基于GPU的北斗B1宽带复合信号实时发生器设计
2024-03-05王子涵巴晓辉蔡伯根
王子涵, 巴晓辉,2,3,*, 姜 维,2,3, 蔡伯根, 王 剑,2,3, 文 韬,2,3
(1. 北京交通大学电子信息工程学院, 北京 100044; 2. 北京交通大学轨道交通控制与安全国家 重点实验室, 北京 100044; 3. 北京市电磁兼容与卫星导航工程技术研究中心, 北京 100044;4. 北京交通大学计算机与信息技术学院, 北京 100044)
0 引 言
随着北斗卫星导航系统的建成,北斗三代系统完成了从区域系统向全球系统的升级。为了保证信号的后续兼容,北斗三代卫星仍需要在B1频段发送传统的B1I信号[1]。此外,北斗三代的B1频段还新增了民用信号B1C,以提高系统的服务能力。为了节约卫星有效载荷资源和延长导航卫星的使用寿命,同一频段的信号应尽可能共用一条发射链路[2]。因此,B1频段的信号需要先组合成一个基带复合信号,然后通过共享载波进行广播。但由于传统的B1I信号和新型B1C信号的中心频率不同,以及北斗三号B1复合信号的恒定包络限制,北斗三号B1频段需要使用新的调制技术和复用技术,以满足系统的要求和性能[3]。
单边带复数二进制偏移载波(single-sideband complex binary offset carrier, SCBOC)是一种用于卫星导航的多路复用技术,是在二进制偏移载波(binary offset carrier, BOC)的基础上发展而来[4-6]。BOC调制将信号分为两个边带,具有抗干扰性强、良好的多径抑制能力等优点[7]。SCBOC采用单边带偏移二进载波调制,相较于BOC调制,调制信号只包含单边带的BOC信号分量。北斗-3 B1频段以SCBOC(14,2)调制作为多频复用技术,实现了与传统B1I信号二进制相移键控(binary phase shift keying,BPSK)(2)调制信号的向后兼容,以提高卫星导航系统的可靠性和兼容性[8-9]。
全球导航卫星系统(global navigation satellite system, GNSS)由地面控制部分、空间卫星星座和地面用户设备三部分组成[10]。其中,地面用户设备起到了至关重要的作用。高性能的接收机对于系统的正常运行非常重要,而卫星信号模拟器的开发和调试是高性能接收机研发的关键要素之一。相比于接收机直接接收真实卫星信号或者使用信号回放仪回放卫星信号,卫星信号模拟器可以按照用户的要求,模拟不同环境下的卫星信号,为接收机提供所需的测试环境[11]。此外,卫星导航也在军事领域得到了广泛的研究,如利用欺骗技术影响对方武器和设备的作战能力。生成高效的实时卫星信号是研究这些技术的基础,具有非常重要的意义[12-13]。
卫星信号模拟器由仿真控制软件和信号生成硬件组成,用以模拟和生成GNSS信号[14]。仿真控制软件负责配置载体运动轨迹和模拟场景,同时还能计算卫星的位置、速度等参数。信号生成硬件中,数字信号处理器(digital signal processing, DSP) 负责计算导航信息、状态参数和控制参数。信号通过现场可编程门阵列(field programmable gate array, FPGA)进行编码和直接序列扩频调制,生成数字中频信号,然后经由数模转换和上变频完成卫星信号的生成[15-16]。目前,市面上的卫星信号模拟器多基于FPGA进行设计,然而这种设计方法存在一些限制,如功能更改和拓展较为麻烦,对于后续新增的GNSS信号的支持也比较困难[17]。此外,由于FPGA的容量限制,支持多种信号的信号模拟器需要多张FPGA板卡。
