聚类标注和多粒度特征融合的基金新闻分类
2024-02-27胡菊香吕学强游新冬周建设
胡菊香,吕学强,,游新冬,周建设
1(首都师范大学 中国语言智能研究中心,北京 100048)
2(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引 言
随着中国金融市场规模的不断扩大和发展,政府监管部门出台了一系列政策和法规,以促进市场的规范化和透明化.尤其是在中国证监会发布了《关于加快推进公募基金行业高质量发展的意见》等相关文件之后,公募基金行业的规范化和可持续性发展已成为趋势所在.在这样的背景下,基金新闻文本的自动分类不仅可以大幅提高基金行业的市场分析速度和准确性,还能够为投资者提供更加精准和全面的基金信息服务,金融行业对基金文本数据的研究也日益深入.然而,基金文本数据通常不规范,非结构化,且语言表达多样,使得基金新闻文本分类任务变得异常繁琐和具有挑战性.因此,基于人工智能技术的基金新闻文本分类具有重要的现实意义和紧迫的工作必要性[1].
由于基金新闻的自动分类需要大量已标注数据的支持,而目前标注方法主要为人工标注方法.针对人工标注存在主观性的影响,导致类别标注结果缺乏一致性和准确性等问题,本文提出了一种基于聚类加权的基金新闻类别标注算法,实现标注的半自动化,可为基金新闻文本分类任务提供有力的数据支持.
随着机器学习和深度学习的不断发展和应用,自然语言处理在新闻文本分类中的应用越来越多,为基金领域带来了新的发展机遇.孙红等人[2]采用BERT对中文文本进行编码,结合注意力机制选取重要词汇,并将编码和注意力机制的输出融合,用于下游的文本分类任务.闫跃等人[3]引入位置编码和自注意力机制增强文本序列信息表示,利用卷积神经网络提取特征,并引入区域注意力机制和元素注意力机制进一步提取关键信息,以实现文本的分类任务.Rai Nishant等人[4]采用BERT融合LSTM模型进行假新闻识别.两种模型的结合可以处理不同级别的语义信息,并应对长文本序列的挑战.为了让模型更好地处理假新闻分类任务,该论文提出了一种增强的LSTM模型,它将文本中的关键信息和重要性进行了加权处理,并采用双向LSTM模型进行处理,增强了其信息提取能力.这些研究成果为基金新闻文本分类提供了新的技术支持和创新思路,并促进了金融行业的快速发展.
上述方法并没有专门针对文本高维稀疏和非结构化等特点进行优化,因此分类性能和特征提取能力存在一定局限性.据此,本文提出了一种多粒度特征融合的文本分类算法,该算法从基金新闻文本词粒度、句粒度等多种粒度考虑,进一步将标题、摘要、内容引入多头注意力机制与BERT融合,以更好地捕捉信息,丰富模型的语义信息,更好地适应文本分类任务.不同粒度的特征具有一定的互补作用,有助于提高模型的鲁棒性,减少过拟合风险.多头注意力机制则可以进一步提高模型的泛化能力,更好地处理文本分类任务中的非线性复杂关系.实验结果表明,该算法在基金新闻文本分类任务上具有很高的分类性能和准确率,且相对于其他算法具有更高的效率和可解释性.
1 相关工作
在基金新闻分类中,传统的人工标注方式耗时耗力,而且需要专业领域的研究人员进行标注,限制了分类效率和范围.而聚类是一种重要的技术手段,可以在无标注数据的情况下对基金新闻进行自动类别聚合,大大减少了基金新闻类别标注的人力成本.有效的聚类方法能够自动地将相似的文本聚合在一起,形成具有类别标签的数据集,为基金新闻分类提供了数据支撑,同时也减轻了专业领域研究人员的负担和工作量.Billah Md Masum等人[5]使用了3种不同的方法将亚马逊产品评论分解为句子,并针对每个簇提取数量有限的基本词,最后通过构造基本词,对每个簇进行标签化.Nur Heri Cahyana等人[6]提出了一种基于K近邻算法的半监督学习模型,该模型不仅仅是基于构造基本词进行数据标注,而是利用TF-IDF特征提取方法获得最优结果.阳爱民等人[7]使用了3种自动化标注方法,包括关键词、概率求和和概率乘积,并将这些结果进行投票加权,最终通过投票机制来确定类别标签.宫衍圣[8]等人则结合Word2vec与TF-IDF提取文本特征,并使用K-Means聚类算法来确定文本类别.综上,现有的类别标注方法没有考虑特定数据的特点,尤其不适用于基金文本类别标注,标注效果不佳.
