基于并行式频繁项集的党政收费平台
2024-03-11郭振华孙艳青王中兴
郭振华,孙艳青,王中兴
(1.北京国电通网络技术有限公司,北京 100070;2.北京中电普华信息技术有限公司,北京 102218)
当前党建工作管理进入信息化时代,线上党政收费平台正在积极开发与优化中。以信息化手段构建新型党政收费管理平台,与国家倡导的加强党政建设工作信息化管理步调一致[1]。现有党政收费平台基本支持全国党员、基层党组织的党费收缴功能,创造了便捷的党费查询和交纳服务[2-3]。不足的是,党政收费平台功能单一,缺少党建工作信息查询、党建热点消息推送等功能。为满足党员与基层党组织的信息管理、热点信息查询、党费缴纳等需求,研究基于并行式频繁项集挖掘技术开发高效率的党政收费管理平台,在保障基本党政收费信息管理基础上,集成党建学习、党建热点消息推送等功能,提高信息传播速度、扩大党建学习信息覆盖面。
1 基于并行式频繁项集挖掘的党政收费管理平台
1.1 党政收费管理云平台总体架构
利用云计算技术开发党政收费管理平台,基于云计算虚拟化技术统一调度管理虚拟资源[4]。同时,应用并行式频繁项集挖掘算法对党政收费信息、党建工作信息进行分类处理[5],为党员及基层党组织提供高效率的党政信息服务。该平台一方面解决了平台软硬件资源统一管理问题;另一方面高效整合了党政收费信息,向基层党组织提供党费管理与党建工作信息的服务,实现了基层党员教学信息资源数据共享。利用云计算技术构建的党政收费管理云平台架构如图1 所示。

图1 党政收费管理云平台架构
党政收费管理云平台由用户接口层、应用服务层、云计算平台层以及最底端的基础资源层四个层次构成[6]。其中,应用服务层集成了频繁项集挖掘算法,以实现党政收费信息与党建工作信息的智能化管理等服务功能。云平台各层次功能设计如下:
1)用户接口层。用户通过计算机端、智能终端等设备进行资源获取,经过身份认证后登录到党政收费平台,基于自身分配权限获取信息列表[7],在党政服务中心获取相应的服务资源,实现缴费、教育学习、信息浏览功能。用户接口层从类别上具体分为控制中心、客服中心、党政服务中心,客服中心由管理者、决策者、专业用户群组成。
2)应用服务层。该层次紧接用户接口层,集成了党政云缴费模块、教育学习模块、党建宣传模块、个性党务模块、电子化党务模块等,为用户提供多元化的党政相关服务;其中,党政云缴费模块提供查询历史交易查询、缴费账单查询功能,其优点是支付方式丰富,党员与基层党组织可以采用多元化的线上支付方式进行缴费,党政收费方式愈加多元、便捷。
3)云计算平台层。底端物理设备同顶端应用层由云计算平台层进行连接,方法是将Hadoop 云计算平台部署在虚拟集群,分别基于HDFS 文件系统和Spark 框架对文件进行管理以及数据处理。分布式文件系统应用“单个namenode 节点+多个datanode节点”模式实现党政收费数据的分布式存储,采用“块”存储策略,datanode 节点具备冗余备份存储功能,保障了收费数据的安全性与完整性。通过应用Hbase 部件扩展云平台在数据管理和分布式存储方面的功能,以提升云平台搭建完整性。
