面向日志的半监督一致性异常检测
2024-02-27顾兆军侯晶雯
顾兆军,侯晶雯,2
1(中国民航大学 信息安全测评中心,天津 300300)
2(中国民航大学 计算机科学与技术学院科学院,天津 300300)
0 引 言
由于软件系统规模的迅速发展,系统维护的困难也逐渐加剧[1-4].日志是软件系统中重要的信息存储载体,记录着系统运行时的各种关键信息,也是维护软件系统运行状态的重要数据来源.系统管理人员可以通过日志数据了解软件系统的运行状态,检测系统异常并探究根本原因,防范恶意攻击.但是,系统规模扩大导致日志数据数量激增,且具有复杂性和多样性,使得手动检查日志是困难甚至不可行的.因此,有效的基于日志的自动异常检测模型[5,6]可以帮助计算机系统运维人员快速定位异常原因和解决问题.
现存的日志异常检测方法通常使用日志解析器,从原始日志数据中提取日志事件模版,然后采用有监督算法或无监督算法进行异常检测.但仍存在一些问题:1)日志解析错误会导致异常检测模型的性能降低;2)由于异常数据较少,且异常数据与正常数据混合在一起很难分离,导致模型难以训练学习异常数据的分布,降低了模型的泛化能力;3)有监督方法需要大量的数据标签,但是,日志数据具有多样性和复杂性,导致人工标记数据耗时耗力且不可行.无监督方法由于缺少历史数据的引导往往性能较差;4)基于静态阈值的机器学习方法以粗粒度检测异常,不考虑同类型日志数据间的差异性或不一致性.
针对上述问题,本文设计实现了一种半监督一致性异常检测算法SemiCAD(Semi-supervised Conformal Anomaly Detection).该算法首先使用词袋模型(Bag-of-Words,BOW)从原始日志数据中提取词频特征向量,避免日志解析错误影响模型性能.然后通过基于分层密度的带噪声应用空间聚类(Hierarchical Density-Based Spatial Clustering of Applications with Noise,HDBSCAN)的正例无标记样本(Positive and Unlabeled Learning,PU)学习算法[7],根据训练集中有标签的数据(全部为正常日志序列)对训练集中未标记的数据(包括正常日志序列和异常日志序列)进行伪标签估计.最后,选择合适的集成学习算法作为不一致性度量模块计算P值,得出待测日志的标签及其标签置信度,并将其不一致性得分反馈到相应数据标签的得分集中,作为现有经验,计算后续待测日志序列的P值.
1 相关工作
大多数日志异常检测方法通常分为4步:日志收集、日志解析、特征提取和异常检测.其中,日志解析是指在数据预处理阶段通过日志解析对半结构化的日志数据进行预处理,将每条日志消息转换为特定的事件模板.如LogRobust[8]、PLELog[9]等都使用日志解析器Drain将半结构化的日志数据解析为日志事件模版,然后通过Word2Vec提取日志事件的语义特征向量,输入神经网络进行异常检测.但是,日志解析错误往往会导致异常检测模型的性能下降一个数量级.比如,Le等人[10]使用了4种不同的日志解析器(IPLoM[11]、Drain[12]、AEL[13]、Spell[14])在LogRobust[8]和SVM[15]两个异常检测模型上进行实验,实验结果证明日志解析错误使LogRobust[8]和SVM[15]的模型性能分别下降了25%和29%.He等人[16]的研究也表明4%的日志解析错误会导致模型性能下降一个数量级.
