基于WPD-ARIMA-GARCH组合模型的酱卤肉制品安全风险区间预测
2024-03-10黄亚平郭鹏程
尹 佳,黄 茜,陈 翔,陈 晨,陈 锂,张 涛,徐 成,黄亚平,郭鹏程,文 红,*
(1.湖北省食品质量安全监督检验研究院,国家市场监管重点实验室(动物源性食品中重点化学危害物检测技术),湖北省食品质量安全检测工程技术研究中心,湖北 武汉 430075;2.武汉理工大学计算机与人工智能学院,湖北 武汉 430070;3.武汉理工大学理学院,湖北 武汉 430070)
近30多年来,中国已经成为世界上食物生产量和消费需求量增长最快的国家之一[1]。《中国食物与营养发展纲要(2014—2020)》[2]指出我国近年来在食物总量上已经实现了“食物供需基本平衡”,即已基本解决粮食数量安全问题。但目前在有效满足人们饮食需要的同时,部分企业还存在重产量而忽视质量的现象,暴露出一些食品安全问题。因此,如何在能够“保障食物有效供给”的前提下,保障食品安全和营养健康、控制有毒有害物质残留超标、快速对风险发出预警,便成为下一步急需解决的问题,同时,食品安全预测研究也具有重要的社会意义。
实践表明,通过对还未发生的潜在风险进行分析,提前判断,主动预防,被认为是保证食品安全的最有效方式[3]。目前,对于食品质量安全风险预警的研究,统计方法和机器学习预测相结合的方法已占主导地位[4],楼皓等[5]使用差分自回归移动平均(autoregressive integrated moving average,ARIMA)-支持向量机(support vector machine,SVM)组合模型对中国出口欧盟的食品风险进行预测,结果表明组合模型比单一模型具有更高的精度;Yan Shengyang等[6]提出了一种基于反向传播(back propagation,BP)神经网络和遗传算法的食品安全综合指数预测方法;白宝光等[7]构建了预警指标体系和BP神经网络预警模型,提高了乳制品风险预警的精准性;Yonar等[8]利用Holt线性趋势模型对多个国家的小麦产量进行了预测;Sivamani等[9]使用季节性ARIMA模型为畜禽类食品供应提供准确的预测。上述主流方法主要是点估计,而区间估计在食品安全风险预警领域应用较少,但在其他领域已有广泛的应用。赵会茹等[10]利用核密度估计(kernel density estimation,KDE)方法对长短期记忆神经网络预测模型预测结果进行区间估计,建立了未来短期电力负荷的区间预测方法;张明宇等[11]基于改进的小波神经网络,对上证指数开盘数据建立了一种新型股指区间预测模型;丁藤等[12]对风速建立ARIMA-广义自回归条件异方差(generalized autoregressive conditional heteroskedast,GARCH)模型,实现了通过少量历史数据对超短期内风速的区间预测;Guo Tianli等[13]建立了自激发门限自回归(self-exciting threshold autoregressive,SETAR)-GARCH混合模型,对非平稳非线性地下水深度进行了评价。以上关于食品安全预警方面的模型主要是点估计模型,此类模型虽然有一定的预测精度,但其通常只能适用于线性变化的趋势,且只能提供确定性的预测结果,而不能提供有关不确定性的信息[14]。而区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,不仅可以提供更多的信息,而且可以量化预测结果的不确定性[15-18],但其在食品安全预测方面应用鲜有报道。
因此,本实验提出了一种点估计和区间估计组合预测模型——小波包分解(wavelet packet decomposition,WPD)-ARIMA-GARCH模型,应用于酱卤肉制品安全风险预警的区间预测。在点估计部分提出了一种基于数据分解WPD[19]的ARIMA方法,对于缺失数据采用高斯过程回归(Gaussian process regression,GPR)进行插值,采用WPD进行分解,依据ARIMA模型自动定阶,对分解后的分量进行点估计预测,将各预测分量重构后输出点估计部分预测结果;在区间估计部分,选择GARCH模型[20]对点估计结果残差进行区间估计,提供每一个确定预测结果的上限和下限,以期通过建立的组合模型量化酱卤肉制品质量安全风险预测结果的不确定性,为其风险防控提供一定的参考。最后,将建立的最优模型与其他预测模型如支持向量回归(support vector regression,SVR)和KDE等进行了对比,验证所建立组合模型结果的有效性。
1 材料与方法
本实验选取2014—2019年来自国家市场监督管理总局公布的以及检测机构内部自行检测获得的部分酱卤肉制品数据作为数据源,其中,前5 年作为训练集,2019年数据作为测试集。为了更加全面了解酱卤肉制品中存在的风险,将所有检测项目均纳入分析。由于存在检验项目结果信息不完全、数据的结构不统一以及稠密性差异等问题[21-22],在建立模型之前,有必要对原始检测数据进行清洗、集成、变换等预处理。
