基于元学习个性化推荐研究综述
2024-02-28吴国栋刘旭旭毕海娇范维成涂立静
吴国栋,刘旭旭,毕海娇,范维成,涂立静
(安徽农业大学信息与人工智能学院,安徽 合肥 230036)
1 引言
随着互联网飞速发展,信息量的爆炸式增长带来了信息过载[1]问题。信息过载导致消费者获取有用信息并做出有效决策的成本逐渐增加,影响了消费者的用户体验。推荐系统作为过滤信息的有效工具[2],通过对用户的历史交互信息进行统计分析,挖掘用户的偏好信息,再根据偏好信息预测该用户是否喜欢给定的项目,或者识别该用户感兴趣的K项集(top-K推荐问题)[3],以此为消费者过滤冗余信息并进行个性化推荐[4],有效地缓解了信息过载问题。传统的推荐算法一般可分为基于内容的推荐、基于协同过滤的推荐和混合推荐[5]。推荐结果根据预测对象的不同,可以分为评分预测和点击率预测。2种预测都对用户的显式或隐式反馈进行特征提取。而传统的推荐系统只利用用户-物品交互类的显式反馈[6]信息作为推荐依据实现推荐。但是,在很多场景中,用户-物品交互信息有限,新用户和新物品甚至没有交互信息,不可避免地产生了难以快速自适应推荐的问题,例如冷启动[7]等。
基于内容的推荐通过寻找与用户交互的历史物品相似的物品为用户进行推荐[8],只需利用当前用户与交互物品的特征属性信息,因此不受其他用户的限制,可解释性较好。但是,音乐、电影等场景提取属性特征困难,因此基于内容的推荐更加适用于文本、新闻等便于计算物品相似度领域的推荐,且存在较严重的用户冷启动问题。基于协同过滤的推荐是目前最流行的方法,其根据应用对象的不同划分为基于用户的协同过滤和基于物品的协同过滤[9]。其中,基于用户的协同过滤利用用户的历史交互信息挖掘用户偏好,并根据偏好对品味相似的用户互相推荐物品或信息,自动地从用户的行为数据中获取用户的偏好,因此对推荐场景无限制,应用更加广泛,但是由于依赖用户-物品评分矩阵,推荐系统的固有缺陷仍然存在,其存在的数据稀疏性问题[10]和严重的冷启动问题导致推荐质量较差,难以满足用户个性化需求[11]。混合推荐扬长补短,将不同的推荐算法通过各种方式组合后,结合不同算法的优点并弥补各种算法的不足来实现推荐,是实际应用中常采用的推荐方式,在缓解冷启动问题以及数据稀疏性问题上,优于基于内容和基于协同过滤的推荐方法。传统的推荐方法利用用户的行为信息等辅助信息完成推荐,但由于辅助信息的分布不均匀且规模较大等问题,导致传统的推荐方法仍然面临着严峻的挑战。尤其是当新物品或者新用户进入到推荐系统中时,相关用户-物品交互次数较少,系统无法提供精确的推荐,是目前推荐系统亟待解决的难题之一——冷启动问题。此外,从众多可用的推荐算法中自动选择最适合当前问题的算法,为不同偏好的用户实现个性化推荐算法选择也是制约推荐系统发展的一大难题。
元学习(Meta Learning)[12,13],因其具有从之前一系列任务中学习到有用的先验知识,再利用少量样本数据快速学习新概念或技能的能力,可以有效挖掘元知识帮助系统选择合适的推荐算法,也为缓解推荐系统冷启动问题提供了一个新的研究方向。本文对元学习在推荐上的模型以及应用分类进行了广泛的研究,主要工作有以下3点:
(1)对现有通过元学习技术提供个性化推荐的研究进行了详细的回顾。从元学习技术缓解推荐系统冷启动问题的视角,将现有研究分为3类,并分别介绍各类当前研究的优点与不足。
(2)对元学习缓解自适应推荐问题进行了分类,并将元学习自适应推荐研究分为算法的自适应选择和模型的自适应选择。
(3)指出当前研究中存在的问题,展望了元学习推荐未来主要研究方向。
本文的主要结构安排:首先对元学习的相关知识进行介绍;第2节对元学习在不同冷启动场景中应用的相关理论进行系统地分析;第3节对元学习在自适应推荐领域研究进行详细探讨;第4节对元学习的自适应推荐进行研究;第5节对元学习在推荐系统领域的研究存在的不足进行具体分析;第6节对元学习在推荐系统中研究的未来发展方向进行展望;第7节为本文的总结。
2 元学习
元学习又被称为“学会学习”(Learn to Learn),是目前深度学习领域的重点研究方向之一。传统的机器学习在大量的数据集支持下学习一个特定分类或者回归任务,存在当数据集的数量较少时无法快速学习、新的未观测任务场景中表现较差等问题。在典型的机器学习基础上,元学习提供了一个新的学习范式,先面向多个任务联合训练学习到有用的先验知识,然后在未来新场景任务时利用先验知识引导训练过程更快更好,增强学习器在多任务时的泛化能力。元学习可以在各种环境中使用[14],且在较多领域都取得较好的成果,例如小样本学习(Few-shot Learning)[15-17]方法是元学习在监督学习领域的应用。
