基于多深度相机融合的机械臂抓取系统
2024-03-13洪诚康江文松
洪诚康,杨 力,江文松,罗 哉
(中国计量大学 计量测试工程学院,浙江 杭州 310018)
0 引言
赋予机器人感知能力是计算机视觉和机器人学科的一个长期目标。相机就是机器人的眼睛,机器人可以通过相机与环境交互进行目标检测和目标抓取,在工业上可以自动化抓取货品和工件,生活中可以为生活不方便的人提供帮助。
常规的机器人抓取系统分为抓取检测系统、抓取规划系统和控制系统,本文主要围绕抓取检测系统展开。目前最广泛的基于机器视觉的抓取检测系统分为2D平面抓取和6自由度抓取。2D平面抓取[1-4]指夹爪垂直于物体自上而下抓取物体,分为预测平面内抓取接触点的方法和预测定向矩形框的方法。6自由度抓取[5]指夹爪在3D空间从不同角度抓取物体,根据输入点云分为基于局部点云的方法和基于完整点云的方法,其中基于局部点云的抓取方法分为两种:①评估候选抓取的抓取质量,MOUSAVIAN等[5-6]提出一种6-DoF GraspNet算法,该算法用可变自动编码器对不同抓取姿态建议进行采样,并用抓取评估器模型对采样的抓取姿态进行细化;MURALI等[7]通过引入一种基于抓手信息和场景原始点云的学习碰撞检测器,进一步改进了6-DoF GraspNet;另外,ZHAO等[8-9]提出的RegNet、FANG等[10-11]提出的GraspNet-1Billion和LIANG等[12]提出的PointnetGPD,均采用端到端的神经网络将一个单视图点云作为输入预测夹具的抓取姿态。②从已有抓取姿态中转移抓取姿态,在定位目标对象之后,利用基于对应模板的方法将抓取点从相似且完整的3D模型转移到当前局部点云视图对象[13-14]。采用基于3D模板的抓取方法可以将部分点云与模板对齐,从而获取完整的物体信息,然而模板数量较少,可能不能学习到具有区别性的特征,而且泛化能力弱,抓取数据集以外物体的成功率相对较低。基于局部点云的方法在采集数据过程中,因复杂环境下的遮挡问题使目标物体点云形状缺失或变形,导致预测结果不稳定。因此,提出一种基于多深度相机融合的方法来预测抓取结果,该方法通过拼接融合不同视角下的点云形成完整的目标物体形状,从而丰富目标物体的3D信息,使抓取预测结果更加准确。
基于GraspNet-1Billion和6-DoF GraspNet,本文提出一个更具鲁棒性的端到端的神经网络GraspNet-Robust,并针对神经网络的抓取质量评估部分进行改进。借助神经网络分析点云的几何特征,再结合力闭合度量法[15]和抓取力螺旋空间场(Grasping Force Spiral Space Field,GFSSF)对预测姿态进行评估虽然效果良好,但是会使一些抓取点因点云形状缺失或畸变导致鲁棒性较差,召回率较低。因此提出GFSSF的方法,查找并统计预测可抓取点球邻域内的其他候选抓取点,如果90%候选点的抓取置信度得分S≥0.6,则将该球邻域的半径作为该抓取点的最大扰动范围。通过结合GFSSF和评估抓取置信度分数的方法,提高了抓取预测结果的鲁棒性,实验结果显示成功率提高了4%。
1 系统搭建
本文搭建了一个机械臂自动化智能抓取系统,主要硬件采用两个Intel公司生产的RealSense D435i深度相机、平行二指柔性夹爪、尔智公司生产的AR5机械臂(可重复定位精度为±0.03 mm)和Windows系统的PC,系统搭建如图1所示。

