基于FPGA 的软硬件协同纠删码编码加速方案
2024-02-29杨思捷陈俊奇王勇李树林
杨思捷,陈俊奇,王勇*,李树林
(1.桂林电子科技大学计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学广西教育大数据与网络安全协同创新中心,广西 桂林 541004)
0 引言
近年来,随着互联网、云计算、云存储等技术的快速发展,全球信息数据规模巨大并呈现爆炸式增长,传统存储系统已无法满足大数据存储的功能和性能需求。在这样的背景下,催生了对于高数据读写性能、可靠性、可拓展性的系统的需求。分布式存储系统在大规模数据的存储和管理中已被广泛采用,例如Hadoop 分布式文件系统(HDFS)[1]、Swift 云存储系统[2]以及Ceph 分布式文件系统[3]。
在分布式存储系统中,由于存储设备故障、系统崩溃、自然灾害、网络故障等问题引起的节点失效进一步导致了大量的数据丢失。为了避免数据丢失,提高存储系统的可靠性,在分布式系统中一般采用两种冗余机制的数据容错技术,分别是副本容错技术[4]和纠删码容错技术[5]。副本容错技术基于复制机制,系统将节点上原始数据块复制到其他存储节点上,提高了数据的可用性。纠删码容错技术基于编码机制,通过将原始数据分割为k个数据块,然后对这些数据块编码得到m个校验块,当数据块丢失数量不超过m时,就可以从现有的数据块和校验块中恢复出原始数据。纠删码技术在提供与副本技术相同的容错能力的同时,能够显著降低存储开销。RS 类编码[6]作为目前使用最为广泛的纠删码算法,具有较好的空间利用率,与三副本技术相比,RS(14,10)在提高了1 倍容错能力的基础上,降低了53%的存储开销[7]。随着纠删码技术的发展,开源的纠删码库为人们提供了多种解决方案。Jerasure开源纠删码库[8]由C/C++语言编写,能够实现多种纠删码,包括RS 码、柯西RS 码[9]、LRC 码[10]等RS 类编码,在最新的Jerasure 2.0 版本中,提供面向对象的接口,增加了 更多纠 删码的实现,例 如RDP 码[11]、EVENODD 码[12]、Blaum-Roth 码[13]等阵列纠删码,支持多线程,在提高适用范围的同时提升了计算效率。
纠删码技术的高可靠性和相对较低的存储成本使其已经广泛应用于数据中心[14],但也在存储过程中带来了更多的计算开销和编码时延,若编码速率过低,则在编码过程中会发生数据丢失,原始数据块将面临无法恢复的风险。因此,纠删码的编码效率不仅影响存储系统性能,还会影响存储系统的可靠性。现场可编程门阵列(FPGA)[15]具有逻辑结构可定制、高速并行计算、片上缓冲大、调度灵活等特点,在加速纠删码[16-17]方面具有以下3 个优点:1)片上逻辑资源丰富,具有动态重构特性,可重复配置以减少硬件开销;2)通过流水线并行设计来提高计算编解码吞吐量;3)存储器访问带宽需求相对较低,有利于有效且充分地利用可用的存储器带宽。在高速网络通信中,FPGA 常用于实现低时延的前向纠错码编解码器[18],然而通过仿真实验验证了现有的基于FPGA 的纠删码存储加速方案在实际分布式存储系统中可能存在通信可靠性较低及难以处理较大数据块的问题。为减少纠删码编码时延、提升纠删码容错存储的性能和可靠性,本文设计基于FPGA 的分布式存储系统纠删码编码加速方案,并在实际的存储环境下进行了实验验证。本文主要工作如下:
1)设计基于FPGA 的RS 码编码硬件加速架构,通过硬件描述语言实现RS(8,2)、RS(8,3)、RS(8,4)、RS(8,5)4 种容错能力的16×8 bit 并行RS 码编码器,通过优化纠删码算法模块的时序实现流水线处理,进一步提升编码速率。
2)拓展片外4 GB DDR3 存储器接口,当存储系统中需要编码的数据块较大时,可以利用其随机存取特性将数据块切分为更小的操作单位,便于编码器进行具体的数据计算,并且实现在上位机和FPGA之间的数据缓存管理,避免数据溢出,提升了数据通信的可靠性。