了小样本学习可以通过新物品的少量示例样本完成精准的分类任务,解决了传统机器学习泛化能力弱、训练成本高等问题。以每个独立的少量样本数据构成的机器学习任务组成元训练任务集(Meta-train Set)与元测试任务集(Meta-test Set),其中每个任务的训练数据集称为支持集,测试数据集称为查询集。下面以小样本学习中一个N分类问题“N-wayK-shot”为例,介绍小样本学习流程(如图1所示)。

Figure 1 N-way K-shot problem of few-shot learning图1 小样本学习N-way K-shot问题
元测试任务集Ttest中的每项任务中,支持集与对应的查询集对应N种数据类别,选取K+m个样本作为每个任务的样本集,K是支持集每个类别下的样本数量,剩余m个样本作为查询集,控制m=0和m=1分别实现机器学习领域的单样本学习(One-shot Learning)[18]和零样本学习(Zero-shot Learning)[19]。实际训练过程中,为了保证元训练与元测试阶段的一致性,Ttrain的任务中设置了相同的参数N和K。通过不断地适应Ttrain中每个具体任务,使训练的模型具备一种抽象的学习能力。
元学习方法有多种分类标准,通常将元学习方法分成3类:基于度量的方法、基于模型的方法和基于优化的方法[20]。基于度量的方法和基于模型的方法的研究重点在分类任务上。与基于模型的方法相比,基于优化的方法[21]的一个关键优势是可以在更广泛的任务分配上取得更好的表现。基于优化的方法为推荐系统领域研究提供了一个新方向,在推荐系统领域应用最为广泛。部分基于优化的方法专注于学习一个好的模型初始化参数,其中Finn等人[22]提出了一个基于优化的“模型无关元学习”MAML(Model Agnostic Meta-Learning)框架,在实际中应用更为广泛。


Figure 2 Schematic diagram of MAML training process图2 MAML训练过程示意图
MAML由内外双层循环构成,以任务作为训练数据的单位,内循环使用梯度下降最小化损失得到每个任务的局部最优参数,通过局部最优参数梯度更新初始化参数θ。MAML可以匹配任何使用梯度下降算法训练的模型,并能应用于各种不同的学习问题,如分类、回归和强化学习等。但MAML也存在一些不足:MAML使用虽然不限制任何的深度学习模型,但需要模型结构都相同,只学习初始化参数,整体泛化能力较弱;二次梯度可能存在不稳定等现实问题。在基于MAML的思想上,Nichol等人[23]还进一步提出一阶梯度下降的FOMAML(First Order MAML)算法,避免了大量的计算,但同时也丢失了很多有用的信息,因此在泛化能力上仍存在缺陷。文献[23]提出一种基于参数优化的小样本学习算法Reptile,同时寻找对任务分布敏感的初始参数,并广泛适用于具有相似内在特征的任务中。Reptile算法与FOMAML本质上是相同的,但Reptile的计算效率和内存占用要优于FOMAML的,且效果优于MAML的。
3 元学习冷启动推荐相关研究
元学习的方法在推荐系统的不同领域都取得较好的研究成果。由于新用户和新物品的不断加入,而模型无法立即获得新用户和新物品的表示,如何向新注册的用户推荐商品或者将新入库的商品推荐给喜欢它的用户,这类问题就是冷启动问题。冷启动问题是所有推荐系统都不可避免的问题。元学习从不同学习任务学习到的模型,拥有快速适应少量样本的能力,与缓解冷启动问题的本质目标相同,因此为用户-物品交互有限导致的冷启动问题的研究提供了一个新的研究方向。本节从物品冷启动、用户冷启动、用户和物品冷启动3方面分别详细论述元学习冷启动推荐相关研究。
本文所述的元学习冷启动推荐相关研究算法小结如表1所示。

Table 1 Summary of research algorithms of meta-learning mitigation recommendation cold start
3.1 物品冷启动
在推荐系统中,源源不断加入新物品,但缺乏相关的用户行为数据,因此难以将其推荐给可能感兴趣的用户,导致了物品冷启动问题。物品冷启动问题在一些物品时效性较强的场景中该问题尤为突出。虽然已经有很多研究通过扩展矩阵分解方法[24]来缓解冷启动问题,但都是通过增加一些物品属性来更新物品的嵌入向量,忽略了新物品连续到达时用户嵌入表示向量的更新。
面对推荐系统中较为严峻的物品冷启动问题,Vartak等人[25]提出了基于元学习技术的2种深度学习框架,来缓解新物品连续到达时的冷启动问题。首先,通过用户交互过的物品来预测一个线性的或非线性的分类器,判断用户对新物品的偏好信息,并利用主动学习(Active Learning)[26]方法优化分类模型,实现对新物品的分类,辅助完成对用户的推荐。