近年来,基于软件定义的无线电(software defined radio, SDR)的GNSS模拟器逐渐受到重视[18]。采用计算机仿真模拟软件来代替DSP和FPGA生成数字中频信号,卫星通道的数量仅与计算机处理器的计算能力有关,避免了FPGA容量限制对卫星通道和信号种类的限制[19-21]。此外,由于整个信号处理过程在软件端完成,因此后续功能拓展也更加方便。但是,在需要多通道、高采样率卫星信号的场景下,普通的中央处理器(central processing unit, CPU)难以实时生成模拟的GNSS信号,因此采用图形处理器(graphics processing unit, GPU)加速以满足实时、多通道、高速率的GNSS信号模拟需求已成为很多人的选择[22-24]。
关于GPU生成卫星信号的算法,前人已经进行了一些研究。文献[25] 对利用GPU并行加速生成GNSS信号的方法进行了系统性的总结,并通过相同条件下比较CPU和CPU+GPU的运行时间充分体现了GPU对于GNSS信号加速生成的重要作用。文献[26]和文献[27]针对卫星中频信号的结构以及调制特点,设计并优化了程序的并行线程结构以及内存分配方式,利用GTX580实现了50 MHz采样率、8通道下全球定位系统(global positioning system,GPS) L1C/A中频信号的实时生成。文献[28]设计了一种数据结构,通过节约扩频码、导航电文的内存占用,加快数据访问速度,利用Quaro M5000实现了50 MHz采样率、16通道下北斗B1I信号的实时生成。文献[29]提出了一种基于统一计算设备架构流(compute unified device architecture stream, CUDA)技术的直接数字频率合成(direct digital frequency synthesizer, DDFS)加速算法。通过对计算任务的算法、数据结构、代码逻辑等方面进行优化,利用GTX285实现了58 MSPS采样率下卫星信号的实时模拟。但是,前人研究的对象多集中于GPS L1C/A、北斗B1I等传统信号体系,且优化的方向主要在程序并行线程结构、内存访问方式和数据存储方法等针对GPU执行部分,程序在执行核函数之外的命令时,仍然采取串行运行的方式,这造成了算力资源的浪费。因此,本文在继承前人并行线程结构、内存访问方式优化思想的基础上,提出了基于异步运算的加速采样点数据计算的CUDA优化计算方案,实现北斗B1宽带复合信号的生成。
本文阐述了一种SDR-GNSS信号模拟器的结构框架。该框架中,仿真控制软件基于本文提出的优化算法,构建基于“CPU+GPU”异构运算架构的中频信号生成算法,快速实时生成GNSS数字中频信号,并送入通用软件无线电设备(universal software radio peripheral, USRP)中。由USRP完成数模转换、正交校正、上变频,将数字中频信号转换为射频信号发射,模拟生成真实GNSS信号。由于中频信号的生成在软件端完成,整个系统具有很好的扩展性,方便测试和验证。