文本分类是自然语言处理领域的一个关键研究方向,具有广泛的应用场景,尤其是在金融领域更为重要.为了实现特定的文本分类任务,常用的文本分类方法包括基于传统机器学习方法、基于深度学习方法和基于迁移学习的新闻文本分类.
基于传统机器学习方法的新闻分类是指通过模型构建和模型参数调整和优化来实现特定的文本分类功能.赵澄等人[9]利用支持向量机(SVM)对金融新闻提取股票市场的影响因子,并通过bootstrap来减轻过拟合问题,最终通过因子的影响来预测股票的波动.许雪晨等人[10]提出一种基于金融文本情感分析的指数预测模型SA-BERT-LSTM,将情感特征与股市行情交易相结合对股票价格进行预测,并以BP神经网络,支持向量机,XGBoost这3种实验作为对比实验对模型进行验证.
基于深度学习方法的新闻文本分类是指通过调用多层的神经网络进行文本分类的方法.谢志峰等人[11]通过无监督学习方法训练财经类词向量模型,并将词向量输入到卷积神经网络中实现财经新闻分类.朱鹤等人[12]针对金融领域文本的专业性,引入词表示模型,提出来一种基于金融领域词典与特征增强BERT的文本分类算法.
基于迁移学习的新闻分类是指利用已有的标注数据和模型对新的新闻进行分类.刘壮等人[13]针对特殊的金融领域文本提取有效的关键信息,通过与BERT融合的方式进行分类.吴峰等人[14]通过学习相关领域数据的分类准则,将其迁移到目标领域数据,并利用深度网络自适应和注意力机制,对源领域和目标域之间数据分布差异进行特征训练,并完成迁移学习的文本分类.
综上,现有的文本分类方法没有考虑公募基金领域特点以及基金新闻标题、摘要、内容之间的相关性.据此,本文在基于聚类加权的基金新闻类别标注数据的基础上,提出了一种多粒度特征融合的基金新闻分类方法.归纳而言,本文主要做了以下几个方面的工作:
1)提出了基于聚类加权算法的基金新闻类别自动标注算法,相比于传统的手工标注方法,不仅省时省力,还提高标注的准确率和效率.通过该算法,辅以少量的人工标注,形成了包括法规政策、宏观新闻、行业要闻、基金行情和评论展望5个类别,总计91473条的基金新闻分类数据集.
2)提出了一种多粒度特征融合的基金新闻分类模型.该模型通过引入多粒度特征,并通过多头注意力机制和BERT的融合来捕捉和丰富模型的语义信息,提高了模型的分类准确性和鲁棒性.
3)通过融入大量的金融领域的专业术语、专业用词和领域语言使用习惯等,对所提出的算法进行多角度实验验证.实验结果表明,该算法比传统分类算法具有更高的准确性和可靠性,对于公募基金新闻领域的分类任务有较好的应用前景.
2 模型构建
基于聚类加权标注和多粒度特征融合的文本分类模型的整体架构如图1所示,该模型的整体运作流程如下:第1阶段是基金新闻类别标签标注,以解决基金新闻数据手工标注所带来的耗时耗力问题,并作为文本分类的基础数据;第2阶段是关键信息抽取,该阶段对基金新闻从词语、句子等不同粒度进行分析,利用TFIDF和TextRank方法[15]对基金新闻抽取关键词、关键句子,并构建停用词表和扩展词典;第3阶段是多粒度特征融合的文本分类模型,该模型从多个角度进行融合,包括标签向量、自建停用词表、扩展词典、BERT模型[16]与多头注意力机制融合等,以实现基金新闻文本的自动分类.