根据训练数据是否带有标签可将日志异常检测方法分为有监督方法和无监督方法.有监督的方法包括逻辑回归(Logistic Regression,LR)、决策树(Decision Tree,DT)等.如Zhang等人提出的LogRobust[8]使用基于注意力机制的双向长短期记忆网络(Bi-LSTM),识别和处理不稳定的日志序列和事件.以上异常检测方法虽然可以有效检测异常,却存在一定的局限性,即需要大量有标签的训练数据.在实际生产环境中,日志数据形式复杂多样且是半结构化的字符串,限制了人工标记的可行性.为了克服有监督方法对数据标签及标签质量的依赖性,大量的研究人员进行了无监督方法的研究.如Du等人提出的DeepLog[6]方法使用长短期记忆网络(LSTM)对日志模版和参数值进行协同异常检测,并根据用户反馈对异常检测进行权重更新;Lin等人提出的LogCluster[17]方法通过线性模式挖掘和日志聚类检测异常;Meng等提出的LogAnomaly[18]方法使用LSTM分别从序列模式和定量模式进行异常检测.无监督方法虽然克服了真实数据缺少标签的局限性,却往往由于缺乏历史数据分布规律的引导导致模型性能较差.
从异常检测方法上看,基于静态阈值的机器学习方法往往以粗粒度检测异常,不考虑同类型日志数据间的差异性.若一种算法可以为预测结果附加一个风险水平(置信度),根据风险水平评估预测结果,可以使样本预测错误的概率可控.顾兆军等人[19]使用Vovk等人[20]提出的一致性预测算法(Conformal Predictor,CP)进行日志异常检测.CP是一种基于置信度的机器学习算法,相比传统的基于阈值的机器学算法,CP使用不一致性得分有效衡量相同类标签日志数据以及不同类标签日志数据之间的不一致性大小,充分体现了日志数据间的相似性和差异性大小.通过不一致性度量还可以将新旧日志数据联系起来,结合历史经验做出预测,并给出带有置信度的数据标签.但是该方法采用基于日志事件计数向量的特征提取方法,忽略了日志数据中单词的语义信息,无法识别日志事件的不同重要程度.此外,日志事件计数向量的维度也会随着日志数据的变化而改变.
如表1所示,本文分别从日志解析方法(表格中“-”表示该模型没有进行日志解析)、特征提取方法、异常检测模型或框架以及算法类型(根据训练数据是否带有或部分带有标签进行分类,表中“有”代表有监督算法,“无”代表无监督算法,“半”代表半监督算法)4个方面,对相关研究工作中不同的异常检测模型进行了详细的对比描述.表1中所提及的异常检测模型也用于后续对比实验中.

表1 异常检测模型对比Table 1 Comparison of anomaly detection models
2 模型方法
在本节中,我们将详细描述SemiCAD模型中的每个主要步骤.如图1所示,SemiCAD主要包括3个步骤:数据预处理;伪标签估计;不一致性异常检测.我们首先将半结构化的原始日志消息预处理为结构化的词频向量特征矩阵;然后,通过基于HDBSCAN的PU学习算法对训练集中未标记数据的进行伪标签估计,后续可以充分利用带有伪标签的训练数据集训练分类器,提高模型的异常检测性能.最后,选择合适的分类器组成不一致性度量模块,如AdaBoost集成学习和随机森林(Random Forest,RF),为每个待测日志序列输出一个带置信度的标签,将每个可能标签的置信度与预先给定的显著性水平进行对比,从而判断日志序列是否异常.
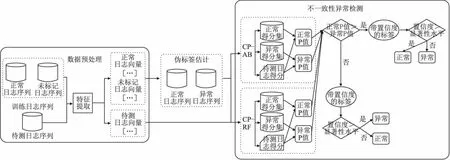
图1 SemiCAD模型组成Fig.1 Consists of the SemiCAD model
2.1 数据预处理
日志数据预处理是构建异常检测模型的第1步,例如,HDFS日志数据预处理的主要步骤如图2所示.为了避免日志解析错误对异常检测模型性能造成影响,SemiCAD首先对原始日志数据进行预处理,然后采用BOW模型进行特征提取便于后续异常检测.

