中文电子病历信息提取方法研究综述
2024-02-28吉旭瑞魏德健张俊忠
吉旭瑞,魏德健,张俊忠,张 帅,曹 慧
(山东中医药大学智能与信息工程学院,山东 济南 250355)
1 引言
近年来,人工智能和大数据的普及带动了各个行业的发展。在与人们健康息息相关的医疗行业中,每天都会产生大量的医疗数据。在这些数据中,电子病历EMR(Electronic Medical Record)的重要性不言而喻。同时,作为智慧医疗建设的重要一环,电子病历已逐渐被各大医院所使用。电子病历以病人为主体,记录着患者的个人基本信息、就诊时间、发病时间、症状、诊断结果以及患者的治疗情况。相比于传统的纸质病历,电子病历依托计算机相关技术处理患者的这些信息,从而形成结构化的病例报告,便于医生对患者进行更准确的诊断治疗。因此,如何从电子病历中提取出跟患者病情相关的信息,也就成为了现如今电子病历数据挖掘的重要研究方向[1]。
在提取电子病历信息的任务中,最为关键的2个内容就是中文电子病历命名实体识别和实体关系抽取。其中,中文电子病历命名实体识别是提取电子病历中医疗信息的第一步,实体关系抽取则是构建医疗知识数据库的基础[2]。随着深度学习在其他领域的广泛应用,很多研究人员尝试使用深度学习技术提取电子病历中的信息,也都取得了不错的效果[3,4]。
本文从国内外中文电子病历的研究现状入手,针对电子病历中的信息提取部分,分析现阶段中文电子病历在命名实体识别和实体关系抽取2方面的研究进展,讨论更加合适的应用技术,为更进一步的探索提供参考。
2 中文电子病历信息提取研究现状
电子病历是我国医疗信息化中不可缺少的部分,因此国内对于电子病历的相关研究在近年来得到了广泛关注。国外的许多发达国家在信息化建设的道路上开始较早,他们建立电子病历档案至今已经有五十多年的历史了。在政府的大力支持下,国外电子病历的规模逐渐壮大,形成了一套较为完整的医疗信息体系。国外研究人员在处理电子病历数据时,主要是在命名实体识别和实体关系抽取2个方面进行,这一点跟国内对电子病历的研究类似。不过,中文跟英文不同,它有着许多英文所不具备的特点[5]。例如,英文会用空格将2个单词隔开,这在处理时能够很好地找到实体的边界,但中文则只能以单个汉字为最小的单位来进行命名实体识别和实体关系抽取。这无疑给中文电子病历数据的信息提取带来了不小的挑战。现如今在处理中文电子病历数据时,还存在以下问题:(1)不论进行命名实体识别任务还是进行实体关系抽取任务,所使用的数据集都需要专业人员手工标注,标注的工程庞大且繁琐,这也给电子病历的信息抽取设置了无形的障碍。(2)各大医院电子病历的标准化程度不同,这样很难将训练好的模型适用于不同医院的电子病历信息提取任务中。因此,需要一些政策的指引来不断完善电子病历的标准化程度。
中文电子病历的信息提取可以将病历文本中的核心信息快速地提取出来,并且将这些知识以形式化和结构化的方式表示出来[6],从而让医生能够更加清晰地了解患者的病情,利用已经抽取好的医疗数据对病人的病情进行分析。对于中文电子病历的信息抽取流程如图1所示。

Figure 1 Process of Chinese electronic medical record information extraction图1 中文电子病历信息提取流程
其中,中文电子病历信息抽取过程中的核心任务为命名实体识别、实体修饰识别和实体关系抽取[7]。本文接下来将会探讨研究人员在处理命名实体识别和实体关系抽取2大任务时所构建的模型,详细阐述常用的各种研究方法;然后系统分析中文电子病历所面临的一些障碍并提出相应的解决方案;最后再对本文研究内容进行总结,展望中文电子病历信息抽取今后的发展趋势。
3 中文电子病历命名实体识别
命名实体识别NER(Named Entity Recognition)是对中文电子病历中的医疗信息进行抽取的第一步,它是实体关系抽取任务的基础,影响着接下来任务的进行。NER的主要目的是识别出与医疗信息相关的专业名词,例如识别出电子病历中存在的疾病名称、药品名称、症状、医疗器械名称和患者的身体部位等[8]。它可以将具有相同属性的名词归为一类,使得医生在处理病人病历时能够更高效。
对于中文电子病历的NER任务,国内外所采用的方法一共可分为3类[9]:基于规则与词典的方法、基于机器学习的方法和基于深度学习的方法。这3种方法也代表了NER技术发展的路线,但现如今研究人员大多选择将不同的方法融合在一起来处理NER任务[10-13],并取得了非常不错的效果,这也给未来NER任务研究提供了参考。