1 信号发生器体系结构
1.1 系统总体架构
信号模拟器由软件端和硬件端两个部分组成,如图1所示。软件端通过仿真控制软件实时控制、计算可见卫星的相关参数(如载波相位、伪码相位和信号幅度),并产生对应时间段的数字中频信号。信号经过高速数据传输接口传输信号到硬件端,硬件端对信号进行处理后通过射频前端发出,生成模拟GNSS信号。
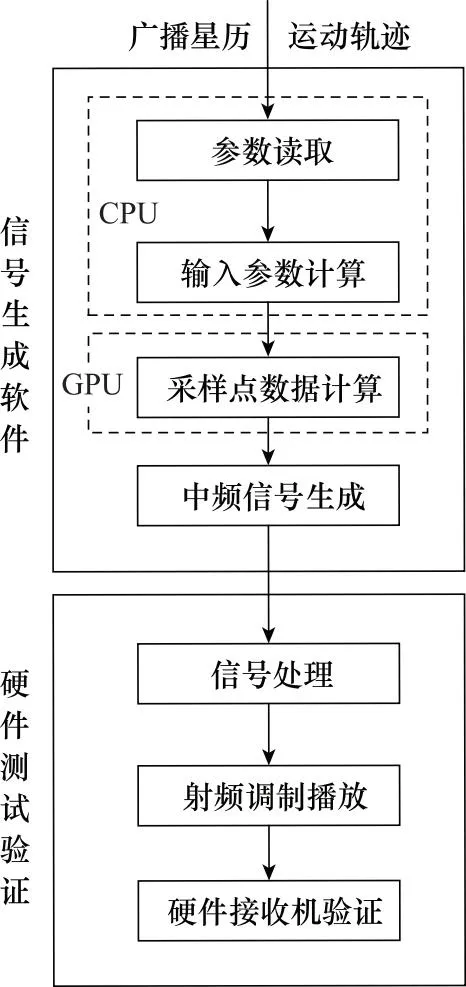
图1 GNSS信号模拟器体系结构Fig.1 Architecture of GNSS signal simulator system
1.2 中频信号结构
由于北斗B1I信号和B1C信号分别处于不同的频点,在一条发射链路中同时发射两种信号需要采用新的调制和复用技术。具体来说,B1C信号采用正交复用二进制偏移载波调制(quadrature multiplexed binary offset carrier,QMBOC)(6, 1, 1/11)调制,B1I信号采用SCBOC(14, 2)调制,以满足频谱约束,最后运用交调构建恒甩络复用(constant envelope multiplexing via intermodulation construction,CEMIC)技术[30-31]实现宽带恒包络信号的生成。北斗三代B1宽带复合信号基带表达式如下:

(1)
式中:SB1I(t)、SB1C_data(t)、SB1C_pilot(t)分别表示B1I信号分量以及B1C信号的数据分量和导频分量。本文以随机选择的码速率为2.046 MHz的Gold码序列代替SB1Q(t)。SB1I(t)、SB1C_data(t)和SB1C_pilot(t)的表达式如下所示:
sB1I(t)=cB1I(t)dB1I(t)
(2)
(3)
(4)
式中:dB1I(t)、dB1C(t)分别为B1I和B1C信号的导航电文;cB1I(t)、cB1C_data(t)、cB1C_pilot(t)分别为B1I信号的扩频码、B1C信号数据通道和导频通道的扩频码;scB1C_data(t)和scB1C_pilot(t)的表达式如下所示:
scBIC _data(t)=sign(sin(2πfsc,at))
(5)
(6)
式中:fsc,a=f0;fsc,b=6f0;f0=1.023 MHz为卫星信号的基准频率; sign(·)表示取符号函数,当x≥0时取1,当x<0时取-1。
副载波scd(t)和scp(t)的表达式分别为
(7)
(8)
式中:fs=7.161 MHz为副子载波频率。通过对scd(t)和scp(t)复子载波的幅度和相位进行改进,修正最终结果的幅度值,实现信号幅度的恒定。
1.3 中频信号产生
生成数字中频信号的方法是每次生成T时间(仿真步长)的数据。假设采样率为FS,每个仿真步长时间内生成的GNSS采样点的数量为N=FS·T。即为保证信号的实时生成,模拟器必须保证能在T时间内至少产生N个采样数据。
