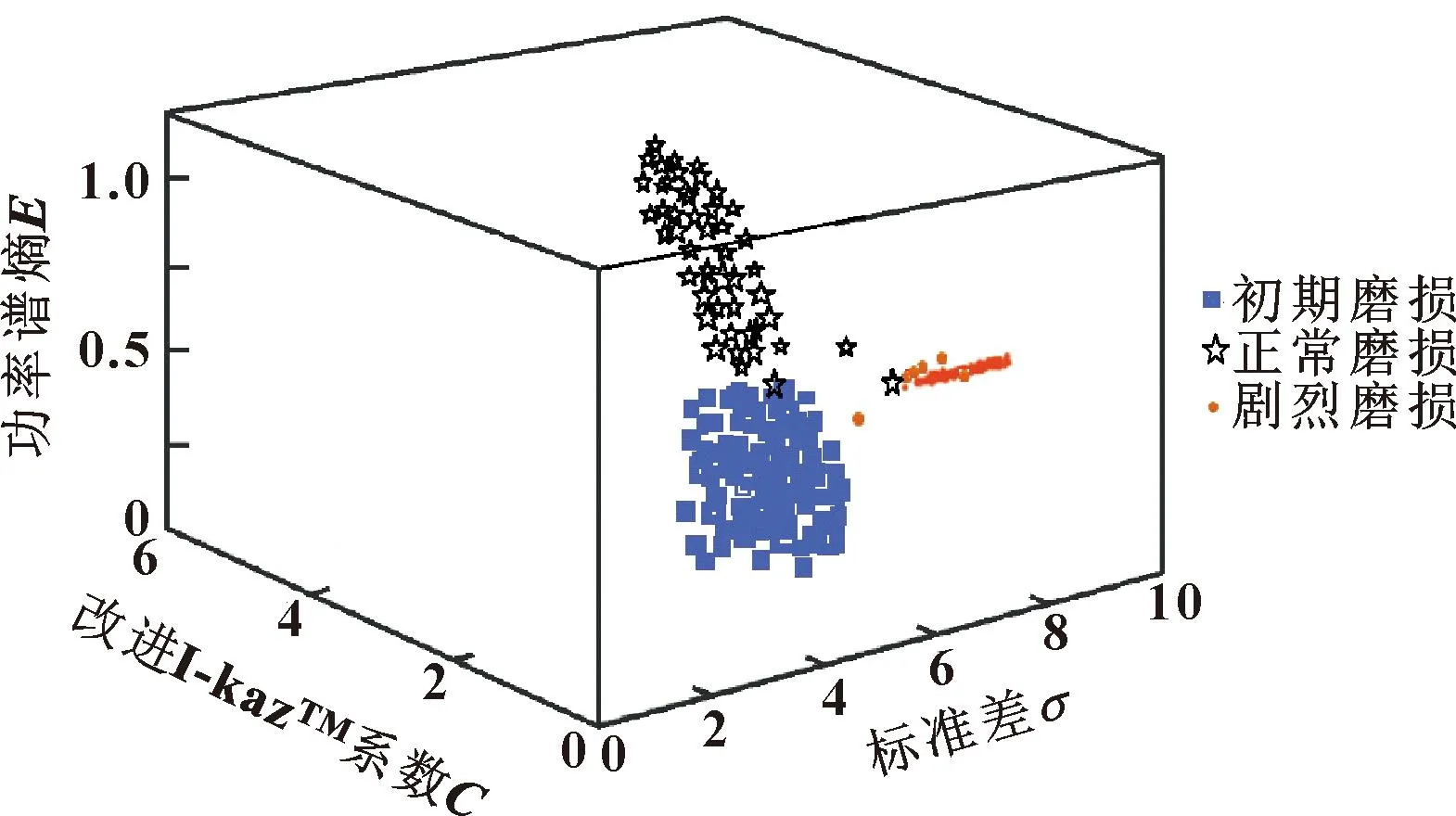
图7 特征矩阵在3维空间分布
由图7可以看出:刀具在同一磨损度下的特征向量聚集度较好,不同磨损度之间的特征向量具有较为明显的区分,这意味着提取的特征向量对刀具磨损度具有较高的敏感度。
4.3 磨损度识别精度验证
从每个类别样本中随机选取80%作为训练样本,剩余20%作为测试样本,即初始磨损、正常磨损、剧烈磨损的测试样本数量分别为28组、56组和44组,共128组样本。
为了与动态专家会议(DEM)算法的刀具磨损识别率进行比较,同时使用随机森林算法(RF算法)、文献[13]最小二乘支持向量机(LS-SVM)对刀具磨损度进行识别。DEM算法中,专家数量设置为60,最大训练次数为200。RF算法、LS-SVM、DEM算法识别得到的混淆矩阵如图8所示。
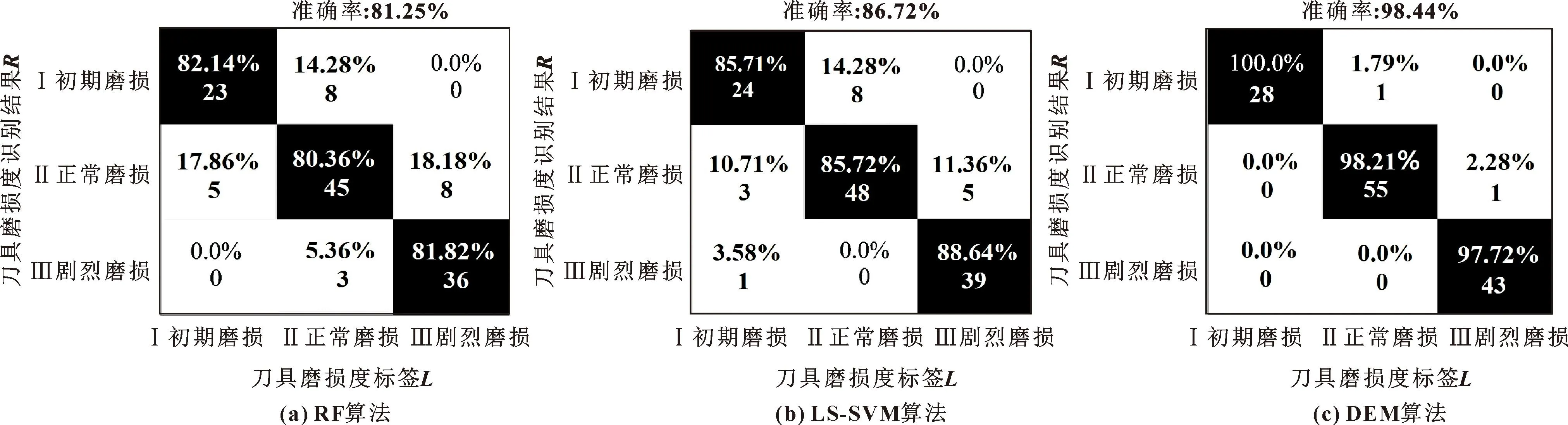
图8 识别结果的混淆矩阵