Figure 3 Structure of classifier图3 分类器结构
LWA通过将抽取的每个用户的历史偏好学习作为一个元学习的任务,训练获取权重自适应的线性分类器的可训练的参数,实现权重随用户的历史交互物品自适应变化,计算新物品到来时用户喜欢的概率,权重随着不同用户有不同的取值。通过概率大小决定新物品是否推荐给用户。
与LWA相反,NLBA是为非线性的偏置自适应分类器提供可训练的参数。现实生活中,通常面临各种非线性的高维数据。NLBA利用多个隐藏层的深度神经网络来学习用户的非线性嵌入。通过深层的神经网络,可以对不同类之间、新物品与类之间的交互进行建模,学习到比LWA更多的信息。
通过LWA和NLBA 2个基于模型的调整策略,2个框架的权重或偏置根据任务信息进行调整。将物品冷启动推荐问题看作元学习问题,解决了当新事物不断到达时,离线测试得到的用户嵌入无法及时表现用户兴趣变化的问题,对用户的兴趣根据新交互及时更新,实现通过元学习方法缓解冷启动问题。但是,由于要训练2个不同的神经网络来学习物品的表示所花费的计算成本较高,也与主流的基于优化的元学习方法MAML不兼容,相比之下面对新的元学习任务快速适应能力更弱。
推荐系统中使用嵌入技术生成用户和物品嵌入向量表示,作为推荐模型的输入。嵌入向量表示生成依赖用户-物品交互数据的数量。使用大量有效的交互数据可以生成合理的嵌入向量表示,加速用户物品适应推荐模型,提升推荐效果。由于大部分物品只有少量交互甚至不存在交互,导致嵌入生成过程有严重的冷启动问题,生成的嵌入表示效果差。Pan等人[27]针对广告推荐冷启动问题,提出了基于元学习的嵌入生成方法(Meta-Embedding),缓解了交互数据有限的嵌入生成冷启动问题。
通常情况下,嵌入技术利用广告的交互信息生成广告ID(Identity Document)的低维嵌入表示,实现更高精度的点击率预测。由于新广告缺乏交互数据,难以生成理想的嵌入表示。利用元学习“学会学习”的特征,融合MAML的快速适应等优势,将每个广告作为一个元学习任务,利用学习过的广告的信息训练Meta-Embedding,使其更好地学习新物品的ID嵌入表示,实现学习共享的跨任务模型参数以及对新任务的快速适应。为新广告的ID快速生成有效的初始化嵌入,提升预测的准确率,缓解了广告的冷启动问题。
然而实际推荐过程中,由于生成冷启动的ID嵌入表示的交互数据有限,且存在错误点击等噪声数据,最终会影响生成的冷启动ID嵌入表示的合理性与稳定性。在Meta-Embedding的基础上,Zhu等人[28]提出了一个通用框架MWUF(Meta Warm Up Framework),其由元偏移网络、元拉伸网络2个元网络为基础,使用元偏移网络将全局交互过的用户作为输入,生成一个偏移函数,来加强物品ID嵌入表示,减少错误点击等行为产生的噪声,生成更稳定的嵌入表示,高效地利用有限的交互数据。
研究表明,具有高相似度的物品充分利用交互数据生成的暖ID嵌入也高度相似。依据该特征,利用相似度高的物品的冷ID嵌入间的联系,将物品的特征作为元拉伸网络的输入,生成一个定制化的拉伸函数,利用现有物品暖ID嵌入表示的均值,代替随机赋值冷启动物品ID嵌入,实现冷启动物品的ID嵌入表示的预热。
根据元学习利用模型从已知任务的训练学到的经验和知识应用在新任务上的思想,可以先根据少量的交互信息对新物品进行分类,再推荐给用户,或者利用已知物品模拟新物品的学习过程,通过在已知物品上学习到的先验知识指导生成相应参数,来代替新物品进入推荐系统时随机初始化的各个参数,从而加快新物品对推荐模型的适应,实现元学习方法缓解缺乏历史交互数据的物品冷启动问题。
3.2 用户冷启动


Figure 4 Process of meta-learning recommendation parameter update图4 元学习推荐参数更新过程
然而,MetaCS在构建元学习任务时设置相同数量的历史交互物品不符合实际。在利用历史交互物品评估用户偏好的基础上,Wei等人[30]提出了一种MAML的学习范式MetaCF(Collaborative Filtering with Meta-learning),将元学习与协同过滤推荐结合,使得协同过滤模型训练的过程中对新用户可以快速学习。将对新用户的快速适应视为一项任务,旨在学习一个合适的模型适应新用户初始推荐。为了建立一个良好的通用模型,MetaCF配备了一个动态子图采样,用于生成快速自适应的元学习任务。动态子图采样过程如图5所示。
