基于Transformer 和GAN 的对抗样本生成算法
2024-02-29刘帅威李智王国美张丽
刘帅威,李智,王国美,张丽
(贵州大学计算机科学与技术学院公共大数据国家重点实验室,贵州 贵阳 550025)
0 引言
深度神经网络在过去几年取得了巨大成功,并引起了学术界和产业界的广泛关注[1]。随着深度神经网络的快速发展和部署,其显露出的安全问题逐渐引起了社会的关注[2]。最近的研究发现,深度神经网络很容易受到对抗样本的影响,对抗样本通常是在合法样本上添加精心设计且难以察觉的扰动[3]。利用对抗样本可以让攻击者在很多应用场景中对人工智能模型本身发起攻击,从而造成难以估计的危害,例如:基于人脸识别技术的手机解锁系统可能存在安全漏洞[4],攻击者可以通过伪装等方式欺骗人脸解锁,从而进入他人手机;自动驾驶汽车的识别系统会被攻击者误导[5],可能导致交通事故;不法分子利用对抗样本欺骗计算机辅助诊断系统修改其医疗诊断记录,从而实施骗保行为[6]。研究更先进的对抗攻击算法能评估深度神经网络的鲁棒性,进一步揭露深度学习的安全漏洞,有助于开发人员对系统的运行进行维护,从而提高系统的安全性和稳定性。
现有的对抗攻击方法根据攻击方式的不同大致分为3 类:1)基于梯度的攻击;2)基于优化的攻击;3)基于生成式的攻击。文献[7]提出基于梯度的快速梯度符号法(FGSM),使用模型的梯度信息来计算对原始样本的扰动从而欺骗模型。文献[8]提出迭代式的投影梯度下降(PGD)攻击,在FGSM 的基础上引入多次迭代,并加入投影步骤来限制对抗样本的扰动大小,以提高攻击的效果和稳定性。文献[9]提出优化式的CW 攻击,通过最小化对抗样本与原始样本之间的距离来生成对抗样本。CW 攻击通过对模型输出的标签和置信度进行修改,使得模型更容易将对抗样本进行错误分类。
在基于生成式的攻击方法中:文献[10]提出AdvGAN 方法,其主要思想是训练一个生成器和一个鉴别器,使用生成器生成具有误导性的对抗样本,使用鉴别器区分对抗样本和原始样本;文献[11]提出AdvGAN 的改进版AdvGAN++,向生成器中加入一定的高斯噪声,使得生成的对抗样本更具随机性和多样性,提高了攻击的鲁棒性和隐蔽性;文献[12]提出AI-GAN 方法,其设计灵感来自于人类的攻击行为,即在攻击者拥有攻击目标背景知识的情况下,攻击者可以针对目标进行精准攻击。AI-GAN 利用这种攻击思路,首先通过背景知识收集对目标模型有益的信息,然后利用这些信息生成对抗样本。
虽然上述攻击方法在对抗样本生成方面取得了一定成果,但是它们也存在一些缺点,例如:基于梯度的攻击方法生成的对抗样本有一定的规律性,易于被发现;基于优化的CW 方法生成的对抗样本迁移性差,在多个模型中攻击效果不一致,且计算成本较高;基于生成式的方法生成的对抗样本在可接受性和可解释性方面有待提高。虽然AI-GAN 可以针对特定目标进行攻击,生成的对抗样本更具针对性和欺骗性,但是AI-GAN 也存在一些缺点,如需要额外的辅助数据集和背景知识,攻击效率较低。上述不足都限制了对抗攻击在实际中的应用,因此,还需要进一步研究和改进对抗攻击方法。
