LogRank++:一种高效的业务过程事件日志采样方法
2024-03-13张帅鹏李会玲曾庆田
刘 聪, 张帅鹏, 李会玲, 何 华, 曾庆田
(1.山东理工大学 计算机科学与技术学院,山东 淄博 255000;2.山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引言
过程挖掘[1-3]旨在从事件日志中提取有关业务过程的有效信息,从而发现、监控和改进实际过程。过程挖掘主要包括过程发现、合规性检查、过程增强与改进3方面,其中过程发现是最具挑战性的过程挖掘任务之一,它允许在不使用任何先验信息的情况下从事件日志中发现过程模型。在过去20年中,学者们已经提出各种过程发现方法,如Alpha Miner[4],Heuristic Miner[5],Inductive Miner[6]等。
然而,大多数过程发现方法只关注单个机器上的模型发现。实际上,由于I/O和内存等硬件的限制,随着当前信息系统中可用数据的增长,大部分过程发现方法都不再适用于单个机器处理整个大规模数据集,大规模事件日志对这些发现方法的性能提出了新的挑战。现有大多数过程发现方法不能正确挖掘大规模事件日志中的信息,导致过程发现算法效率低下。例如,已有过程发现方法在处理大规模事件日志时,容易产生高度难以理解的意大利面模型[7];VAN DER AALST教授与其团队在过程挖掘宣言[8]中曾以ASML光刻机系统产生的海量数据为例,说明现有过程挖掘方法难以处理大规模事件日志,并将处理大规模复杂事件日志问题作为过程挖掘的重要挑战之一。
对于大规模事件日志,一个有效的处理方法是用MapReduce重新实现一些过程发现方法,使其可扩展到大规模事件日志数据集。EVERMANN[9]重写了Alpha Miner和Heuristic Miner的MapReduce实现过程。然而,重写实现的过程非常耗时,需要开发人员深入了解底层发现方法。另外,重新实现技术为特定方法定制,并不适用于其他挖掘算法,例如文献[9]中的方法无法适用于近年来提出的Inductive Miner。另一方面,重新实现技术并未降低事件日志的规模,过程发现的效率未得到实质性改变。
事件日志采样技术不是重新实现现有的发现方法,而是提供了一种提高发现效率的替代方法。通过采样技术得到的样本日志是原始日志的代表性子集,按照“一次采样,多次使用”的原则,可将得到的样本日志保留下来,以便用于后续的过程发现、合规性检查、过程增强与改进等,避免每次使用原始日志时出现效率低等问题,从而极大提高工作效率。
