高效通道注意力结合卷积神经网络的近红外光谱分析模型研究
2024-03-08王妞宦克为傅钲淇刘赋伟王迪
王妞,宦克为,傅钲淇,刘赋伟,王迪
(1.长春理工大学 物理学院,长春 130022;2.中移建设有限公司吉林分公司,长春 130112)
近红外光谱(Near Infrared Spectroscopy,NIRS)技术是一种高效、可靠、无损的分析方法,被广泛应用在药物[1-2]、食品[3]、烟草[4]和其他化学物质成分定性和定量分析中。然而,近红外光谱数据量的激增给常用模型的泛化能力和预测精度带来了重大挑战,传统的建模方法都出现其不足之处,如偏最小二乘(Partial Least Squares,PLS)[5]无法有效对非线性关系进行拟合、支持向量回归(Support Vector Regression,SVR)[6]在数据较多时预测精度差、BP 神网络(Back Propagation,BP)[7]无法有效避免过拟合现象出现并且运算速度慢等。随着机器学习的不断发展,基于卷积神经网络的近红外光谱分析技术可以实现比传统方法更有效地对不同的物质进行定性定量分析,并得到了广泛应用。Feng 等人[8]通过卷积神经网络结合不同光谱预处理方法对芒果中干物质进行了定量分析;Bian 等人[9]基于极限学习机对柴油组分进行了预测,获得了较好的预测结果;Mishra 等人[10]利用最小二乘支持向量机和近红外光谱分析了柴油的沸点、十六烷值、密度、冷冻温度、总芳烃和粘度;魏锦山等人[11]基于深度学习和近红外光谱实现砂土、壤土、黏壤土和黏土的快速区分;谈爱玲等人[12]基于近红外光谱与深度学习融合对玉米成分进行定量检测。为了提升预测精度和泛化能力,本研究以啤酒、牛奶、柴油、谷物公共数据集为研究对象,采用高效通道注意力(Efficient Channel Attention,ECA)结合卷积神经网络(Convolutional Neural Network,CNN)建立了不同物质成分预测的近红外光谱分析模型。该模型与PLS、SVR、BP 神经网络相比,在啤酒、牛奶、柴油和谷物公共数据集上有更好的预测精度和鲁棒性。
1 材料来源
1.1 啤酒数据集
啤酒样本共60 个,其数据来源于参考文献[13]。啤酒样本校正集与预测集的酵母含量分布如表1 所示,本研究采用K-S 方法将其中42 个样本光谱和化学值选作校正集[14],其余18 个样本光谱和化学值作为预测集。啤酒样本的近红外光谱数据如图1(a)所示,每个啤酒样本的酵母含量用化学方法测量得到,近红外光谱波长间隔为2 nm,波长范围为1 100~2 250 nm。
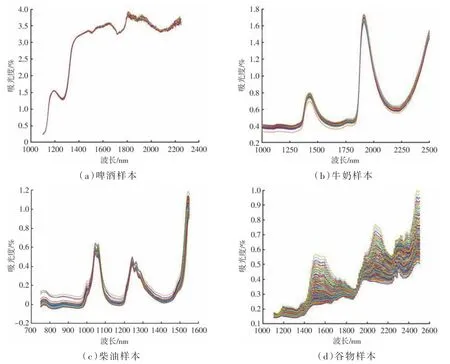
图1 不同样本集的近红外光谱
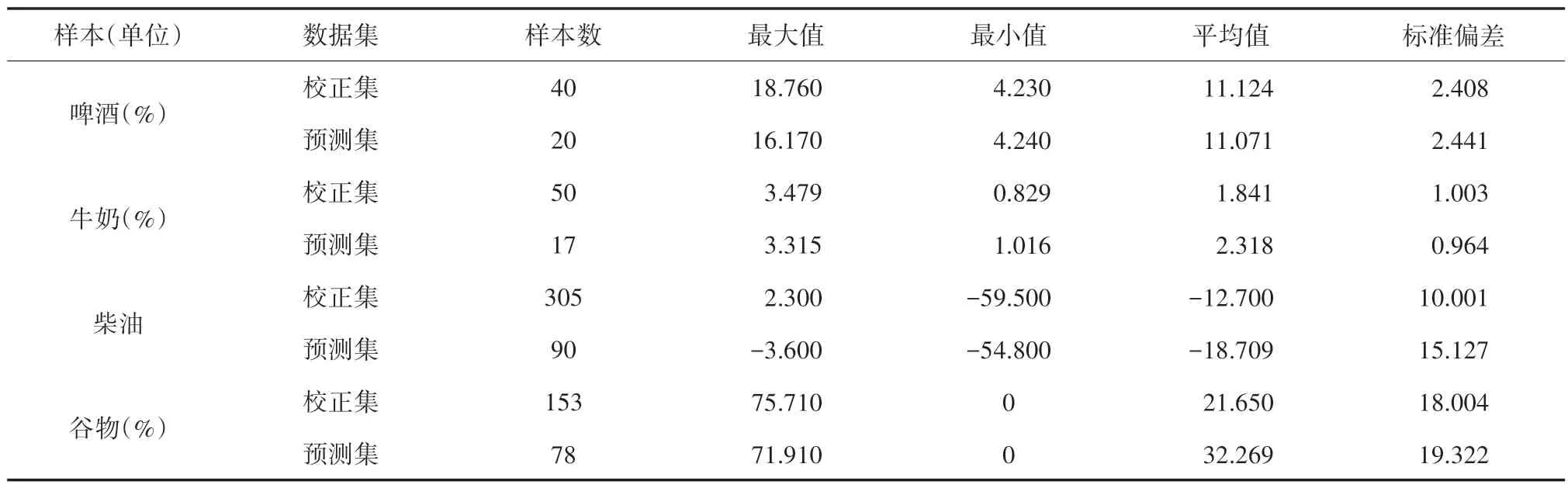
表1 校正集和预测集中物质含量统计分布
1.2 牛奶数据集
牛奶样本共67 个,牛奶样本校正集与预测集的蛋白质含量分布如表1 所示。数据来源于参考文献[15]。本研究采用K-S 方法将其中40个样本光谱和化学值选为校正集,其余的27 个样本光谱和化学值作为预测集。牛奶样本的近红外光谱数据如图1(b)所示,每个样本的蛋白质含量用化学方法测量所得,每个光谱扫描的波长范围为1 000~2 500 nm,扫描间隔为4 nm,扫描32 次取平均值。
1.3 柴油数据集
柴油样本共395 个,其数据来源于公共数据(https://eigenvector. com/resources/data-sets/)。 柴油样本校正集与预测集的冰点分布如表1 所示,柴油样本的近红外光谱数据如图1(c)所示。本研究每个样本的冰点用化学方法测量所得,波长范围为750~1 550 nm,其近红外光谱数据由美国西南研究所测量得到。本研究采用K-S 方法将305 个样本光谱和化学值选为校正集,其余的90 个样本光谱和化学值作为预测集。
