基于联邦学习的船舶AIS 轨迹预测算法
2024-02-29郑晨俊曾艳袁俊峰张纪林王鑫韩猛
郑晨俊,曾艳,2*,袁俊峰,2,张纪林,2,3,王鑫,韩猛
(1.杭州电子科技大学计算机学院,浙江 杭州 310018;2.杭州电子科技大学复杂系统建模与仿真教育部重点实验室,浙江 杭州 310018;3.数据安全治理浙江省工程研究中心,浙江 杭州 310018;4.杭州电子科技大学圣光机联合学院,浙江 杭州 310018)
0 引言
随着全球经济的不断发展,国际贸易呈现快速增长的趋势。海上航运作为重要的国际贸易运输方式,面临着船舶数量不断增多所带来的海上交通和船舶安全问题。复杂多变的海上作业环境加上灾害天气下船舶需要实时改变航行轨迹的需求,导致实际航行轨迹偏离预设轨迹且无法预测,进一步影响了海上交通秩序并可能导致海事事故的发生。船舶自动识别系统(AIS)作为船舶航行信息的主要载体,提供了大量的数据用于轨迹预测。通过多层神经网络挖掘AIS 数据中蕴含的轨迹信息,分析船舶的活动规律和轨迹特征,实现精准预测航行过程,具有重要的研究意义,同时也能够为海上交通和海事监督提供可靠的技术支持。
目前,基于深度学习的船舶轨迹预测方法通常采用集中式训练策略,即将船舶终端收集的AIS 数据汇总至中央云服务器后进行统一训练。但这种传统的集中式训练策略面临以下问题:1)由于海上环境的恶劣和海上通信受限的情况,如无线电通信、卫星通信、计算机网络等多种低效通信方式,海上通信资源紧缺、可传输数据量小和通信代价大,不利于将船舶终端AIS 数据同步至云端进行集中式训练;2)出于隐私和行业规定等原因,不同数据源之间可能存在数据壁垒,从而形成数据孤岛问题;3)数据转移和集中训练过程中,数据安全问题无法得到保障,并伴随着数据使用的隐私泄露问题。由此可见,包括船舶轨迹预测在内的人工智能技术面临实际应用的巨大阻碍。
为了解决上述问题,Google 公司提出联邦学习技术[1],用于在不共享本地数据的前提下高效训练并挖掘数据的价值。联邦学习采用服务器-客户端架构进行机器学习,并在保持数据分散和独立性的同时,通过多个客户端在服务器的协调下共同训练同一个全局模型,比如FedAvg[1]、FedBoost[2]、FedProx[3]、SCAFFOLD[4]等联邦学习算法。
通常云端服务器具有较高的计算效率,而边缘设备具有低时延、轻计算的特点。传统集中式机器学习将数据集中到云服务器进行计算,为船舶轨迹预测任务提供了相对稳定的训练精度和训练速度,同时规避了数据异构性带来的影响,但海上弱通信环境无法满足其需要的高通信代价。
联邦学习利用边缘设备进行本地小样本训练,云端负责接收各客户端定期发回的模型,聚合完成后发回各边缘设备进行本地预测,减少传输压力的同时实现了云边协同[5],在不上传数据的情况下充分利用云边资源和网络资源。
目前,对于联邦学习下的船舶轨迹预测研究,通常假设船舶客户端数据为独立同分布(IID)数据场景,如文献[6]未考虑船舶客户端数据为非独立同分布(Non-IID)[7]的情况,而在实际情况下船舶客户端数据通常呈现Non-IID 分布。
针对Non-IID 场景,本文提出一种新的船舶轨迹预测算法(E-FVTP),使用联邦学习技术来解决船舶轨迹预测中的实际问题,主要贡献和创新点如下:
1)构建一种基于AIS 数据的卷积神经网络-门控循环单元(CNN-GRU)船舶轨迹预测模型,用于解决船舶终端设备计算能力不足的问题。该模型在联邦学习中具有高精度和高训练效率的特点,有效地解决了船舶终端设备实际落实训练的问题。
2)针对数据异构性,采用Fedves 联邦学习算法解决多船舶之间的数据孤岛问题,并优化本地模型训练过程,实现本地模型的稳定快速收敛,同时采用限制本地训练条件策略,减少本地模型更新通信轮数,优化服务器与客户端之间的通信压力,并减小不同采样率下Non-IID 数据特性对全局模型精度的影响。