3)实现FPGA 与上位机的数据通信,在实际环境下通过了FPGA 的板级验证,并在不同规模数据量下进行实验测试。
1 相关工作
1.1 纠删码原理
本文主要关注RS 码,通常被表示为RS(k,m),其中,k表示原始数据块数量,m表示编码后生成的校验块数量,当数据发生丢失时可以通过任意k个数据块或校验块进行数据恢复,最大可以容忍m个数据块的丢失。给定原始数据集合D={D1,D2,…,Dk},Di表示第i个数据块(1≤i≤k),校验数据集合C={C1,C2,…,Cm},Cj表示第j个校验块(1≤j≤m),编码计算是一个定义在伽罗华域GF(2w)[19]上的矩阵点乘,如式(1)所示:
在一次编码过程中生成的所有数据块和校验块记为[D|C]T,称为条带,(k+m)×k阶的矩阵称为生成矩阵G,由m×k阶的编码矩阵A和k×k阶的单位矩阵E构成,记为G=[E|A]T,在RS 码中使用范德蒙德矩阵作为编码矩阵。伽罗华域是一种有限域,域内包含2w个元素,其中定义了一种不可约的特殊多项式,称为本原多项式P(x),通过构建对数/反对数索引表的方法简化有限域上的乘法运算,如式(2)所示:
其中:gflog 和gfilog 分别表示伽罗华域上的对数函数和反对数函数。反对数表和对数表的构建如式(3)和式(4)所示:
当条带中丢失任意m个块时,只需选取任意k个幸存的数据块或校验块组成一个新集合Ds,同时将集合Ds中元素所对应的生成矩阵G中的行向量重组为一个k×k阶的矩阵Gs,如式(5)所示:
对矩阵Gs求逆G-1s并代入式(5)即可恢复原始数据,如式(6)所示:
1.2 纠删码加速优化研究
纠删码在实现数据冗余存储的过程中,分布式存储系统的性能主要面临来自网络资源消耗、编解码计算效率、磁盘I/O 吞吐量3 个方面的挑战。在存储设备内部,计算效率是影响存储性能的主要因素,计算复杂性主要来源于编解码过程中大量有限域上的矩阵乘法运算。为提升计算效率,研究人员提出在CPU、GPU、FPGA 等不同架构下的纠删码优化加速方案。CHEN 等[20]设计一种基于多核CPU 的纠删码软件(parEC),通过实现并行运算,显著提升了纠删码的计算吞吐量。孙黎等[21]通过优化HRC 码算法,提出了HRC 偏移重复码,与三副本技术和S2-RAID 纠删码相比提升了容错性能,降低了修复开销。LIU 等[22]利用GPU 的并行处理、矢量运算等特性,提出一种基于GPU 的纠删码库(GCRS),相比于Jerasure 开源纠删码库编解码速率提升了10 倍。许佳豪[23]设计一种基于GPU 的LRC 编码优化方案,采用异或编码思想,直接对数据块进行移位变换和异或运算,相比于GCRS 库性能提升了3%~5%。CHEN等[24]分别在CPU、GPU、FPGA 和APU 架构下实现了基于OpenCL 的伽罗华域GF(28)纠删码实现方案,针对每种架构的特点提出不同的算法优化策略,通过实验比较不同架构下的加速效果,实验结果表明FPGA 性能优越且相对成本较低。王先鹏[25]利用Xilinx HLS 工具实现对4 种RS 码进行编解码加速,设计基于FPGA 的多速率RS 码编解码器,采用矩阵预处理的思想,将编解码矩阵预先存储在FPGA 的片上ROM 中,从而减少了纠删码编解码过程中构造矩阵所带来的时延,并通过仿真验证其计算功能和效率,结果表明其能有效提高数据吞吐量。