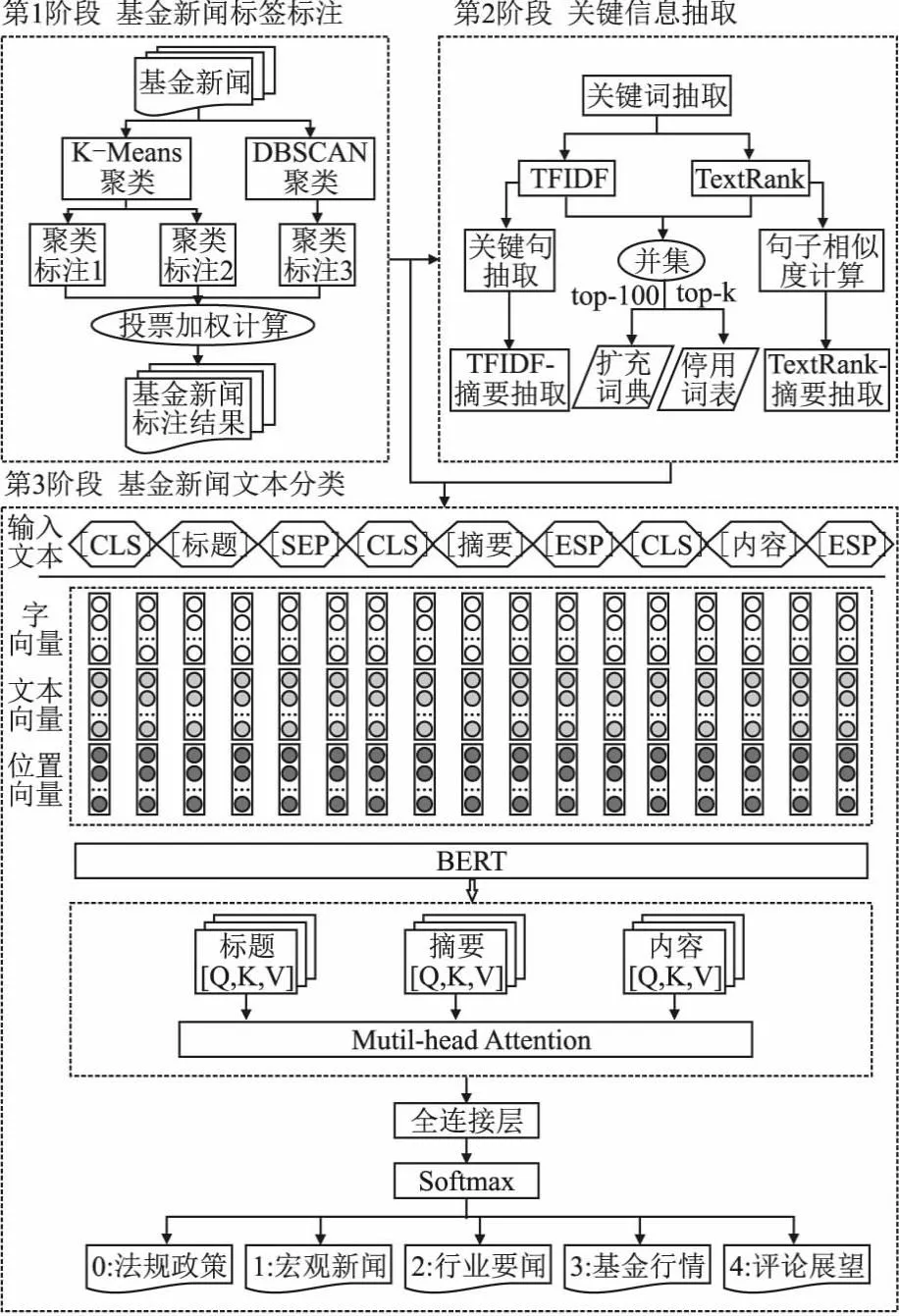
图1 整体架构图Fig.1 Overall architecture diagram
2.1 基于聚类加权的基金新闻类别标签标注方法
相比于传统的人工标注方法,基于聚类加权的基金新闻类别标签标注方法如图2所示.该方法无需人工干预,将相似的文本聚类,并通过加权确保每个类别被恰当标记.首先,本文将基金新闻数据通过数据预处理后,包括分词、去除停用词、标点符号等,对基金新闻进行特征提取,以便于聚类.本文主要采用两种聚类算法,即K-Mean[17]和DBSCAN[18].其中,基于K-Means的聚类算法采用Hashing和Doc2Vec两种特征提取方法,基于DBSCAN聚类算法采用TFIDF特征提取方法.然后,对所获取的3种聚类特征进行LSA(Latent Semantic Analysis)语义降维和PCA(Principal Component Analysis)主成分降维处理,以减少维度并保留主要信息.最后,将聚类结果通过反推主题方式获得基金新闻的3种类别标注结果.将标注结果通过投票机制赋予不同类别标注权重并获得最终标注结果.再辅以少量的人工校对,得到更为准确和可靠的基金新闻类别标注结果,为后续公募基金新闻分类提供有力数据支持.