3)在实际近海数据集下对E-FVTP 算法进行实验。实验结果表明,与传统集中式训练和联邦框架下的CNN-GRU 模型相比,E-FVTP 算法在保证全局精度与集中式训练基本持平的基础上,显著提升了本地模型训练的收敛速度,减少了服务器-客户端通信量,并且在不同客户端采样率下表现较为稳定,具有良好的拓展性。
1 相关工作
1.1 船舶轨迹预测模型
目前,船舶轨迹预测模型的研究已经积累了一定的成果,基本思路是利用船舶历史轨迹信息进行未来轨迹预测,主要的研究方法包括基于统计和船舶动力学方程的方法、基于聚类算法的方法以及基于深度学习算法的方法,其中,基于深度学习算法的方法是当前船舶轨迹数据挖掘的主流方法。
1)基于统计和船舶动力学方程的船舶轨迹预测。文献[8]利用自适应核密度估计框架,从历史AIS 数据中提取运动模式,并构建相应的运动异常检测器。文献[9]提出一种扩展卡尔曼滤波器(EKF),用于舰船状态估计和轨迹预测,并将智能特征集成到VTMIS 中。然而,这些方法均需要提前对船舶运动状态方程进行建模,由于海况的动态多样性,实时建模难度很大,因此不具有良好的拓展性和可用性。
2)基于聚类算法的船舶轨迹预测。相比传统基于统计和船舶动力学方程的方法,聚类方法的泛化性更强,能够在不需要先验知识的情况下根据不同的数据状况无监督训练得到轨迹预测结果。文献[10]综合考虑船舶轨迹的地理空间信息和背景特征,通过改进基于密度的聚类算法,实现对不同航线的轨迹自动分类,无需先验知识。文献[11]提出一种基于Hausdorff 距离和分层密度的带噪声空间聚类(HDBSCAN)的船舶AIS 轨迹聚类方法,利用船舶运动的形状特征进行聚类,具有良好的扩展性。文献[12]采用基于密度的噪声空间聚类算法(DBSCAN)对舰船轨迹模式进行分析,以制定新的船舶港口机动指南。需要注意的是:聚类方法仅将某船舶航行区域内的轨迹进行划分聚类,这与传统的轨迹预测不同,效果受限于现有区域内记录的轨迹,而且计算速度和最终预测效果仍需要进一步改善。
3)基于深度学习算法的船舶轨迹预测。相比上述两种方法,深度学习预测方法在计算开销和泛化效果上更为优秀,目前已被广泛应用于船舶轨迹预测问题。文献[13]采用长短期记忆(LSTM)网络进行轨迹实时预测,并运用遗传算法(GA)对超参数进行优化,提高预测精度和速度。文献[14]通过采用基于DBSCAN 算法推导的主轨迹,将门控循环单元(GRU)网络[15]应用于船舶轨迹实时预测并进行训练,在预测精度与LSTM 相近的情况下,该方法仍能提高计算效率。文献[16]采用CNN 的特征提取和分类能力,利用一系列功能层(如卷积层、最大池化层和全连接层)构建CNN-SMMC 架构,用于船舶运动分类,并取得了优秀的AIS 数据分类性能。需要注意的是:深度学习预测方法需要大量的训练数据和计算资源,因此在实际应用中需要考虑相应的资源成本。
目前,常见的深度学习预测模型主要由CNN、RNN 及多种基于这两类神经网络的变体组成。CNN 在提取时间序列数据的时序特征方面有不错的效果,且模型简单、易于训练。RNN 的两种变体LSTM 和GRU 也被广泛用于时间序列预测,其中,GRU 与LSTM 预测效果相近,但LSTM 存在明显的超参难以获得最优解的问题,导致训练过程复杂,且计算效率低于GRU。在实际船舶联邦环境中,由于船舶边缘计算能力有限,须考虑模型复杂度和计算效率方面的限制,因此本文提出一种基于CNN-GRU的船舶轨迹预测模型,利用CNN 挖掘AIS 数据的时序特征以及不同维度数据之间的关系,再通过GRU完成轨迹预测任务。CNN-GRU 模型相比单类型网络模型具有更高的精度,在控制计算效率和训练效率方面更具优势,同时提高了模型在弱边缘计算设备上的可训练性。
1.2 联邦学习