本文结合先进的深度学习模型Transformer[13]和生成对抗网络(GAN)[14],提出基于生成式的攻击算法Trans-GAN。该算法使用Transformer 作为重构网络,利用其强大的视觉表征能力增强对抗样本的可接受性和可解释性;算法同时训练基于Transformer的生成器和基于深度卷积神经网络(DCNN)[15]的鉴别器,通过对鉴别器的对抗训练来提高生成图像的真实性以及攻击的鲁棒性和欺骗性。此外,本文提出改进的注意力机制Targeted Self-Attention,修改网络输入,同时接收干净图像和攻击目标,针对特定目标进行攻击,生成更具针对性和欺骗性的对抗样本。
1 相关工作
1.1 对抗样本
考虑由正常图像训练得到的目标分类模型f,正常的输入图像是x,攻击者试图找到一个对抗扰动δ,使得x'=x+δ,其中,对抗扰动δ使得x跨越了分类模型f的决策边界导致f(x)≠f(x'),x'即为对抗样本。对抗样本的形式化定义如下:
下面对相关术语进行介绍:
1)对抗攻击和对抗防御。对抗攻击表示通过一定的算法在原输入图像上加入攻击噪声得到攻击图像,使分类器结果出错。攻击任务的难点在于攻击成功率和扰动大小之间的平衡,一般而言,扰动越大,攻击成功率越高。对抗防御表示构建足够鲁棒的分类器或防御模型,使其在输入攻击图像时也能够正确分类。
2)白盒攻击(white-box attack)和黑盒攻击(blackbox attack)。根据攻击者对目标模型先验知识的掌握情况,对抗攻击可以分为白盒攻击和黑盒攻击。还有一种只在训练时利用目标模型先验知识的攻击,称为半白盒攻击。
3)有目标攻击(targeted attack)和无目标攻击(non-targeted attack)。根据对抗攻击是否设置目标结果,攻击被分为有目标攻击和无目标攻击。
4)评价指标。目前攻击算法的评价指标主要采用Lp距离(一般也称为Lp范数),如式(2)所示,其中,vi表示像素点i的像素值变化大小,n表示像素点个数,v一般通过攻击图像减原图像得到,表示两张图的差值,也就是扰动。目前常用的Lp距离包括L0、L2和L∞。
1.2 Transformer 模型
