基于双路特征和混合注意力的微表情识别
2024-03-05薛珮芸师同同
袁 博,薛珮芸,2*,白 静,师同同
(1.太原理工大学 信息与计算机学院,山西 太原 030024;2.山西高等创新研究院,山西 太原 030032)
0 引言
微表情是一种变化迅速的面部表情,具有持续时间短、变化细微等突出特点,通常发生在某人故意隐藏或压抑自己的真实感受时[1]。微表情作为一种心理应激反应,既不能隐藏也不能抑制,因此,微表情识别在公共服务、刑事侦查和临床诊断等领域有着广泛的应用。由于微表情的变化是迅速而微妙的,动作特征非常微小,因此如何有效地识别微表情对专业人士来说是一个极大的挑战。
现有的研究主要从2个方面提取微表情特征:使用传统的特征提取方法和基于深度学习的特征提取方法。传统的微表情特征提取方法包括图像纹理特征[2-3]和光流特征[4-6]2类。近年来,随着人工智能的快速发展,越来越多的研究尝试使用深度学习算法提取微表情特征。然而,由于现有的微表情数据集样本量很少,对原始的微表情图像使用深度学习算法很难获得满意的效果,因此迁移学习成为解决这个问题的一种有效策略[7-9]。在最近的研究中,许多研究者同时将深度学习和光流法应用到微表情识别中[10-12]。作为一种捕获视频中运动信息的成熟技术,在进行微表情识别时,光流比原始图像序列更有效。光流特征是一种动态几何特征,表示了图像序列在X、Y、T三个方向的运动情况,然后将光流特征输入到卷积神经网络中,该网络可以通过监督学习的方式构造并选择更重要的运动特征进行分类。然而,尽管光流图像比于原始图像有更好的效果,但是受到微表情数据集样本量较少的限制,能够提取到的光流特征也是有限且单一的。虽然目前有很多研究在尽可能地提取光流特征中的信息,但对最终微表情识别率的提升效果不明显。
针对以上问题,本文提出了一种基于差分图像序列的微表情特征提取方法,可以有效地提取到微表情序列的运动特征。为了在较短时间内提取到微表情的关键信息,设计了一种基于双路特征和混合注意力机制的分类模型,将微表情的差分图像序列特征和光流特征由2条支路送入混合注意力机制模型。实验结果表明,使用双路特征比单一特征效果更好,使用混合注意力机制的效果远好于不使用注意力机制。
1 微表情光流特征的提取