联邦学习是一种将数据存储在客户端设备上且在不上传源数据的前提下通过多个客户端联合训练全局模型的方法。在训练期间,客户端需要定期与中央服务器通信,交换本地模型和全局模型。由于不同客户端本地数据集的数据异构性,联邦学习客户端在模型训练中会产生不同程度的概念漂移[17],即预测轨迹的统计特性随时间发生变化的现象,从而降低了全局模型的收敛速度和精度。针对海上环境及船舶航行的多样性和复杂性,研究基于数据异构性的联邦学习并对相关工作进行分析。
文献[1]提出的FedAvg 算法是联邦学习的经典算法,它是一种基于平均模型更新的随机梯度下降方法。然而,由于FedAvg 算法没有针对数据异构性问题进行优化,导致在Non-IID 数据下实验效果不佳,因此需要在算法设计中考虑数据异构性,以提高联邦学习性能和效果。
针对数据异构性问题,学者们开展了大量研究工作。文献[3]提出FedProx 算法,该算法在FedAvg的基础上引入近端项,限制了本地模型训练时的偏移,同时引入不精确解,缓解了某些设备的计算压力。文献[4]提出的SCAFFOLD 算法使用控制变量来纠正客户端局部更新产生的偏移,从而提高模型精度,但也会增加通信代价和训练时间。文献[18]提出使用知识蒸馏法处理数据Non-IID 问题,服务器学习一个轻量级生成器以data-free 方式集成用户信息,指导用户使用学习到的知识作为“归纳偏置”来调节局部训练。文献[19]提出一种新的联邦学习个性化方法:聚类(多任务)联邦学习,将参数相似的节点划分为同一个节点簇,共享参数的变化量,以解决Non-IID 数据导致的局部最优问题。文献[20]针对非独立同分布数据提出一种联邦学习架构,将Non-IID 训练数据转换成多个独立同分布的数据子集,并计算从各类别数据中提取的特征对全局模型更新的权重,从而缓解训练数据不均衡的负面影响。文献[21]提出基于本地数据特征的公平性联邦学习模型,以解决训练数据分布不均衡情况下产生的聚合模型对各个客户端模型不公平的问题。文献[22]通过将全局模型与局部模型的排列交织在一起,减小Non-IID 对本地模型概念漂移的影响。文献[23]提出一种简单的算法(FedAlign),通过标准正则项方法有效克服数据异构性和以往方法的缺陷。文献[24]提出方差约简自私学习(VaRSeL),引导模型向内部客户端所青睐的方向更新,以克服传统联邦学习中某些客户端表现较差的问题。文献[25]提出一种平衡信息流的方法,通过平衡从初始模型和训练数据集到局部适应的信息流,在本地数据集异构的情况下,稳定训练高质量的个性化全局模型。文献[26]提出一种基于本地模型质量的客户端选择方法(ChFL),差异选择客户端进行本地训练并提高收敛速度。
上述研究从不同角度分析和改善数据异构性对联邦学习训练模型精度和效率的影响,但多数用于稳定全局模型的优化方法会增加整体负担。目前,多数联邦学习的研究均集中在图像分类、语义分析等领域,而在船舶轨迹预测背景下的联邦学习不仅要关注数据异构性问题,而且要权衡通信代价和计算效率。因此,在研究轨迹数据异构性的前提下,本文提出一种针对联邦学习框架的改进算法,在控制本地训练量的同时保持原有本地模型,添加近端项来控制极端情况下的本地自私化行为,实现本地和全局模型的同步个性化优化,有效解决了数据异构性问题,提高了模型训练精度和效率。
2 问题描述
船舶轨迹预测是指通过对历史的船舶运行数据进行分析来预测船舶未来的运动轨迹。船舶轨迹预测在海上交通管制、安全管理、环保控制、资源调配等领域具有重要的应用价值。通过船舶轨迹预测可以有效提高船舶交通的安全性,避免事故发生,同时通过对船舶的运动轨迹进行预测,可以优化海上资源调配,提高海运的效率和运营成本的可控性,减少资源浪费和环境污染。另外,船舶轨迹预测还可以为海上交通的规划和管制提供参考和决策支持。船舶轨迹预测是一项具有广泛应用前景和重要意义的技术,可以有效提高海上航运的安全性和效率。由于海上环境的多变性,船舶未来轨迹对海上交通统筹调控至关重要,由AIS 数据挖掘未来航线信息成为重要手段。同时,考虑到海上环境多变恶劣且通信条件差,通过传统集中式轨迹预测模型训练并不可行。因此,采用联邦学习与轨迹预测模型相结合处理上述问题。