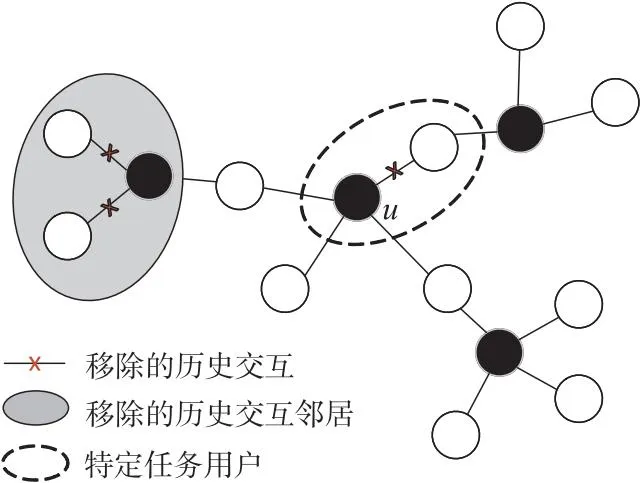
Figure 5 Process of dynamic subgraph sampling图5 动态子图采样过程
动态子图采样的实现过程为现有选中的用户u选取k个交互物品,再隐藏剩下的用户-物品交互,动态生成具有代表性的适应任务Tu来解释新用户的动态到达。在实际场景中,新用户的交互信息极少,且交互数量各异,所以在构建元学习任务时,为了模拟新用户需要对用户交互进行随机采样,采样的个数需要在特定区间内随机选取以模拟现实场景,即动态设置采样样本数量对训练图进行采样,完成每个元任务的数据集采样。目前大部分基于元学习的研究都使用图像、文本等欧几里得数据[31],将元学习应用于非欧几里得域数据的工作很少[32]。而MetaCS对非欧几里得数据进行操作,通过元训练生成全局元参数,实现自适应的用户冷启动个性化推荐。
对于系统中存在的用户和物品冷启动,主要原因是未实现根据用户真实喜好来预估用户对物品的交互可能性。Lee等人[33]提出了一种基于元学习的推荐系统模型MELU(MEta-Learned User),通过少量消费过的物品预估用户的偏好来缓解冷启动问题。在基于先前研究中候选物品不足以评估用户真实偏好的问题基础上,该模型通过元学习的MAML框架来训练已提出的用户偏好评估器,通过对用户真实且少量的消费历史来对用户进行偏好评估,使得新用户或新物品快速适应系统。
基本的用户偏好评估器通过对用户物品自带属性特征的嵌入过程来提取用户物品的有用特征,作为实现推荐的依据,但其与协同过滤推荐算法类似,具有相似属性特征的用户可能得到相同的推荐,未实现为每个用户进行个性化推荐。MELU模型结构如图6所示,在原有用户偏好评估器的基础上,对评估器的各部分参数进行元学习训练,使得这些参数既能学习到不同用户的偏好信息,实现个性化推荐,又能在新任务到来时,快速学习到用户真实偏好进行推荐。
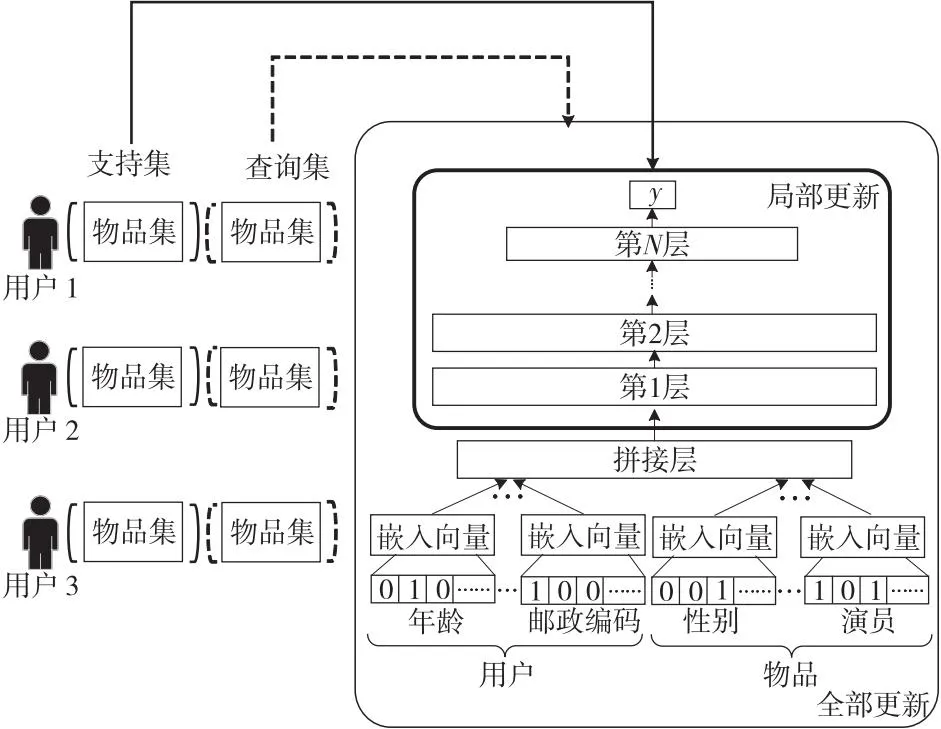
Figure 6 Structure of MELU model图6 MELU模型结构
为了模拟真实用户物品交互过程,以及保证元学习过程的稳定性,将用户偏好评估器的参数分为2个部分分别更新:用户物品生成嵌入向量过程的参数集和在嵌入基础上判断用户对物品交互可能性的参数集。因此,MELU先对后者进行局部更新,再对两者进行全局更新。
局部更新和全局更新分别对应MAML框架的内循环与外循环。较于文献[29]中提出的用户偏好评估,对用户历史的输入大小加以改进,结合了匹配网络的思想,不限制构造支持集时采样的用户历史数据数量必须相同,更加符合实际用户交互数量不均的情况,但由于用户偏好评估器学习的是大多数共享相似用户信息,容易造成任务的过拟合问题。
实际场景中存在用户分布不均匀以及配置信息不均衡等差异,导致用户信息在提取过程中存在过拟合问题。Yu等人[34]将大部分共享相似用户信息的用户定义为主要用户,其他定义为次要用户。现有大部分基于元学习缓解冷启动问题都是利用基于优化的MAML方法,而MAML方法更倾向于拟合具有相似特征的主要用户来获取更加良好的评价指标值,对主要用户优先优化而忽略次要用户。文献[34]中提出了一种全新的个性化自适应元学习PAML(Personalized Adaptive Meta Learning)方法来解决用户过拟合问题。不同于MAML设置固定的学习率,PAML方法为每个用户设置不同的学习率以便找到任务自适应参数,利用基于相似度的方法寻找具有高度相似的特征嵌入与兴趣的用户共享相似的学习率,兼顾主要用户与次要用户,对基于MAML的缓解冷启动的方法进行了优化。
通过MAML内外循环更新参数过程与新用户推荐过程的结合:每次内循环参数迭代更新,对应推荐模型学习利用少量交互获取新用户的潜在偏好,外循环参数迭代更新,对应推荐模型获得对所有新用户的潜在偏好的适应能力,使得模型学会根据用户少量交互识别用户偏好,提供精准的个性化推荐,缓解用户冷启动问题。但是,目前研究都基于新用户的少量交互提取用户偏好,难以适应没有任何交互信息的完全冷启动用户。
3.3 用户和物品冷启动
用户与物品冷启动问题在实际场景中更加广泛,推荐系统缺乏用户与项目的基本信息数据无法根据历史行为进行预测,相比单独的冷启动问题具有更高的挑战性,限制了推荐系统的性能。此外,超参数的设计也是影响推荐精度的一个重要因素。传统手工设计的优化算法通过微调超参数来收敛到一个最优解,不同场景中的最优超参数可能会有所不同,例如不同场景中的最佳学习率有显著差异,下文以超参数的设置方式对基于元学习的用户与物品冷启动研究分别进行分析。
3.3.1 手工设计超参数