1.4 谷物数据集
谷物样本共231 个,谷物样本校正集与预测集的乳酸含量分布如表1 所示,其数据来源于公共数据(https://eigenvector.com/resources/data-sets/)。每个谷物样本的乳酸含量用化学方法测量所得,波长范围为1 104~2 495 nm。谷物样本的近红外光谱数据如图1(d)所示。本研究采用K-S 方法将153 个样本光谱和化学值选为校正集,其余的78 个样本光谱和化学值作为预测集。
2 模型原理
2.1 基本结构
近红外光谱分析模型(Convolutional Neural Network with Efficient Channel Attention,CNNECANet)结构如图2 所示。该模型包括1 个ECA 模块、8 个一维卷积层、4 个最大池化层、1 个展平层、1 个超参数优化器和2 个全连接层,每个部分都由字母标记为C1、C2、C3、C4、C5、C6、C7、C8、F1、M1、M2、M3、M4、D1 和D2,如图2 所示。其中,一维卷积层的卷积核大小为3,卷积步长为1,卷积核数目分别为16、16、64、64、128、128、64和64,激活函数为relu,使用填充;每两个卷积后紧跟一个最大池化层,缩小比例因数为2,最大池化窗口大小为2;然后是展平层;全连接层的输出维度分别为64 和1,第一个激活层的激活函数为relu;在M2 后插入ECA 模块,该模块由一维全局平均池化层、一维卷积层和Sigmoid 激活函数组成,一维卷积层的卷积核数目为1,根据特征图的通道数计算得到自适应卷积核大小,模型超参数设置如表2 所示。该模型通过随机初始化的方式进行实验,训练过程采用均方误差(MSE)损失函数和Adam 优化器,MSE 具体计算公式如下:

表2 CNNECANet在四个数据集上的超参数
2.2 基本原理
CNNECANet 是基于一维卷积神经网络和ECA注意力机制搭建的。卷积神经网络的基本结构主要包括输入层、卷积层、池化层、全连接层和输出层[16]。通过卷积层中的卷积核对输入层特征进行提取,同一特征权值共享[11],激活函数为relu,为模型引入非线性关系。本研究选择最大池化方法,通过池化层压缩数据、减少参数量能够使模型避免过拟合。展平层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。全连接层作线性变换,起到“分类器”或者“回归器”的作用,提高模型预测精度增强稳定性。ECA 具有自适应核大小的一维卷积,Sigmoid 函数能够实现对每个通道的重要性进行预测,由此可以得到模型各个通道的权重,更有效地对光谱内部特征进行自动提取,该方法在较低的模型复杂度下获得了更好的性能。模块在对卷积特征进行聚合后,首先自适应确定核大小k,进行一维卷积,然后使用Sigmoid 函数学习通道注意。
详细步骤如下:
(1)整理啤酒、牛奶、柴油、谷物的近红外光谱公共数据,使用K-S 算法分为校正集和预测集。
(2)设置模型迭代次数为50。
(3)样本光谱数据进入卷积层C1、C2,通过卷积运算提取16 个通道的特征向量。
(4)提取的特征向量进入最大池化层M1,选择每个子区域最大值,并使用子区域最大值表示该子区域。
(5)通过最大池化层的特征向量依次进入模型C3、C4 层和M2 层,输出64 个通道的特征向量。
(6)根据特征图的通道数计算得到自适应的一维卷积核大小kernel_size。
(7)64 个通道的特征向量进入ECA 模块的全局平均池化层,对输入特征图进行空间特征压缩,得到通道数为1 的特征图。
(8)将kernel_size 用于一维卷积中,对压缩后的特征图进行通道特征学习,输入和输出通道数都是1。
(9)然后是Sigmoid 激活函数,权值归一化,将原输入特征图和归一化权重逐通道相乘,生成加权后的特征图,特征向量的通道为64。
