基于多策略强化学习的低资源跨语言摘要方法研究
2024-02-29冯雄波黄于欣赖华高玉梦
冯雄波,黄于欣,赖华,高玉梦
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650504)
0 引言
数据是直接决定能否训练出高性能神经网络模型的关键因素,使用大规模、高质量的跨语言摘要数据训练有利于模型生成更高质量的摘要,但是在跨语言摘要中数据稀缺是1 个公认的问题[1]。目前在跨语言摘要生成研究工作中,大多使用单语翻译构造跨语言摘要数据。此类方法简单便捷,但是在如越南语这种资源匮乏的语言上,机器翻译的表现并不理想。因此,使用翻译方法构建汉越跨语言摘要数据会产生较大的噪声。近年来的研究结果表明[2-3],相比传统的统计模型,神经网络模型对噪声数据十分敏感。ZHU 等[2]在汉英跨语言摘要上提出采用数据筛选的方法提升机器翻译构造跨语言摘要数据的质量。相比汉英,基于机器翻译构造的汉越跨语言摘要数据噪声更多,对数据过滤时既要保证数据的质量又要保证数据的数量,即使过滤掉一部分错误严重的噪声数据后,留下的数据集仍无法避免噪声。
本文针对汉语-越南语以及越南语-汉语跨语言摘要数据,提出基于多策略强化学习的低资源跨语言摘要方法。使 用ROUGE[4]、BERTScore[5]与Mgfscore[6]对单语翻译得到的伪汉语-越南语以及越南语-汉语跨语言摘要数据进行噪声过滤,提高数据集质量。通过对不同情况下的数据集进行噪声分析,发现选词不当和实词缺失是常见的错误类型,分别占据最大的错误比例。针对选词不当,本文在解码器生成目标摘要词语时,通过与源语言摘要词相关性匹配设计强化学习奖励,避免翻译不准确的词带来噪声产生影响。针对实词缺失,本文在解码器生成目标摘要词语时,以源语言摘要中的词语作为基准,根据缺失词语的重要程度设计缺失惩罚。受文献[7]的启发,本文基于强化学习思想,引入真实的源语言摘要来指导目标摘要的生成,采用不同策略从生成词相关性与缺失度组合设计强化学习奖励,同时,与传统的交叉熵损失函数相结合,构建目标函数来优化模型。
1 相关工作
1.1 跨语言摘要
跨语言摘要任务是输入汉语(越南语)文档自动生成越南语(汉语)简短摘要的任务。传统的跨语言摘要任务通常采用先翻译再摘要[8]或者先摘要再翻译[9-10]的技术框架,但通常会受翻译模型和摘要模型错误传递的影响,在低资源语言上效果还不理想。基于神经网络的跨语言摘要任务通常将其看作1 个类似机器翻译任务,不同之处在于机器翻译输入和输出的信息量不变,而跨语言摘要需要对信息进行压缩和翻译。针对低资源跨语言摘要任务通常有2 类方法:1)基于零样本学习的摘要方法,针对源语言文档到目标语言摘要数据集缺乏问题,AYANA 等[11]提出使用预先训练好的机器翻译模型与标题生成模型作为教师网络来指导跨语言标题生成模型,同时学习翻译能力和摘要能力,实现零样本条件下跨语言摘要的生成,DUAN 等[1]在沿用单语摘要模型作为教师网络来指导跨语言摘要模型参数学习的基础上,在学生网络中增加对教师网络注意力权重的学习;2)基于机器翻译和摘要的多任务联合学习方法,利用机器翻译模型与单语摘要等模型联合训练来弥补训练数据稀缺问题。ZHU 等[12]基于Transformer 文本生成框架,提出端到端跨语言摘要模型,跨语言摘要与单语摘要、跨语言摘要与机器翻译任务进行联合训练,在编码端进行参数共享,在训练过程中2 个任务进行交替训练学习跨语言摘要生成能力。此外,研究人员还引入RTT(Round-Trip Translation strategy)的方法,基于机器翻译模型对单语数据集进行翻译,并使用ROUGE 进行打分过滤低质量翻译数据,构造中英语言对上的跨语言摘要数据集。