基于多粒度字形增强的中文医学命名实体识别
2024-02-29刘威马磊李凯李蓉
刘威,马磊*,李凯,李蓉
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.云南省第一人民医院信息科,云南 昆明 650500;3.云南省第一人民医院科研科,云南 昆明 650500)
0 引言
面向医学领域的中文命名实体识别旨在从医学领域非结构化中文文本中提取具有特定指代意义的实体,并识别它们的类型,如症状、药品名称、身体部位等。该任务是准确理解医学领域文本语义的基础,同时也对面向医学领域的信息检索、智能问答等下游任务起着重要的作用。与英文的命名实体识别不同,由于中文句子中表达含义的字或词并不是自然分割的,中文命名实体识别的难度更大。一般的中文命名实体识别(NER)问题通常被形式化为序列标注问题,将文本划分为多个Token,然后将Token初始化为向量输入到神经网络模型中,最终模型输出文本中每个Token 对应的标签。常用的Token 有字符和词两种形式[1]。然而,由于中文字符本身不具备中文词语那样相对独立的语义,基于字符的模型可能会面临所识别的实体不完整和实体类别错误等问题。为解决这一问题,研究人员主要考虑如何在基于字符的输入基础上引入词的信息。如文献[2]提出的Lattice 模型,在每个字符嵌入基础上融合词语嵌入,将匹配到的词的嵌入以特有的方法融合到字符嵌入上以增强字符表示,文献[3]提出SoftLexicon 的方法,将字符匹配到的词根据在词语中出现的位置分类成4 个词集合,并以词频的方法对4 个词集合的词嵌入进行融合,以提升模型的训练速度及判断实体边界和类型的能力。上述方法本质上都是利用外部知识对字符信息进行增强,说明对于基于字符的中文命名实体识别来说,字符信息的增强是一种有效的手段。
对于医学领域命名实体识别来说,组成领域实体的字符有自身的特点,主要表现为2 个方面:
1)很多医学领域中文字符的字形结构具有独立的语意,代表了特定的实体含义。具体来说,中文是一种象形文字,由形旁和声旁两部分组成,形旁的表义功能比较强,具有相同形旁的中文字符有相近的实体含义。汉字中的形旁“艹”,俗称草字头,由“艹”组成的字,大多与药品实体有关,比如“葡萄糖”、“莲花清瘟”、“感冒药”等。由形旁“月”组成的字,大都跟身体部位有关,如“胆囊”、“肝脏”、“肾脏”等。显然,这种字形信息的利用能增加中文字符对于医学实体边界和类别的表征能力。
2)特定的中文字符组合成的医学术语也代表了特定的实体含义。“肝”组成“脂肪肝”和“肝脓肿”等术语。这些术语需要从整个医学文本数据集中获取。对于字形多粒度信息的获取,一方面可以从空间域处理的角度将整个字符视为一幅二维图像,通过图像特征编码器提取汉字在字符中的空间形态信息,另一方面从文本的角度可以将字符拆解为形旁和其他部件结构,通过卷积神经网络进一步获取形旁在字符中的结构及序列信息。对于领域词信息,可以根据大规模医学语料库获得专业术语集合,并根据术语的上下文得到术语嵌入。