由第1.2节可知,中频信号的基本构成,中频信号产生必须得到B1I、B1C信号对应的扩频码、导航电文以及载波相位和码相位。扩频码和导航电文可以根据对应的接口控制文件(interface control document, ICD)和星历文件计算得到,中频信号产生的关键在于信号的码相位和载波相位的计算。本文通过一阶线性插值的方法得到对应信号的伪码和载波相位。采样数据生成过程如下。
(1) 多普勒频偏计算。根据卫星星历和设置的本地接收时间,通过迭代计算的方法得到卫星位置,算出卫星与用户之间的伪距,最后得到载波多普勒频偏:
(9)
(10)
式中:v表示所求的径向速度;r1和r0表示两个相邻时刻的伪距;dt表示两伪距的时间差,在这里等于仿真步长T;fdc表示载波的多普勒频移;c表示光速;fL1=1 575.42 MHz,为B1频点的载波频率。
B1I信号的码多普勒fdcode,B1I和子载波多普勒fdsc,B1I为
(11)
B1C信号的码多普勒fdB1C,code和子载波多普勒fdB1C,sc为
(12)
式中:fcode,B1I=2.046 MHz,fcode,B1C=1.023 MHz,分别为B1I信号和B1C信号的码频率;fB1I,sc、fsc,a和fsc,b分别为B1I信号和B1C信号的子载波频率,其中fsc,B1I=14.322 MHz,fsc,a=1.023 MHz,fsc,b=6.138 MHz。
(2) 确定伪码步进、载波步进和子载波步进。步进的计算方法是由伪码频率或中频载波频率除以信号采样率,得到每前进一个采样点对应码相位和载波相位的变化量,即码相位和载波相位的步进。计算过程如下所示:
(13)
(14)
(15)
式中:φSi、θSi和ΨSi为所求的码步进、载波步进和子载波步进;fc为中频载波频率;FS为采样率;fcode为扩频码的频率;fsc为子载波频率;fd,code和fd,sc为对应信号的码多普勒和子载波多普勒。
(3) 计算每颗被分配通道的可见星任意采样点时刻的伪码相位和载波相位,如下所示:
φi[k]=φFi+k·φSi
(16)
θi[k]=θFi+k·θSi
(17)
Ψi[k]=ΨFi+k·ΨSi
(18)
式中:φi[k]、θi[k]和Ψi[k]分别表示通道i卫星第k个采样点的码相位、载波相位以及子载波相位;φFi、θFi和ΨFi表示码相位、载波相位和子载波相位每个采样点之间的增长量。
2 GPU加速算法
2.1 异构运算架构
为了提高GPU的计算效率,本文通过划分各线程的计算任务以及优化线程内存访问速度两个方面对GPU程序进行优化。“CPU+GPU”异构运算架构下的中频信号各个采样点的计算过程如图2所示。
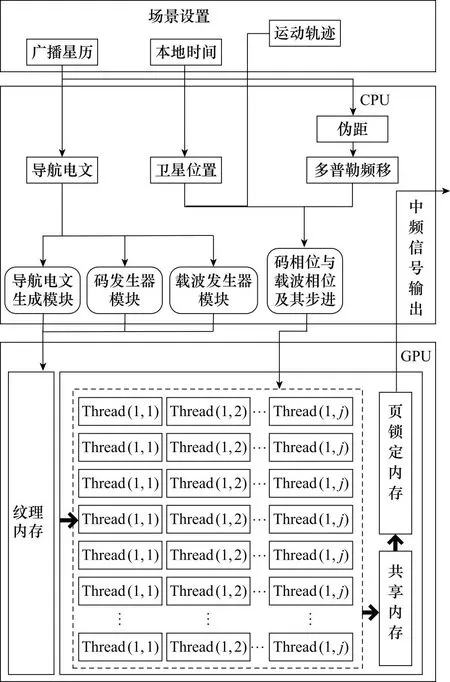
图2 软件并行运算架构Fig.2 Software parallel computing architecture
中频信号的生成过程可以划分为CPU运算和GPU运算两个部分:对于CPU运算部分,根据用户输入的广播星历和本地时间,通过迭代计算的方法得到每个T时间段起始时刻对应的精确发射时间、卫星位置和伪距。接着,根据卫星位置和用户位置计算初始载波相位,根据发射时间计算码相位,根据伪距和用户运动轨迹计算载波多普勒和码多普勒,得到载波步进和码步进。
