基于ARMA模型预测的交换机流表更新算法
2020-04-07夏鸿斌
刘 钊,夏鸿斌,2
1江南大学 数字媒体学院,江苏 无锡214122
2江南大学 江苏省媒体设计与软件技术重点实验室,江苏 无锡214122
1 引言
随着新型网络技术的不断涌现,网络流量的增长也变得十分迅速,不同的网络应用对于网络资源的需求也变得越来越高。传统网络体系结构由于自身结构的僵化[1]越来越不能满足用户和业务的需求。传统网络架构将转发平面和控制平面[2]紧密耦合在独立的设备中,很难对网络进行全局把控,增加了部署新型网络应用的难度。下一代可编程的网络架构软件定义网络(Software-Defined Networking,SDN)[3]应运而生,它通过将传统网络中的数据平面和控制平面解耦,将网络逻辑与网络设备分离开来,降低了网络的复杂性和组网成本。SDN架构以简单、可编程的方式控制网络,它使得分布式的数据平面由一个集中控制的平面来管理。图1 给出了SDN网络体系结构与传统网络体系结构的分层视图。

图1 (a) SDN架构网络体系结构
图1 (b) 传统网络体系架构
在SDN 网络体系中,控制器通过OpenFlow[4]协议中的控制信道,对其管理域内的所有交换机进行配置。SDN 交换机将信息保存到本地的流表中。在进行数据转发的过程中,交换机根据其本地流表中的流表项对数据包进行匹配,并根据该流表项中的动作对数据包进行转发,而未找到对应的流表项的数据包将会被交换机转发给控制器。控制器根据转发来的数据包生成新的转发规则并下发给交换机,同时对交换机中的流表进行更新。在实际的应用部署中,流表一般存储在交换机的三态内容寻址存储器(Ternary Content Addressable Memory,TCAM)[5]中。由于TCAM的高成本与高能耗,其所能存储的流表项数量也是十分有限的。研究表明[6-7],在SDN 数据中心中,90%的数据流为老鼠流,而10%的大象流却传输了超过90%的字节,而处理这些老鼠流的流表项大量的占据了交换机的流表空间。由于对这些使用频率较低的流表项的更新不及时,导致了交换机中流表的匹配率不能满足实际的需求[8],流表资源不能被充分利用。与此同时,随着网络规模的不断扩大,控制器也不可避免地暴露出处理能力有限的问题[9]。流表匹配率过低以及控制器端负载过重严重降低了SDN系统的整体性能。
2 相关工作
为了解决上述问题,相关学者展开了很多研究。文献[10]提出在SDN中部署权威交换机,并将一部分流表项存储在权威交换机中,并使其行使部分控制器的功能。当一条新流到达普通交换机时,由权威交换机直接向普通交换机添加相应的转发规则。这样的设计使得原本需要在控制器处理的大部分数据流,在权威交换机处即可得到解决,有效减轻了控制器的负担。但是这种做法并不符合当前OpenFlow 协议的规范,需要对当前SDN 网络模型进行大规模修改才能实现。文献[11]提出将流表的更新方式与排队系统进行类比,将流表模型转化为排队模型,并通过排队论分析了hard_timeout对阻塞概率与流截断次数的影响。该方法通过调整timeout 值有效提高了流表的匹配率,但对控制器造成的负担较重。文献[12]提出了一种OpenFlow 交换机流表自动控制机制,用于解决在大数据流下交换机流表更新不及时造成的流表资源不足的问题。但是该方案所提出的对流表项停滞时间的优化处理仍然是静态优化,不能满足交换机在真实网络环境下的需求。文献[13]和[14]提出了基于新增流表项数量预测并动态调整流表中流表项空闲超时时间的方法。