图2 数据预处理Fig.2 Data preprocessing
2.1.1 预处理
日志数据通常是半结构化的文本字符串,每条日志消息包括无结构化的数据(例如,时间戳、日志优先级、系统组件)和日志序列.日志事件中的大多数标记都是英语单词.此外,还包括非字符标记(例如,分隔符、运算符、标点符号和数字)、停止词(例如,a、the)和复合单词(例如,NullPointerException).在日志数据预处理阶段,若日志数据具有记录每个作业执行的标识符,则将具有相同标识符的日志消息合并;若没有标识符,则使用大小固定的时间窗口将日志切片为日志序列,合并后的每条日志序列被视为一个自然语言句子.然后,根据常用分隔符(即空格、冒号、逗号等)分割单词并使用Camel Case[21]拆分复合单词,删除非字符标记.因为非字符标记通常表示日志消息中的变量,并不提供任何信息.例如,原始日志消息为“081109 203519 145INFO dfs.DataNodeMYMPacketResponder:PacketResponder 1 for block blk_-1608999687919862906 terminating”,经过预处理后拆分为一组单词集合{info,dfs,data,node,packet,responder,for,block,terminating}.最后,过滤掉合并后的每条日志序列所产生的单词集合中的超高频词汇,即出现的数量占比大于等于该日志序列总词汇数量的70%.因为出现频率过高的词汇(例如,info、for、block等)在后续异常检测中无法起到决定性作用.
2.1.2 特征提取
特征提取的目的是从日志事件中提取有价值的特征提供给异常检测模型.在特征提取阶段,SemiCAD使用BOW模型提取日志序列的词频向量表示,即特征提取的输入为日志预处理过程中生成的日志词汇集合,输出为词汇计数矩阵.在日志文件中,词语在上下文语境中的关联性较弱,某个词语的出现就可以判断该日志序列是否异常,而BOW模型可以很好的突出单个单词的重要性.
2.2 伪标签估计
使用基于HDBSCAN的PU学习算法根据训练集中部分有标签的数据(仅含正常日志序列)对无标签的数据(包括正常日志序列和异常日志序列)进行伪标签估计,将训练集中的数据聚类到不同的簇中,同一簇中的数据具有相同的类标签,即某一簇的簇心为正常日志序列,则该簇中的日志数据标签全为正常,反之为异常.然后将带有伪标签的数据应用于一致性异常检测模型的训练中.HDBSCAN算法使用相互可达距离来表示两个样本点之间的距离,使得密集区域的样本点之间的距离不受影响,而稀疏区域的样本点与其他样本点之间的距离被放大,这样做增加了聚类算法对散点的鲁棒性.相互可达距离的计算方法如公式(1)所示:
dmreach-k(a,b)=max{corek(a),corek(b),d(a,b)}
(1)
其中,d(a,b)表示点a与点b之间的原始度量距离,corek(x)为点x与第k个最近邻样本点的距离,即核心距离:
corek(x)=d(x,Nk(x))
(2)
通过伪标签估计可以在部分样本标签的引导下,充分利用无标签的数据样本提高模型学习性能,避免了数据资源的浪费.虽然伪标签估计的过程中难免会在原始数据中引入噪声,但是后续的一致性异常检测模型可以通过不一致性得分,有效衡量相同类标签日志数据以及不同类标签日志数据之间的相似性和差异性大小,然后将新旧日志数据联系起来,使用多模型协同检测共同决策,降低了伪标签估计过程中引入噪声对模型性能造成的影响.
2.3 不一致性异常检测
2.3.1 不一致性度量
一致性预测框架理论基于随机性和可交换性假设.随机性假设是机器学习中的一个标准假设,可交换性假设意味着变量具有相同的分布[22].