ViT(Vision Transformer)[16]将 纯Transformer 架构直接应用到一系列图像块上进行分类任务,取得了优异的结果,引发了Transformer 在计算机视觉应用中的热潮。Transformer 强大的表达能力主要来源于自注意力机制的应用。计算机视觉中的自注意力机制借鉴自NLP 的思想,保留了Query、Key 和Value等名称。图1 中的自注意力机制结构自上而下分为3 个分支,分别是Query、Key 和Value(彩色效果见《计算机工程》官网HTML 版,下同)。i表示输入的卷积特征图,o表示输出的自注意力特征图。计算时通常分为3 步:第1 步令Query 和每个Key 进行相似度计算得到权重;第2 步使用Softmax 归一化这些权重;第3 步将归一化权重和Key 相应的Value 进行加权求和,得到最后的注意力特征图。输出的自注意力特征图如下(忽略了1×1 卷积操作):

图1 计算机视觉中的自注意力机制Fig.1 Self-attention mechanism in computer vision
自注意力模块有助于模拟跨越图像区域的长距离、多层依赖关系。通过在原始特征图上添加加权的attention 来获得特征图中任意2 个位置的全局依赖关系。生成器可以利用自注意力模块来绘制细节充分协调的图像。
1.3 生成对抗网络
GAN 是一种无监督生成网络,包含生成、判别和对抗3 个部分,利用对抗的思想交替训练生成器G和鉴别器D。生成器G负责根据随机向量z生成尽可能真实的样本G(z),鉴别器负责判别接收的内容是否真实。鉴别器会输出一个概率,概率接近1 表示鉴别器认为输入样本符合真实数据集的数据分布,接近0 表示输入样本不符合真实数据分布。对抗是指GAN 交替训练生成器G和鉴别器D的过程。以图片生成为例,生成器学习真实数据的分布,生成一些假样本,期望能够骗过鉴别器,然后鉴别器学习区分真样本和假样本,交替这一动态博弈过程,直至达到纳什均衡点,即鉴别器对任何图片的预测概率都接近0.5,无法判别图片的真假,此时表示已经训练好生成器,可以停止训练。GAN 的优化目标如式(4)所示:
其中:Pdata(x)表示真实样本数据的分布;Pz(z)表示随机向量的分布;D(x)表示x是真实图像的概率;G(z)表示从输入噪声z产生的生成图像。GAN 的优点是可以产生更加清晰、逼真的样本,缺点是训练不稳定,容易出现模式崩溃问题,即使长时间地训练生成器,生成效果依然可能很差。
2 本文算法设计与实现
受Transformer 和GAN 的启发,本文提出一种深度学习模型Trans-GAN,利用Trans-GAN 生成对抗样本,实现有目标攻击。
2.1 网络结构
如图2所示,Trans-GAN网络结构包括生成模型G、判别模型D和目标分类模型f,其中,生成模型使用Transformer 代替原始GAN 中简单的卷积神经网络。网络以原始实例图像x和目标标签t作为输入,在模型中进行端对端的训练以生成对抗实例。
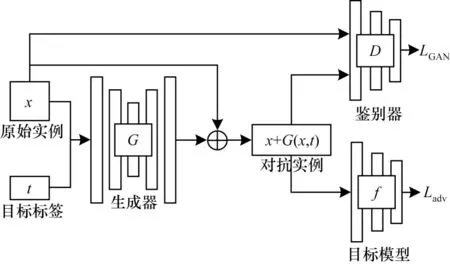
图2 Trans-GAN 网络结构Fig.2 Trans-GAN network structure