CAO 等[13]为实现更好的跨语言对齐,利用生成对抗网络对齐源语言与目标语言2 个单语摘要模型中的上下文表征,在进行单语摘要训练的同时达到双语对齐的目的。BAI 等[14]认为跨语言摘要与机器翻译联合学习的方法虽然可以通过共享编码器参数来增强跨语言摘要性能,但是2 个任务的解码器相互独立,无法很好地建立跨语言摘要与机器翻译任务的对齐。因此,本文提出一种解码器改进方法,同时解码源语言和目标语言摘要,提升解码器对2 种语言的解码能力,相比联合学习使用2 个独立解码器取得更好的结果。以上工作大多基于机器翻译对单语数据集进行翻译构造伪平行的跨语言摘要数据集,但都是中、英等大语种,机器翻译性能较好,翻译错误较少,但是对于低资源翻译效果有限的语言研究较少,对于机器翻译可能带来的噪声问题缺乏有效的分析和处理手段。
1.2 强化学习
强化学习在机器翻译、文本摘要等文本生成任务上的应用较多,主要是通过全局解码优化来缓解曝光偏差问题[15-16]。在摘要 任务上,PAULUS 等[17]提出将真实摘要与生成摘要间的ROUGE 值作为强化学习奖励对模型进行奖励或惩罚,使用线性差值方式将该奖励与交叉熵相结合作为训练目标函数,在一定程度上缓解曝光偏差问题。BÖHM 等[18]认为ROUGE 在词汇多样性表述的摘要上与人工评价相关性较差,基于ROUGE 值作为强化学习奖励的可靠性较低,因此提出采用源文本和生成摘要作为输入,从人工评分的摘要中学习奖励函数,取得相比ROUGE 值作为奖励更优的结果。YOON 等[19]基于语言模型计算生成摘要与真实摘要间的语义相似度作为强化学习奖励,改善了词粒度匹配ROUGE 的奖励获取方式。针对跨语言摘要任务,DOU 等[7]提出用源语言摘要和生成目标语言摘要间的相似度作为强化学习奖励来约束模型,以生成更好的摘要。受该工作启发,本文认为通过更好地建模源语言摘要和生成摘要之间的相关性,能够充分利用纯净没有噪声的源语言摘要来缓解翻译带来的噪声问题。
2 数据分析与研究
2.1 数据集构建
本文分别构建汉语-越南语跨语言摘要以及越南语-汉语跨语言摘要2 个数据集。在汉语-越南语跨语言摘要数据集中,采用LCSTS[20]前20 万个数据进行回译得到汉语-越南语跨语言摘要数据集(Zh-Visum)。越南语-汉语跨语言摘要数据集是通过从越南网(Vietnam+)、越南新闻社、越南快讯、越南通讯社等多个新闻网站收集越南语单语数据集,并进行清洗和翻译得到,最终获得约11.579 8 万条越南语-汉语跨语言摘要数据集(Vi-Zhsum),其中,采用谷歌翻译。
尽管通过翻译构建跨语言摘要数据集是一种简便快捷的方法,但是数据集的质量极大程度受机器翻译性能的约束。为此,基于回译后的数据,本文采用ROUGE[4]、BERTScore[5]与Mgfscore[6]对回译数据进行数据过滤,在ROUGE 筛选中,计算ROUGE-1、ROUGE-2、ROUGE-L 的平均值作为最终得分,而在BERTScore 与Mgfscore 评估中则采用F1 值得分。以汉语-越南语跨语言摘要数据筛选为例,具体操作流程如图1 所示。
在Zh-Visum 数据集中,过滤掉得分最低50%的数据,留下10 万条汉语-越南语跨语言摘要数据。而Vi-Zhsum 的回译质量相对较高,过滤掉得分最低30%的数据,剩下8.1 万条越南语-汉语跨语言摘要数据。数据集过滤前后回译得分详细信息如表1 所示,RG 表示使用ROUGE 指标过滤的数据集。