Lu等人[35]提出了一种元学习MetaHIN(Meta Heterogeneous Information Network)方法来解决异质图HIN的冷启动问题,该方法解决了目前异质图上元学习相关研究的2大难题——如何在元学习环境中捕获基于HIN的语义以及如何学习到一个适用于多种语义的一般知识。根据这2个问题,MetaHIN分成2个模块,如图7所示。第1个模块一个语义增强的任务构造器(语义增强模型),第2个模块是共同适应元学习器(元学习器模型)。

Figure 7 Meta-training procedure of a task in MetaHIN图7 MetaHIN中一个任务的元训练过程


Figure 8 An example of HIN图8 异质图示例

同理,通过在支持集上获得的先验参数来测试查询集。将查询集训练的损失函数反向传播更新初始全局先验,完成对元学习模型的预训练,得到一个适用于多种语义的一般知识。当面临新物品或者新用户的元测试任务时,将接受推荐的节点和候选推荐节点输入训练好的原模型中,判断候选节点是否被推荐,通过融合HIN上下文信息的一般知识,缓解了推荐系统的冷启动问题。
Wang等人[37]同样提出了一种基于元学习缓解冷启动的推荐算法:元学习嵌入集成ML2E(Meta-Learning Embedding Ensemble)算法。文献[25]中的元学习方法虽然能通过用户的交互历史更新用户嵌入来缓解物品冷启动问题,或者基于物品的特征构建物品的嵌入向量来缓解物品冷启动问题,但都未实现更新嵌入方法缓解系统冷启动问题。文献[37]中提出的ML2E算法主要由文献[22]中基于MAML的用户偏好网络的学习方法和文献[23]中的基于Reptile嵌入生成器2部分组成,其中,用户偏好网络的学习与文献[33]中提出的MELU算法类似,都使用局部和全局更新2个层次来更新任务参数,通过局部更新来针对特定用户训练相应的偏好网络,全局更新将其特定网络泛化到所有用户适应的偏好网络。在用户的偏好网络基础上,再为新物品设计嵌入生成器以生成可行的初始嵌入。ML2E通过将偏好网络和嵌入生成器相结合来缓解各种冷启动问题,对缓解系统冷启动有较大提升。
推荐系统的推荐过程是根据用户对特定物品的喜好程度为前提实现的,因此ML2E通过元学习得到一个评估用户和物品喜好程度的函数fθμ。fθμ的参数共包括2部分,一部分是新物品的嵌入生成器参数hω,另一部分是元训练的评估器参数θμ。令pij为用户μj和物品vi的偏好预测结果,pij的计算公式如式(1)所示:
pij=fθμ(Xij)
(1)
推荐过程处理的数据Xij如式(2)所示:
Xij=(IDi,μj,vi)
(2)
处理的数据由物品的嵌入IDi、用户μj以及物品vi3部分组成。
ML2E框架如图9所示。若是用户冷启动,则利用历史物品学习用户偏好,在ID表中查找已存在的物品直接利用fθμ计算偏好实现新用户推荐;在物品冷启动场景中,新物品通过元嵌入生成器生成新物品ID插入ID表,并利用这个ID进行推荐;对于更严峻的系统冷启动场景,同时利用历史学习用户偏好以及生成新物品嵌入ID进行推荐。ML2E利用FOMAML和Reptile来分别设计用户偏好评估器和元嵌入生成器,融合两者的优点缓解冷启动问题。

Figure 9 Framework of ML2E图9 ML2E框架
3.3.2 自适应更新超参数
上述大多数元学习缓解冷启动的方法都使用MAML对参数进行初始化,通过元全局参数引导生成相应推荐模型的初始化参数实现推荐。对于每一个输入的用户,元全局参数采取相同的方式生成每个用户的局部参数,因此不能很好地辨别不同用户模式之间的内在差异,因此Dong等人[38]提出了一种记忆增强的元优化MAMO(Memory-Augmented Meta-Optimization)算法,通过记忆机制设计2个存储器[39],分别用来对用户的嵌入信息进行增强,引导元全局参数生成个性化初始参数以及捕获在不同物品上潜在的用户共享偏好。
(3)
在实际的推荐过程中,新的推荐场景经常伴随更加稀疏的用户物品交互,并且由于传统的推荐系统推荐的物品仅仅属于一个领域,并不符合实际市场跨域推荐[40]的要求。Du等人[41]提出了一种特定于场景的顺序元学习器s2Meta(Scenario-specific Sequential Meta learner),s2Meta通过聚合来自不同预测任务的上下文信息,同时利用在不同任务上学习的知识有效地适应于特定任务,从而产生一个通用的初始模型。s2Meta主要解决了3个当前存在的难点。
