基于融合改进K-means 聚类算法的数据检测技术
2024-03-11郭克难
郭克难
(河北北方学院附属第一医院,河北张家口 075000)
在当前数字化建设广泛普及的背景下,社会各单位对办公、财务及业务系统的信息化建设均较为重视。尤其当进入大数据时代后,财务系统的设计与应用更加趋向于智能化和高效化,这对于财务数据准确率的提升也有极大帮助[1-2]。财务数据具有维度高、数据量大的特点,因此分析平台中核心算法的性能优劣直接决定了该数据流通以及信息整合的效率[3-4]。
在多数医疗机构中,由于数据繁杂、迁移不便与投入较少等原因,存在信息化平台老化、数据处理性能不佳的问题。已有的系统设计难以适用于当前多变的财务环境,检测系统异常数据的准确率也较低,从而导致坏、死账率过高。因此,该文对传统K-means 算法进行改进,使其具有处理大数据的能力,进而在不改变原有系统架构的前提下提升了财务系统检测异常数据的能力。
1 异常数据检测算法设计
1.1 K-means聚类算法
该文所采用的基础K-means 算法[5-7]首先需要确定数据簇的数量K,即有K个簇中心,且这些簇中心在初始数据样本集合D中产生。确定簇中心后,计算簇数据点xi到每个中心点的欧氏距离,计算公式为:
式中,Ci表示数据点xi与簇之间距离最近的类别;μj为数据类的簇中心,其计算公式如下:
其中,l{·}表示距离的集合,根据距离最短原则将xi划入某个簇中并进行多次迭代,直至数据点被分类完毕,算法结束。该算法的执行流程如图1所示。
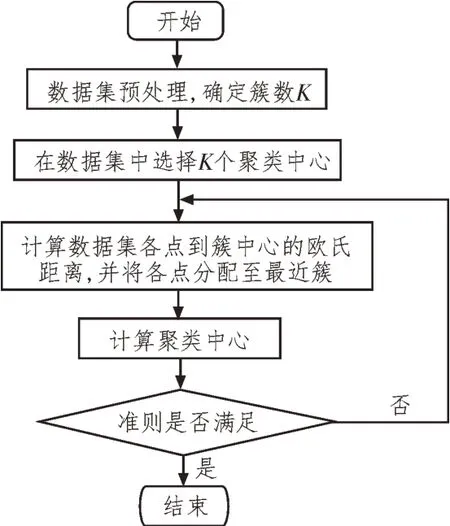
图1 K-means算法执行流程
由上述流程可见,该文采用K-means 聚类算法的实现难度低且建模准确度高,可以对数据进行初步分类。但聚类数量选择的随机性会造成一定的误差,因此需要对原始K-means 算法进行一系列的优化。
1.2 聚类中心优化算法设计
密度峰值聚类(Density Peaks Clustering,DPC)算法[8-10]能对K-means 算法的缺陷进行改进。对于DPC 而言,有两个关键性指标:两个不同点之间的局部密度值和数据点到更高密度簇点的距离。文中使用这两个关键性指标对密度峰值进行定义。假设某簇中的数据点为xi,则该点的局部密度值可表示为:
式中,ψ(·)是一种狄利克雷函数,当自变量>0时,该函数为0,否则函数为1;dc为截断距离;ρi为xi数据点的局部密度。
数据点到更高密度簇点的距离Di可表示如下:
在选取聚类中心时,通常选择Di和ρi数值较大的数据点。设在数据集合D中有数据点xi及xj,若xi的局部密度大于xj,则称xj依赖于xi,此时可将该例引申至数据集合中;若其中的一组数据存在递进依赖链,则最强的依赖项即为簇的聚类中心。
1.3 最优聚类数目选择算法