3.1 电子病历命名实体识别评价指标
中文电子病历命名实体识别常用的评价指标包括精确率P(Precision)、召回率R(Recall)和F-Measure。这3种指标都是通过真阳性TP(True Positive)、假阳性FP(False Positive)以及假阴性FN(False Negative)3个参数计算得出的。具体的计算如式(1)~式(3)所示:
(1)
(2)
(3)
其中,TP表示模型识别出正确实体的样本数;FP表示模型能够识别出实体,但识别结果不正确的样本数;FN表示没有被成功识别的样本数;α是用于平衡精确率和召回率的参数。特别地,当α=1时,评价指标可表示为F1-Measure。F1-Measure的值越高表示模型的效果越好。
3.2 电子病历命名实体识别常用方法
3.2.1 基于规则与词典的方法
基于规则与词典的方法是研究人员早期所采用的方法。该方法实际上是一种模式匹配范式。基于规则的专业词典是模式匹配的基础,词典和规则都需要人工编写。在构建词典的过程中,需要专业人员将医疗领域中的专业名词和术语等收集在一起,再进行相应的整理,最后构建出专业词典作为模式匹配的模板。在构建好词典后,再结合实体构造规则,提取出相应的实体。另外,相应的实体规则还能够弥补文本中缺少专有名词的缺陷。基于规则与词典的方法通过建立词典、制定规则,能有效地识别出相应的命名实体,同时词典的完备性和规则的可行性也直接决定着命名实体识别最终的效果。显然,这种方法实行起来难度不大,只要有专业的词典以及相应的规则作为基础,就能完成命名实体识别的任务。但是,由于国内外开展自然语言处理NLP(Natural Language Processing)的时间不同,词典的建立也存在着很大的差距。
在国外,UMLS(Unified Medical Language System)[14]和ICD-10(International Classification of Diseases 10)[15]等都是具有权威性的医疗词典,国外许多研究人员以这些权威性词典为基础,早期开发出了一些实体识别工具。Savova等[16]开发了临床文本分析和知识提取系统CTAKES(Clinical Text Analysis and Knowledge Extraction System)。该系统基于UMLS实现NER并对其结果进行评估,最终得到的最佳成绩中精确匹配的F-Measure为71.5%,重叠匹配的F-Measure为82.4%。Scott等[17]从转录的医生笔记中使用正则表达式提取出药物、剂量等命名实体。Yang等[18]使用缩写定义识别算法扩展了生物实体名称字典,提高了词典识别实体的性能,最终F-Measure达到了68.80%。在国内,杨锦锋等[19]制定了命名实体和实体关系的标注规范并构建了命名实体和实体关系标注语料库,这也为中文电子病历研究提供了一个良好的开端;苏嘉等[20]针对心血管疾病领域制定了专门的标注语料库。但是,由于对NLP的研究起步较晚,国内并没有建立像国外如此完善的医疗词典库及相关规则。建立词典需要很多专家且要花费大量的时间,成本较高,需要定期维护。因此,基于规则与词典的方法在处理中文电子病历的NER任务时使用起来较为困难。不过,一旦建造出专业性强、完备性好的词典,基于规则与词典的方法也将会为NER任务提供很大的便利。
3.2.2 基于机器学习的方法
基于规则与词典方法的缺点注定使其不能够长期被人们所用,机器学习的快速发展让研究人员更多地使用机器学习方法来处理NER任务。NER任务也转化为给每个实体赋予相应的标记。基于机器学习的NER方法主要是基于分类的方法和基于序列标注的方法[7]。相比于基于规则和词典的方法,基于机器学习的方法需要的人力更少,成本较低[21]。因此,近年来有很多研究人员使用不同的机器学习模型来进行中文电子病历的命名实体识别。
隐马尔可夫模型HMM(Hidden Markov Model)是NER任务研究初期使用较为广泛的机器学习模型,是一种序列标注方法。通过给定的输入序列,计算出概率最大的标记序列,再通过Viterbi算法得出命名实体识别序列标注的最优解。Zhang等[22]使用基于HMM的级联识别方法训练出了基于HMM的命名实体识别模型,并在GENIA V3.02 和 V1.1语料库上进行了测试,分别得到了66.5%和62.5% 的F-Measure值。但是,HMM只考虑了当前所观察的对象,这就要求文本语句上下文具有很高的独立性。电子病历的上下文联系紧密,难以实现这种独立性,因此HMM仅适用于篇幅较短的NER任务。