表1 各数据集回译得分信息 Table 1 Information of back-translation score on each datasets
2.2 数据分析
从表1 可以看出,对回译数据的过滤有效提升汉语-越南语以及越南语-汉语2 个跨语言摘要数据集的质量,但是进一步对汉越跨语言摘要进行分析发现,数据中完全正确的句子占比较小,而在训练模型中需要高质量、大规模的数据。因此,即使对数据进行过滤也只能去除那些低质量数据(错误严重),无法避免数据集中的弱噪声(错误不严重)。本文进一步对机器翻译构造的跨语言数据进行噪声分析,根据文献[21]中划分的类型进行统计,具体噪声类型如表2 所示。随着机器翻译系统性能的提升以及对本文噪声数据类型的分析,发现译文与原文意思相反与数量词/时间词问题错误占比很小。因此,在该数据的噪声类型结果统计中剔除了译文与原文意思相反和数量词/时间词问题错误噪声。

表2 CWMT2013 划分常见类型错误 Table 2 Common type error of CWMT2013 division
本文在汉语-越南语与越南语-汉语跨语言摘要数据集上各抽取100 句标准源语言摘要与目标语言摘要进行人工标记,对过滤前后的数据进行噪声类型统计,得到的结果如表3 所示。其中,Filter-No 表示未过滤,Filter-RG、Filter-Bert 和Filter-Msf 分别代表使用ROUGE、BERTScore 和Mgfscore 进行数 据过滤。Zh-Visum 过滤50%数据,Vi-Zhsum 过滤70%数据。

表3 汉语-越南语跨语言摘要数据集噪声类型占比 Table 3 The proportion of noise types in the Chinese-Vietnamese cross-lingual summarization datasets %
从表3 可以看出:
1)在构造得到的跨语言摘要数据集中没有错误的句子占比较小,虽然通过评价指标过滤数据能提高数据的正确率,但是无法避免噪声数据,这也是在提高数据集质量后,仍须进一步进行噪声下跨语言摘要生成方法研究的原因。
2)针对未过滤时正确句子的占比,在Vi-Zhsum中明显高于Zh-Visum,其原因为Vi-Zhsum 是基于越南语新闻网站爬取的单语数据翻译得到的。虽然越南语新闻摘要数据长度大于LCSTS 摘要数据,但是新闻数据大多表达句式规整且通俗易懂,机器翻译在此类数据集上翻译表现更好。
3)Zh-Visum 数据集的噪声类型占比最大的是选词不当与实词缺失。使用ROUGE 与BERTScore 数据筛选后,选词不当的占比下降较为明显。由此可见,在该数据集中部分属于选词不当类型的句子错误严重,这是因为LCSTS 是在新浪微博上获取以标题作为摘要的短文本摘要数据集,此摘要中大多中文词语表达短小精悍,而机器翻译往往对此类文本理解容易出现偏差,翻译时常忽略部分实词,所以在Zh-Visum 中一半以上的噪声均来自选词不当与实词缺失。相比Zh-Visum 数据集,在Vi-Zhsum 数据集中词序不对的错误占比较高。Vi-Zhsum 是由较长的文本翻译而来,而机器翻译对于长文词语间逻辑顺序理解能力较弱,翻译时容易出现语序错误。
4)此外,使用评价指标筛选后命名实体识别错误类型占比增大。一方面,BERTScore 是一种基于子词的评价方法,基于词级的数据筛选方法对命名实体错误不敏感;另一方面,在汉语-越南语与越南语-汉语跨语言摘要数据集中,命名实体大部分为人名、地名,此类错误大部分按谐音翻译出现偏差。相比其他噪声类型,该类型给句子带来的噪声较弱。