1.1 数据预处理
将检测项目的检测值(微生物项目除外)结合国家标准(例如GB 2760—2014《食品安全国家标准 食品添加剂使用标准》等)采用公式(1)进行去量纲化处理。根据去量纲化的结果结合专家打分法将项目风险等级划分为5 级,1级为安全无风险,2级为轻微风险,3级为轻度风险,4级为中度风险,5级为重度风险(即不符合国家标准要求)。其中较低的检测值(1~2级)视为相对安全的情况,3级需要引起关注,而4~5级则需要进行早期预警,并采取相应的预防措施。具体划分标准见表1。
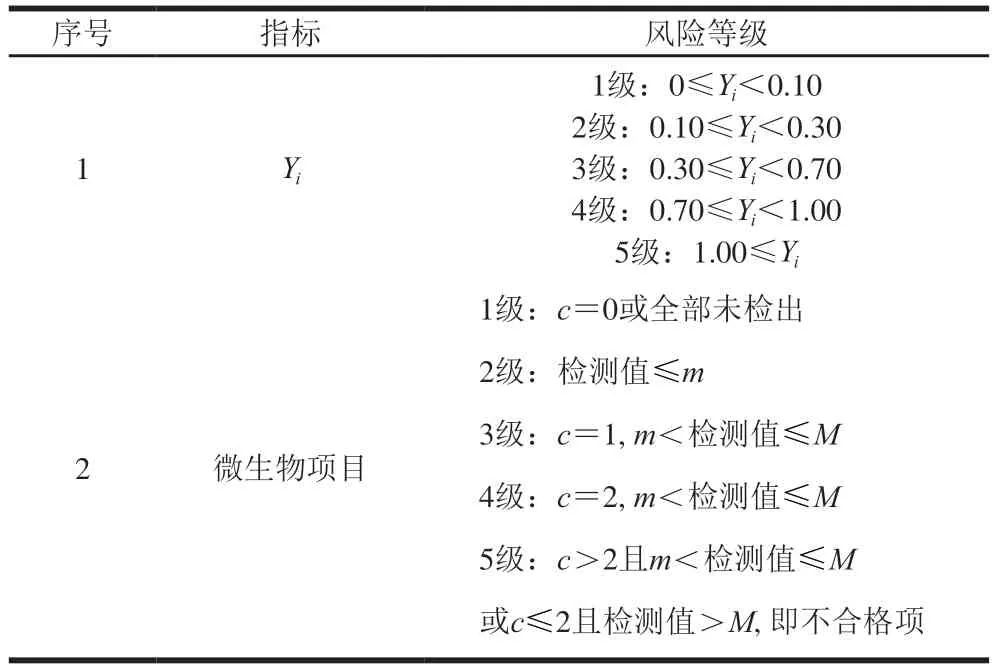
表1 检验项目的风险等级划分标准Table 1 Criteria for risk classification of inspection items
式中:Yi为预处理后的风险等级评价值;Xstandard为国家标准中规定的标准值;Xi为检验项目的检测值。
微生物项目参考表1按照检测值进行风险等级划分。
本实验采用改进的softmax函数计算单一产品的综合风险等级(公式(2)),通过函数中指数权重的变化来调节风险等级的权重[23],将自然周作为一个数据集,通过加权求和(公式(3))计算自然周的综合风险指数。
式中:level(A)为单一产品A的综合风险等级;i为食品A中检测项目的风险等级数值;ωi为风险等级i在食品A中的占比。
式中:weekrisk为自然周的综合风险指数;i为该时间段的风险等级数值;ωi为该时间段风险等级i的占比。
通过对原始周综合风险时间序列的数据特征进行分析,结合专家打分法,将自然周综合风险指数weekrisk≤8划分为低风险,8~21划分为中风险,>21划分为高风险。其中中风险需要给予一定关注,高风险需要引起重视,并采取早期预警和预防措施。
1.2 缺失数据插值
由于基于时间序列的预测模型需要以数据的连续性和相对完整性为基础,而本实验通过自然周分箱后的检测数据存在部分缺失情况,故带入模型训练前需要进行插值。
1.2.1 数据缺失情况分析
以某地区的数据作为插值实验的数据集,该地区周综合风险的数据情况如图1所示。
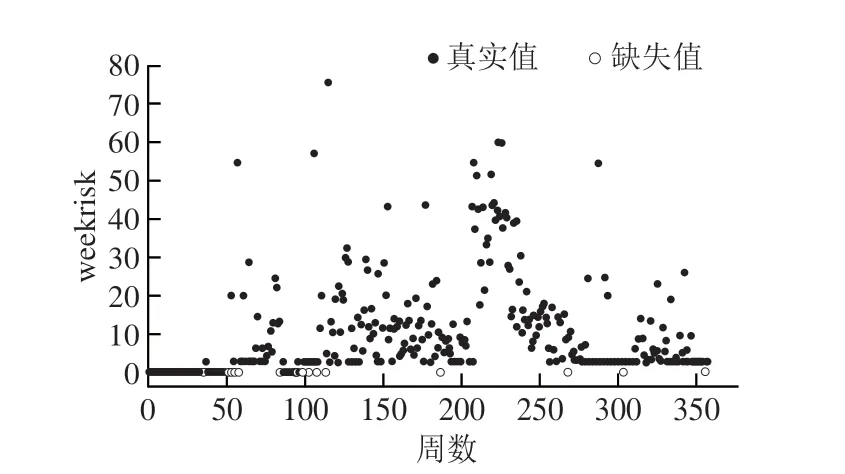
图1 某地区酱卤肉的周综合风险Fig.1 Weekly risk of soy sauce and pot-roast meat products from a certain region
分析该地区整体数据分布情况,数据点分为两种类型:①平稳较多,偶尔波动;②波动较多,平稳较少。本实验选择该地区270~300 周的数据集A和310~350 周的数据集B作为这两类情况的代表数据集。同时,分析缺失点数据,存在两种情况:①连续型缺失,即中间连续一段时间都没有数据;②间断型缺失,即中间偶尔会出现缺失点。故该地区的缺失数据有以下4 种情况:
·D1:A集上的连续缺失;
·D2:A集上的间隔缺失;
·D3:B集上的连续缺失;
·D4:B集上的间隔缺失。
1.2.2 插值方法
针对数据缺失问题,本实验采用GPR进行插值。
GPR使用多维高斯过程条件分布的性质来进行回归预测,其具体的表达如式(4)所示:
式中:Xi为特征向量;yi为对应的值。
对于一个新的观测值X*,GPR给出的预测值y*如式(5)所示:
式中:K为协方差核矩阵,例如径向基核函数、线性核函数等。根据高斯函数的性质,当y*=k(X*,X)K(X,X)-1y,即预测值的平均值时,P(y*|y)达到峰值。
1.2.3 插值方法对比
线性插值、二次样条插值是常用的插值方法,在本实验中用作插值对比方法。为了合理地评价各个插值方法的插值效果,假设原始序列中某些数据是缺失,通过计算各插值方法给出的预测值和真实值之间的误差来评价插值方法的优劣。在选择数据样本时,制定了以下几条准则:
a)数据必须是完整无缺失的;
b)数据量必须保证T≥L;其中,T表示样本数据段的数据量,L表示该样本假设缺失数据的数据量;
c)数据样本应当具有代表性。
本实验将缺失个数L设置为10,随机设置缺失值,在每个数据集Di上重复5 次实验,根据式(6)计算各个插值方法的均方误差(mean-square error,MSE)和加权平均误差mseweight。
式中:ωi为Di的权重。考虑到D3的情况较少,故将其权重设为0.1,其他3 种权重均设为0.3。
1.3 WPD-ARIMA-GARCH组合模型的建立
1.3.1 WPD
小波分解是一种信号时频分析方法,在小波分析理论[24]的基础之上,WPD引入了最优基选择的概念,将频带经过多层次的划分之后,根据被分析信号的特征,自适应地选取最优基函数,使之与信号相匹配,以提高信号的分析能力[25-26]。WPD既对低频部分进行分解,也对高频部分进行分解,可以对原始信号进行更加细致的划分,分解示意图如图2所示。