支持向量机SVM(Support Vector Machine)也是一种使用较为广泛的机器学习方法,是一种分类算法,早期更多地被应用于模式识别上[23,24]。由于NER可以被视为是一种分类任务,因此SVM也被应用到了此任务中。研究人员通常将其与条件随机场CRF(Conditional Random Field)模型进行比较。Lei等[25]使用自己手动创建的中文医疗文本数据集,来对CRF和SVM等机器学习模型进行评估,其中CRF模型在实验中得到了93.52%的F-Measure值,而SVM得到了90.54%的F-Measure值。通过实验也证明了基于CRF的方法在NER任务中要优于基于SVM的方法。与HMM相比,由于CRF没有特别严格的约束条件,对上下文文本可以进行灵活的归纳,从而克服了HMM无法获取长距离文本特征、缺乏多特征融合能力等缺点。因此,基于CRF的方法逐渐成为了NER任务中最受欢迎的机器学习方法。
近几年,作为对SVM的改进,结构化支持向量机SSVM(Structured SVM)在NER任务中呈现出不错的识别效果[26,27]。SSVM扩展了SVM的功能,结合了SVM和CRF的优点,能够处理有关结构化的问题。Lei等[25]在其实验中比较了SSVM和CRF在NER任务中的表现,最终SSVM得到了93.53%的F-Measure值,SSVM在命名实体识别任务中略优于CRF,证明了SSVM是机器学习方法中处理中文NER任务效果最好的。Zhang等[28]还将SSVM用于化学领域的命名实体识别并取得了不错的效果。Tang等[29]开发了基于SSVM的NER系统,比较SSVM和CRF在NER任务上的评估结果,SSVM得到了85.82%的F-Measure值,CRF得到了85.68%的F-Measure值,并且在不同实体类型识别中SSVM比CRF更好。表1对上述方法进行了总结。此外,对于连续标签问题,SSVM也有着很好的处理能力,这也说明SSVM在中文电子病历NER任务研究中有着较好的发展潜力。并且SSVM和CRF组合起来也会是NER任务中一个较好的研究方向。
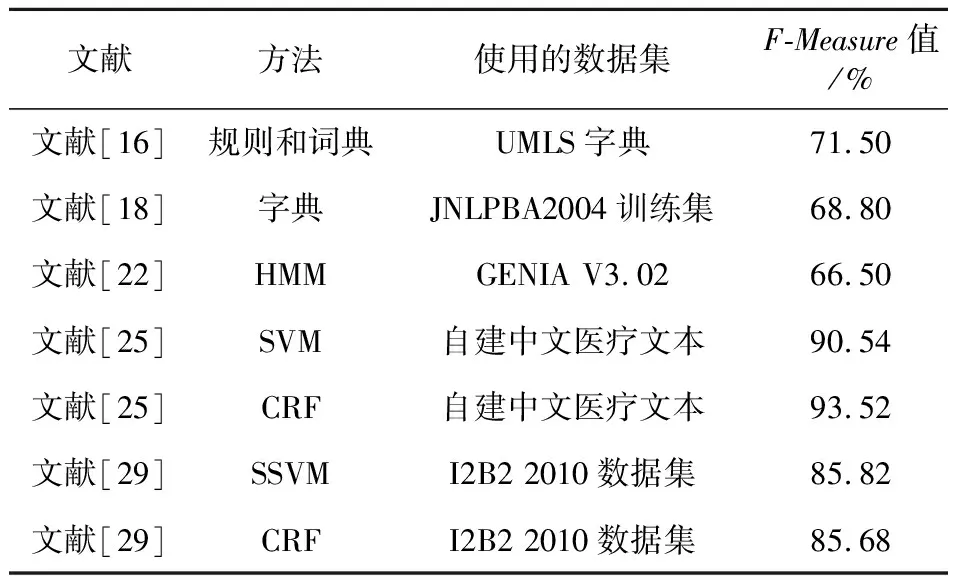
Table 1 Applications of rule-based methods and machine learning based methods in named entity recognition
3.2.3 基于深度学习的方法
近年来,深度学习逐渐成为人工智能领域主要的研究内容,并且在很多应用中都取得了不错的成果,也在一定程度上推动了人工智能领域的发展。在自然语言处理中,能够运用在中文NER任务上的深度学习模型包括长短时记忆LSTM(Long-Short Term Memory)网络、卷积神经网络CNN(Convolutional Neural Networks)、双向长短时记忆Bi-LSTM(Bi-directional LSTM)网络、Transformer模型以及BERT(Bidirectional Encoder Representation from Transformers)模型。以下分别对这4种模型进行介绍:
(1)长短时记忆网络。
长短时记忆网络是最先被广泛应用于NER任务[30,31]的深度学习模型。这种模型是循环神经网络的一种特殊类型,拥有2个传输状态cell state和hidden state,能够有效控制特征的流通和损失。同时,长短时记忆网络也是解决长距离依赖问题行之有效的模型,因此也被广泛地用于处理文本数据。LSTM+CRF模型是当时比较流行的组合模型。Dong等[32]针对中文命名实体识别任务,采用LSTM+CRF网络加强了每个字的部首偏旁,从而加强字的表示来捕捉其象形词根特征,在中文NER任务中获得了很好的性能,这也是针对中文NER任务第一个使用基于字符的LSTM+CRF模型,在SIGHAN Bakeoff-3中文语料库上最终得到了90.95%的F1-Measure值。在这个基础上,Zhao等[33]进行了创新,提出了一种基于对抗训练的网格LSTM-CRF模型AT-Lattice LSTM-CRF(Adversarial Training-Lattice LSTM CRF),得到了89.64%的F1-Measure值。在实验中,对抗训练AT不仅提高了模型的性能,还保证了神经网络方法的稳健性。