第一是特定场景下的推荐系统参数初始化的问题。传统的机器学习是将推荐系统的参数随机初始化,但推荐系统随机初始化参数需要很长的时间才能收敛,并且存在小样本学习过程中过拟合的弊端。因此,s2Meta采用在不同推荐场景中共享全局参数来初始化新场景的推荐系统参数,通过学习不同场景的一般知识来引导新场景的冷启动推荐。第二是超参数的更新。不同场景中的超参数有显著差异。通过构造一个更新控制器实现了比手工算法更灵活的更新策略,实现超参数的自适应更新。第三是控制学习过程停止。由于在小样本学习的过程中,从较小的训练集中学习过多会导致过拟合,影响泛化能力,因此需要在训练损失停止下降或验证集的性能开始下降之前将学习过程停止。文献[41]提出用神经网络来学习停止策略,利用一个LSTM(Long Short-Term Memory)构造停止控制器Ms计算第t个步骤的停止概率p(t)来控制每一步骤的随机停止,避免训练的过拟合。在公共数据集Amazon、MovieLens和淘宝实际场景数据集上验证了提出的模型s2Meta的有效性。结果表明,在Amazon上的召回率相较于传统的同领域或者跨领域的最先进模型的平均提高了9.41%;在MovieLens上的召回率相较于传统的同领域或者跨领域最先进的模型的平均提高2.87%;在淘宝上的召回率相较于传统的同领域或者跨领域最先进模型的平均提高了3.95%,有效缓解了新场景中的冷启动推荐问题。
4 元学习自适应推荐研究
本文所述的元学习改进推荐算法选择的研究方法如表2所示。

Table 2 Summary of adaptive selection of meta-learning improved recommendation algorithm
4.1 推荐算法自适应选择
算法选择[45]的目的是从众多可用的优化算法中自动选择最适合当前问题的算法,即对每个数据集上所有候选推荐预测算法的性能进行评估,然后选择最优预测算法[46]。混合推荐系统与传统机器学习的集成学习思想统一,通过集成不同的算法降低单个算法的误差,提高总体性能,达到更佳的推荐效果。推荐模型通过大量的用户数据进行训练来提供个性化推荐,但当用户的交互数据较少时不足以支持有效的模型训练,并且模型一般对特定用户的数据敏感,对部分用户的数据表现较好,但总体来说泛化能力弱。而基于元学习的推荐算法选择可以有效挖掘元知识帮助用户选择合适的算法,选择最有可能在特定问题上表现良好的算法[14]。
针对当前研究存在的问题,需要对不同用户进行推荐模型自适应匹配,根据用户的偏好为用户选择合适的推荐模型。对于给定的一组深度模型,Luo等人[42]提出利用元学习方法训练模型选择器和推荐模型,为每个用户从这些模型中选择一个最佳模型为其进行精确的个性化推荐,提出了如图10所示的学习框架MetaSelector,促进推荐系统中用户级的自适应模型选择。

Figure 10 Framework of MetaSelector图10 MetaSelector框架
MetaSelector定义每个元学习的任务是对一个用户选择模型的偏好学习,每一个任务都由一个用户的数据组成,对任务进行元训练。MetaSelector由基本模型模块和模型选择模块2部分组成。基本模型模块引用参数化的基本推荐模型,例如逻辑回归LR(Logistic Regression)模型、因子分解机FM(Factor Machine)模型和DeepFM(Deep Factor Machine)这些基本的推荐模型,对应参数θ得到对应的模型M(·;θ),对于输入的特征向量x,得到M(x;θ)作为最终预测结果。模型选择模块包含了一个在基本模型模块上运行的模型选择器S,将特征x作为基本模型M(x;θ)的输入,若基础模型为K个,分别表示为M1,M2,…,MK,每个模型的参数对应θk(1≤k≤K),则选择器的具体输入如式(4)所示:
M(x;θ):=
(M1(x;θ1),M2(x;θ2),…,MK(x;θK)}
(4)
选择器S输出K个基本模型的分布情况。但是在实践中,仅将x作为输入并在基本模型和最终预测上生成分布λ=S(x;φ),选择器S由φ参数化。训练过程中对应输入的支持集数据(x,y),模型选择模块将x作为输入,基本模型上生成每项分布λ,再通过将每项分布λ与基本模型模块结合,得到最终预测p(x;θ,φ),通过支持集上的标签y与得到的预测结果p(x;θ,φ)训练一个损失函数,利用损失函数更新初始化参数θ和φ,得到适应特定任务的θu和φu,即针对某一用户的初始化参数。同理,对应支持集的每一组数据(x,y),只是选择模型时应用的初始化参数是在支持集上得到的特定任务的θu和φu,与支持集上步骤相同计算查询集的损失,但是将查询集上适应任务的损失求和取平均,用来更新全局的初始化参数,而不是针对某一任务更新参数。更新全局参数的过程对应MAML框架的外循环,接收内部循环的损失信号,更新初始化参数。
