基于ARIAM-GARCH 深度学习的股价预测与决策
2024-03-08刘祺施三支娄磊刘璐
刘祺,施三支,娄磊,2,刘璐,3
(1.长春理工大学 数学与统计学院,长春 130022;2.东北证券股份有限公司长春生态大街营业部,长春 130022;3.长春市绿园区春城街道办事处,长春 130022)
金融市场被认为是世界经济的核心,每天有数十亿美元的外汇交易。其中股票市场在经济增长中扮演着重要的角色。因此,分析它们的行为和预测它们的未来对实现经济目标非常有帮助。越来越多的学者投入到对于股价预测以及波动预测的研究当中。早在1982 年Engle[1]就提出了自回归条件异方差(ARCH)过程应用于估计英国通货膨胀方差,并取得了较好的效果。1997年Hochreiter 等人[2]引入一种新的、高效的、基于梯度的方法,称为长短期记忆(LSTM)来解决了传统神经网络(RNN)无法学习长期依赖关系的问题,自此LSTM 模型被得到广泛的关注,并应用到生物、金融等多个领域。2001 年Engle 等人[3]又发展了一类新的能够估计大的时变协方差矩阵的理论和经验性质的多元广义自回归条件异方差(多元GARCH)模型,动态条件相关多元GARCH。2018 年Zhou 等人[4]提出了一个利用LSTM 和卷积神经网络(CNN)进行对抗性训练来预测高频股市的通用框架。2018 年Kim 等人[5]提出了一种新的混合LSTM 模型来预测股价波动,该模型将LSTM 模型与GARCH 型模型相结合。2021 年Lu 等人[6]也是将CNN、双向长短期记忆神经网络(BiLSTM)与注意机制(AM)进行了结合,应用到上证综合指数上。2021 年Boulet[7]为研究混合模型,混合GARCH 过程和神经网络,预测资产收益的协方差矩阵的能力,提出了一个新的模型,基于多元GARCH 情况下分解波动性和相关性预测。2021 年姜旭[8]利用深度学习模型结合传统计量GARCH 族模型来构建新的模型预测波动率。
2022 年Darapaneni 等人[9]使用LSTM 与随机森林进行混合搭建,利用历史价格和可用的情绪数据来预测股票的未来走势。2022 年Fjellström[10]提出了一个独立和并行的LSTM 神经网络的集成来预测股票价格的运动。2022 年Shi 等人[11]提出一种基于注意力机制的CNN-LSTM 和极限梯度提升算法(XGBoost)混合模型来预测股价。2022 年Ogulcan 等人[12]将线性卡尔曼滤波器和不同种类的LSTM 进行构建应用于历史股票价格,以预测股票未来的价格。
受Shi 等人[11]所构建的带有注意力机制的CNN-LSTM-XGBoost 混合模型的方法启发,本文主要针对于中小企业股价进行预测,并在投资者的期望收益率下,给出一种投资组合最优决策方法。主要内容如下:
(1)在Shi 等人[11]的具有注意力机制的CNNLSTM-XGBoost 的基础上,加入GARCH 模型对数据集进行预处理,使数据集更好地展现自身数据特征,大大减小了数据噪声。引入BiLSTM 网络减少训练损失,根据数据特征修改网络结构,提高预测精度。
(2)针对于中证500 指数中的中小企业股建立独立并存的网络模型,并进行相关拟合训练,并与其他4 种文献中的方法进行了比较,结果表明所构建网络对于中小上市企业运行较为稳定。
(3)在给定投资者预期收益率的条件下,采用Bayes 方法进行投资组合,以达到预期收益率,为投资者提供最优决策的数据支持。[13-14]
1 相关模型介绍
1.1 ARIMA-GARCH
上世纪70 年代初,Ljung 等人[13]提出ARIMA模型,又称求和自回归移动平均模型。其思想是针对于非平稳时间序列进行数学建模,将其通过差分运算后,变为一个平稳的新序列,进而进行相关数据刻画。
若{εt}是高斯白噪声N(0,σ2),{Xt}为非平稳序列,如果存在正整数d,可以使{Xt}的d阶差分Yt,Yt= ∇dXt是平稳的,则称随机差分方程:
为求和自回归移动平均模型,记为ARIMA(p,d,q),其中d为差分的阶数,p、q为自回归与移动平均的阶数,B为推移算子。且:
根据平稳性的需求,多项式A(z)和多项式B(z)的根在单位圆外,即 |z|>1,称满足ARIMA(p,d,q)模型(1)式的序列{Xt}为ARIMA(p,d,q)序列。
自1982 年Engle[1]提出了ARCH 过程后,Bollerslev[16]在1986 年提出了ARCH 模型的一种重要推广模型,被称为GARCH 模型。对于一组具有集成波动性的数据rt,本文rt为ARIMA 模型所产生的噪声项,令at=rt-μt=rt-E(rt|Ft-1)为其信息序列,称{at}服从GARCH(m,s)模型,如果at满足:
其中,{εt}为零均值单位方差的独立同分布白噪声序列;at为噪声rt的波动干扰项;m、s为GARCH模型阶数。α0>0;αi≥0;βj≥0;最后一个条件用来保证满足模型的at的无条件方差有限且不变,而条件方差σ2t可以随时间t而变。
1.2 CNN-BiLSTM
CNN(Convolutional Neural Networks)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”。卷积神经网络通常包括输入层、卷积层、池化层、全连接层以及输出层,如图1 所示。

图1 CNN 流程结构图
LSTM(Long Short-Term Memory)是一种RNN特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter 等人[2]提出,并被Graves 等人[17]进行了改良和推广。单向的LSTM 网络在推测信息时是由前向后进行的,在单向LSTM 网络的基础上,同时考虑前期信息和后期信息的双向LSTM 网络—BiLSTM 网络,可以有效保证时间序列预测所得结果的精确性。BiLSTM 单元结构如图2 所示。ct、ht分别表示模型在t时刻的记忆状态和隐层状态,xt、Yt分别表示模型在t时刻的输入与输出,σ表示sigmoid 激活函数。