前期工作[10-11]中,笔者在PageRank算法的基础上实现了一个基于图排序的LogRank事件日志采样技术,其以任意事件日志为输入来获取样本日志,因为样本日志比原始日志小得多,所以处理效率也更高。虽然该采样技术有助于提高过程发现效率,但是在处理大规模事件日志时采样算法本身非常耗时。于是LIU等[12]提出一种基于轨迹相似度计算的LogRank+事件日志采样技术,与基于LogRank的事件日志采样技术相比,该方法在确保采样质量的前提下缩短了采样时间,提高了采样效率。然而,当前已有采样算法在处理一些大规模事件日志时仍需花费大量时间才能完成采样,采样时间还需进一步提升。
鉴于此,本文提出一种新的基于排序的事件日志采样方法LogRank++。首先计算事件日志中的活动和直接跟随活动关系的重要性,然后计算每条轨迹的重要性,最后根据重要性值进行排序,选择最重要的轨迹组成样本日志。另外,从采样质量和采样效率两方面考虑,从过程发现的角度与已有采样技术对比,说明所提采样技术的高效性。
1 基础知识
本章首先介绍在采样技术中使用的基本术语。
假设S是一个集合,∅表示空集,|S|表示集合S中的元素个数,B(S)表示集合S所有多集的集合。
f:X→Y是一个函数,其中dom(f)为其定义域,cod(f)={f(x)|x∈dom(f)}为其值域。定义在集合S上长度为n的序列(sequence)是一个函数σ:{1,2,…,n}→S。若σ(1)=a1,σ(2)=a2,σ(3)=a3,…,σ(n)=an,则σ=
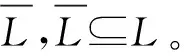
例如,L=[
事件日志可被视为轨迹的多重集合,因为可能有多个过程实例(或案例)具有相同的轨迹,每个轨迹描述了特定实例(或案例)的生命周期。过程发现以事件日志为输入,返回一个过程模型。
定义2过程发现[11]。设UM是所有过程模型的集合,一个过程发现方法指从一个事件日志L∈B(A*)映射到一个过程模型pm∈UM的函数γ,即γ(L)=pm。
一般来说,过程发现方法能够将事件日志转换成由标记的Petri网、业务流程建模标注(Business Process Modeling Notation,BPMN)语言、事件驱动过程链(Event-driven Process Chain,EPC)等表示的过程模型。无论过程模型采用什么表示方法,输入事件日志中的每个轨迹都对应于发现的过程模型中的一个可能的执行序列。然而已有过程发现方法不能有效挖掘出大规模事件日志中的信息,有必要对事件日志进行采样处理。
定义3事件日志采样[12]。事件日志采样技术指将一个事件日志L∈B(A*)映射到另一个事件日志L′∈B(A*)的函数,其中L′⊆L,L为原始事件日志,L′是L的一个采样日志。
根据定义3,事件日志采样技术将原始事件日志作为输入,并返回原始事件日志的一个子集。
2 研究问题和方法概述
本章首先提出两个将要解决的研究问题,即获取样本日志的高效方法和评估样本日志是否具有代表性。然后,概述了本文提出的解决方案,系统阐述了本文的主要方法思想。
2.1 研究问题
本文需要解决的问题如下:
(1)如何找到一种高效的方法来获取一个样本日志,使该样本日志足以代表原始事件日志中的所有(或大多数)轨迹行为。