图2 三级WPD示意图Fig.2 Schematic diagram of three-scale WPD
1.3.2 ARIMA模型
ARIMA模型是Box和Jenkins在20世纪70年代初提出的一种著名的时间序列预测方法,并改进衍生出诸多精度优良的模型[27]。在ARIMA模型中,最常用的是求和自回归移动平均模型ARIMA(p,d,q)[28],其中,p为自回归阶数,d为成为平稳时间序列时所做的差分次数,q为移动平均阶数。其基本原理是将非平稳时间序列经过差分运算转化为平稳时间序列,再将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型[29]。
1.3.3 GARCH模型
GARCH模型由Bollerslev在1986年提出[30],相较于自回归条件异方差(autoregressive conditional heteroskedasticity,ARCH)[31],其允许自决定条件方差,可以避免必要的高滞后顺序的困境,在波动性分析和预测方面应用广泛[32-34]。同时,GARCH模型也是一种概率模型,本实验将其用于置信区间的区间估计,预测区间表示为式(7):
式中:μt为时间t的预测平均值;Z为Z分数;α为置信水平;σt为时间t的标准偏差;n为样本量。
1.3.4 WPD-ARIMA-GARCH组合模型
本实验提出了一种WPD-ARIMA-GARCH组合模型,采用点估计和区间估计结合的方式对酱卤肉制品的质量安全风险进行预测,具体流程如图3所示。在点估计阶段,采用WPD-ARIMA模型,对于缺失数据采用GPR进行插值,采用WPD进行分解,依据ARIMA模型自动定阶,对分解后的分量进行点估计预测,将各预测分量重构后输出点估计部分预测结果;在区间估计阶段,采用GARCH模型对点估计结果残差进行区间估计。