在这两种方法中,控制器通过分析每次的新增流表项数量,预测下一个取样周期内新增加的流表项数量,并且根据当前流表空间的使用情况动态调整流表项超时时间。其中,文献[13]使用AR 模型对下一个取样周期内新增的流表项进行预测,文献[14]使用的预测算法是基于二次平均移动的。他们的方法很好地克服了静态优化的缺点,提高了流表资源的使用效率,但在调整流表项停滞超时时间的过程中,未能考虑每一条流表项自身的特点,没有根据每条流表项的使用频率做出调整,因此具有进一步的改进空间。文献[15]提出了一种基于LRU 的改进型流表更新算法。他们将流表中的空闲空间作为一个缓存区,用于存放过期的流表项,并对每一条过期流表项进行计时。当有到达交换机的数据包与缓存区中过期的流表项相匹配时,该流表项被重新激活。在缓存区中存在时间最长的流表项在流表空间不足时将被优先删除。这种方法的优点在于可以使SDN交换机尽可能多的保存使用频率高的流表项。但在网络高峰期时,SDN交换机的流表并没有太多空闲空间可以被用作缓存区,其所能存储的流表项太少也就失去了意义。
针对上述问题,本文提出了一种基于ARMA 模型预测的流表更新算法。算法通过收集每个单位时间内新增加的流表项数量,预测下一个时刻的新增流表项数量,并根据预测值提前删除一定数量的最近一段时间内使用频率较低的流表项,为即将到来的数据流预留出足够的流表空间。算法在提高流表匹配率的同时也减少了与控制器的交互次数,有效减轻了控制器的负担。
算法框架如图2所示。

图2 算法框架
3 流表更新的一般方法
OpenFlow 标准协议通常采用基于先进先出(First In First Out,FIFO)的、基于随机(Random)的、基于最少使用(Least Recently Used,LRU)的、基于最不经常使用(Least Frequently Used,LFU)的更新算法对流表资源进行管理。在交换机流表空间不足时,更新算法通过控制器主动地向下层的交换机发送消息来删除旧流表项。其中FIFO 置换算法和Random 置换算法的区别很小,在对流表进行更新的过程中二者都有很大的随机性。所以本文下面将对FIFO、LRU、LFU等流表更新算法进行阐述。
3.1 基于先进先出的置换算法
基于先进先出的(FIFO)的流表更新算法因为实现过程简单,更新效率相对较高,因此经常将该算法作为流表的更新算法。该算法的核心思想为:当流表空间不足时,总是优先选择在流表中存在时间最久的流表项进行删除,即最先在交换机中安装的流表项将被最先删除。交换机流表中的Duration_sec字段记录了每条流表项在交换机中存在的时间,该值越长说明该流表项越早被安装。实现FIFO算法的伪代码描述如下。
算法1 基于先进先出的(FIFO)置换算法FIFO_FlowEntryReplacement
输入:数据流Flows={p0,p1,…,pn}
输出:流表FlowTable
FIFO_FlowEntryReplacement()
{for ∀pi∈Flows do
{//将当前数据流pi的数据包封装在Packet_in 消息中发送给控制器
Packet_in_message ←sendPacket_in(pi)
//控制器提取流表项信息
FlowEntry ←getFlowEntry(Packet_in_message)
//获取交换机当前流表
FlowTable ←getFlowTable()
If(FlowTable is not full):