具体实现过程如下:
(1)用两个固定位置的深度相机实时拍摄工作台上的物体,两个相机相距90 cm,距离工作面高度为70 cm,分别从物体的前上方和后上方45°左右进行拍摄,通过将两个相机的视锥最大化来覆盖工作平台上的物体。
(2)当机械臂接收到采集物体的指令时,两个深度相机同时拍下当前物体同一帧的彩色图和深度图,通过提前标定好的相机内参将深度图转化为点云图,并将RGB信息赋给点云。
(3)将两个相机的拍摄位姿通过立体匹配法计算求得两个相机坐标系之间的旋转平移矩阵。将相机2坐标系下的点云经过旋转平移转换到相机1坐标系下,拼接成一个完整的待抓取目标物体的点云图像,再将点云进行去噪和降采样处理。
(4)将预处理过后的点云输入GraspNet-Robust神经网络,输出预测执行抓取夹爪的6D姿态,其中包含夹爪的3D位置和3D方向,以及夹爪的抓取宽度。因为该抓取姿态是相机1坐标系下的抓取姿态,所以在输入机械臂运动控制模块前,先借助手眼标定的结果将相机1坐标系下的抓取姿态转换到机械臂工具坐标系中心点(Tool Center Point,TCP)下。
(5)机械臂将当前的进给坐标系转化到激活的TCP下,接收到上位机传输的运动参数后,利用机械臂的运动控制模块将机械臂末端夹爪沿直线运动到预测位置,夹爪根据预测抓取宽度闭合,抓取物体后将机械臂移动到预先设定好的位置,放置被抓取的物体后进入监听状态等待下一次抓取指令。
抓取流程如图2所示。

2 抓取视觉检测
2.1 多相机标定
本文采用两个深度相机融合的方法,旨在将两个深度相机获取的深度信息融合,获取更加完整的物体点云图。然而将两帧点云直接用迭代最近点(Iterative Closest Point,ICP)方法进行配准时因为点的个数较多,消耗时间太长,影响机械臂抓取的实时性,所以采用先标定后拼接的办法。将相机1和相机2固定在机械臂工作台周围,同时拍摄同一个标定板棋盘格,利用双目相机立体匹配的原理将双相机视角下同一标定棋盘格上的角点一一对应,计算两个相机坐标系的旋转平移矩阵。具体方法如下:
假如世界坐标系下有一点P坐标为(Xw,Yw,Zw),P1为点P在相机1坐标系下的点,坐标为(X1,Y1,Z1),P2为点P在相机2坐标系下的点,坐标为(X2,Y2,Z2),(R1,T1)为世界坐标系到相机1坐标系下的旋转平移矩阵,(R2,T2)为世界坐标系到相机2坐标系下的旋转平移矩阵,因此根据转换关系可以得到:
P1=R1P+T1;
(1)
P2=R2P+T2。
(2)
令(R,T)为相机2坐标系到相机1坐标系下的旋转平移矩阵,则有
P2=RT(P2-T)。
(3)
将式(1)和式(2)代入式(3)并化简可得:
(4)
T=T1-RT2。
(5)
在双相机标定预处理实验中采集16组匹配的图像,根据每组标定板棋盘格上多个角点的位置,获得相机2到相机1坐标系下的旋转平移矩阵,并计算得到图像平均重投影误差为0.217,采集的标定板姿态与相机视点如图3所示。

2.2 点云预处理
2.2.1 点云拼接
分别用两个相机从两个角度拍摄待抓取物体,得到RGB-D图像。因为用深度相机拍摄获得的点云比目标物所在的工作空间更宽广,所以先用直通滤波器设置两个视角下的背景遮罩,滤去深度图像中待抓取物体和机械臂工作平台以外的背景点。根据深度图和相机标定获得的相机内参,将深度图转化为点云图,并将RGB图像中的RGB信息对齐赋值给对应点,然后根据2.1节两个深度相机的标定结果,获得完整的待抓取物体的点云图像,如图4所示。

2.2.2 点云降噪
深度图像存在噪声,虽然3D卷积神经网络(Convolutional Neural Network,CNN)对传感器噪声具有鲁棒性,但是抓取采样算法仍然可能产生一个导致姿态失调的空闲抓取点,因此对拼接后的点云进行降噪处理。首先采用k邻域去噪算法,通过k-维树(k-dimension tree)对散乱点云建立拓扑关系,找到每个任意点附近的k个点,计算任意点到k个点的平均距离和标准差,设置距离阈值为平均距离加两倍标准差,视距离阈值以外的点为离群点并剔除[16-17]。
然后采用体素化降采样的方法,保持原有物体的3D特征并输入下一步神经网络。该方法是对输入的目标点云创建一个3D体素网格,在网格划分的每个体素内,用其中点云数据的重心代替该体素内的全部点,通过提取重心点的方法对点云进行降采样。该方法在减少点云数量的同时仍能保持物体的形状特征不被破坏,而且点云在空间中均匀分布。总体效果如图5所示。