该层次构造党政收费频繁项集挖掘模型,利用“主-从”节点模式实现并行式频繁项集挖掘,获得党政收费管理信息分类结果;同时应用多个数据处理模型清洗原始采集的基础数据,并进行格式转换等处理。
4)基础资源层。基础资源层由虚拟资源机和物理资源机构成,是支撑整个党政收费管理平台功能实现的基础[8]。其一,物理机由计算机与网络构成,提供计算资源、存储资源、网络资源等硬件基础设施;其二,虚拟机基于虚拟技术、以计算机为基础虚拟化而成,是云计算平台部署安装、数据存储的场所。虚拟机联网构成一个分布式的计算环境,区别于传统的服务器以虚拟化形式存在,其优点是充分发挥硬件资源作用,避免物理资源的繁琐性,维护虚拟机同收费管理系统的关系即可,降低数据管理的难度。
总体而言,虚拟机部分实现了服务器虚拟化、网络虚拟化、数据库虚拟化以及存储虚拟化,物理机部分集成了服务器节点、网络服务节点、数据库以及大数据存储节点。
1.2 基于Spark与矩阵的频繁项集挖掘算法
1.2.1 频繁项集挖掘
频繁项集挖掘是从已有的数据集中对比“项集支持度”与“阈值”挖掘出全部频繁项集。数据集中包含该项集的全部事务总数称为项集的支持度。当一个项集支持度超过预设的最小支持度阈值时,将该项集被认定为频繁项集。
定义D={T1,T2,…,Tn}为一个事务集,{i1,i2,…,im}表示一个事务,并涵盖一组项集。每个项集的支持度用包含此项集事务的数量来表示,当项集满足X∈T时,式(1)为支持度的计算方法:
当存在20 个事务,X出现于其中的四个时,计算得到X的支持度为0.2;当项集支持度大于最小支持度阈值时,此项集则被认定为频繁项集。
为实现并行式频繁项集挖掘,该平台开发基于Spark 分布式计算框架之上,一个主节点和多个工作从节点构成了Spark 集群,从节点由主节点进行资源与任务分配。在Spark 框架下,Hadoop 分布式文件系 统(Hadoop Distributed File System,HDFS)、Open StackSwift、Cassandra 等格式的数据存储均被允许。数据读取完毕,继续实施运算,计算结果存储在文件系统之中。文中基于Spark 平台实现矩阵频繁项集挖掘算法,文件存储系统应用HDFS。
1.2.2 矩阵的频繁项集挖掘算法
平台以B/S 架构作为支撑、基于Linux 操作服务端,使用Web 服务器构建SQL Sever 数据库;以党政费用管理与党建工作信息管理为目的设计平台功能模块进行设计,构建了包括党员用户信息、缴费信息、党组织活动、教育学习资源等内容的数据库关系表,满足党员与平台管理人员的收费与信息管理需求。云平台的党政收费信息过于庞杂,为此基于并行式频繁项集挖掘算法对其进行分类,该算法突破了多次扫描数据库信息的弊端,变革式地采用分布数据库的各个处理器单独实施党政收费数据挖掘,以降低频繁项集大小、缩减频繁项集的通信频次与同步次数[9],优化党政收费信息分类挖掘的效率。