由图8可知:基于RF算法的刀具磨损度识别准确率为81.25%,基于LS-SVM算法的识别准确率为86.72%,基于DEM算法的识别准确率为98.44%,比RF算法高出了17.19%,比LS-SVM高出了11.72%,说明DEM算法在刀具磨损度识别中具有最高精度。这是因为:(1)专家会议算法发挥了群体智慧,以投票方式进行决策,极大地提高了算法的鲁棒性和容错能力;(2)专家会议算法中专家的决策权重根据其历史决策准确率确定,它是动态的且具有个体差异性,充分发挥了优质专家的决策引导能力。因此动态专家会议算法在刀具磨损识别中具有最高精度。
5 结论
文中研究了机床加工过程中刀具磨损度的监测方法,基于CEEMD算法对源信号进行分解并提取了多指标特征矩阵;针对随机森林算法存在的问题,提出了一种新的动态专家会议算法。经实验验证可以得出以下结论:
(1)在多指标特征矩阵的空间分布中,不同磨损度之间的区分性较好,同一磨损度的特征聚集性较好,说明特征矩阵具有充足的磨损特征信息。
(2)在刀具磨损度识别准确率上,动态专家会议算法高于随机森林算法和LS-SVM算法,说明动态的、具有个体差异性的专家决策权设置是合理的。