基于以上分析,本文提出通过对字符的多粒度字形进行增强,从而改善基于中文字符的医学命名实体识别模型的性能。本文主要贡献有:
1)提出一种综合利用汉字多粒度字形信息的NER 模型,通过融入中文字符的多粒度字形信息和领域术语信息来增强字符表示,增强字符的语义和潜在边界信息,使模型获得更好的实体识别能力。
2)提出并利用交互门控机制控制字符多粒度字形信息和领域词信息对于字符表征的贡献程度,综合考虑到汉字的领域信息和汉字底层信息并进行门控过滤,从而更好地表示输入句子中汉字的潜在含义。
3)在两个中文医学NER 基准数据集上对所提出的方法进行评估,验证该模型对特定领域和密切相关实体的表示能力。
1 相关工作
医疗领域的命名实体识别方法在早期主要采用传统机器学习方法。一些研究者利用支持向量机(SVM)和条件随机场(CRF)等机器学习算法来识别临床实体。例如,文献[4]开发了基于SVM 的NER 系统,用于识别医院收费摘要中的临床实体。文献[5]为了提取词典特征,构建了一个医学词典,对基于CRF 的中文电子病历命名实体识别进行了深入研究。文献[6]对结构化支持向量机、最大熵CRF 和支持向量机的字袋、词袋、词性、信息量等特征进行了对比实验。文献[7]采用双重分解模型,兼顾分词和实体识别。文献[8]提出一种基于条件随机场的医学文本药物名称识别方法。尽管医学命名实体识别的研究已经取得了很大的进展,但基于机器学习的方法还存在许多问题,模型效果容易受稀疏数据的影响,扩展性差,这些问题无法得到很好的解决。
近年来,深度学习迅速发展并进入到公众的视野。对于医学神经网络,文献[9]使用神经网络对大量的医学文本进行训练,生成词向量,然后为神经网络构建多层CNN。文献[10]使用双向长短期记忆(BiLSTM)作为基本的NER 结 构。文 献[11]将BiLSTM 和CRF 相结合,在药物名称识别任务中取得了良好的效果。之后,人们引入注意机制来突出输入序列中的重要信息。文献[12]构建了一个将BiLSTM-CRF 与文档级复合命名实体识别中的注意力机制相结合的模型,并通过引入注意力机制来获取全局信息,以确保文档级数据中同一实体标注的一致性。医学文本包含的信息错综复杂,包含了大量的领域词汇和专业知识,这就需要更有效的方法来解决医学专家的任务。另外,一些研究还关注于联合提取医学实体和关系。这些研究结果表明,深度学习在命名实体识别领域具有广阔的应用前景。文献[13]提出了一种BiLSTM-CRF 模型,并将其广泛应用于医疗NER 任务[14]。我国电子病历的NER有其特殊性,我国企业资源管理机构结构复杂,实体类型众多,具有一定的领域特殊性。文献[15]使用了变形Transformers 的双向编码器表示(BERT)结构,并利用未标记的中文医疗文本进行预先训练,实现了中国临床命名实体识别。文献[16]从Transformer 中的策略和思想入手,利用主流经典模型研究了如何提高传统卷积神经网络的精度,采用了BERT 预训练汉语模型以提高中医神经网络的精度。文献[17]提出一种用于医学序列标记任务的预训练并加入池化上下文嵌入模型。这些研究都致力于解决中文医疗文本处理中的问题,有助于提高临床数据的建模、关系抽取和医学序列标注任务等的准确性和效率。