研究采用矩阵式频繁项集挖掘算法代替传统频繁项集挖掘,目的在于减少频繁项集挖掘的冗余工作、缩短数据挖掘时长。文中算法基于矩阵存储数据,基本实现思路如下:只需扫描一次矩阵,并根据矩阵行列间运算获得频繁k项集的支持度[10]。在此基础上,基于“主-从”节点模式,由主节点开始运算并以“子矩阵”的形式描述该矩阵,为各个从节点分配这些子矩阵展开运算,经过从节点并行计算处理之后,将结果反馈到主节点。具体实现步骤如下:
首先,构造党政收费频繁项集挖掘矩阵。矩阵选用“0-1”模式[11-13],将待挖掘信息存储在其中,如此,求取频繁k项集支持度时计算每一行“1”的个数即可。设定事务数据库D并定义m表示事务数量、n表示项目数量;同时定义一个包含m行n列的矩阵H[14]。当项目P属于事务T的情况下,则矩阵中的X值为“1”,反之为“0”。通过优化矩阵H构建崭新矩阵M*,为频繁k项集计数;增加1 列R,R列中每个值为每一个项目P的支持度求和,即R=Xi1+Xi2+…+Xin,计数前归零全部R值。图2 描述了新矩阵H*的形式。

图2 矩阵H*的崭新形式
其次,设计主节点与从节点算法实践策略。主节点算法部分:求取矩阵H中每个项目P的R值,对比每个R值与定义的最小支持阈值,删除最小支持阈值以下的项目所在行,反之不予处理[15-16]。举例说明:第一步,预设2 为最小支持阈值,两两组合主节点的项目,分送给从节点计算后将结果返回得到频繁2 项集矩阵,原矩阵H被覆盖;第二步,划分频繁2项集矩阵的项目并实施分组,然后将其分送到从节点部分,进而求取频繁3 项集矩阵,紧接着覆盖频繁2 项集矩阵。按照上述策略持续操作,获取频繁k项集矩阵H*′时终止。
2 实验分析
为了验证文中开发的党政收费管理平台的优越性,搭建分布式平台测试环境,构建Spark 集群内含一个主节点、五个从节点,主从节点的连接由100 Mb/s以太网转换器实现,节点在不同计算能力的设备上运行。配套选用2.6 版本的Hadoop 以及1.6.0 版本Spark 软件。平台利用Scala 编译语言进行矩阵频繁项集挖掘算法编程。测试前采集大量党员收费信息与党建学习数据,包括党费缴纳金额、缴费时间、缴费项目、党建热点资讯、党政教育学习五项内容,将这些收费数据进行不同规模划分,构建五个测试样本集,分别包括400、800、1 200、1 600、2 000 条数据记录。
为突出文中开发平台的优势与不足,采用基于MapReduce 频繁项挖掘的党政收费管理平台、基于Apriori 算法的党政收费管理平台进行同条件对比测试。
2.1 收费管理功能响应分析
响应时长是评估党政收费管理云平台实际性能的重要指标之一,在云环境条件下进行50 次平台响应测试,将有效响应时长设置为2 s,即响应时长低于2 s 时视为通过测试。分别测试使用平台后云缴费、党建教育学习、党建宣传等的平均响应时长,如表1 所示。
