基于DBN 模型的互联网敏感信息泄露检测研究
2024-03-11艾雪瑞
邓 伟,许 放,张 涛,艾雪瑞,甄 珍
(北京中电飞华通信有限公司,北京 100000)
随着互联网的发展以及社会信息化水平的不断提升,互联网和人们的生活、工作变得密不可分。现阶段,互联网敏感信息主要是指危害社会公共安全的相关信息,主要涉及思想政治、经济、社会、文化等多个领域。而相关的恐怖组织利用互联网展开相关攻击后,一旦互联网敏感信息因攻击而泄露,会严重扰乱社会秩序,对于经济社会的安全稳定发展造成不利影响,进行互联网敏感信息泄露检测,并有针对性地设计相关的舆情方案具有重要意义。
针对互联网敏感信息泄露检测这一重要研究课题,文献[1]设计了一种基于扩展权限组合的信息泄露检测方法。该方法通过获取互联网敏感信息安全规则集,从多个特征出发获取危险权限组合,结合危险权限组合对于信息泄露情况进行判断,输出信息泄露检测结果。但是将该方法应用至实际中发现,这种方法存在泄露检出率较低的问题。文献[2]设计了一种基于局部差分隐私的物联网敏感数据泄露检测与控制方法。该方法通过获取物联网敏感数据链,结合数据链距离估计结果与检索条件获取敏感数据集,根据泄露检测阈值判断数据是否处于泄露状态,利用局部差分隐私设计数据加密方法,实现数据泄露控制。但是这一方法存在检测任务完成时间较长的问题,整体质量较差。
为了弥补传统方法存在的不足,设计基于DBN模型的互联网敏感信息泄露检测方法。
1 互联网敏感信息捕捉与去噪处理
1.1 互联网敏感信息捕捉
利用分布式网络爬虫技术爬取互联网网页敏感信息,并结合近邻策略对这些信息进行分组处理,保证每个组中所包含的敏感信息数量至少为k。假设第G组所包含的敏感信息用{X1,X2,…,Xk} 表示[3-5],互联网网页Xk中所包含的d维数据用表示,则第G组不同类的网页敏感信息统计结果[6-7]分别用下述公式表示:
该组中敏感信息属性之间的协方差通过下述公式计算得出:
式中,n(G)表示第G组不同类的网页记录统计记录个数,Scij(G)表示第G组所有的敏感信息参量。
根据敏感信息以及信息属性之间的协方差重新构造一个新的信息集合A,以此实现互联网敏感信息捕捉[8-9]。
1.2 互联网敏感信息去噪处理
以互联网敏感信息捕捉结果为基础,对互联网敏感信息集合中的数据进行去噪处理,以此保证后续互联网敏感信息泄露的检测效率与质量。
从互联网敏感信息集合中随机选取出m个样本数据,用S={S1,S2,…,Sm}表示,每选择出一个近邻Si,就按照下述公式构造出一个新的样本:
式中,rand 表示(0,1)区间内的一个随机常数。
S和Si之间的欧氏距离通过下述公式计算得出[10-11]:
式中,xi与yi分别表示S和Si中的一个n维样本。
结合式(5)的计算结果,从A中取出距离最近的k个样本,从而得到一个新的互联网敏感信息集合A(S),并从A中取出少数类信息样本,构造另一个互联网敏感信息集合B(S)。B(S)在A(S)中的所占比例通过下述公式计算得出:
假设存在一个互联网敏感信息样本N∈A(S),从这个数据集中随机选择出一个样本U∈(B(S)-A(S)∩B(S)),计算这两个数据之间的距离。如果Z×DN<DU,则需要将N加入到噪声数据集中,若是该噪声数据集不为空,需要从A中将该数据集中去除,完成互联网敏感信息去噪处理。
2 基于DBN模型的敏感信息泄露检测
文中以DBN 模型为基础,研究了一种敏感信息泄露检测方法,该方法的实现流程如下:
步骤一:信息编码和序列化处理
对于去噪后的互联网敏感信息进行编码处理[12-13],具体的公式如下:
式中,s表示操作类型;t表示数据记录量。
将互联网敏感信息编码结果进行序列化处理[14-15],将其转换为一个数组作为DBN 模型的训练数据。序列化处理过程如下:
式中,x对象数量;F表示储存量。
步骤二:DBN 模型构建
深度信念网络(DBN)[16]是深度学习方法的一种,DBN 由多个受限玻尔兹曼机(RBM)堆叠而成,建立的DBN 模型如图1 所示。
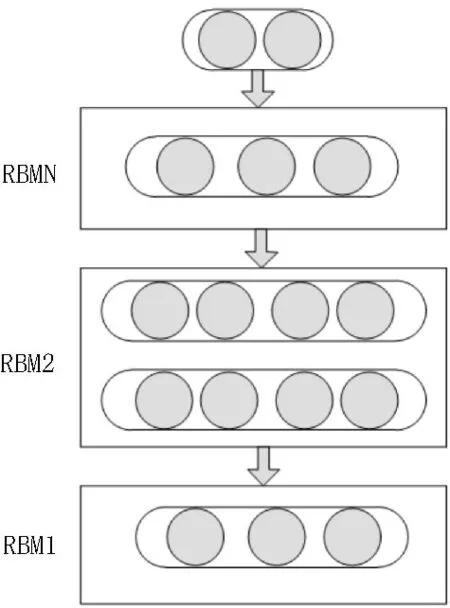
图1 DBN模型
RBM 由观察层和潜层组成,这两层之间的任何单元之间均不存在连接关系,RBM 组成如图2 所示。
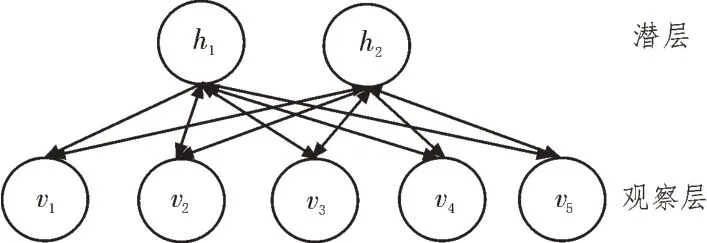
图2 RBM组成
观察层变量v由一组nv个二值随机变量组成,潜层变量h由nh个二值随机变量组成。
步骤三:DBN 模型训练
对DBN 模型进行训练,采用sigmod 函数计算出潜层的激励值,计算结果如下:
将每个隐元的激励值加上该层神经元的偏向,神经元只能处于开启状态与关闭状态,用下述方程组表示:
式中,δ(hj) 表示激励函数,e-x表示指数函数。通过更新权重实现DBN 模型训练,结果如下:
式中,v(0)、v(1)分别表示将互联网敏感信息训练数据赋值给观察层的不同结果,h(0)、h(1)分别表示将互联网敏感信息训练数据赋值给潜层的不同结果,λ表示重构次数。