(2)从过程挖掘的角度如何衡量一个样本日志相对于原始日志具有代表性。
本文对问题(1)的解答将提供一种将大规模事件日志采样为相对较小的样本日志的采样方法,用于高效地发现过程模型;问题(2)的答案用于评估样本日志相对于原始事件日志的质量。
2.2 方法概述
图1所示为本文方法架构图,包括以下两个阶段:
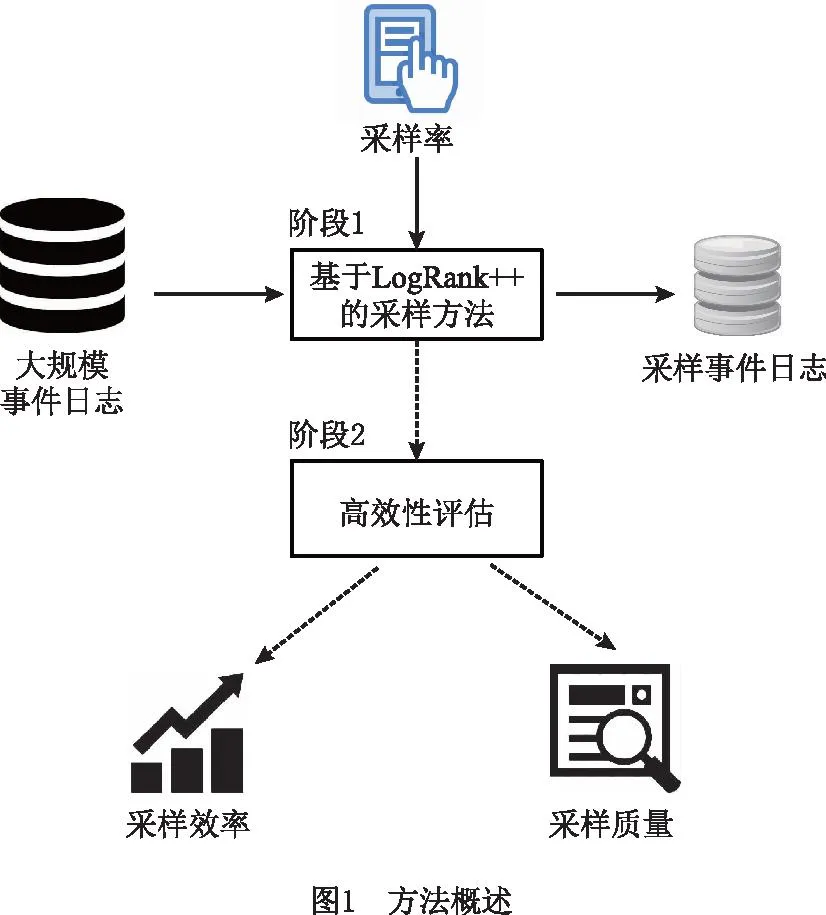
阶段1事件日志采样。
本文提出一种基于LogRank++的事件日志采样方法,将原始事件日志和用户输入的采样率作为输入,根据轨迹的重要性将日志中的轨迹排序,获取一组最重要的轨迹组成样本日志作为输出。样本日志本质上是原始事件日志的子集。
阶段2采样技术的高效性评估。
给定一种事件日志采样技术,可以从以下两个角度评估高效性。
(1)采样质量 为了量化样本日志的质量,首先从样本日志中发现一个过程模型,发现的模型应该保证100%样本日志拟合度;然后通过测量原始日志和该过程模型之间的拟合度值来量化样本日志的质量。
(2)采样效率 采样效率可以通过获取样本日志所花费的时间来量化,采样技术花费的时间越少,采样效率越高。
3 基于LogRank++的业务过程事件日志采样
本章首先给出一个示例事件日志,用于介绍后续采样方法,然后详细介绍基于LogRank++的业务过程事件日志采样方法,最后通过量化所获样本日志的质量和采样效率两方面来评估采样技术的高效性,借助该评估方法对真实事件日志进行实验质量评估。
3.1 事件日志示例
3.2 基于LogRank++的业务过程事件日志采样方法
事件日志采样技术旨在选择一个原始事件日志的代表性子集,以便更高效地进行分析。在一个事件日志中,如果一条轨迹包含整个事件日志的更多信息(或行为),则该轨迹比其他轨迹更重要,这里的信息(或行为)指活动、直接跟随活动关系等。因此,一条轨迹的重要性可以通过其活动重要性和直接跟随活动关系重要性来量化。基于这一思想,提出一种基于排序的业务过程事件日志采样技术,记作LogRank++,通过计算轨迹的重要性值对轨迹进行排序,然后选择重要程度最高的轨迹构造样本日志。
为了度量轨迹重要性,首先要获得事件日志中包含的轨迹变体σ及其频次L(σ),在示例日志LC中包含的变体及其频次如表1所示;然后,统计原始事件日志中的活动数和直接跟随活动关系数量。

表1 事件日志LC中的变体及其频次
定义4直接跟随活动关系。令a和b是事件日志L中的一条轨迹σ的两个活动,如果活动b紧紧跟随在活动a之后,则称在轨迹σ中从a到b存在直接跟随活动关系,记作
例如,在示例日志LC中,有7个活动a,b,c,d,e,f,g,直接跟随活动关系有
(1)计算事件日志的活动重要性和直接跟随活动关系重要性。
事件日志L中活动a的活动重要性
(1)
直接跟随活动关系
(2)

表2 事件日志LC中的活动重要性