2.1 船舶轨迹预测问题
船舶轨迹是船舶在港口间航行的路线,在实际场景中由于AIS 信息发送不连续,实际船舶轨迹信息由离散的轨迹点组成,轨迹T的定义如式(1)所示:
轨迹点信息包含船舶实时位置与航行状况,如对地航速和对地航向,轨迹点p的定义如式(2)所示:
其中:li是轨迹点的经度;bi是轨迹点的纬度;si和ci是轨迹点船舶的对地航速和对地航向;ti表示轨迹点的时间信息。
船舶轨迹预测问题是利用历史轨迹数据的特征预测未来时刻的轨迹信息,通过船舶轨迹可以定义轨迹预测模型,如式(3)所示:
其中:Pl,x表示前l个时刻的轨迹点作为输入预测的第x个轨迹点;f表示轨迹预测模型。
2.2 联邦学习下的船舶轨迹预测问题
在船舶轨迹预测问题中,将轨迹特征输入xi=(pi,pi+1,…,pi+l-1)和轨迹预测输出yi=pi+l分别构成特征空 间X=x1,x2,…,xn-l和特征 预测空 间Y=y1,y2,…,yn-l,其中,l表示预测特征长度,n表示原始轨迹点样本数。使用函数f作为特征空间到特征预测空间的映射函数(预测函数)。损失函数l(w)为时序预测中常用的均方误差损失函数,如式(4)所示:
其中:w是神经网络参数。将集中式学习的学习任务表示为式(5),并使用随机梯度下降法迭代求解神经网络参数w。
假设wt,(c)表示集中式学习设置下服务器第t轮更新的神经网络参数,η表示学习率,∇w表示在第t轮更新的模型参数。因此,集中式学习设置下的SGD 梯度更新如式(6)所示:
假设联邦学习系统中共有K个客户端,每个客户端在本地训练过程中单独进行SGD 梯度更新。nk表示客户端的本地训练数据集大小,wt,(k)表示客户端在第t轮SGD 梯度更新后的权重,如式(7)所示:
规定每经过E次全局SGD 迭代后进行一次同步处理,wmE,(f)表示第m次联邦聚合之后的全局模型,则全局模型wmE,(f)的聚合子式如式(8)所示:
其中:wmE,(k)表示客户端经历mE次迭代后的本地模型参数;表示客户端的模型聚合权重。在聚合完成后,服务器向所有客户端发送更新过的全局模型参数wmE,(f),客户端使用新的全局模型参数替换本地模型参数进行接下来的迭代过程。
3 基于联邦学习的船舶轨迹预测算法
首先,采用CNN-GRU 模型处理船舶轨迹预测问题,其中CNN、GRU 网络用于轨迹特征提取和长短时预测,在高精度的前提下保证较高的计算效率,适合船舶边缘计算性能有限背景下的计算任务。然后,为了管理船舶AIS 数据的处理和训练,采用Fedves 联邦学习框架用于统一客户端训练数据集规模,减少数据量不均衡特性,在Non-IID 数据特性下实现稳定全局的聚合效果。最后,在CNN-GRU 模型和Fedves 联邦学习框架的基础上提出E-FVTP 算法,该算法引入正则项对过大的客户端更新进行适当校正限制,从而降低局部概念漂移对全局精度的影响,显著提高船舶轨迹预测的准确性和效率。
3.1 CNN-GRU 模型
船舶航行轨迹是典型的时间序列数据,因此船舶轨迹预测也被定义为时间序列预测问题。针对该问题,提出基于CNN-GRU 轨迹预测模型,充分利用CNN 和GRU 的优势。CNN 是一种含有卷积过程和深度结构的前馈神经网络,具有局部连接、权重共享等特性,能够有效提取数据特征和短时特征,卷积运算过程可融合局部上下文信息,用于船舶时间序列的捕捉,显著改善模型精度和收敛速度。GRU 是RNN 网络的一种变体,具有处理较长时间序列的问题,并且能够在一定程度上避免传统RNN 产生的梯度消失和梯度爆炸问题。与RNN 的另一种变体LSTM 相比,GRU 在精度上与LSTM 基本持平的前提下,单元结构更加简单,训练效率更高。