更新后的参数在2个公共数据集(Movie- Lens、Amazon)和一个真实生成的数据集上与单个推荐模型以及具有模型选择的混合推荐系统相比的测试结果表明,在指标AUC(Area Under the Curve)和LogLoss上都有了进一步提高,证实了元学习对新任务的泛化能力,也表明了在实际推荐场景中的潜能。
推荐系统在实现推荐的过程中,面对不同的推荐请求对象需要采取不同的推荐方式和选取不同的推荐内容。Collins等人[46]将推荐系统面临的不同推荐请求对象情况分为宏观推荐和微观推荐。宏观推荐具体指的是向希望构建推荐系统的组织推荐性能最佳的推荐算法;微观推荐具体指的是微型推荐系统为每个推荐请求推荐最佳推荐算法。传统的算法选择通常会基于实时推荐系统收集的数据计算精度、召回率等指标来实现。但是在实际情况下,对于给定场景中算法的总体性能并不是最优的。因为一个场景中的细微差别可能会导致算法性能的显著变化,这个细微差别就是微观级别的。例如在新闻网站上有当天的时间、用户的性别和年龄、要求推荐的数量以及很多其他因素。经过实验证实,对MovieLens数据集的每一行数据,为其选择Python推荐系统库Surprise中提供的9种即用型协同过滤算法中性能最好的一个算法,但是这些不同算法整体而言,表现出的平均性能差异不大,但是针对微观级别下,每个算法的性能表现出了较大的差异,例如奇异值分解SVD(Singular Value Decomposition)算法在MovieLens的17.2%的行中性能最佳,而KNNBasline算法仅在3.92%的行中表现最优。不同于已有的在宏观层面为整个数据集增加元特征数量的研究[47,48],针对微观级别算法性能差异大的特点,尝试利用元学习学习数据间的特征关系以及该数据和算法性能之间的关系,在微观层面预测给定情况下每个用户-物品对的最佳推荐算法。通过监督式学习方式学习推荐系统推荐功能和推荐算法性能之间的关系。通过为每个算法单独训练2个模型,一个线性回归模型用来为该算法下的用户-物品对预测评分,另一个是元学习的误差预测模型,利用给定的真实评分来评估线性回归模型预测评分的损失,因此可以获得每一个算法在用户-物品对上的损失大小,选择最佳性能的推荐算法。
然而在实际情况下,可能由于数据集本身的差异,或者仅仅选择用户-物品对的原始特征作为模型输入或选择的9个基础推荐算法不合理等原因,导致提出的微观元学习的推荐器(Meta-learned Recommender)选择出的算法在指标均方根误差RMSE(Root Mean Squared Error)上表现得效果并不理想,比SVD推荐算法以及组合算法都略高,需要在模型结构、输入数据和基础推荐算法等方面进一步改进。
4.2 元模型自适应选择
实际生活中开发仿真模型[49]来代替现实世界中日益复杂的系统,以模仿实际系统的基本功能。元建模技术利用近似模型在设计和优化过程中,逐渐取代计算昂贵的仿真模型,这些模型通常被称为元模型,提供了“模型的模型”[50],即元建模指的是对模型的建模,一个模型是元模型的一个实例,通过元建模技术可以用来代替计算昂贵的模型。实际中,不同的元建模技术性能具有差异。将一系列不同的元模型组合取最优以及几个模型的最佳组合的研究,面临计算成本高的挑战。以大规模的基于元模型设计优化问题为例,为了支持优化过程,启动数百万的适应度评估,导致建立若干元模型或集合的代价过于昂贵。元建模技术和元学习是在不同领域的元层次的学习,由于元学习的计算效率和自动学习能力,它可以应用于算法选择的优化过程和计算密集型元模型推荐的过程。Cui等人[44]提出了一种基于元学习的通用元建模推荐系统,可以实现元建模推荐的自动化,该推荐系统以Rice[45]提出的模型为基础,Rice模型基于问题特征的算法选择流程示意图如图11所示。
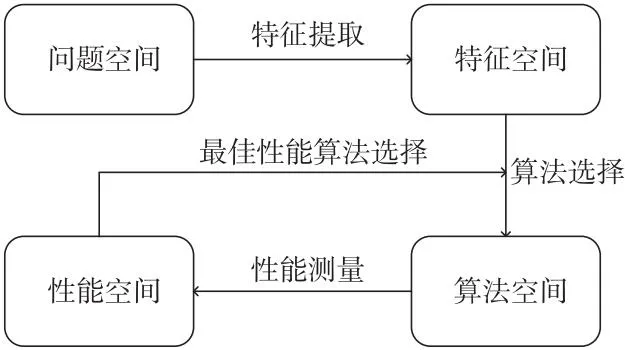
Figure 11 Schematic diagram of Rice model图11 Rice模型示意图
基于四维空间的Rice模型,将特征简化组件添加到框架中以及将元学习算法扩展为基于排名的算法,包括基于模型的学习器和基于实例的学习器,通过比较基于实例的元学习器和基于模型的元学习器在6个元模型的学习排名,增强了系统的推荐能力。提出的推荐系统框架通过元学习学习偏置自适应问题特征来自动执行元建模推荐。元学习的快速自适应能力,使得元建模推荐的时间成本大大降低,在候选元模型数量较大而先验知识较少的情况下替代传统元建模任务,解决元模型选择的问题,通过元学习学到的关系可以用来预测模型排名,促进了元建模推荐技术的研究。
5 元学习推荐研究存在的主要问题