//控制器发送Flow_mod消息给交换机安装流表项
Flowtable.add(FlowEntry)←sendFlow_mod(FlowEntry)
else:{//寻找交换机中存在时间最长流表项进行删除
deleteEntry ←findLongestFlow(Flowtable)
//控制器发送Flow_mod消息给交换机删除流表项
Flowtable.delete ←sendFlow_mod(deleteEntry)
Flowtable.add(FlowEntry)←sendFlow_mod(FlowEntry)
}
//控制器向交换机发送Packet_out 消息处理Packet_in 消息中封装的数据包
FlowTable.foward ←sendPacket_out(Packet_in_message)
}
}
return FlowTable;
}
在算法1 中,函数findLongestDuration 优先寻找当前流表中Duration_sec 值最大的流表项进行删除,这可能导致一些使用频率较高的流表项被频繁删除,降低了流表的匹配率。此外FIFO算法在对流表进行更新时的随机性较大,对于数据传输时间不同的数据包,不能满足其对于流表更新算法的需求。
3.2 基于近期最少使用的置换算法
基于近期最少使用(LRU)的流表更新算法根据近期数据流的匹配情况对当前交换机内的流表项进行更新,更加符合真实的数据流环境。一般的LRU 算法根据每条流表项匹配数据包的时间,找到最长时间没有数据包与其匹配的流表项作为近期最少使用的流表项,并将其优先删除。流表中的idle_timeout值可用于记录每条流表项最后匹配数据包的时间。根据OpenFlow协议规范,每条流表项的idle_timeout值随时间递减,当该条流表项有匹配的数据包到达时,其对应的idle_timeout值将被重置。对于LRU 算法而言,idle_timeout 值最小的流表项即为最近最长时间没有处理数据包的流表项,应优先被删除。实现LRU算法的伪代码描述如下。
算法2 基于近期最少使用(LRU)置换算法LRU_FlowEntryReplacement
输入:数据流Flows={p0,p1,…,pn}
输出:流表Flowtable
LRU_FlowEntryReplacement()
{for ∀pi∈Flows do
{//将当前数据流pi的数据包封装在Packet_in 消息中发送给控制器
Packet_in_message ←sendPacket_in(pi)
//控制器提取流表项信息
FlowEntry ←getFlowEntry(Packet_in_message)
//获取当前交换机的流表
FlowTable ←getFlowtable()
If(FlowTable is not full):
//控制器发送Flow_mod 消息给交换机安装流表项并设置idle_timeout值
Flowtable.add(FlowEntry,idle_timeout)←sendFlow_mod(FlowEntry,idle_timeout)
else:
{//寻找当前交换机中最少流表项进行删除
deleteEntry ←findleastUsedFlow(Flowtable)
//控制器发送Flow_mod消息给交换机删除流表项
Flowtable.delete ←sendFlow_mod(deleteEntry)