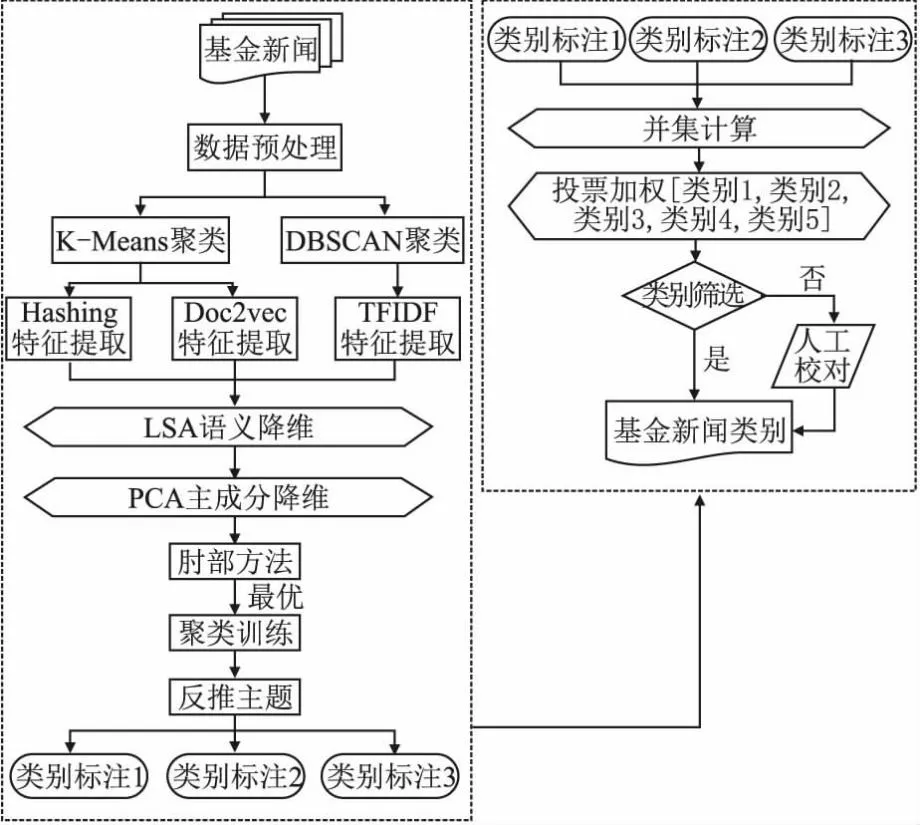
图2 基金新闻文本类别标签标注Fig.2 Labeling of fund news text categories
聚类加权计算是一种通过遍历数据集中的每一篇文档,并分别对每一篇文档的类别进行加权计算的方法.在计算权重时,通过统计每个类别的频数得到每个类别的权重值,并将权重值最大的类别标记为该文档的基金新闻标注类别.类别权重计算公式如公式(1)所示:
Weight(X)=Max(count(y)) y∈[0,4]
(1)
其中,f(x)为K-Means的Hashing特征向量聚类、K-Means的Doc2Vec特征向量聚类、DBSCAN聚类3种算法类别标注结果,类别标注结果可能是0~4类别中的一种.利用投票机制对将3个算法得出的不同标记值进行投票,其中count(y)为类别0~4的投票结果,max()表示返回括号中参数的最大值.
基于聚类算法的基金新闻类别标注流程如算法1所示:
算法1.基于聚类的基金新闻类别标注算法
输入:输入基金新闻文本D={x1,x2,…,xN},分簇数K=40,最大迭代次数为M
输出:输出基金新闻类别标注{C0,C1,C2,C3,C4}
1.ifClusteringmethod=K-Meansthen
2.ifV0=HashingVectorizerthen
//V0表示哈希特征提取
3. V0=features //表示特征提取训练
4. V0=LSA //LSA 表示语义降维
5. V0=PCA //PCA 表示主成分分析降维
6. V0=SVD //SVD 表示标准化处理
7.endif
8.ifV1=doc2vecthen//V1表示文档特征提取
9. V1=features
10. V1=LSA
11. V1=PCA
12. V1=SVD
13.endif
14.endif
15.ifClusteringMethod=DBSCANSthen
16.ifV2=TFIDFthen//V2表示TFIDF特征提取
17. V2=features //表示特征提取训练
18. V2=LSA //LSA表示语义降维
19. V2=PCA //PCA表示主成分分析降维
20. V2=SVD //SVD表示标准化处理
21.endif
22.endif
23.V0,V1,V2=ElbowMethod
//ElbowMethod表示肘部方法
24.k=Optimalk&&k=Optimaleps&&minsamples
//表示最优化k,eps,minsamples
25.K-Means //表示最优化k-means聚类训练
26.returnD1,D2,D3
//表示V0,V1,V2特征提取的基金新闻类别标注
2.2 基金新闻文本关键信息抽取
2.2.1 基金新闻领域词典构建
在基金领域,由于非结构化的基金新闻文本包含的专业术语和独特术语很多,难以充分的挖掘出有用的文本信息并构建文本因子,尤其是对于某些特定领域的文本信息,例如,关于基金业绩的特定词汇,如“牛/熊市”、“浮亏/浮盈”、“回撤”等,更需要适合于该领域的专业词汇和短语.据此,为特定的基金领域构建一个适用的基金新闻领域词典具有重大的意义和价值[19],可以为文本分类和分析领域提供更好的数据支持和技术保障.