光流是图像序列中连续2帧之间物体的视运动的模式,是一种二维向量场,其中每个向量都是位移向量,代表图像中像素点在相邻帧之间的运动位移。光流法是基于以下3个假设提出的:
① 连续帧之间的亮度恒定;
② 连续帧像素强度不变;
③ 保持空间一致性。
在上述3个假设条件满足的情况下,连续2帧之间的像素值可以表示为:
I(x,y,t)=I(x+dx,y+dy,t+dt),
(1)
式中:I(x,y,t)表示在t时刻图像在坐标(x,y)处的像素值,2帧之间间隔dt时间,dx、dy分别表示上一帧(x,y)处的像素点在x轴和y轴上的位移。
然后使用泰勒级数进行右侧逼近展开,去掉常数项且两端同时除以dt,得到:
fxu+fyv+ft=0,
(2)
式中:
(3)
(4)
式(1)~式(4)称为光流方程式,其中fx和fy表示像素在x轴和y轴上的位移,ft是像素随时间变化的梯度,这些可以很容易得到。但是(u,v)是未知的,不能用2个未知变量来求解这个方程。为了解决这个问题,本文使用Lucas-Kanade算法,用一个3×3矩阵将像素周围9个点包围起来,在假设③满足的情况下,可以视为被3×3矩阵包围的这些点的运动是相同的,可以找到这些点的fx、fy和ft,然后得到一个包含2个未知变量的方程组,使用最小二乘法求方程组的解,公式如下:
。(5)
通过上述算法即可得到微表情的光流向量(u,v),然后将微表情光流向量转化为RGB图像,得到的光流特征如图1所示。

图1 微表情光流特征Fig.1 Micro-expression optical flow characteristics
2 微表情差分图像序列的提取
虽然光流图像可以很好地反映帧间目标运动状态的变化,但是在计算光流特征时会受到光流法3个假设条件的限制,当这3个假设不能很好地满足时,很容易产生误差,从而引入大量的噪声。在实际情况中,由于光线和目标运动速度不确定等因素的影响,导致光流特征的3个假设条件不容易满足。针对上述问题,本文提出了一种基于差分图像序列的微表情特征提取方法,该方法可以有效地提取到微表情序列的运动特征,当不考虑光照条件变化的影响时,图像差分算法的表达式如下:
Di(x,y)=Ii(x,y)-Ionset(x,y),
(6)