在分布式存储系统中,作为存储单位的默认数据块一般比较大,比如在Hadoop 3.0[26]中默认块大小为128 MB,Ceph 的数据对象大小默认为4 MB。当这些数据对象被分为k个数据块Di时,如果直接对其进行RS(k,m)编码,需要构造一个大小为m×k×Dsize的 编码矩 阵,Dsize表示每 个数据 块Di的大小。Dsize越大,矩阵越大,用于运算的对数/反对数索引表也越大,会占用更多的内存,导致计算效率降低。因此,在实际的纠删码容错应用中,通常不会直接对数据块Di进行编码,而是将数据块Di切分为更小的单位,称为报文di,将报文作为数据编码的基本单位[27]。文献[24-25]分别使用FPGA 实现了细粒度为64 Byte 和1 Byte 的RS 码编码器,但忽略了对数据块缓存和切片操作,导致上位机和FPGA 间通信可靠性较低,并且要求上位机将数据块切分为更小的报文后再发送给FPGA,难以满足分布式存储系统的纠删码容错需求。本文的目标是通过拓展FPGA片外存储器接口,实现数据缓存和数据块切片功能,利用FPGA 加速RS 码编码计算,从而提升数据写入吞吐量。
2 基于FPGA 的软硬件协同RS 码编码加速
为了提升基于纠删码容错机制的分布式存储系统性能,本文提出一种基于FPGA 的软硬件协同RS码编码加速方案。首先,对FPGA 进行模块化设计,实现对数据的接收、缓存、处理和发送;然后,设计RS 码编码器,利用对数/反对数索引表简化矩阵乘法运算;最后,通过对RS 编码器的并行化处理和时序优化提升数据吞吐量。
2.1 基于FPGA 的RS 码编码硬件加速架构
基于FPGA 设计的RS 码编码硬件加速架构如图1 所示。在FPGA 中设计4 个主要模块:1)数据通信模块,该模块包含物理层和链路层;2)数据接收/发送模块;3)用户模块,该模块包含数据解析、纠删码算法、数据封装3 个子模块;4)DDR3 接口模块。
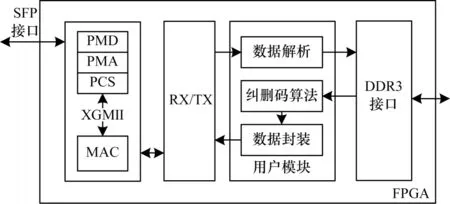
图1 基于FPGA 的RS 码编码硬件加速架构Fig.1 FPGA-based hardware acceleration architecture of RS code encoding
FPGA 外部提供SFP 接口,支 持10 Gb/s 速率 通信,上位机可以通过万兆以太网接口与FPGA 实现数据通信。在该架构中,纠删码算法模块用200 MHz 时钟驱动,DDR3 接口的时钟为双沿800 MHz 时钟,DDR3 内部存储阵列系统时钟为200 MHz,其余模块的驱动用户时钟为156.25 MHz。在数据通信模块中,物理层包括PMD、PMA、PCS 三层结构,PMD 层实现物理连接。PMA 层将PMD 层传来的串行差分数据进行时钟恢复,转化为66 bit 的并行数据,如果数据来自PCS 层,则将66 bit 并行数据转化为串行差分数据。PCS 层主要功能为实现64/66 bit 信道编解码,MAC 核与PCS 层之间通过XGMII 接口传输数据。MAC 核将下层数据去掉前导码、起始符和帧校验序列,转为MAC 帧后发送到更上层,对于来自上层的数据则增加前导码、起始符,计算帧校验序列。在数据接收/发送模块中,根据AXIS 总线时序,在数据接收时将来自数据通信模块的两个时钟周期的64 bit 数据合并成128 bit 数据后,增加起始符、有效标识符后发送到用户模块。用户模块首先解析数据包,去掉数据报文头部后只保留数据部分,通过DDR3 接口存入DDR3 中。纠删码算法模块从DDR3 通过地址索引获取数据进行RS 码编码。数据封装模块对编码完成的数据添加数据报文头部后发送给数据接收/发送模块。
2.2 并行RS 码编码器设计
通过硬件描述语言Verilog HDL 实现对RS(8,2)、RS(8,3)、RS(8,4)、RS(8,5)4 种RS 码的编码计算进行硬件加速。图2 为RS 码编码器框架以及主要信号,编码器中所有相关运算定义在GF(28)内,本原多项式P(x)=x8+x4+x3+x2+1,根据P(x)生成512 Byte的对数/反对数索引表,存储一个大小为16~40 Byte的编码矩阵,矩阵大小由RS(k,m)中的参数k和m决定,使用200 MHz 时钟驱动,数据报文位宽为8 bit。