本文利用两种常用的关键词提取算法TFIDF[20]和TextRank[21]对基金新闻文本进行关键词提取,并对这两个算法所获得的关键词集合进行并集计算和关键词词频排序.通过筛选词频排序为前100名的词汇,构建了文本分类的扩充词典.此外,选取了所有词频排序为1的词汇构建了停用词表.
2.2.2 基金新闻文本摘要抽取
本文基于“关键词”提取的思想对基金新闻进行文本摘要抽取.在基于TFIDF算法和TextRank算法抽取文本摘要的过程中,将所抽取的“关键词”替换为“关键句”,抽取最终的基金新闻文本摘要.
TFIDF是一种加权技术,用于评估词对文档集或语料库的重要性程度.在文本中,对基金新闻文本集合中所有的词计算TFIDF值,并设定固定阈值来筛选关键句子,以此生成基金新闻文本摘要.
TextRank算法将句子类比为网页,其基本思想是将任意两个句子的相似性转换为网页之间的转移概率,该算法通过计算句子之间的相似度,构建一个无向有权图,以句子为节点,相似度计算值为边的权值.然后,再通过迭代计算算法,得到每个句子的TextRank值.在文本中,通过计算基金新闻文本集合中的所有句子的相似度,并构建相应的图结构进行计算,以此得到每个句子的TextRank值.通过将“关键词”替换为“关键句”,可以更全面地抽取基金新闻文本中重要的信息,从而生成更为准确和具有代表性的文本摘要.其计算公式如公式(2)所示:
(2)
其中,基金新闻文本内容以句子为单位进行分割,分割后句子集合为T=[S1,S2,S3…Sn],构建图G=(V,E),其中V为句子集合,对句子集合T进行预处理操作得到Si=[Wi1,Wi2,Wi3,…,Wik],其中Wik为候选关键词.
2.3 多粒度特征融合文本分类模型
多粒度特征融合文本分类模型如图3所示,该模型主要包括以下内容:

图3 多粒度特征融合的文本分类模型Fig.3 Text classification model with multi-granularity feature fusion
首先,将2.2.1构建的扩充词典替换到BERT模型的Vocab词典中预留的100行[unused]位置,从而更好地让BERT模型理解领域特定的词汇.然后,在输入基金新闻文本到BERT模型之前,进行多粒度融合和类别标签向量化.多粒度融合将基金新闻划分为标题、摘要、内容3部分,并采用两两拼接的方式,以实现信息融合.这种不同粒度的信息融合有助于增加数据样本的多样性和模型的泛化能力.类别标签向量化通过One-Hot编码,将类别标签映射为向量,每个类别分配唯一的向量,以准确标识基金新闻所属类别.最后,通过将标题、内容和摘要输入多头注意力机制[22]后,模型能够并行地从不同角度捕捉文本的语义.每个注意力头可以在独立的注意力机制下,聚焦于不同的特征.随后,这些丰富的特征被融合在一起,形成更全面的文本表示.多头注意力机制的精妙之处在于,它能够提取每个输入部分的最重要特征,然后以高度交互的方式将这些特征融合,从而更好地捕捉不同输入之间的关联和上下文.通过多头注意力机制融合形成的多维特征经过Softmax函数输出,用于对待分类的基金新闻进行分类.模型通过概率值判断获得基金新闻文本所属类别.
