基于类型注意力和GCN的远程监督关系抽取
2024-02-28李卫疆
张 欢,李卫疆
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
关系抽取任务是信息抽取下属的子任务。任务目标是从非结构化文本中抽取出实体关系三元组,即〈e1,r,e2〉,其中e1和e2是关系涉及到的2个命名实体,r指2个实体间的关系类型。关系抽取可用于自动问答、知识图谱自动构建以及信息检索等自然语言处理任务,具有非常重要的研究价值。
Mintz等[1]在2009年首次提出的远程监督方法是近几年的热门研究方向。该方法通过自动对齐外部知识库获得大量带有标签的训练数据,省去了繁琐的人工标注过程。远程监督方法假设:知识库中若存在某个实体关系三元组〈e1,r,e2〉,则在自由文本中包含该实体对〈e1,e2〉的所有句子都包含r这种关系。由于假设过强,引入了大量的噪声数据。示例如表1所示。

Table 1 Sentence label 表1 句子标签
目前基于远程监督的方法[2-4]在公共关系数据集上取得了很好的效果。远程监督虽然能自动注释足够数量的训练数据,但这些数据通常只涵盖了关系的有限部分。当某些关系类型只有少量的训练样本时,模型的性能会显著下降[5]。
如图1所示,在数据集中许多关系都是长尾(long-tail)的(许多关系被标注为NA,也就是句子中给定实体对之间不存在关系),而且存在数据缺陷,造成远程监督得到的大部分句包(Riedel等[6]的“至少一次假设”将包含同一实体对的句子组合成一个句包)中只包含一个句子,这使得句包的表示并不准确。因此,在数据方面优化远程监督关系抽取显得尤为重要。

Figure 1 Frequency distribution of label without NA category图1 无NA类的标签频率分布[5]
为了解决单句子句包信息太少的问题,本文提出基于位置-类型注意力机制和GCN(Graph Convolutional Network)的远程监督关系抽取模型PG+PTATT(Piecewise convolutional neural network and GCN and Position-Type ATTention)。本文的主要工作总结如下:
(1)针对存在的句包信息不足的问题,在句包层面使用与编码方式无关的GCN进行优化,基于句包相似性将句包特征表示输入到GCN中,通过GCN的聚合性融合归纳相似句包的高阶隐含特征表示,以此得到句包全面的高阶特征信息,丰富句包的特征信息。
(2)构建新的注意力机制——位置-类型注意力机制,利用实体词与非实体词的位置关系和类型关系进行建模,降低噪声词对关系抽取结果的影响,从而解决远程监督中的错误标签问题。
(3)在真实数据集NYT(New York Times)上进行了实验。实验结果表明了本文提出模型的有效性。
2 相关工作
为解决人工标注数据繁杂的问题,Mintz等[1]率先提出使用远程监督方法来实现对自由文本的标注,以高效地产生大规模有标签的数据。由于远程监督提出的假设过于强烈,为后续任务引入了大量噪声数据。研究人员为了解决噪声数据问题,提出了多实例学习[2]、多标签多实例学习[7]和注意力机制[3]等诸多方法。