根据上述分析,在汉语-越南语短文本和越南语-汉语长文本的跨语言摘要数据集中,噪声类型占比最大的都是选词不当与实词缺失。因此,对数据进行筛选以提高通过翻译生成的伪数据质量,并继续弱化噪声是非常必要的。
3 多策略强化学习的汉越跨语言摘要方法
多策略强化学习的汉语-越南语跨语言摘要模型结构如图2 所示。
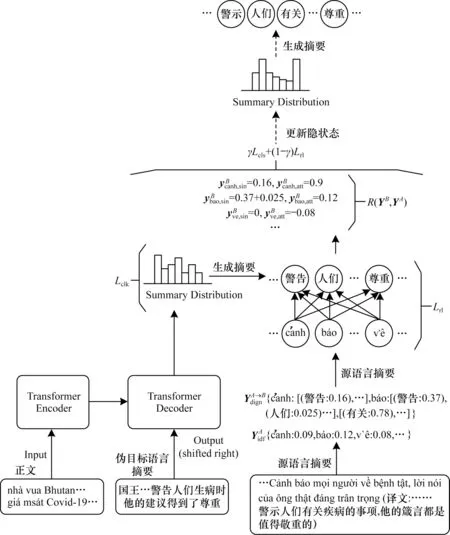
图2 多策略强化学习的汉语-越南语跨语言摘要模型Fig.2 A cross-lingual summarization model for multi-strategy reinforcement learning of Chinese-Vietnamese
针对汉语-越南语跨语言摘要中监督信号的噪声问题,本文提出一种多策略强化学习方法来改善汉语-越南语跨语言摘要的生成。在Transformer[22]模型的基础上,该方法通过源语言摘要和目标语言生成摘要之间的词相关性和词缺失度设置奖励来结合强化学习函数和最大似然估计函数作为训练目标,以提高生成摘要的质量并减少噪声对伪目标语言摘要的影响。
3.1 交叉熵损失
在基于Transformer 架构的传统跨语言摘要模型中,给定训练集,A代表源语言,B代表目标语言。对每个文档XA进行高维向量映射得到输入文档序列XA={x1,x2,…,xN},并输入编码器进行编码得到文档序列的向量表征H={h1,h2,…,hN}。最后,解码器依据给定的H进行解码,解码器依次生成摘要序列YB={y1,y2,…,yM}。在该过程中使用生成摘要YB与标准摘要间的最大似然估计作为优化目标。交叉熵损失函数定义如下:
其中:M为YB摘要的长度。
3.2 强化学习策略
在词相关性方面,使用源语言摘要序列YA=直接评估目标语言生成摘要词汇质量预先使 用fast-align[23]工具对 汉语-越南语双语平行语料对齐,得到每个源语言词汇与目标语言词汇间的相关度表示,记为。如式(2)所示,使用t时刻生成的目标语言摘要词汇,与中的每个源语言摘要词汇YA匹配,记为,即:YB与每 个源语言摘要词汇的相关度值,具体操作如图2 中间部分。
其中:sim 为相关性计算,本文使用fast-align 工具对汉语-越南语进行双语对齐,并计算2 种语言之间词汇的相关性;sum 表示求和。
在词缺失度方面,计算源语言摘要YA=中每个词汇重要程度,记为,也可使用该词在上下文中的重要程度来匹配生成摘要词汇的重要程度或词缺失程度,如式(3)所示:其中:使用词频-逆文本频率指数(TF-IDF)计算词汇重要程度。在词相关性中,如t时刻生成的目标语言摘要词汇能匹配到对应源语言摘要序列YA中的词汇时,则将源语言摘要中所匹配到词语的重要程度记为 生成摘要的的重要程度。当t时刻生成摘要匹配不到YA中词汇时,则认为生成摘要中该词缺失,此时将YA中未匹配到词的重要程度记为生成摘要中的词缺失度,从而避 免伪目标语言 中重要词缺失对模型学习造成的影响。
在跨语言摘要模型中,将跨语言摘要模型看作1 个智能体(Agent),每个解码t时刻得到的上下文表征向量以及前t-1 时刻生成的摘要可以看作智能体中环境(Environment),从候选词表中选取哪个词作为解码t时刻生成的摘要词,即为智能体的1 个动作(Action),而选择哪个词是依据策略(Policy)产生的,即概率分布函数。当智能体生成摘要时,模型就会得到1 个奖励(Reward),记为R(YB,YA)。本文采用式(4)计算期望奖励。其中,使用生成摘要中每个词汇与目标语言中对应词汇的相关度和缺失度来评估当前生成摘要的质量,从而避免伪目标语言摘要中噪声产生的错误指导。