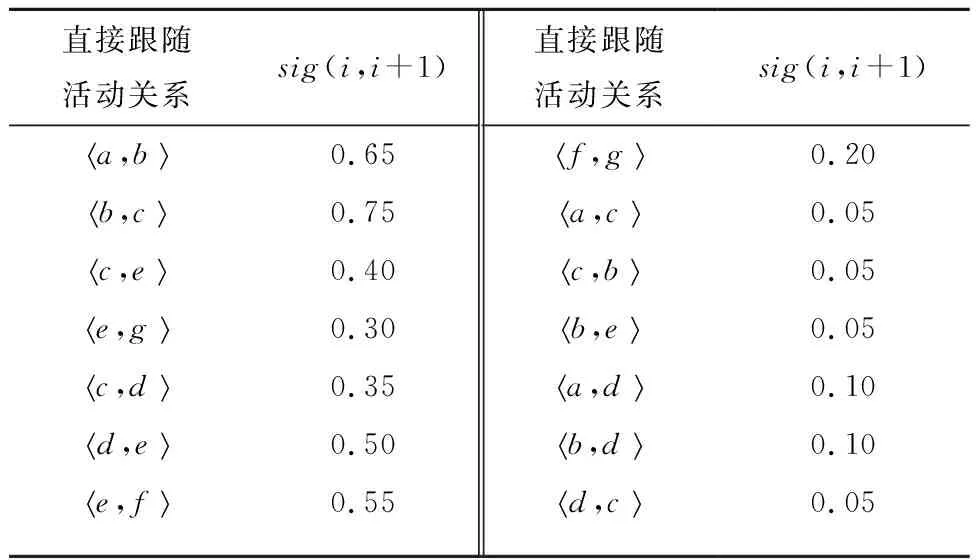
表3 事件日志LC中的直接跟随活动关系重要性
(2)计算事件日志中每条轨迹的平均活动重要性和平均直接跟随活动关系重要性。
轨迹σ的平均活动重要性
(3)
轨迹σ的平均直接跟随活动关系重要性
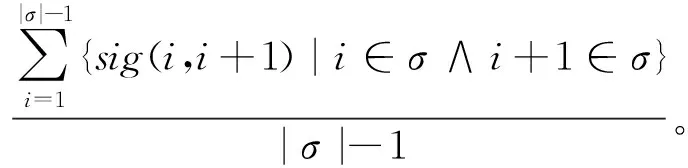
(4)
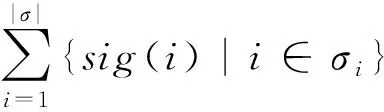
(3)计算事件日志L中轨迹σ的轨迹重要性
(5)
至此得到LC的所有重要性信息,包括每条轨迹的平均活动重要性、平均直接跟随活动关系重要性和轨迹重要性,具体数值如表4所示。
根据轨迹重要性对事件日志LC中的轨迹进行降序排列,得到σ3,σ1,σ6,σ2,σ8,σ5,σ4,σ7,根据选定的采样率(默认为0.3)和原始事件日志的大小确定最终样本日志的大小,即20×0.3=6,最终所得的样本日志LC′=[
综上所述,给定一个事件日志和一个采样率,基于LogRank++的业务过程采样过程如下:
(1)获取事件日志中的轨迹变体及其频次。
(2)获取事件日志的活动数和直接跟随活动关系数量。
(3)用式(1)和式(2)分别计算事件日志的活动重要性和直接跟随活动关系重要性。
(4)用式(3)和式(4)分别计算事件日志中每条轨迹的平均活动重要性和平均直接跟随活动关系重要性。
(5)用式(5)计算事件日志中每条轨迹的重要性,并根据轨迹重要性对轨迹排序。
(6)根据特定的采样率选择前N条轨迹组成样本日志。
3.3 采样技术的高效性评估
给定一个大规模事件日志,通过日志采样技术获得一个更小规模的样本日志。由于与其他事件日志采样技术相比,本文所提事件日志采样技术是否更高效尚不清楚,本节通过量化获得的样本日志的质量和采样效率两方面综合评估采样技术的高效性。
通过LogRank++日志采样技术得到原始事件日志的一个代表性子集作为样本日志,然而样本日志通常不完整,可能导致模型过拟合(或欠拟合)。采样的目标是在不牺牲(太多)模型质量的情况下提高过程发现的效率,而衡量采样技术获得的样本日志是否具有代表性,通常是将从样本日志中发现的过程模型与原始日志作合规性检查来评估其过程模型质量,为此量化原始事件日志与从样本日志中发现的过程模型的拟合度。BUIJS等[13]认为,拟合度量化了从原始日志得到的过程模型,能够准确再现日志中记录轨迹的程度,其基本原理是,如果从样本日志中发现的模型可以重演原始事件日志中的所有(或大部分)轨迹,则样本日志对过程发现来说是高质量的。
上述思想可行最关键的因素是保证从样本日志中发现的模型可以完全代表样本日志中的行为,即100%拟合,其基本原理在于,如果从样本日志中发现的模型不能覆盖样本日志中所有可能的行为,则针对该模型重演原始事件日志没有任何意义。因此,应该选择一种能够保证100%拟合度的过程发现方法,即确保过程模型能够重演样本日志中的所有轨迹。