在中文电子病历的NER任务中,一个词要想被命名为一个实体,与文本的上下文通常有一定的联系。LSTM模型尽管能够处理长距离的文本信息,但是它不能够对反向的文本数据进行操作。于是,Schuster等[34]于1997年提出了双向长短时记忆(Bi-LSTM)网络。这种模型能够捕捉每个状态的上下文,使用从左到右和从右到左的2个独立隐藏状态,同时捕获过去和未来的信息,以更好地捕捉上下文的语句依赖信息。在Bi-LSTM模型被用来处理中文电子病历NER任务后,它逐渐替代了具有一定局限性的LSTM模型。
双向长短时记忆网络克服了LSTM的劣势,成为了近年来处理各个领域NER任务时使用较为广泛的模型[35,36]。与LSTM类似,研究人员发现在Bi-LSTM后面接CRF层作为输出也是一个不错的处理方法,其模型结构如图2所示。由于CRF层能够考虑标签之间的顺序问题,因此在接收到Bi-LSTM处理完的输入后,能够计算出更加精确的标签,使得提取的精度进一步提高。
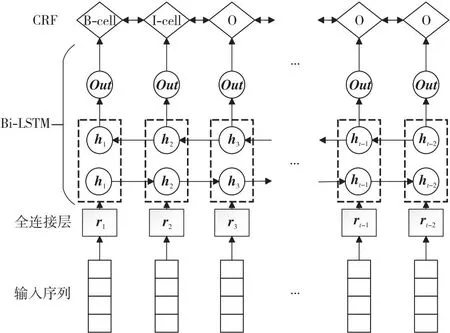
Figure 2 Basic structure of Bi-LSTM+CRF model图2 Bi-LSTM+CRF模型基本结构
Xu等[37]使用Bi-LSTM+CRF模型在公开的NCBI(National Center for Biotechnology Information)语料库上进行评估,最终得到了80.22%的F1-Measure值,其结果相对于其他广泛使用的方法要更好。还有一些使用Bi-LSTM+CRF模型的研究[38,39]在命名实体识别任务中也获得了不错的效果。Yin等[40]提出了基于字符偏旁等级和自注意力(Self-attention)机制的Bi-LSTM+CRF模型,在实验中使用CNN来提取字符偏旁的特征,得到字词之间内部的相关性,使用自注意力机制是为了捕捉上下文文本之间的依赖性。将训练得到的模型在CCKS-2017(China Conference on Knowledge graph and Semantic computing 2017)数据集上进行评估,得到了93.00%的F1-Measure值。在TP-CNER(TP-Clinical Named Entity Recognition)数据集上得到了86.34%的F1-Measure值,其结果要好于原始Bi-LSTM+CRF模型的,也证明了基于字符偏旁等级的自注意力机制在处理中文医疗NER任务中的有效性。
(2)卷积神经网络模型。
卷积神经网络近年来在计算机视觉领域取得了显著的成果,被大量应用到图像处理中[41-44],并且取得了很多突破性的进展。在NLP领域中,CNN能够在训练过程中充分利用GPU(Graphics Processing Unit)实现数据处理的并行化,这使CNN在并行计算过程中拥有很高的自由度。
CNN在处理长距离文本信息时表现一般,只能通过不断增加卷积层的个数来处理更多的输入信息,但这会导致卷积层越来越深,参数越来越多,整个模型将会变得非常庞大不易训练。基于此,Yu等[45]提出了扩张卷积神经网络(Dilate CNN),为过滤器增加了一个dilation width,但过滤器本身的大小保持不变,这样可以让过滤器获得更多输入数据,随着卷积层数的不断增加,参数的数量只以线性增加,而感受域呈指数增加,使得感受域更快地覆盖到全部的输入数据,从而解决了CNN在NER任务中的缺陷。Strubell等[46]又在上述工作的基础上提出了迭代扩张卷积神经网络ID-CNN(Iterated Dilated CNN),并且在实验中将ID-CNN同CRF融合起来,把CRF接在ID-CNN后面,在CoNLL-2003数据集上ID-CNN-CRF模型得到了90.54%的F1-Measure值,略优于NER任务中主流的深度学习模型Bi-LSTM+CRF的,并且ID-CNN-CRF在模型训练的速度上也要快于Bi-LSTM+CRF。但是不论LSTM还是CNN,它们在处理中文电子病历NER任务时都存在局限性,LSTM在处理数据时不能实现并行化操作,CNN是不能处理序列化的文本信息。而将这2个模型一起配合训练可以发挥出它们的优势,同时弥补彼此的不足,这种融合方式在未来也不失是一种较好的处理NER任务的方法。