在医学领域,由于一般领域对训练语料库的影响,目前主流的NER 方法没有考虑汉字字形的空间和偏旁部首序列两个方面底层的字符信息,并引入可能包含冗余成分的词信息。从这一角度出发,本文使用多粒度的字形信息增强字符潜在边界和语意信息,提升了基于字符NER 模型的性能。
2 本文模型
针对基于字符的NER 模型中字粒度语意信息的不足和领域词信息冗余问题,本文提出使用字形和部首嵌入增强字粒度的信息,并使用交互门控机制来过滤领域词信息中噪声的方法。本文提出方法的总体架构如图1 所示。首先将输入序列中的每个字符通过预先训练的字嵌入表映射成向量表示,接着与字符在领域词典上匹配到的词进行联合嵌入,得到丰富的语意知识,并使用两种不同的卷积网络分别对字符的字形信息进行特征抽取,将多粒度字形特征与包含丰富医学知识的字符表示使用交互门控机制来得到最终输入,然后送入到序列编码层和CRF 层,以获得最终的预测。
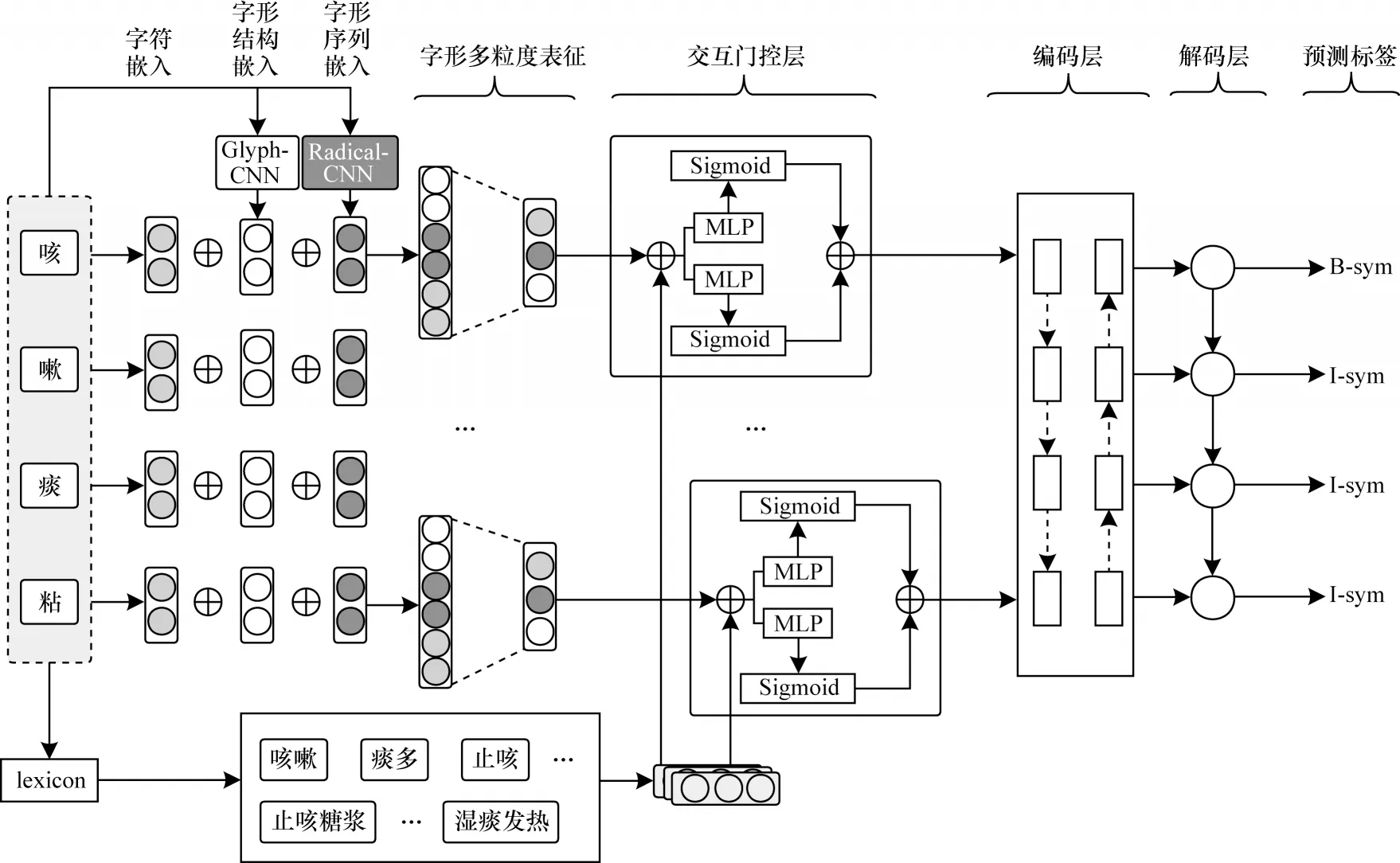
图1 基于多粒度字形增强的中文命名实体识别网络框架Fig.1 Framework of Chinese named entity recognition network based on multi-granularity glyph enhancement
2.1 字形结构嵌入
简体中文是最容易写的文字,但不可避免地丢失了最重要的象形文字信息,比如意义不相关的“未”和“末”在形状上非常相似,但在早期历史文字中,它们的形状却截然不同,所以使用多种不同字体来补充汉字的象形信息。首先,将单个字符视为一副二维图像,从空间域处理的角度,通过图像特征编码器来获得字符的字形结构嵌入。参考文献[18]模型的做法,分析汉字字符图像较小,使用更小的滤波器和通道数捕获更低维的图形特征,因此不太容易过拟合。如图2 所示,将字符转换为对应的6 种不同字体的灰度图像,其中第j种字体的大小为12×12 像素的8 bit 灰度图像。

图2 字形结构特征提取Fig.2 Feature extraction of glyph structure
将不同图像矩阵进行拼接,得到字符ci的结构图像
其中:Concat 表示拼接操作。然后使用卷积核大小为5×5,有384 个输出通道的卷积操作Conv1,捕获较低级别的图形特征,得到隐藏层向量
使用模板大小为4×4 的Max-Pooling 操作,将的分辨率从8×8 像素降低到2×2 像素;通过一个卷积核大小为1×1 和ds个输出通道的卷积操作Conv2,得到隐藏层向量
将送入卷积核大小为2 的群卷积操作,并进行维度转化操作reshape,得到该字符的字形结构嵌入∈Rds。
2.2 字形偏旁部首及部件结构嵌入
字符的形旁本身具有较强的实体指示作用,而这个作用仅用字形结构信息可能无法得到完全体现。因此,需要进一步强调形旁的作用。本文将字符拆分为形旁和其他的部件,然后用卷积神经网络来提取字符的这种特征向量。