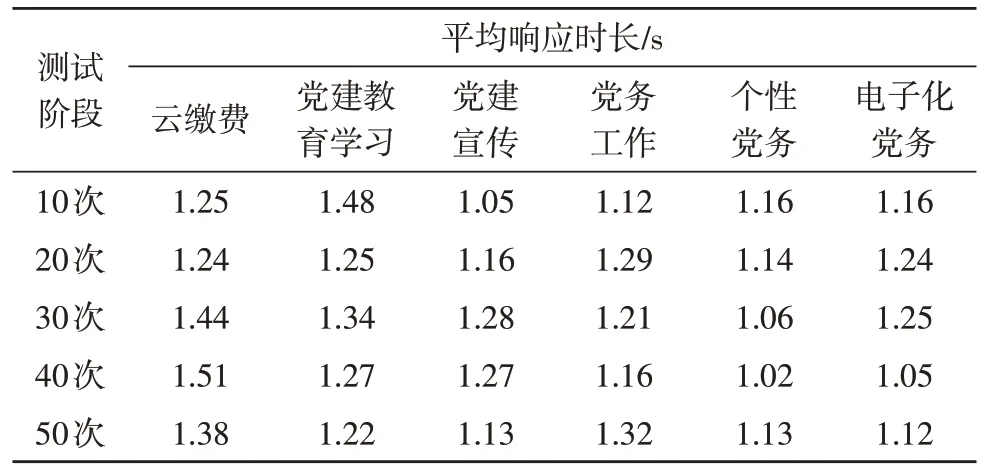
表1 平台功能平均响应时长
由表1 数据可知,50 次测试中云平台各功能的响应时长均低于2 s,符合使用标准。云缴费功能、党建教育学习功能的响应时长相对较大,云缴费平均响应时长区间为[1.25 s,1.51 s],党建教育学习平均响应时长区间为[1.22 s,1.48 s],相比之下,其他几项功能的响应时长较小,这是因为前两个模块的资源内容较大,尤其是云缴费模块是党政收费云平台的核心模块,容纳的数据量较为庞大,导致响应延迟较大。
2.2 党政收费信息挖掘效率分析
2.2.1 事务数量对效率的影响
测试中设定文中平台频繁项集挖掘算法的最小支持度值为3,记录了不同数据事务集状态下各平台挖掘党政收费信息频繁项集效率,如图3 所示。
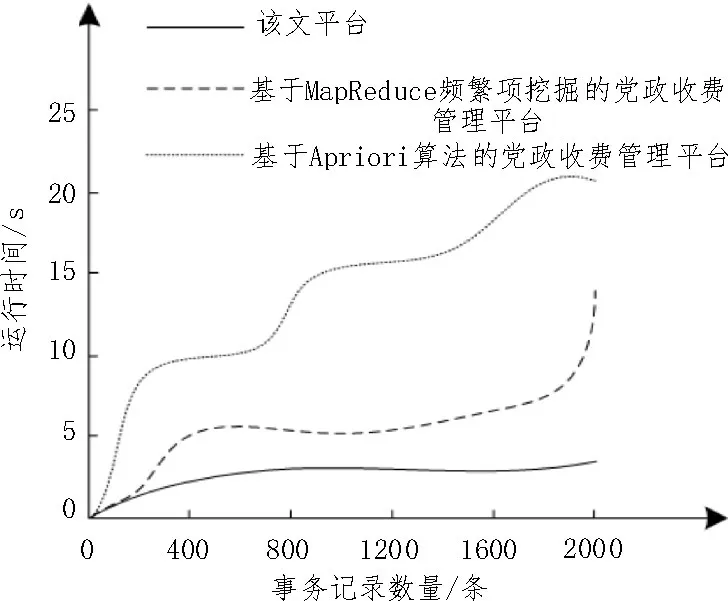
图3 不同事务数量下数据挖掘的运行时间对比
分析图3 可知,三种平台的运行时间走势差异较大,文中平台运行时间曲线发展较为平稳,没有显著的上升与下降趋势,随着事务数量的增加,挖掘党政收费信息频繁项集的时间有所增长,涨幅不大;事务数量达到最大值2 000 条时,运行时间最长仅约为4.1 s,是三种平台中时间开销最低的,证明文中平台挖掘党政收费信息频繁项集的时间复杂度最低。原因主要有两点:1)文中使用矩阵频繁项集挖掘收费对大规模数据库的频繁项集挖掘,有效减少扫描数据库的次数。扫描一次矩阵即可,使用矩阵来存储数据,基于矩阵行列间计算频繁k项集的支持度,降低了频繁项集大小、缩减频繁项集的通信频次与同步次数,频繁项集生成效率得到良好优化。2)在Spark 分布式计算框架下进行计算节点布局,多节点协作、并行化运算,有效减少频繁项集挖掘的时间消耗。
基于Apriori 算法的党政收费管理平台挖掘党政收费信息频繁项集用时增长较快,实验初期事务数量为400 条时,其运行时间达到10 s,事务数达到900 条时出现了第二个时间峰值,当事务数量为2 000 条时运行时间达到了20.8 s。
同样的,基于MapReduce 频繁项挖掘的党政收费管理平台前期测试用时较少,当达到测试后期时,时间开销攀升至14.1 s。这是因为该平台采用了MapReduce 模型进行并行式频繁项集挖掘布局,前期能够较好地应对大量事务数据的扫描处理工作,但是事务数量增加到一定数量时,其节点运算性能下降,难以应对海量事务数据的挖掘问题,导致频繁项集挖掘的时间开销攀升。
2.2.2 节点数量对效率的影响
设定文中平台频繁项集挖掘算法的最小支持度值为3,选用党政教育学习集和缴费项目集作为测试数据,其事务数量为3 200 条,在此条件下展开党政收费信息频繁项集挖掘测试,逐渐增加运算节点的数量。记录了不同节点数量下数据挖掘的运行时间对比情况如图4 所示。

图4 不同节点数量下数据挖掘的运行时间对比