2.3 预测抓取姿态的神经网络
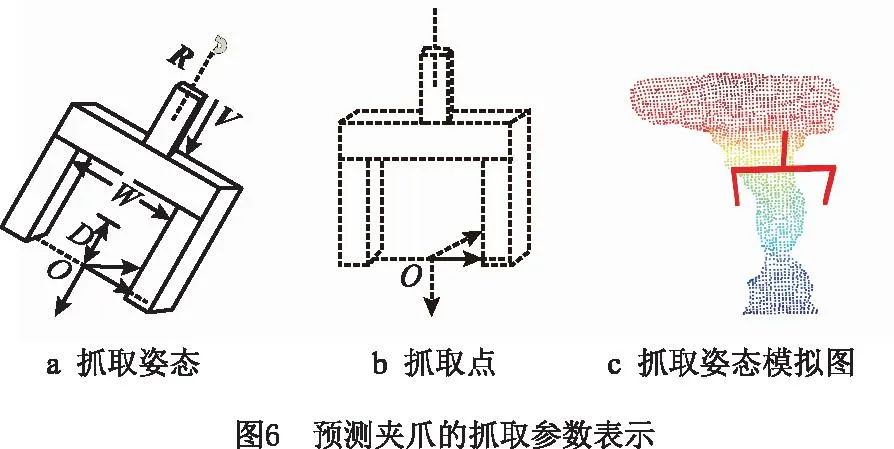
2.2节获得了待抓取物体的完整点云图像,将点云图像输入GraspNet-Robust的神经网络,输出结果为相机坐标系下二指平行夹爪的6D抓取姿态估计。GraspNet-Robust实现了端到端的抓取预测,将6D抓取姿态分为夹爪到待抓取物体的接近向量、夹爪在抓取点垂直于接近向量平面内的旋转矩阵和夹爪的抓取宽度。在预测过程中,预测接近向量为机械爪二指末端点到物体表面抓取点的接近向量,因此还需估计机械爪可行的抓取深度才能成功抓取,定义抓取姿态参数为

式中:R∈3×3表示夹爪沿着接近向量,经过抓取点垂直于接近向量的平面内的旋转矩阵;V∈3×1表示机械爪的接近向量,即机械爪末端中心到物体表面抓取点的平移向量;W∈表示机械爪的抓取宽度;D∈表示机械爪的抓取深度。具体参数表示如图6所示,其中图6c为预测夹爪抓取姿态可视化效果,且抓取位姿在相机1坐标系下。
2.3.1 神经网络模型
本文将GraspNet-Robust的神经网络模型分为接近网络、操作网络和容差网络3部分,网络总体模型如图7所示。神经网络前面的主干部分采用PointNet++的编码和解码部分[18]。将输入的N×3点云进行4次特征提取,主要操作为在欧几里得空间中,先通过最远采样法下采样点云数量,每次下采样的点云个数为[2 048,1 024,512,256],然后经过特征提取层,通过k邻域球查询的方式查找并聚合球内固定数量的点云来构建局部区域集,球查询的半径分别为[0.01,0.02,0.03,0.04](单位:m),对应每次球体内的聚合点云个数为[64,32,16,16]。每个局部区域集采用PointNet[16]神经网络方法进行编码变成特征向量,然后将这些特征向量经过两层特征传播层,通过反向插值的方法将基于k个邻域的反向距离加权平均作为点的特征向量,借助“跳跃连接”(skip link)与上一层特征提取层的点特征向量聚合,最终得到M×(3+C)的张量。简单来说,3+C表示从k邻域中提取相机捕捉到的目标中精细几何结构的局部特征。