式中:Ii(x,y)表示微表情序列第i帧在(x,y)处像素的灰度值,Ionset(x,y)表示微表情序列起始帧在(x,y)处的灰度值,Di表示微表情序列第i帧通过图像差分运算得到的特征矩阵,Di(x,y)表示经过图像差分算法后在(x,y)处的特征值。
在使用图像差分算法时,同样会受到光照条件变化的影响。为了解决这个问题,本文对微表情序列中的每一帧与起始帧进行图像差分运算,可以得到与微表情序列帧数相同的差分图像序列。由于差分图像序列中的每一帧都是由微表情序列的对应帧与起始帧进行差分运算得到,所以差分图像序列中的每一帧都考虑到了光照变化产生的影响。为了表示第i帧和起始帧之间由于光照条件变化引入的噪声,本文引入时间维度变量t,具体表达式如下:
Fi(x,y,ti)=Di(x,y,ti)+δ(ti),
(7)
F= {F1,F2,…,Fn}=
{D1+δ(t1),D2+δ(t2),…,Dn+δ(tn)},
(8)
式中:δ(ti)表示在计算第i帧差分图像时由于t0~ti时刻的光照变化引入的噪声,Fi表示考虑了噪声的第i帧差分图像,F={F1,F2,…,Fn}表示最后得到的差分图像序列特征。本文在对微表情图像帧归一化时,使用的是等间隔采样法,即对每一个微表情序列等时间间隔采取10帧,因此这里n=10,间隔时间Δt表达如下:
Δt=t1-t0=t2-t1=…=tn-tn-1。
(9)
式(8)可以写成:
F= {F1,F2,…,Fn}=
{D1+δ(t1),D2+δ(t1+Δt),…,Dn+δ(t1+(n-1)Δt)}。
(10)
由于亮度随时间的变化是平稳连续的,且n=10是一个有限数值,所以当Δt足够小时,在Δt时间内由于光照产生的噪声可以忽略不计,即:
δ(t+Δt)=δ(t),Δt→0,
(11)
所以式(10)可以写成:
F= {F1,F2,…,Fn}=
{D1+δ(t1),D2+δ(t1),…,Dn+δ(t1)}。
(12)
因此,差分图像序列特征F={F1,F2,…,Fn}中每一帧都考虑到了与起始帧之间的噪声,且每一帧的噪声都是δ(t1),δ(t1)表示微表情序列第一帧与起始帧之间的噪声。将差分图像序列特征F={F1,F2,…,Fn}作为神经网络的输入特征时,由于每一帧引入的噪声都是δ(t1),相当于在原始序列特征上加了一个常数,因此在训练时并不会对训练结果产生影响,这样就避免了光照条件变化对分类结果产生的影响。得到差分图像序列特征Fi后,将这些特征使用均值归一化进行处理,将所有特征值归一化到-1~1,这样可以避免在后续对特征进行分类的过程中由于特征值范围过大对最终分类结果产生影响,具体表达式如下:
(13)


图2 根据原始微表情序列提取差分图像序列Fig.2 Extract the difference image sequence according to the original micro-expression sequence
3 基于混合注意力机制的分类模型
注意力机制的本质是给予不同的特征信息赋不同权重的过程,即给那些对最终结果贡献度较大的特征赋予较高的权重,而对那些无用的特征信息,注意力机制会赋予它们很小的权重,正是通过这种方式,注意力机制可以准确地定位到那些有用信息,同时忽略掉那些无用信息。由于光流特征和差分图像序列特征都是多通道图像的形式,因此本文使用通道注意力机制和空间注意力机制,组成混合注意力机制来提取关键特征。
为了更精准地进行区域定位并识别对最终结果贡献度大的特征信息,本文所用的空间注意力机制将平均池化和最大池化进行了分离,用2个通道分别对特征进行处理,如图3所示。

图3 可分离空间注意力机制Fig.3 Separable spatial attention mechanism
图3展示了本文使用的可分离空间注意力机制的细节,其中X为模型的输入特征,维度为C×H×W,C为通道数,H为特征高度,W为特征跨宽度。为了方便以后训练,避免出现梯度消失的问题,可以对输入特征进行批标准化(Batch Normalization,BN)处理,顾名思义,就是选取一小批数据对特征X作标准化处理,具体公式如下:
(14)
(15)
(16)
(17)

图4 批标准化使用的batch组卷积核Fig.4 Batch convolution kernel used for batch standardization
图5所示为通道注意力机制,输入特征X同样经过批标准化处理后,用2个通道对特征BN(X)进行最大池化和平均池化,输出为C×1×1的特征向量,然后使用多层感知机(Multilayer Perceptron, MLP)对2个特征向量进行处理,最后使用Sigmoid激活函数对其进行激活,即可得到最后的输出结果。