图2 RS 码编码器框架Fig.2 Framework of RS code encoder
在数据编码过程中,8 bit 位宽的原始数据报文输入RS 编码器,同时拉高输入有效信号,当最后一个数据报文即第k个报文输入时,拉高输入数据尾部标识信号。在输入完成后,原始数据报文和编码矩阵进行有限域上的矩阵乘法运算得到编码数据报文,其中包括查表操作和异或运算,需要3 个时钟周期。在计算完成后,编码器开始输出编码报文条带,同时拉高输出有效信号,当最后一个编码报文即第k+m个编码报文输出时,拉高输出数据尾部标识信号。整个编码流程需要消耗k+m+3 个时钟周期,即(k+m+3)×5 ns。
在该框架下,1 个时钟周期内只能处理1 Byte 数据,吞吐量较低,难以满足分布式存储系统对纠删码容错的高性能需求。因此,在本文设计的纠删码算法模块中实例化了16 个这样的RS 码编码器,通过并行化处理,使其在1 个时钟周期内的数据处理量达到16 Byte,并且优化了接口时序,从而提升了数据吞吐量。图3 为纠删码算法模块实现RS(8,4)编码的主要接口时序图。模块用2 个时钟周期从DDR3 中读取8个大小为16 Byte 的原始数据报文,记录为di(1≤i≤8),对应的接口信号为DDR2AL_data;数据报文di依次输入RS 编码器,对应信号接口为RS_input_data,最后一个数据报文d8输入编码器后开始计算校验报文cj(1≤j≤4);编码器输出接口RS_output_data 从数据报文输入3 个时钟周期后开始输出报文条带,既确保了每个校验报文计算所需的时延,又提升了编码效率;AL2FIFO_data 表示纠删码算法模块向数据封装模块发送数据的接口,模块之间定义了一个异步FIFO 用于跨时钟域数据传输,RS 编码器输出第1 个校验报文c1,经过1 个时钟周期后算法模块向数据封装模块 发送数 据;RS_input_valid、RS_input_last、RS_output_valid 和RS_output_last 分别对应编码器输入有效、编码器输入尾部标识、编码器输出有效和编码器输出尾部标识,均为高电平有效。总流程耗时18 个时钟周期,编码流程耗时15 个时钟周期。
2.3 基于FPGA 的RS 码编码加速实现
FPGA 作为加速RS 码编码的外部硬件设备需要与上位机进行数据通信,采用万兆以太网实现FPGA与上位机的通信,传输层协议为UDP 通信协议。为了能有效获取上位机下发的数据块信息并支持FPGA 计算,对数据信息格式进行设计,其中主要包括MAC 帧首部、IP 首部、UDP 首部和数据字段大小。FPGA 接口对应的MAC 地址为58∶69∶6C∶69∶6E∶78,IP 地址为192.168.1.101。数据字段大小规定为128~1 408 Byte,且为128 Byte(8 个原始数据报文)的整数倍。
在上节中实现了基于FPGA 的RS 码硬件加速算法,每个用于编码的数据报文大小为16 Byte。为了满足分布式存储系统中数据对象的编码需求,需要在FPGA 和上位机之间增加一个缓存结构,将接收到的数据块Di进一步划分为大小为16 Byte 的数据报文di。拓展片外4 GB DDR3 接口用于实现数据缓存和数据块分片,地址结构如图4 所示,其中高3 位[28∶26]被分配为列地址,每一列对应一个数据块Di,低26 位[25∶0]被分配为行地址,在这个存储阵列中,每个存储单元可以存储8 Byte 数据。由于DDR3 接口模块采用双沿800 MHz 时钟,因此在200 MHz 的时钟下存取128 Byte 数据即8 个用于编码的数据报文只需要2 个时钟周期。

图4 DDR3 地址结构Fig.4 DDR3 address structure
图5 为基于FPGA 的RS 码编码加速架构下的RS(8,4)编码过程,主要步骤如下:
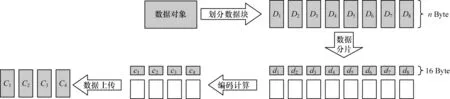
图5 RS(8,4)编码过程Fig.5 RS(8,4)encoding process
步骤1上位机将数据对象划分为8 个数据块,每个数据块大小相等,为nByte,构成的数据块集合定义为D={D1,D2,…,D8},按顺序通过万兆以太网接口并以上文规定的数据包格式发送给FPGA。
步骤2FPGA 通过光纤接收到数据信号后,经过数据通信模块和数据接收模块的处理,串行差分数据信号被转化为128 bit 并行数据后传入用户模块中的数据解析模块。
步骤3数据解析模块去掉UDP 数据包首部,只保留数据字段,通过DDR3 接口模块存入DDR3,其中数据块序号对应列地址,例如D1对应的列地址为000。
步骤4当所有的数据块都存入DDR3 后,纠删码算法模块通过DDR3 接口模块从DDR3 的存储阵列中按行地址读取数据,一次读取128 Byte,分为8 个数据报文,每个报文大小为16 Byte,构成的数据报文集合定义为d={d1,d2,…,d8}。
步骤5算法对数据报文集合d进行编码运算,计算出4 个校验报文,构成校验报文的集合定义为c={c1,c2,c3,c4}。
步骤6纠删码算法模块将校验报文集合c放入纠删码算法模块与数据封装模块之间的FIFO 暂存,每当FIFO 中存储的校验报文集合达到11 个即704 Byte 时,将数据封装为UDP 数据包传输给数据发送模块。
步骤7判断编码算法是否已经执行次,若是则进入步骤8,否则回到步骤4。
步骤8判断FIFO 是否为空,若是则直接进入步骤9,否则将FIFO 中的数据封装后传输到数据发送模块,进入步骤9。
步骤9数据发送模块和数据通信模块将UDP数据包恢复为串行差分数据信号后通过光纤发送给上位机,整个编码过程结束。
3 实验测试与分析
本节测试FPGA 对4 种容错能力不同的RS 码在不同数据量下的加速效果,主要关注编码速率vencoding和数据写入吞吐量vtotal2 个性能指标,计算公式分别如式(7)、式(8)所示:
其中:k表示原始数据块个数;n表示每个数据块的大小;tencoding表示数据编码时延,即原始块输入RS 编码器到最后一个校验块输出的耗时;tdownload为编码数据下载时延;twr为数据写入DDR3 的时延;trd为FPGA的算法模块从DDR3 读取数据的时延;tupload为数据上传时延。为了验证本次实验结果,将所提方案与Jerasure 2.0 开源纠删码库(记为Jerasure 2.0 方案)进行结果对比,实验结果显示所提方案表现更优,并且编码数据量越小,性能越好。
3.1 实验环境
实验硬件加速平台为Xilinx VC709 评估板,属于Xilinx 公司的Virtex-7 系列FPGA 开发板,该系列的芯片具有高集成度、强大的数据处理能力以及高可拓展性。表1 为实验硬件环境主要参数。

表1 实验硬件环境 Table 1 Experiment hardware environment
表2 为用于对照实验的Jerasure 2.0 开源纠删码库的软件实验环境主要参数。

表2 软件实验环境 Table 2 Software experiment environment
3.2 编码性能测试
选用编码速率vencoding和数据写入吞吐量vtotal作为比较纠删码编码性能是否优良的指标,作为对照实验的Jerasure 2.0 开源库的源码给出了这两个速率的计算方案,在对文件进行数据编码后可以直接得到。
所提方案通过Xilinx VC709 上的200 MHz 系统时钟来记录FPGA 执行数据下载、DDR3 读写、数据编码和数据上传消耗的时钟周期数,在编码完成后FPGA 向上位机发送1 个时钟周期数记录数据包,包结构如图6 所示,可以看出:数据下载和上传的时延最大,用32 bit 记 录;DDR 读写较 快,用16 bit 记录;编码算法用24 bit 记录;最后8 bit 暂作保留。