将M个候选点输入接近网络,通过3层多层感知器(Multilayer Perceptron,MLP),维度分别为[256,302,302],输出一个M×(2+V)的张量,其中:2表示一个二进制的类别,判断该抓取点是否能抓取;V为该点预测的接近向量,定义抓取向量Vij表示第i个抓取点的第j个接近向量,通过预测V个接近向量的得分,挑选得分最高的Vij作为该候选点的接近向量,并通过索引获得该接近向量的3D空间位置坐标。
通过接近网络得到可抓取候选点以及候选点预测的抓取接近向量后,需要预测机械爪面内的旋转矩阵R、抓取深度D、抓取宽度W和抓取置信度得分S。
因为机械爪的抓取深度随不同的候选点变化,难以直接回归,所以将抓取深度分成K个类,本文将其设置为4类,分别为[0.01,0.02,0.03,0.04](单位:m)。在将M×(2+V)的张量输入操作网络前,先将M个点的特征信息与PiontNet++解码后M个点的特征信息对齐,再拼接特征信息,用于筛选抓取候选点并丰富每个候选点的抓取信息。将可抓取的候选点调用PointNet++中的CylinderQueryAndGroup函数,分割该候选点及其附近点云并聚合成半径固定的圆柱体形点云簇。然后给每个候选点建立一个统一的坐标表示,将每个候选抓取点设置为新的坐标系原点,该候选点的接近向量为坐标系的Z轴方向。根据4类给定的抓取深度,按照每个抓取深度分别沿接近向量靠近该候选点坐标系所在的圆柱体区域,直到在圆柱体内采样的点云数量达到固定值(设置为64个点),此时圆柱体的最大高度即为候选点预测的抓取深度。经过维度分别为(64,128,256)的3层共享参数的MLP,将经过对齐和聚合后的张量转化为高维特征信息,用于后续特征处理。
将预测的抓取深度与上述M个点的特征信息对齐并聚合,输入操作网络,经过维度分别为(128,128,36)的3层卷积层,输出预测的各个抓取位姿参数,包括抓取平面内的旋转矩阵R、抓取宽度W和抓取置信度得分S。采用力闭合度量法预测抓取得分,即根据摩擦系数μ预测每个抓取姿态的抓取置信度得分。设置抓取得分
S=1.1-μ。
(6)
设置Δμ=0.1为摩擦系数的变化步长,将μ从1逐步减小到0.1,直到无法抓取物体,因此将抓取置信度得分分为10类。摩擦系数μ越低的抓取得分越高,抓取成功率也越高。抓取宽度通过抓取点的距离信息得出,因此采用直接回归的方式。
与此同时,将M×(2+V)的张量输入容差网络,用于筛选具有鲁棒性的可执行抓取姿态。本文提出通过抓取力螺旋空间场F来提高抓取姿态预测的鲁棒性,由于每个抓取候选点有多个可抓取的姿态,需要从诸多抓取姿态中选取抓取成功率最高的抓取姿态,而因为只采用网络输出的抓取得分S排名靠前的抓取姿态作为结果,所以抓取成功率并不能达到最优。为了提高抓取成功率,采用抓取力螺旋空间场F的方法来判断抓取结果,对于数据集中标记的抓取姿态中的每个可抓取点,在其最大球邻域内,若满足90%的候选点抓取置信度得分S≥0.6,则该球体的半径即为抓取点的最大可抓取扰动范围,表示为
Tij=radius(P(S≥0.6)>0.9)。
(7)
通过GFSSF预测的每次抓取的最大扰动范围,即能够容忍可能具有错误的、可抓取姿态的最大范围,然后将操作网络和容差网络的信息聚合,选取抓取得分最高的K′个抓取姿态。这种通过力螺旋空间场最大扰动范围结合抓取得分排名进行抓取的方法,提升了预测抓取姿态的成功率。
2.3.2 损失函数
在训练过程中,通过下面的目标函数,对整个网络进行更新:
L=LA({ci},{sij})+αLR(Rij,Sij,Wij)+
βLF(Tij)。
(8)
式中:LA为接近网络的代价函数;ci为第i个点预测能否抓取的二进制数;sij为视点j到抓取点i的预测置信度得分;LR为操作网络的代价函数;Rij为抓取点平面内的旋转矩阵,为了简化预测回归的值,将其转化为抓取点平面内的旋转度数,本文将平面内的旋转角度分为12类,因为选用的二指平行的机械爪是对称的,所以预测的旋转角度范围在0°~180°之间;Sij,Wij分别为直接回归的抓取置信度得分和抓取宽度;LF(Tij)表示容差网络的代价函数,Tij为容差网络预测抓取点可以抵抗的最大扰动距离。
接近网络的代价函数表示为
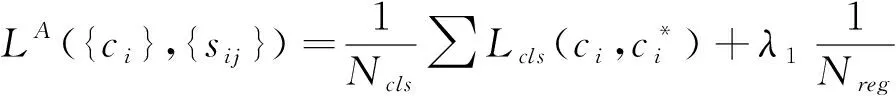
(9)

操作网络的代价函数表示为

(10)
式中:d为抓取的深度距离;因为Rij为多分类任务,所以Lcls采用softmax激活函数结合交叉熵损失函数计算损失值,Lreg采用平滑L1损失函数计算损失值。Ld为不同抓取宽度类别下的平均损失。
容差网络的代价函数表示为
(11)