随着深度学习在关系抽取方面的应用,基于深度学习的方法取得了卓越的抽取效果[8]。Li等[9]基于标签-标签(label-label)和标签-句子(label-sentence)的关系,构建了一个新的标签图来捕获标签之间的知识;通过关系感知注意力为噪声句子分配权重,从而降低噪声句子的影响。E等[10]提出带噪声的强化学习,将参数化噪声添加到神经网络权重中,能有效改善远程监督关系提取的效果。Amin等[11]将句子级关系抽取扩展到句包级多实例学习,并提供一种简单的数据编码方案捕获潜在的关系,来减少远程监督中的噪声。
另外,在研究中也常常使用多实例学习、选择性注意力机制来解决远程监督数据集中的long-tail问题。Han等[4]提出了一种新的层次注意力方案从粗细粒度方面着手识别更有效的实例,以解决long-tail问题。Zhang等[5]提出使用知识图嵌入和图卷积网络学习隐式和显式关系知识,并通过粗到细的知识感知注意力机制将关系知识整合到关系提取模型中,最后通过分布顶端的数据来丰富类的知识以提高尾部数据差类的性能。Li等[12]通过层次关系协作和关系增强注意力来同时处理错误标签和long-tail问题。Cao等[13]提出从未标注的文本中学习关系原型,通过迁移学习来促进long-tail关系的提取。Heng等[14]提出利用辅助 BGRU(Bidirectional Gated Recurrent Unit)来提高特征提取性能,在处理long-tail关系方面的表现也相当出色。
近几年,外部信息作为辅助信息能够进一步提升关系抽取效果,为研究人员提供了新的研究方向。Vashishth等[15]使用知识库中的附加信息对关系分类施加软约束。Wang等[16]提出基于循环分段残差网络框架,并联合嵌入中的实体类型来获取句子上下文的潜在表示。Bai等[17]提出将实体类型信息集成到关系抽取模型中,结合句子级注意力和类型注意力来改善关系抽取模型的性能。Chen等[18]提出利用类型感知映射内存模块对获得的依赖信息进行编码,不仅利用了依赖类型信息,还能区分可靠的依赖信息和嘈杂的依赖信息进行降噪处理。Heng等[14]提出了一种动态双多头注意力,学习实体类型信息,动态生成多头查询向量,提供细粒度信息来过滤噪声。
以上解决long-tail问题的研究多数采用的是基于注意力机制的方法[4,5,12],通过为相关信息赋予注意力权重,从而能够识别类似关系。注意力机制的计算公式因研究人员考虑的角度不同而各有不同,且基于经过编码的向量进行计算,不能适用于其他关系抽取模型。本文提出利用可复用性高的GCN来实现句包间相似特征信息聚合,直接提供句包间细粒度的关系知识。该方法与编码方式无关,只需句包表示能够正确输入到GCN中即可,因此通过GCN来解决long-tail问题的方法是可重复使用到其他关系抽取任务中的。
此外,为了缓解远程监督带来的错误标签影响,不同于其他只使用实体类型的模型,本文同时考虑了每个单词的类型和非实体词相对于实体词的位置关系对关系抽取的影响,构建以实体词为中心的位置-类型注意力机制,为句中单词分配相应的权重,从而达到降低噪声词影响的目的。