LEEMANS等[6]提出的IM(inductive miner)算法是一种可以保证发现的模型对输入日志有100%拟合度的典型方法。该算法采用分而治之的思想,将发现一个日志L的过程模型问题分解为发现通过拆分日志L得到n个子日志的n个子过程模型问题,具体如下:①选择最适合日志L的切分运算(顺序、并发、循环、排他);②将日志L中的活动通过切分运算划分为不相交的集合;③用这些集合将日志L拆分为子日志L1,L2,…,Ln。通过上述步骤递归挖掘这些子日志L1,L2,…,Ln,直到子日志只包含一个活动。因此,本文选择IM算法发现过程模型。
采样技术的高效性在很大程度上取决于采样效率,考虑到即使获得高质量的样本日志,用户也不愿意选择需要花费数小时才能完成的采样技术,本文的采样效率通过获取样本日志所花费的时间来量化,一般来说,采样技术花费的时间越少,采样效率越高。
4 实现工具与实验评估
本章首先介绍了基于LogRank++的事件日志采样方法的工具实现,然后对第2章中提出的问题进行了解答,最后结合6个事件日志,从拟合度指标评估采样质量,从采样花费时间衡量采样效率,分别对比了LogRank,LogRank+,LogRank++方法的采样质量和采样效率,有力地说明了基于LogRank++的事件日志采样技术的高效性。
4.1 基于LogRank++日志采样方法的支持工具
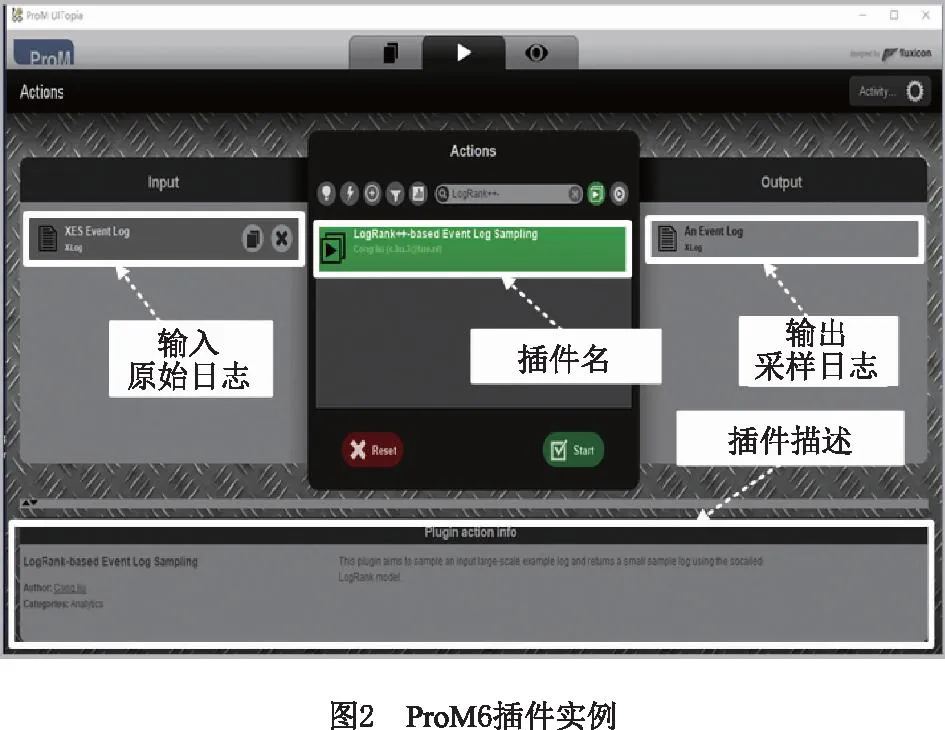
开源过程挖掘工具平台ProM 6为过程挖掘提供了一个完全可插拔的实验环境,其通过添加插件进行扩展,目前包括1 600多个插件,该工具和所有插件都是开源的,详见http://www.promtools.org/prom6/。
基于LogRank++的事件日志采样技术已作为插件(称为LogRank++-based Event Log Sampling,详见https://svn.win.tue.nl/repos/prom/Packages/SoftwareProcessMining/)在开源过程挖掘工具平台ProM 6中实现。该工具的快照如图2和图3所示,其输入为一个事件日志和一个采样率,输出为返回的一个样本日志。应该注意的是,以下实验中的所有示例日志均由该插件生成。
4.2 实验评估
本节使用9个事件日志(3个仿真日志和6个真实日志,链接地址为https://github.com/Brain515/ProcessMiningDatasets/tree/main/LogRankPlusplus)对所提基于LogRank++的业务过程事件日志采样方法进行实验评估,表5所示为这些事件日志的部分主要统计数据。
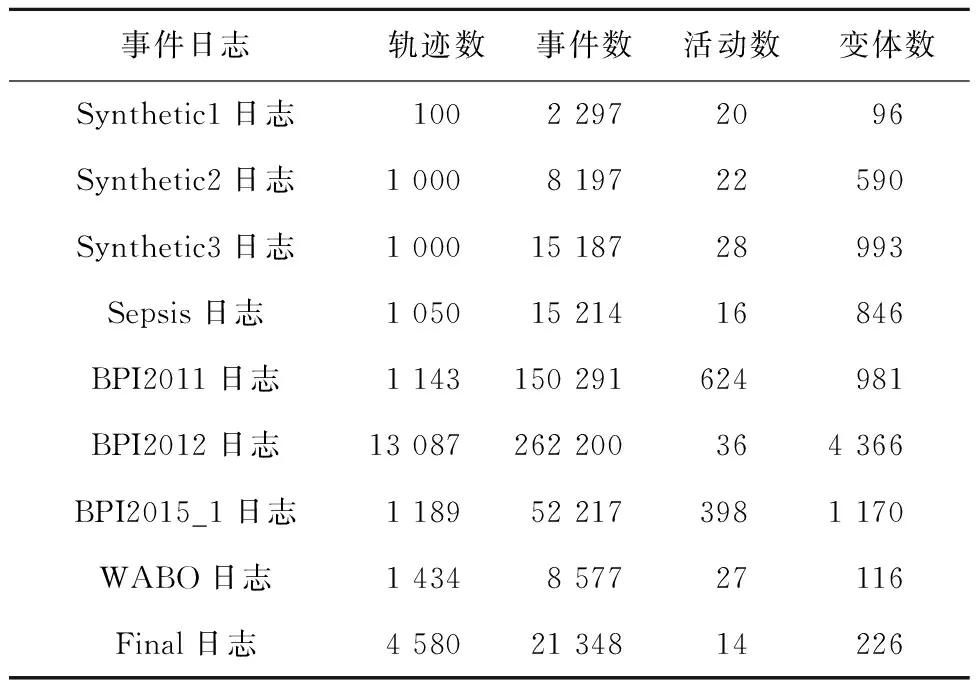
表5 实验日志概述