在日志异常检测中,给定一个训练样本集合(z1,…,zn-1),每一个样本zi∈Z由一个实例xi(通常是一个属性向量)及其标签yi组成,即(xi,yi),i=1,2,…,n-1.检测新数据zn时,一致性预测尝试每一个可能标签,即yc={正常,异常}作为xn的备选标签.在随机性假设下,即(xi,yi)是独立同分布的,选择不一致性度量函数来计算不一致性得分,如公式(3)所示:
αi=An(
(3)
αi表示第i个样本与其他样本的不一致性大小,αi越小,即不一致性越小,表示属于样本序列的可能性越大.根据得到的不一致性得分通过公式(4)计算P值:
(4)
其中,分子为i=1,2,…,n时满足αi≥αn的个数,P(z1,…,zn)∈(1/n,1).如果P(zi)的值较小,表明zi与其余样本的不一致性较大.分别计算待测实例xn的正常P值PN和异常P值PA,比较两者大小,标签所对应的置信度为1减去两者中较小的值.然后,将置信度与预先给定的显著性水平ε∈(0,1)进行比较,从而判断待测样本xn是否异常.
2.3.2 置信度和可信度
一致性预测框架提供了两个关键的指标:置信度和可信度.如上所述,测试对象xn尝试每个可能的标签yc={正常,异常}作为xn的标签,然后计算P值.最后选择具有最大的P值对应标签作为检测对象xn的标签.
检测标签将由置信度(confidence)和可信度(credibility)来衡量.置信度定义为1减去第2大的P值,而可信度定义为最大的P值.
4种可能的结果如下:1)高可信度—高置信度:一个测试样本对应且只对应一个类;2)高可信度—低置信度:测试样本很相似,属于两个或两个以上的类;3)低可信度—高置信度:测试样本不能与数据集现存类别的任何一个类别联系起来;4)低可信度—低置信度:算法给测试样本检测一个标签,但它似乎与另一个标签更相似.
2.4 算法描述
SemiCAD模型伪代码描述如表2所示.
3 实验环境及评价指标
3.1 数据集介绍
如表3所示,实验采用两个广泛使用的公共数据集来评估SemiCAD,即Hadoop分布式文件系统数据集(HDFS)和超级计算机数据集(Blue Gene/L Supercomputer,BGL).HDFS是通过在超过2000个Amazon的EC2节点上运行基于Hadoop的MapReduce作业38.7小时生成的.根据日志消息的block_id,可以直接提取日志序列.BGL由劳伦斯利弗莫尔国家实验室(LLNL)的Blue Gene/L超级计算机产生.与HDFS数据集不同,BGL日志没有记录每个作业执行的标识符.因此,我们使用大小为120的固定窗口将日志切片为日志序列.

表3 日志数据集细节描述Table 3 Log data set detail description
如果一个日志序列存在任何失败日志,则被视为异常日志序列.实验以7∶3的比例按照日志序列的时间顺序将数据集分割为训练集和测试集,以保证训练集中的所有日志序列都是在测试集中的日志序列之前生成的来模拟实际场景.为了模拟半监督场景,在训练集中按顺序遍历日志序列,若该日志数据标签为正常,则记为训练集中已知标签样本,直至数量达到训练集样本数量的50%为止,其余数据作为未标记的日志序列.
3.2 实验设置
为了验证SemiCAD模型的异常检测效果,搭建仿真实验环境,实验环境配置如表4所示.

表4 实验环境配置Table 4 LabEnvironment configuration
3.3 实验评价指标
日志数据异常检测是一个二分类问题,记正常数据标签为0,异常数据标签为1,则TP、FP、TN、FN为以下4种情况:
TP:真实值为1,预测值为1,预测正确.
FP:真实值为0,预测值为1,预测错误.
TN:真实值为0,预测值为0,预测正确.
FN:真实值为1,预测值为0,预测错误.
实验采用的评价指标均由表5所示的混淆矩阵中的4个值计算得出:即准确率(Accuracy)、精确率(Precision)、召回率(Recall)和后面两种指标的调和平均数(F1)值.这些指标被用来评价SemiCAD模型的有效性.评价指标的计算方法如公式(5)~公式(8)所示:
(5)

表5 混淆矩阵Table 5 Confusion matrix
(6)
(7)
(8)
如上所示,Precision表示所报告的异常中正确的百分比,Recall表示所检测到的真实异常的百分比,F1表示Precision和Recall的调和平均值.