步骤四:敏感信息泄露检测结果输出
将互联网敏感信息信息编码和序列化处理输入至训练好的DBN 模型中,该模型通过提取敏感信息泄露特征以及泄露判断阈值实现敏感信息泄露检测。
利用DBN 模型提取互联网敏感信息泄露特征,具体公式如下:
结合互联网敏感信息泄露特征提取结果设计泄露判断阈值,该阈值如下:
式中,e表示指数函数,d表示攻击者位置参量。
将互联网敏感信息训练数据输入至DBN 模型,经过DBN 模型迭代处理得出互联网敏感信息泄露检测结果,具体如下:
式中,Ti表示序列化数据向量,A(x)表示数据编码向量。
3 实验研究
为了验证提出的基于DBN 模型的互联网敏感信息泄露检测方法的有效性进行了实验测试。设定实验环境如图3 所示。

图3 实验环境
采用DBN 模型对互联网敏感信息进行分解,得到的分解序列如图4 所示。
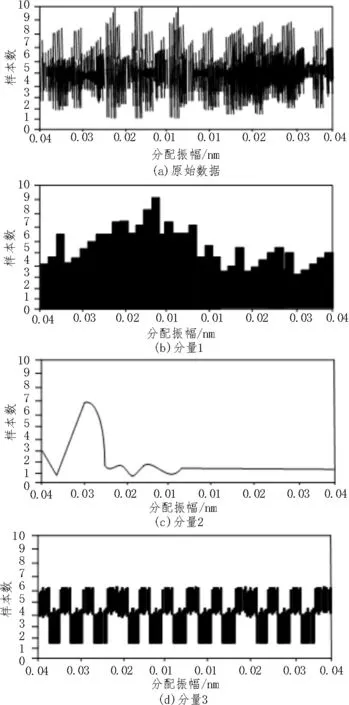
图4 分解序列实验结果
通过分解序列确定模态分量,以此实现互联网敏感信息泄露检测。
选用文献[1]提出的基于扩展权限组合的信息泄露检测方法以及文献[2]提出的基于局部差分隐私的物联网敏感数据泄露检测与控制方法作为实验对比方法。探究不同方法的互联网敏感信息泄露检出率,计算公式如下:
其中,m表示泄露的敏感信息;l表示正常传输的数据。
三种方法的互联网敏感信息泄露检出率比较结果如表1 所示。
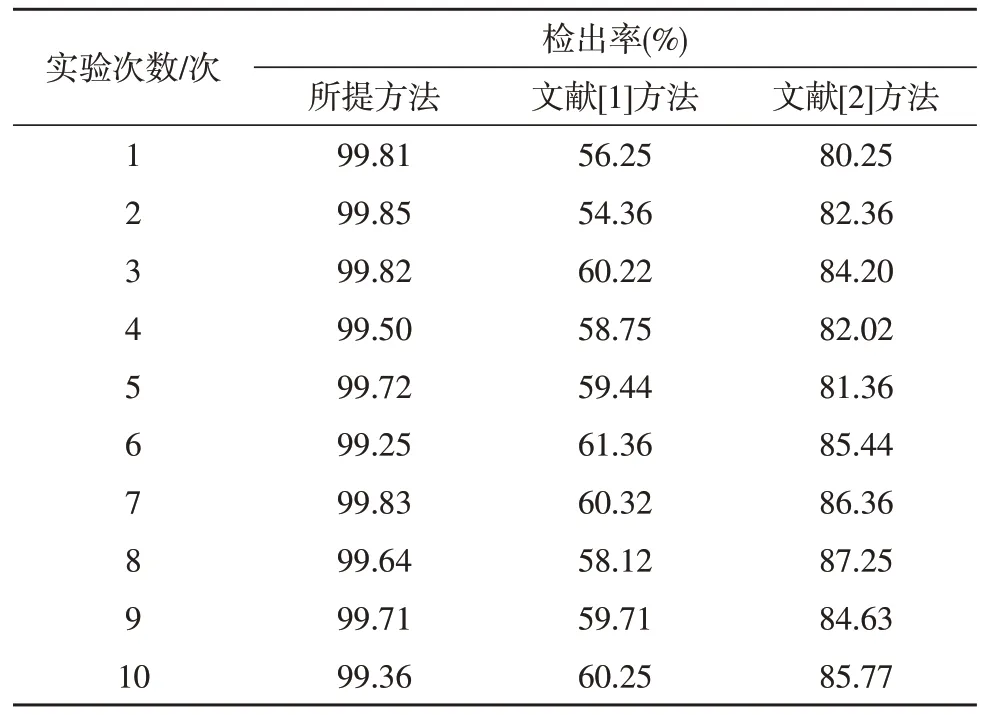
表1 检出率
根据表1 可知,所提方法的互联网敏感信息泄露检出率高达99.8%,能够很好地识别出互联网存在的泄露敏感信息,与实验对比方法相比,检测能力更佳,更适合应用在隐私保护领域。
三种方法的互联网敏感信息泄露检测任务完成时间比较结果如图5 所示。
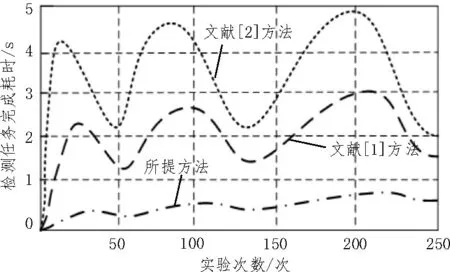
图5 检测任务完成时间
根据图5 可知,与实验对比方法相比,所提方法的检测任务完成时间更短,效率更高,可以快速得到互联网敏感信息泄露检测结果。
4 结束语
互联网敏感信息对于该领域来说至关重要,研究敏感信息泄露检测方法可以极大提升互联网的安全性。因此基于DBN 模型,研究了一种互联网敏感信息泄露检测方法。经实验表明,所提出的互联网敏感信息泄露检测方法在检出率和检测任务完成时间方面具有良好性能,但该方法在鲁棒性方面仍有不足之处,后续将围绕此方面进行研究。