本文使用基于Transformer 的Restormer 模型[17]作为生成器网络结构,其在高分辨率图像复原领域取得了较高的性能。为了实现有目标攻击,将目标标签作为辅助信息参与到重建任务中,提出自注意力机制的修改版本Targeted Self-Attention,改进后的生成器模型架构如图3 所示。在图3 中,生成器模型[图3(a)]采用编码-解码结构,由若干个Transformer Block 组成。模型接收干净样本x进行下采样,在编码器的每一层,同时接收由目标标签t变换到同等尺寸大小的目标特征图tn(n取1、2、3、4)作为输入,在充分提取到图像特征和目标信息后经解码器进行逐步上采样,恢复原始图像大小,输出噪声信息。下采样的每个Transformer Block 中使用修改的自注意力机制Targeted Self-Attention[图3(c)],上采样中每个Transformer Block 使用原有的自注意力机制[图3(b)]。在修改的注意力机制中,V不再由x通过卷积操作得到,而是由输入的目标特征tn产生,tn表示目标标签扩张维度后的特征,其尺寸大小和x相同,其余部分不变,这种简单操作将目标标签作为辅助信息,能有效指导生成器进行有目标攻击。
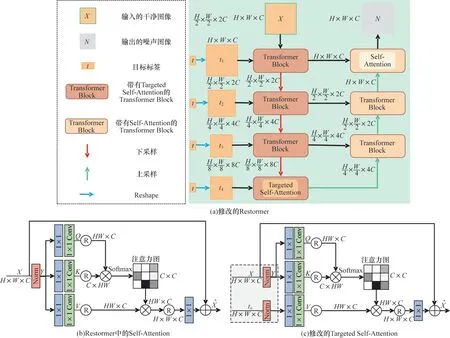
图3 生成器模型架构Fig.3 Generator model architecture
本文使用CNN 作为鉴别器网络。表1 所示为用于CIFAR10 数据集的鉴别器架构(用于MNIST 数据集的架构由于输入图片尺寸不同而稍有改变,具体详见公开代码)。在表1 中,Conv 表示卷积层,BN表示批归一化,激活函数使用斜率为0.2 的LeakyReLU。鉴别器架构默认使用核窗口大小为4、步幅为2 的卷积操作进行下采样,最后使用Sigmoid函数输出鉴别器的置信分数。

表1 用于CIFAR10 数据集的鉴别器架构 Table 1 Discriminator architecture for CIFAR10 dataset
2.2 损失函数
在训练过程中,Transformer 接收原始干净图像和攻击目标类别后生成噪声信息,将残差连接与原始干净图像相结合生成扰动实例。判别模型和生成模型联合训练,使用LGAN损失函数来提高模型的稳定性,LGAN损失设计如式(5)所示,其中,G表示生成器,D表示鉴别器,x表示干净样本,t表示目标标签。
此外,通过在噪声信息上添加L2约束Lperturbation来控制所生成扰动的大小幅度,如式(7)所示,其中,表示L2范数,即求欧氏距离。
为了提高生成模型的能力,改善对抗样本的视觉质量,采用结构相似度损失Lssim[18]和感知损失Lperception[19]进行联合训练,分别如式(8)、式(9)所示:
其中:a表示生成的对抗样本,即x+G(x,t);μx、μa、σx、σa和σx,a分别表示2 个图像、图像的均值、方差以及协方差;c1和c2为常数,通常取c1=(K1·L)2,c2=(K2·L)2,一般地,K1取0.01,K2取0.03;L表示灰度级,取255;ϕ表 示VGG 网 络[20];j表示网 络的第j层;ϕj(·)和CjHjWj表示第j层的特征图和尺寸。
网络总体损失函数如式(10)所示,α、β、γ和λ为各部分损失函数的平衡参数,为了增强模型对扰动量的约束能力,上述参数默认设置分别为1、10、1 和1,以提高所生成对抗样本的可视质量。
在推理过程中,本文算法不再需要目标分类模型的参与,直接输入干净图像和攻击标签就能生成相对应的对抗样本,能够攻击目标分类器,使其分类错误。
2.3 算法流程
Trans-GAN 算法训练流程如算法1 所示。生成器根据干净样本x和目标标签t生成对抗扰动,计算出对抗样本a;将a输入目标分类器f中计算对抗损失,提升攻击能力;将a和x一起输入D中计算GAN损失,提升生成的对抗样本和干净样本的区分度;对x和a计算相似度损失、感知损失和L2损失,进一步提高对抗样本的视觉效果。

在测试阶段,不需要鉴别器D和目标分类器f的参与,只需向生成器G中输入测试集的干净样本以及想要攻击的目标类别标签,即可计算得出相应的对抗样本,从而实施相应的攻击。
3 实验结果与分析
本文所有实验均运行在Linux 操作系统上,系统版本为Ubuntu 18.04 LTS,所使用的GPU 资源为2 块RTX 2080Ti,采用PyTorch 1.9.0 作为深度学习框架,CUDA 版本号为11.1。实验设置的总训练轮数为100 个Epoch,采用Adam 作为优化器,学习率设为0.000 1,权重衰减系数设为0.000 5。
首先评估所提算法在没有防御时对MNIST[21]和CIFAR10[22]的攻击效果,然后评估所提算法在有对抗训练防御下的攻击效果。此外,通过对ImageNet 数据集[23]执行半白盒攻击,评估所提算法的可扩展性。实验过程中对抗性扰动的评价指标采用L2和L∞范式。MNIST 的扰动幅度限制在0.3 以内,CIFAR10 和ImageNet 的扰动使用L2范式进行限制。使用不同攻击方法生成对抗性例子,以进行公平的比较。
从表2 可以看出,在计算效率方面:FGSM 生成对抗样本的运行时间为0.06 s;PGD 在FGSM 的基础上执行迭代攻击,多次计算梯度信息,因此运行时间是FGSM 的数十倍;基于优化的攻击算法CW 超过3 h,运行时间最长;本文所提算法和AdvGAN 一样属于生成式攻击,运行时间远小于基于梯度的攻击算法和基于优化的攻击算法,在训练好模型参数后,只需进行一次简单的前向传播即可快速生成对抗样本。此外,FGSM 和优化类算法只能进行白盒攻击,本文所提算法可以在半白盒设置下进行攻击,只在训练时需要模型参与。