3 PG+PTATT模型
针对远程监督,Riedel等[6]在Mintz等[1]提出假设的基础上,提出“至少一次假设(at-least-once assumption)”。该假设表述如下:若2个实体词之间存在某种关系,那么在所有这2个实体词共现的句子中,至少有一句表达了这种关系。在此假设下,远程监督将所有具有实体对〈e1,e2〉的句子都标注为关系r,并将这些句子组合成一个句包,然后在句包中解决错误标签的问题。本文模型结构如图2所示,第j个句包为bagj={s1,s2,…,sn},其中s1,s2,…,sn为句子,n为句子个数。句包中的句子经过编码之后,在输入PCNN(Piecewise Convolutional Neural Network)之前使用位置-类型注意力机制对句子向量进行优化,然后经过PCNN和GCN得到每个句包的最终表示。

Figure 2 Structure of the proposed model PG+PTATT图2 所提模型PG+PTATT结构
3.1 编码层
将源句的每个输入词转换为嵌入层中的词嵌入WE(Word Embedding)和位置嵌入PE(Position Embedding)的组合。词嵌入是将文本中的每个单词映射到一个k维实值向量的单词分布式表示,它可以捕捉单词的句法和语义属性。对于每个句子使用嵌入查找表将句子中的单词映射到实值向量中得到句子的词嵌入向量表示T={t1,t2,…,tm},m为句子中的单词个数,维度为dT。


Figure 3 Example of relative position图3 相对位置示例
3.2 注意力层
在编码层已得到的S上利用位置-类型注意力机制基于位置和类型的关系为句子特征向量添加影响因子权重,得到句包中每个句子的最终表示S′i。随后将矩阵S′i输入卷积部分。PCNN通过提取输入向量的3个局部特征并将3个特征拼接在一起,接着通过句子级注意力来对句包中的句子加权,为不同的句子赋予不同的权重,从而削弱噪声句子的影响,最后得到每个句包的初步表示。
下面介绍位置-类型注意力机制处理句子向量得到高阶注意力特征的过程。
e1和e2作为句子T={t1,t2,…,e1,…,e2,…,tm}中的不同实体,在关系抽取中识别这2个实体词间对应的关系类型时,句子中其他非实体词会对结果存在影响。为了得到更准确的关系抽取结果,需要进一步计算非实体词的影响权重,以区分非实体词对实体词间关系的影响程度。
非实体词与实体词之间最简单的关系就是位置关系,也是目前研究中使用最多的关系信息。一般来说,距离实体词越近的单词能够表达实体对之间关系的可能性越大。因此,本文利用句子中的实体词与非实体词的相对距离计算非实体词的影响权重。表2展示的是句中非实体词对实体词的距离序列。

Table 2 Example of distance sequence of non-entities to entities
得到非实体词相对于实体词的距离序列后,通过式(1)计算非实体词的影响权重,得到位置影响因子f1。
(1)
其中,x表示d1和d2序列中的某一个值,μ是期望,σ是标准差。