分析图4 可知,基于MapReduce 频繁项挖掘的党政收费管理平台、文中平台均采用了并行式频繁项集挖掘策略,所以节点数量增加的情况下,党政教育学习频繁项集挖掘的时间均为递减趋势,文中并行式频繁项集挖掘算法的效率具有显著优势,初始运行时间为28.2 s,终止运行时间为6.3 s;基于MapReduce 频繁项挖掘的党政收费管理平台运行时间在文中平台之上,这是因为文中不仅使用Spark 分布式计算框架布局计算节点,并且通过构造“矩阵”实现频繁项集挖掘,具体基于“主-从”节点模式实施数据扫描与频繁项集支持度计算,将矩阵划分为若干个子矩阵,在从节点上展开子矩阵的并行式计算,计算完毕由主节点回收运算结果。这种布局方法一定程度上实现了分布式运算,因此降低了党政教育学习频繁项集挖掘的时间开销。
相对而言,基于Apriori 算法的党政收费管理平台采用传统的串行运算方式,节点数量增加其运算效率没有得到提升,反而出现增加趋势。
2.3 党政收费信息挖掘的推荐非空率分析
用户访问的全部项集内,被推荐项集占全部访问项集合项的比重称为推荐非空率,能够评价频繁项集挖掘算法的质量,推荐非空率与频繁项集挖掘质量成正比。选用党建热点资讯集和党费缴纳金额集作为测试数据,事务数量为2 000 条,测试中为频繁项集挖掘方法赋予不同的最小支持度,统计推荐非空率如表2 所示。
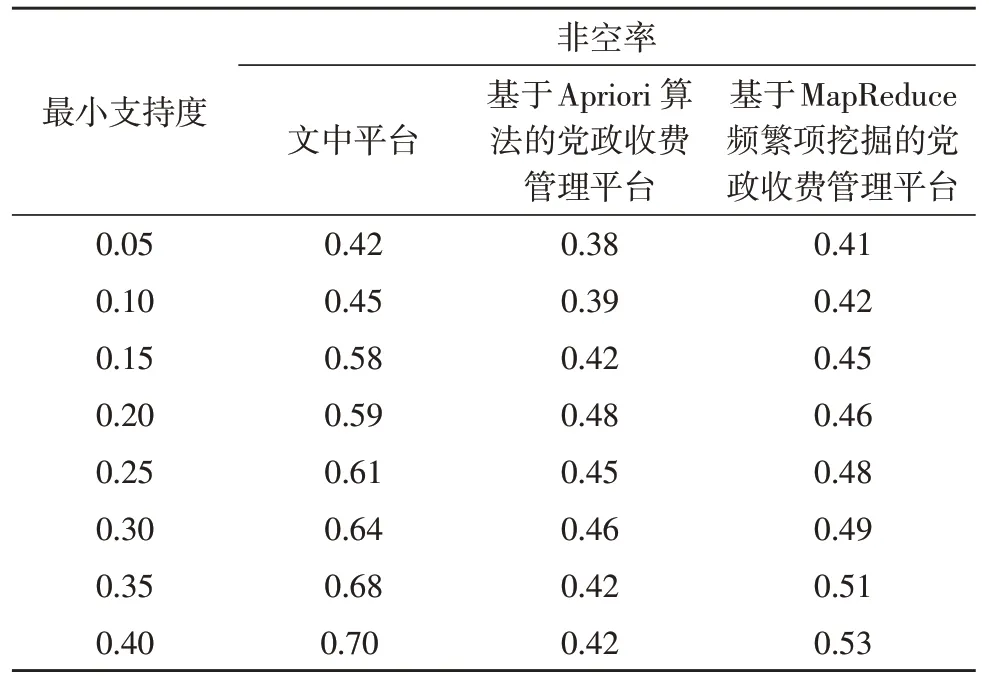
表2 推荐非空率统计
分析表2 数据可知,文中平台使用的并行式频繁项集挖掘算法的推荐非空率直线升高,随着最小支持度的增加该算法展现了良好的党建热点资讯和党费缴纳金额频繁项集挖掘效果,最高推荐非空率可达0.70。相对而言,基于Apriori 算法的党政收费管理平台的推荐非空率呈先增加再降低的趋势,当最小支持度值为0.25 时,频繁项集挖掘质量回落,其推荐非空率由0.48 跌落为0.45,测试后期,推荐非空率降低为0.42。基于MapReduce 频繁项挖掘的党政收费管理平台的推荐非空率虽然呈现上升趋势,但是其数值低于文中平台使用的算法,最高推荐非空率可达0.53,挖掘党建热点资讯和党费缴纳金额频繁项集的效果不够理想。
3 结论
为解决海量党政收费管理信息中传统频繁项集挖掘算法的缺陷,文中基于并行式频繁项集挖掘算法构建党政收费管理平台,提高平台党政信息挖掘的效率、提高频繁项集挖掘的质量,以满足党员与基层党组织对党建热点信息、党建教育学习、党组织管理的需求。文中实现了“并行式”党政收费管理信息的挖掘,在Spark 分布式计算框架下进行集群布局,应用矩阵频繁项集挖掘策略设计“主-从”节点计算模式,分布式实现频繁k项集支持度运算,且扫描一次矩阵数据即可,减少了党政收费信息挖掘的冗余工作量,因此获得了理想的信息挖掘分类效率。
但是,该平台仍有许多不足之处进行优化,例如,小规模数据集频繁项集挖掘的效率优势不够明显,可从降低内存需求量角度入手,增强小规模数据集处理的性能;最小支持度获取方式应逐步改进,以快速获得最优的最小支持度值,进一步减少党政收费频繁项集挖掘的时间开销。