表2 不同攻击算法的攻击效率比较 Table 2 Comparison of attack efficiency of different attack algorithms
与AdvGAN 算法相比,本文算法接收目标标签作为输入,只需训练1 个模型即可实现任意目标类别的有目标攻击,而AdvGAN 的攻击目标在训练时的损失函数中指定,训练好的模型只能实现特定目标的攻击。如果将AdvGAN 应用到ImageNet 这种具有1 000 个物体类别的数据集中,就需要针对每个目标类别共训练1 000 个模型,而本文算法只需训练1 个模型就能使目标分类器分错至任意目标类别,因此,本文算法具有更强的应用价值。
3.1 没有防御系统下的攻击评估
首先评估本文所提算法在没有任何防御设置下对MNIST 和CIFAR10 的攻击能力。对于MNIST 数据集,在所有实验中为2 个模型生成对抗性例子,2 种模型网络结构如表3 所示,模型A 是文献[24]使用的架构,模型B 是文献[9]用于评估基于优化策略的目标网络体系结构。对于CIFAR10 数据集,选择ResNet-32[25]和Wide ResNet-34(WRN-34)[26]作为目标模型。
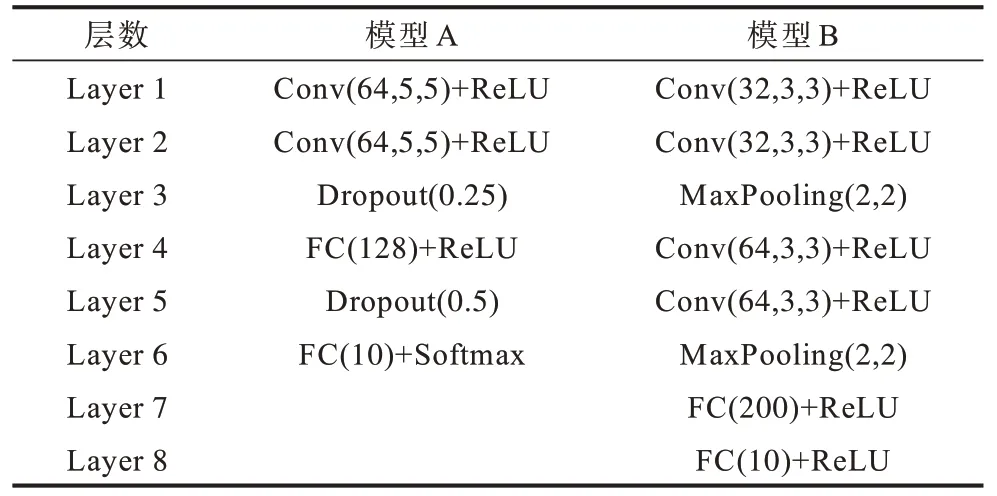
表3 用于MNIST 数据集的2 种分类模型结构 Table 3 Structure of two classification models for MNIST dataset
表4 中展示了在MNIST 和CIFAR10 测试数据集上使用AI-GAN 和本文算法对各个目标类别进行攻击的实验结果,表中数值表示攻击成功率(ASR),最优结果加粗标注。从表4 可以看出,在不同数据集上,本文算法的攻击能力在大多数攻击类别上都要强于AI-GAN,并都取得了最高的平均攻击成功率。具体来说,在MNIST 数据集上,本文算法的平均攻击成功率达到了99.9%以上,在CIFAR10 数据集上平均攻击成功率也分别达到了96.36% 和98.47%,这主要得益于作为生成器的Transformer 网络具有很强的学习能力。
针对CIFAR10 数据集随机选择样本,生成的对抗性示例如图4 所示。使用训练好的攻击算法从CIFAR10 的10 个类别中随机选择一张图像对其他类别进行攻击。图4(a)表示生成的对抗样本示例,其中对角线上为原始干净图像,“0~9”表示攻击的目标类别,可以看出,从肉眼上基本看不出干净图像和对抗样本的区别。将生成器生成的对抗噪声进行可视化,如图4(b)所示,可以看出,生成的扰动非常小,看不出任何细节。将噪声图放大10 倍后如图4(c)所示,从中可以看出明显的扰动细节。此外,在对不同图像进行相同目标的攻击时,生成器产生了纹理极为相似的噪声扰动,猜测这是由于在训练过程中同时接收了干净图像和目标标签作为输入,而针对CIFAR10 数据集而言,训练集图像有50 000 张,而目标类别只有10 种,在训练过程中,目标标签容易占据主导地位,指导生成器生成与攻击类别相对应的特定扰动,这样的扰动施加在干净图像上可以促使目标分类器将关注点聚焦于对抗样本中的特定扰动,从而产生错误分类。上述这一现象可能推动相关人员对于通用扰动的研究。