CNN-GRU 船舶轨迹预测模型结构如图1 所示(彩色效果见《计算机工程》官网HTML 版,下同)。该模型结构主要由卷积神经网络和循环神经网络组成,包括双层一维CNN-ReLU、一个池化层、一个卷积特征处理结构(全连接层-ReLU-全连接层)、一个双层循环GRU 结构和一个单独的全连接层,其中:双层一维CNN-ReLU 用于初步提取高维数据特征、短时时序特征;池化层用于保存选择卷积层的特征;卷积特征处理结构用于将特征提取为GRU 输入;双层循环GRU 结构负责对子序列信息进行长短时特征处理预测;末尾的全连接层负责结果输出。

图1 CNN-GRU 船舶轨迹预测模型结构Fig.1 Structure of CNN-GRU ship trajectory prediction model
3.2 Fedves 联邦学习框架
Fedves 是一个针对船舶轨迹预测问题提出的联邦学习框架,允许不同参与方(搭载AIS 的船舶个体)在具有Non-IID 特征的AIS 轨迹数据集上进行训练,训练数据集存储在参与方的本地客户端上,在联邦学习过程中无需交换原始数据,只需进行中央云服务器与船舶终端之间的模型参数通信。
基于Fedves 的船舶轨迹预测整体方法如图2 所示,该方法包括中央云服务器、边缘计算设备、终端数据库、终端AIS,其中:中央云服务器在系统中负责全局通信协调,对各船舶终端模型更新状态监听,并获取更新过的本地模型,在聚合后覆盖更新终端模型;终端数据库负责存储本地AIS 数据;终端AIS在系统中负责终端的AIS 数据收集工作,收集并整理数据后发送至终端数据库进行存储;边缘计算设备(即船载微机)具有一定的计算能力和通信能力,负责客户端模型实际计算任务以及与中央云服务器的通信任务。

图2 基于Fedves 的船舶轨迹预测框架结构Fig.2 Structure of ship trajectory prediction framework based on Fedves
根据实际场景,以每艘船舶为单位作为联邦学习客户端,各终端AIS 获取的AIS 数据集相互独立,并且每个船舶终端实际航行产生的AIS 数据量不同,即各终端本地数据具有强Non-IID 特性。由式(8)可知,客户端参与训练的数据量相等时,各客户端pk相等,在聚合过程中全局模型对各个本地模型权重相等,聚合过程稳定度较好。考虑到船舶航行背景下各客户端的强独立性,为了满足高收敛速度与高模型精度的平衡需求,规定同时满足以下条件才进行本地模型训练:
1)终端数据库中存在长度为M的原始数据;
2)边缘计算设备已完成上一轮的本地模型训练;
3)本地模型已更新为中央云服务器下发的聚合过的全局模型。
在满足上述条件的情况下,基于Fedves 的船舶轨迹预测流程具体如下:
1)由终端AIS 收集原始AIS 数据并存入终端数据库;
2)终端数据库定时更新未训练的原始数据量,长度达到M后通知边缘计算设备取数据;
3)边缘计算设备满足训练条件后取终端数据库中的定长原始数据进行本地模型训练并上传参数至中央云服务器;
4)中央云服务器定时对各个边缘计算设备发回的本地模型参数进行聚合并下放;
5)边缘计算设备接收中央云服务器发回的参数并更新本地模型,重复步骤1)~步骤3)。
3.3 E-FVTP 算法实现
E-FVTP 算法基于CNN-GRU 模型与Fedves 联邦学习框架构建,主要包括客户端数据集划分、全局协调、客户端本地训练和服务器聚合模型。