图2 BiLSTM 总体结构图
BiLSTM 网络的计算方式分为前向计算和后向计算,BiLSTM 网络模型由两个LSTM 网络构成,求解时分别计算前项隐藏向量产生新的隐藏向量h*t和后项隐藏向量产生新的隐藏向量h∇t。h*和h∇分别表示前向、后向单元状态。将正反两项与输入序列的输出结果相结合,得到结果Yt,计算公式如下:
其中,wh*y,wh∇y表示每一层连接到前一个隐藏状态时的相关信息对于之后单元影响的权重矩阵;by表示偏置项。
1.3 Attention
Attention(AT)注意力机制由Bahdanau 等人[18]提出,很快得到了广泛的应用。AT 机制可以帮助神经网络更好地利用相关输入的信息,还使得LSTM 等神经网络在长距离依赖中梯度消失的问题得到了进一步的缓解,且还具有一定的可解释性,对相关信息进行权重的分配,忽略一些不重要的信息[19]。图3 展示了AT 机制的结构图。结构过程中三阶段常用公式如下:
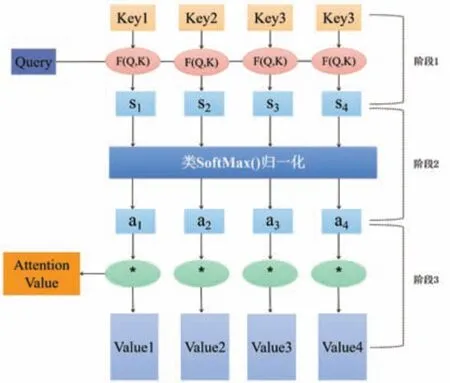
图3 Attention 结构图
(1)计算Query(输出特征)与Key(输入特征)之间的相似性或相关性,如下所示:
其中,Wh为相关权值且各层共享;bh为偏置且各层共享;ht为输入向量。
(2)对第一阶段的得分进行归一化处理,利用softmax 函数对注意力得分进行转换,如下式所示:
其中,v为注意力值。
(3)根据权重系数,对相关输入向量进行加权求和得到特征变量最终的注意力值,如下式所示:
1.4 XGBoost
2016 年,Chen 等人[20]首次提出XGBoost 算法,又称极限梯度提升算法。是一种优化结构损失函数的决策树算法。其算法流程如图4 所示。
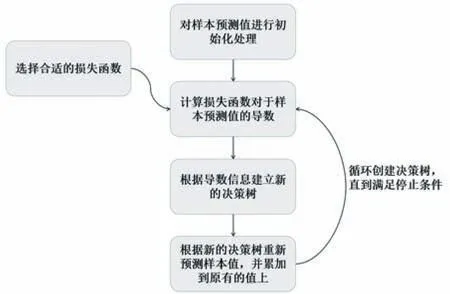
图4 XGBoost 算法流程图
1.5 Bayes 方法
Bayes 方法是一种常用的样本估计的方法。使用Bayes 方法的充要条件是要已知先验信息和样本信息。先验信息即根据经验、常识给定的信息,样本信息即为所抽样本的相关信息。其原理为现如今所熟知的条件概率公式,如下所示:
其中,ωi为投资组合中各资产所分配的权重;θ为期望收益率;π(ωi)为ωi的先验信息;P(θ|ωi)为已知的样本信息;P(θ)为边际信息,通常看作常数;π(ωi|θ)为所求的后验信息。通常可简化为:
2 投资预测与决策
2.1 模型构建与预测
在本文的混合模型构建及预测过程中,首先使用ARIMA-GARCH 混合模型对数据进行预处理,然后采用CNN-BiLSTM-AT 混合神经网络对数据集进行训练并预测,最后用XGBoost 对预测结果进行修正。其相关模型影响如表1 所示。

