基于自适应权重与透镜成像学习的麻雀算法
2024-03-11史洪岩蔡志豪
史洪岩,蔡志豪
(沈阳化工大学信息工程学院,辽宁沈阳 110142)
群智能优化算法根据对自然界中生物群落个体之间的互相合作以及信息交换的模仿来找寻各种繁杂优化问题的最优解。近年来,群智能优化算法凭借其简单灵活的特点在优化领域中受到了广泛的关注。
麻雀搜索算法是薛建凯[1]在2020 年提出的一种群智能优化算法,自提出以来,麻雀算法相较于其他优化算法,凭借其原理简单高效、搜索速度快等优势被广泛应用。然而,基本的麻雀算法同大多数优化算法一样,仍然面临着求解精度不足、不能跳出局部最优值等问题。因此,部分学者对其进行了改进。文献[2]在发现者位置公式中引入自适应权重并改进边界约束,增强算法的寻优效果及搜寻速度。文献[3]通过引入自适应T 分布对麻雀个体进行变异扰动的方式,防止算法陷入局部最优。以上研究从不同角度在一定程度上对SSA 的寻优性能有了提升,但仍有改进的余地。
针对SSA 存在的不足以及为了提高SSA 的寻优性能,提出一种基于自适应权重与透镜成像反向学习的改进麻雀搜索算法(LIW-SSA)。通过找寻九个基准测试函数最优解并进行对比,证明LIW-SSA 是有效可行的。
1 麻雀搜索算法
麻雀搜索算法是受大自然中麻雀种群的行为特征启发而设计的一种优化算法,根据模仿麻雀种群的觅食与反觅食活动来实现全局寻优求解。在麻雀种群中发现者的作用通常是搜索食物并且为其他麻雀供应食物来源,加入者则通过监视发现者掌握食物来源。另外,当某只加入者的食物来源优于发现者,便取代了发现者的身份。反捕食行为由麻雀种群中意识到危险的警界者负责,当危险来临时,迅速向其他位置移动。
发现者的位置更新公式为:
加入者的位置更新公式为:
式中,Xworst表示在所有麻雀中占据的最劣位置,n为麻雀数量,是发现者中的最优位置,A是1×d的矩阵(所有元素均随机取值为1 或者-1),且A+=AT(AAT)-1。
警界者的位置更新公式为:
2 基于多策略融合的麻雀搜索算法
2.1 Circle混沌映射
在基本的麻雀搜索算法中,麻雀种群的产生是随机的,这往往会出现麻雀种群多样性低且分布不均匀的问题[4]。混沌映射可以生成混沌序列,混沌序列分布与随机生成相比更为均匀,故可以用来生成麻雀种群[5]。目前,常被使用的映射有Logistic 映射、Circle 映射等,如图1 所示,在分别经过300 次与500次迭代后,Logistic 映射生成的混沌序列在接近1 和0处分布相对密集,而Circle 映射与之相比整体分布较为均匀,所以该文将Circle 映射用来生成麻雀种群。

图1 混沌映射分布图
Circle 映射公式如下所示:
其中,a=0.5,b=0.2,i为映射产生的序列号。采用Circle 映射生成种群的步骤如下:首先,随机生成一组d维序列,然后,根据式(4)进行迭代,直至产生N(麻雀种群规模)组d维序列,最后,将其映射到算法的优化空间中。
通过采用Circle 映射策略来代替麻雀算法中的随机生成种群方式,使得麻雀种群质量更高且分布更均匀,从而提升算法找寻最优解的速度。
2.2 自适应权重因子
在基本麻雀算法中,式(3)中的β由于取值为随机值,使得算法在前后期的搜索能力大打折扣[6]。在文献[7]的启发下,将自适应权重因子w引进到麻雀警戒者更新公式中,在搜索前期,权重较大,能够很好地提高算法的全局开发能力;在搜索后期,权重较小,又能大大提高算法的局部挖掘能力。w的数学表达式为:
式中,t为算法当前迭代次数,P的值为500。
引入w后的警戒者更新公式如下:
通过在警戒者的更新公式中引进自适应权重因子,有利于加强算法早期所需的全局开发与末期所需的局部挖掘能力,从而能够进一步提升算法的求解性能。
2.3 透镜成像反向学习策略
针对麻雀搜索算法跳出局部最优能力弱的缺陷,许多学者引入反向学习策略[8-11]来改善算法的性能,根据当前麻雀位置生成反向位置,以此寻求最优解。与反向学习相比,透镜成像反向学习策略[12-13]能更好地扩大搜索范围,找寻最优解。透镜成像原理图如图2 所示。
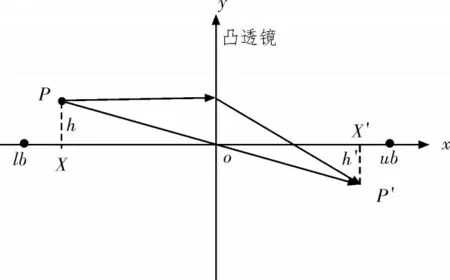
图2 透镜成像原理图
如图2 所示,假设在区间[lb,ub]的空间范围内存在个体P,其高度为h,在x轴上的投影为X。通过放置在o点(为[lb,ub]的中点)的凸透镜成像可得到高度为h′的P′,其在x轴上的投影为X′,则由成像原理可以得到:
由式(8)可以清晰地看出,当k的值为1 时,公式变为一般反向学习策略。另外,通过式(8)可以得到在D维空间中的公式如下:
该文将一般反向学习策略与Circle 映射相结合来初始化麻雀种群,Circle 映射可以使初始麻雀个体在搜索空间内分布较为广泛,再通过一般反向学习策略生成反向种群,根据麻雀个体优劣确定最终种群,因此提升了算法的初始种群质量以及收敛速度。最后采用透镜成像反向学习策略对当前最优麻雀个体进行扰动,生成新的麻雀个体,并引入贪婪机制:首先求出最优麻雀个体与透镜成像反向学习策略生成的反向个体的适应度值,然后对适应度值进行比较,最后选择适应度值较优的麻雀个体作为当前的最优麻雀个体,从而大大降低了算法陷入局部最优的可能性。
2.4 LIW-SSA算法步骤
LIW-SSA 算法的整体实施流程如下:
步骤一:确定相关参数:如搜索空间界限、种群数量、算法迭代次数、发现者数量、警戒者数量等。
步骤二:初始化麻雀种群:首先,将Circle 映射用来生成麻雀种群(种群规模为N),然后,利用一般反向学习策略产生一个与之相反的种群并与初始种群合并(种群规模为2N),最后,根据麻雀个体的适应度值大小选取前N个麻雀作为最终种群。
步骤三:记录最优、最差麻雀个体的适应度值与相应位置。
步骤四:根据麻雀的适应度将排在较前的个体视为发现者,根据式(1)进行位置更新。
步骤五:除发现者外的所有麻雀均为加入者,根据式(2)进行位置更新。
步骤六:在所有麻雀中随机抽取部分个体为警戒者,根据式(6)进行位置更新。
步骤七:按照式(9)对当前最优麻雀进行透镜成像学习,生成新的麻雀个体,并根据适应度值大小决定是否替换。
步骤八:更新最优值、最差值以及对应位置。
步骤九:反复执行步骤四至八,直到达到算法最大迭代次数,输出最终结果。
3 LIW-SSA性能测试与分析
为了检验该文提出的LIW-SSA 是有效可行的,从文献[14]中选取F1-F8、F13九个基准测试函数并对其进行寻优求解,在文中表示为F1-F9,其中F8-F9为多峰测试函数,其余均为单峰测试函数,所有测试函数的维度均为30。
3.1 不同优化算法之间的对比
将LIW-SSA 与SSA、GWO(灰狼优化算法)[15]、WOA(鲸鱼优化算法)[16-17]进行性能测试对比,每种算法的种群规模均为30,算法迭代次数均设置为500,麻雀算法中的发现者和警戒者数量分别占种群规模的20%、10%。另外,由于群智能优化算法存在很大的不确定性,故为了确保测试结果的公平每种算法均测试30 次,最终仿真测试结果如表1 所示。