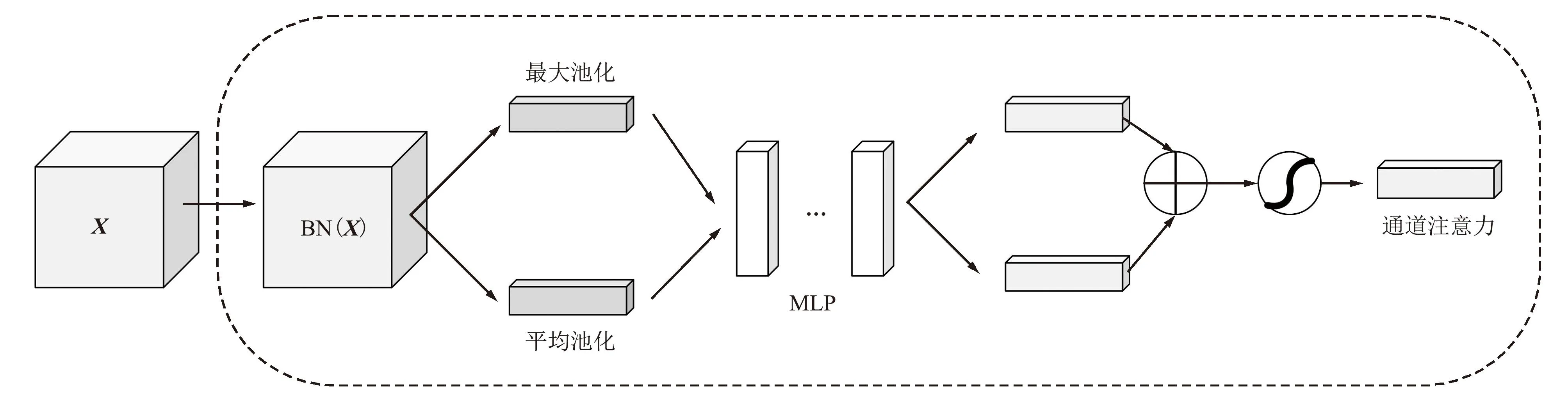
图5 通道注意力机制Fig.5 Channel attention mechanism
将通道注意力机制和空间注意力机制组合成混合注意力机制模块,对微表情的差分图像序列特征图和光流特征图进行分类识别,整体模型结构可视为由混合注意力模块和CNN模块构成,如图6所示,模型输入为微表情序列,根据本文前面提到的算法提取微表情的差分图像序列特征图和光流特征图。然后将2种特征图分2路输入图5所示的通道注意力机制,得到通道注意力输出后对输入的特征图进行采样,即将特征图对应通道特征值与通道注意力输出的对应通道值相乘,得到output_1和output_3。之后将其输入图3所示的空间注意力机制,得到空间注意力机制输出后分别对输入的output_1和output_3进行采样,即将output_1和output_3与空间注意力机制输出的对应位置相乘,得到output_2和output_4。将output_2和output_4经过三维卷积(conv3d)和最大池化之后,将输出通过Flatten展开并送入全连接层(Fully Connected Layers, FC),最后使用Softmax进行分类。
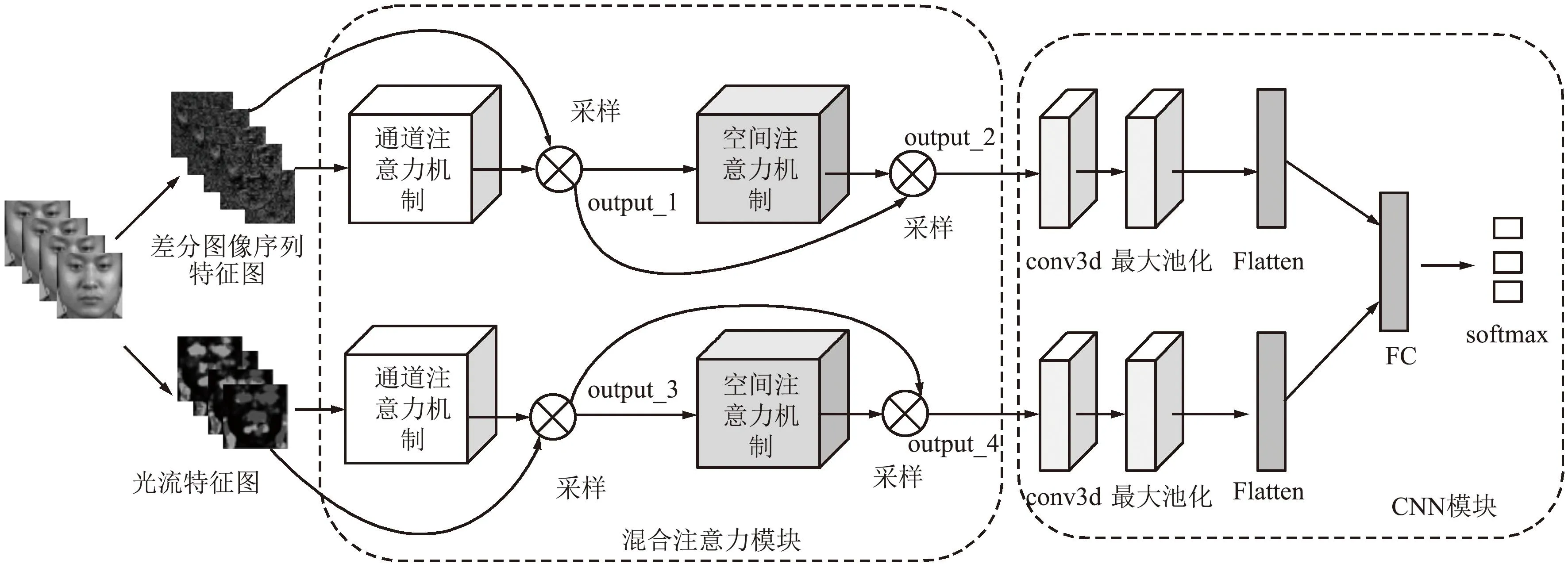
图6 融合注意力机制的双通道微表情识别网络模型Fig.6 Two-channel micro-expression recognition network model with attention mechanism
4 实验结果分析
4.1 实验数据集
本文在CASMEⅡ[13]、SMIC(HS)[14]、SAMM[15]和MEGC2019[16]数据集上进行实验,采用第2届国际微表情识别大赛 (MEGC2019)的微表情分类标准,将标签划分为negative、positive、surprise三类。MEGC2019数据集包含442个样本,分别从CASME Ⅱ、SMIC(HS)、SAMM数据集上抽取了145、164、133个样本,具体划分方式如表1所示。

表1 MEGC2019数据集详细信息