表1 各模型作用凭栏表
根据ARIMA、GARCH、CNN、BiLSTM、AT 和XGBoost的特点,建立了基于ARIMA-GARCH-CNNBiLSTM-AT-XGBoost 的股票预测模型。模型结构图如图5 所示。主要结构可分为三个阶段:数据预处理阶段、数据训练预测阶段和预测结果调整阶段。

图5 ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost模型结构
ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost实施步骤如下:
(1)数据预处理阶段。使用ARIAM 模型对数据集进行差分训练,将非平稳时间序列变为平稳时间序列。通过p值检验检测到残差序列还存在着异方差性,其组成具有集成波动性特点的时间序列,则使用GARCH 模型对残差序列进行建模,消除其存在的异方差性,大大缩小了其噪声干扰因素,使得数据可以更好地展示数据本身所持有的特征。
(2)数据训练预测阶段。首先使用CNN 提取输入数据的特征。然后利用BiLSTM 对提取的特征数据进行学习和预测。最后AT 机制可以用来捕捉时间序列数据在不同时间的特征状态对预测结果的影响。
(3)预测结果调整阶段。使用XGBoost 算法,通过优化结构损失函数,对预测值进行修正。以此来提高该方法的预测精度。
2.2 Bayes 投资决策
在本文中,选择π(ωi)先验分布为共轭先验分布,服从LDA(狄利克雷)分布,P( )θ|ωi服从高斯分布,则π( )ωi|θ也服从LDA 分布。在给定期望收益率θ和求出π( )ωi|θ的后验分布的条件下,使用极大似然估计法,解出作为初始值,带入MCMC(蒙特卡罗)采样中,进行抽样迭代,最终取趋于稳定后的采样结果均值作为最终值。
LDA 分布的概率密度函数如下:
其中,ωi∈[0,1] 且∑ωi= 1;α= (α1,α2,…,αk)为超参数;
3 数据与实验
3.1 数据选取
本实验选取中证500(000905)指数在2022 年5 月20 日时权重较高的十只股票:振华科技(000733)、山西焦煤(000983)、纳思达(002180)、格林美(002340)、以岭药业(002603)、永泰能源(600157)、兖矿能源(600188)、广汇能源(600256)、中天科技(600522)和中国化学(601117)作为实验数据。从雅虎财经官网(https://hk.finance.yahoo.com/)获得2012年5月2日至2022年4月29日2 431个交易日的日交易数据。每条数据包含6 个项:开盘价、最高价、最低价、收盘价、调整收盘价和成交量,数据如表2。本实验以前2 000 个交易日的数据作为训练集,以后431 个交易日的数据作为测试集。