(3)Transformer模型。
只使用注意力机制的模型是2017年由Vaswani等[47]提出来的,也是近两年来NLP领域主流的模型,并且还拓展到了其他的领域。这种模型缓解了循环神经网络训练慢的问题,使用完全基于注意力机制的方式,将自注意力机制作为编码器和解码器的核心,获得了很好的学习效果。后来的BERT模型在NLP任务中能取得良好成绩一个关键因素就是Transformer模型。
李博等[48]针对中文电子病历的NER任务,提出了一种Transformer-CRF的模型,使用Transformer来提取上下文的文本特征,并增加CRF层作为分类器进行联合解码。在实验中,通过中文电子病历数据自建数据集对比了包括Transformer-CRF在内的8种模型,在身体部位的实体识别中Transformer-CRF得到了最高的F1-Measure值 95.05%。但是,Transformer模型也存在着一定的问题,其局部特征捕捉能力相比于循环神经网络RNN(Recurrent Neural Network)略显不足。在文献[48]中,对于医疗检查和检查类的实体,由于其包含大量的英文缩写,在识别过程中文本特征较为复杂不易提取,导致模型的识别效果不佳,不过在其他医疗实体的识别中这种模型的识别效果都要好于其他模型的。尽管Transformer模型存在着一定的缺点,但它这种完全基于注意力机制的方式很大程度上促进了NLP领域的发展,也为后来BERT模型的出现打下了基础。
(4)BERT模型。
BERT模型是Google在2018年开发出来的一种用于语言表示的模型,它的内部采用全新的MLM(Masked Language Model)模型,对双向的Transformers进行预训练,这样能快速生成深度的双向语言表征。此外,微调(Fine-tune)BERT模型也能在很多下游NLP任务中获得非常好的表现。
近年来,BERT模型也逐渐被用于科学领域和生物医学领域,以提高这些领域中NLP任务的性能。不过,在中文电子病历NER任务中,仅使用BERT模型并不能够获得很好的效果。但是,通过对BERT模型进行预训练或与其他模型相结合,都能获得很多模型达不到的效果。Li等[49]使用网上爬取的中文医疗文本数据对BERT模型进行预训练,并在BERT模型上添加不同的层(包括CRF、Bi-LSTM层等)来比较各种模型的性能,还在模型中添加了字典功能以及偏旁功能,最终的模型结构为BERT+Bi-LSTM+CRF,在CCKS-CNER 2017与CCKS-CNER 2018数据集上分别进行了模型评估。在实验中,Li等[49]将BERT模型又进行了微调,微调的BERT模型要明显优于原始的BERT模型,在CCKS 2018数据集上基于FT-BERT+BiLSTM+CRF的模型得到了89.32%的F1-Measure值,该结果要优于其他先进方法的,并且集成模型获得了更高的F1-Measure值89.56%。在CCKS2017数据集上,基于FT-BERT+BiLSTM+CRF的模型得到了91.60%的F1-Measure值。在整个实验中,微调的BERT很明显提高了模型的性能,并且字符偏旁部首的嵌入以及基于字典的后处理方式也在中文NER任务中十分有效。在Li等[49]的实验中,他最开始对BERT模型进行预训练。参照这个方法,胡婕等[50]从百科知识库CN-DBPedia(ChiNa-DisamBiguation Pedia)中抽取实体来构建词典,随后利用构建的词典来对BERT进行预训练。这种方法可以免去网络爬虫所带来的数据不规范等问题,为后续中文电子病历NER的研究也提供了一种思路。
ALBERT(A Lite BERT)模型是Google在2019年开发的一种更加精简的模型[51],是BERT模型的改进版。ALBERT的参数量要远远小于之前的BERT模型的,解决了BERT模型过大、训练困难的问题。李军怀等[52]利用ALBERT模型进行预训练,提出了基于ALBERT+BGRU+CRF的模型用于中文NER任务。在这个模型中,使用ALBERT模型处理相应的文本,得到动态词的向量表示作为下一层的输入,双向门控循环单元BGRU(Bidirectional Gated Recurrent Unit)用来捕捉上下文的语义信息,并通过在CRF层中加入约束来控制错误标签的输出。此外,在MSRA(MicroSoft Research Asia)数据集上此模型得到了94.81%的F1-Measure值,要好于BERT- IDCNN-CRF模型的94.41%。ALBERT模型还能与IDCNN+CRF相结合,也能在NER任务中取得不错的效果。表2对上述命名实体识别方法进行了总结。