图3 WPD-ARIMA-GARCH组合模型流程图Fig.3 Flow chart of WPD-ARIMA-GARCH model
ARIMA-GARCH模型的运行过程如表2所示。

表2 ARIMA-GARCH模型的运行过程Table 2 Operation process of ARIMA-GARCH model
1.4 预测模型的评价指标
1.4.1 点估计模型评价指标
本实验选用以下3 个指标——MSE、平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)作为点估计模型的评价指标,具体计算如式(8)~(10)所示。
式中:n为样本数量;yi和分别为第i个实际检测值和预测值。
1.4.2 区间估计模型评价指标
本实验选用以下3 个指标——预测区间覆盖率(prediction interval coverage probability,PICP)、预测区间平均宽度(prediction interval normalized average width,PINAW)、覆盖宽度标准(coverage width-based criterion,CWC)作为区间估计模型的评价指标。具体计算如式(11)~(14)所示[35]。
式中:n为样本数量;当第i个真实值落在[Li,Ui]中时ci=1,否则ci=0([Li,Ui]表示第i个预测区间,Li和Ui分别是该区间的下界和上界)。
蚤状幼体Ⅰ期已有口器,开始摄食,主要投喂蛋黄、酵母。每隔3小时投喂一次,蚤状幼体后期可投喂轮虫及少量的卤虫幼体。水温控制在22~24℃,充气量微充气略显沸腾状。每天换水30~40cm,换水网箱网目为80目。
式中:R为目标值的取值范围。
式中:η和μ为惩罚系数,本实验中η的取值为0.7。
1.5 对比模型
1.5.1 点估计对比模型
本实验构建了SVR、WPD-SVR、ARIMA模型作为点估计预测阶段对比模型。SVR是一种常用的点估计模型,其核心是误差函数和核函数,通过最大化间隔带的宽度与最小化总损失优化模型[36]。在点估计模型中,设置lookback=6,即使用6 个连续的数据预测第7个数据。
1.5.2 区间估计对比模型
本实验分别采用KDE和GPR模型作为区间估计对比模型。KDE属于非参数检验方法之一,是在单变量KDE的基础上,通过对KDE变异系数的加权处理,可以建立不同风险值的预测模型[37]。KDE不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法。GPR是一个贝叶斯方法的概率模型,不仅可以作为缺失数据插值方法之一,还可以获得整个回归函数的分布,计算出其预测区间。
2 结果与分析
2.1 插值方法结果比较
在缺失数据插值部分,对于每个数据集Di,GPR、线性插值和二次样条插值的均方误差MSE(Di)和加权平均误差mseweight结果见表3。