4.2 实验评估准则
由于微表情数据集样本数比较少,因此在本文的实验中,采用了留一交叉验证法,具体来说,就是从微表情数据集的所有人员样本中抽取一个人的样本作为测试集,其余所有人的样本作为训练集,一直重复这个流程,直到整个实验过程中所有人都被当作过测试集。
由于微表情数据集样本数量不均匀,本文使用未加权平均召回率(Unweighted Average Recall, UAR)和未加权F1得分(Unweighted F1-score, UF1)对实验进行评估,并使用混淆矩阵分析在微表情识别时容易产生混淆的数据。首先分别统计真阳性(True Positive,TP)、假阳性(False Positive,FP)、真阴性(True Negative,TN)、假阴性(False Negative,FN)的数量,设样本总数为N。根据这些信息即可算出UAR和UF1,具体计算如下:
(18)
(19)
(20)
(21)
式中:c表示标签类别,TPc表示类别c真阳性数量,FPc表示类别c假阳性数量,FNc表示类别c假阴性数量,Recallc表示类别c的召回率(Recall),UF1c表示类别c的UF1,Nc表示标签数量。
4.3 实验设置
本文实验使用的操作系统为Windows 10,CPU为Intel酷睿i9 12900H,主频2.5 GHz,运行内存64 GB,GPU为NVIDIA GeForce RTX3060Ti,显存8 GB。实验使用环境为Anaconda 4.9.2,Python 3.6.13,Tensorflow 2.2.0,Keras 2.4.3。实验提取的差分图像序列特征图和光流特征图维度均为N×10×32×32,其中N表示微表情数据集的样本数量。图6所示模型可训练参数设置如表2所示,空间注意力机制中卷积核大小为5×5,最大池化和平均池化大小为10×1×1。通道注意力机制中最大池化和平均池化大小为1×32×32,MLP包含2个全连接层,每一层都由2个神经元组成。实验中使用的激活函数除了图3、图5提到的Sigmoid和图6提到的Softmax之外,其余均为ReLU。模型训练时batch_size设置为8,epoch设置为50,使用的损失函数为SparseCategoricalCrossentropy。