Flowtable.add(FlowEntry,idle_timeout)←sendFlow_mod
(FlowEntry,idle_timeout)
}
//控制器向交换机发送Packet_out 消息处理Packet_in 消息中封装的数据包
FlowTable.foward ←sendPacket_out(Packet_in_message)
}
}
return FlowTable;
}
在算法2中,idle_timeout值作为记录流表项匹配数据包的最后时间,所以将其设置为一个相对长的固定值。当流表空间已满时,函数findLeastUsedFlow在当前流表中寻找idle_timeout值最小的流表项并将其优先删除。LRU置换算法能够避免FIFO算法删除使用高频率使用流表项的缺点,但LRU 算法也会导致一些使用频率较高,数据包时间间隔较长的数据流的流表项被频繁删除。
3.3 基于最不经常使用的置换算法
基于最不经常使用(LFU)的流表更新算法在流表空间不足时,根据每条流表项历史访问次数,优先删除匹配数据包数量最少的流表项。流表中的匹配计数器可用于记录每条流表项所匹配过的数据包数量。根据OpenFlow协议规范,当流表项有匹配的数据包到达时,其对应的匹配计数器就会自动加一。对于LFU 流表更新算法而言,当前流表中匹配过数据包数量最少的流表项即为使用频率最低的流表项,应优先被删除。LRU算法的伪代码描述如下。
算法3 基于最不经常使用的(LFU)置换算法LFU_FlowEntryReplacement
输入:数据流Flows={p0,p1,…,pn}
输出:流表Flowtable
LFU_FlowEntryReplacement()
{for ∀pi∈Flows do
{if ¬∃entry ∈FlowTable is matched
{//将当前数据流pi的数据包封装在Packet_in 消息中发送给控制器
Packet_in_message ←sendPacket_in(pi)
//控制器提取流表项信息
FlowEntry ←getFlowEntry(Packet_in_message)
//获取交换机当前流表
FlowTable ←getFlowTable()
If(FlowTable is not full):
//控制器发送Flow_mod消息给交换机安装流表项
Flowtable.add(FlowEntry)←sendFlow_mod(FlowEntry)
else:{//寻找当前流表中使用频率最低的流表项进行删除
deleteEntry ←findLeastestCountFlow(Flowtable)
//控制器发送Flow_mod消息给交换机删除流表项
Flowtable.delete ←sendFlow_mod(deleteEntry)
Flowtable.add(FlowEntry)←sendFlow_mod(FlowEntry)
}
//控制器向交换机发送Packet_out 消息处理Packet_in 消息中封装的数据包
FlowTable.foward ←sendPacket_out(Packet_in_message)
}
}
return FlowTable;
}
在算法3 中,函数findLeastedCountFlow 在流表空间不足时寻找当前流表中匹配计数器最小的流表项进行删除。LFU 相对于FIFO 与LRU 算法可以清除更多的使用频率较低的流表项。但与FIFO 和LRU 算法相同,LFU算法只有在当前流表空间不足时才对当前流表资源进行管理,不能提前为交换机留出足够的流表空间容纳新增流表项。