对于GPU运算部分:将上述得到的B1I信号和B1C信号的码相位、载波相位及其步进送入线程中。然后,将扩频码、导航电文和正弦余弦表送入GPU的纹理内存,以便访问。接下来,线程根据获取的信息以及中频信号计算公式,计算出每个采样点对应的输出结果。最后,线程通过共享内存数据合并输出,并将结果传回到CPU的页锁定内存中,提供给射频端。
受限于GPU内存大小的限制,不可能通过调用一次GPU核函数完成全部中频信号采样点的计算,有必要对数据进行分块。理想情况下,每个采样点都会对应单独的传播时延,但若要单独计算每一个传播时延,这样对计算机的算力要求过大。考虑到在一个较短的时间T内,传播时延的变化量非常小,故可以认为T时间内的传播时延以及多普勒频偏保持不变,以此作为数据分块的依据。在T时间内,根据起始时刻的初始相位和步进,得到任意采样点中频信号的输出值。由此得到GPU并行计算模型,如图3所示。
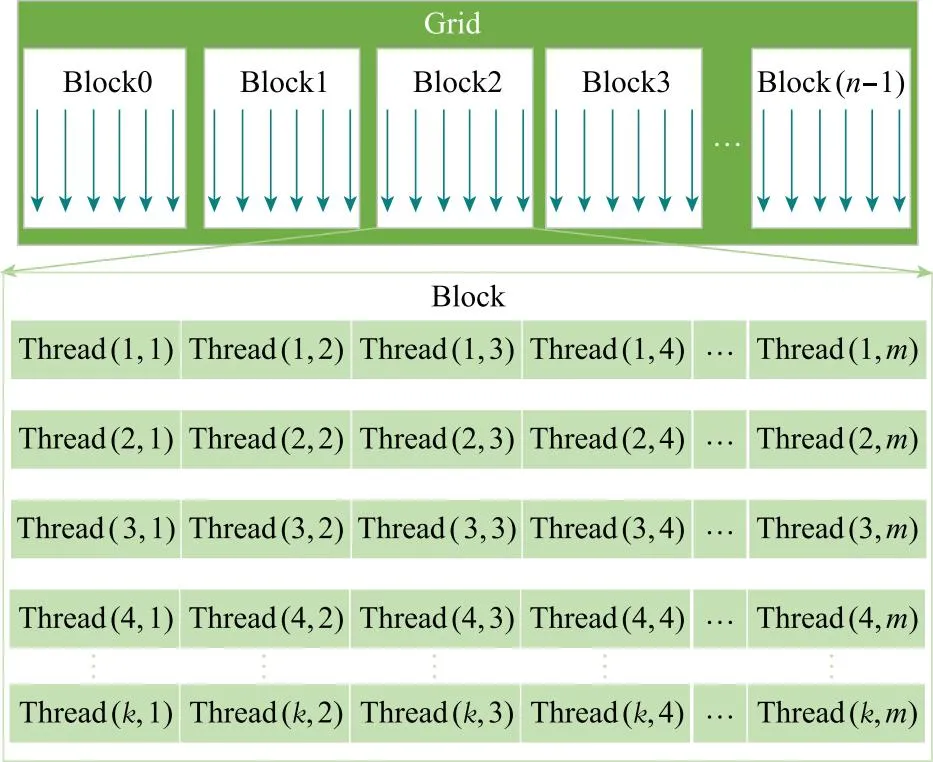
图3 GPU并行计算模型Fig.3 GPU parallel computing model
l、m、n分别表示单个block中线程的行数和列数以及所使用的线程块的个数,满足下列关系:
(19)
式中:l的值取决于可见星的数目,并决定单个线程块的行数;FS是信号采样率;T为信号仿真步长;m为单个线程块的列数;n为分配的线程块的数目,其值取决于FS、T和m。所述并行架构设计优化就在于对m的值进行设计。
2.2 并行线程架构设计
线程并行架构设计主要考虑以下两个方面。
(1) 确保使用了足够多的线程束,以及CUDA流多处理器(streaming multiprocessor, SM)没有进入空闲。SM可看作GPU的心脏,线程束是GPU并行计算的基本单元,一个线程束包含32个并行线程,这32个线程同时执行同一条指令,一个线程束中的线程必须在同一个block中。一个SM中,并不一定会一次性执行完线程束中的所有内容,这个时候就切换到别的线程束进行计算,由此可以避免等待的时间。理论上,当一个SM中有足够多的线程束进行切换时,就可以避免因为SM等待而造成的时间浪费。
(2) 基本上线程束分组的行为是由SM以连续的方式自行进行的,最后不足32的部分独立组成一个线程束,这可能会导致算力的浪费。所以系统应尽量确保block中使用的线程数量为32的整数倍,以节约计算机的运行资源。
2.3 内存结构优化
一般情况下,CPU与GPU各自的内存中的数据无法互相直接读取。将CPU内存称为主机内存,GPU内存称为设备内存,获取GPU计算结果需要经过如下步骤。
步骤 1从主机内存向到设备内存中传输数据。将T时刻对应的码相位、载波相位及其步进等输入信息传输到设备内存中。
步骤 2GPU内的各个线程并行执行核函数,而后将各个线程的计算结果合并,得到最终结果。
步骤 3从设备内存向主机内存传输数据。将各个采样点的输出结果由设备内存拷贝到主机内存中。
不同于CPU,GPU内有足够多的算术逻辑单元(arithmetic and logic unit, ALU),因此程序运行速度的快慢主要受到内存访问速度的影响,程序在步骤1~步骤3的内存读取过程中花费了大量时间。因此,程序优化的重点,在于针对上述问题进行优化。