多粒度特征融合文本分类模型可以有效地解决传统文本分类模型中不能充分利用文本中不同粒度特征的问题,对于基金新闻文本分类研究具有重要的意义和实际应用价值.该模型算法流程如算法2所示:
算法2.多粒度特征融合文本分类模型
输入:输入基金新闻文本类别标注数据 train[40000]、test[5000]、dev[5000]
输出:输出基金新闻文本分类结果C0:法规政策类,C1:宏观新闻类,C2:基金行情类,C3:行业要闻类,C4:评论展望类
1.INIT:加载BERT模型和tokenizer
2.INIT:定义训练参数:epochs,optimizer,learning rate,loss function
3.Data Deal = Data deal node selection(Self-Stop-Dictionary,Extended-Dictionary,Deal-Data)
4.ifSelf-Stop-Dictionary then
5. structure Self-Stop-Dictionary
6.endif
7.ifExtended-Dictionary then
8. structure Extended-Dictionary
9.endif
10.ifDeal-Data then
11. Filter stop words //自建停用词表
12. jieba //jieba 分词
13.endif
14.Input Data=Input Data(title,abstract,content)
15.Vectorization:Label Vectorization
16.Classification:BERT
17.MultiHeadAttention:title,abstract,content
18.Fully connected layer
19.Softmax
20.Return C0:法规政策类,C1:宏观新闻类,C2:基金行情类,C3:行业要闻类,C4:评论展望类
3 实验与分析
3.1 数据预处理
在基金新闻文本的标题、内容和摘要中,存在一些无用的标点符号或者无用词汇.如果直接将这些数据输入到BERT模型中,就会产生噪声,从而干扰文本分类的准确性.为了解决这一问题,本文构建了一个自建的停用词表,除了基于中文停用词表、哈工大停用词表、百度停用词表、四川大学及其智能实验室停用词库进行去重外,加入了一些针对特定领域的停用词,例如一些与基金领域不相关的词语、无实际意义的标点符号、虚词等.使用自建停用词表可以过滤掉文本中无用的信息,减少噪声的干扰,提高分类模型的准确性和可靠性.
3.2 基于聚类加权的基金新闻文类别标注方法
本文采用2.1基于聚类加权的基金新闻类别标签标注方法对91473条基金新闻数据进行聚类.实验结果表明,基于K-Means-Hasing聚类算法得到的聚类效果最好,且聚类结果边界清晰(见图4).这说明Doc2vec和DBSCAN算法的适用性受数据的特点和问题的影响较大.
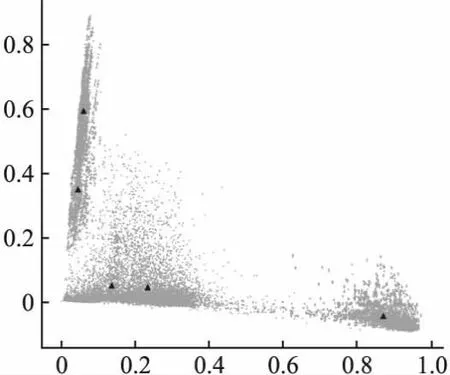
图4 K-Means-Hashing聚类结果Fig.4 K-Means Hashing clustering results
为了对基于聚类加权的基金新闻文类别标注结果进行有效性评估,本文对文本类别标注做人工校对调整(见图5).图5表明K-Means-Hashing聚类算法的0类、2类聚类结果与手工调整结果Data-class的0类、2类相似度较高,几乎完全相同.而K-Means-Doc2vec方法聚类结果比较平衡,边界清晰度欠缺,DBSCAN聚类效果较差.相比传统的手工标注方式,基于聚类加权的类别标注方法无需逐一阅读和标注每一篇文本,大大节省了人力和时间.因此,基于聚类加权的类别标注方法可以更加高效、准确地完成大规模基金新闻文本类别标注工作,为后续的基金新闻分类研究提供了有效的基础.
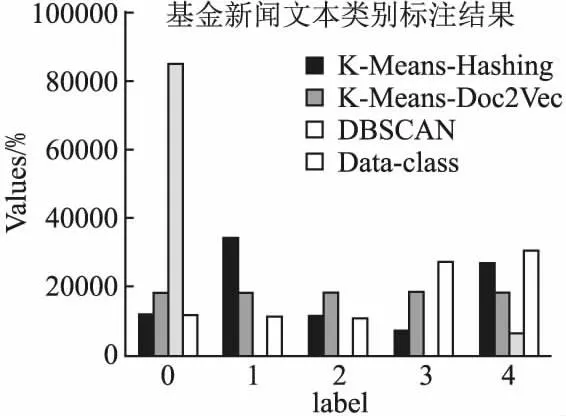
图5 基于聚类加权的基金新闻文类别标注结果Fig.5 Labeling results of fund news categories based on cluster weighting
3.3 实验数据
本文基于3.2标注的数据选取40000条基金新闻数据作为训练集,5000条作为验证集、5000条作为测试集.基金新闻标注为5个类别,分别为法规政策、宏观新闻、行业要闻、基金行情、评论展望,Label设置为0~4.本文所选用的基金新闻数据集类别分布相对较为均匀,相较于仅包含单一类别或类别分布不均的数据集,更能有效展现本文提出的多粒度特征融合模型的优秀特性.