4 基于ARMA模型预测的流表更新算法
在网络流量的高峰期,现有的一般流表更新算法不能很好的解决流表资源不足以及控制器负担过重的问题。为了解决上述问题,本文提出了一种新的P-LRU流表更新算法(Promoted Least Recently Used,P-LRU)。该算法收集每个取样周期内新增的流表项数量作为历史数据,使用自回归移动平均模型(ARMA模型)[16]预测下一个取样周期内新增加的流表项数量。并根据当前流表空间的使用情况动态清除使用频率低的流表项。本文算法不仅使交换机的流表拥有了足够的空闲空间容纳新增流表项,并且在增加了流表的匹配率的同时,减少了交换机与控制器间交互的次数,有效降低了控制器端的负担。
4.1 基于ARMA模型的数据分析
自回归移动平均模型(ARMA 模型)是一种常见的用于短期预测的时间序列模型,由自回归模型与移动平均模型两部分组成。文献[17]使得ARMA 模型拥有一套完整、结构化的建模方法,以及坚实的理论基础和统计学上的完善性。
4.1.1 ARMA模型表述
基于ARMA模型的新增流表项数量预测的基本思想为:将每个取样周期内增加的流表项数目随着时间推移而形成一个随机时间序列。ARMA 模型认为序列中第t个时刻的数值不仅与前p 个时间序列的数值有关,而且与前q 个进入系统的随机扰动有关,并由此来预测下一个时刻的数值。其中作为预测对象的Xt受到前P个时间序列数值的影响,其自回归过程如下式:
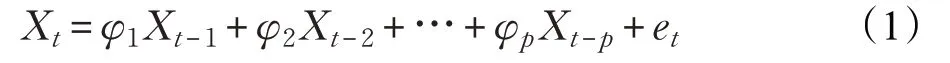
式中,φ1,φ2,…,φp为自回归系数,{Xt}为新增流表项数量所形成的时间序列数值,et为误差项。
误差项在不同时期具有依存关系,其移动平均过程如下式表示:

式中,θ1,θ2,…,θq为移动平均系数,{αt}是与{Xt}独立共同分布的白噪声。
由此,新增流表项数量预测ARMA 模型可以表述为:

将该模型记作ARMA(p,q)。其中p 为自回归阶数,q 为移动平均阶数。
4.1.2 预测步骤
基于ARMA模型的新增流表项预测按照以下步骤进行。
(1)数据预处理和平稳性检验
首先获取新增流表项数目的时间序列,可表示为:{Xt}={X1,X2,…,Xk}然后,将现有的时间序列进行零均值化处理,得到零均值化后的序列,其中为的平均值。接着,计算自相关函数与偏自相关函数:
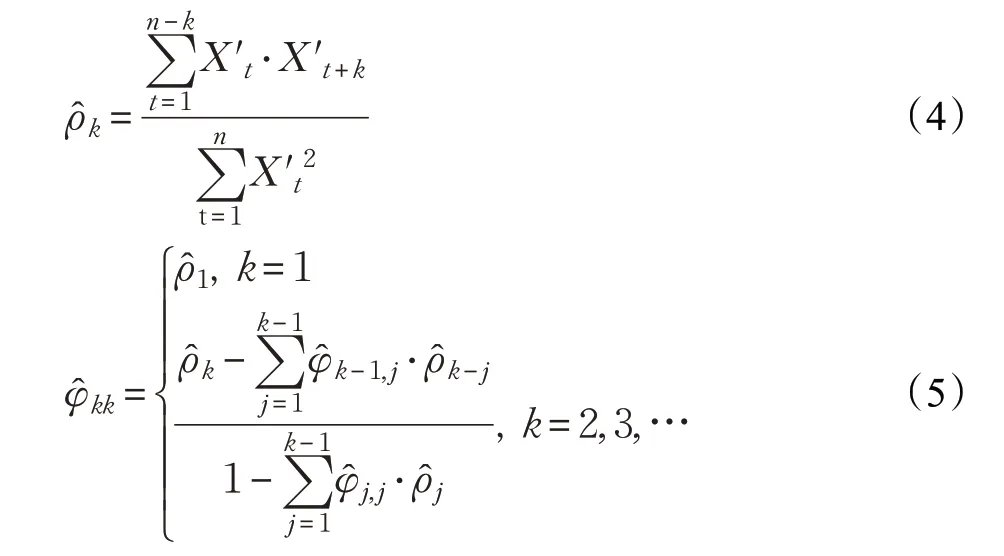
(2)建立模型,参数估计
接下来,根据的偏相关函数和自相关函数确定ARMA(p,q)模型的阶数p,q。由于ARMA 模型在很多领域的广泛使用,已经出现了很多相关的科学计算包,例如Python 的StatsModels 等。通过调用相关科学计算包中的工具函数,对ARMA(p,q)模型进行拟合,并结合最小信息准则(AIC),计算不同的(p,q)组合下模型的AIC 值,选择使得AIC 值最小的阶数,将其作为ARMA(p,q)模型的最佳阶数。
确定最佳阶数(p,q)组合的同时,使用最小二乘估计法对模型中剩余未知参数进行计算,得到t+1 时刻的新增流表项数量的预测关系式:
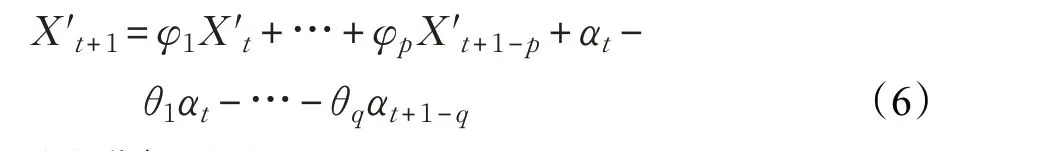
(3)进行预测
最后,运用预测关系式对下一取样周期的新增流表项数量预测,并输出预测结果Nnew。
4.2 清除流表项数目分析