表2 模型参数设置
4.4 实验结果与分析
本文在CASME Ⅱ、SMIC(HS)、SAMM、MEGC2019数据集上进行了实验,提取微表情数据集的光流特征和差分图像特征,送入图6所示的分类模型中对微表情进行识别。为了验证同时使用光流特征和差分图像特征的有效性,在图6所示模型结构不变的情况下,改变模型的输入特征图,即设置以下3组对比试验,分别是2路均为光流特征、2路均为差分图像序列特征和2路分别为光流特征和差分图像序列特征,实验结果如表3所示。可以看出,除了SMIC(HS)数据集上2种特征UF1略低于差分图像序列特征,其余情况下相比于单一特征,同时使用光流和差分特征在UAR和UF1上均有所提升。由此可知,在大多数情况下,相比于使用单一的特征,同时使用光流特征和差分图像序列特征对微表情识别的效果更好。
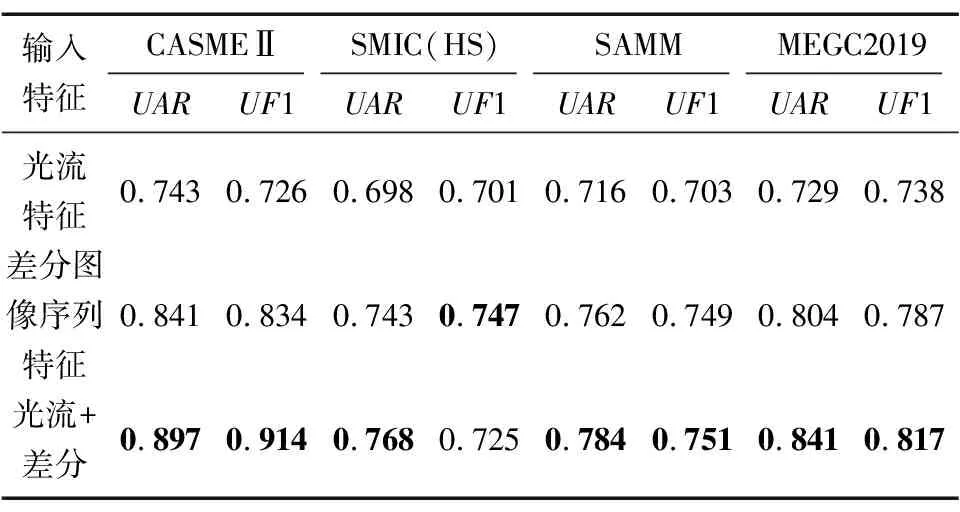
表3 不同特征在微表情分类模型下的识别率
为了验证本文提出模型的有效性,对图6所示的模型进行消融实验,在输入特征为光流特征和差分图像序列特征双路特征的情况下,将图6所示的模型进行拆分,并在CASMEⅡ、SMIC(HS)、SAMM、MEGC2019数据集上进行实验,实验结果如表4所示。相较于不使用注意力机制的情况下,仅使用空间注意力机制或仅使用通道注意力机制,在UAR和UF1上均有10%左右的提升,使用混合注意力机制又比使用单一的空间注意力机制或通道注意力机制在UAR和UF1上有3%左右的提升。根据表2所示的可训练参数设置可知,注意力机制所引入的可训练参数不到整体模型的0.1%,却对最终识别率带来了较大的提升,由此可知使用混合注意力机制对模型的提升效果较为明显。
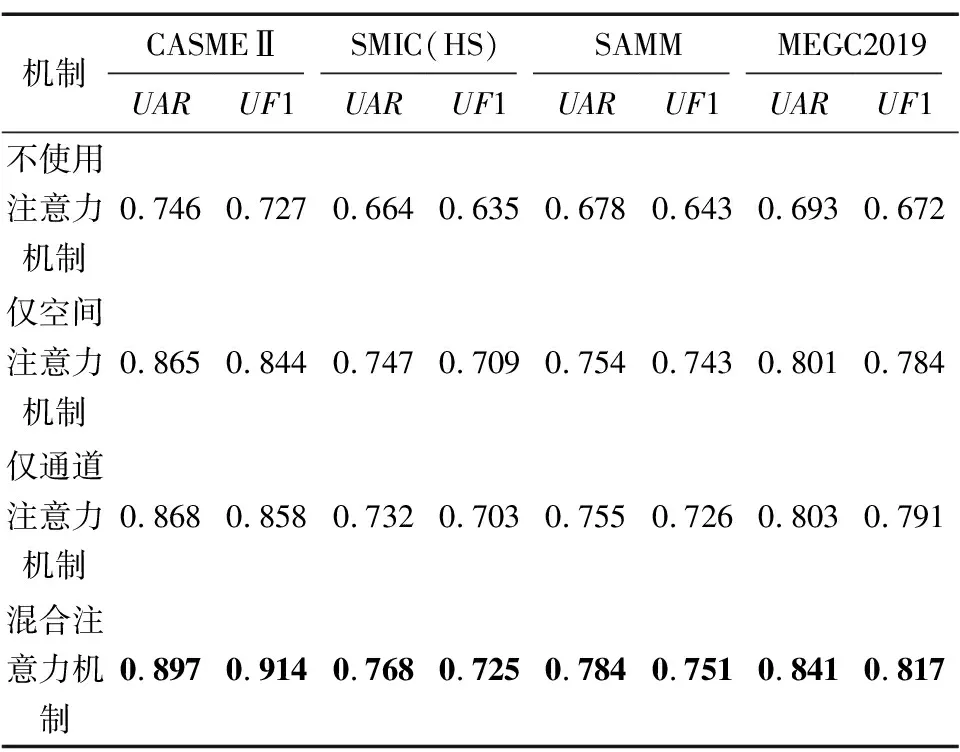
表4 消融实验结果对比
图7为CASME Ⅱ、SMIC(HS)、SAMM、MEGC2019数据集上的混淆矩阵表示。可以看出,在4个数据集上,对negative的识别率最高,而对positive和surprise的识别率则相对较低,并且在所有错误识别的样本中,大多数被误判为negative,这种现象是由于微表情数据集样本数量不均衡导致,其中negative的样本数量远大于positive和surprise。