3 机械臂抓取控制
3.1 机械臂与相机的手眼标定
3.1.1 手眼标定的算法
通常深度相机与机械臂安装分为“眼在手上”和“眼在手外”两种,“眼在手上”指深度相机安装在机械臂末端,使末端执行器坐标系和相机坐标系相对不变;“眼在手外”指深度相机安装在机械臂外,使机械臂基坐标系与相机坐标系位置固定不变,末端执行器坐标系和标定板坐标系同时移动,且保持相对位置不变[19]。本文采用“眼在手外”的标定方法,标定相机1与机械臂基坐标系的位置关系。令:
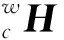


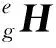
根据各个部分变换关系可得:
(12)
(13)
(14)
(15)

AX=XB。
(16)
其中:A根据机械臂正向运动参数直接获取,B根据深度相机标定棋盘格位姿求得。根据传统线性求解法求得X在相机1坐标系相对于机械臂基坐标系下的齐次变换矩阵,为后续机械臂抓取物体做准备。最后得到的齐次变换矩阵可拆分为旋转和平移矩阵。
3.1.2 手眼标定的定位精度实验与分析
令机械臂末端夹持棋盘格标定板,棋盘格与夹爪的相对位置固定不变。移动机械臂依次到达13个不同位姿,采集相机视野内的图像,并记录每次运动过程中机械臂末端夹爪中心在机械臂基坐标系下的位姿,包括X,Y,Z坐标,因为AR5机械臂的定位精度达到±0.6 mm,远小于待抓取物体尺寸和夹爪尺寸,对抓取结果没有影响,所以将可直接读取的机械臂末端位姿数据视为真实值。将相机坐标系下棋盘格的坐标通过3.1.1节中标定的结果转化到机械臂基坐标系下,并与真实值进行比对分析。因为通过双相机的标定结果将相机2的点云转化到相机1坐标系下,两幅点云基本重合(如图4),所以只要将合成后的点云转换到机械臂基坐标系下即可。通过计算13个位姿,由相机获得的机械臂基坐标系下沿X,Y,Z轴的运动变化量与真实值之间误差的平均值分别为2.677 784 mm,2.351 656 mm,2.232 656 mm。
因为在实际操作中,物体尺寸和夹爪的可抓取尺寸远大于定位误差,而且以上求得的误差并未影响所抓取的物体,所以认为手眼标定的精度足够高,能够满足目标抓取任务的需求。
3.2 机械臂运动控制
机械臂使用尔智公司生产的AR5六轴机械臂,分别为基座、肩、轴、腕1、腕2、腕3。采用RJ-45连接器即双绞线以太网接口,连接机械臂控制系统和上位机,通过TCP/IP协议分配端口实现机械臂与上位机之间的通信,并利用与AR5机械臂配套的SDK接口对机械臂进行编程,控制机械臂运动。抓取系统中机械臂的运动路径借助机械臂自身的运动模块结合运动学模型,通过上位机与机械臂交互,将上位机预测的机械臂基坐标系下夹爪的3D位置和3D方向传输给机械臂,机械臂借助机械臂系统运动解算规划出一条运动路径,向作业空间内的指定位置移动。运动过程中,以机械臂基坐标系作为参考坐标系,以夹爪为机械臂末端执行器的工具坐标系作为进给坐标系,在安全模式下工作,防止机械臂与工作台发生碰撞以及机械臂自身轴旋转发生碰撞。
4 实验与分析
4.1 神经网络模型训练
本文GraspNet-Robust神经网络模型在GraspNet-1Billion数据集上训练,包括在190个复杂场景下由两种深度相机(Kinect 4 Azure和RealSense 435)在不同视角下拍摄的512张RGB-D图像。其中100个场景图片用于训练集,90个场景图片用于测试集。每幅图像通过力闭合方法密集标注6-DOF抓取姿势,数据集共有超过11亿个抓握姿势。该数据集中包括88种物体,因为这些物体有适合抓握的尺寸,而且在形状、质地、尺寸、材料等方面各不相同,所以多样的局部几何形状可以为算法带来更好的泛化能力。
网络训练环境在Ubuntu 16.04 LTS系统下、单个GeForce GTX 3090 16 G显存的GPU上训练,采用基于Cuda 10.1环境的Pytorch 1.6.0计算架构,并用Adam优化器进行优化,用LambdaLR方法调整学习率。共训练18个周期,样本数批次为4,初始学习率为0.001,第8个周期后学习率降至0.000 1,第12个周期后降至0.000 01,第16个周期后降至0.000 001。式(8)~式(10)中的超参数设置为λ1,λ2,λ3,α,β=0.5,1.0,0.2,0.5,0.1,神经网络中C=256,V=300。最后用获取的权重文件预测实际抓取结果。图8所示为训练过程中的总体损失函数下降图(即式(8)的值),图9所示为基于力螺旋空间场的容差网络的损失函数下降图(即式(11)的值),图10所示为接近网络预测候选抓取点的精确度,图11所示为预测候选抓取点的召回率。