表3 不同的插值方法结果比较Table 3 Comparison of interpolation results using different methods
插值后该地区的周风险时间序列见图4,其中2014—2018年的检测数据作为训练集,2019年检测数据作为测试集。
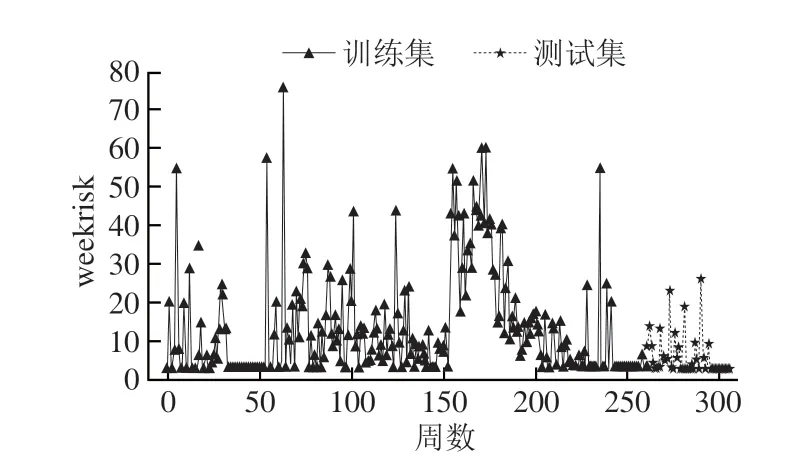
图4 某地区酱卤肉的周综合风险时间序列Fig.4 Weekly risk time series of soy sauce and pot-roast meat products from a certain region
2.2 点估计
2.2.1 WPD-ARIMA模型
将采用GPR插值后的周风险数据作为原始序列,输入建立的WPD-ARIMA模型,对其进行WPD。
WPD用光滑性较好的8 阶Daubechies小波基,对原始序列进行3 层分解,将原始信号分解为[‘AAA’‘AAD’‘ADD’‘ADA’‘DDA’‘DDD’‘DAD’‘DAA’]8 个子序列S1~S8。图5为某地区分解后各级分量示意图。

图5 某地区的WPD示意图Fig.5 WPD results of soy sauce and pot-roast meat products from a certain region
由于S1序列数据的波动范围较大,通过增强迪基-福勒(Augmented Dickey-Fuller,ADF)检验,该序列为非平稳序列,通过差分处理后进行建模。其余子序列P值均小于检验水平的临界值(α=0.05),满足平稳性要求,可以直接进行建模。
对差分处理后的子序列,根据赤池信息准则(Akaike information criterion,AIC)和贝叶斯信息准则(Bayesian information criterion,BIC)值越低越好的原则,依据ARIMA模型的自动定阶确定最优参数后(表4),对WPD得到的各个分量进行预测,将各预测分量重构后输出最终的预测结果,并使用测试集用来验证该模型的精确度。

表4 某地区酱卤肉WPD各分量的ARIMA模型最优参数Table 4 Optimal parameters for the ARIMA model of WPD components for soy sauce and pot-roast meat products from a certain region
2.2.2 点估计模型比较
为评价所构建的WPD-ARIMA模型在酱卤肉制品预测中的效果,本研究分别采用SVR、ARIMA、WPDSVR模型进行对比分析。图6和表5为某地区4 种点估计方法的预测结果。

图6 某地区酱卤肉的点估计结果Fig.6 Point estimation results of soy sauce and pot-roast meat products from a certain region