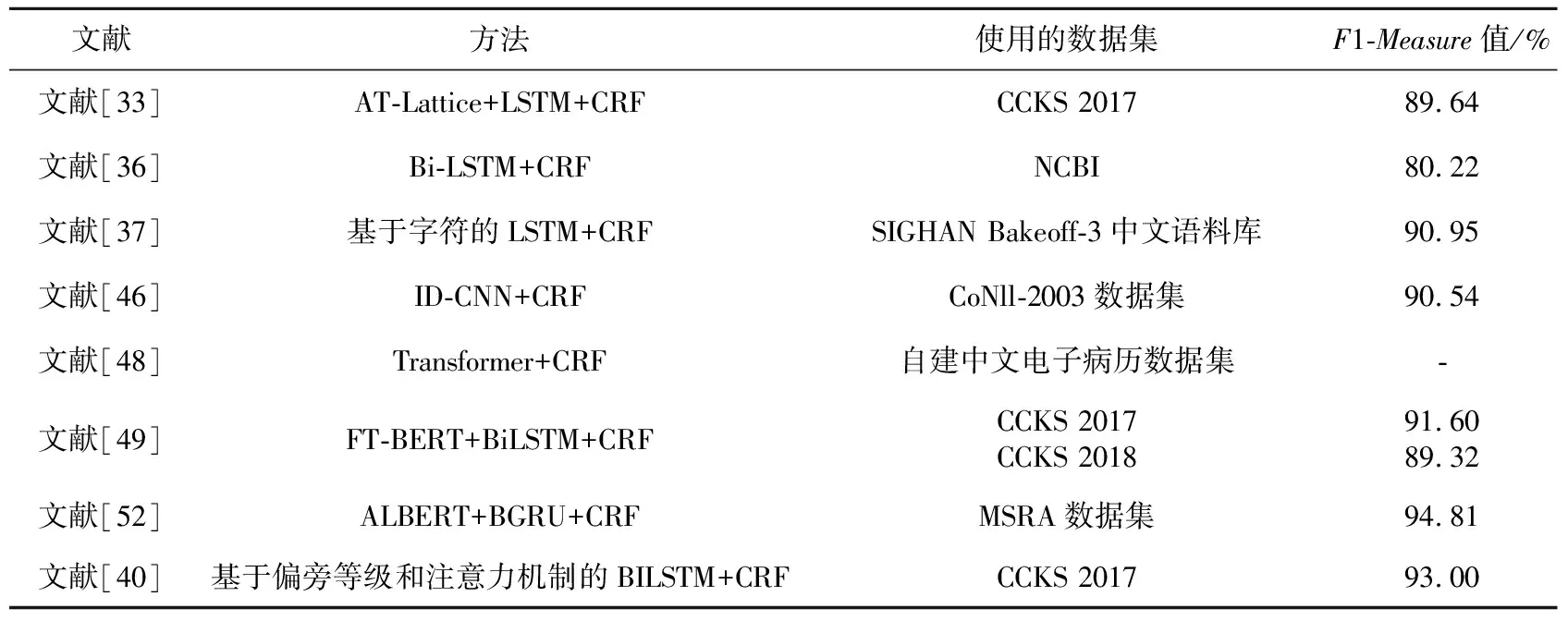
Table 2 Summary of methods based on deep learning
深度学习模型的广泛应用带动了中文电子病历NER任务的研究。图3展示了近两年中文电子病历NER技术的发展路线。目前,研究人员主要采用基于多种模型相结合的方式来进行命名实体识别。例如,Dong等[32]在模型中加入了字符;Li等[49]对BERT模型进行了微调并将其加入到了原有的模型中,还嵌入了偏旁部首。这些研究人员都利用多种模型在NER任务中取得了非常不错的效果,因此在未来的研究中,多模型组合将是中文电子病历NER任务的一个重要研究方向。表3比较了中文电子病历命名实体识别任务中所采用的各类方法及其基本思想、优点和缺点。
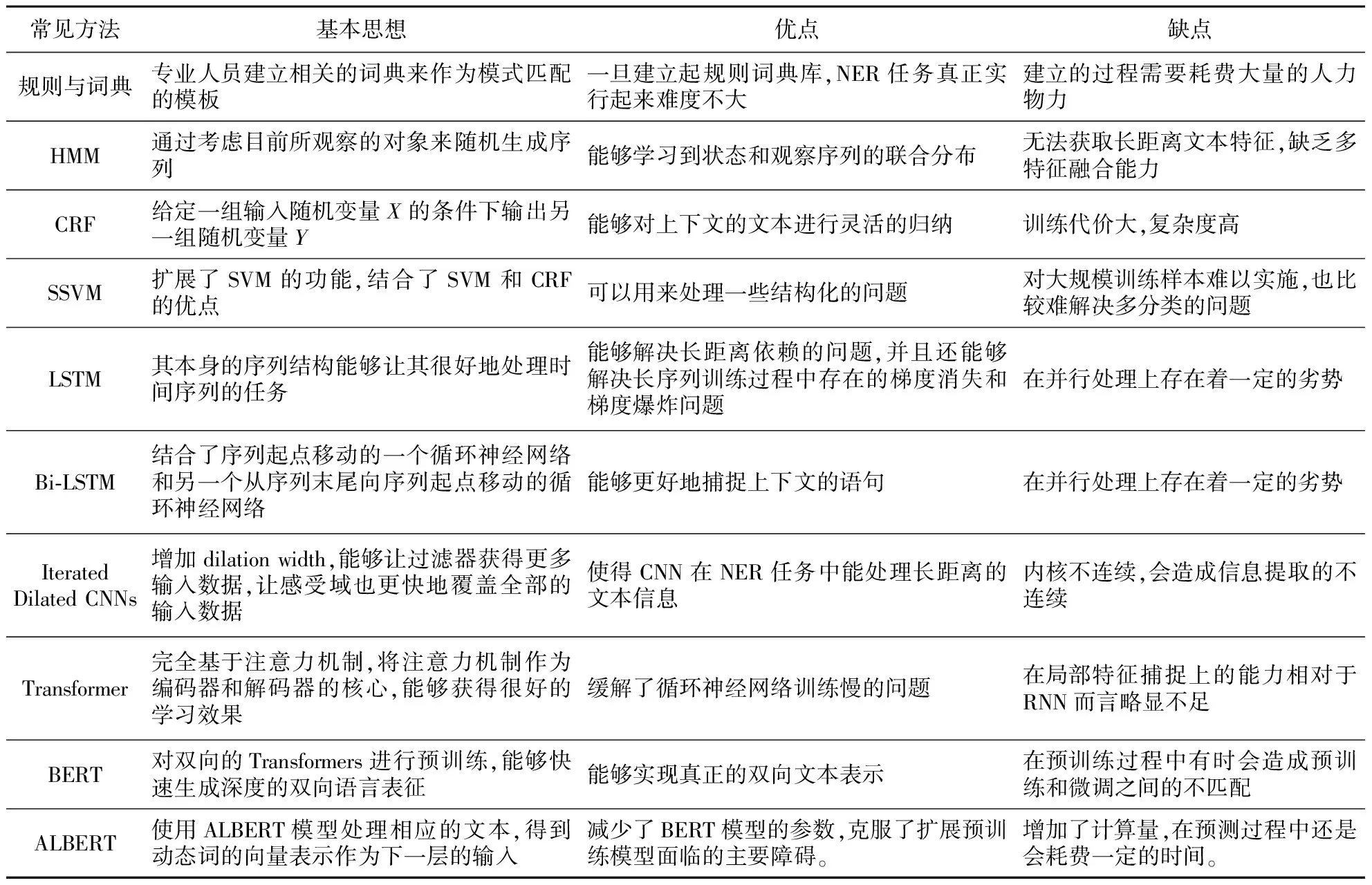
Table 3 Comparison of typical methods for named entity recognition
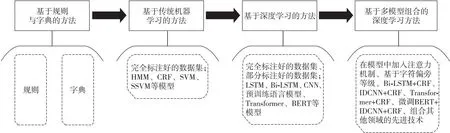
Figure 3 Development route of Chinese EMR NER technology图3 中文电子病历NER技术发展路线
4 中文电子病历实体关系抽取
实体关系抽取(Entity Relation Extraction)是NLP任务中重要的一步,是在命名实体识别任务的基础上,进一步提取出2类实体之间存在的关系。这项任务也是医疗健康知识库建立维护的基础。在电子病历中,大部分的实体之间存在着一定的关系。关系抽取任务不仅要抽取出它们之间的关系,更重要的是要识别出这些关系是属于哪种类型[53],很大程度上会影响后续电子病历处理任务。
对于医疗关系,Uzuner等[54]率先展开了研究,将医疗实体关系分为6大类:当前的疾病-治疗、可能的疾病-治疗、当前的症状-治疗、可能的症状-治疗、疾病-检查和疾病-症状。根据中文电子病历的特点,可以将医疗关系解释为更加通俗易懂的说法。例如,将疾病-症状关系类型解释为疾病导致了这种症状,疾病-检查关系类型解释为通过检查找出了这种疾病,疾病-治疗关系解释为这种疾病通过这种方式进行治疗。抽取出这些关系类型能辅助医生更加全面地了解患者的病情,对患者的下一步治疗有更加明确的方向。
目前,中文电子病历的实体关系抽取研究尚在起步阶段。综合近年来研究人员所采用的各类方法[55,56],可以大致分为3种:有监督学习的方法、半监督学习的方法和无监督学习的方法。这3种方法各有优劣,在不同的时期都发挥出了不同的作用。如今,半监督学习的方法也逐渐被广泛应用于实体关系抽取的任务中,成为了一大热门的研究方向。无监督学习的方法目前还处于探索阶段,还未出现有效的实体关系抽取方法,本文不作详细介绍。接下来本文将会对有监督学习、半监督学习近年来的研究进展进行详细介绍。
4.1 有监督学习的方法
有监督学习的方法是电子病历实体关系抽取任务早期广泛使用的方法,大多是采用机器学习和深度学习的方法来完成实体关系的抽取。在传统的机器学习方法中,使用到的方法主要是基于规则的方法和SVM等。在深度学习的方法中,主要使用深度神经网络来处理实体关系抽取的任务。这些方法在大量已标注数据集为前提的情况下能够获得较好的分类效果。
Xu等[57]提出了一种由数据驱动的模型,同时基于规则和SVM,并且在实验中创新性地使用SVM估计医疗事件之间的相关性,以更好地对各类医疗实体进行抽取,最终在中文电子病历数据集上得到了84.6%的F1-Measure值。Tao等[58]提出了一种KeMRE(Knowledge-enhanced Medical Relation Extraction)的医学关系抽取深度模型,所建造的模型共被分为4大块。首先是基于BERT-CNN-LSTM的文本建模;之后是基于 CNN-LSTM 的实体建模,用来捕捉各个实体之间的相关性;第3是建立了知识嵌入,以代表实体之间潜在的关系;最后使用MLP(Multi-Layer Perceptron)网络从实体的表示和知识嵌入中预测实体之间的关系。上述模型在自主构建的数据集上的F1-Measure要明显好于LSTM模型、CNN模型等的。随着深度学习的快速发展,有监督学习的方式也能在实体抽取中取得十分不错的效果。但是,繁重的标注工作是这类方法的一大缺陷,一旦缺少已标注的数据,模型性能会快速下降。因此,在之后的中文电子病历研究中,如何使用较少的标注数据来进行关系抽取成为了研究人员着重关注的地方。