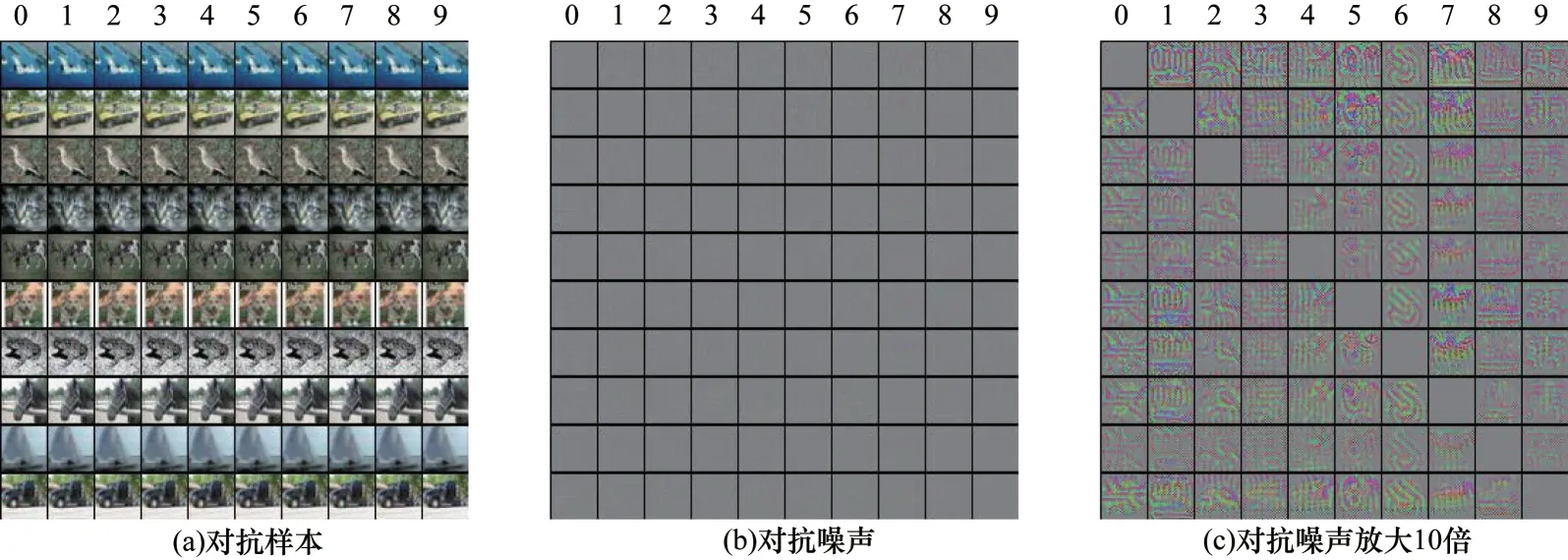
图4 CIFAR10 数据集的对抗样本示例Fig.4 Examples of adversarial samples of CIFAR10 dataset
3.2 防御系统下的攻击评估
面对不同类型的攻击策略,学者们提出了不同的防御手段,其中,对抗训练被广泛认为是最有效的方法。文献[7]首先提出对抗性训练作为提高深度神经网络鲁棒性的有效方法,文献[24]将其扩展到集成对抗性学习,文献[8]也提出针对更强攻击方法的鲁棒网络。本文选择3 种流行的对抗性训练方法来提高目标模型的鲁棒性:1)使用FGSM 进行对抗性训练;2)集成对抗性训练;3)使用PGD 进行迭代式对抗性训练。假设攻击者并不知道防御模型,并使用白盒设置中的普通目标模型作为目标,直接尝试攻击原始的学习模型,在这种情况下,如果攻击者仍然可以成功攻击模型,就表明攻击策略具有很强的鲁棒性。
首先不考虑任何防御,应用不同的攻击方法在原始模型的基础上生成对抗性样本,然后应用不同的防御方法来直接防御这些对抗性的实例以得到鲁棒模型。将本文所提算法与FGSM、CW 攻击、PGD 攻击、AdvGAN、AI-GAN 一起对这些防御方法进行攻击,定量比较结果如表5 所示。从表5 可以看出,本文所提算法具有最高的攻击成功率,优于所有其他算法。与传统的攻击方法和AdvGAN 相比,AIGAN 和本文算法在2 个数据集的不同模型、不同防御下都取得了更高的攻击成功率。与AI-GAN 相比,本文所提算法攻击成功率高出10.74%~55.14%,展现出其良好的攻击能力。
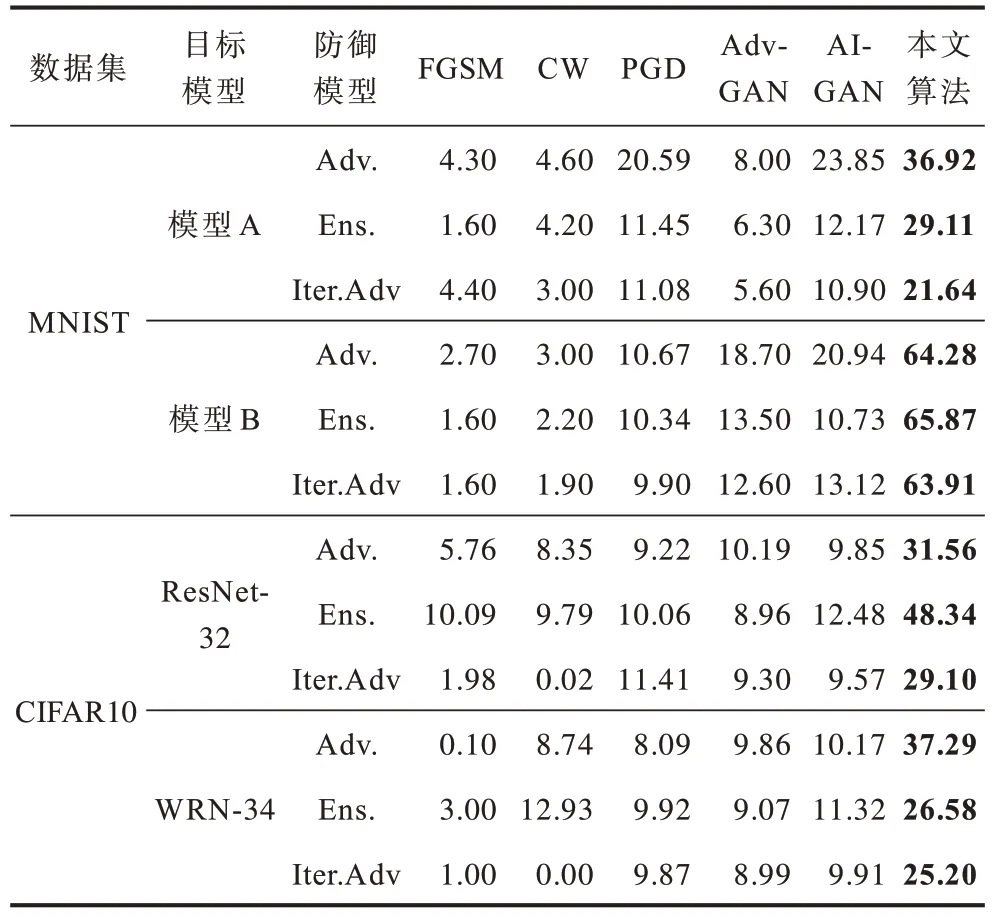
表5 在防御模型上不同算法的攻击性能比较Table 5 Comparison of attack performance of different algorithms on defense models %
3.3 ImageNet 实验评估
为了评估本文所提算法生成高分辨率对抗样本的能力,针对复杂数据集进行相关实验,研究所提算法的有效性和可扩展性。从ImageNet-1000k 数据集中随机选择100 个类别,每个类别含有600 张图像(输入大小为224×224 像素)进行对抗攻击实验。为了减轻训练压力,在进行有目标攻击时,从100 个目标中随机选择10 个目标进行训练。