页锁定主机内存也称为固定内存或不可分页内存。其优势在于操作系统不会对此内存进行分页以交换到磁盘,因此该内存不会被破坏或重新定位。相比之下,GPU在应用直接内存访问(direct memory access, DMA)技术与主机之间传输数据的过程中,主机可能会移动可分页数据,这会对DMA操作造成延迟。页锁定主机内存的性能比标准可分页内存的性能高出约2倍,通过使用页锁定内存完成步骤1和步骤3中的数据传输工作,可以显著提高程序的运行效率。
在中频信号的生成过程中,常会用到较长时间内不会发生改变的量,如导航电文、扩频码、正余弦表等。这些数据本身数量较多,直接访问所需的时间较长。本文采用纹理内存的方式对此类信息进行加速。
纹理内存是专门针对具有大量空间局部性内存访问模式的图形应用程序而设计的。具体来说,当线程读取的位置与周围线程的读取位置非常接近时,将设备内存绑定为纹理内存可以减少内存请求次数,提高内存带宽的利用效率。对于扩频码、导航电文等存在空间局部性的数据访问,纹理内存的特性非常契合,能够显著提升设备内存的访问速度。
此外,在步骤2线程计算和合并中频数据时,需要涉及线程内部的累乘和线程间的累加操作。线程内部的累乘操作可以快速完成,使用寄存器内存即可;线程间的累加则需要借由外部的设备内存完成,设备内存中可用于线程间通信的共有全局内存和共享内存两种。在一般情况下,可以选择全局内存,因为其空间充足,但访问延迟较高。然而,若进行线程间累加,共享内存是更好的选择。这是因为共享内存存放于片上,相比于全局内存,拥有较高的带宽和很低的延时,非常适合线程间累加的操作。图4为设备内存模型。
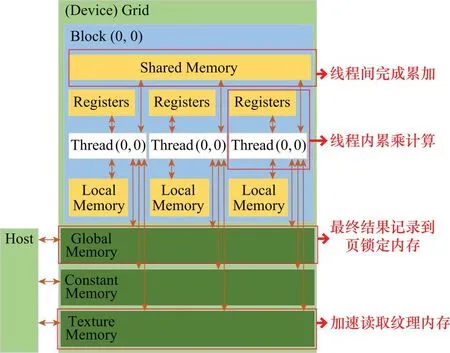
图4 GPU内存模型Fig.4 GPU memory model
2.4 CUDA流加速
CUDA流在加速程序方面扮演着重要的角色。每个CUDA流表示一个GPU操作队列,队列中的操作按照指定的顺序执行。系统可以在流中添加一些操作,例如核函数调用、内存复制以及事件的启动和结束等。每一个CUDA流的执行都可以视为GPU的一个任务,这些任务可以彼此异步的运行。将流视为有序的操作队列,其中包含有一个或多个内存复制引擎,以及一个核函数调用引擎,这些引擎彼此独立运行。CUDA程序按照操作顺序将代码调用到硬件上执行,图5说明了这种依赖关系,其中从核函数到复制操作的箭头表示,复制操作必须要等待核函数执行完成后才能开始。
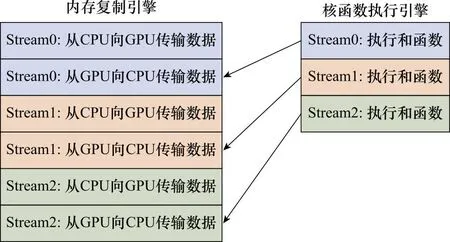
图5 CUDA流执行的依赖性Fig.5 Dependency of CUDA stream execution
因此,需要安排合理的队列顺序,特别是在同一个流中。为避免堵塞,另一个流的内存复制或核函数调用操作,CUDA流采用宽度优先的方式来调度所有操作。假设内存复制时间与核函数运行时间大致相当,程序的执行时间线如图6所示。

图6 CUDA流程序执行时间线Fig.6 Execution timeline of CUDA stream program
如果不做特别的处理,CUDA会默认只使用一个Default Stream,这会导致单个流的操作队列顺序必须严格执行,也就是说在执行内存复制操作时,核函数将进入等待,而在执行核函数调用时,内存复制引擎也将空闲,这会极大地造成资源的浪费。