测试时将拼接后的点云文件输入神经网络,最后输出一个50×17的张量,表示前50个抓取置信度得分最高的抓取姿态。其中17维的数据包括抓取置信度得分、抓取宽度、抓取深度、夹爪平面内旋转矩阵和夹爪的平移向量。神经网络预测结果如图12所示,其中选取了前50个抓取得分最高的夹爪抓取姿态进行可视化,不同抓取深度对应不同的颜色。

4.2 机械臂抓取结果验证
本文在实际环境中搭建了完整的机械臂抓取系统。在Windows 10系统下,PC端用以太网接口连接机械臂,用USB 3.0接口连接机械爪,用两个USB 3.0接口连接两个深度相机。在机械臂工作平台上放置多样物体,包括数据集中的物体和数据集外未知的物体,分别进行抓取预测,然后将抓取数据传递给机械臂和机械爪进行抓取,抓取成功率实验结果如表1所示,可见平均成功率达到了91%。

表1 已知物体和未知物体的抓取成功率对比
当物体包含于数据集时,其预测结果比预测未知物体的成功率高6%。本文提出用双相机点云融合的方法对物体进行点云拼接,对比多视角融合预测结果与单视角(俯视)预测结果,以及有无点云预处理的预测结果,结果如表2所示。可见相同抓取条件下,相比单相机视角,双相机视角拼接点云方法的抓取成功率提高了4%。

表2 单相机、双相机的抓取成功率和时间对比
本文提出的机械臂抓取系统旨在实时抓取,为验证采用多相机融合点云方法的机械臂抓取系统反应时间的快慢,本文记录了双深度相机从拍摄一帧RGB-D图像到输出预测得分最高的前50个结果的时间,并与相同操作下的单相机进行比对。结果表明,在采用点云预处理的前提下,相比单相机方法,虽然双相机方法预测过程的平均处理时间多0.313 9 s,50次抓取实验即为15.695 s,但是单相机方法平均每抓取失败一次会浪费2 s,因此双相机视角下的高抓取成功率更加满足实际应用。
为了评估容差网络中改进力螺旋空间场的有效性,本文对改进的容差网络进行了消融实验。首先,用GraspNet-1Billion数据集对不包含力螺旋空间场的GraspNet-Robust神经网络进行预训练,输入双相机获取的点云数据,直接选取得分最高的抓取姿态进行抓取;然后,用GraspNet-1Billion数据集通过包含力螺旋空间场的GraspNet-Robust进行预训练,查找并统计每个抓取姿态标记的可抓取点最大球邻域内的其他候选抓取点的抓取得分,若抓取姿态每个抓取点邻域内90%候选点的抓取置信度得分S≥0.6,则认为该抓取点为有效抓取点。对两个预训练结果进行测视,输入相同的点云数据,挑选S最大的抓取姿态进行抓取。如表3所示,在相同实验条件下抓取100次,其中已知物体和未知物体各50次,相比直接评估回归抓取分数,通过结合GFSSF和评估抓取分数方法抓取的成功率提高了4%。

表3 有无力螺旋空间场消融实验
5 结束语
本文建立了一套机械臂自主抓取系统,通过程序完成机械臂从目标检测到抓取目标。为了解决单深度相机视角下3D特征不稳定的问题,提出多视角点云融合目标的方法,并与单视角方法分别进行了50次抓取实验,结果多视角点云融合方法的抓取成功率为92%,比单视角点云方法的抓取成功率高4%。同时建立了一个端到端的神经网络,提出通过力螺旋空间场来评估预测结果,并与无力螺旋空间场的神经网络分别进行了100次抓取实验,结果表明有力螺旋空间场的神经网络的抓取成功率达到91%,相比提高4%,增加了预测结果的鲁棒性。基于深度学习的抓取预测还需要庞大的数据集支撑,因为已包含在数据集中的已知物体抓取成功率比无数据集的未知物体抓取成功率高6%,所以通过丰富数据集,可以使所提方法具有更优的泛化能力。虽然多视角点云融合目标方法相比单视角点云的预测结果准确,但是处理时间更长,其比单视角增加了0.313 9 s的预测时间,影响了机械臂的实时性,因此未来研究将提高多视角点云融合方法的预测速度。