(1)Synthetic 1~Synthetic 3数据集 Synthetic1数据集由论文评审过程模型生成,每一条轨迹都描述了评审论文的过程,Synthetic2和Synthetic3数据集是由构造模型生成的仿真日志。
(2)Sepsis 数据集 该数据集包含来自医院的脓毒症病例事件,每一条轨迹代表一个脓毒症患者的治疗过程。
(3)BPI2011数据集 该数据集来自荷兰一家学术医院的妇科,每一条轨迹代表一个病人进行的医疗活动过程。
(4)BPI2012数据集 该数据集源自荷兰一家金融机构的个人贷款申请过程,每一条轨迹描述了不同客户申请个人贷款的过程。
(5)BPI2015_1数据集 该数据集源自荷兰城市市政当局提供的本地企业所有建筑许可证的申请过程,期限约为4年,本数据集选取其中一部分进行处理。
(6)WABO数据集 该数据集源自荷兰科学研究组织中编号为638.001.211执行的CoSeLoG项目,记录了荷兰城市的城市建筑许可证申请过程。
(7)Final数据集 该数据集来自意大利软件公司服务台的票务管理过程。
下面根据第2章中定义的两个研究问题给出实验结果。
(1)找到一种高效的方法来获取一个样本日志,使该样本日志足以代表原始事件日志中的所有(或大多数)轨迹行为。
针对该问题,提出基于LogRank++的日志采样技术来进行高效的事件日志采样。该方法首先获取事件日志的活动数和直接跟随活动关系数,通过计算活动的重要性和直接跟随活动关系的重要性得出每条轨迹的重要性,然后根据轨迹重要性将事件日志中的轨迹降序排列,最后结合设置的采样率和原始事件日志大小选择前N条轨迹组成样本日志(N为采样率与原始事件日志乘积向下取整的结果)。在之后的实验中,用基于LogRank++的事件日志采样插件为每个实验日志生成一组不同采样率的样本日志(从5%~30%,增量为5%)。
(2)从过程挖掘的角度衡量一个样本日志相对于原始日志具有代表性。
针对该问题,从以下方面衡量采样技术的高效性:①量化样本日志的质量,本文采用拟合度[14]评估指标;②量化给定采样方法的采样效率。综合这两方面思想,在以下实验中将本文方法与基于LogRank的采样方法、基于LogRank+的采样方法的采样质量和采样效率进行对比。
4.2.1 采样技术的可行性评估
下面对问题(1)展开详细研究。首先对比未采样的原始日志和采样后的样本日志应用过程发现算法(此处为IM算法)的时间,来说明采样技术的有效性,实验设置默认采样率为30%,得到的实验结果如表6所示。
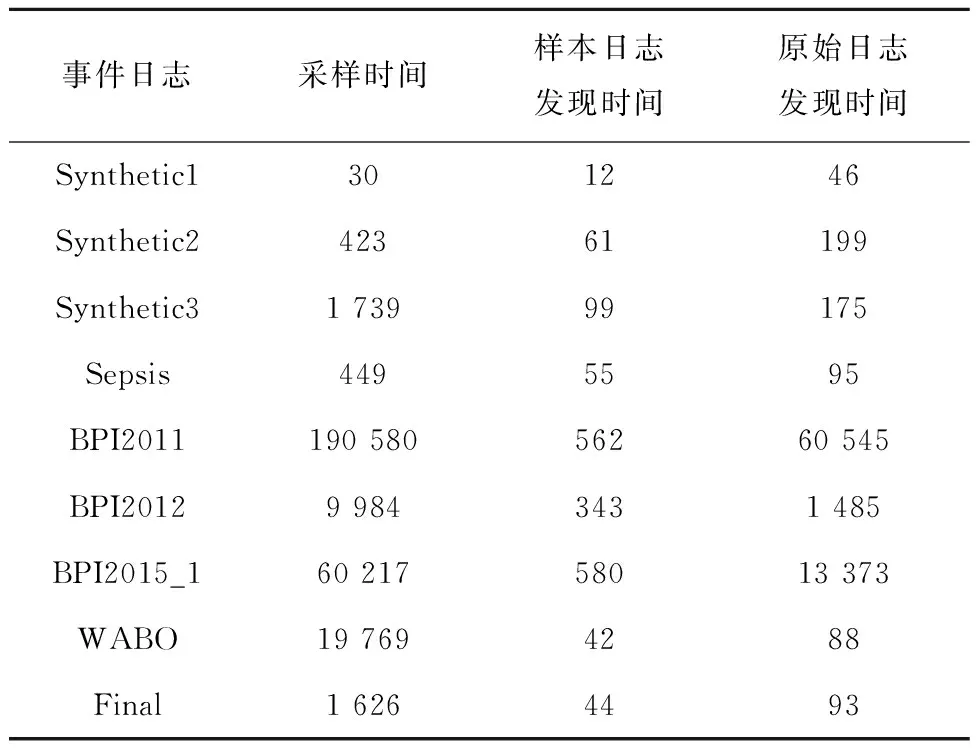
表6 过程发现时间对比 ms
从表6可见,将采样后的样本日志进行过程发现的时间均小于原始日志的过程发现时间,说明该采样技术提高了过程发现的效率。值得注意的是,采样时间和样本日志的过程发现时间多于原始日志的过程发现时间,这是由采样时间过长导致的,并不能说明采样技术无效。相反,按照“一次采样,多次使用”的原则,通过采样技术得到的样本日志能够代替原始日志进行后续过程挖掘相关工作分析,如一致性检查、过程增强、预测性监控等,不必每次都要分析原始日志,提高了工作效率。