3.4 实验评估指标
本文选取评价指标包括精确率(Precision)、召回率(Recall)和 F1值(F1)这3个指标来评估模型效果,评价指标计算公式如下:
(3)
(4)
(5)
其中,TP表示正确识别的基金新闻类别样本数,FP表示识别为正确类别的基金新闻但是实际上不是该类别基金新闻类别的样本数,TN表示正确识别没有标注错误的基金新闻类别样本数,FN表示没有识别的错误类别的基金新闻的样本数.
3.5 实验结果与分析
为了证明多粒度特征融合的基金新闻分类方法模型的有效性,本文从多方位和多角度对基金新闻文本进行分析和处理.将基金新闻文本分解为标题、摘要、内容3个粒度进行多样式融合,并将其作为本文的基准实验.此外,针对一些基金新闻缺少标题的问题,本文选取TFIDF关键词和TextRank关键词并集的前20个词作为该篇基金新闻的标题,从而完善了数据集,提高了分类模型的性能.
3.5.1 标题、内容粒度对模型分类效果影响
为了验证多粒度特征融合中的标题、内容、内容拼接标题3种粒度的实验效果,本文以BERT为分类模型,设计了表1中的3组实验,并通过多次实验调整最优参数,将dropout设置为0.2,学习率learn-rate设置为2e-5.该组实验作为本文的基准实验与对比实验进行对比.实验结果如表1和表2所示.

表1 标题、内容粒度融合实验结果Table 1 Fusion of ittle and content granularity

表2 Content+Title+BERT方法细分类的实验结果Table 2 Experimental results of content+Title+BERT method for subdividing classes
从表1可以看出,将基金新闻内容融合标题的模型在各项指标中优于单一粒度模型.相比于单一标题的F1值上升了15.28%,相比于单一内容的F1值上升了2.35%.这说明内容融合标题可以有效捕捉标题和内容中包含的关键信息,从而获得更好的实验结果.从表2可以看出来,0类、3类、4类的F1值比较高,同时每个分类任务的精确率都超过了90%,这说明1类、2类中存在噪声,模型学习该类别的特征比较困难.
3.5.2 词粒度对对模型分类效果影响
为了验证自建停用词表、扩展词典Vocab[100]对模型分类效果的影响,本文设计了表3中的4组实验.首先利用2.2.1节构建的自建停用词表作为预处理的停用词表对输入文本进行预处理;其次利用扩展词典融合到BERT中进行实验.实验结果如表3和表4所示.

表3 词粒度融合实验结果Table 3 Experimental results of word granularity fusion

表4 Content+Title+MyStopWords+Vocab[100]+BERT方法细分类的实验结果Table 4 Experimental results of content+Title+MyStopWords+Vocab [100]+BERT method for subdividing classes
从表3可以看出,从词粒度分析,融合自建停用词表和扩展词表的F1值最高.这说明自建停用词表可以去除无意义和噪声单词,使得文本中有意义的单词和短语更加突出,从而提高了文本特征的表达能力.在去除无意义单词和噪声单词之后,BERT模型可以更好地捕捉文本中有意义的特征.而扩展词典通常是一些特定领域词汇,可以增加模型对领域专业术语的识别和理解能力,从而提高模型在特定领域或任务上的性能表现.从表4可以看出来,0类、3类、4类的F1值比较高,同表2实验结果相似,这说明这3类文本特征比较明显容易捕捉.
3.5.3 句子粒度对模型分类效果的影响
为了验证多粒度中文本摘要和扩展词表对模型的影响,设计了表5中的13组实验,基于2.2.2节TFIDF和TextRank关键句抽取方法抽取基金新闻文本摘要.通过利用TFIDF抽取比例为30%、50%、60%的句子进行实验对比,最终选取F1值较高的30%句子作为表5中的对比实验.利用TextRank分别抽取基金20句、50句、150句、200句作为基金新闻文本摘要,分别融合扩展词表Vocab[100]进行多粒度融合实验.实验结果如表5和表6所示.

