视觉机器人的零件识别与抓取方法研究
2024-02-29李荣焕吴瑞明
袁 斌,王 辉,李荣焕,吴瑞明
(1.浙江科技学院机械与能源工程学院,浙江 杭州 310023;2.杭州东城电子有限公司,浙江 杭州 310016)
1 引言
目前在物流包装运输、工业生产制造、餐饮等领域,均出现了视觉机器人的应用,机器人作为智能制造中的重要工具,因此被广泛关注[1]。零件分拣搬运是生产制造中的重要环节,为了提高视觉机器人抓取零件的成功率,提出一种视觉机器人的零件识别与抓取方法。
目标识别与定位是机器人抓取物体的前提,近年来,在视觉机器人抓取物体方面有许多解决方案被提出。文献[2]提出采用卷积神经网络识别物体和单目视觉定位物体位置的方案,并且取得较理想效果,但单目视觉定位物体需要提前知道物体的深度信息[3]。文献[4]基于双目视觉技术,采用图像特征点对目标物体进行立体匹配,获得深度信息,但识别物体时易受光线干扰。文献[5]提出一种具有自动识别与抓取物体的机械手,但检测目标时以矩形框的形式框出物体,对于L形状的物体,很难真实反映出物体真实的中心位置。
随着计算机计算能力的提高,基于深度学习的算法已经普遍应用在各个领域,根据上述物体识别与定位方法存在的不足,提出一种解决方法,首先利用YOLOv4-tiny算法识别物体,然后初步提取出ROI,并送入PSPnet[6]网络中进一步提取ROI,最后将ROI区域中的像素进行模板匹配,并引入二次项拟合求出亚像素视差。只将感兴趣的区域进行模板匹配,可以降低匹配的误匹配率,提高匹配的效率和精度。在计算中心坐标时,将分割后的图像做最大内接圆,圆心为物体中心,这样能够真实找出物体的最佳抓取点,提高抓取的成功率。
2 设备与方法
实验设备分为硬件、软件,硬件主要包括:笔记本电脑(i5-9300H处理器;12 G,2 667 MHz内存,NVIDIA GTX1650显卡);双目摄像头(型号为H-3040;分辨率3 040*1 520;帧率30帧/s;镜头焦距2.6mm);标定板GP200-5;一台视觉机器人。软件主要包括:Pytorch深度学习框架;Opencv库。
2.1 算法流程与模型
识别与定位方法的算法流程,如图1所示。主要由目标检测算法、图像分割算法、模板匹配组成。

图1 识别与定位方法的算法流程Fig.1 Algorithm Flow of Identification and Location Method
流程步骤如下:
(1)将待识别零件放入工作区,并矫正双目相机的图像畸变和采集零件图像信息。
(2)将左图像送入YOLOv4-tiny网络中,初步提取出物体所在的矩形ROI。
(3)将左图像的ROI送入图像分割网络中进一步提取ROI,并将ROI区域和右图像转为灰度图。
(4)左图像的灰度ROI区域与右图像进行初步模板匹配,并截取右图像中ROI所对应的区域。
(5)将右图像中被截取的区域送入PSPnet网络中进一步提取ROI。
(6)将右图像的ROI 进行灰度化、二值化、与运算生成新的ROI。
(7)把左图像的ROI与右图像新的ROI进行模板匹配,并计算亚像素视差。
(8)根据双目测距原理计算出物体深度信息。
(9)在左图像的ROI区域计算最大内接圆,圆心为目标物体的像素中心。
(10)根据三角形相似原理计算出目标所在位置的空间坐标。
2.2 零件目标检测
为了提高零件识别的鲁棒性,采用了深度学习方式的目标检测算法,并对检测精度、实时性、场合等因素加以考虑,最后选用YOLOv4-tiny 轻量级网络。YOLOv4-tiny 属于有监督型的深度学习算法,它是通过神经网络对物体图像进行特征提取,并按照特征对物体进行分类。监督型的网络需要采集数据集进行训练,在训练过程中会自调节到最佳的检测精度,并得出网络权重。检测网络训练完成后,当输入已训练物体的图像时,检测网络便可根据权重识别该物体,因此在实际应用过程中,只需对想要识别的物体进行打标签并训练即可。YOLOv4-tiny目标检测算法的网络主要由三部分组成:主干特征网络(CSPDarknet53-Tiny)、加强特征提取网络(FPN)、Yolo head。主干特征网络由卷积块、残差结构(Resblock_body)构成。卷积块由卷积层(Conv)、归一化函数(Batch Norm)、激活函数(Leaky ReLU)。加强特征提取网络由卷积块、上采样(Upsample)、堆叠块(Concat)构成。YOLOv4-tiny网络结构,如图2所示。