同时,由于句子中存在介词、冠词等无关词汇,且无关词汇与实体词间的距离并不能反映出对实体的影响,而仅利用位置关系计算单词的影响权重并不能完全代表单词在关系抽取中影响权重。本文引入单词的类型进一步计算单词的影响权重。例如,如果2个实体的类型分别是“人(PEO)”和“电影(FILM)”,那么这2个实体之间很可能存在“导演”的关系。可见单词的类型能够暗示出2个实体间的关系。
表3所示是关系抽取中部分实体词的类型标签举例。根据实体类型标签可以得到句子的类型序列,利用句子的类型序列计算非实体词对实体间关系的影响,同时在注意力机制中加入类型关系可以进行一步解决无关词汇造成的噪声影响以及利用实体词类型所隐含的信息避免关系出现错误识别。表4展示的是句子的类型序列示例。

Table 3 Type marks of partial entities

Table 4 Example of type sequence of sentences
通过单词类型标签得到句中单词的类型序列后,利用式(1)计算单词的影响权重,得到类型影响因子f2。
在分别得到位置影响因子f1和类型影响因子f2后,通过式(2)得到最后的影响因子f。
f=σ(W2f2σ(W1f1+b1)+b2)
(2)
其中,W1和W2为可学习参数,b1和b2为偏移值,σ(·)为激活函数。
然后利用Softmax函数对影响因子进行归一化处理,得到位置-类型注意力矩阵α,如式(3)所示。最后对句子表示S进行加权处理得到最终句子表示S′,如式(4)所示:
α=Softmax(f)
(3)
S′=∑α⊙S
(4)
其中,⊙代表逐元素相乘。
3.3 聚合层
GCN是一种简单有效的基于图的卷积神经网络。由于它可以通过图节点之间的信息传递有效地捕获数据之间的依赖关系,因此被广泛用于处理对象之间关系丰富的数据。GCN直接作用于图,网络的输入是图的结构信息和图中节点的特征表示。对于图中的每个节点,GCN通过融合节点附近其他节点的属性来获得节点的特征表示向量。
统计显示,在远程监督数据集 NYT上,80%的句包中只包含一个句子,而单独使用句子级注意力机制的效果并不好,单句子句包还存在特征信息不足的问题,在进行特征训练时会严重影响模型的抽取效果。经过实践后发现,大多long-tail关系在数据集头部存在类似的关系类型,所以不同句包之间有可能存在类似的隐含特征。为了丰富当前句包的特征信息,可以融合其他相似句包的隐含高阶特征。基于句包之间特征相似性,本文提出通过GCN聚合相似句包的高阶隐含特征,以此得到句包更准确全面的特征信息。这种方法不关心不同句包之间是不是具有相同的关系标签,只在乎它们之间是否具有足够的特征相似度。
本文使用余弦函数来计算2个句包的相似度,如式(5)所示:
β=similarity(bagj,bagz)
(5)
其中,j,z∈{1,2,…,batch_size},β为计算得到的2个句包间的相似度。
本文针对句包使用GCN进行优化,基于句包间的相似度,利用GCN聚合相似句包的高阶隐含特征,得到句包隐含的高阶特征。算法1描述了构造相似图的过程。
通过算法1得到句包相似图后,将其输入GCN,在l层 GCN 中,Hl表示节点在l层的特征向量。一个图卷积操作如式(6)和式(7)所示:
(6)
(7)
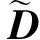
(8)
4 实验及结果分析
4.1 数据集
本文在广泛使用的远程监督数据集NYT上评估所提出的模型。该数据集是 Riedel等[6]在 2010 年发布的,其中的数据文本为纽约时报New York Times标注语料。本文使用2005年至2006年的数据作为训练集,使用2007年的数据作为测试集。本文使用的是处理过的数据集,即删除了训练集和测试集中的重复句子。该数据集总共包含39 528个唯一实体和52个关系,还有一个NA关系表示句子中的给定实体对之间不存在关系。数据集具体统计信息如表5所示。
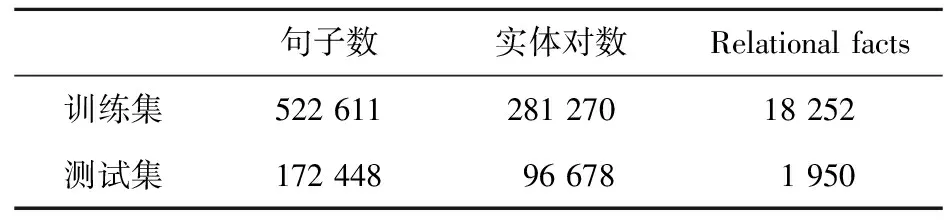
Table 5 Statistics information of NYT dataset
4.2 评估指标
与其它文献中使用的评价指标一样,本文采用F1值(PR曲线)作为本文实验的评估标准来呈现实验结果。F1值的计算如式(9)所示:
(9)
其中,Precision是精确率,Recall是召回率。F1值反映的是对精确率和召回率的综合考量。
另外,本文还使用P@N(top-NPrecision)来评估不同模型的性能。
在这个评价指标中,N表示前N个实体对,即模型在预测前N个实体对的关系时,能够正确预测的比例。例如,P@100表示模型在预测前100个实体对的关系时,能够正确预测的比例。为了计算P@N,本文会随机选择句包中One/Two/All句子,然后评估模型在这些句子中预测实体关系的能力。这里的One/Two/All句子是指:
(1)One句子:只选择1个句子进行评估。
(2)Two句子:选择2个句子进行评估。
(3)All句子:选择所有句子进行评估。
4.3 参数设置
实验沿用之前研究所使用的参数,详细参数设置如表6所示。
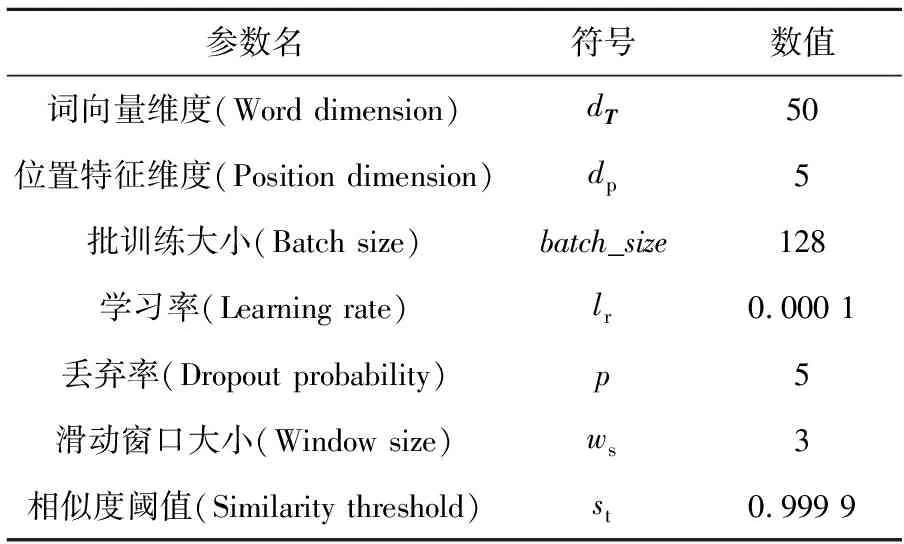
Table 6 Parameters setting
4.4 基线模型
经过综合考虑,本文选取的基线模型包括经典远程监督模型、解决long-tail问题的模型和使用实体相关信息的模型。具体如下:
(1)PCNN+ATT(ATTention)[3]:在PCNN多实例学习的基础上加入选择性注意力,以解决错误标签的问题。
(2)PCNN+ATT+SL(Soft-Label)[19]:采用软标签来缓解错误标签问题,实现了在实体对级的降噪。
(3)PCNN+BAGATT(BAG ATTention)[20]:使用句袋内注意力处理句子级别的噪声,并使用句袋间注意力处理句袋级别的噪声。
(4)SeG(Selective Gate)[21]:提出选择性门机制以缓解选择性注意力在单句子句包方面的缺陷。
(5)PCNN+HATT(Hierarchical ATTention)[4]:利用先验关系层次信息,计算层次结构中每一层的选择性注意力,并连接所有图层进行最终分类以解决long-tail问题。