(10)64 个通道的特征向量依次进入C5、C6、M3、C7、C8 和M4,输出64 个通道的特征向量。
(11)输出的64 特征向量进入展平层F1,展平操作将其展平成一维向量。
(12)经过展平的特征向量依次进入到全连接层D1、D2,经过线性变换得到预测值。
(13)使用MSE 计算预测值和真实值之间的差距,使用Adam 优化器优化模型参数。
(14)超参数优化器根据预测结果的准确性选择最优超参数。
(15)依据模型参数和最优的超参数保存最优CNNECANet。
2.3 评价指标
本研究使用校正均方根误差(RMSEC)、校正集相关系数(R2c)、预测均方根误差(RMSEP)、预测集相关系数(R2p)和相对分析误差(RPD)对模型进行评价,公式如下:
式中,Nc为校正集样本数;Np为预测集样本数;、分别为校正集样品平均值和预测集样品平均值;yc i、分别为校正集第i个样品的实际值和预测值;yp i分别为预测集第i个样品的实际值和预测值;SD 是预测集样本的标准差。
3 结果与讨论
将校正集原始光谱分别输入PLS、SVR、BP网络模型,不同建模方法均运行50 次,对啤酒、牛奶、柴油、谷物四个公共数据集进行预测。CNNECANet、PLS、SVR 和BP 模型均使用keras 机器学习库搭建和训练,最终统计CNNECANet、PLS、SVR 和BP 模型的预测结果。啤酒、牛奶、柴油、谷物的建模统计结果如表3 所示,其中,表示取平均值。

表3 不同建模方法统计结果
对比PLS、SVR、BP、CNNECANet 四种不同模型预测结果可知,CNNECANet 模型的泛化能力和预测精度都比其他三种模型更好。在啤酒酵母含量的预测中,CNNECANet 的RMSEP 值分别比PLS、SVR 和BP 减少0.175、0.203 和2.943,建模精度分别提升了30.3%、33.5%和80.0%;在牛奶蛋白质含量预测中,CNNECANet 的RMSEP 值分别比PLS、SVR 和BP 减少0.08、0.104 和0.2,建模精度分别提升了14.1%、17.6%和29.0%;在柴油冰点的预测中,CNNECANet 的RMSEP 值分别比PLS、SVR 和BP 减少2.639、4.018 和0.49,建模精度分别提升了29.5%、39.0%和7.2%;在谷物乳酸的预测中,CNNECANet 的RMSEP 值分别比PLS、SVR 和BP 减少5.296、5.654 和4.196,建模精度提升了48.4%、50.0% 和42.7%。由表3 可知,PLS、SVR 和BP 模型的RMSEP 与RMSEC 差值较大,说明这些模型预测误差较大,可能存在过拟合现象;而CNNECANet 模型相较之下,其RMSEP 与RMSEC 差值较小,说明该模型并未出现过拟合,同时,CNNECANet 的RPD 平均值相较于PLS、SVR 和BP 均有所增大,说明CNNECANet 有更好的泛化能力和鲁棒性。
综上,CNNECANet 的卷积层和激活函数提供了更好的非线性表征,使用最大池化避免了模型出现过拟合,同时结合ECA 注意力模块,以少量参数增加模型复杂度,提升模型性能。因此,相较于PLS、SVR 和BP 模型,CNNECANet 有更好的鲁棒性和预测精度。
4 结论
CNNECANet 是一种结合了ECA 注意力模块与卷积神经网络的近红外光谱分析模型。四种不同的模型在啤酒、牛奶、柴油和谷物的公共近红外光谱数据集上进行预测,结果表明,CNNECANet 比PLS、SVR 和BP 模型有更好的鲁棒性和预测精度。CNNECANet 模型通过卷积层提取输入层的特征信息,采用relu 激活函数让模型获得更好的非线性表征,使用最大池化层减少参数量,采用ECA 模块降低模型复杂程度并增强了模型性能,通过全连接层提供更好线性表征。与PLS、SVR 和BP 模型相比,CNNECANet 减少了过拟合的现象,增强了模型的泛化能力并提高了预测精度,使模型具有更好的鲁棒性。