4.2 半监督学习的方法
半监督学习的方法能够解决有标注数据集稀缺的问题。有标注的数据集难以获取,而无标注的数据集又不能够很好地训练模型,因此半监督学习的方法成为了近年来较为热门的研究方向。这种学习方法只需要少量有标注的数据集和大量无标注的数据集,就可以获得很好的效果。半监督学习关系抽取基本框架如图4所示。
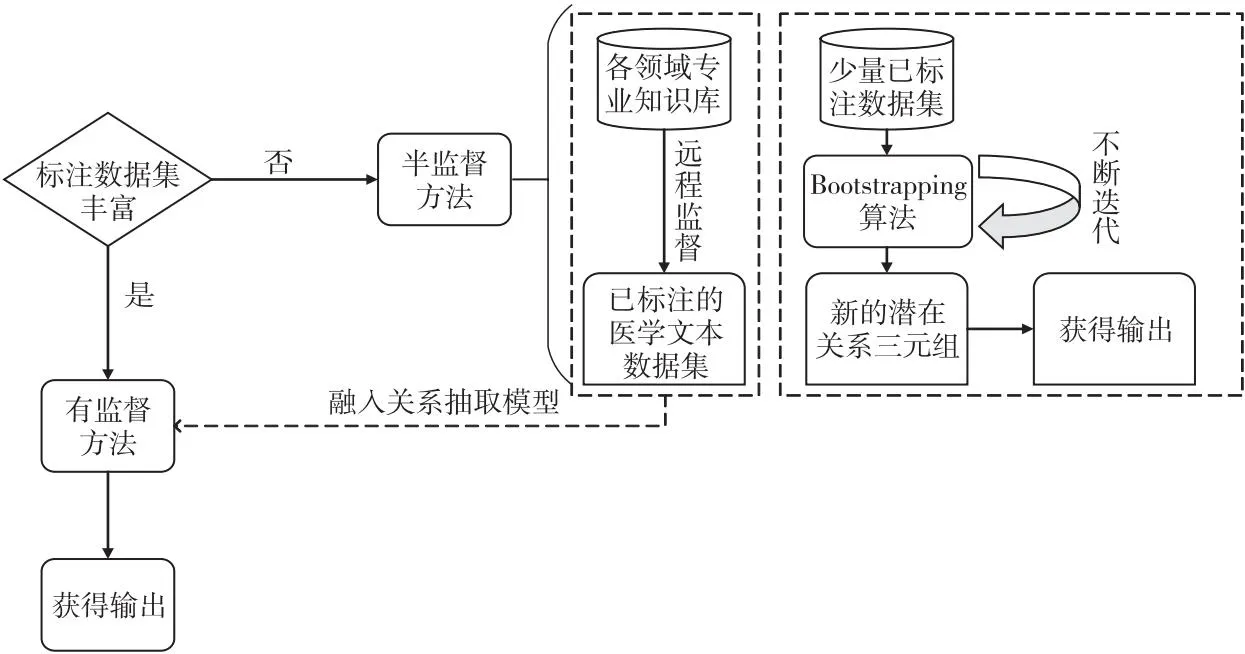
Figure 4 Basic framework of semi-supervised learning relation extraction图4 半监督学习关系抽取基本框架
在中文电子病历的研究中,标注数据集的问题尤为突出,因此半监督学习方法也逐渐被应用起来。陈立玮等[59]在解决双语关系抽取问题时提出了n-gram的模型特征来增强模型的鲁棒性,还提出了基于Bootstrapping思想的协同训练在中文知识库上进行半监督学习来强化模型,以解决数据标注的相关问题,最终在中文和英文的关系提取中这个模型能适应不同语言的需求。肖丹[60]采用了半监督学习的方法来对中文电子病历进行实体关系抽取,提出了一种基于残差网络的半监督方法。该方法结合残差网络和BiGRU(Bi-Gated Recurrent Unit)2种神经网络的优势,还融入了注意力机制,构建了ResGRU-Att(Residual Gated Recurrent Unit Attention)混合神经网络模型,并在训练过程中使用Bootstrapping半监督学习算法对没有被标记的数据集不断迭代,扩展数据集。此外,该方法还针对关系抽取任务改进了Bootstrapping算法。结果表明,多层卷积的ResNet(deep Residual Network)模型效果要明显好于单一的CNN模型的,当ResNet模型增加注意力机制以及GRU模型后获得了更好的效果,F1-Measure值达89.78%。
作为半监督学习的一种方法,远程监督也能够解决标注语料少的问题。随着人工智能的发展,远程监督通过机器学习得到了进一步的发展。在关系抽取任务中,为了避免使用到庞大的标注数据集,无监督学习的方法被应用到了关系抽取的任务中。无监督学习的方法不需要使用带标签的数据,通过聚类算法来自动归纳关系的类型,从而达到关系抽取的目的。不过,这种方法所抽取出来的关系在一定程度上规范化程度很差,而且会影响其他的关系属性。因此,Mintz等[61]在2009年第1次提出了远程监督的概念来解决上述问题,并将文本与大规模知识图谱进行对齐。远程监督既能够解决有监督学习中缺少有标签数据集的问题,又能够弥补无监督学习中关系的规范化问题。车金立等[62]基于远程监督方法提出了一种基于双重注意力机制的关系抽取模型,使用网络爬虫来筛选实验数据,再通过远程监督得到有标注的关系数据。但是,远程监督有可能会带来一部分的噪声数据。为了解决这个问题,该模型通过BI-GRU网络获取上下文语义信息,并使用字符级注意力机制来关注语义特征,利用实例级注意力机制来计算实例和对应关系之间的相关性。上述模型结合了双重注意力机制的优势,有效地处理了噪声数据,在关系抽取的任务中得到了更高的准确率。王斌等[63]提出了基于远程监督的领域实体属性关系抽取的混合方法,使用隐含狄利克雷分布LDA(Latent Dirichlet Allocation)主题模型来进行数据去噪,并且将各项特征融合用于关系抽取,实验结果表明,去噪后的训练数据更加具有代表性,上述模型训练后取得了91%的F1-Measure值。表4对上述方法进行了总结。远程监督在关系抽取任务中主要是为深度学习模型处理无标签数据,它较依赖各个领域的专业知识库。近年来,国内各科研机构已初步建立了几个中文开放百科类知识图谱的链接,包括Zhishi.me(狗尾草科技、东南大学)、CN-DBPedia(复旦大学)、XLore(清华大学)、Belief-Engine(中科院自动化所)和PKUPie(北京大学)等。这些知识图谱都已经通过OpenKG提供了开放的Dump或开放访问API。这些中文知识图谱的建立为远程监督方法在中文电子病历关系抽取上的应用提供了良好的基础。