(6)CoRA(Collaborating Relation-augmented Attention)[22]:在关系增强的注意力网络基础上,引入层次关系之间共享的协作关系特征,以促进关系增强过程,平衡long-tail关系的训练数据。
(7)HiRAM(Hierarchical Relation-guided type-sentence Alignment Model)[23]:从成对和分层的角度利用实体类型中的结构化信息来改善远程监督关系抽取效果,以分别减轻错误标签和long-tail问题带来的影响。
(8)RESIDE(Relation Extraction utilizing additional SIDE information)[15]:利用KB(Knowledge Base)的额外边信息来改进关系提取,使用实体类型和关系别名信息,在预测关系的同时施加软约束。
(9)GRUCapNet[14]:提出动态的双多头注意力机制,通过学习实体类型信息动态生成多头查询向量,获得细粒度信息以区分正确的实例和噪声。
4.5 实验结果与分析
为了验证所提模型的有效性,本节将其与上述基线模型在数据集NYT上进行比较,实验结果如图4和表7所示。从图4中可以观察到,本文模型F1值在一定程度上优于其他基线模型F1 值。在top-N精确度方面,与对比模型(SeG、CoRA、GRUCapNet和HiRAM)相比,性能也相差不大。
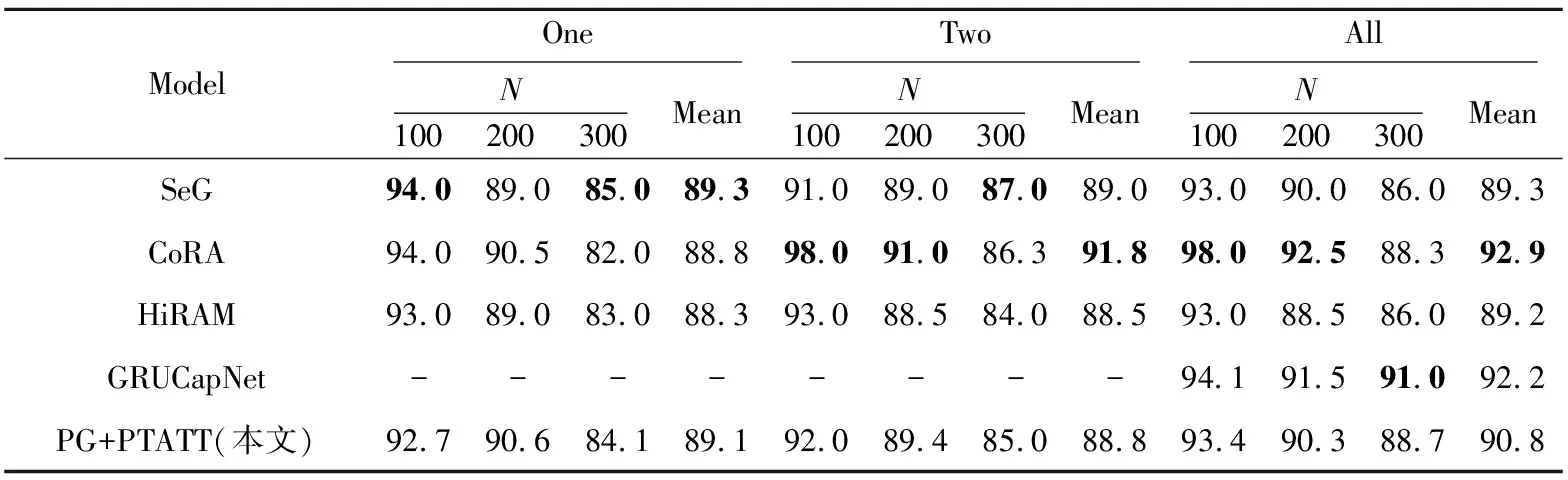
Table 7 top-N experimental results
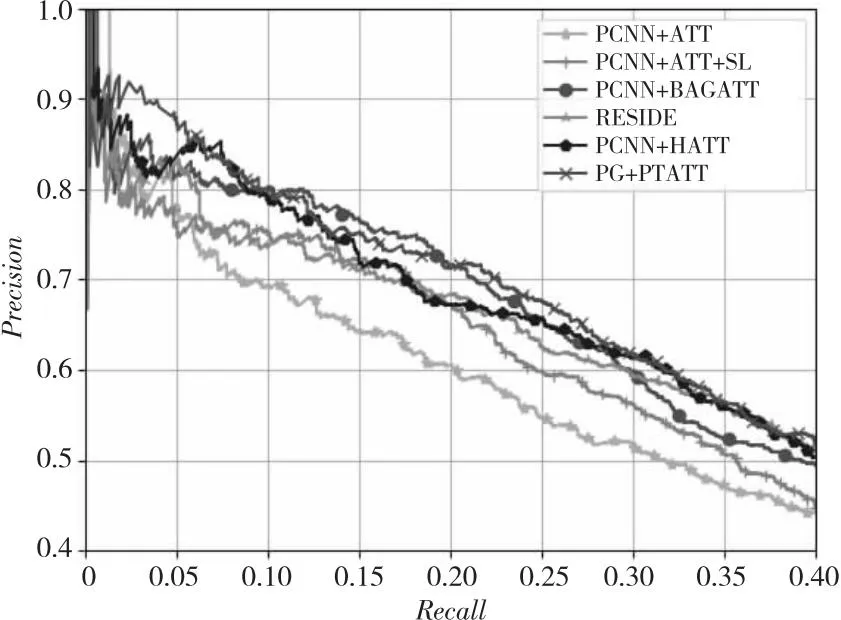
Figure 4 PR curves图4 PR曲线
与除PCNN+BAGATT以外使用注意力机制的模型相比,本文模型性能上有较大的提升,这表明本文提出的使用GCN聚合方法能够有效解决单句子句包特征信息过少的问题,从而提高模型性能。与PCNN+BAGATT模型、PCNN+HATT模型相比,本文模型性能上相差的不大。这是因为PCNN+BAGATT模型使用的是句袋级别的注意力机制来解决错误标签,在一定程度上缓解了long-tail问题带来的影响。
在使用注意力机制和实体描述信息方面,本文模型F1值大约提高了1.5%。这表明在模型中加入类型注意力信息是有效的。从图4可以看到,使用实体描述信息比单独使用注意力机制的性能更好,可见实体描述信息所提供的背景知识可以提高注意力机制模块的性能。与RESIDE相比,本文提出的模型性能高于RESIDE的,这说明与实体描述信息相比,实体类型是更精确的信息,能够使模型捕获更准确的实体语义。
从表7可以看到,对比模型与本文模型在性能上没有显著差异。SeG采用选择性门机制代替选择注意力机制,性能达到了最优。而CoRA使用关系增强注意力,GRUCapNet使用双多头注意力,本文模型使用的是位置-类型注意力机制,虽然对注意力机制改进了许多,但仍然存在局限。HiRAM、GRUCapNet和本文模型都使用了实体的类型信息,模型性能都有一定程度的提升,进一步说明实体相关信息有利于改善关系抽取效果。
5 模型分析
5.1 参数比较