4 实验结果及分析
4.1 最佳显著性水平的确定
本节我们探究不同显著性水平下,SemiCAD各指标的性能(如图3、图4所示),从而确定最佳的显著性水平来进行后续实验.如图3所示,Recall、F1等随着显著性水平的增加而缓慢提高,在显著性水平为0.99时取得最大值.所以,对HDFS日志数据集进行实验时将显著性水平设置为0.99.

图3 HDFS数据集SemiCAD各项指标变化Fig.3 HDFS datasets has different indicators in the SemiCAD

图4 BGL数据集SemiCAD各项指标变化Fig.4 BGL datasets has different indicators in the SemiCAD
如图4所示,当显著性水平在0.5~0.9之间时,Recall、F1等指标值随着显著性水平的增加整体呈上升趋势,当显著性水平为0.90时,Recall、F1等性能指标值整体达到最大.所以,在BGL数据集上,我们将显著性水平设置为0.90.
4.2 SemiCAD的有效性
由于SemiCAD是一种半监督的日志异常检测方法,本文将其与基于半监督方法(如PLELog)、无监督方法(如LogCluster、LogAnomaly)和有监督方法(如LogRobust)等日志异常检测模型性能进行对比,对比模型具体描述如第2章节中表1所示.
表6和表7展示了不同异常检测模型在Precision、Recall和F1值方面的对比结果,可以看出SemiCAD在HDFS和BGL上的性能基本优于所比较的异常检测方法.尽管在BGL数据集中LogCluster[17]和LogAnomaly[18]较SemiCAD分别获得了更好的Precision和Recall,但SemiCAD的F1分数明显优于其他方法.在F1分数方面,SemiCAD相比其他方法在HDFS上的提升范围为4.7%~46.6%,在BGL上的提升范围为3.2%~70.1%.此外,我们发现几乎所有的方法在BGL上的性能都比HDFS差.这是因为与HDFS相比,BGL的时间跨度更长,因此包含了更多的不稳定数据.

表6 不同异常检测算法在HDFS数据集上的实验结果Table 6 Experimental results of different anomaly detection algorithms on HDFS data set

表7 不同异常检测算法在BGL数据集上的实验结果Table 7 Experimental results of different anomaly detection algorithms on BGL data set
进一步分析实验结果可得,SemiCAD在HDFS数据集上的召回率为1.00,这意味着SemiCAD能够高精度地识别该数据集中的所有异常.SemiCAD是一种半监督的日志异常检测模型,实验结果说明使用带有伪标签的训练数据集训练一致性异常检测模型,可以有效结合历史知识,学习数据分布规律,提高模型检测性能.其次,SemiCAD的Recall和F1值也优于无日志解析的LogCluster[17]和NeuralLog[20],表明基于原始数据进行特征提取,有效避免解析错误影响检测结果的情况下,SemiCAD可以检测到更多更全面的异常.最后,SemiCAD相比于半监督异常检测模型PLELog[9]检测性能也有所提高,因为一致性预测使用不一致性得分可以有效度量日志数据间的相似性和差异性大小,充分学习历史数据分布规律的的同时,将新旧日志数据联系起来,结合多模型协同检测共同做出决策,有效缓解了伪标签估计时引入噪声对检测模型造成的影响.实验结果充分证明了SemiCAD在缺少标签的日志数据中,通过提取原始数据特征,使用带有伪标签的数据集训练多模型协同的一致性预测模型,可以有效的检测数据异常.
4.3 底层算法选择
在一致性异常检测框架中不同底层算法的差异性会对模型性能产生重要影响,为探究此问题,本文分别选择LR、DT、SVM、NB和集成学习作为底层算法进行实验对比,分别记作CP-LR、CP-SVM、CP-DT、CP-NB和SemiCAD.在选择集成学习作为底层算法时,文中分别选择LR、SVM、DT、NB作为AdaBoost的弱分类器以及RF进行实验,实验结果取达到最好效果的一种.图5和图6分别记录了在HDFS和BGL数据集中,使用不同底层算法的异常检测模型性能.