1)客户端数据集划分:每艘船舶独占一个水上移动通信业务标识(MMSI)码,用MMSI 码对船舶进行编号,记di为船舶i的终端收集的航行数据,参与训练的数据集合为D={d1,d2,…,dm},并且子集之间满足条件∀di,dj∈D,len(di)=len(dj)。每个客户端数据相互独立,且按照相同比例划分训练集、评估集及测试集。
2)全局协调:规定全局轮数为E,每轮全局服务器随机选取c个(0 <c≤C,其中C为客户端数量)客户端参与训练,客户端模型训练结束后向服务端发送客户端号、数据量及更新过的本地模型参数。在本轮c个客户端全部训练结束后,对接收的所有客户端的本地模型参数进行处理,并聚合新的全局模型进行广播下放。
3)客户端本地训练:服务器选取指定客户端后客户端开始训练本地CNN-GRU 模型,每次训练随机从训练集中取,其中Di为客户端i分到的数据集)batch 的数据作为本轮本地训练的训练输入。本轮训练任务结束后,客户端向服务器发送客户端号、数据量及本地模型更新参数。
4)服务器聚合模型:服务器接收各客户端的客户端号、数据量及本地模型参数后,根据客户端i训练数据量ni,赋予各个本地模型参数权重pc,聚合过程如式(9)所示:
其中:m表示全局轮数(即全局模型迭代数);C为客户端数量;wm,(c)和wm,(f)分别表示第m轮客户端和服务器的 模型参 数;系数用 于判断客户端是否本轮进行过训练以及是否参与模型聚合。
E-FVTP 算法具体如下:

为了进一步提升模型精度,采用正则化方法[3]对局部更新做出有效规范和限制,如式(10)所示:
客户端不仅最小化本地模型Fk,而且使用局部求解器来近似最小化hk。
3.4 E-FVTP 算法复杂度分析
1)客户端本地训练复杂度
每个客户端在本地进行SGD 更新,复杂度与每轮更新的样本数量和模型参数的维度有关。假设每个客户端进行N轮迭代,客户端本地训练数据集的大小为k,则客户端本地迭代更新的时间复杂度为O(Nk)。
为防止本地模型参数更新过大,导致概念漂移,在客户端本地模型迭代更新一次后,对所有参数梯度更新进行一次正则化处理。假设模型参数规模为w,则本地正则化规范的时间复杂度为O(Nw)。
2)服务器聚合复杂度
对于本轮客户端更新过的模型,服务器根据客户端的模型聚合权重将各个更新过的模型参数进行聚合,假设每轮平均有m个客户端更新模型参数,则时间复杂度为O(mw)。
3)通信代价
客户端将本地模型参数、梯度更新等信息传输给中央服务器,每轮通信代价为O(mw)。
中央服务器完成聚合后,将聚合后的模型发送至所有客户端进行模型同步,假设共有c个客户端,则通信代价为O(cw)。
如表1 所示,E-FVTP 与FedProx 复杂 度相同,且仅在客户端训练复杂度上比FedAvg 高O(Nw),其他方面与FedAvg 相同,具有较低的复杂度。需要说明的是:客户端总数为c,每个客户端进行N轮迭代,客户端本地训练数据集的大小为k,每轮平均有m个客户端更新模型参数。

表1 联邦学习算法复杂度对比 Table 1 Comparison of complexity for federated learning algorithms
4 实验设计与分析
4.1 实验设置
4.1.1 实验环境
基于PyTorch 框架搭建深度学习模型。实验使用的系统版本为Ubuntu 18.04.4 LTS。其他实验环境详细配置如表2 和表3 所示。

表2 软件环境配置 Table 2 Software environment configuration

表3 硬件环境配置 Table 3 Hardware environment configuration
4.1.2 实验数据集