图6 时钟周期数记录数据包Fig.6 Clock cycle number recording data packet
通过式(9)可得到FPGA 执行每个操作的时延,其中,频率f=200 MHz,Tn表示时钟周期数,结合式(7)、式(8)计算编码速率和数据写入吞吐量。
实验测 试两种 方案对RS(8,2)、RS(8,3)、RS(8,4)、RS(8,5)4 种RS 编码模式在14 KB、140 KB、1 400 KB、14 MB、42 MB 5 种不同大小的测试文件上的加速效果,RS 码的各项参数设置如表3所示。

表3 RS 码参数设置 Table 3 RS code parameter setting
3.3 结果分析
Jerasure 2.0方案和所提方案在4种RS码的不同测试文件大小下的编码算法平均速率对比曲线图如图7所示,具体数据如表4 所示。由于所提方案的编码速率不随文件大小而改变,因此只用一条曲线表示。

表4 平均编码速率对比数据Table 4 Comparison data of average encoding rate 单位:(MB·s-1)
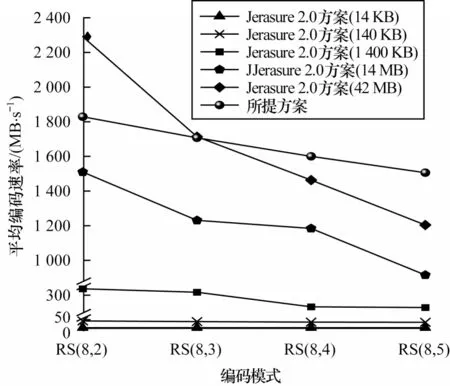
图7 平均编码速率对比曲线Fig.7 Comparison curve of average encoding rate
从测试结果可以发现,所提方案的编码速率相对恒定,文件的测试大小不会成为影响算法速率的因素,对于较小文件的编码有显著优势。与Jerasure 2.0方案相比,在横向上所提方案的算法速率随着RS 码校验块数量的增加而缓慢降低,在纵向上所提方案在大多数情况下为最优或与其相当,仅在编码模式为RS(8,2)时比Jerasure 2.0 方案(42 MB)略差。所提方案和Jerasure 2.0 方案(42 MB)在编码模式为RS(8,3)时产生了交叉节点,这是因为Jerasure 2.0 方案对大文件的编码能力较强,但是随着校验块数量的增加,计算生成矩阵和编码运算的复杂度随之增加,导致Jerasure 2.0 方案(42 MB)的编码性能曲线下降段的斜率较大,而所提方案在编码器中预存了生成矩阵,并且将编码运算的查表操作和异或运算均匀分配到每个用于计算的时钟周期,使得编码性能曲线下降段的斜率较小。
对于纠删码存储而言,除了编码算法层面的时间开销外,系统的I/O、矩阵生成、对文件划分操作等同样存在大量时间开销,对系统性能产生重要影响。图8为Jerasure 2.0 方案和所提方案对4 种RS 码在不同测试文件大小下的平均数据写入吞吐量对比。由图8可以看出,使用所提方案的纠删码编码的数据写入吞吐量提升了2.7~93.0 倍,并且Jerasure 2.0 方案在处理不同数据量时,数据写入吞吐量波动较大,当数据量较小时由于此时的系统I/O、矩阵生成和数据划分时间开销很大,导致系统运行速率明显降低,而所提方案在处理不同数据量时由于编码矩阵已经预先写入FPGA 的RAM 中,因此能够以较恒定的速率运行。
4 结束语
针对纠删码容错机制在分布式存储系统中存在编码时延高、数据吞吐量小的问题,本文提出一种基于FPGA 的RS 码编码加速方案。利用FPGA 实现高效的并行RS 码编码器,同时扩展DDR3 接口用于缓存管理和数据切片,并且在由上位机和FPGA 组成的纠删码编码硬件加速架构中进行了实验验证。实验结果表明,在不同规模的数据量下,所提方案相比Jerasure 2.0 开源纠删码库能够大幅度提升RS 码的编码速率与数据写入吞吐量,并且对于较小的文件具有更显著的性能提升。下一步将针对柯西RS 码的编解码优化展开研究,提升纠删码容错机制在数据写入和数据修复方面的综合性能。