表2 000733 股票的部分数据
这里的开盘价是一个交易日(股票交易所开市后)的第一笔交易股票价格。最高价格是指股票在每个交易日开盘价到收盘时的最高价格。最低价是指某只股票从每个交易日开盘到收盘的最低价。收盘价是指当日股票最后一次交易前一分钟每笔交易的加权平均交易量价格。调整收盘价是指在收盘价的基础上进行相应的差值调整,往往与收盘价差异不大,调整后的收盘价往往是由多种影响股价的因素所导致而成,更能体现企业进行各种活动后的价值。成交量指的是当天交易的股票总数。
3.2 相关评价指标
为了证明ARIMA-GARCH-CNN-BiLSTM-ATXGBoost 的有效性,在相同的操作环境下,使用相同的训练集和测试集数据,将该方法与CNNBiLSTM、CNN-BiLSTM-AT、SVM-LSTM 和ARIMACNN-LSTM-AT-XGBoost 进行了比较。为了评价ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost 的预测效果,以均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和R平方(R2)为评价标准。
(1)均方根误差
均方根误差表达式为:
其中,为预测值;yi为真实值。RMSE 越小,预测越准确。
(2)平均绝对误差
平均绝对误差表达式为:
其中,为预测值;yi为真实值。MAE 越小,预测越准确。
(3)R平方
R平方表达式为:
其中,为预测值;yi为真实值;为均值。R2的取值范围为0~1 之间,越接近1 效果越好。
3.3 算法步骤
ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost训练过程的主要步骤如下:
(1)输入数据。将10 只股票相关数据分别输入ARIMA-GARCH 层。
(2)ARIMA-GARCH 数据预处理。对于10 只股票分别进行ARIMA 模型建模,对其噪声项(残差项)再分别进行GARCH 建模,减少数据噪声,得到一组新的数据,加入到原有数据集中,组成新的数据集。
(3)输入更新后的数据。分别输入ARIMAGARCH-CNN-BiLSTM-AT-XGBoost 训练所需的数据。
(4)输入数据标准。由于输入数据差距较大,为了更好地训练模型,采用z-score 标准化方法对输入数据进行标准化,如下式所示:
其中,yi为标准化值;xi为输入数据;为输入数据的平均值;s为输入数据的标准差。
(5)网络初始化。初始化ARIMA-GARCHCNN-BiLSTM-AT-XGBoost 每一层的权值和偏差。
(6)CNN 层。输入数据在CNN 层内经过卷积层,对输入数据进行特征提取,得到输出值。
(7)BiLSTM 层。通过BiLSTM 层的隐层计算CNN 层的输出数据,得到输出值。