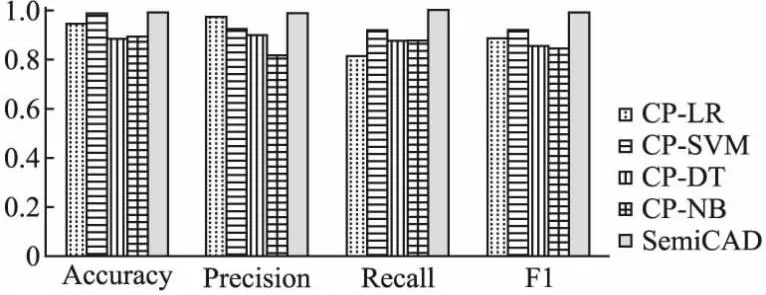
图5 不同底层算法在HDFS数据集上的异常检测结果Fig.5 Anomaly detection results of different underlying algorithms on HDFS data sets
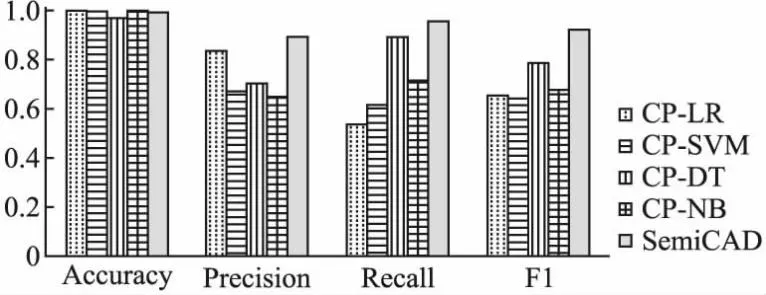
图6 不同底层算法在BGL数据集上的异常检测结果Fig.6 Anomaly detection results of different underlying algorithms on BGL data sets
从图5可以看出,一致性异常检测在HDFS数据集使用不同模型作为底层算法时,CP-SVM的F1值最高,但SemiCAD的F1值仍高于CP-SVM 7.5%.从图6中看到,一致性异常检测在BGL数据集使用不同模型作为底层算法时,CP-DT的F1值最高,但SemiCAD的F1值仍高于CP-NB 14.2%.实验结果表明选择相比传统的分类器,使用集成学习作为底层算法时可以有效提高检测精度.同时,SemiCAD的Recall也优于其他异常检测模型,这意味着采用集成学习作为底层算法时可以检测到更多的异常,这在系统维护中更加重要.
5 总结与展望
基于日志的异常检测方法已经成为维护系统运行和检测系统异常的重要手段之一.但是,随着软件系统规模扩大,日志数据变得数量庞大且类型复杂多样,手动进行数据标记代价高昂甚至不可行,导致有监督方法难以应用于实际生产环境中.然而,不需要数据标签的无监督方法往往由于缺乏历史经验导致检测性能较差.其次,大多数现存的日志异常检测方法在日志数据预处理阶段使用日志解析器提取事件模版,实证研究表明日志解析错误会导致模型性能大大降低.
本文提出了一种基于置信度的半监督一致性异常检测方法——SemiCAD,该方法首先基于原始日志数据提取词频特征向量;然后,使用基于HDBSCAN的PU学习算法对训练集中未标记的数据进行伪标签估计,使用带有伪标签的训练数据对模型进行训练;最后,在一致性预测框架中使用集成学习算法作为底层算法进行协同异常检测,通过不一致性度量将待测数据和训练数据联系起来,结合历史经验做出预测的同时,能够适应数据的变化.SemiCAD在有效避免日志解析错误影响模型性能的同时,通过伪标签估计充分利用现有数据,学习历史数据分布规律,克服了有监督方法需要大量数据标签的局限性.通过使用多个异常检测模型在HDFS和BGL数据集上进行对比实验,验证了该模型的性能,进一步证明该模型具有较好的异常检测效果.