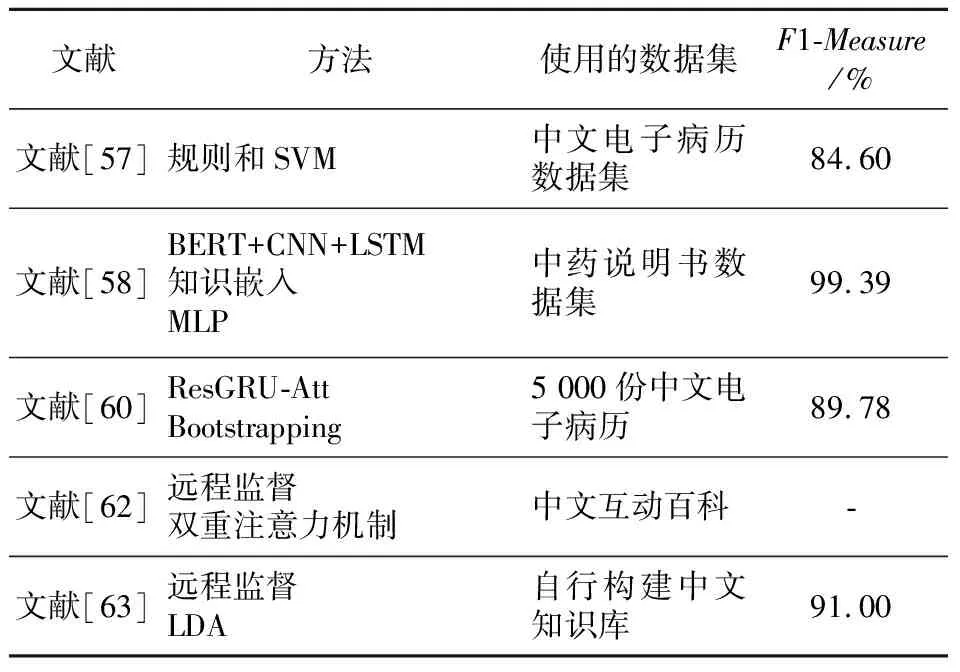
Table 4 Typical methods for entity relationship extraction 表4 实体关系抽取常用方法
5 问题分析
5.1 数据集
目前,不论是在国内还是在国外,对于电子病历的研究都需要非常庞大的医疗数据集作为基础。国外对电子病历的研究起步较早,到目前为止,已经形成了以I2B2为代表的医疗评测任务及相应医疗语料库,这在很大程度上促进了国外对于电子病历的命名实体识别和关系抽取方面的研究。并且这些数据集以及语料库还在不断地改良和完善。
在国内,由于对电子病历信息抽取方面的研究起步较晚,因此并没有形成完善的医疗语料库。为了推动中文电子病历命名实体识别研究的发展,中国知识图谱与语义计算大会CCKS(China Conference on Knowledge graph and Semantic computing)从2017年起,连续几年推出了中文电子病历命名实体识别评测任务[64,65],所用的数据集都经过了专业人员的标注,这也使得近年来国内中文电子病历的NER任务得到了突飞猛进的发展,取得了很多显著的进展。
在实体关系抽取任务上,国内的大多数研究都是使用人工标注的电子病历数据集,但标注过程中的工作量巨大且特别耗时。为了促进中文医学NLP的发展,阿里云天池实验室在近年来发布了中文医学文本实体关系抽取CMeIE(Chinese Medical Information Extraction)评测任务,并提供了评测任务所需要的数据集[66]。国外的I2B2评测任务为国内研究电子病历的NER以及关系抽取任务指明方向,发起和组织与电子病历相关的评测任务是解决现如今中文电子病历语料库缺乏的有效途径[67]。
在中文电子病历语料库的构建上,杨锦锋等[19]利用宾州中文树库 PCTB(Penn Chinese TreeBank) 标注规范[68,69]作为语料库构建的基础规范,制定了适用于中文电子病历的标注规范,并且构建了分词和词性标注的语料库,为构建中文电子病历语料库做出了杰出的贡献。随着研究的不断深入,相信在未来也会形成如同国外一样庞大的中文电子病历语料库。
5.2 模型性能
尽管深度学习近年来在中文电子病历信息提取任务中取得了较大的进步,但组合经典的模型处理相关任务也使性能达到了瓶颈。转换思路设计更合适的模型可以显著提高模型的性能。Li等[70]创新性地将NER视为机器阅读理解MRC(Machine Reading Comprehension)任务,而不是经典的序列标记问题,提出了一种MRC框架,获得了显著的效果。因此,如何将此模型推广到中文电子病历信息提取的任务中,也成了今后研究的方向之一。
此外,深度学习模型对于实体的边界不太敏感,尤其是医疗领域,实体的边界具有很高的专业性。将基于规则的词典信息引入深度学习模型是一种不错的方法,但庞大的词典使模型运行速度过慢,因此如何在保证识别准确率的基础上提高运行效率也是今后的研究方向之一。
5.3 嵌套实体的识别与提取
嵌套实体是指一个实体嵌套在另外一个实体中,例如在中文电子病历中经常会出现“肺结节”“胃溃疡”“肾结石”等嵌套实体,实体“肺、胃、肾”都被嵌套在了相应的疾病实体中。这些问题也是今后的模型需要解决的。
6 结束语
本文阐述了近年来中文电子病历命名实体识别和关系抽取方面的研究进展,选取了国内外在这些方面的典型论文,重点介绍了中文电子病历信息提取所采用的方法、建立的模型、使用的相关数据集、数据标注情况以及这些模型最终所取得的效果。
近年来,深度学习在各个领域都取得了十分显著的进展,也被应用于中文电子病历的命名实体识别和关系抽取的任务中,是诸多方法中效果最好的方法,也促进了中文电子病历信息提取领域的发展。在有关电子病历的任务中,比较常见的深度学习模型包括LSTM模型和CNN模型。近几年,多种模型融合的方式也逐渐成为了研究人员主要的研究方向。Transformer模型和BERT模型的快速应用也在NLP领域展现出了很高的性能,也推动了中文电子病历NER任务的发展。另外,图神经网络、数据增强在NLP领域中的应用等都处于前期的发展阶段,如何将它们与现有的模型进行融合也将会成为今后的研究方向。