首先将第i个字符ci拆分为K个部分,Oi=如果某个字符成分的长度不足K,则将空缺位置用PAD 来填充。然后对每个字符成分进行随机嵌入操作Er:
将该字符隐向量序列中每一个字符成分所对应的向量进行Max-Pooling,然后送入一个全连接层fc进行维度变换,得到该字符的字形序列嵌入
2.3 字符预训练嵌入及多粒度表征
基于字符的中文命名实体识别模型通常采用在大规模语料上所训练的字符向量来作为字符的初始嵌入[19]。这种表征通常蕴含了字符的上下文信息,即也是一种字符粒度的局部信息。使用预训练字符嵌入查找表Ec来获得字符的Word2Vec 向量。字符嵌入表是在一个大量的中文语料Gigaword 上使用Word2Vec 模型训练得到的。通过Ec得到每一个字符ci的嵌入向量:
在获得字符的3 种局部向量后,需要将三者结合来获得字符的表征。具体地,首先将进行拼接,得到初始拼接向量
然后将进行以下两次线性变换和激活,得到隐向量
将隐向量作为融合的汉字字形多粒度表征。
2.4 基于门控机制的多粒度表征和领域词嵌入融合
首先收集医学语料(包括医渡云4K、中文医学问答、中文医患问答、天池中文医疗信息等数据集)并与本文使用的两个数据集合并,然后使用北大开源分词工具包pkuseg 里的医学领域分词工具对收集到的语料进行分词操作,分词后的语料包含许多医学术语,最后使用Word2Vec 的Skip-Gram 模型得到词嵌入,设置窗口大小为4,去掉数量少于5 的词。通过以上操作,得到一个医学领域词典D,以及每个词的词嵌入查找表Ed,按照文献[3]提出的方法得到每个字符的领域词嵌入
在获得字符的多粒度表征和领域词嵌入后,由于两者相对可能会存在信息冗余,因此利用交互门控机制对两者的特征进行信息筛选,从而得到更合理的综合表征,计算公式如下:
最后将多粒度表征和领域词表征的门控与其对应的表征相乘并进行拼接,得到模型自适应学习后的综合表征的
2.5 上下文编码及CRF 序列标注
通过以上操作,增强了字符所蕴含的字形多粒度和领域信息。基于字符的NER 是一个连续的标记任务,相邻字符之间存在很强的约束关系。因此,还应该考虑字符在句子序列中的上下文信息。将句子序列送入BiLSTM 网络来提取字符的序列表征hi∈Rdh:
在序列标签输出阶段,使用CRF作为解码器。CRF会基于前一个标签的结果影响当前标签的结果。例如,B-Drug、I-Symptom 就是一个无效序列。字符通过BiLSTM 编码后得到隐向量hi,使用H来表示输入序列的隐向量矩阵,然后送到CRF 中,通过最小化负最大似然函数找到概率最大的标签序列。计算公式如下:
其中:ϕ(S,y)为观测序列与标签序列之间的发射概率与标签序列转移分数之和;S表示观测序列;y为真实的标 签;Wt∈Rdh×tags和bt∈Rn×tags是线性 层的参数;n是句子中的字符数;tags 是实体标签数;Y表示有效标签序列的集合。
最后使用负对数似然函数来计算标签分类的损失值:
3 实验
3.1 数据集