CUDA流正是解决这类问题的重要工具,具有如下显著特性:① 数据传递和核函数调用可以在不同的流中同时进行。② 所有的流会在程序运行过程中同时启动,并由GPU来决定调用的顺序。
图7可以充分体现使用CUDA流加速带来的程序加速方面的好处。多个CUDA流可以使数据传输与计算并行执行,相比Default Stream状态下增加了相当多的数据吞吐量,对于大规模数据运算具有重要意义。
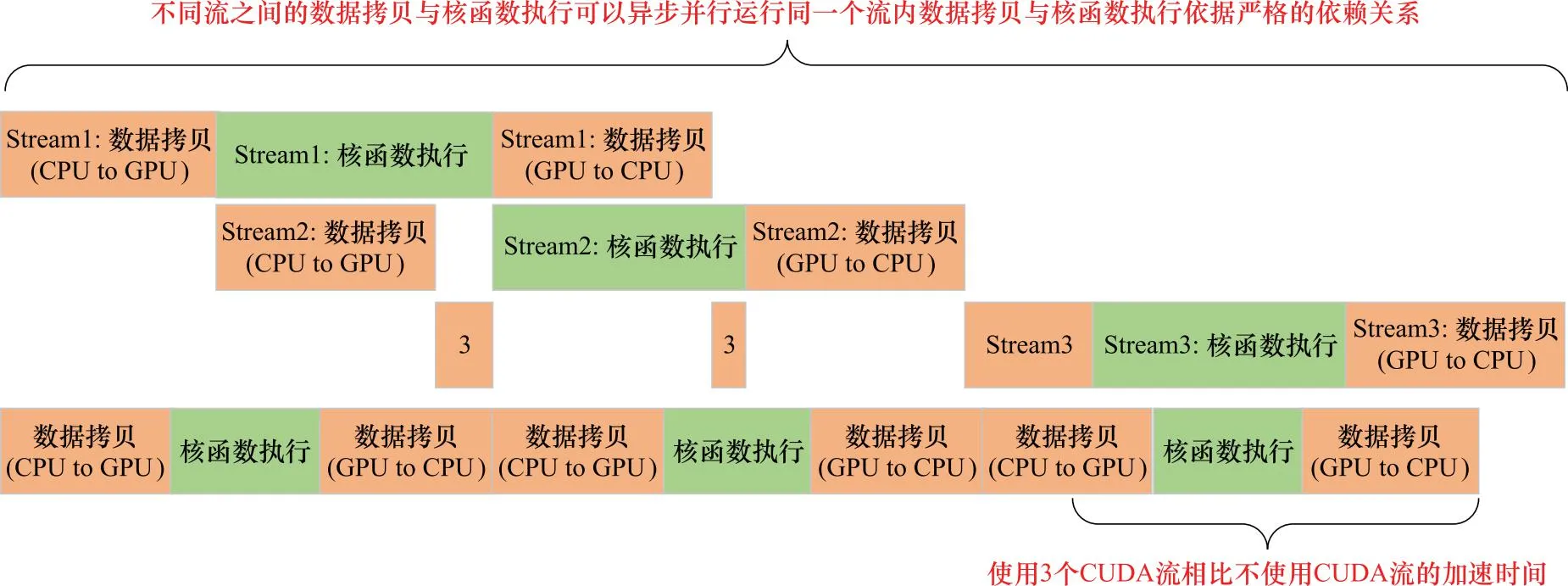
图7 CUDA流加速效果对比Fig.7 Comparison of CUDA stream acceleration effect
3 信号测试与验证
3.1 信号测试与验证流程
信号测试与验证流程如图8所示,系统根据用户的输入参数和配置文件,在“CPU+GPU”异构运算架构下实时生成卫星中频信号。然后,将信号通过USRP转化为射频信号发送,最后由软硬件接收机验证信号的正确性。
3.1.1 频谱图验证
对信号生成软件输出的中频信号值进行频谱分析,结果如图9所示。可以清晰看到B1I信号和B1C信号的频谱分量,频谱特性与理论值一致。
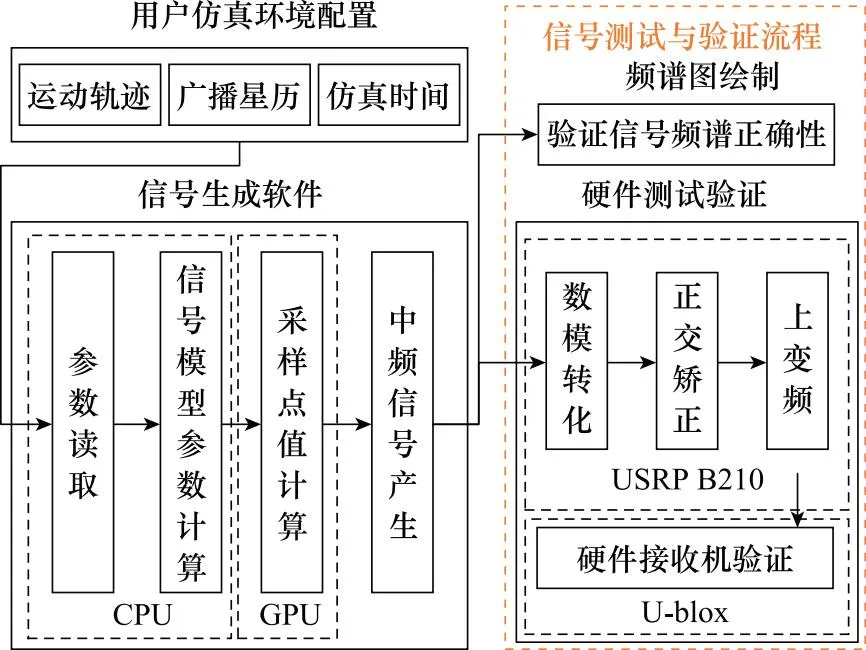
图8 信号测试与验证流程Fig.8 Signal testing and verification process

图9 中频信号频谱特性Fig.9 Spectrum characteristics of intermediate frequency signals
3.1.2 接收机验证
将USRP发射出的射频信号接到U-blox接收机中进行分析定位,验证生成信号的正确性,接收机定位结果示意图以及设备连接图如图10和图11所示。
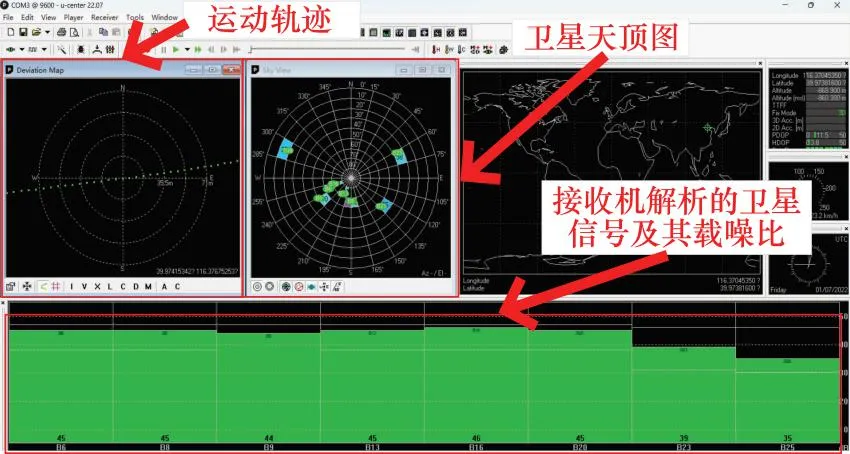
图10 接收机验证信号正确性Fig.10 Receiver verification of signal correctness
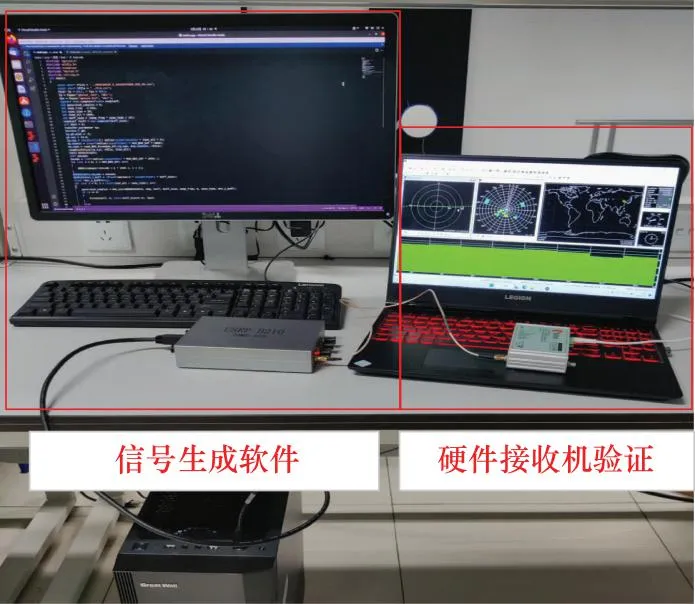
图11 接收机测试验证连线图Fig.11 Receiver test verification wiring schematic
运用软件接收机对6号和9号卫星B1I分量和B1C分量的载波多普勒频移值分别进行跟踪,结果如图12和图13所示。

图12 6号星载波多普勒跟踪结果Fig.12 Satellite carrier 6 Doppler tracking results

图13 9号星载波多普勒跟踪结果Fig.13 Satellite carrier 9 Doppler tracking results
测试结果表明,B1I分量和B1C分量信号多普勒频移的变化趋势一致,载波多普勒跟踪值的比值与B1I信号和B1C信号载波频率的比值一致。以9号星为例,t=1 s时刻,信号B1I分量载波多普勒跟踪值为452.1 Hz,B1C分量载波跟踪多普勒跟踪值为456.2 Hz,二者的比值等于B1I频点1 561.098 MHz与B1C频点1 575.42 MHz之比,由此确定载波多普勒频率结果符合理论值。