5.1 任务分布不均匀不平衡
由于任务相互之间存在梯度冲突,不同的任务分布导致元学习个性化推荐面临许多挑战。在普通的多任务学习中,将任务分组为更加紧凑的分布通常能取得更好的效果,对于复杂的任务分布却难以适应,并且大部分元学习框架默认任务分布均匀,使用单一的学习策略可以为均匀分布任务提供一个解决方案。然而实际任务的分布通常是不均匀的,并且在推荐系统中用户的分布受到用户信息或历史交互的影响,通常是不平衡的,因此不同任务可能需要不同的学习策略,而这在现有的研究中很难实现。
5.2 计算代价高
基于优化的方法目标是通过参数优化快速学习新任务。这与经典的学习方法非常类似,然而,与传统方法相比,基于优化的元学习器可以学习优化本身,并且是在多个任务下执行参数优化得到的,这让模型可以快速学习新任务,但由于大部分基于优化的元学习方法的研究都基于MAML算法,其内外双循环的设计以及二次微分计算特性都加大了计算代价。并且推荐算法自适应选择研究中,对集成的各种模型的预训练也有较高的计算成本。
5.3 易陷入局部最优
目前关于元学习的研究都还是狭隘的元学习,大部分基于元学习的研究都是采用欧几里得域数据。缓解冷启动问题的研究大部分都采用基于优化的元学习方法,选择 MAML对模型进行训练,学习一个共享的全局初始化参数,使得不同用户具有相同的初始化参数,容易导致模型陷入局部最优的问题,减缓收敛速度。
5.4 难以提取用户隐私信息
部分基于元学习缓解推荐冷启动问题的研究需要利用各种辅助信息,生成用户和物品嵌入表示或者提取用户的偏好信息。而辅助信息例如用户的配置文件等,涉及用户的隐私。通常用户配置文件被限制获取与使用,导致部分研究在现实场景中应用受限制。
5.5 难以获取适配任务
元学习通过在元训练和元测试任务中学习元知识,指导目标任务快速适应。然而当训练任务与目标任务涉及的领域差异较大时,元学习方法效果较差,并且需要有与目标任务同量级的元训练任务支持元学习训练。
5.6 可解释性差
可解释性增加用户对推荐系统的信任与接受程度,同时提高推荐的效率。而基于元学习的算法选择研究一般采用黑盒的形式,获取的元知识可解释性差。
6 未来主要研究方向
6.1 自适应推荐任务分布
单一学习策略为均匀分布任务提供较优解。多模态分布任务,通过学习如何为每个均匀分布的任务生成多元的元先验知识,根据每个不同分布规律自适应选择最佳元先验知识。以此来适应复杂任务分布,缓解因用户信息或历史交互导致的用户分布不均的影响,进而提高推荐系统的泛化能力,可以用来解决不同任务分布不均匀、不平衡的问题。
6.2 模型参数的优化更新策略
推荐计算成本决定推荐的可实施性与有效性,基于优化的元学习使用梯度下降的方式优化模型的参数,计算成本较高且无通用最佳的优化策略。如何优化模型参数的更新策略,减少大量内外循环步骤解决计算代价高的问题,以提高整体推荐过程的时效,是一个值得研究的课题。
6.3 元学习图神经网络推荐
元学习从经验中获取知识适应新任务的能力,可以运用于非欧几里得数据,例如在图神经网络中学习图的结构信息,利用元学习方法在图上通过梯度更新快速实现知识转移,传递任务间的有用信息,对信息稀疏的图的标签和链路进行预测,学习图的局部结构,缓解图的稀疏性问题,快速适应新的图任务,解决元学习已陷入局部最优的问题,为图神经网络的研究发展提供一个新的思路,将研究的静态图扩展为动态图或扩展到交通预测、分子性质预测等现实场景之中具有较好的前景。
6.4 元学习时间序列推荐
现实世界中的推荐系统通常需要与复杂的实际场景进行交互,并且用户的兴趣时刻更新,根据用户的长期偏好以及时刻更新的短期兴趣,利用元学习提取用户的长期偏好以及稀疏的即时交互数据快速适应用户偏好变化以及捕捉潜在的隐式兴趣,缓解推荐过程中对辅助信息的依赖,为用户提供精准的个性化推荐,同时增强元学习的可解释性。
6.5 增量式元学习个性化推荐
实际场景推荐环境动态变化,需要对推荐系统模型定期使用历史交互数据与新的交互数据更新,以维持推荐算法的准确性与可扩展性。更新的速度受限于历史交互数据的规模,同时耗费时间与内存,易造成过拟合和遗忘等问题。增量式改进可以大大降低模型更新的复杂度,而元学习对历史任务的知识获取和引导新任务快速适应的能力,可以实现增量学习的思想,节约推荐系统模型更新的时间成本与内存成本,对提高推荐系统性能具有非常重要的现实意义。
7 结束语
本文对基于元学习方法缓解推荐系统冷启动问题以及自适应推荐问题的主要研究进行了分析,以及对当前研究的优缺点进行归纳总结,进一步梳理元学习推荐的一些最新研究内容。最后,指出基于元学习思想的推荐研究存在的不足,并从多个方面对其未来的研究方向进行了展望,以期对未来元学习个性化推荐提供借鉴。