使用两个数据集:一个是中国计算语言学大会(CCL)提供的数据集IMCS21,包括2 000 组医患对话案例样本,覆盖10 种儿科疾病,8 万余句对话,样本平均对话次数为40 次,平均每个样本的对话字数为523 个,其数据集包含5 种实体类型,分别是症状、药品名称、药品类型、检查和操作,训练集数据15 000 条,验证集数据5 000 条,测试集数据3 000 条;另一个是中文医疗信息处理挑战榜里的中文医学命名实体识别(CMeEE)数据集,包含47 194 个句子和938 个文件,平均每个文件的字数为2 355,数据集包含504种常见的儿科疾病、7 085种身体部位、12 907种临床表现、4 354 种医疗程序等医学实体。
3.2 评价指标
本文采用准确率(P)、召回率(R)、F1(F1)值作为评价指标来衡量模型性能,计算公式如式(21)~式(23)所示:
其中:N为模型预测正确的实体数;M为模型预测实体总数;Z为数据中标注实体总数。
3.3 实验设置
基于PyTorch 框架,GPU 为NVIDIA GTX 3090,网络参数优化器为Adam,学习率设置为0.001 5,并且逐渐递减。采用优化函数为Adam,初始学习率大小为0.001 5,学习率缩减步长lr_decay 设置为0.05,dropout 率设置为0.5。模型参数设置如表1 所示。

表1 实验参数设置 Table 1 Experimental parameter settings
3.4 对比模型
BiLSTM-CRF[20]:使 用BiLSTM 将字符 序列进行编码后输入到CRF 层进行解码,得到序列标签。
Lattice[2]:对句子中的所有字符和词典识别的潜在词汇进行编码,从而将潜在词信息整合到基于字符的LSTM-CRF 中。
WC-LSTM[21]:对Lattice 进行了改进,将以每个字符为结尾的词汇信息进行静态编码表示,即每个字符引入的词汇表征是不变的,并且如果没有对应的词汇,则使用<PAD>进行填充,以实现批次并行化处理。
IDCNN[22]:提出dilated CNN 模型,为CNN 的卷积核增加了一个dilation width,作用在输入矩阵时会skip 所有dilation width 中间的输入数据;而卷积核本身的大小保持不变,这样卷积核获取到了更广阔的输入矩阵上的数据,可以很快覆盖到全部的输入数据。
LR-CNN[23]:该模形通过多层级CNN来不断地提取n-gram 信息,通过层级attention 来加权不同词汇权重,通过融合n个层级进行attention 来进行最终特征提取。
LGN[24]:利用词典和字符序列来构建图,将NER转换为节点分类任务。模型使用随机梯度下降(SGD)算法进行参数优化,初始学习率为0.001,迭代100 次,dropout 率为0.6 进行正则化。此外,学习率在每次迭代后会按照0.01 的步长进行缩减。
SoftLexicon[3]:对Lattice 引入词信息的方式进行优化。将字典信息融入字符表示,能够转换到不同的序列标注模型框架,而且容易与预训练模型合并。
FLAT[25]:将Lattice 结构转换为多个跨度表示,然后通过Transformer 模型引入位置编码融合字词信息,同时能够并行化运算。