根据表1 可以看出,在函数F8中,GWO 的标准差最小,SSA 次之,LIW-SSA 与WOA 不相上下。在除F8之外的其余函数中,LIW-SSA 的标准差均小于其他算法,说明了LIW-SSA 算法比其余三种算法的稳定性能要好。另 外,对于函数F1、F3,LIW-SSA 与SSA 相较于另外两种算法都能够达到理论最优值,而对于函数F4,只有LIW-SSA 找到了理论最优值,对于函数F2,F5-F9来说,尽管LIW-SSA 没有找到理论最优值,但相较于另外三种算法均有不同程度的提升。在所有测试函数的仿真实验中,LIW-SSA 的平均值远远领先于另外三种算法。通过对最优值以及平均值的比较,证明了LIW-SSA 的寻优性能较好。综上所述,LIW-SSA 算法稳定性及寻优精度均优于其余三种算法。
3.2 改进策略之间的对比
为了验证不同改进策略对SSA 的贡献,将LIW-SSA 与SSA、融合透镜成像反向学习策略的LI-SSA以及引入自适应权重因子[18-19]的W-SSA 进行寻优实验对比。在测试过程中,算法的迭代次数均设置为1 000 次,麻雀种群规模均设定为100,发现者和警戒者数量分别设置为种群规模的20%、10%。目标函数的最终仿真测试结果如表2 所示。

表2 不同策略的仿真数据
根据表2 分析得出,两种不同的改进策略对麻雀搜索算法均有不同程度的提升。通过函数F1-F4的仿真,虽然四种算法都能够达到目标函数的最优值,但LIW-SSA 的平均值以及标准差有了极大的提升,同样在函数F5、F7的对比中,LIW-SSA 的平均值以及标准差也有了几个量级的提升。在函数F6、F8、F9中,W-SSA 的寻优 精度是 最高的,LIW-SSA 次之。总体而言,在九个测试函数中,LIW-SSA 寻优效果较好。在其余算法的比较中,LI-SSA 在函数F1-F4中表现较好,W-SSA 在函数F5-F9中占据明显优势。因此验证了SSA融合两种改进方法是有效可行的。
为了更加直观地观测改进策略对SSA 的影响,给出函数的收敛曲线如图3 所示。可以看出,对于函数F1-F4,LIW-SSA 与LI-SSA 都能够 找到目标函数最优值,且求解精度与速度领先于另外两种算法,W-SSA 在收敛速度以及寻优精度上略微领先于SSA。通过函数F5、F8可以看出LIW-SSA 和W-SSA在收敛速度以及寻优性能上表现良好,LI-SSA 的收敛速度与SSA 大致相同,但在求解精度上略胜一筹。在函数F6、F7、F9上虽然四种算法收敛速度不相上下,但LIW-SSA、LI-SSA、W-SSA 的寻优精度与SSA 相比均有不同程度的提升,故通过收敛曲线的对比再次证明了该文提出的改进策略的有效性以及LIW-SSA 的优越性。

图3 收敛曲线图
4 结论
该文在SSA 的基础上利用Circle 映射+一般反向学习机制初始化麻雀种群,提升了种群丰富性,然后通过将自适应权重因子w引入到警戒者更新公式中,加强了算法前期所需的全局开发以及后期所需的局部挖掘能力,最后将透镜成像反向学习策略应用到当前麻雀最优个体上,避免算法陷入局部最优。经过九个基准测试函数的寻优求解对比实验,证明了该文提出的LIW-SSA 与其他群智能优化算法如GWO、WOA 以及单策略的LI-SSA、W-SSA 相比,无论是算法的寻优精度还是稳定性都得到了极大改善。