在交换机转发数据包的过程中,流表空间的大小、控制器处理信息的能力的不足是制约交换机转发能力的瓶颈。因此在流表空间一定的情况下,流表项的处理就成为了关键。如图3所示,流表空间由已在交换机中存在流表项和空闲空间构成。每条流表项包含匹配域、动作、在交换机中的存在时间、超时时间等信息。理论上流表的空闲空间必须保持一定且合适的数量才能使系统发挥最佳的性能。
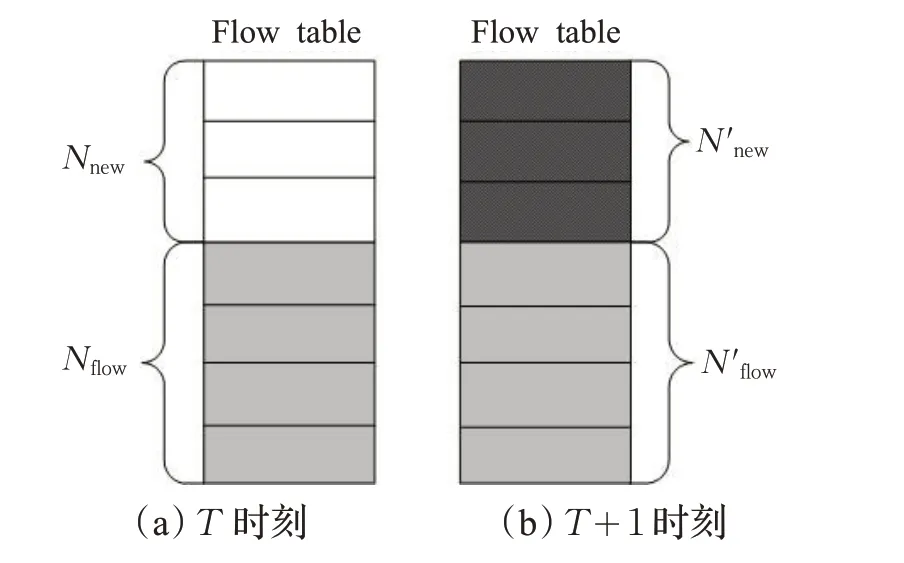
图3 流表空间
假设取样周期T 时流表空间如图3(a)所示,由此图可知:

其中,Nmax是流表最多可以容纳的流表项数目,Nflow是流表中已经存在的流表项的数目,Nempty是流表的空闲空间。通过对近期历史数据的分析,预测下一个取样周期的新增流表项数目,如果预测值较大,表明流表可能需要应对在下一取样周期中产生大量的流表项的情况,此时流表应该保留较大的空闲空间。如果预测值较小,表明在下一个取样周期产生的流表项较少,需要的空闲空间较少,此时可以保留更多的使用高频率的流表项以减少控制器与交换机之间的交互次数。假设N′flow为取样周期T+1 时在上个周期T 时就已经存在的流表项,Nnew为流表中新增的流表项,T+1 时的流表空间如图3(b)所示。

由式(7)和式(8)可知,若Nnew>Nempty则需要清除流表中的部分已经存在的流表项,为下一个周期中新增的流表项预留空间。此时需要从当前流表中清除的流表项数目:

4.3 流表优化算法(P-LRU)
本文算法通过调用基于ARMA模型的预测算法对收集的历史数据进行分析,估计下一个取样周期内可能新增加的流表项数目,并且根据当前流表空间使用情况计算出需要清除的流表项数目。最后在交换机中提前清除一定数目的使用频率较低的流表项,使交换机流表有足够的空间容纳在下一个取样周期内产生的流表项。与一般的LRU算法根据处理数据包的最后时间寻找优先删除的流表项不同,函数FindLeastPacketCount在当前流表中寻找在上一个取样周期中处理数据包数量最少的流表项作为优先删除的流表项。当新增流表项数量远大于预测结果时,调用一般LRU 算法对部分新增流表项进行置换,防止流表项溢出。P-LRU算法的具体伪代码描述如下。
输入:数据流Fl ows={p0,p1,…,pn},交换机收集到的新增流条目历史数据集dataold
输出:调整后的流表FlowTable
FlowEntryReplacement_PLRU()
{for ∀pi∈dataFlow do
{if(intervalTime ≤T)://每T 秒清除一次使用频率低的流表项
{//调用预测算法对下一个周期内新增流条目进行预测,得到预测值
Nnew←UseARMA(dataold);
//获取当前交换机流表
FlowTable ←getFlowtable()
//得到当前交换机空闲流表数目
Nempty←getFreeEntryNum(FlowTable);
//计算出要清除的流表项数目Ndel
Ndel=Nnew-Nempty
//清除Ndel条流表项
While(Ndel>0)
{
deleteEntry ←FindLeastPacketCount(Flowtable);
//控制器发送Flow_mod消息给交换机删除流表项
Flowtable.delete ←sendFlow_mod(deleteEntry);
Ndel--;
}
//更新历史数据集
dataold ←update(dataold)
}
}
//若流表溢出则调用一般LRU算法更新流表