在传统的K-means 聚类算法中,核心思想均是在已知聚类簇数量的情况下完成后续的算法操作。这种方式主观性较强,对于维度较高的样本,无法通过数据直观地对聚类簇数量进行判断。同时,若直接确定簇的数量,则在后续分类过程中对隶属度较低边缘模糊点的分类准确率也偏低。因此,该文通过主成分分析法(Principal Component Analysis,PCA)[11-13]对数据的聚类簇数量进行确定,并使用聚类有效性指标改进算法,最终根据数据的特征,自适应地确定最优聚类数量。
由于医疗财务数据的维度较高且具有诸多边缘特征,因此,文中首先使用PCA 算法对数据进行降维操作。该算法的作用主要体现在两个方面:1)消除数据在高维度空间中存在的冗余信息;2)对高维数据中难以计算和分析的特性进行简化。通过对数据进行预处理,将所得结果表征为矩阵的形式。设矩阵中的元素为xkj,然后计算数据集中两个不同变量的协方差参数为:
根据式(6)构建矩阵的特征值方程,同时计算该矩阵的特征值λi以及其所对应的特征向量,同时将特征值进行排列。然后再计算主成分贡献率,并对数据进行降维。主成分方差贡献率和累计方差贡献率的计算公式为:
最终输出主成分数量,进而得到预处理后的数据。
1.4 基于LOF的数据离群点检测算法
局部异常因子(Local Outlier Factor,LOF)算法[14-16]是一种用来描述数据点离群程度的因子,该算法可根据K-means 聚类算法的结果来获得离群点周围的数据密度。该文将LOF 算法放置于K-means 算法之后,后者聚类会产生一些离群点,而前者则将聚类得到的簇作为算法的一个检测域。设某点的局部密度和领域内数据点的密度接近,即认为该点是正常数据;否则为异常数据。LOF 离群点检测示意图如图2所示。
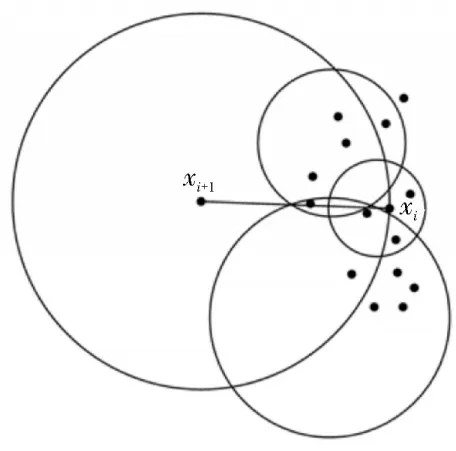
图2 LOF离群点检测示意图
假设数据集D的维度为d,且D中的数据点用xi表示,则数据集中任意相邻两点的欧氏距离可表示为:
而点xi的第k个距离可定义为dk,其是指点xi附近的密度值,当dk值较大时,表示周围的密度较小;反之亦然。从该定义可引申至第k个邻域的概念,由此可知,数据集合中点xi到xi+1的可达距离如下:
由式(10)可知,任意两点的可达距离实际就是点xi+1的第k个距离与xi到xi+1真实距离的最大值。因此局部的可达密度则表示为:
点xi的离群因子使用可达密度进行表示,则有:
由此可见,利用LOF 算法对数据离群因子进行计算时,由于使用了改进的K-means 算法完成分簇,所以产生的离群点较少,因此仅使用少量计算资源便可以对离群因子进行计算并排名,从而得到异常数据的检测结果。
1.5 基于改进K-means的异常数据识别算法
基于上文的理论分析和模块改进,该文在上述算法优化的基础上提出了一套医疗财务异常数据识别算法,其总体结构如图3 所示。

图3 算法结构