3.2 加速效果验证
本文使用CUDA架构作为开发平台,所采用的软硬件型号及性能参数如表1所示。

表1 硬件型号及性能参数Table 1 Hardware model and performance parameters
本节对第2节所提到的GPU程序优化加速方法的效果进行验证。图14是在8颗可见卫星的情况下,统计不同采样率下生成1 s卫星中频信号所需花费的时间;图15是在信号采样率为30 MHz时,统计不同可见星下生成1 s卫星中频信号所花费的时间。
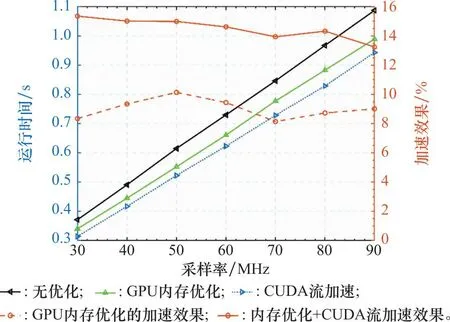
图14 不同采样率下的加速效果Fig.14 Acceleration effect at different sampling rates

图15 不同可见星下的加速效果Fig.15 Acceleration effect at different visible satellites
从图14和图15可以看出,针对信号采样率的不同,采用内存优化方法后,程序运行速度相比优化前提升约7%,在CUDA流加速+内存优化方法下,程序运行速度提升约13%。针对可见星数目的不同,在采用内存优化方法后,程序运行速度提升了5%,采用CUDA流加速+内存优化方法下,程序运行速度提升了10%。
此外,图15中程序优化效果的起伏波动较大,可能是因为可见星数目的变化影响了线程的并行结构,即第2.1节中的k值,针对设计程序并行架构对程序加速效果的影响如图16所示。实验条件为固定可见卫星的数量为8,信号采样率固定为30 MHz,记录m取值的不同对程序产生1 s中频信号所花费时间的影响。
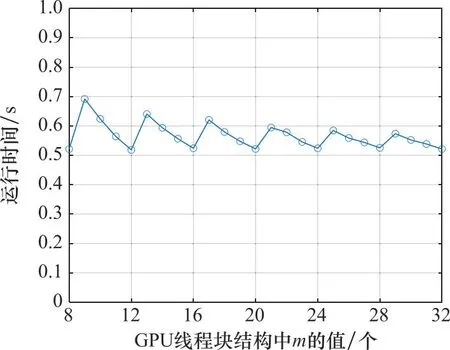
图16 线程架构对程序运行时间的影响Fig.16 Impact of thread architecture on program runtime
从图16可得,当m的值分别为8、12、16、20、24、28、32时,信号花费时间相比其他情况下更短,这是因为由于可见星的k值为8,当m取上述值时,单个线程块中线程的总数为32的倍数,从而使得每个线程束中的线程都得到了充分的利用。本文m取值16,是在综合考虑上述因素以及单个线程块最大线程个数的限制后的选择:如果取值更小,则更容易出现线程束的浪费;如果取值更大,则会限制最大可见星数量。
本文所涉及的信号生成加速方法已在GitHub上开源[32]。
4 结 论
本文设计了一种针对北斗B1宽带复合信号的实时生成方案,构建了基于“CPU+GPU”异构运算架构下的中频信号生成算法,实现了SCBOC调制下北斗-3 B1宽带复合中频信号的快速实时生成,并送到USRP中转换为射频信号播发。通过这种方式,实现了对真实卫星信号在地面情景下的精准实时复现,使用U-blox商用硬件接收机进行验证,证实了信号的正确性。此外,本文还提出了一种基于CUDA流异步运算的GPU加速方法,从线程并行架构设计、设备内存优化方案、CUDA流异步加速3个角度,加速卫星数字中频信号的计算过程,并通过实验验证了效果。实验结果表明,本文采用的加速方法可以使程序运行速度相比优化前提升约10%。