采用搜集的舟山海洋船舶航行AIS 数据集以及MarineCadastre 开源数据集来验证E-FVTP 算法的可行性。数据集遵循AIS 规范,包含大量的航行轨迹信息,原始数据包括MMSI 码、经纬度、对地航向、对地航速、时间戳、航行状态等维度的特征。舟山海洋船舶航行AIS 数据集包含522 000 条原始AIS 数据,其中每个MMSI 码对应1 000 条AIS 数据,且原始AIS 数据已经过数据清洗符合时序数据规范特征。MarineCadastre数据集包含2021年1月1日的1 048 576条原始AIS 数据,按照8∶1∶1 的比例划分为训练集、测试集和评估集。
4.1.3 数据划分与分片
假设舟山海洋船舶航行AIS 数据集D包含m个船舶终端的数据,且每艘船舶独占一个水上移动通信业务标识码,将数据集按MMSI 码划分D={d1,d2,…,dm},确保子数据集的Non-IID 特性。另外,子集满足∀di,dj∈D,len(di)=len(dj),保证di作为分片单位的分片大小相等。控制每个客户端分到相同数量的di,并按比例划分训练集、评估集及测试集,仿真实际船舶航行中各MMSI 码对应船舶之间互相独立的数据特性。
4.1.4 评估指标
实验任务为时间序列预测,对于时序预测任务可以通过计算误差对模型的最终效果进行度量。均方误差(MSE)是衡量时序预测模型的常用指标,定义如式(11)所示:
其中:y为样本对应的待预测特征;y为样本预测结果。
在联邦框架下,评估指标表示为各个客户端均方误差的平均值,定义如式(12)所示,MSE 值越大,表示实验误差越大,预测效果越差。
4.2 结果分析
在联邦学习背景下的船舶轨迹预测具有数据Non-IID 特性,相比于集中式训练船舶轨迹预测模型,模型精度、收敛速度以及训练效率有较大的优化空间。为了证明E-FVTP 算法的实际可行性,从模型精度、可拓展性和通信代价3 个角度对E-FVTP 进行对比实验验证。本节共设置了3 个实验:1)在集中式、FedAvg、FedProx 和SCAFFOLD 下训练CNN-GRU模型,与E-FVTP 进行对比实验,以验证使用E-FVTP在模型精度方面与集中式训练基本持平,并且模型精度与训练效果均优于一般联邦学习框架下的预测工作;2)通过改变每轮参与训练的客户端数量,分析不同采样率下的模型精度,以验证E-FVTP 面对不同采样情况的可拓展性;3)比较相同数据集下集中式、FedAvg、FedProx、SCAFFOLD 及E-FVTP 下的训练通信代价。
4.2.1 模型精度对比
在相同实验环境下,在舟山海洋船舶航行AIS数据集上对集中式、FedAvg、FedProx 和SCAFFOLD下训练的CNN-GRU 和E-FVTP 算法进行对比实验,分别记录训练过程中评估的模型损失值及训练时间,对两者的实验数据进行横向对比。在该实验中,客户端的本地训练轮数设为1,每轮选取2 个客户端参与全局模型的聚合,全局训练轮数设为100,集中式训练轮数也设为100,控制总轮数相同。E-FVTP的每个客户端分到一艘船舶的连续1 000 条数据作为训练数据,总共设置10 个客户端;集中式训练分到所有10 艘船舶的1 000×10 条数据作为数据集。在控制系统总输入相同及训练轮数相同的前提下,比较不同实验的预测误差和训练时间,其中联邦学习框架下的误差为全局误差。
分析图3、图4 和表4(其中最优指标值用加粗字体标示,下同)的实验结果可以得到:1)E-FVTP 每个客户端数据均具有Non-IID 性质,并且数据特征量仅为集中式训练的1/10,但精度和收敛速度均优于集中式训练,其中,预测误差降低40%左右,收敛速度提升了67%左右;2)E-FVTP 客户端选取随机且数据具有异构性,期间损失值产生微小波动,但总体相对稳定,未对全局损失值产生巨大影响;3)E-FVTP 每个客户端的数据集仅有集中式训练的1/10,但训练速度得到明显提升,说明在有通信代价的前提下,E-FVTP 训练相比于集中式训练更为高效;4)SCAFFOLD 由于控制变量的影响,在预测误差和收敛时间上表现非常不理想,均远低于集中式和其他联邦算法;5)由于正则项的限制,E-FVTP 全局训练前100 轮的损失值仅略微高于FedAvg,但收敛预测误差略优于FedAvg 和FedProx,并且收敛速度分别提高了50.0%和24.2%,说明E-FVTP 的正则项对指导模型找到最优参数具有重要作用,相比其他联邦算法更适合船舶轨迹预测任务。