在强化学习的训练过程中,其目标是最大化期望奖励,在强化学习损失中定义如下:
其中:Y代表所有可能生成的候选摘要,这是1 个指数级别的搜索空间。在实际操作中,常从概率分布函数P(YB|XA,θ)中采样1 个序列YS来优化上述期望奖励,但由此也带来期望奖励而存在较高的方差。此时,引入1 个基线奖励来减小梯度方差,采取与文献[24-25]相同的方法来解决该问题。在强化学习的目标训练中,使用自我批判策略梯度训练算法,在训练时采用2 个策略生成摘要:依据条件概率函数P(YB|XA,θ)从中随机采样得到YS;贪婪解码得到YG。由此,1 个摘要句的强化学习训练目标定义如下:
最后,本文采用线性插值的方式混合交叉熵损失函数和强化学习训练目标函数,得到跨语言摘要模型的混合训练目标函数,如式(7)所示:
其中:γ表示交叉熵损失函数与强化学习训练目标函数在混合目标函数中的比例因子。
4 实验与结果分析
4.1 数据集
为验证该模型的有效性,本文采用第2.1 节方法构造的20 万个Zh-Visum 与11.579 8 万个Vi-Zhsum数据集进行基础实验。在数据筛选后,得到1 个包括10 万个样本的汉语-越南语跨语言摘要数据集(Zh-Visum)和1 个8.1 万个样本的越南语-汉语跨语言摘要数据集。基于此,通过对数据集进行划分,详细数据信息如表4 所示。采用不同的过滤方式对汉语-越南语和越南语-汉语跨语言摘要数据集进行处理,其中,Bert 表示使用BERTScore 过滤汉语-越南语跨语言摘要数据集,Mgf 表示使用Mgfscore 过滤越南语-汉语跨语言摘要数据集,RG 表示使用ROUGE指标过滤的数据集。在本文中,为了公平比较,同一语种下的测试集保持不变。
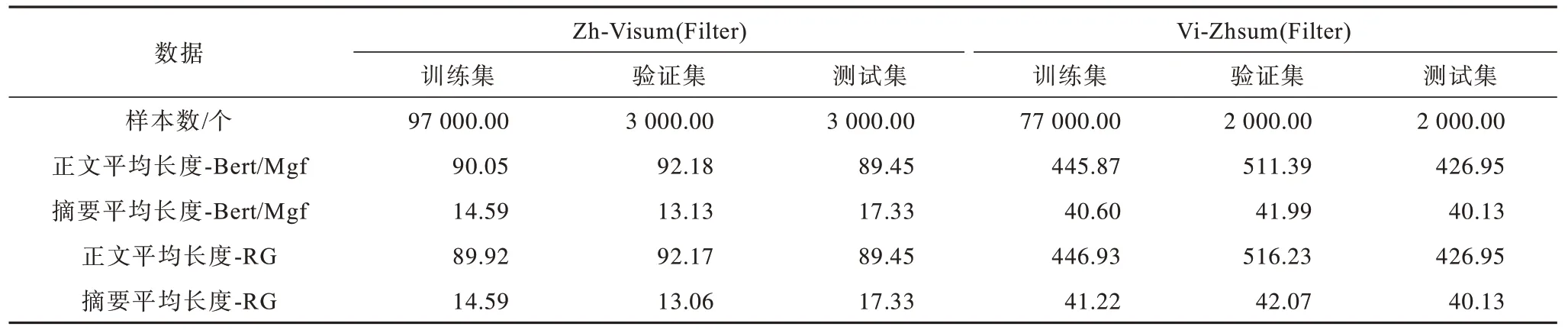
表4 实验数据详细信息 Table 4 Details information of experimental datas
其中,Zh-Visum(Filter)数据集为基于BERTScore指标过滤的数据;Vi-Zhsum(Filter)数据集为使用基于Mgfscore 指标过滤的数据。
4.2 评价标准
本文采用2 个评价指标来测评跨语言摘要系统生成摘要的质量。与大多数摘要工作相同,一种是基于统计方法ROUGE[4],计算标准摘要与生成摘要间的N-Gram 共现程度,计算式如式(8)所示:
其中:G为生成摘要;Ref 为标准参考摘要;N-Gram为N元词组;Countmatch(N-Gram)为生成摘要与标准摘要中的N元词组重叠个数;Count(N-Gram)为标准摘要中N元词组个数;N常设置为1,2,L(最长公共子序 列)。本文使 用ROUGE-1、ROUGE-2、ROUGE-L 评价生成摘要的质量,分别简写为RG-1、RG-2、RG-L。
文献[5]提出基于深度语义匹配的评价方法BERTScore,使用预训练语言模型计算生成句与参考句间的语义相似度。在中文中,预训练模型使用“bert-base-chinese”计算得分;在越南语中,预训练模型使用“bert-base-multilingual-cased”,使 用BERTScore 计算时,生成摘要中的“<unk>”替换为BERT 词表中的“[UNK]”。
4.3 实验设置