MECT[26]:使用双流Transformer 模型融合字符、词典和部首信息,该模型能够通过2 个交互的Transformer 模型综合利用部首和字符间的关系,并使用随机注意力进一步提高性能。
3.5 结果分析
表2 给出了不同模型在CMeEE 和IMCS21 数据集上的实验结果,其中加粗字体为最优值。从表2可以观察到:
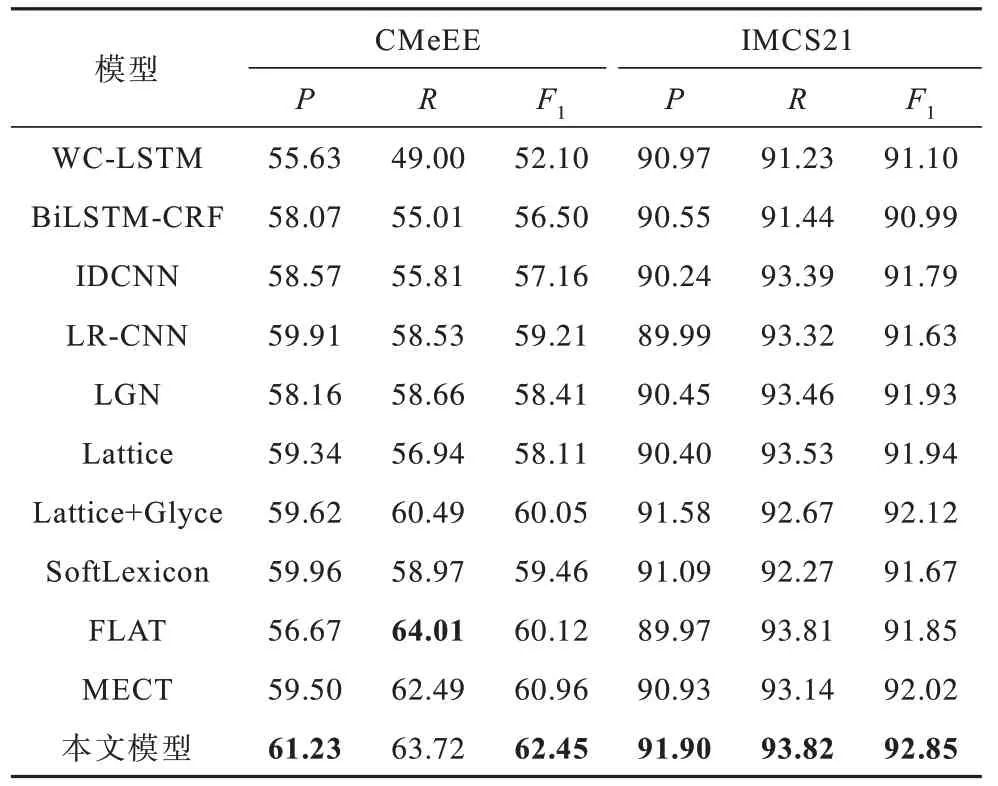
表2 在CMeEE 和IMCS21 数据集上实验结果Table 2 Experimental results on the CMeEE and IMCS21 datasets %
1)本文模型在所有模型中取得了最优性能。相比基模型中性能最好的MECT,本文模型的F1 值在CMeEE 数据集中提升了1.49%,在IMCS21 数据集中提升了0.83%。
2)从整体来看,模型BiLSTM-CRF 和WC-LSTM的性能最低,这可能是BiLSTM-CRF 模型仅仅使用了字符的上下文信息,对于中文NER 任务来说,遗漏了重要的词语信息,而WC-LSTM 在加入词信息的编码上有多种方式。显然,最短单词优先策略并不适合大部分实体较长的医学数据集,导致模型性能偏低。使用CNN 当作特征提取器的模型如IDCNN 和LR-CNN 较MECT 和FLAT 取得了更低的F1值,推测主要原因是它们更善于提取局部语意特征,但在学习全局语意特征方面受到限制。
3)MECT、Lattice+Glyce 和本文模型整体要优于IDCNN、LR-CNN、LGN、SoftLexicon 和FLAT 模型,前者在融入词信息的基础上都加入了字形信息,MECT 融入了偏旁部首,Lattice+Glyce 融入了字形信息,而本文模型两者都有,后者则都是通过不同的方式融合了词信息的模型,这说明本文模型使用外部字形信息的方法较好。
4)在CMeEE 数据集上,FLAT 的召回率最高,说明在长句子中实体抽取能力较强,但其精确率却很低,导致整体的性能不如本文模型,本文模型在长句子较多的CMeEE 数据集和短句子较多的IMCS21 数据集上都取得了最佳的F1 值,证明本文模型具有较强的鲁棒性。
5)数据集CMeEE 的结果比IMCS21 较低,推测原因是CMeEE 数据集中实体出现的频次更高,实体长度更长,模型难以拟合。
3.6 消融实验
为了验证本文模型各个方法的有效性,本文进行了消融实验来验证多粒度字符信息和门控信息对模型的影响。实验结果如表3 所示,其中,w/o glyph structure 中去掉字形结构嵌入,w/o radical sequence中去掉字形部首序列嵌入,w/o gate mechanism 中去掉门控机制。从表3 可以看出,去掉字形结构嵌入和字形部首序列嵌入导致模型的F1 值分别下降了1.15%和1.10%,这验证了字形结构和字形部首序列嵌入对于本文模型性能的保证都具有重要作用。同时,去掉门控机制后F1 值下降了0.94%,这表明了门控机制的有效性。值得注意的是,去掉字形结构嵌入比起去掉字形部首序列嵌入的效果要稍差,这可能是从图片上做卷积会比直接对偏旁部首做卷积有效,推测有两点:首先字形图片中包含偏旁部首之间的空间位置关系,比如“病”和“咳”还有“药”,分别是半包围、左右、上下结构,而偏旁部首嵌入显然没办法融入这一信息;然后使用了多个不同朝代的字体,这些字体更加象形,能够学到字义相近的字之间的一些相似的字形特征。从图片上直接做卷积得到的信息更原始更丰富,因此比字形部首序列能得到更多的信息。