图2 YOLOv4-tiny网络结构Fig.2 Yolov4-tiny Network Structure
Leaky ReLU 激活函数是将ReLU 激活函数的负值区域赋予一个非零斜率,表示如下:
式中:ai—在(1,+∞)区间内的固定值。
检测的都是小零件,因此将先验框进行修改,第一个Yolo head将图片划分为(26×26)的网格用来检测小物体,预先设定好的先验框为(23,27),(37,58),(50,50);第二个Yolo head将图片划分为(13×13)的网格用来检测稍大物体,预先设定的先验框为(50,50),(81,82),(135,169)。
2.3 双目视觉定位
两个相机捕捉同一物体时,物体在两相机的像素平面上呈现的位置会存在差异,这种差异称为视差。双目立体视觉技术就是利用视差来计算物体的深度信息。在理想情况下,根据空间几何关系物体的深度信息可以表示为如下式子:
式中:z—目标物体深度信息;
f—焦距;
b—两相机的距离;
d—视差值。
在实际情况中相机安装、镜头畸变等因素都会产生误差,因此,在模板匹配之前需要将相机进行标定。畸变主要是径向畸变和切向畸变。畸变模型可由如下式子表示[7]:
式中:(x0,y0)—线性模型计算得出的图像点坐标;
(x,y)—真实点坐标;
δx、δy—非线性畸变函数。
根据实际情况,建立单相机的世界坐标系与像素平面坐标系之间的转换关系,表示如下:
式中:s—比例因子;(u,v)—目标物体在像素平面上的投影坐标;dX、dY—像元尺寸;(u0,v0)—主点坐标;f—相机焦距;R—旋转矩阵;t—平移矩阵;(Xw,Yw,Zw)—目标物体的世界坐标。将式子(4)简化可得:
式中:K—相机内参矩阵。
根据式子(5),建立左右相机的数学模型,可以解出物体空间坐标,其中K、R、t通过标定可以获得。
为了获得相机内、外参数和消除畸变带来的误差,采用张定友棋盘格标定法对相机进行标定。拍摄15张(5×5)mm间距的棋盘格,并导入MATLAB工具箱中进行标定。标定结果如下式子:
式中:Al—左相机内参矩阵;Ar—右相机内参矩阵;Bl—左相机畸变矩阵;Br—右相机畸变矩阵;R—旋转矩阵;T—平移矩阵。
经标定后,相机采集的图像具有极限约束的特点[8],即左相机上的目标物体与右相机上的目标物体在同一水平线上,极限约束可以大大减少模板匹配的计算量,极限约束结果,如图3所示。

图3 左右相机标定后的图像Fig.3 Images After Calibration of Left and Right Cameras
匹配算法基于区域一般可分为:全局匹配、半全局匹配、局部匹配[9]。全局匹配效果比较好,但运行速度较慢,半全局和局部匹配虽然速度较快,但容易受光线、弱纹理等因素干扰,出现误匹配的概率较大。这里的匹配方法是将目标检测后的截取框作为匹配对象,先进行粗匹配。由于目标检测算法截取框都是以矩形的形式,截取时会引入干扰像素参与匹配,从而影响匹配精度。为了更加精准找出属于目标物体本身的像素,需要将图像进行分割后再进行匹配。在图像分割领域中,传统的分割算法容易受到环境的影响,如分水岭算法。为了增加算法的鲁棒性,这里采用基于深度学习方式的图像分割算法。PSPnet算法采用MobilenetV2作为主干网络提取特征,采用金字塔池化结构进行加强特征提取。金字塔池化结构是将特征层划分为(6×6),(3×3),(2×2),(1×1)大小,然后对各自区域进行平均池化,金字塔池化结构可以很好解决全局信息丢失的问题。PSPnet语义分割网络,如图4所示。
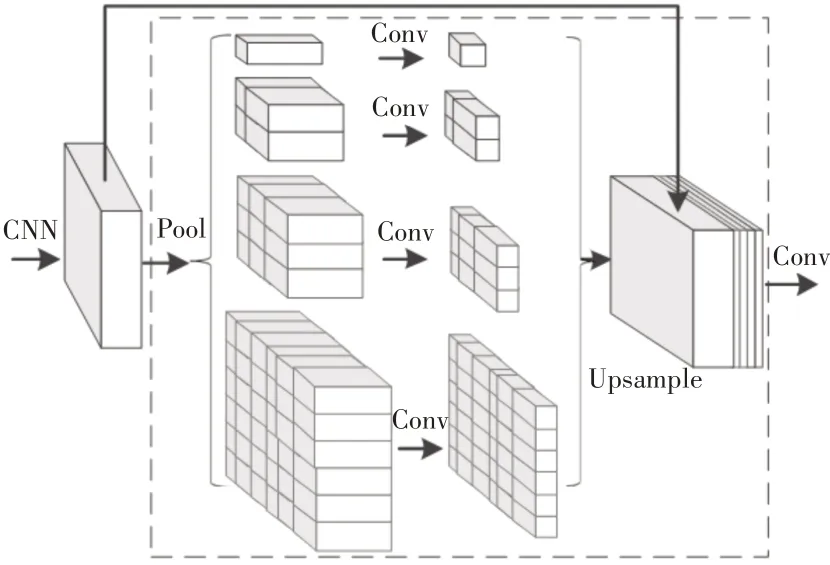
图4 PSPnet语义分割网络示意图Fig.4 Schematic Diagram of PSPnet Semantic Segmentation Network
相机经过矫正后具有极限约束的特性,因此匹配时只需将ROI在同一水平线上做搜索。粗匹配是将目标检测后的截取框送入PSPnet网络中分割所得到的新ROI与右图像进行匹配,移动步长为1像素;精匹配是将新ROI与右图像分割后的目标框进行匹配,移动步长为1像素。匹配过程中采用差值的绝对值(Sum of Ab‐solute Differences,SAD)进行相似度评估,SAD函数[10]表示如下:
式中:CSAD(p,d)—两图像像素值的绝对差;Il(p)—左图像中的待匹配区域;Ir(p-d)—右图像中视差为d的待匹配区域。
经过模板匹配得到的视差与相似度曲线,如图5所示。匹配步长为1像素,因此匹配结果为像素级单位。受文献[11]启发,为了得到亚像素级结果,首先取出相似度最高的三个坐标点,并做二次项拟合,最后将拟合出来的二次项进行最值求解,最高点坐标为(57.21,0.93),如图5(b)所示。