本文采用PyTorch 框架实现模型代码。在模型结构上,使用多层Transformer 编码器和解码器结构,每层都采用8 个多头注意力机制,隐层向量维度设置为512,前馈神经网络设置为1 024。采用Adam 作为模型优化器,参数β1=0.9,β2=0.98,∈=10-9。使用teach-forcing 策略,平滑因子 设置为0.1,Dropout 设置为0.1。当模型解码时,采用束搜索策略(Beam search),beam size 设置为5。与文献[26-27]方法相同,对于带强化学习策略的模型,本文均使用未过滤的Zh-Visum 与Vi-Zhsum 数据进行参数初始化,然后使用过滤后的数据继续训练模型。
4.4 基准模型
为验证多策略强化学习的汉语-越南语跨语言摘要方法的有效性,本文在Zh-Visum(Filter)与Vi-Zhsum(Filter)数据集上对以下基线模型训练并进行比较。
Sum-Tra 是一种传统的跨语言摘要方法,对输入的源语言文本进行自动摘要生成,对生成的摘要再进行翻译得到目标语言摘要。
Tra-Sum 与Sum-Tra 类似,是一种两步式的跨语言摘要方法,首先进行源语言文档到目标语言文档的翻译,在将目标语言文档输入到自动摘要模型,得到目标语言摘要。在Sum-Tra 与Tra-Sum 中,本文采用谷歌作为机器翻译模型,摘要模型采用无监督的抽取式方法LexRank。
NCLS[2]是一种基于Transformer 框架的 端到端神经网络的跨语言摘要模型。
LR-ROUGE 与本文提出的方法类似,但使用ROUGE-L 得分计算奖励期望。
LR-MC 是本文所提的跨语言摘要模型,将交叉熵与强化学习相结合作为优化目标,其中,期望奖励根据源语言摘要与生成目标语言摘要间的词缺失度与词相关性计算得到。
4.5 结果分析
本文从不同角度设计实验,验证汉语-越南语跨语言摘要基于多策略强化学习方法在噪声数据下的有效性。首先,对比本文提出不同策略的强化学习方法与基线模型的效果;然后,探究基于强化学习设计的词相关性奖励与词缺失度惩罚对噪声下模型性能的提升效果,各部分对模型的影响;其次,研究交叉熵损失函数和强化学习训练目标函数之间的比例因子对模型性能的影响,分别使用噪声过滤前后的数据训练模型,探究神经网络模型在不同数据下的表现;最后,针对不同模型生成的摘要进行实例分析。
4.5.1 与基线模型对比结果
本节所提的模型与基线模型的对比结果如表5所示,加粗表示最优数据,其中,γ为交叉熵损失与奖励期望间比例因子,当γ=1 时,即不加入强化学习奖励。
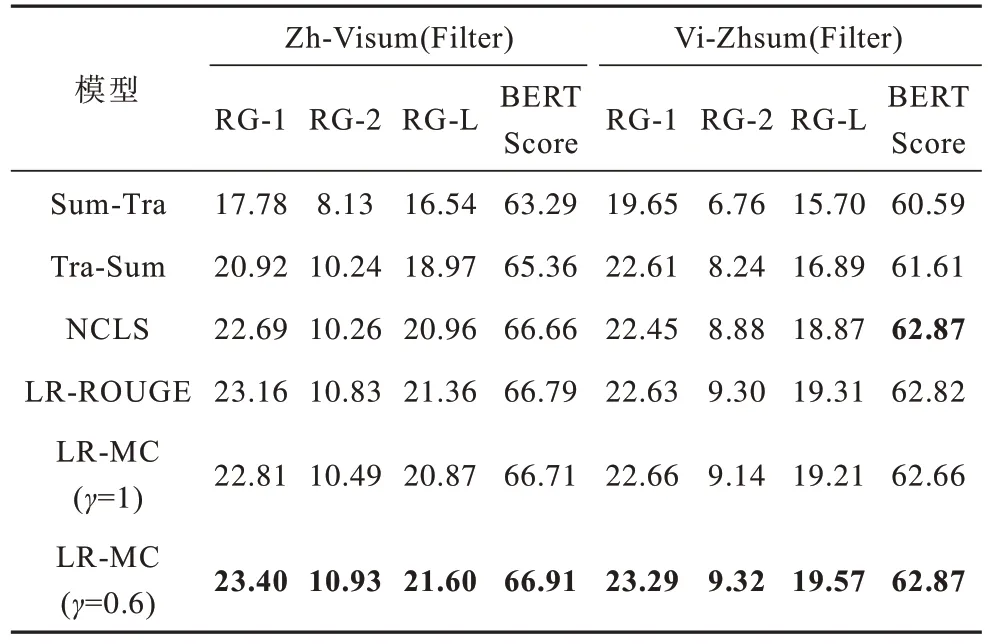
表5 不同模型的实验结果对比 Table 5 Experimental results comparison among different models
从表5 可以看出,本文提出的多策略强化学习跨语言摘要方法与基线模型相比在汉语-越南语和越南语-汉语跨语言摘要数据集上的性能均取得了提升,其中,与端到端的跨语言摘要模型NCLS 相比,LR-MC(γ=0.6)在Zh-Visum(Filter)跨语言摘要数据集上RG-1、RG-2、RG-L 分别提升0.71、0.67、0.64;在Vi-Zhsum(Filter)跨语言摘要数据集上RG-1、RG-2、RG-L 分别提升0.84、0.44、0.70,说明本文模型与传统端到端模型相比能够有效弱化汉语-越南语跨语言摘要数据集中噪声的干扰,提升跨语言摘要模型性能。与利用ROUGE-L 作为强化奖励的LRROUGE 方法相比,本文模型在RG-1、RG-2、RG-L 和BERTScore 上均取得了提升,说明利用源语言摘要与生成摘要的单词相关性和单词缺失度来设计强化学习奖励能够有效减弱汉语-越南语和越南语-汉语跨语言摘要数据中噪声的干扰,从而提升跨语言摘要模型的性能。