FlowTable ←LRU_FlowEntryReplacement(pi)
}
Return FlowTable;
}
5 模拟实验
为了验证算法的性能,本文使用真实的数据中心流量作为测试数据,该数据来源于文献[7]的校园数据中心所获得的数据集。该数据中心拥有500 台服务器以及22 台交换机,其数据集包含了E-mail、Web 服务和音频视频等数据流。该数据集原本用于分析数据包和数据流的传输特性对于丢包率、链路利用率以及链路阻塞等方面的影响。因此使用从数据集中所选取的数据进行实验,能够有效地比较本文描述的3种流表更新算法对真实SDN数据中心网络的影响。
本文使用RYU 控制器和mininet 仿真平台搭建SDN 网络环境。在实验过程中从数据集中选取3 组数据作为实验测试数据,每组数据数据流类别在10~40k之间,数据包个数为400 万到800 万之间。每个数据包都包含时间戳、源地址、目的地址、数据包长度等信息,并且按照各个数据包上的时间戳模拟数据包的到达,SDN 交换机流表空间被设置为500 条。并且为了分析不同取样周期可能对流表更新效果产生的影响,P-LRU算法在三组实验中分别将5 s、10 s、20 s 作为取样周期对流表进行更新。
5.1 性能指标
本文使用3个指标即新增流表项预测精度、数据包匹配率、控制器与交换机间平均每秒交换的信息数量,将本文所提P-LRU 算法与上文描述的FIFO 和LRU 算法进行了比较。
新增流表项预测精度的计算公式如式(10)所示:

其中是Paop为预测精度,Prec为平均相对误差。新增流表项的预测精度反映了预测算法对于下一取样周期内新增加的流表项数量的预测是否准确,预测精度越高说明预测结果与实际值之间的误差越小。
流表匹配率的公式如式(11)所示:

流表匹配率是指到达交换机的数据包,在流表中能够直接找到与之匹配的流表项的数量占到达交换机的总数据包数量的比率。假设Nmatch表示到达交换机的数据包能够直接在交换机中找到匹配的流表项的数量,Nall表示到达交换机总的数据包数量。流表的匹配率越高说明流表中使用频率高的流表项越多,流表资源的使用效率也就越高。
消息交换数量是指在交换机在处理数据包的过程中,交换机与控制器之间平均每秒交换的消息数量。当数据包在流表中找不到对应的流表项时,交换机与控制器之间会交换PacketIn、FlowModify、PacketOut 这3 种消息。当交换机与控制器之间交换的消息越少时,算法对控制器端所造成的负担越小,算法效率也就越高。
5.2 实验结果
5.2.1 新增流表项预测精度
在3组实验中,每一个取样周期记录一次本周期内新增的流表项数量,收集前50 个数据作为初始历史数据,使用预测模型对下一个周期内产生的流表项数量进行预测。为了验证ARMA模型对于新增流表项数量的预测效果,本文采用文献[13]所使用的AR 模型作为对比,实验结果如表1~3所示。
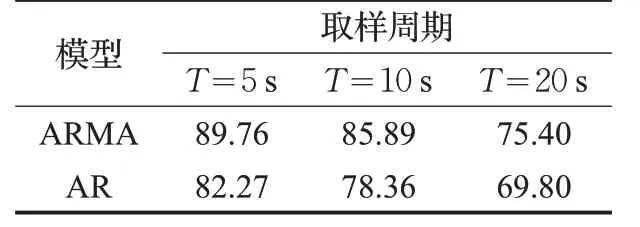
表1 实验组1预测精度 %
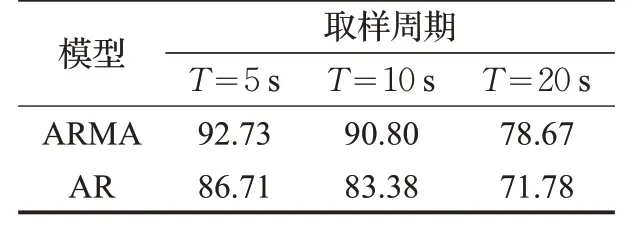
表2 实验组2预测精度 %
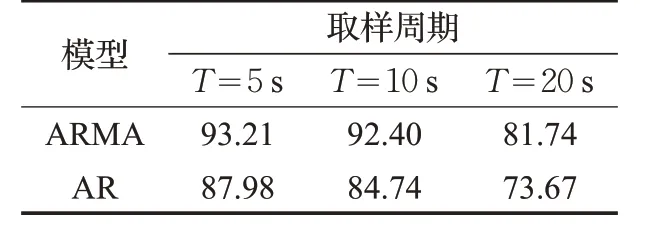
表3 实验组3预测精度%