图5 视差与相似度曲线Fig.5 Disparity and Similarity Curve
为了确定目标物体的空间位置和提高抓取的成功率,首先对分割后的物体图像进行轮廓检测,使用OpenCV 中的cv2.find‐Countours()函数,得出轮廓矩阵。然后取出最大的轮廓Qmax,将轮廓内的坐标点与轮廓上的坐标点进行两点距离计算。当两点距离最短时,轮廓内的坐标点为最大内接圆圆心点,其式子表示如下:
式中:R—内接圆半径;
(xi,yi)—最大轮廓Qmax上的像素点;
(xj,yj)—轮廓内的像素点。
最大内接圆圆心点也是最佳抓取点(u,v),如图6所示。
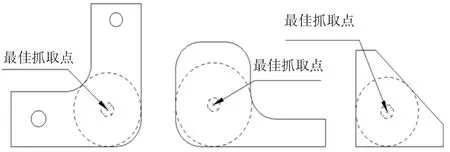
图6 零件最佳抓取点Fig.6 The Best Grabbing Point of Parts
最后结合上述的亚像素视差值,可计算出深度信息z,并根据相似性原理计算空间坐标(Xw,Yw,Zw)。
2.4 逆运动学解算与轨迹仿真
这里采用三自由度码垛机器人,根据基座坐标系与末端位置关系可得到如下变换式:
式中:cosθi—ci;其中θ—关节的旋转自由度;cos(θi+θj)—ci+j;sinθi—si;sin(θi+θj)—si+j;L2、L3—一级臂长度和二级臂长度;d0—坐标原点到一级臂旋转中心的距离。
根据式(14)可以得出,末端位置xt、yt、zt与底盘自由度θ1、一级臂自由度θ2、二级臂自由度θ3之间的关系式:
对式(15)进行求解可得到逆运动模型,如下式子表示:
根据逆运动学解算结果,利用Adams 软件进行三次轨迹仿真,为避免抓取零件时,吸盘与零件出现相对滑动,因此在抓取零件时,吸盘先移动到距离零件5mm处,然后吸盘呈现直线下降的轨迹进行抓取,同理,抬取零件时,吸盘先直线抬取5mm。这样可以提高抓取的稳定性。轨迹仿真,如图7所示。
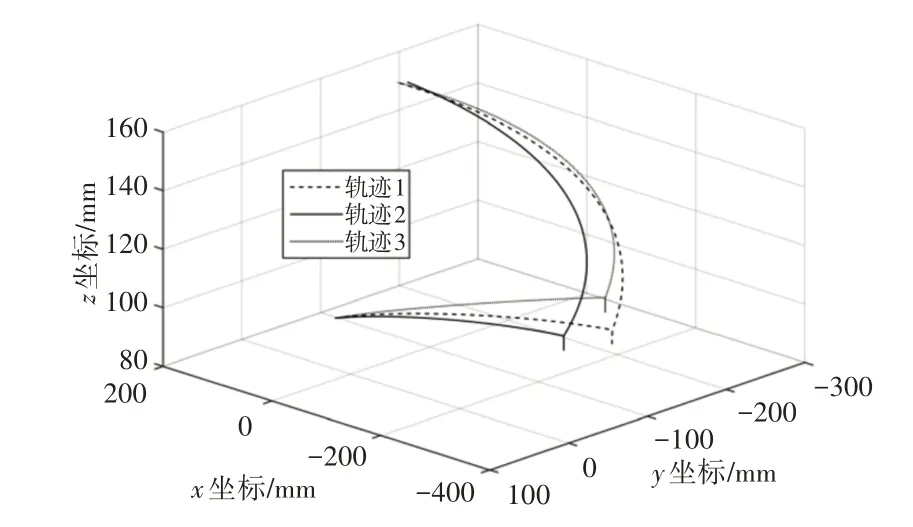
图7 轨迹仿真结果Fig.7 Trajectory Simulation Results
3 实验与分析
在机器人前方搭建工作平台,如图8所示。首先,结合现有的实验设备和需求,在平台上摆放外接矩形为(35×35)mm、(50×50)mm、(60×35)mm的三种异形且有平面的小零件,然后用双目相机对工作平台上的零件进行拍摄,拍摄1000张来自于不同时间段、光线、摆放方式等情况的图片作为数据集。训练时将代码上传到服务器进行训练,待训练完成后进行测距和抓取实验。