(8)AT 层计算。通过AT 层计算BiLSTM 层的输出数据,得到输出值。
(9)XGBoost 修正。对预测值进行误差修正。
(10)输出层。计算修正后的输出值,得到模型的输出值。
(11)计算误差。将输出层计算出的输出值与该组数据的真实值进行比较,计算出相应的误差。
本文针对选取的10 只中小企业股票对应于10个混合模型进行训练测试,相关结构如图6 所示。
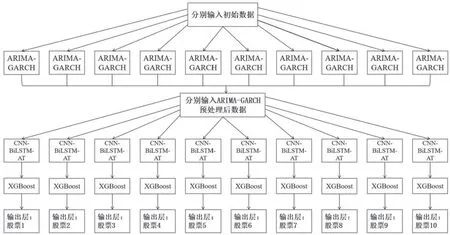
图6 ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost 独立训练模型
3.4 模型的参数设置
本实验的ARIMA-GARCH-CNN-BiLSTM-AT模型的参数设置如表3 所示。
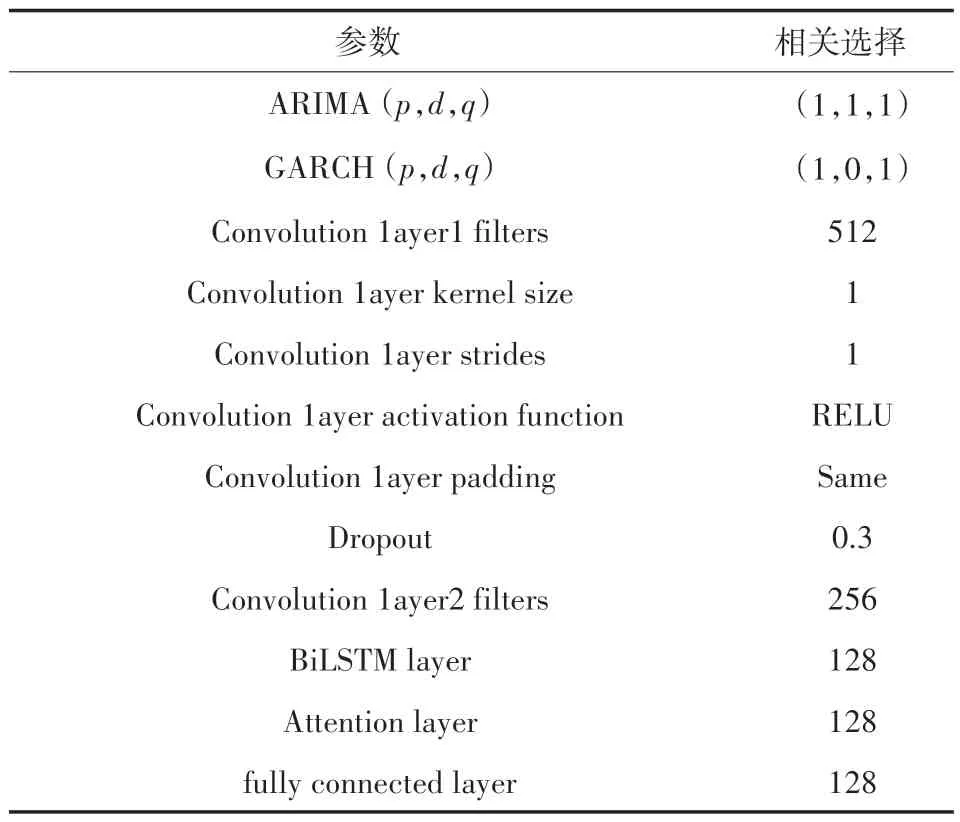
表3 ARIMA-GARCH-CNN-BiLSTM-AT 模型参数设置
在本实验中,所有方法训练参数相同,epoch为20,loss function为MAE,optimizer chooses为Adam,batch size 为100,滑动窗后设置为20,learning rate为0.01。在本文的研究中,发现随着迭代次数的增长,信息损失越少,如图7 所示,这也体现了模型对信息的充分利用性。

图7 000733 在混合神经网络训练中信息随迭代次数的损失
3.5 结果分析
使用ARIAM 模型对时间序列数据集进行差分训练,对其残差序列进行p值检验,检验序列是否还存在异方差性,相关结果如表4 所示。

表4 p 值检验残差序列
由表4 可以看到,对各股票历史数据进行差分训练,将非平稳时间序列变为平稳时间序列的过程中,对其残差序列进行的p值检验中发现,除600522 股票外其余各股p<0.05,存在着异方差性,需进一步进行数据处理,而600522 股因其时间序列中有一段较长时间的空集,导致p值异常,这是因为其有一段较长时间的停盘期所导致。
为简洁、直观,本文仅以代码000733 的股票为例。在数据预处理阶段,发现有无GARCH 模型对于数据残差项的处理有着很大的差距,如图8 和图9 所示。通过图8 和图9 可以清晰地看到,在未加入GARCH 模型前,对数据的处理所产生的残差项大多数在±10 区间内,而在GARCH模型介入后,可以看到,绝大多数残差落在了±0.04区间内,这大大缩小了噪声项对于数据的影响,使得数据可以更加纯粹地展示自身的数据特征,为之后的数据训练打下了良好的基础。

图8 ARIMA 模型下000733 的残差轨迹和核密度函数

图9 加入GARCH 模型后000733 的残差轨迹和核密度函数
通过数据训练及预测调整阶段,计算模型的评价误差指标RMSE、MAE 和R2并分别与其他方法进行比较,结果分别如表5~7 所示。

表5 十只股票对应于各方法的RMSE 值