在真实的数据上对使用噪声数据训练后的模型进行继续训练,模型性能得到进一步提升,相较而言RG-2 的提升较大,这是由于真实数据中伪摘要文本质量更高、句子连贯性更好,因此生成的摘要较之前得到了进一步提升。相比直接使用交叉熵损失函数优化模型时,加入本文所提的多策略奖励期望能有效弱化噪声,其中,在Zh-Visum 数据集 下RG-1、RG-2、RG-L 和BERTScore 分别提 高0.59、0.44、0.73 和0.20;在Vi-Zhsum(Filter)数据集下RG-1、RG-2、RG-L 和BERTScore 分别提 高0.63、0.18、0.36 和0.21。使用真实的源语言摘要计算奖励期望,相比与RG-L 计算奖励期望与交叉熵损失函数混合来优化模型性能够得到进一步提升,说明本文提出的多策略强化学习方法无论是在汉语-越南语跨语言摘要数据集或是越南语-汉语跨语言摘要数据集下都有较好的表现,同时在噪声数据下的短文本和长文本摘要任务中也表现出较优的性能,在一定程度上弱化伪目标语言摘要中噪声带来的影响。
4.5.2 消融实验
为验证本文提出的基于词相关性与词缺失度的强化学习奖励对模型性能的影响,采用各单一模块进行试验,结果如表6 所示。其中,LRmis 为只计算生成摘要缺失度作为期望奖励,LRcor 为只计算生成摘要相关性作为期望奖励,γ均为0.6。

表6 消融实验结果 Table 6 Results of ablation experiments
从表6 可以看出,只计算源语言真实与目标语言生成摘要间的缺失度计算奖励期望时(LRmis),性能下降较为明显。仅使用相关性计算奖励时(LRcor),性能下降较小。本文认为这是由2 个方面原因造成的:1)只使用缺失度时,模型得到的信息较为单一;2)缺失度只针对实词缺失这一噪声类型设计的,从第2.2 节中噪声数据的分析中可以得知,实词缺失占比小于选词不当。
4.5.3γ参数实验
γ参数实验结果如表7 所示。从表7 可以看出,当奖励期望与交叉熵损失函数相结合的参数γ为0.6时,模型性能最好。当γ值较大(γ=1.0)时,即不加入强化学习奖励时,模型在所有指标上的性能较低,表明强化学习奖励对模型的性能有积极的影响。随着γ值的减少,即奖励期望的比例增加,模型性能并没有发挥到最优。结合实验结果对解码的测试集数据观察,发现当奖励期望的比例增加时,解码得到的未登录词占比增大,这是造成生成摘要质量下降的主要原因。本文认为使用强化学习奖励作为优化目标函数,基于源语言的词级奖励中包含更多词级信息,并不包含目标语言词语间的逻辑关系与语序特征。相比与短文本汉语-越南语跨语言摘要在长文本越南语-汉语跨语言摘要中,长文中的词序以及词语间的逻辑属性关系占比更大,这也是在越南语-汉语跨语言摘要中增加奖励期望的比例时模型性能下降更多的原因。因此,即使本文设计的基于源语言词级奖励对噪声有较优的弱化作用,但不建议单独使用该奖励期望来训练模型。将奖励期望与交叉熵损失相结合,在弱化噪声的同时也可以更好地学习到目标语言词语间的语序信息,进一步提升汉语-越南语和越南语-汉语跨语言摘要模型性能。
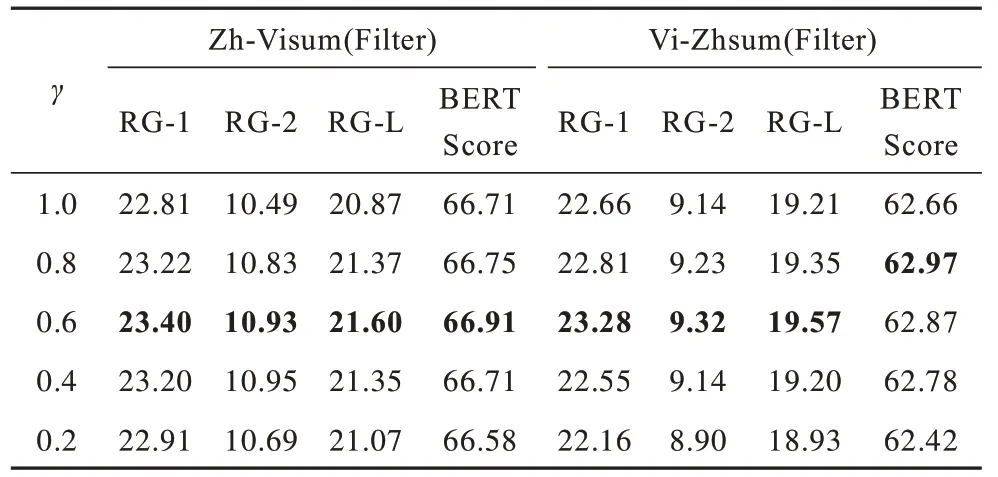
表7 γ 参数实验结果 Table 7 Experimental results of γ parameter
4.5.4 探究噪声数据对模型性能的影响
为充分探究噪声数据对神经网络模型的影响,在本实验中,使用基础的Transformer 框架进行噪声数据对比实验,结果如表8所示。All表示使用20万个未过滤的汉语-越南语跨语言摘要数据和11.579 8万个未过滤的越南语-汉语跨语言摘要数据进行训练;Filter-Bert/Mgf 表示训练数据采用过滤后的数据进行训练,其中汉语-越南语跨语言摘要数据集使用BERTScore 方式进行过滤,越南语-汉语跨语言摘要数据集使用Mgfscore 方式进行过滤;Random 表示从未过滤数据集中随机抽取相同数量的数据进行训练。