图8 机器人抓取实验平台Fig.8 Robot Grasping Experimental Platform
3.1 网络训练与结果
使用labelimg和labelme软件分别对目标检测数据集和语义分割数据集进行手动标注,训练时载入预训练权重,预训练权重可以加快网络模型的收敛,并设置学习率为0.001,迭代到一定的次数后再设置学习率为0.000 1。在数据集的划分中,90%为训练集,10%为测试集。网络的目标检测和图像分割效果,如图9所示。

图9 网络检测结果Fig.9 Network Detection Results
3.2 测距精度评估与抓取实验
零件的深度距离是定位的关键所在,因此,使用YOLOv4-tiny+PSPnet算法与Opencv中的SGBM算法、BM算法进行测距对比实验,并记录深度距离和计算误差率。实验结果,如表1所示。根据表中数据可以看出,这里算法深度误差基本在5mm内,小于等于吸盘的缓冲距离,通过计算得出平均误差率大约为0.72%,而SGBM与BM算法的误差率分别为1.17%、1.66%。

表1 测距试验结果Tab.1 Ranging Test Results
实验对三种不同零件进行抓取,首先,在上位机软件中输入待抓取零件的名称和数量,然后上位机软件与机器人控制端进行socket远程通信,使得机器人根据设定的需求完成自主抓取,上位机软件,如图10所示。
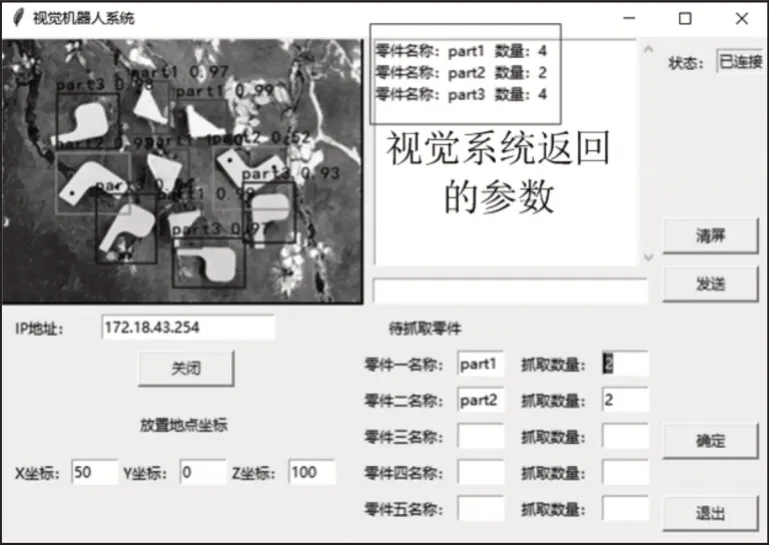
图10 机器人系统上位机界面Fig.10 Upper Computer Interface of Robot System
根据实验,记录并计算每种零件识别的平均精度(average precision,AP)和抓取率。抓取实验结果,如表2所示。

表2 抓取实验结果Tab.2 Grasp the Experimental Results
实验结果表明:设计的识别与抓取方法,零件识别精度最低95.91%,成功抓取率最低为88%。
4 结论
这里的方法是采用深度学习算法识别目标物体,在物体空间定位中,首先建立双目视觉模型进行物体定位,并引入图像分割算法提高物体的定位精度,然后对分割后的零件图像进行最大内接圆的求解,得出最佳抓取点,最后使用D-H法对机器人进行逆运动学求解。通过抓取实验验证了,该零件抓取方案的可行性,可以满足一般工业零件分拣搬运需求。