从表5 可以看出,针对这10 只股票,ARIMAGARCH-CNN-BiLSTM-AT-XGBoost模型下的RMSE最小效果最好,且ARIMA-GARCH-CNN-BiLSTMAT-XGBoost 模型效果明显要优于其他模型。其他模型的效果除个别股票情况外相差较小,个别情况可能是由于不同数据集所拥有的数据特征不同所产生的。但SVN-LSTM 模型下的RMSE均值效果最差,二者相比ARIMA-GARCH-CNNBiLSTM-AT-XGBoost 的RMSE 最大减少了90.57%。
由表6 可以了解到,针对于本文所选的10 只股票而言,ARIMA-GARCH-CNN-BiLSTM-ATXGBoost 模型下的MAE 最小效果最好,且明显要优于其他模型。SVM-LSTM 模型下的MAE 平均效果最差,二者相比ARIMA-GARCH-CNN-BiLSTMAT-XGBoost 的MAE 最大减少了92.21%。
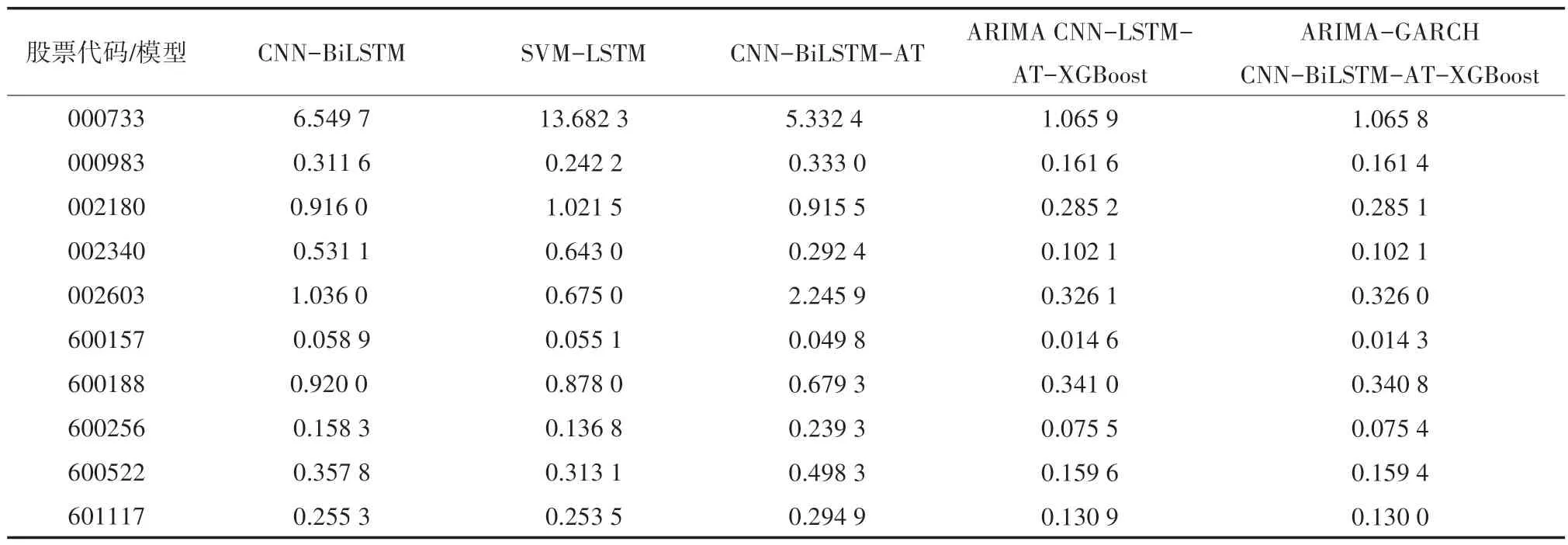
表6 十只股票对应于各方法的MAE 值
根据表7 可知,对于本文选取的10 只股票来说,ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost 模型下的R2均值更接近于1,效果最好,且效果显著优于其他模型。CNN-BiLSTM 模型下的R2均值较其他模型而言与的1 的差值最大,且效果最差,二者相比ARIMA-GARCH-CNN-BiLSTM-ATXGBoost 的R2最大增加了144.40%。

表7 十只股票对应于各方法的R2 值
由表5~7 综合来看,前期对于数据集噪声项的处理是非常有必要的,越纯粹的数据集越能表现出数据本身所特有的特征,可以更好地帮助研究者进行相关的研究。这10 只股票在不同的模型下虽有着不同的表现,但在ARIMA-GARCH-CNNBiLSTM-AT-XGBoost 模型下的综合表现最好,且效果显著优于其他模型,其他模型可能是因训练数据不同,数据噪声波动有所差异,对此数据未能较好地适应所导致。
由实验结果可知,针对于不同的数据集需要制定不同的网络模型。但针对于股票金融时间序列数据不管构建什么样的混合模型用来预测,都存在数据噪声干扰项,对于数据噪声项的处理是非常有必要的,以此来保证所使用的数据的有效性,提高预测精度。针对于中证500 指数中的中小企业而言,本文所改进的ARIMA-GARCHCNN-BiLSTM-AT-XGBoost 混合模型方法在预测第二天的股票收盘价上效果最优,为投资者做出正确的投资决策提供参考。
4 Bayes 实现投资组合优化