首先,融合PCA 算法对数据进行降维;降维后的数据输出到基础K-means 算法中完成分簇,且簇数量由数据维度决定;同时,使用DPC 对K-means 聚类中心加以优化;然后采用LOF 算法对模型的数据离群点进行检测;最终,根据离群因子的排名判断出异常数据。
2 实验与分析
2.1 实验环境与数据样本
该文使用Matlab 平台对算法进行实现,实验的环境配置如表1 所示。

表1 硬件环境
该文所采用的聚类数据集为人工和真实数据集,其中前者为虚假二维数据集,主要是不规则的分簇点集合,其可以对算法的聚类性能进行有效验证;而后者则为某大型医疗机构2017-2021 年的财务数据,且对该数据进行了归一化预处理。
2.2 算法测试
首先使用人工数据集对文中所提算法的数据聚类性能进行验证,该数据集选择的标签为:Ring、FuzzyX、Zigzag、Para 与Moon。同时,采用基础Kmeans、FMK-means、DBSCAN 以及K-means-DPC 这四种对比算法来验证该文算法的性能。此外,还选择了调整兰德系数(Adjusted Rand Index,ARI)指标对算法进行评估,ARI 指数越趋近于1,表示算法的聚类效果越优,具体测试结果如表2 所示。
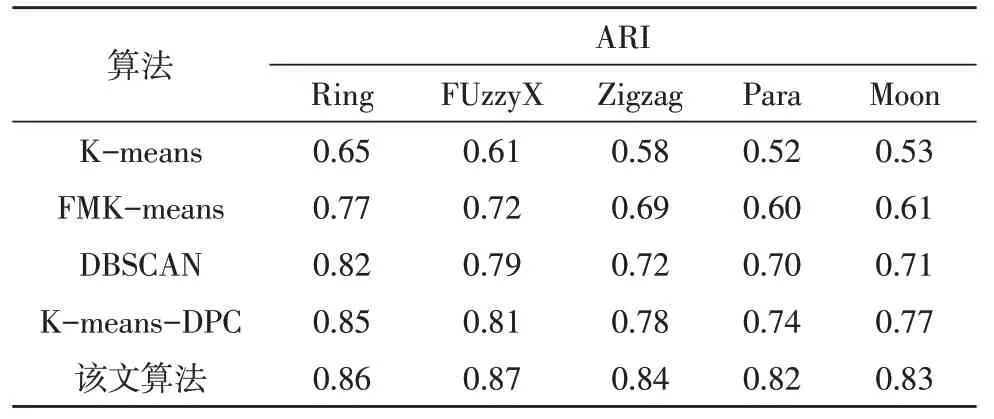
表2 不同算法的聚类性能对比
从表2 中可以看出,该文算法对多个不平衡人工数据集的聚类效果均较优,且在所有算法中ARI的指标最高,而基础K-means 算法在所有数据集中的表现均最差。由此表明,该文对基础算法的改进是有效的。
除了算法的理论性能外,文中还对算法检测真实异常数据的能力进行了检测[17-19]。通常而言,异常数据均为离群数据,因此使用离群因子对该数据的离群能力进行测试。使用的数据集为真实数据集,并对其中的异常数据均做了标记,评估指标为检测准确率,而使用的对比算法则为K-means-LOF、FMK-means-LOF、DBSCAN-LOF、K-means-DPCLOF 以及该文算法。算法测试结果如表3 所示。

表3 不同算法对异常数据的检测准确率
由表3 可知,基础K-means 算法的准确率最低,仅为68.5%;在其基础上增加了DPC 的改进算法,准确率达到了76.8%;而该文算法则进一步引入了PCA降维的环节,因此准确率达到了79.2%,在所有算法中最高。
3 结束语
为了提高医疗机构财务系统对异常数据检测的准确性,该文基于改进K-means 算法提出了一种适用于各类常见平台的异常数据检测算法设计。针对基础K-means 算法簇中心点选择随机与分簇精度较差的问题,文中结合了DPC 算法对数据集合的密度情况进行计算,进而选择出最优簇中心点。同时融合了PCA 方法对数据进行降维,提高了运算的速度并确定簇数量。最后通过LOF 对离群点进行测试,进而检测出异常数据。实验结果表明,该文算法在人工和真实数据集测试中的指标均为最优,证明了该算法的综合性能良好,可以对常见的异常财务数据进行准确地检测。