表5 基于各种点估计方法的结果比较Table 5 Comparison of results based on various point estimation methods
通过上述结果分析发现,未经WPD分解的ARIMA模型和SVR模型拟合度明显较差,误差也明显增大,原因可能是WPD能够自适应地选择基函数,对原始数据进行更细致地划分,使分解后的各个分量有更好的光滑性,从而使得组合模型的误差更小,拟合度更高;WPD-SVR模型的误差略高于WPD-ARIMA模型,可能是因为SVR对参数和核函数选择敏感,性能的优劣主要取决于核函数的选取。因此,本研究选择WPD-ARIMA模型作为点估计模型,其不仅有最好的拟合度,而且MSE、MAE和MAPE均明显小于其他3 种模型。
2.3 区间估计
2.3.1 区间估计WPD-ARIMA-GARCH预测结果
在经过WPD-ARIMA点估计模型预测后,本研究采用GARCH模型对其残差进行区间估计,WPD-ARIMAGARCH预测结果如图7所示。

图7 某地区测试集WPD-ARIMA-GARCH的预测结果Fig.7 Prediction results of WPD-ARIMA-GARCH for test set
2.3.2 区间估计模型比较
为评价GARCH模型区间估计的效果,本研究分别采用KDE和GPR模型作为区间估计对比模型进行比较。WPD-ARIMA-KDE和WPD-ARIMA-GPR的预测结果如图8、9所示。各种区间预测组合模型的预测结果如表6所示。

图8 某地区测试集WPD-ARIMA-KDE的预测结果Fig.8 Prediction results of WPD-ARIMA-KDE for test set from a certain region

图9 某地区测试集WPD-ARIMA-GPR的预测结果Fig.9 Prediction results of WPD-ARIMA-GPR for test set from a certain region

表6 基于不同区间预测方法的结果比较Table 6 Comparison of results based on different interval prediction methods
预测结果中的PINAW和CWC值越小,置信区间越窄;PICP值越大,置信区间涵盖的目标值越多,模型的预测效果越好。实验结果表明,GARCH模型区间估计预测效果明显优于KDE模型区间估计,同时,GARCH模型的90%和95%置信区间均可以覆盖所有真实值,且90%置信区间的PINAW和CWC更小。虽然GPR的PINAW和CWC较低,但其PICP仅为0.58左右,这意味着其置信区间仅涵盖近58%的真实值。综合考虑准确性和置信区间,GARCH模型90%的置信区间效果最佳。
采用建立的WPD-ARIMA-GARCH模型,对测试集进行预测,结果如表7所示。结果表明,预测值均与实际真实值相近,且90%置信区间可以涵盖所有真实值和预测值的结果。根据测试集的预测结果,结合公式(3)的计算结果以及专家打分法对风险的划分,测试集中序号7和24的预测结果为高风险项,考虑本实验中设置的lookback=6,即需要对2019年第13周和第31周重点关注,也就是对2019年的3月底和7月底进行提前预警并采取预防措施;同时,2019年第8、16、18、21、27、34周的预测值在8和21之间,也应当给予适当的关注。该结果与实际食品抽样检测中风险一致,说明该预测结果准确且有效。
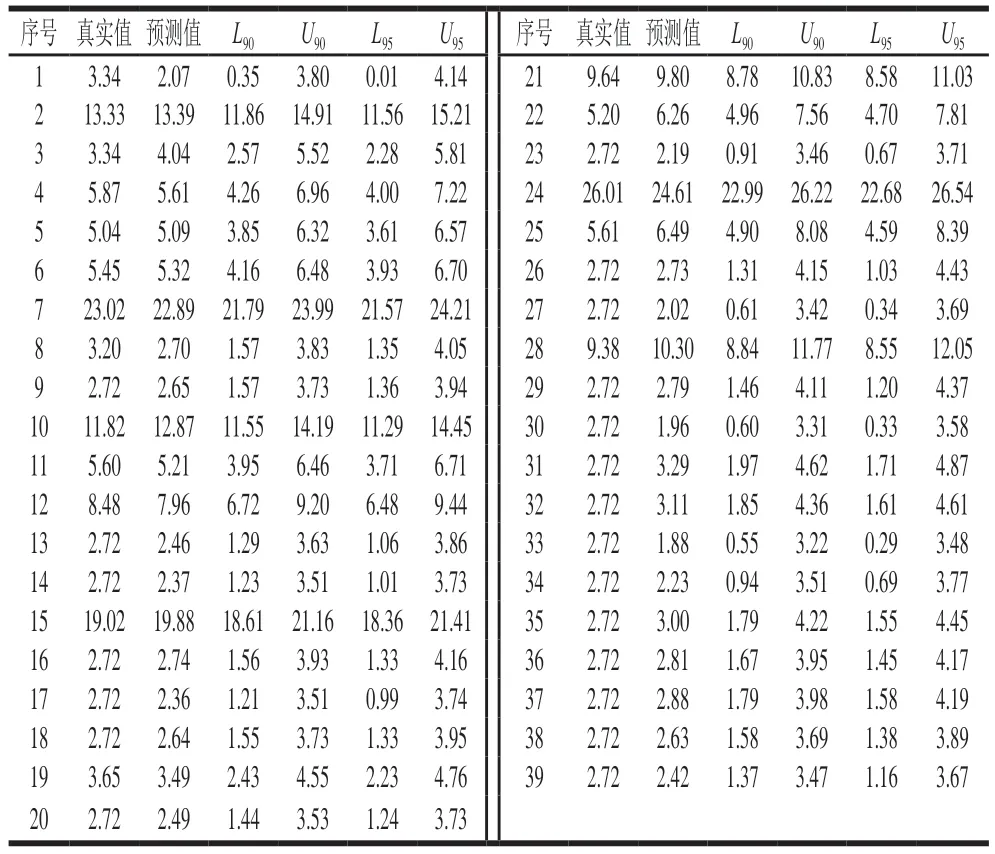
表7 WPD-ARIMA-GARCH的测试集预测结果Table 7 Prediction results of WPD-ARIMA-GARCH for test set
为了测试WPD-ARIMA-GARCH模型的通用性,本实验采用所建立的模型,对其他10 个不同地区的酱卤肉制品质量安全风险进行预测,预测结果的评价指标如表8所示。