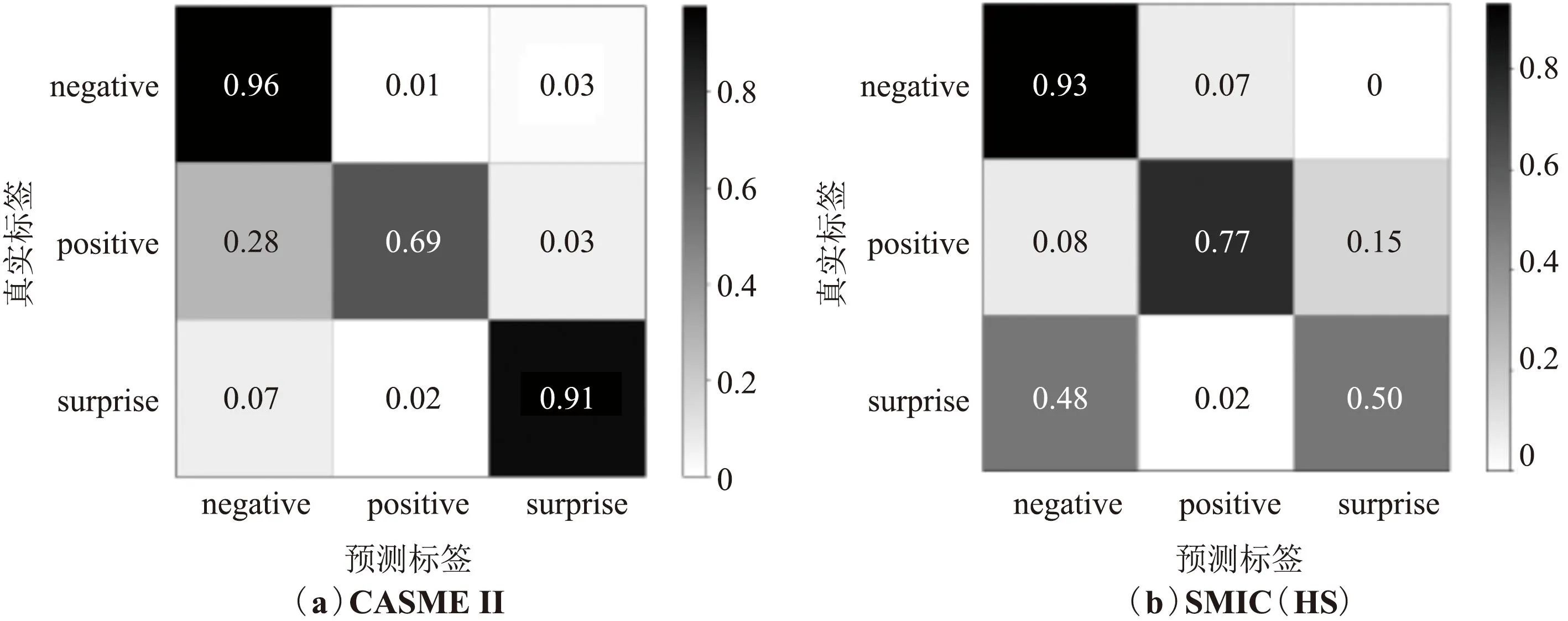
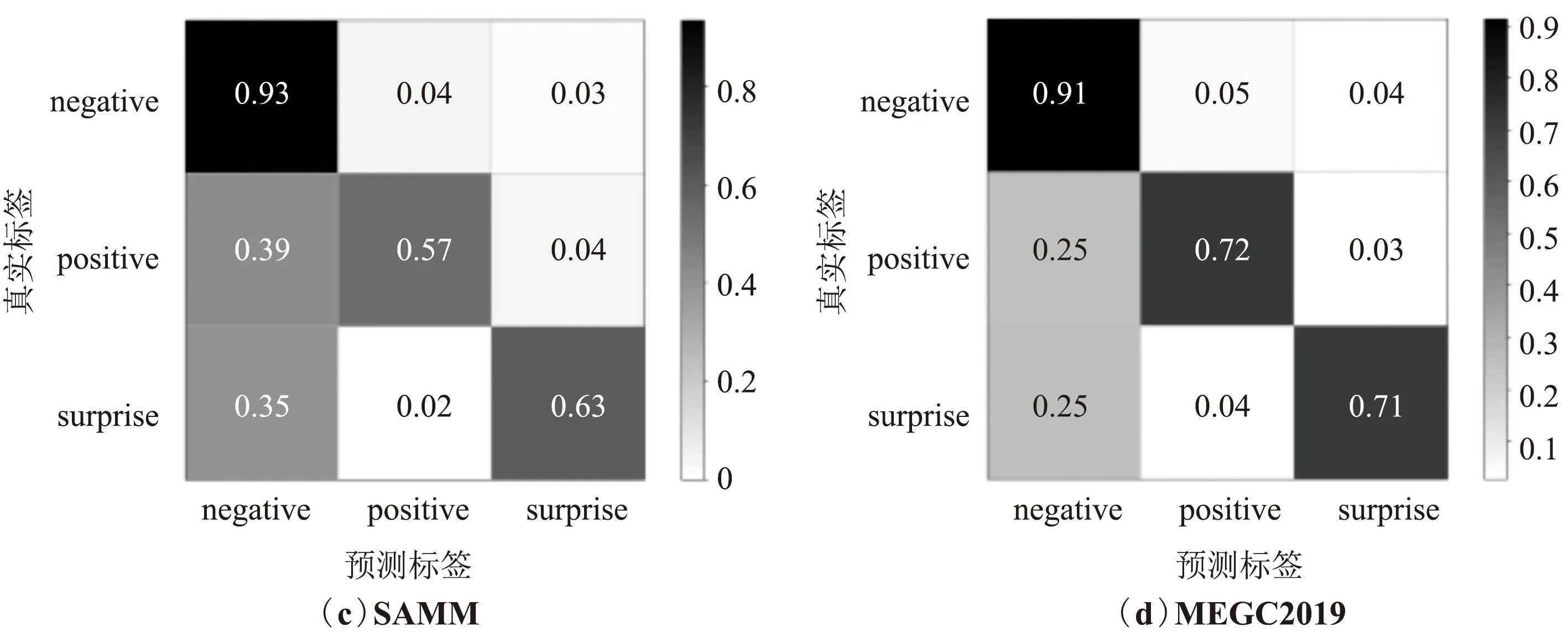
图7 CASMEⅡ、SMIC(HS)、SAMM和MEGC2019在混合注意力模型上的混淆矩阵Fig.7 Confusion matrix of CASMEⅡ, SMIC(HS), SAMM and MEGC2019 on mixed attention model
为了验证本文方法的有效性,将本文提出的方法与目前已有的微表情识别算法在CASMEⅡ、SMIC(HS)、SAMM、MEGC2019数据集上进行对比,结果如表5所示。可以看出,除了文献[17]所用方法在SMIC(HS)和SAMM数据集上UF1指标略高于本文方法之外,其余情况下本文方法均优于其余方法。这是因为文献[17]使用了深度卷积和自编码器,模型复杂度远远高于本文使用的模型,由此可知本文模型在训练效率远高于文献[17]使用方法的基础上,仅2个指标略低于文献[17]使用方法,其余情况下均高于文献[17]使用方法。相比于目前已有的微表情识别方法,本文提出的基于双路特征和混合注意力机制的微表情识别方法效果更好。
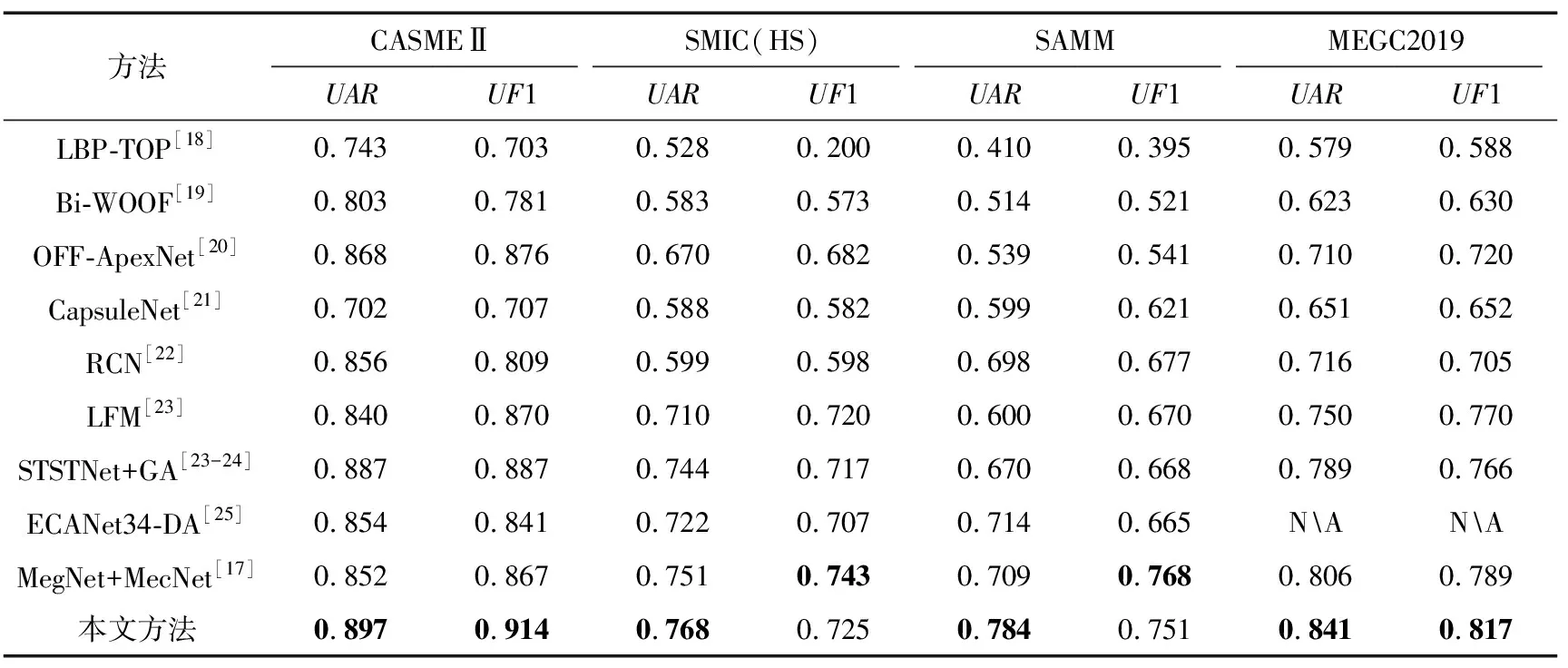
表5 本文方法与其他主流方法对比
5 结束语
本文提出了一种基于双路特征和混合注意力机制的微表情识别方法,针对微表情特征难以提取的问题,首先提出了同时使用光流特征和差分图像序列特征对微表情进行识别。由于微表情的动作具有持续时间短、幅度小的特点,寻常的分类模型难以准确地捕捉到关键信息,因此本文提出了一种改进的混合注意力机制的微表情分类模型,即同时使用空间注意力机制和通道注意力机制提取微表情的关键信息,并且在CASME Ⅱ、SMIC(HS)、SAMM、MEGC2019数据集上进行了实验,取得了较好的识别效果。虽然本文提出的方法取得了较好的识别效果,但是双路模型引入了较多的模型参数,整个流程的实时性难以得到保证。在今后的工作中,将尝试优化微表情分类模型,并且在保证不影响识别率的情况下,尽量减少网络输入特征的维度、提升微表情识别的效率,并将本文提出的微表情识别方法运用到微表情识别系统中。