本文使用所选的10 只股票来构建投资组合,选定2021 年12 月14 日至2022 年4 月29 日作为投资期间,选取此期间每只股票的日收盘价,并进行相关日收益率计算形成所需数据集。根据相关经验,选取先验信息π(ωi) 服从LDA 分布,P(θ|ωi)服从高斯分布,由经验可知π(ωi|θ)与π(ωi)的概率分布为共轭分布。分别给定期望收益率为8%、10%、12%的情况下,对于本文所构建的投资组合权重分配方法,如表8~10 所示。由表8~10 可以看到投资组合资产分别在相对应的权重分配下最大概率会分别实现期望收益率为8%、10%和12%的情况。
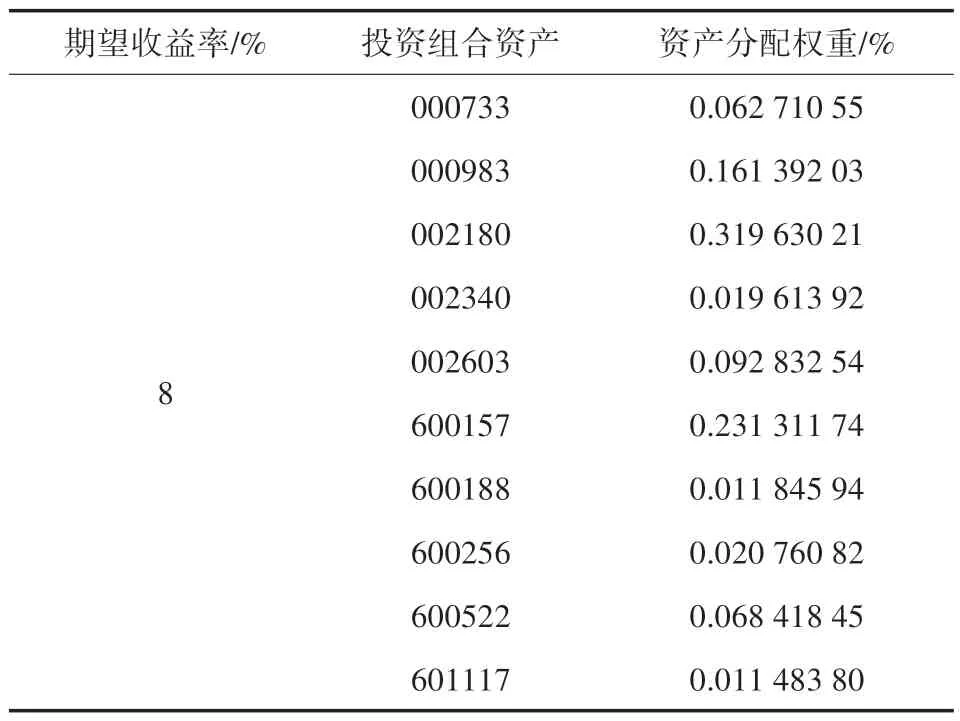
表8 期望收益率为8%的情况下的投资组合权重

表9 期望收益率为10%的情况下的投资组合权重

表10 期望收益率为12%的情况下的投资组合权重
在上述随机选定的投资区间内,在资金充足,每次买入份额相同的条件下,实行以15 天为一周期,每期三次操作,期初买入,期中买入,期末卖空的交易策略,应用上述方法分别对期望收益率为8%、10%和12%的条件下进行10 次实际操作,所得实际收益率的相关情况如图10 所示。
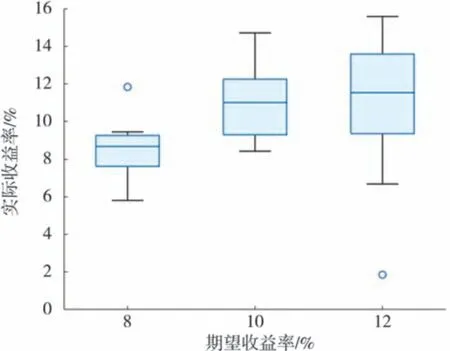
图10 期望收益率与实际收益率对比箱线
通过图10 可以看到10 次操作的实际收益率的均值均接近期望收益率,且期望收益率在8%和10%的情况下实际收益率的均值也是超过了期望收益率,获得了一个超额收益,说明Bayes 实现投资组合优化的可实用性。此后还分别进行了6%、14%、16%、18%和20%期望收益率条件下的实际操作所得实际收益率情况,发现随着期望收益率的增加,在此交易策略下的实际收益率相较于期望收益率相差较大,这是由于中小企业股的投入成本相对较小,收益率有限所导致的。
5 结论
本文建立了ARIMA-GARCH-CNN-BiLSTM-ATXGBoost 模型对股价进行了预测。并在给定期望收益率的条件下,运用贝叶斯方法进行投资组合,给出最优投资策略。
本文以开盘价、最高价、最低价、收盘价、调整收盘价、成交量等数据作为输入。充分利用了股票数据的时间序列特征。实验结果表明,ARIMA-GARCH-CNN-BiLSTM-AT-XGBoost 模型的RMSE 和MAE 是所有方法中最小的,R2也是最接近1,其性能最优。由于股票数据存在着数据干扰,通过该模型对数据噪声项进行处理,以此来保证数据的有效性,提高预测精度。使用Bayes 方法在给定期望收益率下进行投资组合优化。为投资者的最大化投资收益提供相关参考。
Bayes 方法相较于传统的均值-方差模型而言,无需考虑无风险资产状况。传统的均值-方差模型主要是针对与无风险资产和风险资产构建的投资组合产品进行资产配置。且传统的均值-方差模型是在确定投资者风险厌恶程度的基础上,实现最大收益的投资组合方案,一定程度上未能满足投资者的期望收益率。本文Bayes方法从概率角度出发,实现了在给定期望收益率条件下,最大概率实现投资者预期收益的最优投资组合方案,对于投资而言会更加严谨,在满足投资者期望收益率的条件下提供最优投资决策。