在训练好攻击模型参数后,为测试数据集中的每个样本随机选择一个不同于其真实类别的目标标签,然后采用FGSM、PGD、本文算法进行有目标攻击测试,统计攻击所需总时长以及攻击成功率,实验结果如表6所示。从表6 可以看出:虽然FGSM 作为经典且简单有效的对抗攻击算法,在MNIST 和CIFAR10 数据集上有着较高的攻击能力和生成速率,但对于ImageNet 这种较大尺寸和多目标类别的数据集,其攻击性能明显下降,有目标攻击的成功率只有28.76%;相比于FGSM,基于迭代的PGD 攻击具有更强的攻击能力,但其生成对抗样本的时间也成倍增加;本文算法相比于PGD 攻击不仅具有更高的攻击成功率,同时具有更快的生成速率。
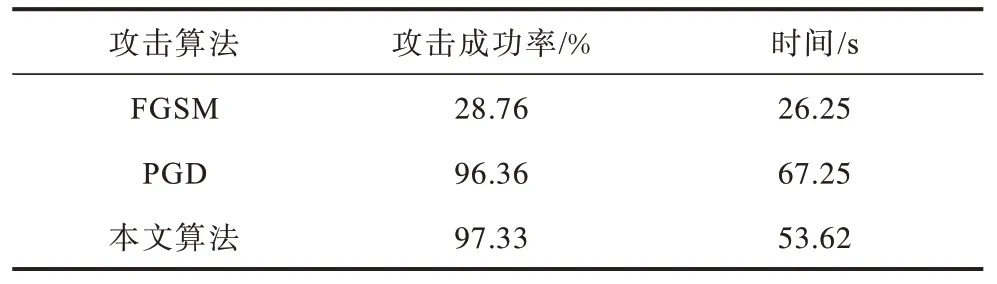
表6 在ImageNet 数据集上不同算法的攻击性能比较 Table 6 Comparison of attack performance of different algorithms on ImageNet dataset
本文算法的攻击性能不仅体现在高攻击成功率上,还体现在生成的对抗样本具有高可视质量。如图5 所示,图中第1 行表示从测试集中随机选取的干净样本,第2 行表示使用本文算法生成的对抗扰动的可视图像,第3 行表示施加了对抗扰动的对抗样本。由于训练过程中相似度损失函数和感知损失函数的约束,模型学习到了更高级的对抗扰动,能够改变原始图像的亮度(如第1 列和第2 列示例),或者改变原始图像的颜色(如第3 列和第4 列示例),或者改变原始图像的纹理特征(如第5 列和第6 列示例)。传统方法生成的对抗扰动通常表现为无规律的杂乱无章的噪声点,会严重影响干净样本的清晰度,而本文算法针对干净样本和目标标签生成的对抗样本看起来更加自然,更符合人类视觉的观感特性。

图5 ImageNet 数据集的对抗样本示例Fig.5 Example of adversarial samples of ImageNet dataset
4 结束语
本文提出一种基于Transformer 和GAN 的对抗样本生成算法Trans-GAN。利用Transformer 架构作为GAN 的生成器,同时接收干净图像和目标标签作为输入,提出改进的注意力机制Targeted Self-Attention,有针对性地生成对抗性扰动,并施加到干净图像上生成对抗样本。将生成网络与鉴别器进行联合训练,以实现快速收敛,同时使得对抗样本和干净样本不可区分。实验结果表明,相比FGSM、PGD等算法,Trans-GAN 算法生成的对抗样本可视质量更高,图像更为自然,且在各个攻击目标类别上具有较高的攻击成功率,有更好的迁移性能,能够满足复杂应用场景的需求。但是,通过定性实验结果发现,本文算法针对同一目标类别生成的对抗扰动具有相似的纹理特征,因此,下一步将研究如何快速有效地生成通用扰动。