本文是基于句包之间的特征相似度来解决long-tail问题,所以本节测试与相似度计算有较大影响的参数batch_size和st对模型性能的影响。batch_size是指一个批次中数据量的大小,在计算特征相似度时是依次计算某一个句包与batch_size中其他所有句包的相似度。batch_size的值越大,则可能有越多的相似句包,进而影响模型的性能。此外,batch_size的大小还影响模型的优化程度和速度。st是相似度阈值,计算特征相似度时,若超过该阈值,则视为句包相似。阈值的设定关系到最后得到相似句包的数量,关系到最后聚合得到的句包特征信息。表8展示的是batch_size∈{64,128,256}时对模型性能的影响。表9展示的是st∈{0.999,0.999 9,0.999 99}时对模型性能的影响。

Table 8 Impact of batch_size
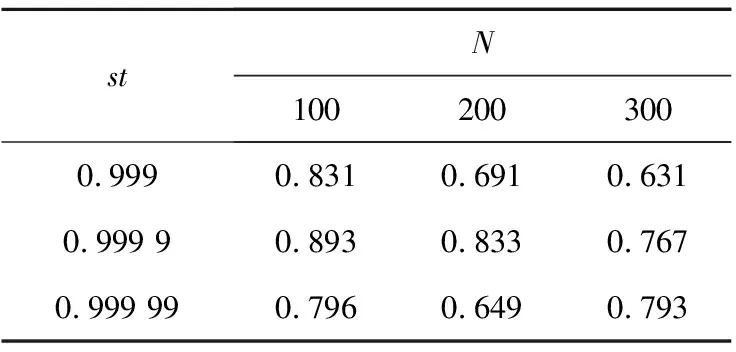
Table 9 Impact of st
从表8和表9可以看到,batch_size和st对模型性能的影响。通过实验发现,当batch_size=128,st=0.9999时,模型性能达到最佳。
5.2 位置-类型注意力的影响
本节通过实验来确定位置关系和类型关系对模型性能的影响程度,并评估位置-类型注意力机制的有效性。实验结果如表10所示。

Table 10 Impact of attention mechanism
从表10可以看出,位置、类型和位置-类型3种注意力机制都有提升模型性能的作用,且使用位置-类型注意力机制的实验结果相较于其他2种注意力机制的更好。通过实验结果验证了同时考虑句中单词的位置和类型,能够进一步强化或弱化单词的影响,在获得更多信息的同时更好地解决噪声词的问题。
5.3 GCN的影响
基于句包间的相似性和GCN的聚合性,本文利用GCN聚合相似句包的隐含高阶特征,得到句包隐含的高阶特征。在NYT数据集上进行了实验来验证GCN的有效性。但是,在GCN聚合的过程中可能会引入新的噪声信息。因为GCN本身的思想是信息的聚合与传播,图中的一个节点可能会聚合到与它相距甚远的节点信息,这种信息的聚合对节点本身不一定有用。本文通过实验来测试GCN聚合过程中噪声带来的影响。实验结果如表11所示。
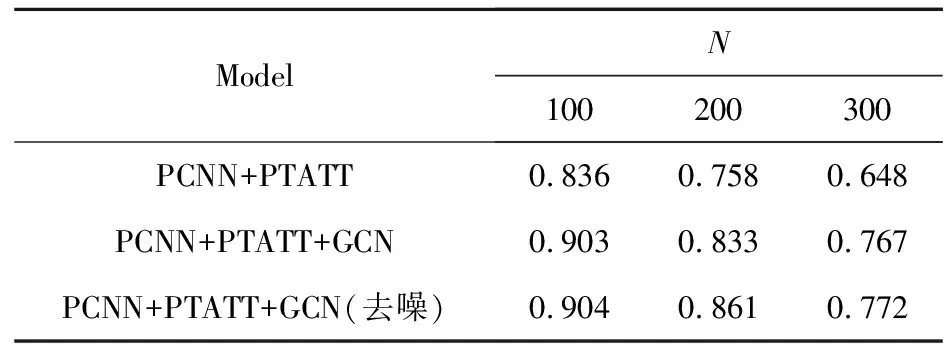
Table 11 Impact of GCN
从表11可以看到,GCN能够得到句包的全面高阶特征,从而有效提高模型性能,且经过去噪的GCN聚合的模型性能最好。
6 结束语
本文介绍了一种基于类型注意力和GCN的远程监督关系提取模型。该模型提出使用图卷积网络聚合相似句包的特征信息以丰富句包信息,从而解决由long-tail数据引起的单句子句包信息不足的问题;还提出在进入分段卷积神经网络前先施加位置-类型注意力权重来缓解句子中噪声词带来的影响,以得到更好的句子表示,进而提高模型效率。从在NYT数据集上的实验结果来看,与之前的一些模型相比,该模型性能取得了显著的改进。未来将继续探索以下内容:(1)如何同步解决句中关系的重叠问题;(2)进一步改进本文提出的注意力机制,进而探索注意力机制的多样性。