其次,统计不同采样率下样本日志的详细信息,包括轨迹数、事件数、活动数和轨迹变体数量,实验结果如表7~表10所示,可见:①样本日志的大小随采样率的降低而急剧减小;②随着采样率的降低,事件日志的活动数或轨迹变体数略有减小或保持大致稳定,即大多数的代表性信息都包含在样本日志中。由此,进一步验证了本文采样方法的可行性。
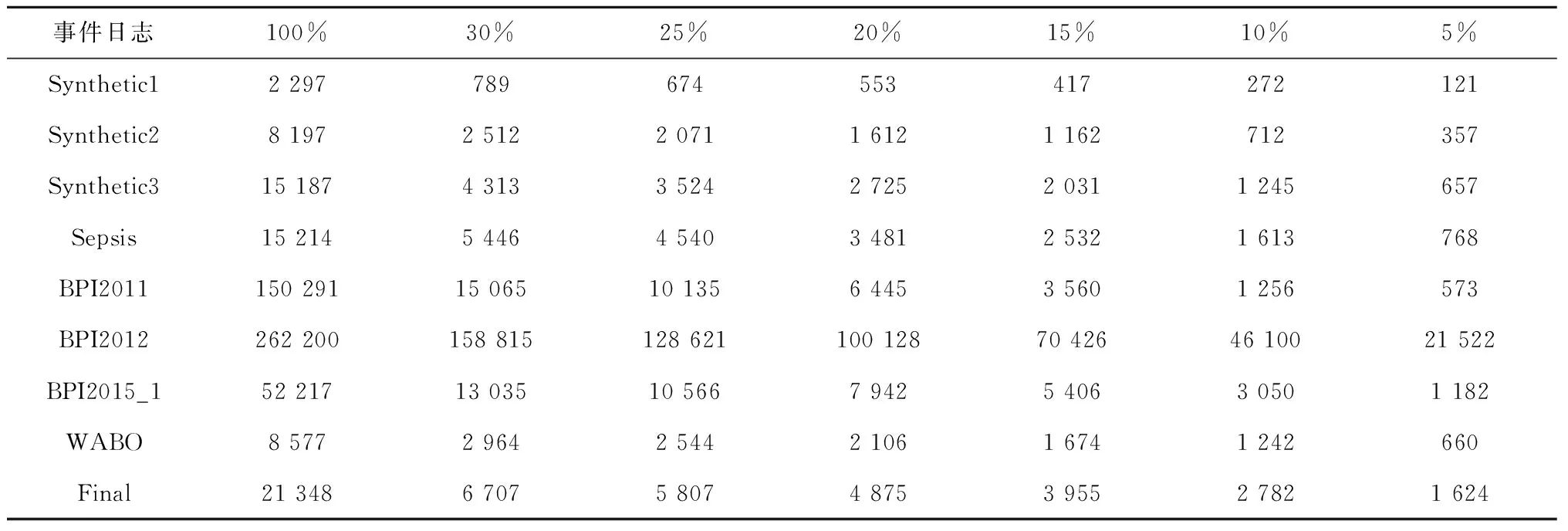
表8 不同样本日志的事件数
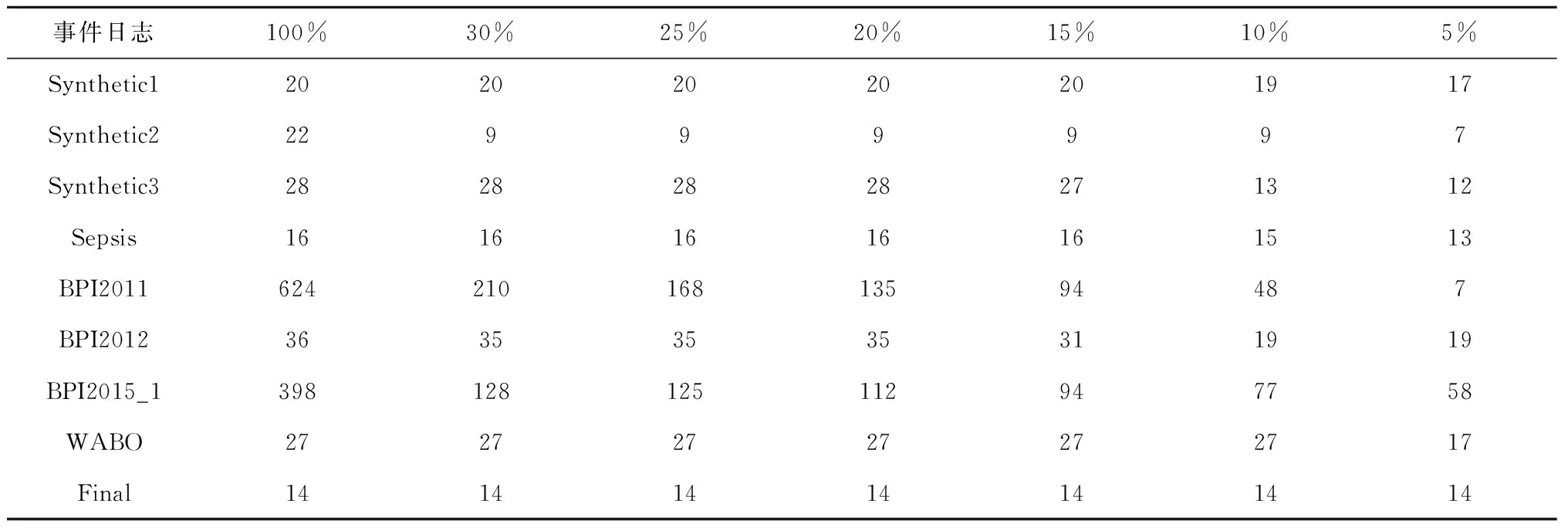
表9 不同样本日志的活动数
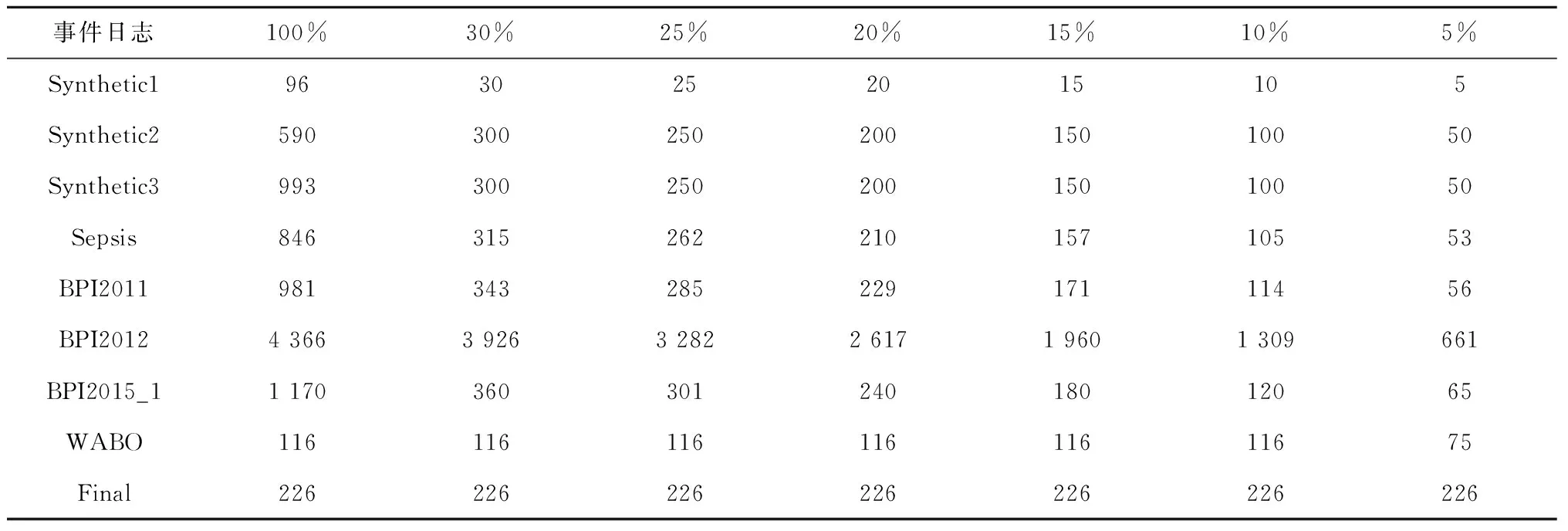
表10 不同样本日志的轨迹变体数
4.2.2 采样技术的高效性评估
下面对问题(2)展开详细研究。为了对比样本日志的质量,量化从样本日志中发现的过程模型相对于原始事件日志的拟合度。首先采用IM算法为样本日志发现过程模型,然后针对该模型重演其原始日志获得拟合度值,拟合度值越大,样本质量越高。基于这一思想,对上述6个实验日志进行拟合度指标的质量评估,图4所示为基于LogRank++的采样方法与基于LogRank的采样方法、基于LogRank+的采样方法进行对比实验得到的拟合度值。
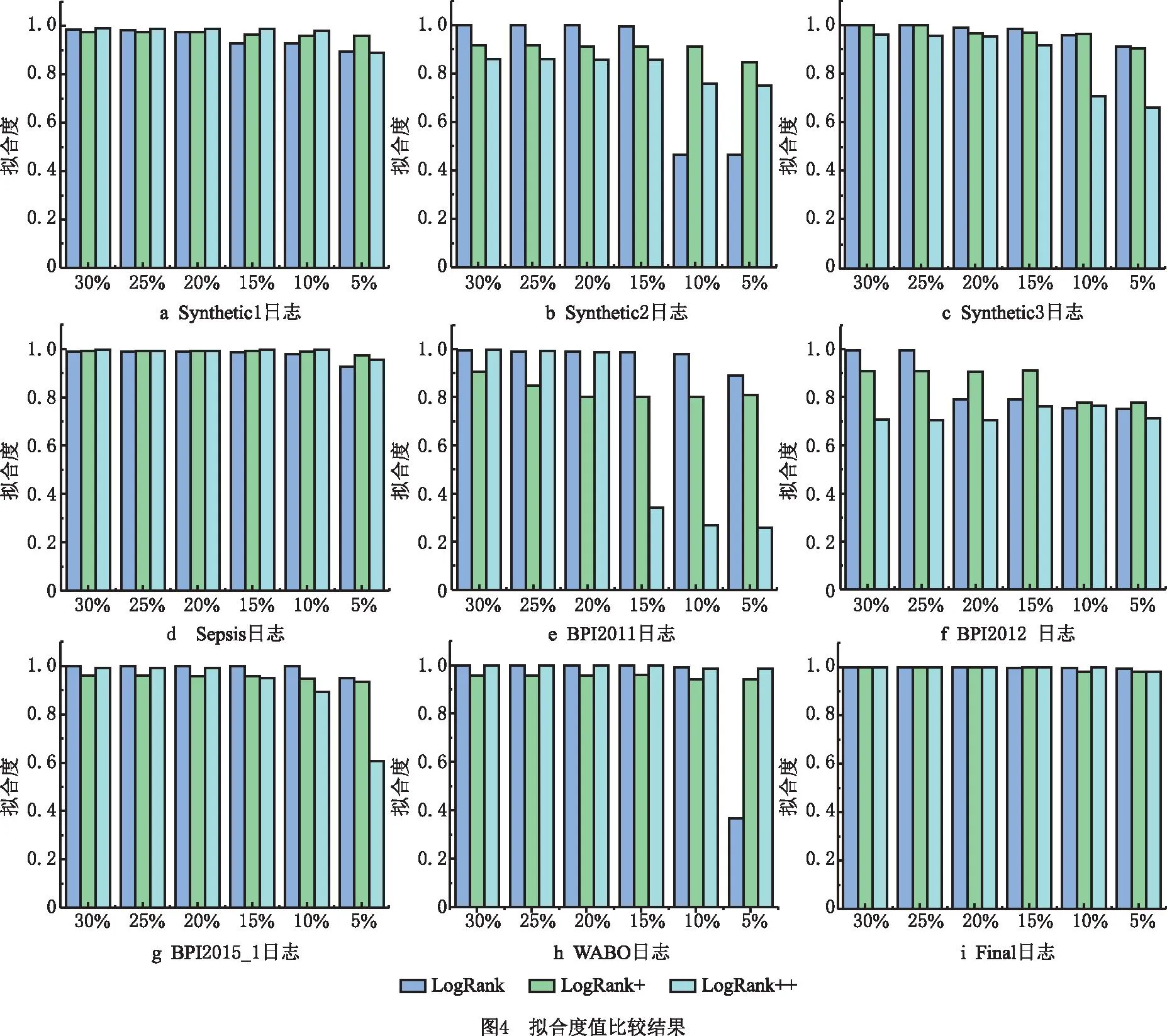
图4的3种日志采样技术显示,随着事件日志的减小,样本日志的质量逐渐降低,采样率区间在20%~30%之间时,其质量下降相对较慢,可以保持在一个适当的值以上,但在个别样本日志中样本质量会在某一个采样点出现较大波动,例如在BPI2011日志中,选择采样率由20%~15%时日志的拟合度值下降较快。因此采样率的选择至关重要,采样率过大会导致采样花费时间长,采样率过小则会降低样本日志的质量。实验结果表明,采样率一般选择在20%以上时,样本日志的质量可以得到保证。
采样效率通过计算采样技术获取样本日志的时间来量化。一般来说,采样技术花费的时间越少,采样效率越高。在图5中,通过输入9个实验日志和不同采样率,展示了基于LogRank的事件日志采样技术(用A1表示)、基于LogRank+的事件日志采样技术(用A2表示)和基于LogRank++的事件日志采样技术(用A3表示)的执行时间,间接地比较了采样效率。将给定采样率的每个实验日志运行插件5次,其平均值在图中突出显示。
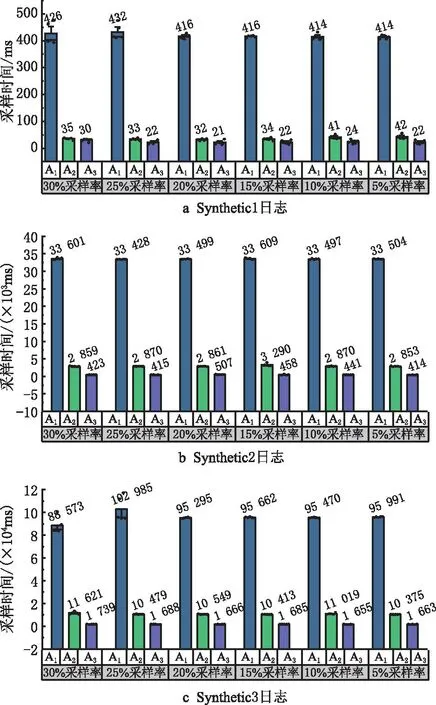
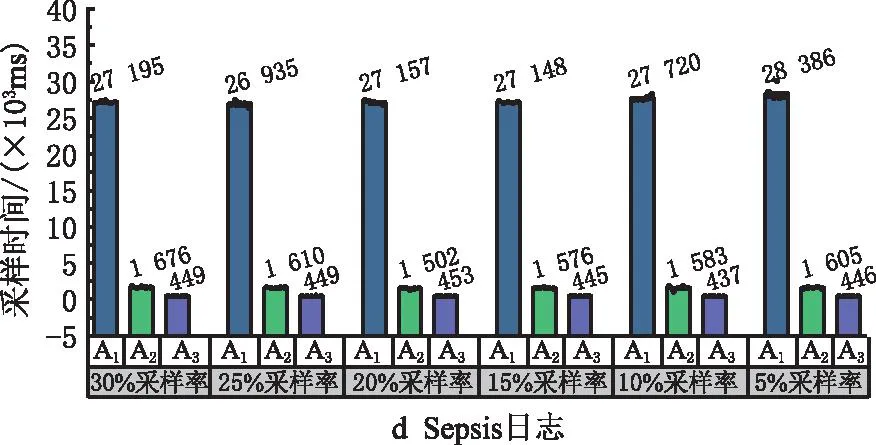
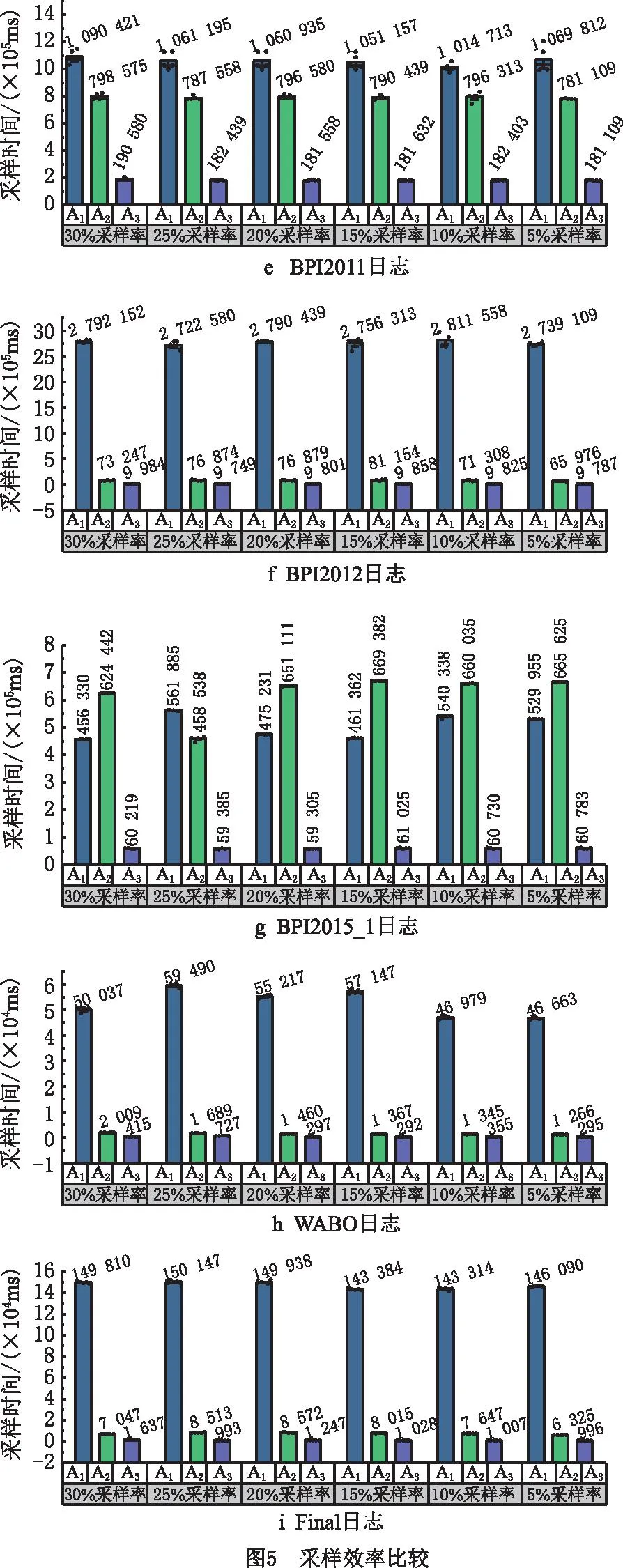