表8 其他10 个地区酱卤肉制品的预测结果Table 8 Prediction results of soy sauce and pot-roast meat products from 10 other different regions
结果表明,10 个地区的点估计平均误差MSE、MAE和MAPE分别为1.626、0.806和20.824,90%置信区间下,区间估计预测PICP、PINAW和CWC分别为0.992、0.024和0.024,表明本研究构建的WPD-ARIMA-GARCH模型对酱卤肉制品风险有较好的预测效果,该模型通过WPD和ARIMA的耦合,使其对高频数据处理更加容易,提高预测精度,减小误差,准确地模拟时间序列变量的波动性变化,不仅考虑了待分析数据在时间序列上的依存性,而且考虑了随机波动的干扰,GARCH模型对残差进行区间估计,进一步验证结果的可靠程度,且提供每个确定预测结果的上限和下限,可以量化预测结果的不确定性。
3 结论
通过对原始数据分析和划分,将点估计和区间估计结合起来,构建了WPD-ARIMA-GARCH组合模型,并创新性地应用于酱卤肉制品的质量安全风险预测。在点估计方面,WPD-ARIMA模型与对照模型(WPDSVR、ARIMA、SVR)相比,不仅拟合度最好,而且MSE、MAE、MAPE均最小。在区间估计方面,与其他区间估计模型(如KDE、GPR)相比,基于GARCH模型的区间估计可以产生更窄的PINAW,同时可以保证更高的PICP,效果最佳。根据实验建立的WPD-ARIMAGARCH组合模型,对某地区酱卤肉制品进行风险预测,预测结果表明,2019年的3月底和7月底酱卤肉制品安全风险较高,需要进行提前预警并采取必要的预防措施,同时,也应当给予2019年第8、16、18、21、27、34周适当的关注,该结果与实际抽样检测结果一致,因此,本实验建立的模型准确且有效。同时该模型在10 个不同地区的平均MSE、MAE和MAPE分别为1.626、0.806和20.824,其90%置信区间的PINAW和CWC值均为0.024,该置信区间可以覆盖所有真实值,具有高预测精度和较低的误差,可以对酱卤肉制品质量安全中潜在的风险起到防控和监督的作用,并能够在日常检测的过程中提供相应的技术支持。