表5 句粒度融合实验结果Table 5 Experimental results of sentence granularity fusion

表6 TentRank-150(Sentences)+Vocab[100]+BERT方法细分类的实验结果Table 6 TentRank-150 (Sentences)+Vocab [100]+BERT for subdividing classes
从表5可以看出,从句子粒度分析,TextRank抽取150个句子作为摘要的F1值最高.不同数量的句子作为输入,对BERT模型的分类效果会产生不同的影响.抽取20句子时,抽取的关键句子数量过少,可能无法涵盖文本的重要信息.抽取50句子时,虽然抽取的关键句子数量增加,但可能出现文本信息不全、重复或者冗余的情况,也可能对BERT模型的分类效果造成一定的影响.而当句子数量增加到150时,抽取的关键句子数量更多,可以更全面、准确地表达文本的语义信息,并且不会出现信息冗余的情况.如果句子数量大于200,尽管抽取的关键句子更多,但输入文本也变得过于冗长,可能会对BERT模型的表现造成不利影响.从内容、标题、摘要融合分析,未融入摘要句子的实验效果比较好.另外,从扩展词典角度分析,融入扩展词典的F1值比较高.从表6可以看出来,0类、3类、4类的F1值比较高.
3.5.4 标签向量化对模型分类效果的影响
为了验证标签向量对模型分类效果的影响,设计了表7中的2组实验,分别将融合自建停用词表和扩展词典的实验再进一步同标签向量进行融合,实验结果如表7和表8所示.

表7 标签向量化融合实验结果Table 7 Experimental results of label vectorization fusion

表8 Content+Title+MyStopWords+One-Hot+BERT+Vocab[100]方法细分类的实验结果Table 8 Content+Title+MyStopWords+One Hot+BERT+Vocab [100]for subdividing classes
从表7可以看出,融合标签向量的实验结果F1值较高.这说明标签向量化技术使得BERT模型可以更好地捕捉标签之间的关系,从而提高了模型的分类辨别能力.从表8可以看出来,0类、3类、4类的F1值比较高.
3.5.5 多头注意力机制对模型分类效果的影响
为了评估多头注意力机制对本文所提出的多粒度特征融合文本分类模型分类效所产生的影响,本文进行了一系列精心设计的实验.本文的多头注意力机制针对输入的标题、摘要和内容进行了建模,以捕捉不同层次和粒度的语义关系.为了充分验证多头注意力的效果,设计了表9中的8组实验,对比了BiLSTM、CNN的分类效果,实验结果如表9和表10所示.

表9 多头注意力机制融合实验结果Table 9 Experimental results of multi head attention mechanism fusion

表10 Content+Title+MyStopWords+Vocab[100]+One-Hot+Multi-head-attention+BERT细分类的实验结果Table 10 Content+Title+MyStopWords+Vocab [100]+experimental results of one Hot+Multi head attention+BERT method for subdividing classes
从表9可以看出,深度学习融合模型比单一模型的分类效果好,融入多头注意力机制的模型比未融入的分类效果较好.其中融入以基金新闻标题、TextRank抽取150个句子、内容作为输入的多头注意力机制实验的F1值最高.相比于BERT+BiLSTM的F1值上升了1.02%,相比于BERT+CNN的F1值上升了5.42%,相比于BERT+CNN+Multi-head-attention的F1值上升了1.66%,相比于BERT+Multi-head-attention+CNN的F1值上升了0.90%,相比于Multi-head-attention+BiLSTM的F1值上升5.95了%.这说明单一的CNN模型在特征提取方面只考虑基金新闻文本的局部特征,单一的BiLSTM模型在结合前向信息和后向信息做深入获取时具有一定的局限性.融合多头注意力机制可以使模型更好地关注文本中的不同部分,从而更好地理解文本的含义和上下文信息.通过给不同的文本部分分配不同的权重,多头注意力机制可以帮助BERT模型更好地捕获文本中的重要信息,从而提高整体的性能和效果.从表10可以看出,本文提出的模型实验中0~4类的F1值都比较高.这说明本文提出的多粒度特征融合的基金新闻文本分类方法具有相当的泛化能力,可以显著提高模型的分类性能,为其他文本分类问题的解决提供了有效借鉴.
4 结束语
本文提出了基于聚类加权的文本类别标注算法,可有效节省人力成本,还可提取基金文本的特征,为多粒度特征融合的文本分类算法实验提供了有效的数据支撑.基于聚类加权的文本类别标注算法实验结果,提出了多粒度特征融合的文本分类算法,该算法有效地将标题、内容、摘要等多粒度作为特征拼接,输入到BERT模型中.进一步地,本文利用多头注意力机制融合多种特征提高文本分类效果.
实验结果表明,本文提出的多粒度特征融合文本分类模型相较于其他方法具有较好的分类性能.为了进一步提升分类效果,后续工作中将对数据内容进行更加细致的分析,使用更加高级的技术方法比如Word2Vec、义原向量等来丰富词汇特征.