分析3 组实验结果可知:ARMA 模型总体上比AR模型的平均误差更小,预测精度更高。这是因为AR模型通过时间序列历史数据的线性组合加上白噪声建立自回归方程对当前数据进行预测,并且在预测的过程中认为历史数据中各个时期数值的随机波动可以相互抵消。但是在实际过程中,交换机在每个取样周期中新增加的流表项数量具有较大的随机性,各个时期所产生的随机干扰或误差并不能相互抵消,而这些随机波动的累积又会对预测结果产生较大影响。ARMA 模型由自回归和移动平均两部分组成,综合了AR 模型与MA 模型的优势。自回归过程负责量化当前数据与历史数据之间的关系,移动平均过程负责解决随机变动项的求解问题。其中,移动平均部分对原序列有修匀和平滑的作用,可以有效的削弱原序列的随机波动。因此,ARMA模型对于交换机新增流表项数量的预测结果比AR模型具有更小的误差方差。与此同时,随着取样周期的缩短,新增流表项历史数据之间的变化趋势变得更加明显,ARMA 模型的预测结果与实际结果之间的误差变小,预测精度也就更高。
5.2.2 流表匹配率
如图4 为3 组实验中流表的匹配率,其中FIFO、LRU、LFU 和P-LRU 为本文所提到的4 种流表更新算法。由图可知,P-LRU 算法的流表匹配率明显高于FIFO、LRU 以及LFU 算法。FIFO 算法在4 种算法中的流表匹配率最低,原因在于FIFO 算法并未对每一条流表项根据使用频率进行区分,导致一些使用频率较高的流表项被频繁删除。LRU 算法则会导致一些数据包时间间隔较长但数据包数量较多的数据流的流表项被优先删除。LFU 算法的缺点在于会将一些新到达交换机的流表项当作使用频率较低的表项优先删除。P-LRU 算法可以很好的避免这些问题,算法优先清除在上一个取样周期内匹配数据包数量最少的流表项,可以使交换机保存更多的在近期使用频率较高的流表项,有效提高了流表的匹配率。同时,P-LRU 算法的取样周期越短,对流表的更新速度也就越快,流表匹配率也就越高。
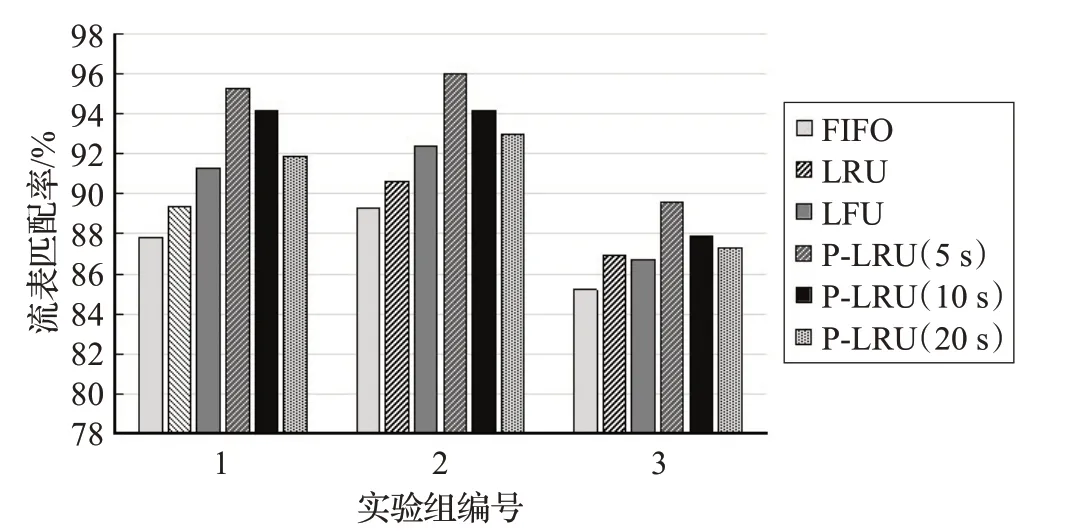
图4 流表匹配率
5.2.3 信息交换数量
如图5 为交换机与控制器之间平均每秒交换的信息数量。在3组实验中,FIFO算法因为在对流表进行更新的过程中缺乏灵活性,所以在交换机与控制器之间产生的消息数量最多,对控制器端造成的负担最重。而P-LRU算法平均每秒在交换机与控制器之间产生的消息数量最少。原因在于FIFO、LRU、LFU算法只有在流表空间不足的情况下才开始对流表资源进行管理,具有一定的滞后性。而P-LRU 算法周期性地清除流表中使用频率较低的流表项,可以使交换机保持更多的空闲空间以容纳新增流表项,有效减少了交换机与控制器之间的交互次数。同时,P-LRU 算法的取样周期越短,控制器所需要获取的当前交换机的流表信息也就越多,交换机与控制器之间所交换的信息数量也相应增多,控制器端的负载也就变得更重。

图5 信息交换数量
6 结束语
在SDN 网络中,因为流表的资源有限以及控制器处理能力的不足,在网络高峰期,交换机的性能受到严重影响。针对该问题,文中提出了一种新的流表更新算法。在本文所提流表更新算法中,通过周期性的清除交换机中使用频率较低的流表项,使交换机在尽可能多的保存使用频率较高的流表项的同时,也留出足够的流表空间以容纳新增的流表项。通过模拟实验表明,本文所提算法相对于流表更新的一般方法可以有效提高流表的匹配率,降低控制器的负担,并且取样周期会对流表的更新效果产生一定的影响。尽管如此,本文还是存在一些不足,比如在清除流表项的过程中只考虑到了每条流表项在过去一段时间内的使用情况,而没有考虑到该流表项在未来一段时间内可能再次被使用到的可能性,因此对于流表项本身的特点还需要进行深入研究。