以Synthetic1数据集、Synthetic3数据集、Sepsis数据集为例,采样率范围为30%~20%的样本日志的拟合度值仅从1降至0.9,即原始日志中的主流行为保留在样本日志中。另外,基于LogRank++的采样技术、基于LogRank的采样技术和基于LogRank+的采样技术的样本日志的质量相近,不同的是,基于LogRank++的采样技术的采样时间远少于图5所示的基于LogRank的采样技术,也少于基于LogRank+的采样技术。以Sepsis日志为例,与基于LogRank的采样技术相比,基于LogRank++的采样技术(30%采样率)的采样时间从27 195 ms减少到449 ms,降低了98.3%;与基于LogRank+的采样技术相比,基于LogRank++的采样技术的采样时间从1 676 ms减少到449 ms,降低了73.2%,但样本日志的质量却相近;对于BPI2011日志,与基于LogRank的技术相比,基于LogRank++的采样技术(30%采样率)的采样时间从大约2 790 000 ms减少到10 000 ms(节省大约45 min);与基于LogRank+的技术相比,基于LogRank++的采样技术的30%采样时间从大约73 000 ms减少到10 000 ms(节省约1 min),而其质量基本相同(0.99 vs 0.90 vs 0.99)。因此,可以得出结论,基于LogRank++的采样技术提供了一种高效的解决方案,能在提高采样效率的同时确保样本日志高质量;另外,事件日志的规模越大,采样技术的采样效率越高。
5 结束语
为了提高采样效率,本文提出一种基于排序的业务过程事件日志采样技术LogRank++,并通过量化采样效率和样本日志的质量来评估所提采样技术的高效性,所提方法已经作为插件在开源过程挖掘工具平台ProM6中实现。通过9个实验日志的实验表明,相比已有采样方法,所提采样方法在保证样本日志质量的同时能够大幅提高日志采样效率。
本文提出的日志采样技术为处理大规模事件日志提供了一种更高效的解决方案,但在实验过程中发现,已有采样技术均需用户输入采样率,采样率的选择至关重要。从以上实验表明,无法直接明确一个采样点能有效权衡样本日志质量和日志采样效率。下一步工作将分析采样率的设置对采样技术的影响,给出一种有效的采样率选择方法,以兼顾日志质量和采样效率。
除此之外,在本文工作的基础上,未来还可以从如下3方面继续深入研究:①将基于LogRank++的业务过程事件日志采样方法部署在分布式系统上[15],处理特大规模的事件日志;②将基于LogRank++的业务过程事件日志采样方法应用到专业领域(如医疗、物流、制造业等)的事件日志;③除了用于过程发现之外,将采样技术用于支持一致性检查[16]、预测性监控[17]、软件过程挖掘[18-20]和跨组织过程挖掘[21-23]。