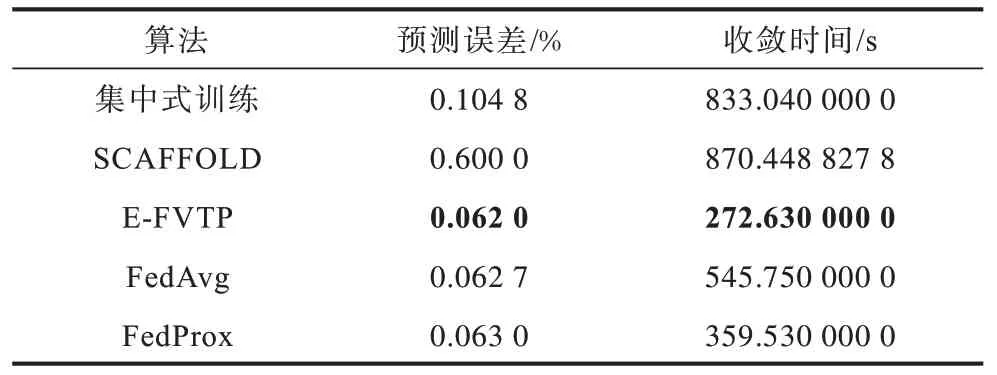
表4 不同训练算法的预测误差与收敛时间对比 Table 4 Comparison of prediction errors and convergence times of different training algorithms

图3 训练过程损失值对比Fig.3 Comparison of loss values during the training process

图4 训练时间对比Fig.4 Comparison of training times
4.2.2 采样率对比
本节选择采样率作为指标进行单指标实验。由于实际场景下面临采样率差异问题,为验证E-FVTP在不同场景下具有可拓展性和良好的性能,改变每轮参与训练的客户端数量以验证E-FVTP 对不同采样率的强适应性,E-FVTP 下的采样率为每轮参与训练的客户端数与客户端总数之比。
如图5 所示,对不同采样率下E-FVTP 的训练情况分析可以得出:1)在各采样率下,E-FVTP 均能在全局训练200 轮内完成收敛,并且不同采样率下的最终收敛预测误差几乎一致;2)当采样率较低时,收敛速度会在一定程度上受到影响。综上,E-FVTP 不依赖高采样率进行稳定高效的训练过程,能够在远低于全采样的训练时间内得到理想的CNN-GRU 预测模型。

图5 采样率对E-FVTP 训练的影响Fig.5 Impact of sampling rate on E-FVTP training
4.2.3 通信代价对比
模拟实际船舶预测环境下进行集中式、FedAvg、FedProx、SCAFFOLD、E-FVTP 训练,计算云边通信产生的通信代价,对比验证E-FVTP 在实际海上弱通信条件下的低通信资源占用特点。本部分的通信代价以训练过程中需要通信的模型参数或数据大小表示,集中式、SCAFFOLD 和E-FVTP 训练的全局训练轮数均设置为200,其中SCAFFOLD 和E-FVTP 每轮参与训练的客户端数量为2。
由表5 可以看出,E-FVTP 采取联邦学习方法,相对于集中式训练节约了76.32%通信量,并且相较于SCAFFOLD 训练节约了4.78%通信量,与FedAvg和FedProx 的通信量持平,验证了E-FVTP 相较于传统集中式训练在海洋交通管理上的可用性,相较于主流联邦学习算法具有更低的通信代价。

表5 全局训练通信量分析 Table 5 Analysis of communication volume for global training 单位:Byte
5 结束语
针对海上通信资源紧缺、数据样本量不足等造成船舶轨迹预测困难及事故频发的问题,提出一种新的船舶轨迹预测E-FVTP 算法。E-FVTP 算法使用联邦学习技术解决船舶轨迹预测中的实际问题,利用边缘设备进行本地小样本训练,云端负责接收各客户端定期发回的模型参数,在聚合完成后发回各边缘设备进行本地预测,减少传输压力的同时实现了云边协同。在舟山海洋船舶航行AIS 数据集和Marine Cadastre 开源数据集上的实验结果表明,相较于集中式训练,E-FVTP 算法在收敛速度、预测误差、通信代价方面均有很好的性能提升,为船舶轨迹预测技术的应用提供了一种可行的解决方案,并对联邦学习方法在该领域中的进一步研究提供了有价值的借鉴。后续将针对船舶预测及数据特征信息进行更深入的分析,进一步优化E-FVTP 算法。