表3 在CMeEE 数据集上消融实验 Table 3 Ablation experiments on the CMeEE dataset %
表4 显示了模型在两个数据集上实体识别错误的数量,包括实体头部边界错误(BE)、实体尾部边界错误(EE)和实体类型错误(TE),其中,w/o glyph 中去掉字形结构嵌入,w/o radical 中去掉部首序列嵌入。本文模型对比SoftLexicon 在CMeEE 上的实体头部边界错误和实体尾部边界错误数量分别减少了377 和394 个,实体类型错误减少了80 个。需要指出的是,单独增加字形结构或者部首序列信息的模型预测实体类型错误的数量会更少,这可能是因为两个信息会对实体类型判断造成干扰。毫无疑问,本文模型对于实体边界和实体类型的识别都是非常有益的。
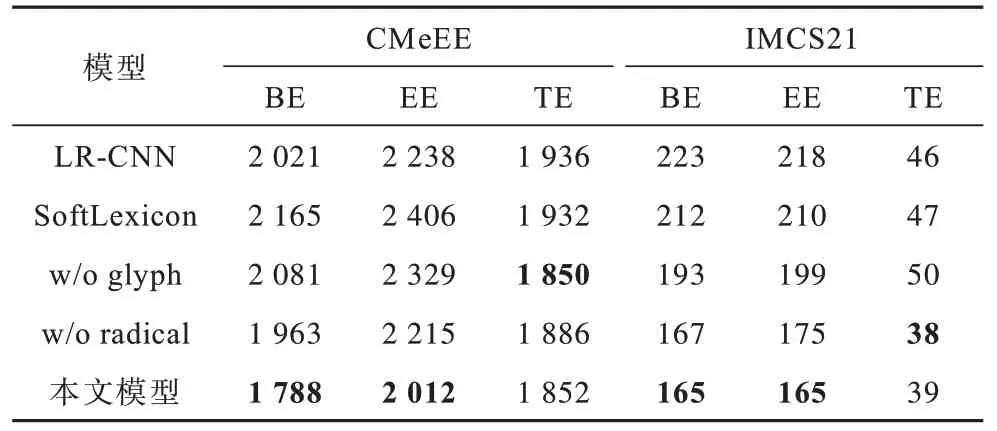
表4 实体识别错误类型统计Table 4 Statistics of entity recognition error types 单位:个
3.7 案例分析
表5 列出了不同模型对CMeEE 数据集中的实例的处理结果。对于第1 个案例,可以观察到LR-CNN 和SoftLexicon 不能有效地识别连续出现的全部实体,即模型对于多个连续实体的识别能力不足。此外,根据第2 句的预测的错误实体如“气管异物”,LR-CNN 模型将该实体的类型及边界预测错误,该模型使用CNN 获得上下文编码,并使用rethink 机制来控制词信息的输入,这可能是CNN 作为编码器对字符远距离信息利用不足,干扰到模型的判断。SoftLexicon 模型将实体的类型识别错误,其引入的词信息占比较大,所以词典的质量会较大程度地影响模型对实体类型的判断。本文提出的模型,有效利用了字形的信息并控制词信息的输入,能够有效识别医学实体的边界,在识别实体边界方面表现优于其他模型。

表5 案例分析 Table 5 Case analysis
4 结束语
为了避免错误的词信息对中文命名实体识别模型的影响,并在嵌入层有效地利用外部字形知识,本文提出一种多粒度字形信息增强中文命名实体识别方法。该方法具有一般领域的字符信息、领域信息的词和多粒度的字形信息,其中字形序列组成部分的向量初始化的方法是随机初始化,利用一定量的先验知识对其进行初始化,可使其具有一定的语义信息,能够快速有效地提取字形序列信息,可在少样本场景下发挥作用。下一步将用更多方法来增强模型对于医学领域实体的识别能力,如加入医学知识图谱或者使用预训练语言模型的方式。同时,将继续研究实体嵌套和实体重叠问题,寻找更为有效的方式来准确识别中文医学实体。