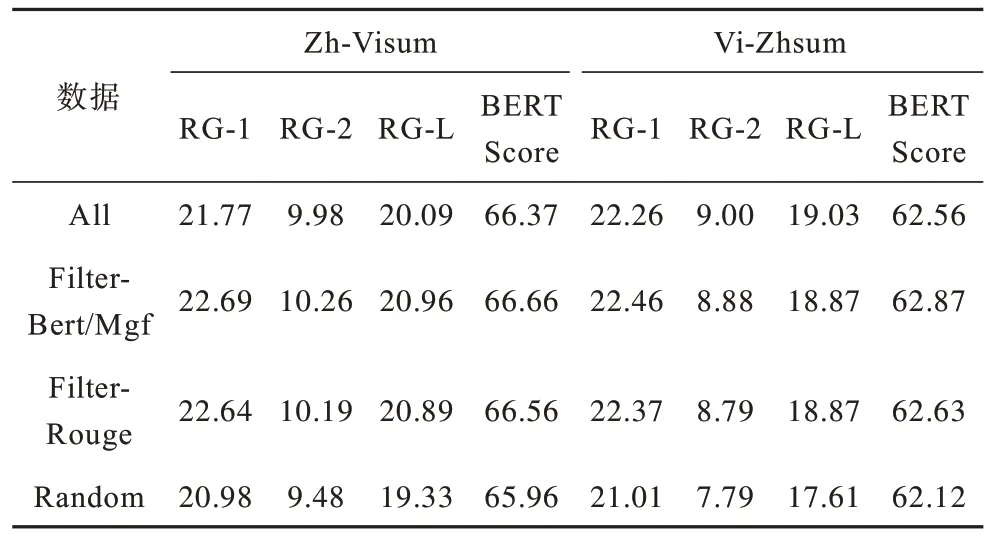
表8 在不同数据下的实验结果 Table 8 Experimental results under different datas
从表8 可以看出,神经网络模型对噪声数据较为敏感。为训练出更好的模型,需要过滤掉噪声数据。在汉语-越南语跨语言摘要数据集中,噪声数据的比例较高,经过筛选后使用前10 万个高质量数据进行训练比使用20 万个未过滤数据训练的模型更有效地生成可读性高的摘要。相对而言,越南语-汉语跨语言摘要数据的总量相对较小,但质量相对较高,过滤掉前30%的数据训练模型在RG-2 和RG-L指标上略逊于使用全部数据训练的模型。然而,不管在哪个数据集下,噪声都会对模型产生负面的影响。因此,必须从噪声数据出发对汉越跨语言摘要研究进行探索。
4.5.5 实例分析
表9 所示为不同摘要模型生成的摘要示例。从表9 可以看出,以“2 ca cách ly ngay sau khiAn Giang.76 ca ghitrongTP.Trong71 capháttrong khu cách lykhuphong.Nam có11.289 ca ghitrongvà 1.689 ca.catínhngày 27/4nay:9.719 ca,trongcó 2.280…(译文:进入安江后立即隔离了2 病例。胡志明市国内记录76 例,其中71 例已隔离或封锁。越南国内累计11 289 例,境外输入1 689 例。4 月27 日至今新增病例9 719 例,其中2 280 例已治愈……)”以越南语-汉语摘要任务为例,相较于其他摘要模型,本文模型生成的摘要质量更高,语义更连贯,且提供的信息更加完整,在内容上更加接近参考摘要。在未使用过滤数据训练的基础模型(Transformer-all),生成的摘要信息较少。经过使用高质量数据继续训练模型后,各个模型都试图生成更加丰富的信息,然而,只有本文所提的多策略强化学习汉越跨语言摘要模型才能生成关键信息:“迄今为止越南已记录#名患者”。
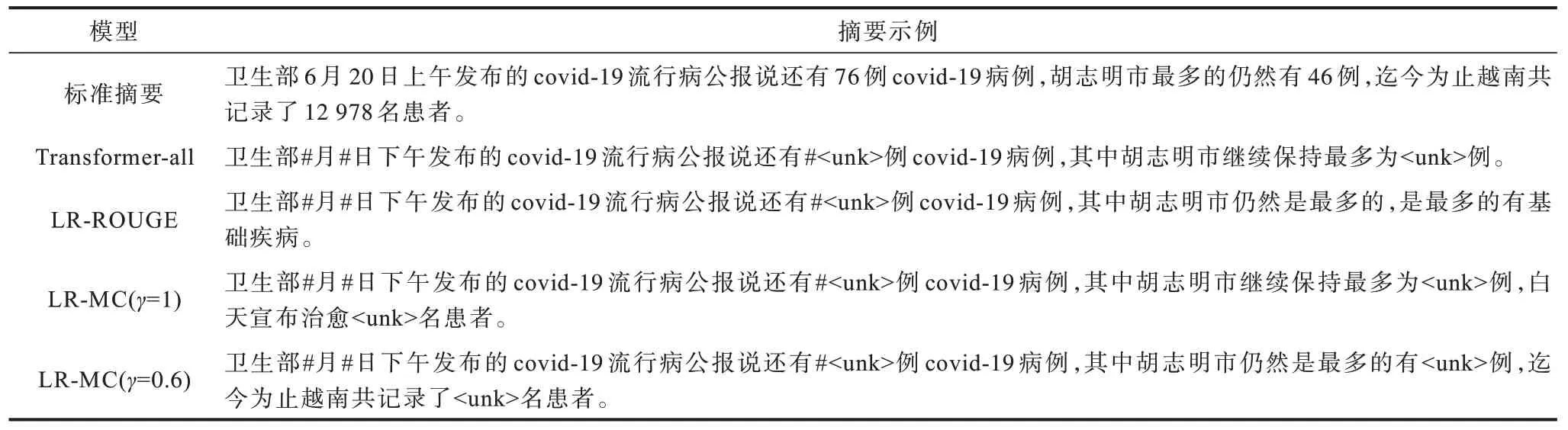
表9 不同汉语-越南语跨语言摘要模型生成的摘要示例 Table 9 Examples of summaries generated by different Chinese-Vietnamese cross-lingual summarization models
5 结束语
针对汉语-越南语跨语言摘要中的噪声、伪目标摘要中选词不当与实词缺失2 种噪声类型,本文提出一种多策略的跨语言摘要方法用于汉语-越南语跨语言摘要。基于强化学习技术,使用真实源语言摘要和伪目标语言摘要作为基准,通过计算源语言摘要与生成摘要的相关性和缺失度来计算期望奖励,弱化噪声干扰;保留传统的伪目标语言与生成摘要间的交叉熵损失,以学习目标语言间的词序关系;通过将强化学习损失函数和交叉熵损失函数相结合,优化模型训练目标,改善直接使用伪目标语言摘要训练模型时噪声数据对生成摘要质量的负面影响,从而提高生成摘要的质量。实验结果表明,引入真实的源语言摘要来设计多策略强化学习方法,能够有效提升跨语言摘要模型在噪声数据下的性能。后续将该方法扩展到其他数据集和任务中,例如针对机器翻译数据噪声问题,利用本文方法来降低噪声数据对机器翻译模型性能的影响。
